
管理层语调视角下的上市公司财务风险预警
2022-03-04 12:06李程李聪
金融理论探索 2022年1期
李程 李聪



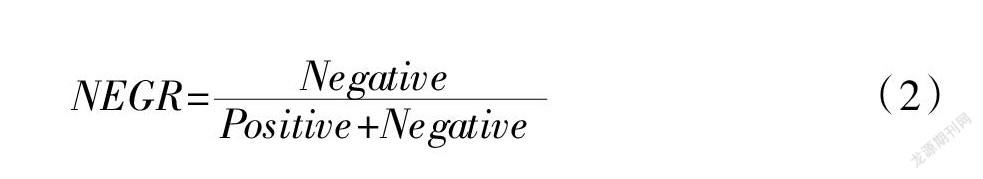



摘 要:为了解决现有财务风险预警模型中指标大量冗余相关性高、实时分析能力差以及忽略财务文本信息的问题,提出一种管理层语调视角下的财务风险预警模型。选取2016—2020年276家上市公司作为研究样本,从五个维度筛选了财务数据指标后,对企业财务年报中的前瞻性信息进行中文分词处理并根据常用情感词典计算其语调,并加入财务指标,利用因子分析降维,消除指标冗余和其间的相关性,提取出少量共性因子,最后采用支持向量机构建风险预警模型。结果表明,五维指标体系与因子分析所得的共性因子具有较强的一致性,证明了因子分析的经济意义可解释性。同时,结合财务文本信息可以有效提高财务风险预测的准确率,验证了财务文本对风险预警模型的有效性。
关 键 词:管理层语调;上市公司;风险预警;财务风险
中图分类号:F832.5 文献标识码:A 文章编号:2096-2517(2022)01-0061-11
DOI:10.16620/j.cnki.jrjy.2022.01.007
一、引言
随着经济全球化进程的快速发展和上市公司之间竞争的激烈化,企业在经营过程中背负着巨大的财务风险和不确定性,进而可能导致财务危机的发生。在市场经济中,财务风险对于每一家公司的投资者和经营者来说无处不在。截至2020年年底,国内因为发生财务危机而被ST处理的上市公司就高达272家。被ST或ST*处理的公司,不仅会给投资者带来巨大的经济损失,同时也会使上市公司背负较大的运营、生产压力,随时都有退市的可能性。
但一般而言,企业的财务危机和破产并不是突然发生的,而是一个循序渐进的过程。在危机的萌芽阶段,公司某些局部的财务危机和困难都会在一定程度上暴露,而这种异常在一些财务数据指标上可以体现,并被广泛用于财务预警。建立高效、准确的预警系统可以在风险发生的早期就向公司管理层发出警报,有助于上市公司实时应对导致其财务状况恶化的问题,及早消除危机。此外,智能的预警系统还能辅助投资者做出正确的投资决策,有利于信贷风险的防控。因此,精确预测上市公司的财务危机,有效防范金融风险,最大限度地避免金融危机的再度发生,一直是世界各国关注的焦点,具有重要的现实意义。如何建立一套实时、准确的金融风险预警体系一直是国内外学者的重点研究方向,在财务数据指标的选取和模型建立的方法等各个方面取得了出色的成果[1-4]。
20世纪60年代,国外对财务危机预警的研究基于一定的会计信息和统计理论,取得了一定的成果并广泛应用于实际。如Altman(1968)通过分别对美国20年间的破产公司和正常盈利公司的模式进行深度挖掘后提出的利用财务指标来判断危机的Z值模型,与设定的阈值对比即可判断上市公司的财务危机程度[5],但其适用范围比较狭窄,只能对制造业相关的上市公司进行预测。Beaver(1966)提出了单变量模型,在对财务风险进行预测时选择了5对财务指标做线性回归分析,并发现模型结果与现金流动负债比率具有较高的相关性[6],但过于依赖简单的线性回归模型并不能对复杂数据做出准确的拟合,一般来说模型处于欠拟合状态,无法得到较高的预测准确率。
