
基于强化学习的电力数据存储系统参数自适应调优
2022-02-28 06:30屠子健毛莺池吴明波
电力系统自动化 2022年4期
屠子健,毛莺池,吴明波,陈 禹
(1. 河海大学计算机与信息学院,江苏省南京市 211100;2. 华能澜沧江水电股份有限公司,云南省昆明市 650214)
0 引言
现有的数据存储系统大多部署于条件优越的专用数据中心。一方面,存储规模随着数据量的动态增加而扩展存储柜,无须考虑部署空间的问题;另一方面,数据中心由专业的存储运维人员进行配置优化与故障处理。特高压互联大电网的建设使得调度自动化系统监控的电网规模越来越大,需要采用更为先进的技术支持手段支撑更大范围内调度业务的统一协调和电网运行各类数据的全景监视与分析。特高压互联大电网的建设也使得调度自动化系统需要处理的实时数据量越来越大,多个调度系统间需要共享的实时数据也越来越多[1]。但当存储系统部署在偏远且环境恶劣的电网边缘(如开关站、变电站等)时,在部署空间、性能与鲁棒性等方面均面临严峻挑战。
随着电动汽车、智能家电等智能用电设备的快速发展,可采集到的智能用电终端也将快速增长,直接提高了数据采集的频度。上述问题对用电信息采集系统的自适应能力提出了新的挑战[2-3]。目前,电力数据存储系统数据量大、变化速度快、人工经验难以寻优,深度学习方法要优于传统方法,能够有效地解决上述问题。传统存储系统参数配置固定、不能自适应优化且资源部署方案原始,系统性能无法满足日益增大的负载。上述存储系统配置过程的问题使得应用性能受制于存储性能,且受到写操作任务并发影响,性能不断衰减,而使用Ceph 分布式软件定义存储,可灵活配置参数[4-5],实现性能的大幅提升。同时,通过调节中央处理器(CPU)、内存、存储、网络的参数提升动态、复杂电网数据的处理能力,且通过建立机器学习模型[6-8]自我优化参数,自适应解析所应用的负载,并对应标准化测试场景组合,构建了一个具备优化实时应用数据的服务质量保证的存储系统性能架构。
针对以上分析和电力数据存储系统中使用的Ceph 系统,本文提出一种基于强化学习的数据负载感知自适应配置参数推荐(DACR)方法。该方法利用基于强化学习的马尔可夫链蒙特卡洛采样(Qlearning-MCMC)方法配置参数样本集和相应的集群性能,使用分层建模(HM)方法构建性能预测模型,采用集群性能代价函数与负载相似度估算结合算法,提供负载的快速感知和配置参数的持续优化。在此基础上,建立服务质量感知与反馈机制,支持自适应的存储参数配置调整。实验结果表明,该方法采样效率优异,预测精度与现有预测方法相比有了一定的提升,满足电力数据采集系统的运行要求,且寻优耗时也明显低于现有的黑盒参数调优方法。
1 相关工作
面向电力物联网边缘数据存储应用场景,针对源-网-荷友好互动下的用电信息采集系统中数据负载(智能电能表、分布式光伏、电动汽车充电桩、移动巡检终端、视频摄像装置、电力资产电子标签)的快速动态变化,用电信息采集的颗粒度越小、频度越高对源-网-荷友好互动能力支撑就越大。
传统电力数据存储系统配置参数调优方法通过系统管理员的专业知识和经验选择局部参数进行设置。管理员根据不同的应用程序,总结出对电力数据存储系统性能影响较大的参数,在具体的应用场景手动调整配置参数的取值,但是电力数据存储系统中的配置参数通常种类繁多,例如电力数据存储系统中常用的Ceph 分布式存储系统[9]包含上千个配置参数,且参数与参数间呈现复杂的非线性关系,因此,找到最佳参数配置的概率极低。此外,在现代电力数据存储系统的部署环境中,系统硬件和工作负载快速变化,其使用的分布式数据存储系统从一个或几个相同节点扩展到数百个高度异构的环境,导致手动调整参数非常繁琐且耗时。
近年来,学者们开始研究智能化方法[10]以实现电力数据存储系统配置参数的自动调优。常用的参数自动调优方法包括:统计推理技术中的贝叶斯优化(BO)、模拟退火(SA)、遗传算法(GA)[11]、随机搜索(RS)、深度Q 网络(DQN)、智能爬山(SHC)等。这些智能搜索算法通过遍历配置参数样本空间,尝试迭代不同的参数配置,直至搜索到最优的参数配置[12-13]。Gaonkar 等人[14]使用遗传算法为多应用环境设计可靠的数据存储系统,该系统既能满足业务需求,也能最小化系统的成本。为了优化层次数据格式HDF5 应用的输入/输出(I/O)性能,Behzad 等人[15]提出了一种基于遗传算法的优化模型。以上智能搜索算法大多以“黑盒”方式进行参数调优,而忽略了存储系统内部的复杂结构。这导致每次搜索都需要运行包含大量数据集的应用程序,耗时较多。随着机器学习的广泛应用,针对电力数据存储系统配置的复杂问题,科研人员开始尝试使用基于机器学习的预测模型进行自动调整存储系统配置参数。Willke 等人[16]提出一种支持向量机回归(SVR)模型,在2 种不同的应用程序下分别比较了简单多元线性回归(MLR)、具有参数相互作用的多元线性回归(MLR-I)、具有二次效应的多重线性回归(MLR-Q)等方法,结果表明SVR 模型具有较优的准确性和计算效率。