
中国政策试点中的随机实验:一种方法论的探讨
2022-03-02 07:55:38王思琦
公共行政评论 2022年1期
王思琦
一、引言
众所周知,政策试点(Policy Pilots)是中国公共政策制定的一种特色机制,也是理解中国政策过程的重要研究视角(赵慧,2019)。政策试点体现了中央政府“尊重地方和基层的经验、智慧和首创精神”的基本理念(江小涓,2020),在中国公共政策的制定与实施过程中发挥了至关重要的作用。
一方面,很多研究者关注到试点中的“点”在政策制定中的意义(陈那波、蔡荣,2017),并将政策试点概括为“由点到面”,将某个地区或领域行之有效的政策方案推广到更大的范围(韩博天,2008、2010、2018;周望,2016)。这种“由点到面”的政策执行及创新,被视为解释中国适应内外部环境的复杂变化,并推动经济社会持续发展的重要路径(李智超,2019;刘伟,2015;朱旭峰、张超,2020)。
另一方面,试点中的“试”从字面上很容易让人联想到“试验”或“实验”(1)在本文中,出于简单化的目的,不对“试验”和“实验”两个概念进行区分。匿名审稿人指出,严格来讲这两个词还是有一定区别的,虽然部分学者混用了两个词,但在官方用语中,几乎从来不使用“实验”一词。。部分研究者提出,政策试点的实质是将实验这一研究方式应用于公共决策或社会实践领域(赵慧,2019)。这种观点实际上将“试点”与“实验”两个概念等同起来(陈靖、洪伟,2020;康镇,2020;杨宏山,2013;章文光、宋斌斌,2018),认为实施政策试点的最理想、最科学的方法就是实验。
具体来说,这种观点通常基于实验方法和因果推断的基本逻辑,建议采用世界银行等国际组织推崇的影响评估(Impact Evaluation)视角来评估中国的公共政策。研究者认为,传统的政策试点在很多方面违背了实验与因果推断的原则,导致政策结果(效果)的真实性与可靠性有问题。例如,试点运行过程可能受到选择性偏差(Selection Bias) 和霍桑效应(Hawthorn Effects)两大效应的影响,使得政策试行的结果被高估或被低估(刘军强等,2018),因此,要解决政策试点机制存在的问题,应当采用随机对照(控制)实验(Randomized Controlled Trails,RCT)来进行政策评估(2)本文中的随机实验,特指严格意义上的随机对照实验(RCT),即由研究者(政策评估机构)实施随机分配与政策干预的真正实验,不包括采用准实验(Quasi-Experiments)或自然实验(Natural Experiments)方法的研究(评估)。感谢匿名审稿人的意见。。
然而,本文认为,采用随机对照实验方法,不仅没有真正解决样本选择偏误、外在效度等因果推断问题(Alcott,2015),还可能带来一些观察性方法所没有的问题。而且,鉴于中国的政策试点与随机实验存在诸多差异,以及中国的政府执行能力与政策实施规模,本文认为,用随机实验方法来替代或改造政策试点是没有必要的。
政策试点与随机实验的差异体现在多个方面。首先,政策试点区域的选择,更多地是基于科层制的运行逻辑,而非政策效果评估的因果逻辑(Ko & Shin,2017)。研究者认为,政策试点的选择机制有“由上至下”的行政官僚式与“由下至上”的基层创新式两种解释视角(朱旭峰、张超,2020)。很明显,这两种选择机制都不是为了准确评估政策效果,更多是一种上下级政府之间的宣传、协调与沟通机制。中央与地方之间的官员流动强化了相关城市与中央部委间的信息传递,借此形成的信息优势影响了政策试点的选择(朱旭峰、 张超,2020)。换句话说,政策试点中上下级之间主动与自发的双向选择,替代了随机实验中样本的随机选择和分配。
其次,与基于随机实验方法的影响评估相比,中国政策试点的内容通常比较模糊,政策干预和结果测量缺乏定量化与精确化。一般来说,必须清晰界定与测量影响评估的干预内容(自变量)与结果变量(因变量),以便建立一个“变迁理论”(Theory of Change),来解释因果效应的传递机制,否则就很难建立一套可操作的政策实验方案(Gertler et al.,2016;Glennerster & Takavarasha,2013)。
正是这种模糊性,使得中国的政策试点很难采用这种因果推断的逻辑。因为政策试点内容具有较大的模糊性,在一个政策中往往存在多种干预方案,尤其是在多地区、多层级和多部门参与试点的情况下,各主体都会将现有工作内容与职责嵌入政策试点当中,尤其在中央没有提供实施具体步骤和方案,只提供政策名称与大概思路的情况下,这些政策试点内容之间甚至缺乏统一标准。与实验内容的单一性相比,试点内容则呈现出明显的整体复合性(何挺,2018)。