财务危机的判定是一个典型的二分类问题。因此,随着人工智能和机器学习的迅速发展,涌现出了一批采用机器学习的分类方法对公司财务风险进行研究的学者。比如,文柯(2012)利用Logistics回归模型构建了我国企业产融结合风险预警模型,并揭示了企业偿债能力、盈利水平和营运能力与企业产融结合后发生财务危机的关系[7]。张琳等(2021)利用Logistic模型探究企业ESG表现在债券信用风险预警中的应用[8]。谷慎等(2019)利用支持向量机以我国的碳金融试点市场为研究样本,构建了风险预警模型[9]。但上述研究中,无论是早期的单变量分析和多变量分析法还是近年来的机器学习方法,均存在一个共同的缺陷,都仅以定量数据为基础, 而忽略了定性的财务文本信息。
自然语言处理(Nature Language Processing,NLP)和文本分析的迅速发展,为分析财务文本中的语调提供了不可或缺的帮助。情感语调是文本信息语言的重要特征之一。依据心理学效应,文本中正向的情感语调会激发接收者联想积极、正面的信息,而负向语调则向接收者传递消极、负面的信息。类似的, 财务年报作为上市公司的重要文本信息,其管理层讨论与分析(Management Discussions and Analysis,MD&A,以下简称MD&A)部分语调的走向对于财务风险预警具有一定的参考意义。MD&A文本由董事会回顾和未来展望两部分内容组成,而未来展望信息具有一定的前瞻性,对风险发生的预测具有互补性的作用。谢仁德等(2015)基于上市公司年度业绩说明会的相关文本,对管理层语调和公司业绩的关系进行研究,结果显示二者呈显著正相关关系[10],这对投资者挖掘和利用文本信息具有重要意义,揭开了国内学者对财务文本语调研究的序幕。刘逸爽等(2018)对公司财务年报文本进行分词后根据常用情感词典计算文本语调,并结合公司的财务指标,利用logistics回归、SVM等机器学习方法证明了文本信息语调对财务危机预警的有效性[11]。
已有的研究为财务危机预警提供了新的视角,引入了语调分析方法,但其研究中加入了大量的财务数据指标,而财务指标之间通常具有较强的相关性,导致严重的数据冗余,给公司财务预警系统的实时计算带来了较大的难度和较高的算力成本,甚至还会降低模型预测的准确率。
综上所述,为解决现有风險预警模型中指标大量冗余、相关性高以及忽略财务文本信息对于企业破产预测效用的问题,并进一步提高模型预测的准确率, 本文首先从五个维度初步选取财务指标,并对样本公司的财务年报MD&A部分进行中文分词,参考常用金融情感词典计算管理层语调,并考虑单独加入负向词频比率的影响,最后融合财务指标和管理层语调进行因子分析,剔除冗余信息并压缩数据,提取出少量共性因子,采用支持向量机来构建风险预警模型, 并与未压缩的模型进行对比。
二、研究设计与指标选择
(一)样本选择
对于上市公司出现财务危机的概念与定义,国内外研究者暂未形成统一的观点,国内学者一般以上市公司因出现财务异常状况被ST作为可能的财务风险标志[12]。由于上市公司的财务年报是在当前年度结束后的4个月内发布,因此该公司t-1年年报的发布与其在t年是否被ST处理是同时发生的,本文采纳刘逸爽等(2018)的方法[11],模型输入的数据均滞后两期,即使用t-2年(2018年)的数据来预测该公司在t年(2020年)是否会因财务状况异常被ST处理,使模型具有更强的风险预测能力。