Herodotou 等人[17-18]提出了细粒度的性能分析模型来预测系统每个阶段的性能,该方法结合每个阶段的预测值,得到总体性能的预测。Yu 等人[19]提出了一种RFHOC 方法,利用随机森林(RF)算法为Map 和Reduce 阶段构建性能模型,但RF 预测结果具有不可解释性,整个预测过程是一个“黑盒子”。Lama 和Zhou[20]构建了一个基于支持向量机(SVM)的模型来预测Hadoop 作业的性能。Oceane 等人[21]提出一种基于神经网络强化学习的无监督参数调整系统(CAPES),定期测量目标存储系统的状态,并训练神经网络对当前配置参数的更改。上述性能预测模型都试图根据训练数据建立高度准确和复杂的个体模型,容易出现过拟合问题。一些线性回归的统计模型通常假设配置参数之间存在线性关系,这不符合存储系统配置参数非线性的特征。神经网络预测模型的建立需要的数据样本过多,会加大系统的采样工作量,且模型训练耗时过长。而电力数据存储系统的参数配置需要高效、精准以及可靠等特性。结合上述特点,深度学习方法优势远大于传统的人工配置参数方法。
综上所述,从基于经验规则的手动调整方法,发展到基于统计推理技术与机器学习相结合的自动调整方法,可以在一定程度上提升电力数据存储系统配置参数的工作效率。但针对电力物联网边缘快速变化的数据负载学习时间长且准确率低的问题,上述方法尚不能解决。本文分析电力数据存储系统的数据规律,快速识别边缘物联网数据类型的分布,鉴别整体数据负载变化,通过对电力数据存储系统中的Ceph 分布式存储系统配置参数的自适应调节,最大化提升数据存储系统的性能。
2 Ceph 配置参数
电力数据存储系统中的Ceph 分布式存储系统读写的基本流程如图1 所示。Ceph 是一个统一的可扩展的分布式存储系统,通过底层的librados 与后端 的OSD 交互,如附录A 图A1 所示。OSD 是Ceph系统的对象存储单元,实现数据的存储功能。其内部包含众多模块,模块之间通过队列交换消息,相互协作共同完成I/O 的处理。
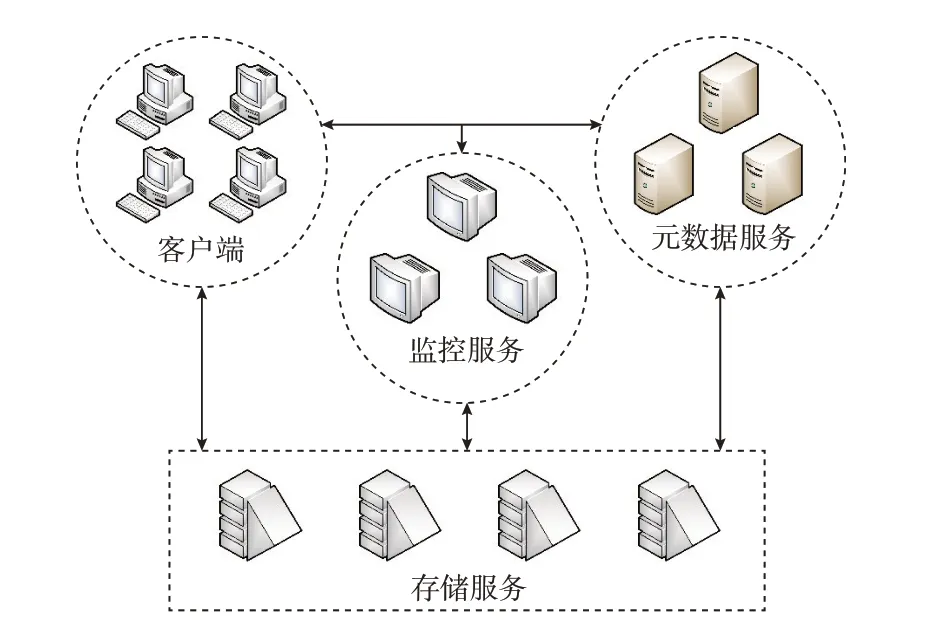
图1 电力数据存储系统中的Ceph 分布式存储系统流程图Fig.1 Flow chart of Ceph distributed storage system in electric power data storage system
本文针对源-网-荷友好互动下的用电信息采集系统中数据负载,包括智能电能表、分布式光伏、电动汽车充电桩、移动巡检终端、视频摄像装置、电力资产电子标签等用电数据,主要选取显著影响数据密集型应用(data-intensive application)性能的Ceph配置参数。数据密集型应用的主要挑战是数据量大、数据复杂、数据变化速度快。本文主要解决电力数据存储系统中数据量大、变化速度快等带来的问题,配置参数信息如附录A 表A1 所示。
3 模型架构
电力物联网中一般是通过边缘设备采集各种电力数据,这些电力负载数据是快速变化的。与此同时,整个电力系统基础设备数量多导致其整体数据量庞大。本文针对电力物联网边缘快速变化的数据负载,分析数据分布变化,自适应调节Ceph 分布式存储系统中CPU、内存、存储、网络的相关配置参数,从而提升动态、复杂电网数据的处理能力。
在电力数据存储系统中使用Ceph 系统可以很好地解决各个边缘设备数据量的动态变化,防止个别节点由于数据量突变而导致工作不正常,从而影响整体。通过对默认配置参数采样、系统性能预测建模、数据负载感知自适应推荐3 个方面进行研究,模型总体架构如图2 所示。
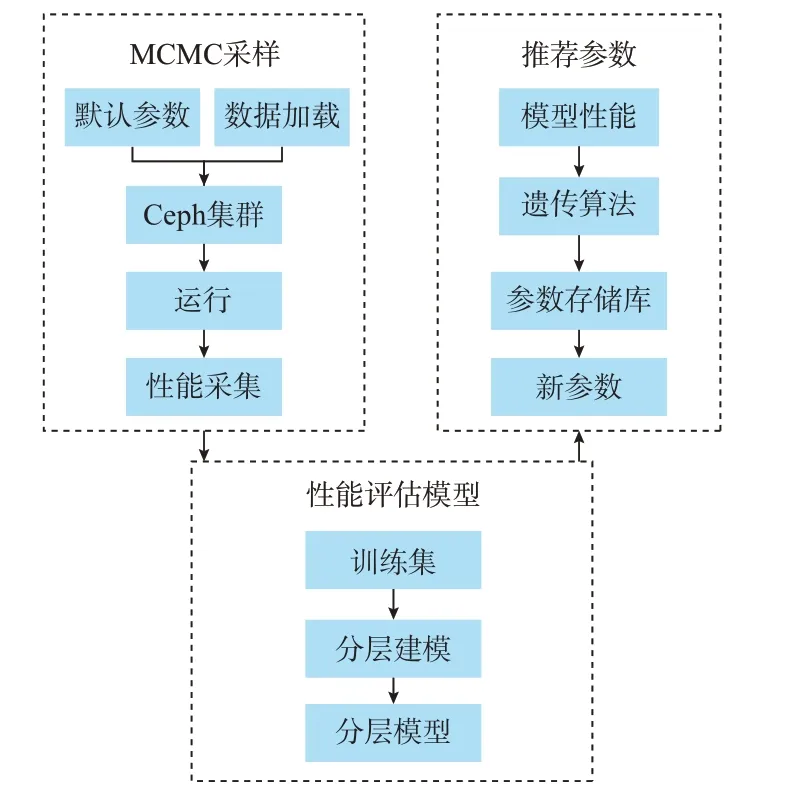
图2 模型总体架构Fig.2 Overall architecture of model
主要步骤如下:
1)泛在电力物联网应用类型多、负载变化快,电力数据存储Ceph 系统配置参数空间巨大、非线性的特性导致电力数据采集系统不能平稳运行。为了获得更高效的配置参数组合,需要对默认参数进行采样。在实际采样过程中,部分配置参数组合会导致集群发生崩溃,降低集群性能。为此,本文提出Qlearning-MCMC 方法,通过对配置参数的多维联合调整,将I/O 每秒读写速度(IOPS)作为强化学习中的奖励值,大于默认IOPS 值即增加奖励值,增加速度根据探索速率决定,使得配置参数实现有偏向的状态转移,提高采样的精度和效率,保证Ceph 集群的稳定性。
2)基于采样得到的参数样本集,吞吐量、I/O 延迟、系统能耗等可以作为性能评价指标。由于本文数据负载多为读写类型数据,故仅选用IOPS 值作为评价指标。以IOPS 作为性能评估指标,为Ceph集群建立性能预测模型。针对Ceph 集群每次运行具有大量输入数据的应用程序会耗费大量时间并占用系统资源的问题,提出一种HM 方法,通过多个简单子模型的合作来预测集群性能,避免复杂单个模型的过拟合问题。分层模型中每个子模型中的回归树训练特征不同,预测结果也存在差异,子模型之间不会发生耦合,反而能增强性能预测模型的鲁棒性和预测准确性。