正是由于这种政策内容的模糊性与多样性,使得随机实验评估方法难以直接用于中国的政策试点过程。正如史耀疆等(2020)提出的,实验方案必须简单化才能推广:“对于一个社会问题,人们可能想到的干预是多方面的、多层次的,其解决通常需要整合社会资源、上下联动、多方参与。但由于开展教育领域的随机干预实验最终是为了推动教育政策的改善,如果实验方案过于复杂、对实施者的要求过高,则会给后续政策推广造成一定的困难。”
最后,中国的政策试点的目标与影响评估也存在差异。影响评估的目标,是通过估计政策因果效应来提供决策依据,以便进一步推广(Scale up)或取消(Cancel)政策。然而,政策试点最重要的目标,是通过试点来解决政策实施的制度障碍,即“试点能够积累经验、测试效果、突破障碍和缓冲压力,是推进改革的有效途径”(江小涓,2020)。这种情况不同于政策影响评估具有的科学决策意义,政策试点实际上是一种科层制下的资源和绩效分配机制,具有更复杂的政治、经济意义。
试点项目一般会伴随着政策红利,与中央政府或地方政府的高度重视与汇聚的资源成正比,形成辐射网络,使政策得以有效的推动(陈靖、洪伟,2020;杨宏山、李沁,2021)。正是科层制中的这些政治、经济激励,使得政府部门不一定有动力采用随机实验方法与证据,即使实验方法能够验证政策效果的有无或高低。研究者认为,在自上而下的科层体系中,政策方案的成功与否实际上并不是推广的充分条件(梅赐琪等,2015)。
本文对政策试点与随机实验进行了全面地比较和分析。第二部分基于随机实验的因果推断原理,比较了中国政策试点与随机实验的差异。第三部分基于国家发展、组织能力、科层制逻辑以及外部效度问题,讨论了为什么随机实验对于中国的公共政策评估并不是必要的。在第四部分与结论中,论文提出将实验与非实验方法、定量与定性方法结合起来,才能更加全面和深入地理解政策试点对中国国家治理的独特意义。
二、通过随机实验来理解政策试点
随机对照实验(RCT)或实地实验(Field Experiments)在公共政策尤其是发展政策当中的广泛使用,与公共政策研究中循证决策(Evidence-based Policy Making)的兴起是同一个过程(Cartwright & Hardie,2012)。在一定程度上,随机对照实验解决了观察性研究中存在的混杂因素(Confounder)问题,从而可靠地建立了政策干预与政策结果之间的因果关系,因此受到广泛推崇(王思琦,2018)。
(一)随机实验的因果推断逻辑
众所周知,包括随机对照实验与准实验、自然实验(工具变量、回归间断设计、双重差分、倾向值匹配、合成控制等)等一系列用于影响评估的因果推断方法,均建立在潜在结果框架(Potential Outcome Framework),或称为反事实框架(Counterfactual Framework)的统计基础上(马凌远、李晓敏,2019;曾婧婧、周丹萍,2019)。因此,要准确理解随机实验与政策试点的联系与区别,可以使用潜在结果符号对平均干预效应(Average Treatment Effect,ATE)的估计值进行进一步分析。
=E[Yi|Di=1]-E[Xi|Di=1]-E[Yi|Di=0]+E[Xi|Di=0]
=E[Yi(1)]-E[Yi(0)].
(1)

从式(1)第1行可以看出,在满足随机分配的条件下,平均干预效应的估计值,是分配到干预组被试的前测与后测之差(Yi-Xi)的期望值,减去分配到控制组被试的前测与后测之差(Yi-Xi)的期望值。换句话说,平均干预效应的估计值的大小取决于公式第1行中第1项与第2项的比较,二者互为反事实。如果第1项越大,第2项越小,那么平均干预效应越大。而每一项期望值的大小,则取决于每组结果变量的前测与后测之间的差值。
基于式(1)可以得出,一项公共政策或项目的平均效果,等于随机分配到干预组和控制组被试的平均效果之差。如果以扶贫政策的随机实验为例,假定干预组为实施某种扶贫干预的人群(即Di=1),而控制组为不实施任何扶贫干预的人群(Di=0)。这里的Yi可以定义为政策实施之后的平均家庭收入,而Xi定义为政策实施之前的平均家庭收入。第1行的第1项E[Yi-Xi|Di=1]即干预组人群政策实施前后的平均家庭收入之差,第1行的第2项E[Yi-Xi|Di=0]即控制组人群政策实施前后的平均家庭收入之差。
在中国的政策试点背景下,如果扶贫对象所在的干预组(Di=1)在扶贫前后的收入变化(Yi-Xi)非常明显,即Yi远远大于Xi,而非扶贫对象所在的控制组(Di=0)在同时期的收入变化(Yi-Xi)并不明显,即Yi与Xi差别不大,则说明政策的平均干预效应很大,即使不采用随机分配的实验设计,政策效果也是非常可靠的,即扶贫效果存在选择性偏误和混杂因素的可能性非常低。因为从经验与逻辑上我们无法找到除了政策干预以外的因素来解释这种巨大的收入变化(Mckenzie,2020)。
相反,如果政策的效果并不理想,即扶贫政策实施前后,政策干预组与控制组的收入变化(Yi-Xi)均不明显,则理所当然,第1行的两项之差也不大。在这种情况下,要在统计上可靠地识别政策效果,只有采用随机对照实验设计,通过随机分配和政策干预,进一步排除其他因素的干扰。