本文选取2016—2020年A股全部上市公司中证监会2012版行业分类为制造业的ST公司,并采用样本配比原则,即选择行业相同、公司规模相近的非ST公司作为配对样本。为保证实证结果的准确性,本文选取1:1和1:2两种比例确定实证样本中ST公司和非ST公司的数量进行实验。剔除缺失数据的样本后,确定ST公司共92家,健康公司(非ST公司)共184家,合计276家,并以7:3的比例划分得到模型训练集和测试集。
(二)财务指标的选取与定义
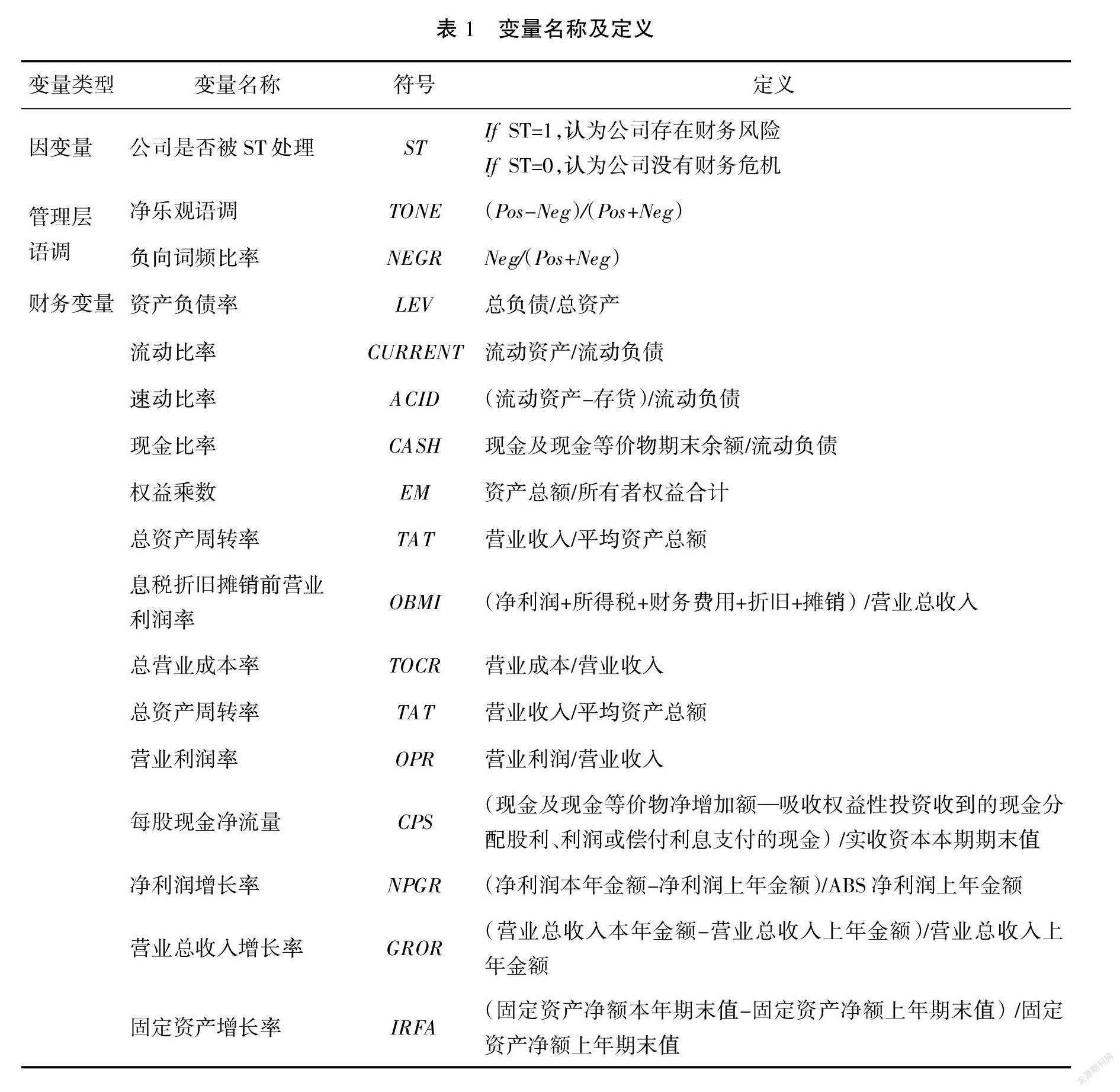
财务指标是指上市公司总结和评价其财务状况和经营绩效的相对指标。通过结合已有文献和大量实验的基础上,本文的财务指标分别从上市公司的偿债能力、经营能力、盈利能力、每股指标和现金流分析五个维度选取,包含流动比率(CURRENT)、速动比率(ACID)、现金比率(CASH)、资产负债率(LEV)、权益乘数(EM)、总资产周转率(TAT)、营业利润率(OPR)、息税折旧摊销前营业利润率(OMBI)、总营业成本率(TOCR)、净利润增长率(NPGR)、营业总收入增长率(GROR)、固定资产增长率(IRFA)和每股净现金流量(CPS),其定义如表1所示。
本文选取的财务指标均来源于CSMAR数据库,为了避免离群点对本文实证分析的影响,对所有连续型财务指标均进行了上下1%的Winsorize处理,最终纳入本文机器学习模型的有效年度财务指标观测值为3588个。
(三)财务年报MD&A文本语调计算
Loughran等(2009)指出,管理层人员在金融文件中更专注于讨论“公司责任”“社会责任”等类似主题的上市公司更有可能被贴上罪股的标签,公司治理措施不当, 并在提交文件后的一年被起诉[13]。考虑到上市公司财务年报中MD&A部分能体现出管理层语调对公司持有一定程度的积极或消极态度,本文对此部分文本纳入模型。本文上市公司财务年报均来源于新浪财经网,从中截取MD&A部分。在衡量一份金融文件的语气或情感时,研究人员通常会计算与特定情绪词列表相关的单词数,并将其按文档中单词总数进行缩放。例如,文档中较高比例的否定词倾向于更悲观的语气。
Loughran等(2016)指出对金融文本的情感分析主要有两种方法:机器学习法和词袋法(Bag of Words)[14]。机器学习方法主要通过朴素贝叶斯(Na?觙ve Bayes)等分类算法对文本进行训练以确定分类准则, 再应用于全样本中进行预测,但其分类准则通常带有一定程度的主观性。而词袋法依据情感词典对文本情感进行正向和负向分类,在使用合适的情感词典后可以基本避免主观因素的影响。Connor等(2010)也認为通过词袋法来分析小型文本的情感倾向尤为合适[15]。LM词表相对全面, 一般来说,没有常见的消极或积极的词缺失;它的创建考虑到了财务沟通。因此本文参考LM词典,将其作为衡量财务年报文本的基准,同时结合大连理工大学整理的情感词典中的褒贬义词, 通过Python的HanLP作为分词工具对财务年报文本进行分词处理后,进行正向和负向情感词频统计,在此采用归一化的方法计算MD&A管理层语调Tone, 其计算公式如下:
Tone= (1)
式中,Positive为上市公司财务年报MD&A文本中正向情感词频,Negative则为同一文本中的负向情感词频。可以看出,Tone的取值范围在-1到1之间,且Tone的值越接近1,说明管理层语调越积极,反之则说明管理层的语调偏向消极态度。
同时,考虑到负向词汇会披露更多的财务风险信息,本文将负向词频比率NEGR也纳入到模型中训练,其计算公式如下:
NEGR=(2)
综上,本文构建了两个衡量管理层语调的指标,整体指标体系中的变量,如表1所示。
三、财务困境预警模型的构建
国内外学者在财务困境预测的相关研究中,大多使用两类方法,一是较为传统的方法,如单变量模型、Altman多元回归模型和Z值模型;二是基于机器学习中监督学习的分类算法, 如Logistics回归、支持向量机、决策树和AdaBoost等。而传统的Altman多元线性回归的回归系数更适用于美国国情,若直接套用会造成某些财务指标畸变,导致分类预测精度较低。而机器学习的方法通常能学习到指标具有的特征,可以得到较高的准确率。因此,本文考虑使用机器学习的方法进行模型的构建和实证分析。
在选择预警指标进行训练的时候,可能会遇到较多冗余特征,随着数据样本量的不断增大,模型训练结果的精确度虽然会有小幅度提升,但同时带来巨大的时间和算力成本,这在实际情况中是不现实且不被允许的。 因此本文对选取的16个指标使用因子分析,将高维的数据转化为低维的数据后再次进行训练,同时与直接使用支持向量机的模型进行对比。
(一)支持向量机
支持向量机(Support Vector Machine,SVM)是一种分类算法,它的基本模型是定义在特征空间上的几何间隔最大的线性分类器, 而核技巧(kernel method)和软间隔的引入,使其能够很好地解决高维非线性分类问题,支持向量机在中小型样本上具有尤佳的表现[16-17]。
在给定的训练数据集T={(X1,y1),(X2,y2),…,(XN,yN),}中,待求解的最优分类超平面?仔由W·X+b=0确定。其中,W为特征学习出的权重矩阵,b为偏置,因此超平面可用(W,b)表示。分类超平面将特征空间划分为正类和负类两部分,其对应的分类决策函数为f(x)=sign(W·X+b)。
间隔(Margin)可以度量一个样本点距离分类超平面的远近,从而表示分类预测的确信度,引入超平面(W,b)关于训练集T的函数间隔■和几何间隔?酌分别为:
=min yi(W·Xi+b)
= (3)
支持向量机考虑求解一个几何间隔最大的分离超平面,具体地,可以定义为以下最优化问题:
s.t.(W·Xi+b)yi≥ (4)
其中,i=1,2,…,N。因为函数间隔的取值并不影响最优化问题的求解,因此假设=1。这样一来,X到平面?仔的最大距离为?酌=1/‖W‖。注意到最大化?酌和最小化‖W‖2是等价的,因此得到等价的凸二次规划问题:
WT·W
s.t.(W·Xi+b)yi≥1 (5)
为了求解该规划问题,应用拉格朗日对偶性,为了方便求解该优化问题和自然地引入核函数,通过求解其对偶问题(dual problem)得到原始问题(primary problem)的最优解。具体地,引入Lagrange函数,对约束条件分别加入Lagrange乘子?琢i,即:
L(W,b,)=WT·W-i[yi(W·Xi+B)-1]
(6)
令其相应的偏导数为0,可以分别得到:
将求得的偏导数代回Lagrange函数后,求L(W,b,)对的极大,即是求解对偶问题:
求解此二次规划问题,即可得到最优分类超平面。对于非线性分类问题的求解,首先需要对数据进行归一化,利用核函数将样本从原始空间映射到高维空间,使其线性可分。本文使用的函数为高斯径向基函数:
f(x)=signiyi·exp-+b (9)
(二)因子分析