3)基于Ceph 集群性能预测结果,建立配置参数库,在不同数据负载下推荐最优配置参数。针对电力物联网边缘数据变化速度快、负载类型多、调优结果不通用的特性,提出DACR 方法,采用变异系数(CV)分析数据分布,快速识别边缘物联网数据类型分布,鉴别整体数据负载变化,采用集群性能代价函数与负载相似度估算结合算法,提供负载的快速感知和配置参数持续优化,达到对整个电力数据存储系统性能优化与提高。
3.1 参数采样
本文所使用的采样方法在传统的MCMC 算法的基础上做了进一步的研究。目前,常用的采样算法包括接受-拒绝采样、Metropolis-Hastings 算法、吉布斯采样(Gibbs sampling)。这些采样算法根据配置参数的空间分布随机地产生服从该分布的样本,能够得到不同的参数样本集,但在实际采样过程中,需要考虑参数之间的相互影响以及集群运行的稳定性。MCMC 算法在采样的过程中不能很好地适用于电力数据变化快的环境中,只能解决高维且复杂的参数分布。改进的Q 学习算法[22-23]在电力通信领域有着很好的使用效果,所以本文提出了Qlearning MCMC[24]。其 本 质 是 在MCMC 算 法 中 加入一个奖励函数,使得采样过程中参数能够实现有偏向的状态转移,从而增强整个电力数据存储系统的稳定性以及性能高效性。图3 显示了Q-leaning MCMC 方法的具体架构。
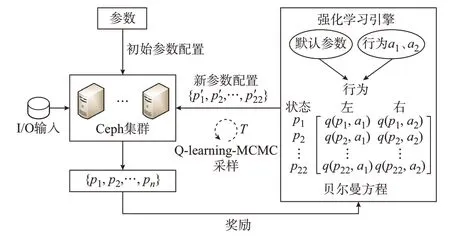
图3 Q-learning MCMC 方法框架Fig.3 Framework of Q-learning MCMC method
首先,将电力数据存储系统的默认配置参数与数据负载输入Ceph 集群中,以IOPS 作为标准化性能评估指标,得到相应的系统性能{p1,p2,…,pn};然后,对所研究的参数进行迭代采样,输入系统的默认配置参数集{p1,p2,…,p22}与动作值a1,a2至强化学 习 模 块 中,其 中{p1,p2,…,p22}为Q(s,a)中的状态s,每一个参数代表一个状态,动作值a1,a2定义为左和右,表示参数值向最小值方向与最大值方向进行探索,IOPS 值作为强化学习模块中的目标函数(奖励值),大于默认IOPS 值即增加奖励值,增加速度根据探索速率决定;最后,配置参数通过策略选择动作执行,根据贝尔曼方程[25]更新Q(s,a)指导MCMC 算法进行步长转移,将采样出来的新的配置参数再次输入Ceph 集群中,经过T次迭代后,得到最终实验样本集。
基于强化学习的马尔可夫链蒙特卡洛方法的详细步骤如算法1 所示。算法中需要先手动设置参数的状态转移次数、样本个数、探索速率及学习率。
选取对应IOPS 值最大的配置参数作为Qlearning-MCMC 采样的初始参数组,初始化动作值函数Q(s,a),执行动作a并观察奖励值r和新的状态s′的值。这里的奖励值r是配置参数与环境交互的过程中,量化动作对目标系统影响的指标。
本文设定的奖励值分为3 类:高于系统默认IOPS 值、低于系统默认IOPS 值、与系统默认IOPS值相等。奖赏规则记为:参数执行动作后,IOPS 值高于系统默认值时r+10,低于默认值时r-10,相等时r=0。学习率α控制着智能体的学习速率,选取较高的学习率会加快算法的收敛,但是过大的学习率可能导致智能体无法找到最优策略,本文设置α取值为0.5。通过对动作值函数Q(s,a)的不断更新,算法依据最优策略π(s)采样出新的配置参数pt,经过T次状态转移后,最终得到所需样本集{p1,p2,…,pn},每 一 个pi={x1,x2,…,x22}作 为 一组参数配置取值,其中包含了22 个单个参数配置。

算法1 基于强化学习马尔可夫链蒙特卡洛方法输入:参数分布pi={ x1,x2,…,x22}、状态转移次数T、样本个数n、探索速率ε、衰变系数γ、学习率α输出:样本集{ p1,p2,…,pn}1.初始化马尔可夫链{ x1,x2,…,x22}2.for t=1,2,…,T do 3. 初始化Q(s,a)4. 重复(对于每一个episode)5. 执行动作a,观察r 和下一个状态s′6. if random(0,1)>ε 7. a′←a 8. else 9. a′←Epsilon-Greedy 算法10. end 11. Qnew(s,a) ←Q(s,a) +α(R(s,a) +γmax Q′(s′,a′) -Q(s,a) )12. s ←s′13. 直到s 为终端14. pt~π(s)15. end for
3.2 模型建立