需要进一步讨论的是,在进行随机对照实验之前,政策评估者需要基于实验设计的基本参数,来计算实验的统计效力(Statistical Power),即拒绝无干预效应的零假设的概率(Athey & Imbens,2017),具体计算参见式(2)。
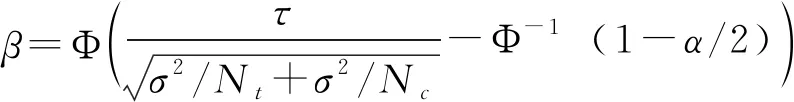
(2)
式(2)的等号左边为统计效力β,研究通常会选择β=0.8,等号右边的Φ和Φ-1分别表示累积标准正态分布函数及其反函数。在右边的各项参数中,按照研究惯例,通常选择α=0.05作为统计显著性水平。τ是预先指定的平均干预效应水平(即两组的结果变量均值差)。一般假设两个组实验样本具有相同的方差σ2。这几个参数可以通过公式的变换相互计算。例如,从公式可以看到,另一个研究经常感兴趣的实验设计参数,即实验所需的最小样本量N=Nt+Nc是α、β、τ、σ2的函数。一般来说,为了最大化统计效力,通常会选择Nt=Nc=N/2,即干预组与控制组的样本量相等的设计。
实际上,统计效力分析需要一定程度上的猜测(Gerber & Green,2012)。研究者必须基于文献和经验,提供一些未知参数的值,诸如预期的ATE,即τ的大小。基于公式,还可以发现,随着样本量N的增加,统计效力将增大。因此,解决随机实验缺乏统计效力问题的一个方法就是增加样本量。统计效力同样随着效应τ变大而增加,所以增加干预强度是解决统计效力不足的另外一种途径。效力也会随着σ2的减少而增加,因此,研究者可以减少数据中的随机噪音来提高统计效力:收集各种协变量数据;最小化被试的异质性;随机分配之前先对样本分层;在层内实施随机化;等等。
在扶贫政策试点中,如果研究者或政策制定者基于文献和经验,预期一项扶贫政策的效果将非常明显,那么在方法论意义上,随机实验其实并不是一种必须的效果评估方法,采用传统的评估方法,甚至基于公众的日常观察就足以获得可靠的结果了。然而,如果预期扶贫政策的效果不太明显,或者预期效果的不确定性(取值范围)很大,这个时候,随机实验相对来说可以提供比较可靠的因果效应(平均干预效应)估计值。
然而,如果要确保实验发现的因果效应可靠程度较高,即统计效力较大,政策评估者和研究者需要尽可能地增加样本量N,减少统计误差σ2。这些保证统计效力措施的实行,是以耗费巨大的研究资源(人力、物力、经费、时间等)为代价的,随机实验的成本甚至会占政策或项目总成本的相当一部分,而这些资源本来可以直接用于扶贫对象。从现实意义上讲,在政策试点过程中,不区分政策的类型与特征,不考虑政策效果的预期,大量采用实验方法进行评估,至少在经济上是不合理的,存在公共资源的浪费问题。
(二)政策试点的政治经济逻辑
如前所述,与随机对照实验不同,至少在宏观制度层面上,中国政策试点的主要目标并非是获得政策(项目)方案的因果效应估计值,而是关注其控制、宣传、示范与协调、沟通等多重作用。因此,试点的政治经济逻辑取代了实验的因果推断逻辑(刘培伟,2010)。正如韩博天(2008、2010)指出的那样,中国的政策试验并非一种科学过程,而是一个充满了政治博弈的过程,央地之间的关系是理解政策试验的一个主要角度。李振(2014)也通过对比中国政策试验(试点)和欧洲的试验主义治理,将政策试验(试点)视为应对不确定性的一种机制。
研究认为,中国政府开展政策试点的目标是多重的,这些目标包括:第一,因为还看不准对新的制度或政策的实施效果,需要进行小范围实测,观察实效和完善改革方案;第二,表明此事仅在小范围试行,有进退余地,容易与持不同意见者达成妥协;第三,允许地方因地制宜推进改革;第四,有极少数试点是具体部门的“缓兵之计”;第五,还是在部门层面,有极少数试点是“设租”的一种方式(江小涓,2020)。在以上五种试点目标中,只有第一种接近随机实验或影响评估的目标,其余几种都是服务于不同层级、部门、官员之间的协调与沟通,以便实现各自的政策偏好,进行上下级权力与部门利益的博弈与分配。
此外,地方政府对于试点成功的期待,使其难以算作一种科学实验,而是一个塑造示范标杆的政治经济过程(赵慧,2019)。尤其在试点选择上,不会像实验那样将不同地区随机分配到干预组与控制组。研究发现,上级政府倾向选择拥有较多资源、具有较好经验积累、成功可能性较大的地区试点,因为试点并非追求纯粹的科学属性,而在于突破现有制度障碍、建立示范(赵慧,2020)。
为了使试点取得成功,上级政府还往往将资源集中投入到试点地区(吴怡频、陆简,2018)。正是因为试点能够在政策、财政等方面获得额外支持,地方政府会积极争取成为试点,并将成为试点作为一种政绩(赵慧,2020)。从实验与因果推断的逻辑来看,给予试点地区额外的资源或权力,相当于引入了混杂(混淆)因素,进一步导致试点效果归因的困难:究竟试点政策本身产生了效果,还是额外资源产生了效果?