因子分析(Factor Analysis,FA)是指通过寻找多个可观测变量相关矩阵的内部依赖关系,从中提取少数共性因子,从而将原始观测变量表达为共性因子的线性组合的降维技术。因子分析在简化大规模观测变量系统、减少观测变量维度的方面起到了至关重要的作用。利用公共因子代替原始观测系统,使得因子之间代表的信息互不重叠,在一定程度上解决了数据冗余的问题[18-19]。
设要进行因子分析的原始观测变量有m个,记为x=[x1,x2,x3,…,xm],n个样本对应的观测值为xik(i=1,2,3,…,n;k=1,2,3,…,m),记样本协方差矩阵为:
sk=(xik-xk)(xik-xk)'=(sik) (10)
其中,xk=xik为样本均值。
一般p的确定原则为累积贡献率大于等于75%。
因子分析中的公共因子是不可直接观测但又客观存在的共同影响特征,每一个变量都可以表示成共性因子的线性表达及特殊因子之和,即:
X1=a11F1+a12F2+…+a1m Fm+i,X2=a21F1+a22F2+…+a2m Fm+i,…Xp=ap1F1+ap2F2+…+apm Fm+i (11)
式中,F1,F2,…,Fm為Xi的共性因子,?着i为Xi的特殊因子。因此,因子分析的矩阵表达形式为:
简记为:
其中,矩阵A称为因子载荷矩阵,是第i个变量在第j个共性因子上的载荷,由主成分分析确定。
之后,由相关系数矩阵R得到特征值?姿j(j=1,2,3,…,m)及各个主成分的方差贡献率、贡献率和累计贡献率,并根据累计贡献率确定主成分保留的个数p。
如果共性因子有m个,则需要逐次对每两个共性因子进行旋转操作,也就是对每两个因子确定的因子面正交旋转一个角度,转角需要满足使旋转后的因子载荷矩阵A总方差达到最大值,并得到因子得分。至此,因子分析的过程全部完成。
四、实证结果与分析
(一)指标的描述性统计与显著性差异检验
为了确定ST公司和非ST公司之间是否存在显著差异, 本文利用非参数检验中的Wilcoxon符号秩和检验(也称Wilcoxon Mann-Whitney检验)来考察财务风险带给两类公司的差异性。若检验统计量显著, 则说明该指标可以有效区分ST公司和非ST公司,反之则不能有效区分。
表2给出了本文确定的指标体系描述性统计和Wilcoxon符号秩和检验结果。 除了净利润增长率(NPGR)的Wilcoxon检验不显著外,其余指标均较为显著,可以很好地区分财务困境和财务状况健康的上市公司。其中,现金比率(CASH)、总资产周转率(TAT)、总营业成本率(TOCR)、管理层语调(TONE)和负向词频比率(NEGR)的Wilcoxon检验Z统计量均小于-5.39,说明这些指标对区分ST和非ST公司起到了至关重要的作用。由管理层语调的定义式可得,当其值大于0时,表明管理层对公司的语调基本呈现乐观趋势。实际计算出的管理层语调均值为0.5672,中位数为0.5763,两者较为接近,说明选取的研究样本均匀分布,且MD&A文本大多呈现出管理层较为乐观的态势。
(二)基于支持向量机的实证分析
本文将主要以预测准确率(accuracy)、第一类错误(Type I Error)、第二类错误(Type II Error)和AUC四个指标来衡量本文模型在财务风险预警中的作用, 模型测试集为样本确定的92家上市公司。