考虑到SVR、RF、SVM 等方法容易出现过拟合问题,并且一些线性回归算法之类的统计模型通常假设配置参数之间的关系是线性的。这不符合存储系统配置参数非线性的特征,而神经网络预测模型的建立需要的数据样本过多,会加大系统的采样工作量,并且模型训练耗时过长,不适用于电力数据存储系统的Ceph 性能预测工作。
本文提出一种HM 方法,通过多个简单模型的合作来预测系统性能,分层模型中每个子模型中的回归树训练特征不同,预测结果也存在差异,子模型之间不会发生耦合,反而能增强性能预测模型的鲁棒性和预测准确性。分层建模将多输入多输出建模问题分解为一系列单输入多输出的数据建模问题,通过构造多个更简单的子模型而不是构建精确复杂的单一模型来预测系统性能,以递归方式组合各个单独的子模型,产生1 阶、2 阶或更高阶的分层模型,从而提高性能预测模型的鲁棒性和准确性,图4 显示了该方法的总体框架。
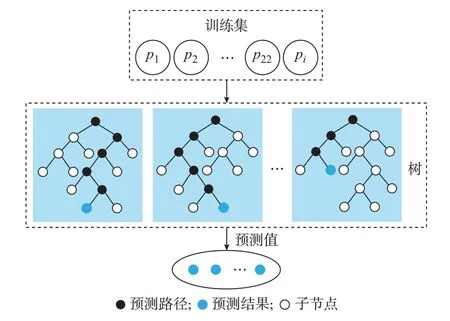
图4 分层模型框架Fig.4 Hierarchical model framework
模型框架由收集数据、建立子模型和预测性能3 个阶段构成,对于组合模型的构建主要由3 步组成。第1 步根据输入的配置参数和相应的IOPS 值,构建单个子模型M1;第2 步构建不同的子模型M2以反映未被M1预测到的系统性能变化;第3 步通过组合前2 个子模型构建初始组合模型IM,1=α1M1+α2M2。其中M1和M2为2 个子模型所预测的集群性能,α1和α2为模型学习率对应的相关系数。该过程迭代执行,将更多的子模型添加至组合模型中,执行次数由模型的目标精度决定。若组合模型IM在算法达到收敛之前满足目标精度,则得到最终性能预测模型;若组合模型IM在算法收敛之后还未满足目标精度,则重复上述过程,构建另一个组合模型CM进行第2 级组合:β1IM,1+β2IM,2,将不同级别模型分层地添加到最终组合模型中,直至模型达到目标精度。
构建基于分层建模的性能预测模型详细步骤如算法2 所示,算法2 中需要确定回归树的个数及树的复杂度(叶子节点数),实现误差最小化。

算法2 分层建模算法输入:训练集S、回归树个数nt、叶子节点个数nl、学习率α输出:预测性能Ppre,i 1.设置初始组合模型IM 精度为0,模型层数ml 为1 2.for i=1 to nt 3. Mi 为从S 中有放回抽样4. IM =IM +Mi α 5. if IM 的准确率大于目标准确率6. return IM 7. else 8. while IM 的准确率小于目标准确率9. ml =ml +1 10. IM =IM α+IM(ml -1)α 11. end while 12. return IM 13. Ppre,i ←IM{ p1,p2,…,p22}14.end for
HM 的建立是一个分层顺序过程,原始模型在每一步都保持不变,随着模型阶数提升,对系统性能预测误差逐渐减小。进一步分析算法2 的时间复杂度,在模型建立过程中最大时间消耗为双重循环,因此算法最大时间复杂度近似为O(ntml)。
3.3 参数调优
本文采用blktrace 工具抓取不同数据负载下的I/O 信息,根据负载下I/O 特征的不同,鉴别电力物联网边缘数据负载的变化。图5 显示了blktrace 工具在块设备层(block trace)收集磁盘I/O 信息的过程。
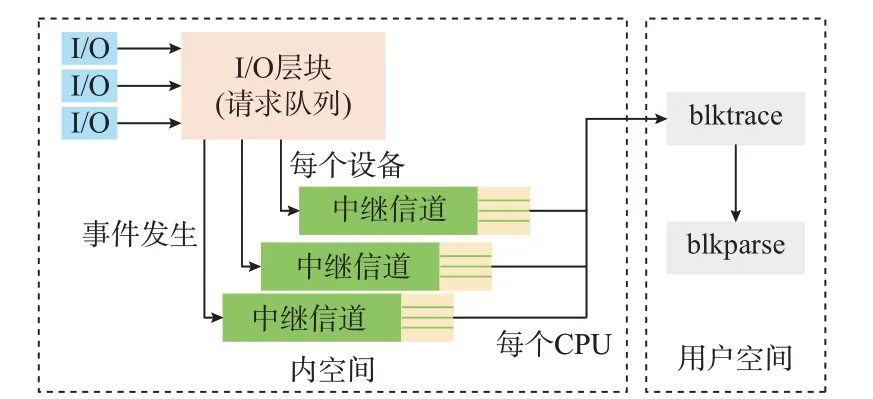
图5 I/O 信息抓取Fig.5 I/O information capture
抓取过程分为内核空间和用户空间2 个阶段,当用户应用程序中的I/O 进入块层(请求队列),被I/O Scheduler 依照调度策略发送给driver(用于支持它的块存储硬件),blktrace 在进行信息抓取时,会分配物理机上逻辑CPU 个线程数,每一个线程绑定一个逻辑CPU 来收集数据,每个CPU 对应输出一个文件rbd.blktrace.*,来保存所采集的信息,其中rbd 为设备名,*表示CPU 序列号,通过blkparse(配合blktrace 使用,用于分析和展示数据)将不同CPU的I/O 的trace 文件合并,并解析、格式化输出为可读的I/O 信息。
由于电力物联网边缘数据负载的快速变化,每次需要对更新的工作负载重新遍历配置参数空间,导致耗时过大。同时,相似特征的工作负载具有类似的最优配置参数。对于多数情况下的数据负载而言,根据工作负载的数据特征,快速匹配类似的最优配置参数,可以有效提高系统资源利用率。本文利用推荐引擎快速地找出能够适合新工作负载的配置参数,图6 显示了推荐引擎的工作流程。
首先,由工作负载分析器识别新的数据负载特征类型,与预先生成的配置参数组成评分数据矩阵,采用奇异值分解(SVD)对矩阵中的缺失值进行处理。然后,计算电力数据存储系统工作负载类型之间的相似度,生成近邻负载类型集。最后,采用性能代价函数与负载相似度估算结合算法来生成推荐配置参数,根据负载的实际运行情况和集群状态确定是否更新电力数据存储系统配置参数库。具体实现步骤如下。