不管是上级政府基于试点成功可能性的主动选择,还是地方政府出于政绩考虑,积极争取成为试点(自选择),都将导致样本选择性偏误(Selection Bias)。试点地区的高度自选择性,使得相比非试点地区,试点地区会更重视试点工作,有更多内部资源倾斜。在极端情况下,其他政策的效果都会被算到该试点政策头上,甚至虚构与夸大政策的效果。
表1比较了政策试点与随机实验的主要区别。在政策干预地点的确定上,如前所述,政策试点地区往往是高度选择性的,无论是上级政府(中央政府)的挑选或指派,还是下级地方政府的积极争取,都与政策试点效果高度相关。而随机实验在选择实验地点时,则会采用完全随机分配、整群随机分配、区块随机分配等,即使限于条件,无法采用真正的随机分配,选择试点地区也会尽量减少人为选择,保证结果至少是近似随机的。

表1 政策试点与随机实验的比较
在政策干预的内容上,由于政策试点涉及上级政府与下级政府之间的合谋机制,即复杂的讨价还价、协调沟通过程。同时,政策试点往往不是单一部门、单一地区的试点。因此,即使上级政府在出台政策试点方案时,方案内容相对统一与清晰,在试点的推进过程中,其干预内容也会变得越来越多样和模糊。各级政府、各个地区以及各种部门,都会有意无意地改变政策内容,加入有利于本级、本地区、本部门利益的项目。在试点过程中,可能最终能够统一的只有政策名称。
此外,中国是一个面积广大,人口众多,文化、自然与气候条件复杂的国家。“因地制宜”“具体问题具体分析”本来就是被体制所推崇和肯定的,这进一步导致了政策内容的多样性。相反,实验方法的高度定量化,决定了其干预内容的设计必须是清晰和标准的,否则根本无法对不同干预对象(如个人、家庭、社区、企业等)统一实施。
与试点地区选择的逻辑一致,正是因为结论在上级决定试点地区时就基本确定了,因此,试点并不严格强调对政策结果的定量与精确测量,而基本上均采用定性评价程序与手段,如采用专家座谈、实地考察、单位自评等方式来判定政策实施的效果。这些方法往往是一次性和短期的,因为上下级政府都期望政策效果立竿见影,便于及时宣传推广。而随机实验为了保证政策干预效应的可靠性,减少结果测量的误差,基本上采用定量的、多次的和长期的测量工具。
总之,政策试点体现的是政治经济逻辑而非因果推断逻辑。或者说,基于随机实验和因果推断基础上的政策效果(影响)评估,可能只是其中一个目标,甚至并非是其中的主要目标。不管是将试点与实验(试验)视为同义词,还是认为应当基于实验方法对其进行改造完善的观点,都过于理想化,强调了随机实验的科学性,却相对忽视了传统政策试点机制的内在合理性。
三、随机实验是否是必要的?
尽管随机实验有利于在统计上发现政策的因果效应(平均干预效应)。但是,采用随机实验进行政策评估的真实意义,仍然需要根据不同的应用背景来具体分析。实际上,与传统观察性评估方法一样,随机实验同样存在一系列方法与应用上的局限,导致其对中国公共政策评估的意义被夸大了。
(一)随机实验与国家发展
如前所述,在政策效果非常明显的情况下,即使不使用随机实验,也能够进行因果推断,发现可靠的因果效应,这就为政策试点机制的合理性提供了理论基础。因为中国政策试点涉及的人口规模、地区范围、经济资源往往非常庞大,从而产生了明显可观察、可识别的政策效果。例如,近年来中国的精准扶贫政策,成功地实现了9899万农村贫困人口全部脱贫,创造了人类减贫史上的奇迹和减贫治理的中国样本,为全球减贫事业做出了重大贡献。如此巨大的政策效果,不可能来自于其他任何地理、自然等混杂因素,只能归结于精准扶贫政策本身。
在中国的体制环境下,政府具有强大的政策执行力和资源动员能力,它能使用包括科层制与项目制在内的各种治理手段,可以制定与实施长期的经济与社会发展计划,最终实现中国政治、经济的可持续发展。而这种宏观的、国家层面上的结构转型与发展,恰好是随机实验难以甚至无法评估的政策层次。
正如Pritchett(2018、2020)提出的那样,国家发展(National Development)是一个国家、地区或社会向更高水平能力的转型,体现为四个方面:从低生产力到高生产力的经济转型,向更能回应人民愿望政府的政治转型,向具有更高执行能力的组织(包括国家在内)的行政转型,还有向使这个国家的公民得到更平等待遇的社会转型。
与此形成鲜明对比的,是目前发展经济学当中的随机实验评估。这些评估基本上是研究者与基金会等社会组织推动的,导致解决政策问题的视野比较狭隘,基本上是围绕琐碎且微观的主题,采用市场化、货币化的干预手段,很大程度上忽视了国家整体发展层面的政策议题。这些微观主题诸如:要求小学老师每天早上提交一张自拍,研究这是否会提高教师出勤率;研究免费或收费发放蚊帐对非洲民众蚊帐使用率的影响;研究饮用水加氯、驱虫药等对民众身体健康的影响;研究电话、短信、网络等信息干预对经济、健康、教育行为的影响;研究与小额贷款相关的诸多随机对照实验;等等。