在衡量指标中,AUC代表接收者操作特征曲线(Receiver Operating Characteristic Curve,ROC)下所围成区域的面积,其x轴为负假阳率,y轴为真阳率,是评价二分类模型优劣的重要指标之一。ROC曲线对于正负样本数量不平衡的模型具有很好的适应性, 考虑到本文采用了1:1和1:2两种样本比例, 因此将其作为评价指标。 随机分类情况下的AUC值为0.5,AUC数值越接近于1, 说明模型的有效性越强。
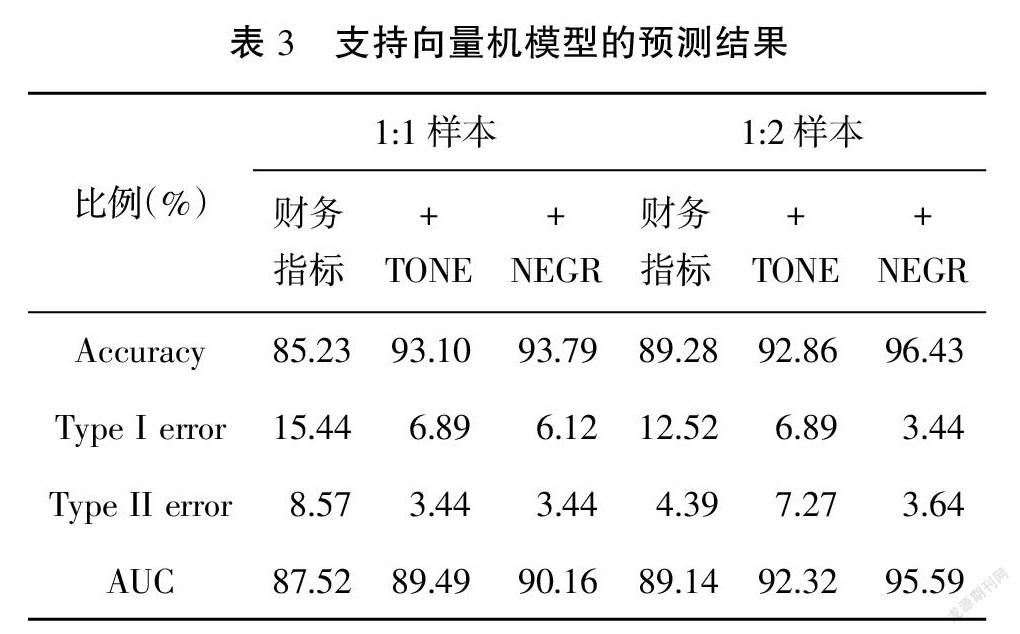
表3给出了在两种样本比例下支持向量机模型的实验结果。在加入管理层语调指标后,样本比例1:1时,整体准确率都有一定提高,并较为显著地降低了第一类和第二类错误发生的情况;样本比例1:2时,模型的预测准确率有一定提升,而加入负向语调词频后,预测准确率从89.28%上升至96.43%,并显著减少了第一类错误的发生,AUC也提升至90%以上,证明财务年报文本语调信息对预警起到重要作用。
(三)基于因子分析和支持向量机的实证分析
首先对初步筛选的16个指标利用因子分析进行降维后,再使用支持向量机进行财务预警模型的构建,以比较因子分析在復杂观测系统中起到的克服相关性、重叠性的问题,并对比SVM模型的预测效果。
在进行因子分析前, 需要使用KMO和巴特利特检验判断原始观测系统之间是否存在相关性。表4给出了本文所选指标体系的KMO和巴特利特检验结果。其中,KMO值为0.612,大于经验阈值0.6。同时, 巴特利特球形度检验的显著性远小于0.05,拒绝各观测指标间独立的假设,认为变量间具有较强的相关性。因此,检验的结果均表明本文构建的指标体系适合进行因子分析。
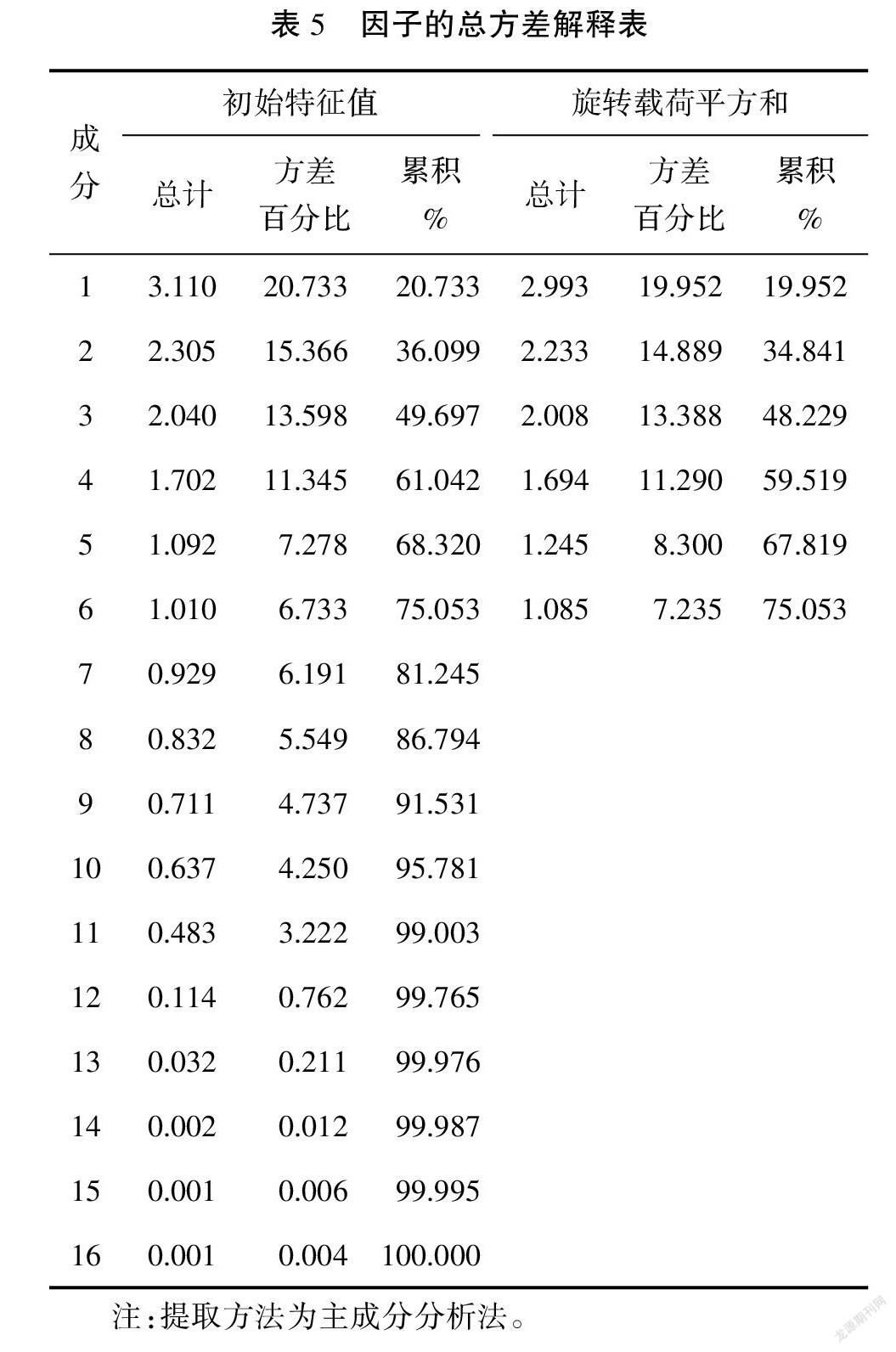
在进行因子分析的过程中,可以通过因子的总方差解释表确定要选取共性因子的个数,该表需要计算各个因子的特征值、 贡献率和累计贡献率,表示各观测指标中所含原始信息能被提取的共性因子所表达的程度,即变量信息被提取的占比,如表5所示。
由表5结果可以得出,前6个共性因子包含了原始观测系统中75.053%的信息,累计贡献率大于70%,满足因子分析要求。从第7个共性因子开始,其包含的原始观测系统信息逐渐减少, 后10个共性因子仅包含原始系统中不到25%的信息,因此可以放弃这10个因子, 利用前6个共性因子代替之前选取的16个观测指标。
通过共性因子的碎石图也可以判断各因子对原始观测系统的重要性,如图1所示。横轴代表共性因子的序号,纵轴代表其特征根大小。坡度越陡,对应的特征根越大, 表示该因子起到的作用越明显。在因子分析中,一般选取特征根大于1的作为共性因子,因此碎石图验证了本文选取前6个共性因子的正确性。
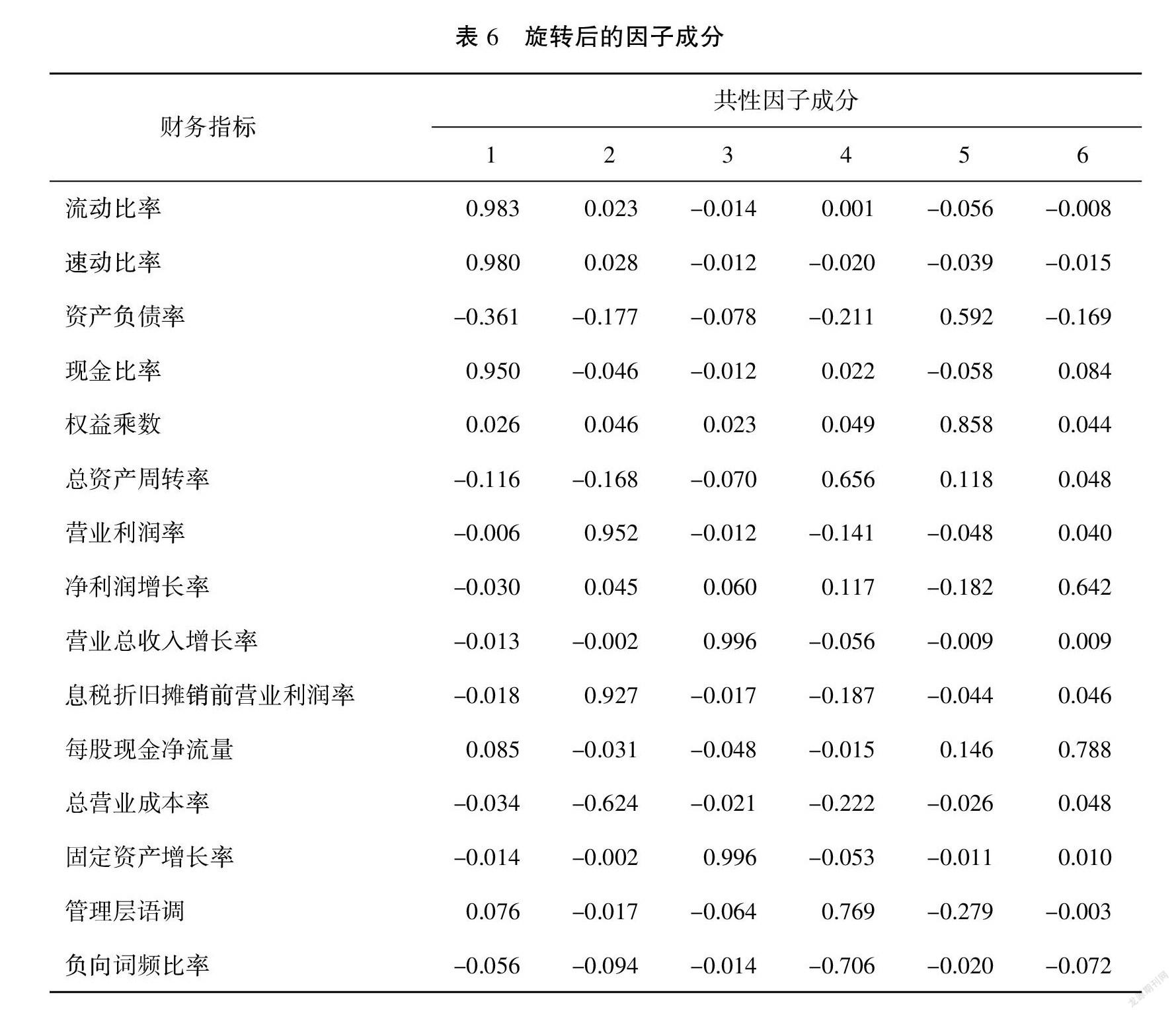
由于在初始的因子载荷中,确定的6个共性因子的意义并不明显,为了清晰地解释各公共因子的经济含义,需要对因子进行旋转。表6展示了使用凯撒正太化方差最大化的正交旋转所得到的因子载荷矩阵。
由表6可以看出, 第一共性因子在流动比率、速动比率、现金比率三个指标具有90%以上的载荷量,反映了上市公司的偿债能力,因此第一共性因子可以定义为“偿债因子”;第二共性因子在营业利润率、 息税折旧摊销前营业利润率两个指标具有90%以上的载荷量, 反映了上市公司的盈利能力,因此定义第二共性因子为“盈利因子”;第三个共性因子在营业总收入增长率、固定资产增长率两个指标具有95%以上的载荷, 反映了公司的规模状况,因此定义第三共性因子为“规模因子”;第四个共性因子,在管理层语调和负向词频比率上的载荷量较高,因此命名为“管理层响应因子”;第五个共性因子在权益乘数、资产负债率上具有较高的载荷量,反映了上市公司的负债程度,因此命名为“负债因子”;最后一个共性因子在每股现金净流量、总资产周转率和净利润增长率上具有较高的载荷,可以看作公司的“成长因子”。