1)工作负载分析器识别并收集不同负载特征类型,在集群中测试每种负载特征在不同配置参数样本下的资源利用率。为了方便推荐过程计算,将资源利用率看作数据负载对不同配置参数的评分值,具体评分值见附录A 表A2。
将表A2 中的数据记作评分矩阵A,使用SVD法对矩阵A进行分解,得到2 个矩阵P和Q的乘积表示评分矩阵A。

利用评分矩阵A中的已知评分训练矩阵P和Q,使得P和Q相乘的结果最好地拟合已知评分。将评分矩阵A中负载类型u对配置参数i的缺失值评分记作R′ui,用矩阵P的第u行Pu乘上矩阵Q的第i列Qi可以得到式(2)。

假设已知评分为Rui,对于矩阵A中每个缺失值误差记为Eui=Rui-R′ui,计算出总的误差平方和为:
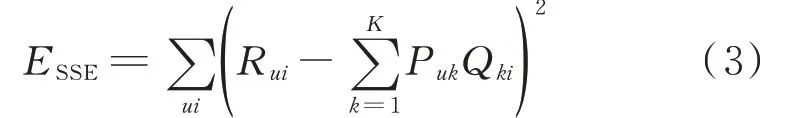
式中:Puk和Qki分别为矩阵P和Q中对应的元素。
为了使预测出的值更好地拟合矩阵A,需要通过训练使得ESSE的值最小。利用梯度下降法求得ESSE值在变量Puk处的梯度为:
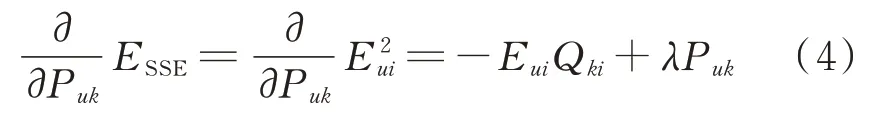
式中:λ为正则化因子。为避免过拟合情况的发生,得到目标函数ESSE在Puk处的梯度后,将Puk向负梯度方向变化,记参数更新速率为β,得到Puk和Qki的更新式为:
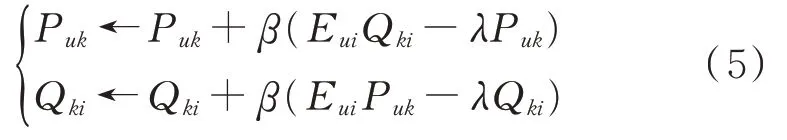
采用随机梯度下降(SGD)算法对Puk和Qki进行更新,每次迭代使用一个训练数据对参数进行更新,直到算法收敛。经过数据填充后的矩阵信息如附 录A 表A3 所示。
与批量梯度下降(BGD)算法相比,SGD 不需要使用全部数据来计算目标函数,而是在每轮迭代中,随机优化某一条训练数据上的SSE 值,使得Puk和Qki的更新速度大大加快并有利于避免局部最优解。
2)在实际工程应用中,电力物联网边缘设备不断产生新的数据负载,导致工作负载分析器生成高维的负载类型变量。面对复杂高维的负载变量特征,推荐配置参数会增加算法相似度计算的工作量。因此,需要分析每个特征变量指标,将强相关的变量组用单一的新变量替代,使用较少综合指标表征各变量中的各类信息,降低负载类型变量特征维度。
采用主成分分析(PCA)方法对负载类型特征进行降维。PCA 主要思想是通过坐标系的转换,以数据最大方差方向作为坐标系转换方向,选取包含绝大部分方差的坐标轴实现数据的降维。通过计算负载类型的协方差矩阵,得到其特征向量。选择J个特征值最大的特征向量组成特征向量矩阵,将原始负载类型数据转换至J个特征向量构成的新空间中[26]。运用PCA 对高维数据进行降维,减少特征个数,实现数据缩减,防止数据过拟合,加快算法运行速度和减少数据的存储空间。PCA 算法有2 种实现方法:基于特征分解协方差方法和基于SVD 分解协方差矩阵方法。由于负载类型变量矩阵是非方阵的,因此选用基于SVD 分解协方差矩阵方法。
将负载类型特征F={f1,f2,…,fn}构造为一个m×n的矩阵R,初始矩阵R表示为:
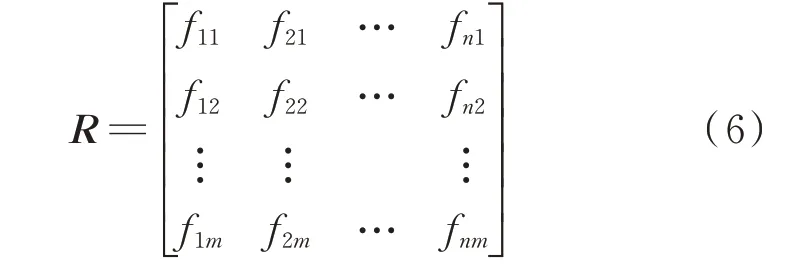
式中:每一列表示一个负载类型特征,每一行表示具体的特征值。
采用PCA 算法对特征进行降维的具体步骤如下。
步骤1:中心化。
将每个负载类型特征fi所对应的特征值fij减去所在维度特征的平均值:
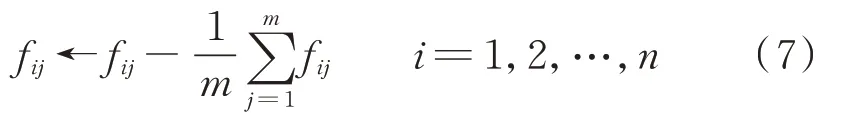
步骤2:计算协方差矩阵。
使用协方差来量度每2 个负载类型特征之间的关系,将中心化后的矩阵记为X,得到协方差矩阵为:
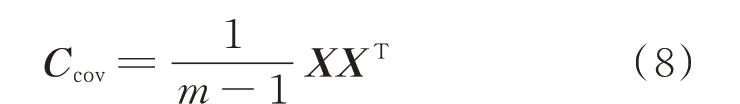
步骤3:奇异值分解。
通过SVD 对协方差矩阵Ccov奇异值分解,计算协方差矩阵的特征值和特征向量。
步骤4:特征向量选择。
对计算得到的特征值从大到小排序,选择其中最大的J个特征值所对应的特征向量w1,w2,…,wJ构成特征向量矩阵W,将初始矩阵R与特征向量矩阵W相乘,得到降维后的数据集。
步骤5:主成分个数选择。
通过特征值计算得到主成分所占的百分比,选取贡献率累积和大于95%的J维特征,对于J维特征所保留的信息量计算公式为:
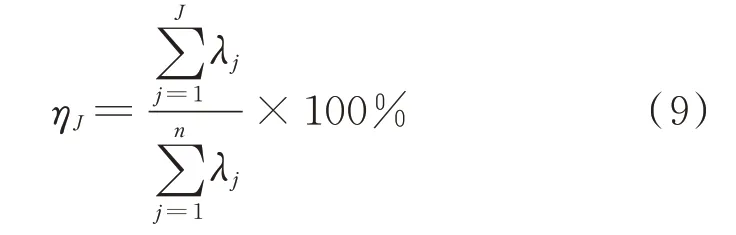
式中:λj为特征向量对应的特征值。
3)传统协同过滤算法采用相似度计算,找出最相近的数据负载类型,但并未考虑推荐的配置参数所对应的集群性能情况,导致推荐的配置参数所对应的系统性能不佳、推荐效率过低。因此,将集群性能影响因素也考虑到电力数据存储系统中,将电力数据负载和Ceph 系统负载的相似度和集群性能通过权值w加权求和,得到综合评分权重函数sscore。
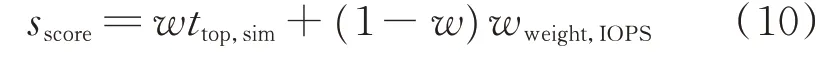
式中:ttop,sim为选取的前k个最相似的数据负载类型;wweight,IOPS为前k个数据负载对应配置参数下的集群性能权重,计算公式见式(11)。