在随机实验中,政策制定者与研究者无法提出这些微观政策所嵌入的机构和制度的总体改革方案,只能提出零碎的解决方案。这些方案没有充分考虑政策的社会、文化背景因素和制度约束(Pritchett & Sandefur,2015),基本上是照搬西方或其他国家。一旦各种外来的助推与资源消失,政策效果就随之消失,难以真正解决制度性与结构性的国家发展问题(Pritchett,2020)。例如,近年来,多个国际组织与阿富汗政府部门合作开展的阿富汗国家团结项目(National Solidarity Programme),基于500个村庄的实验样本,采用随机对照实验评估了一系列经济、社会领域的子项目,但最近阿富汗的政治局势表明,这种外生的国际援助项目并没有肩负起国家建设与发展的重任(4)感谢匿名审稿人的启发。该评估项目的详细情况可以参见网站:http://nsp-ie.com/index.html. 2021年12月8日访问。。
总之,诸如精准扶贫等国家发展层面上的政策,具有宏观性、复杂性,很难被整齐和均匀地分割为一个个微观问题及解决方案,以便使用随机实验进行评估。而且,即使能够把宏大议题分解为小的主题进行研究,在市场化、商业化的干预设计思路下,也无法将其还原为整体性的国家战略知识。
相反,中国的政策试点是一种从国家与中央政府层面推动的政策试错机制,尽管某个试点地区得到的经验是局部的、微观的,但是在总体性和长期性发展规划的框架下,通过对这些局部知识的汇总与理解,可以制定推动国家长期、可持续发展的有效战略。
(二)有效政策与实施能力
公共政策的有效性与政府实施能力高度相关。研究发现,很多政策即使在前期或小规模的评估中是有效的,可能也难以大规模应用和推广,因为对政府能力提出了更高的要求。江小涓(2020)认为,当小范围试点“政府私人合作伙伴(PPP)”项目时,由于管理精细且关注度高,项目推进过程的可控性较好。而当大面积铺开后,有可能出现严重的利益输送或腐败等问题。
一般来说,在小规模政策影响评估中,随机实验的资助者、设计者、实施者往往具备一定的特殊动机与能力,正是这种动机与能力导致前期实验的成功,同时也为政策推广后的失败埋下了种子。因为在大规模应用和推广时,这种动机与能力是异常的或稀缺的。例如,在发展中国家进行的实验发现,一些小规模评估时有显著效果的政策,一旦推广到更大范围,效果往往会下降甚至消失。理所当然,在初期进行实验时,相关人员通常具有高度专业知识和强烈服务动机,而且实验规模较小,沟通协调的问题也较少,政策效果肯定容易出现。一旦推广到更多区域,由常规的机构来实施时,这些人很难具有像参与前期实验的那些人员的素质与能力,而且面对的将是更复杂的社会环境,政策效果就消失了。
众所周知,很多发展中国家政府的管理和监督能力很弱,根本无法实施大规模、标准化的政策方案(Andrews et al.,2017)。换句话说,这些国家真正缺乏的是实现发展目标的政府能力,而不是具体的政策有效性知识。不管是来自随机实验评估的结果,还是来自常规方法评估的结果,都无法解决政府治理能力的问题。在这种低国家能力的约束条件下,各种小打小闹、创可贴式的政策方案反而更适合他们。因为这样更容易出成果,更有可见度,更有利于选举获胜、快速调任与升迁。
实际上,与其他发展中国家的地方政府相比,中国的地方政府能力总体较高。考虑到中国的人口规模庞大、地区差异明显,如果非要采用经过实验评估后制定的、高度统一和标准化的政策方案,尽管下级政府在执行上没有问题,但可能导致政策在执行时丧失灵活性。例如,东部沿海发达地区行之有效的政策,要求西部地区全盘复制,如果不考虑西部地区行政资源相对较少的状况,就会导致政策实施的效果不尽相同。正如福山(Fukuyama,2013)提出的那样,在高政府能力的情况下,需要增加政府的自主性,即鼓励地方的政策创新,而在低政府能力的情况下,要保证其忠实执行中央政策,以实现政策的基本目标。
在中国这种政治上高度统一的单一制国家,政府具备良好的政策执行能力和行政资源,公众政治信任程度较高。因此,在选择试点地区和方案时,应充分尊重各地区、各部门的实际情况,因地制宜、上下协商,这样更有利于发现具有局部最优适应性的政策方案,避免复制机械和呆板的标准化政策。而且,政策试点内容的复杂性与结果测量的模糊性,也有利于实现多种政策目标组合,在这些目标之间进行调整与迭代,最终发现适合解决本地特殊问题的创新方案。
(三)实验结果与科层制
如果将随机实验用于中国的政策评估,还会面临组织结构与制度背景不适应的问题。目前,国外发展政策等领域的实验评估,很多是由研究机构设计、社会组织资助或实施的,著名的影响评估机构有J-PAL、International Initiative for Impact Evaluation(3ie)等。由于其所处的制度环境,使得其采用的政策干预往往基于竞争性、市场化、商品化的激励机制(Berndt,2015)。这种政策干预模式相对忽视了真正的公共政策,基本上是由国家和政府主导与实施的,政府的政策工具与科层制内部的激励,与各种社会组织和企业有巨大的差异。
从这种意义上来说,在中国的制度背景下,即便政策在前期实验评估时被认为有效,相关政府部门也有实施能力,但政策可能仍然无法被广泛采纳或重视,原因就在于目前这种市场导向、自下而上的实验评估与科层制的运行逻辑是不兼容甚至是冲突的。