综上,六个共性因子与上文选取的财务指标维度较为吻合,验证了因子分析的有效性和经济意义可解释性。
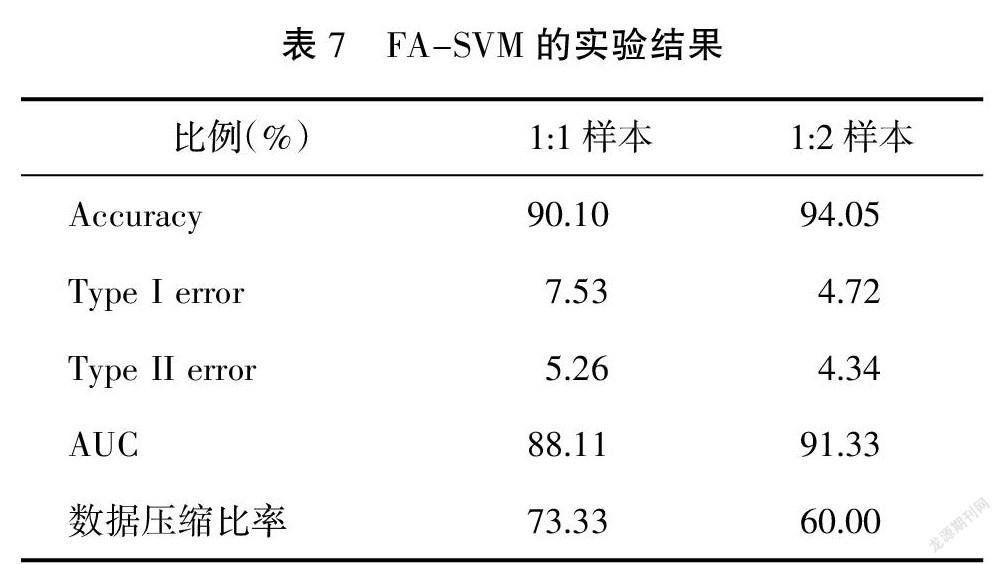
最后,根据旋转成分矩阵,将原始观测系统的指标表示为公因子的线性形式,也称为得分因子函数。至此,因子分析完成,16个指标降维至6个共性因子指标。将因子分析得到的6个共性因子输入支持向量机中进行训练,并与直接使用支持向量机的结果进行数据压缩量对比,如表7所示。
由表7可以看出,与单独使用支持向量机的模型一样,FA-SVM模型在两种比例的上市公司财务风险预测上均取得了90%以上的精确率,而相较于SVM模型所使用的观测指标系统,FA-SVM模型分别得到了73.33%和60%的数据压缩率, 这对提升企业预警的实时性起到了至关重要的作用。
五、结论与启示
上市公司财务年报中MD&A部分的内容是其信息披露的必要组件之一,对这部分文本的处理与分析有助于投资者更好地了解企业的真实财务现状, 同时帮助企业经营者更准确地预测财务困境,合理做出调节。本文以财务困境公司和正常运营公司的财务数据及年报文本为研究对象,通过初步筛选财务数据指标, 对年报文本进行中文分词后,根据情感词典计算语调得分,并将更有可能对风险起到预警作用的负面语调单独计算作为指标,融合财务指标进行因子分析,得到少量共性因子,采用支持向量机的方法建立财务预警模型,并对进行因子分析前后的模型分别分析。
本文得到的主要结论有:
第一,无论在配对样本比率为1:1还是1:2的实验条件下, 向财务指标体系中加入MD&A文本计算所得的管理层语调均可以提升财务风险模型预测的有效性,且在是否加入因子分析方法时均成立。这一结论表明企业财务年报文本内容确实会给风险预警带来一定的增益信息,量化财务文本内容是对定量财务数据的合理补充。
第二,加入单独计算的负向语调对模型预测的准确率有一定的提升,说明了文本中揭露的管理层负向信息能更有效地反映企业经营现状。
第三,基于因子分析处理错综复杂的财务指标是有效的。使用因子分析,不仅消除了财务指标之间的冗余性,降低共线性,还赋予了提取出的公共因子以合理的经济意义,压缩了模型空间并提升了支持向量机模型的计算速度。
综上所述,在对上市公司财务困境进行建模和预测时,可通过对其财务年报中管理层披露的文本信息进行多尺度地挖掘和利用,建立合理情感语调指标对更好地强化风险预警具有重要意义。同时,可以将本文对公司财务年报的研究推广到任何与公司有关的公开文本,如社交媒体舆论、新闻报道等,多元化的信息来源有助于扩展公司信息披露,对于进一步优化风险信用预警有着至关重要的意义。但是需要注意的是,现实中存在较大道德风险的企业管理层可能故意放出正面信息,使得财务风险难以识别,这时不能一味依靠管理层语调的变化来判断财务风险,而是应该根据其他指标,更加客观地综合考量企业财务风险的真实状况。
参考文献:
[1]庞清乐,刘新允.基于蚁群神经网络的财务危机预警方法[J].数理统计与管理,2011,30(3):554-561.