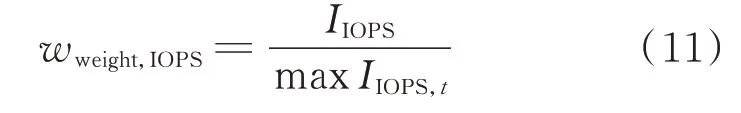
式中:IIOPS为当前IOPS 值;maxIIOPS,t为t时 刻 电力数据存储系统配置参数库中最大的IOPS 值。
电力数据存储系统配置参数推荐完成后,根据数据负载的实际运行情况,更新配置参数库。由于频繁更新配置参数库需要消耗一定时间,会增大系统开销,因此当推荐精度满足应用需求时,不需要频繁更新配置参数库,以提升Ceph 系统性能。贝叶斯优化、模拟退火、智能爬山、随机搜索等智能算法,其本质都是通过不断迭代寻优,这与遗传算法本质相同,只是迭代的方法不一。大量的实验表明,这些智能算法的最终结果都在同一数量级上。本文采用遗传算法优化电力数据存储Ceph 系统的参数配置,是参数选择配置的一个中间步骤,不详细讨论不同智能算法对参数选择性能的影响。
将推荐系统推荐出的配置参数对应的电力数据存储系统集群性能记为IIOPS,pre,数据负载实际运行的最优性能记为IIOPS,real,由遗传算法寻优获取,使用平均绝对百分比误差(mean absolute percentage error,MAPE)测量推荐准确度:

为了使推荐系统保持较高的推荐精度并且低频率地更新配置参数库,设置如下规则决定是否更新:1)若当前数据负载推荐任务完成时集群中没有等待作业,则调用MCMC 采样器以采样更多的电力数据存储系统配置参数更新数据库;2)设定MAPE 的阈值为10%,当一个数据负载推荐的精度大于该阈值时,无论集群中是否有等待作业,都必须更新电力数据存储系统配置参数库。
4 实验结果与分析
4.1 采样方法分析
测试环境由5 台服务器构成,模拟真实情况下的电力数据存储系统,其中一台作为客户端节点,其余4 台服务器构成OSD 集群,每台服务器中包含3 个OSD 节点和1 个Monitor 节点,每台服务器之间使用万兆局域网卡连接。电力数据存储系统中的Ceph 集群的网络拓扑图如附录A 图A2 所示。
使用Q-learning-MCMC 算法和传统MCMC 算法各采样1 000 组参数配置{f1,f2,…,f1000},在混合负载下的电力数据存储系统Ceph 集群中测试出不同参数配置所对应的集群性能,实验结果如附录A图A3 所示。从附录A 图A3 中可以看出,传统MCMC 算法采样出来的参数配置所对应的性能集中在750~1 250 之间,而高于电力数据存储系统默认性能的参数配置很少,导致采样精度过低;Qlearning-MCMC 算法采样出来的参数配置所对应的性能集中在1 000~2 500 之间,最高性能可达到4 688,并且大多数参数配置所对应的性能要高于电力数据存储系统的默认性能。但是Q-learning-MCMC 算法采样出来的部分参数配置对应的参数性能很低,这是由于Q-learning-MCMC 中的智能体在更新动作值函数Q(s,a)过程中,选择了探索策略,随着采样组数的提高,智能体会选择使集群性能提高的参数配置作为最佳路径去采样,从而使采样精度更高。
使用Q-learning-MCMC 算法和传统MCMC 算法采样,观察随着采样组数的不断提升,2 种采样算法的采样精度改变趋势,结果如附录A 图A4 所示。从整体趋势上来看,随着采样组数的增加,Qlearning-MCMC 算法采样的参数所对应的性能百分比不断上升,其中在2 000 组到4 000 组之间性能提升速率最快,在采样组数到达6 000 时,性能提升百分比逐渐趋向平稳;而传统MCMC 算法的性能提升百分比始终维持在一个较低水平。说明Q-learning-MCMC 算法中的智能体在经过一段时间的采样策略学习后,能够指导MCMC 选择能使集群性能更高的参数配置进行采样,从而使采样更加智能化。
由于电力物联网工作负载的快速变化,采样效率对系统性能有很大影响,在实际采样的过程中,有些参数状态可能会拒绝转移,从而增加采样工作量。附录A 图A5 为采样5 000 组参数配置的样本分布图,可以看到较传统MCMC 算法相比,Qlearning-MCMC 算法采样所得到的实际有效样本点更加密集,即采样效率更高。
从附录A 图A6 可以看出,传统MCMC 算法的采样时间随采样组数增加线性增长,Q-learning-MCMC 算法在采样1 000 组时耗时较多,随着采样组数的增加,采样时间趋于平稳,呈现小幅度上升。这是由于Q-learning-MCMC 算法在刚开始采样时,智能体没有找到最优采样策略,从而需要不断选择动作来更新动作值函数,以此找到最优路径指导MCMC 算法采样,导致耗时较多。经过一段时间的策略选择后,智能体会利用之前探索到的最优策略,无须重复探索,从而使采样耗时下降并趋于平稳。