首先,随机对照实验评估在学术上的重要价值在于证伪而非证实。例如,随机对照实验证伪了小额贷款的有效性。尽管小额贷款的倡导者将其描述为赋予妇女权利和大规模减贫的关键因素(Angelucci et al.,2015),但很多实验结果表明,小额贷款只是一种有用的金融产品,并不能实现社会变革(Morduch,2020)。在很多环境下,小额贷款对家庭决策和支出模式没有明显影响 (Banerjee & Duflo,2011)。
这种证伪逻辑,固然可以验证某些政府主导政策在统计意义上的无效性,但忽略了科层体制下,政策过程的现实性与复杂性,因此难以被政府部门采纳。例如,某些政策被验证为无效(如对弱势群体的再分配政策,并没有改变其生存状况),但可能具有重要的政治意义,因此短期内不能取消或减少。很多政策的目标是多方面的、潜在的,单一结果测量的实验过于简单化,容易忽视政策的积极作用。然而一旦进行全面地观测,可能会发现政策实际上是有其积极作用的,或者对非政策目标人群具有意想不到的某种效果。
其次,即使在实验评估中行之有效的市场化干预工具,也可能并不适合由政府部门来实施,要么干预成本太高,花费大量财政经费反而导致公众的反对,要么干预过程过于琐碎和漫长,不符合政府部门的年度预算规定与行政流程。例如,很多时效性政策是针对特定问题的解决而提出的,而实验为了保证其规范性,通常会花费大量时间用于研究设计、基线(Baseline)调查、干预分配和结果测量,尤其是终线(End Line)测量或后续(Follow up)测量,可能花费几个月甚至几年的时间。而政府官员倾向在短期内做出政策决定,否则会面临相当大的政治与社会压力,因此无法采用旷日持久的随机实验评估。
相比之下,政策试点更符合中国的制度环境,因为试点机制内在于科层制本身,包括:政策干预工具符合科层制的工作惯例,由政府部门主导评估过程,不需要漫长的评估周期,对政策结果的相对灵活使用符合政治要求,允许上下级政府之间的协调、默许、讨价还价等。更重要的是,实验测量的是某种政策干预的整体效果,这种效果无法被分解为不同干预成分的边际贡献,哪怕有多个部门都参与了政策干预实施。无法分割对政策效果的贡献,违反了科层制按部门进行绩效考核的基本原则,而政策试点伴随着科层制的运行过程,允许观察政策效果和分配部门与岗位绩效,从而形成强大的政绩激励,更有利于公共政策的落实与推广。
(四)政策实验的外部效度
一般来说,政策评估的实验方法,通过随机分配样本,建立干预组与控制组的反事实比较,能够测量政策因果效应,因此具有较高的内部效度。然而,由于研究经费、研究环境的限制,整个实验样本通常并不是从研究总体中随机抽样得来的,因此实验结果对总体很难有统计代表性,即外部效度并没有想象的那么高,或者说,研究结果很难推广到异质性的政策环境与政策对象中去(Bates & Glennerster,2017)。
政策实验外部效度的不足,与政策一旦有效就应当推广的逻辑产生了冲突。在理想状态下,只有同时具备内部和外部效度的政策工具,才能被认可并成为政策方案(赵慧,2019)。但现实中的政策实验,其效果其实只经过了少量实验对象、个别地区的检验,并没有经过大范围的验证。这些实验对象或地区中出现的因果效应,可能受其内在特征(性别、年龄、收入、地理气候、经济发展水平等)的调节(Moderation),而这些内在特征在总体(政策总体)上是分布不均匀的。因此,在更大范围的实验对象中可能无法重现效果。
更重要的是,政策的不断推广会导致一般均衡(General Equilibrium)效应。换句话说,前期实验中的政策效果只是一种市场的局部均衡而非一般均衡。例如,一项旨在促进失业人员再就业的培训政策(项目),前期评估发现它可以有效提高就业率或收入,因此政府部门在不同地区和行业大力推广。但随着接受政策干预的人数的增加,政策的效果会逐渐变小甚至消失,因为最初的实验是对少数人进行的,没有改变整个劳动力市场的供求与价格,一旦规模扩大,就可能影响市场的基本供求结构。因为参加培训的人越多,培训对人力资本的价值就越小,对个人就业和收入的边际作用就越低,而这种效应可能要很长时间才能显现出来。
政策总体的高度异质性与一般均衡效应的存在,使得很难有一个“放之四海而皆准”的政策方案,即“试点效果好并不能得出大面积实施后的效果也同样好的结论”(江小涓,2020)。或者说,有效政策基本上是局部的,要在更大范围内实现政策目标,需要熟悉政策环境的本地机构和人员,通过针对问题的不断试错来进行迭代适应(Iterative Adaptation)。这种“具体问题具体分析”的逻辑恰好与政策试点有很多的共同之处,即允许各个地方采用不同的政策方案,基于本地的实际情况来设计,避免了将特定群体的实验结果推广到高度差异化的总体,也减轻了一般均衡效应的影响。
四、政策评估方法的黄金标准
最近20年来,无论在发展经济学、计量经济学还是统计学等领域,无论是世界银行、世界卫生组织等国际组织,以及在众多发展中国家的政府部门,都将采用随机实验进行政策评估的实践,随机试验被视为一种黄金标准(Bothwell et al.,2016)。很多人认为只有基于实验(或准实验、自然实验等)评估方法得到的政策效果,才是值得信任的(Angrist & Pischke,2010;Gueron,2017;Imbens,2018)。与此同时,其他定量和定性评估方法在政策因果推断上的价值都被有意无意地贬低(Banerjee & Duflo,2009)。