[2]杨毓,蒙肖莲.用支持向量机(SVM)构建企业破产预测模型[J].金融研究,2006(10):65-75.
[3]鄒清明,黄钟亿.基于比例优势模型的上市公司财务困境预测研究[J].数理统计与管理,2016,35(3):536-549.
[4]赵冠华.基于遗传算法和熵的缩减记忆式LS-SVM财务困境预测模型研究[J].运筹与管理,2010,19(5):71-77.
[5]ALTMAN E I.Financial Ratios,Discriminant Analysis and the Prediction of Corporate Bankruptcy[J].Journal of Finance,1968,23(4):589-609.
[6]BEAVER W H.Financial Ratios as Predictors of Failure,Empirical Research in Accounting:Selected Studies[J].Journal of Accounting Research,1966:179-199.
[7]文柯.基于Logistic的上市公司产融结合风险预警模型研究[J].中国管理科学,2012,20(S1):346-350.
[8]张琳,潘佳英.融入ESG因素的企业债券信用风险预警研究[J].金融理论探索,2021(4):51-65.
[9]谷慎,汪淑娟.基于SVM的碳金融风险预警模型研究[J].华东经济管理,2019,33(3):179-184.
[10]谢德仁,林乐.管理层语调能预示公司未来业绩吗?——基于我国上市公司年度业绩说明会的文本分析[J].会计研究,2015(2):20-27,93.
[11]刘逸爽,陈艺云.管理层语调与上市公司信用风险预警——基于公司年报文本内容分析的研究[J].金融经济学研究,2018,33(4):46-54.
[12]李秉成,苗霞,聂梓.MD&A前瞻性信息能提升财务危机预测能力吗——基于信号传递和言语有效理论视角的实证分析[J].山西财经大学学报,2019,41(5):108-124.
[13]LOUGHRAN T,MCDONALD B,YUN H.A Wolf in Sheep's Clothing:the Use of Ethics-Related Terms in 10-K Reports[J].Journal of Business Ethics,2009,89(suppl.1):39-49.
[14]LOUGHRAN T,MCDONALD B.Textual Analysis in Accounting and Finance:A Survey[J].Journal of Accounting Research,2016,54(4).
[15]O'CONNOR B,BALASUBRAMANYAN R,ROUTLEDGE B R,et al. From Tweets to Polls:Linking Text Sentiment to Public Opinion Time Series[C]// Proceedings of the Fourth International Conference on Weblogs and Social Media,ICWSM 2010,Washington,DC,USA,May 23-26,2010. DBLP,2010.
[16]王泽霞,李正治.基于管理层讨论与分析情感性的财务预警研究[J].杭州电子科技大学学报(社会科学版),2019,15(3):1-6.
[17]陈艺云,贺建风,覃福东.基于中文年报管理层讨论与分析文本特征的上市公司财务困境预测研究[J].预测,2018,37(4):53-59.
[18]陈艳娇.基于因子分析的国有农场财务危机预警实证研究[J].经济问题,2007(5):109-111.
[19]顾雪玲,燕璇.基于显著性检验和因子分析的企业财务危机预警研究[J].商业会计,2015(18):42-45.
Financial Risk Warning from the Perspective of Management Tone
——Research Based on FA-SVM Model
Li Cheng1, Li Cong2
(1. School of Economics and Management, Tiangong University, Tianjin 300387, China;
2. School of System Science, Beijing Normal University, Beijing 100875, China)
Abstract: In order to solve the problems of the existing financial risk early warning models with a large number of indicators, high redundancy, poor real-time analysis capabilities, and ignoring financial text information for corporate bankruptcy prediction, this paper proposes a financial risk early warning model under the perspective of management tone. Selecting 276 listed companies from 2016 to 2020 as the research sample, after preliminary screening of financial data indicators from five dimensions, the forward-looking information in the corporate financial annual report is processed in Chinese word segmentation and the tone is calculated according to the commonly used emotional dictionary, and the financial data is added for indicators. And factor analysis is used to reduce dimensionality, to eliminate indicator redundancy and the correlation between them. We try to extract a small amount of common factors, and finally use support vector machines to build a risk early warning model. The experimental results show that the five-dimensional index system selected in this paper has strong consistency with the common factors obtained by factor analysis, which proves the economic significance of factor analysis and the interpretability. At the same time, the combination of financial text information can effectively improve the accuracy of financial risk prediction, which verifies the effectiveness of financial text on risk early warning models.
Key words: management tone; listed company; risk warning; financial risk
(責任编辑:李丹;校对:卢艳茹)
猜你喜欢
现代企业(2022年5期)2022-05-31
商情(2017年23期)2017-07-27
考试周刊(2016年82期)2016-11-01
商(2016年25期)2016-07-29
商(2016年8期)2016-04-08
第二课堂(课外活动版)(2015年5期)2015-10-21
语文教学与研究(教研天地)(2015年8期)2015-08-19
青少年科技博览(中学版)(2006年7期)2006-07-13
浙江社会科学(2004年2期)2004-04-21