在参数采样策略的学习过程中,智能体以一个探索速率ε进行动作选择。从附录A 图A7 可以看出,在迭代次数为0~100 时,应选取较大的探索速率;在经过一段时间迭代后,ε=0.2 所对应的奖励累计值为1 319,ε=0.9 所对应的奖励累计值为1 015,选取较小探索速率所对应的奖励累计值要明显高于大探索速率下的奖励累计值。这是因为在智能体执行动作的初始阶段,由于不了解Q 函数中的任何值,故随机的探索环境往往比固定的行为模式要好,随着智能体对估算出的Q 值更有把握,智能体将利用之前探索到的较优策略,故将逐渐减小探索速率ε。
根据对采样方法的分析,Q-learning-MCMC 算法采样的电力数据存储系统配置参数所对应的最高系统性能可达4 688。与传统MCMC 算法相比,采样精度提升了约1.8 倍,并且随着电力数据存储系统采样组数的提升,Q-learning-MCMC 算法的采样效率要优于传统MCMC 算法。
4.2 模型对比分析
为了使性能预测模型能够精确地预测系统性能,需要确定3.2 节中的3 个模 型参数nt、nl和α,其中nt为构建初始组合模型所需要的子模型数量,nl为子模型回归树中叶子节点的个数。较高的nt值能使性能预测模型获得较高的精度,但也会导致较长的模型评估时间,nl值越高单个回归树越复杂,nl值的大小在一定程度上影响子模型的最终个数。
考虑到电力数据存储系统的特殊性,本节选取网格搜索[27]的方法来确定nt与nl的最优值。通过对参数值进行穷举搜索,利用模型精度作为参数值选择的评分方式,采用5 折交叉验证方法计算电力数据存储系统的各个参数值的平均评分,选取评分最高的作为最优解。由附录A 图A8 可知,当nl取19时,模型返回的平均评分达到最高。
由附录A 图A9 可以看出,随着回归树个数的增多,平均评分随之上升,当回归树个数达到165时,平均评分的提升趋于平缓,综合模型的运行成本选取nt值为165。
为了更直观地了解性能预测模型的预测性能,选取采样的样本集,形成300 组不同的电力数据存储系统配置参数,以IOPS 值作为性能指标,运行Ceph 集群观察电力数据存储系统性能变化,实验结果见附录A 图A10。结果表明,当配置参数改变时,Ceph 集群性能随之发生显著变化,且电力数据存储系统配置参数与集群性能呈非线性关系。
选用其中电力数据存储系统集群性能变化趋势波动大、数值变化明显的数据,利用基于HM 的性能预测模型预测相应配置参数下的集群性能(IOPS),模型预测过程如附录A 图A11 所示。从整体趋势看,分层性能预测模型能较好地预测集群性能,并能及时反映实测性能值的变化趋势。
为了验证分层性能预测模型对于电力数据存储系统领域的优劣性,本文采用SVR、RF、人工神经网络(ANN)等复杂单个模型分别预测Ceph 集群性能。选取附录A 图A10 中性能连续发生波动、差异较大的数据区域,将分层模型和单个预测模型进行对比。几种单个模型在所选数据区域的预测过程如附录A 图A12 所示。
从附录A 图A12 可以看出,在配置参数第4 组至第13 组的数据区域中,实测值的峰值发生连续骤变,而单个模型的预测值仅在第4 组至第7 组配置参数数据区域跟上实测值的变化,在第8 组至第13 组配置参数数据区域上预测值趋向平缓,没有及时跟随实测值上升和下降,在第15 组至第22 组配置参数数据区域上,单个模型预测值存在明显振荡,且严重滞后于实测值的变化趋势。
基于配置参数特征的高维非线性特性,HM 通过组合多个简单模型进行性能预测,与复杂单个预测模型相比,HM 不会因为实测性能的骤变而出现突变与振荡,其性能预测较为稳定。
不同工作负载下,电力数据存储系统Ceph 集群的最优配置参数也发生改变。为了验证不同负载下性能预测模型的预测性能,使用filebench 仿真fileserver 应 用 程 序,生 成4 KB 随 机 读 和512 KB 顺序读2 种负载。利用HM 模型和单个回归预测模型(MLR、SVR、RF、ANN)分别在2 种工作负载下预测集群性能,统计指标。采用均方根误差(RMSE)和R 平方(R2)作为预测性能的评价指标。其中RMSE 的值越小,表明模型预测效果越好,但RMSE 值对异常点较为敏感,若预测模型中对某个点的预测值很不合理,则误差较大;R2 通常取值范围为[0,1],越接近1 表明模型预测性能越好,越接近0 表明模型拟合效果越差,实验结果见附录A表A4。
在2 种负载下MLR 方法预测效果最差,因为它将电力数据存储系统配置参数特征视为线性的,而实际配置参数呈现非线性关系;ANN 建模方法在2 种工作负载下的R2 和RMSE 值相差较大,其预测鲁棒性较差、预测结果不稳定;HM 的R2 值最接近1 且RMSE 值最小,说明HM 预测性能要优于其他建模方法。
在电力数据存储系统中通过模型对比分析可以发现,HM 性能模型的预测误差要明显小于现有的性能预测模型,并且能够及时反映电力数据存储系统的性能变化,在4 KB 随机读和512 KB 顺序读2 种负载下,HM 模型的RMSE 值分别为205.472和214.327,与现有算法中性能最好的SVR 模型相比,预测精度提升了约12.95%。