Heckman (1992、2020)指出,从1965年以来,经济学领域实地实验的历史可以分为两个时代。(1)早期利用实验来解决重要的政策辩论,认为非实验证据是模棱两可的。(2)发展经济学实验复兴,以2019年诺贝尔经济学奖为高潮。每个时代都以对随机对照实验方法论的近乎宗教般的热情为标志。Heckman (2020)认为,在两次实验方法热潮中,“第一波的动机是解决主要的社会问题,而第二波则更注重方法论。获得因果效应是经济学领域痴迷的一部分,即使所确定的效应没有社会意义和(或)经济意义”。
换句话说,所谓随机主义者(Randomistas)对于实验方法的推崇(Leigh,2018;Ravallion,2020),只是出于利益与偏好,而非真正的科学证据(Donovan,2018)。与其他方法相比,实验方法并不具有天然的优越性(Deaton,2010;Deaton & Cartwright,2018;Harrison,2011)。
从实验方法的发展来看,经过历史上长期的方法论争议,政策评估领域其实已达成共识,实验并不具有绝对的优先性(Barrett & Carter,2010),好的评估一定是多种方法并用的(Concato et al.,2000)。但这种共识被20世纪90年代以来对随机实验的高度推崇所干扰,重新陷入了方法论争议当中(Ogden,2017;Rodrik,2009;Teele,2014)。因此,要准确理解实验评估的局限性与政策试点的意义,需要对实验与非实验方法的关系进行讨论。
(一)实验评估与非实验评估方法
社会科学的随机对照实验方法起源于医学与生物学研究传统(Bothwell & Podolsky,2016;Favereau,2016)。但与医学研究不同,社会科学中的实验很难遵循医学实验那种严格标准(Cook,2018)。例如,社会科学实验基本上无法做到“双盲”,仍然存在霍桑效应等研究者介入效应。例如,控制组被试可能出现约翰·亨利效应(John Henry Effects),即在研究某种干预(如提高福利)对工作效率的实验中,控制组被试如果意识到自己没有被分到干预组,出于竞争的心态,可能会更努力地表现自己,从而干扰实验结果,降低干预效应。而且,很多政策实验没有像医学实验那样采用安慰剂(Placebo)设计,即经常使用无任何干预的空白对照组,而非对其实施现有的政策。在这种情况下,即使新的政策并不优于现有政策,也被视为有效的政策创新。
与非实验方法相比,尽管实验采用了随机分配,在一定程度上消除了样本选择偏误和遗漏(混淆)变量的干扰,但这只是理想状况而非现实状况。政策评估中的实地实验,由于在真实社会环境下进行,虽然比实验室实验的外部效度高,但也面临更多干扰,如随机分配失误、实验对象不遵从、样本缩减、实验对象相互干扰等问题(Della Vigna & Pope,2018)。换句话说,实施一项有问题的实验评估,因果推断的能力可能远远不如实施良好的非实验(观察性)评估,如问卷调查、参与观察、深度访谈、管理数据分析等。
表2对实验评估和非实验评估进行了比较。尽管非实验评估缺乏随机分配,但是由于其实施简单、成本较低,采用随机或非随机抽样,对总体的代表性反而更高。而且非实验研究方法包括了定量与定性的多种方法,更能适应复杂的社会环境。实验方法虽然有利于因果推断,但其较高的成本也限制了其推广性。而且,在政策经费有限,或因伦理、政治等因素(Baele,2013)而无法进行实验时,观察性评估甚至是唯一可行的方法(5)这里的观察性评估包括准实验、自然实验等一系列因果推断方法。本文将由研究者或政策评估机构实施随机分配与干预的方法视为真正的实验,而把无随机分配和干预、随机分配和干预不是由研究者来实施的方法,都视为准实验或自然实验。。

表2 随机实验评估与非实验评估比较
因此,将随机实验作为最高地位的评估方法,忽视甚至排斥其他方法的观点是有问题的(Barrett & Carter,2014)。这种观点忽视了现实世界的复杂性以及实验方法面临的诸多困难,从方法论的角度来看,更接近于广告宣传而非科学研究(Bédécarrats et al.,2019)。
(二)多种评估方法的结合
需要说明的是,本文对于实验评估方法的分析与批评,并不意味着在政策评估中不应该使用随机实验。这种方法论上的反思,是为了将实验与非实验评估方法结合起来,充分发挥不同方法的优势,同时避免各自的缺陷(Basu,2014;Gelman,2018)。
随机实验方法在统计推断上的优势,最重要的是研究设计的透明性以及结果分析的简单性。如果满足随机分配有效、干预正确实施的条件,实验数据可以直接计算均值差估计量,使用最简单的t检验就可以直接比较干预组与控制组在结果变量上的差异,无需像观察性数据那样,进行复杂的回归分析和模型设定,从而减少了为找到统计显著性结果导致的学术不端行为。例如,Vivalt(2019)发现,在统计模型设定搜索(Specification Search)行为方面,采用随机对照实验方法的文献比传统观察性研究文献要少。