4.3 参数调优对比分析
为了衡量在电力数据存储系统条件下数据负载分布识别效果,选取I/O 请求在驱动和硬件上所消耗的时间(D2C)和平均每个I/O 请求所消耗的时间(Q2C)作为指标,计算2 个阶段下不同阈值所对应的曲线下面积(AUC)值,从而选取最优阈值。实验的最终结果如附录A 图A13 和图A14 所示。
从附录A 图A13 和图A14 可以看出,随着阈值的变化,电力数据存储系统负载分布识别准确率会出现明显波动,并且D2C 和Q2C 的变化趋势相似,在阈值为0.3 时准确率达到最高。
利用基于评分函数的协同过滤(score-CF)算法和基于相似度的协同过滤(sim-CF)算法分别为电力数据存储系统混合负载下的Ceph 集群推荐配置参数,在不同组数候选配置参数下所对应的2 种算法推荐集群性能如附录A 图A15 所示。从图A15可以看出,本文提出的score-CF 算法所推荐的配置参数对应性能要优于sim-CF 算法,说明在电力数据存储系统数据负载相似度计算过程中,加入集群性能影响因素能够有效提升推荐系统的推荐精度。
为了验证不同电力数据存储系统工作负载下推荐系统的推荐精度,本文利用score-CF 算法和sim-CF 分别为5 种不同工作负载推荐配置参数,具体实验结果见附录A 表A5。从整体上看,加入集群性能影响因素的score-CF 算法推荐精度要优于sim-CF算法,且score-CF 算法的MAPE 值均小于10%,满足集群性能工作需求,而sim-CF 算法须不断更新电力数据存储系统配置参数库,增加系统运行复杂度。
为了评估推荐系统的推荐效率,将黑盒参数调优方法(加入性能预测模型)和DACR 方法进行对比。在电力数据存储系统不同配置参数组数下,2 种方法搜索最优配置参数的耗时对比如附录A 图A16 所示。从整体上看,DACR 找出最优配置参数的耗时要明显低于黑盒参数调优方法,说明推荐系统能够在一定程度上减少寻优耗时,并在短时间内针对快速变化的数据负载推荐出合适配置参数。
通过对于电力数据存储系统参数调优分析,score-CF 算法在不同推荐组数下的推荐精度均要高于sim-CF 算法,且在5 种不同数据负载下的推荐误差分别为7.4%、4.9%、6.2%、7.1%和5.2%,满足电力数据采集系统的运行要求。在参数推荐效率上,本文推荐系统耗时也要明显低于现有的黑盒参数调优方法。
5 结语
本文对电力数据存储系统中Ceph 分布式储存系统配置参数自动调优问题进行研究,聚焦于电力物联网设备状态数据、用户用电数据以及电网运营等海量边缘数据的存储问题。从配置参数智能采样、集群性能预测模型建立和数据负载感知自适应参数推荐3 个方面自适应调整电力数据存储系统中CPU、内存、存储等相关配置参数,从而提升动态、复杂电网数据的处理能力。通过建立HM 性能模型减小预测误差,及时反映系统的性能变化,比现有SVR 算法预测精度提升了12.95%。本方法在推荐参数方面同样有较好的提升,在不同推荐组数下的推荐精度均要高于sim-CF 算法,能够满足电力数据采集系统的运行要求。在电力数据存储系统参数推荐效率上,DACR 耗时也要明显低于现有的黑盒参数调优方法,可以广泛应用于如今的电力数据存储系统中。
本文主要贡献如下:
1)对被广泛使用的强化学习进行调整,融入符合电力数据变化背景的MCMC 采样方法,与原始的MCMC 算法进行实验比较,采样精度提升了约1.8倍,并且随着采样组数的增加,Q-learning-MCMC算法的采样效率要优于传统MCMC 算法。
2)针对Ceph 集群运行应用程序时间过长的问题,提出一种HM 性能预测模型,通过多个简单子模型的合作来提高预测模型的精度和鲁棒性。实验表明,HM 性能模型的预测误差明显小于现有的性能预测模型。
3)针对电力物联网快速变化的数据负载,使用blktrace 工具抓取不同数据负载下的I/O 信息,快速识别边缘物联网数据类型分布,提出一种基于评分差异的配置参数推荐方法,结合负载相似度与集群性能2 种指标共同搜索最优参数。通过实验可知,score-CF 算法满足电力数据采集系统的运行要求。
附录见本刊网络版(http://www.aeps-info.com/aeps/ch/index.aspx),扫英文摘要后二维码可以阅读网络全文。
猜你喜欢
哈尔滨轴承(2020年2期)2020-11-06
军事运筹与系统工程(2019年4期)2019-09-11
发明与创新·大科技(2019年12期)2019-03-17
电子制作(2018年11期)2018-08-04
中国交通信息化(2017年3期)2017-06-08
知识就是力量(2017年2期)2017-01-21
中央民族大学学报(自然科学版)(2016年3期)2016-06-27
南都周刊(2015年4期)2015-09-10
南都周刊(2015年3期)2015-09-10
南都周刊(2015年1期)2015-09-10