用形象的语言来说,政策评估如同警察破解疑案中的蛛丝马迹,需要利用所有可得的知识与信息(Freedman,1991)。因此,一项好的政策评估,应当是实验与非实验方法、定量和定性方法的结合(Morvant-Roux et al.,2014)。如果随机对照实验基于各种文献积累,并得到了观察性或定性方法的帮助,才能真正有效地获得政策洞见,帮助设计行之有效的政策方案,以及在相互竞争的政策方案之间选择成本效益最好的那种。
因此,可以在开展大规模实验之前,利用田野调查、民族志或其他方法来发现关键的因果机制传递过程,结合学术研究文献和部门政策经验,确定合适的政策干预变量与结果测量。在实验结束之后,如果发现了异质性干预效应,就进一步深入实地,从实验对象中补充收集数据,基于问卷调查与访谈,来探索这种异质性干预效应出现的原因,即为什么干预对某些对象有效或者无效。
总之,要发挥实验与非实验方法各自在政策评估中的作用,一方面,必须进入到政策实施环境中,理解政策对象的态度、认知与偏见,观察政策执行中的意外、矛盾与失误,不断修改和完善评估设计(Karlan & Appel,2011)。另一方面,必须主动去收集与政策相关的自然、技术、人文和社会科学知识,不能局限在某个学科或领域内,才能设计出有想象力、创造力的政策干预与结果测量:除了观察现有政策的效果,还可以尝试检验前所未有的政策干预的效果。
当然,将非实验方法单独用于政策评估也是合理的。例如,对于一种创新性的政策方案,政策对象数量很少,无法满足实验随机分配(或定量研究)的样本量,可以采用案例分析式的评估,通过观察政策过程与事件,为进一步的政策设计提供参考。此外,前述中提到的国家发展政策,由于任何随机实验都无法评估,也需要结合多种非实验方法来排除其他宏观因素的干扰,确定发展政策的效果和意义。
五、结论
政策试点作为中国国家治理的一种重要机制,得到了学术界广泛的关注。有研究者认为,应该采用随机对照实验的方法来改造甚至替代政策试点,提高政策评估的因果推断能力。基于随机实验以及因果推断的统计原理,本文对政策试点与随机实验进行了深入比较,分析了政策试点的价值以及随机实验的局限,提出政策试点的基础是适合中国治理体制的政治经济逻辑,而非统计意义上的因果推断逻辑。这两种逻辑都有其合理性与适用性,因此,没有必要用随机实验的标准来要求或评价中国的政策试点。
本文认为,随机实验强调微观的、市场化的政策解决方案,而政策试点能更好地帮助制定与评估国家发展层面的宏观战略与政策。经随机实验评估有效的政策,由于地方政府能力高低与条件差异,难以在更大范围内推广与应用。科层制环境下,实验方法的评估结果可能难以被政府官员采纳,而政策试点与科层制的内在关系密切,采纳与实施的可能性更高。现有实验评估通常由社会组织或研究机构主导,缺乏与政府科层制的衔接,难以适应政府决策的复杂性和时效性,而政策试点则具有更高的适应性。随机实验往往选择部分区域和少量对象实施,一旦拓展到更大范围,就容易出现干预效应异质性和一般均衡效应,而政策试点则可以进行局部方案的优化调整。
总之,随机实验评估并非是一种万能方法,也不是政策评估的黄金标准,没有自动高于其他方法的地位。作为诸多评估范式和方法的其中之一,实验必须与非实验的定性和定量方法结合起来,扬长避短,才能获得有洞见的政策评估知识。
相比实验方法,政策试点更加具有灵活性、包容性和开放性,在某种意义上,政策试点更加接近于贝叶斯统计学的逻辑,即通过政策干预与观察学习来不断试错,随时结合新出现的信息,不断对干预手段与政策信念进行迭代更新。这种贝叶斯类型的政策评估,可以让我们在高度复杂、充满不确定性的世界中,越来越接近政策背后的真相。
因此,高质量的政策制定与评估,必须抛弃“唯实验”方法论的偏执,对所有方法一视同仁、兼容并包。与医学和生物学研究将实验用于药物、疫苗与治疗方案上的应用不同,社会科学中的随机对照实验,可能更适用于理论的验证和修改,而不是具体政策的评估。因为,如果没有理论的指导,就难以将各种分散化评估的结果联系起来,建立理解中国公共政策更大的、更完整的图景。
当然,无论是政策试点还是随机实验,都需要考虑政策的成本-效益(Cost-Effectiveness)问题。任何公共政策,实际上都是资源的再分配,为了取得某种政策效果,一定会付出某种代价(时间、经济、健康、生命、尊严等)。现实中可以看到,相互竞争的政策方案之间的比较并不总是基于成本-效益,可能更多的是基于政策主导机构的绩效与利益。在这种情况下,政策试点和随机实验都失去了意义。
猜你喜欢
房地产导刊(2022年8期)2022-10-09 06:19:34
房地产导刊(2022年6期)2022-06-16 01:28:40
非公有制企业党建(2020年2期)2020-03-08 08:03:56
华人时刊(2019年21期)2019-11-17 08:25:07
中国资源综合利用(2016年5期)2016-02-03 02:56:13
中国卫生(2015年12期)2015-11-10 05:13:26
质量与标准化(2015年9期)2015-07-10 15:12:07
中国卫生(2014年7期)2014-11-10 02:32:52
中国卫生(2014年6期)2014-11-10 02:30:52
浙江人大(2014年5期)2014-03-20 16:20:25
