
基于Stacking-Bagging-Vote多源信息融合模型的财务预警应用
2022-02-26 06:58刘家鹏田冬梅
计算机应用 2022年1期
张 露,刘家鹏,田冬梅
(中国计量大学经济与管理学院,杭州 310018)
0 引言
市场竞争的日益激烈,资本市场的瞬息万变,使得企业陷入财务困境的可能性也在提高。财务预警模型在一定程度上能够使得企业及时规避、有效防范财务风险,对投资对象和项目审慎决策,防止企业陷入财务困境。而基于大数据的海量性、多样性、高速性和价值性[1],越来越多的学者尝试将以机器学习为代表的大数据人工智能技术应用到财务预警领域[2]。随之出现的财务预警样本的严重不平衡性[3],一定程度上限制了分类器的性能[4]。重采样技术[5]被提出应用到财务预警研究领域,并取得了一定的成果。但是经典的不平衡采样技术存在一定的缺陷,随机上采样[6]通过对小样本的多次重复来达到平衡,容易造成过拟合;随机下采样[7]通过删减大样本从而达到样本平衡,但是对数据信息利用不足,预测存在很高的随机性;人工合成新样本的重采样技术(Synthetic Minority Over-sampling TEchnique,SMOTE)[8]通过合成新样本,来使得样本达到平衡,但是合成样本容易造成与原样本之间的边界模糊问题。有学者尝试将集成学习的思想应用到重采样技术中[9],证实可以有效提高算法性能。
人工智能技术快速发展,性能优越的分类器如弹性网(Elastic Net,EN)[10]、随机森林(Random Forest,RF)[11]和极端梯度提升(eXtreme Gradient Boosting,XGBoost)[12]等在财务预警研究中有了一定的应用。但基于单分类器的性能提升陷入了一定的瓶颈,因此有学者将目光投向集成分类器的研究中,目前比较成熟的集成技术[13]有装袋法(Bagging)、提升法(Boosting)和堆叠法(Stacking)等[14]。集成技术对简单分类器如决策树等的性能有明显的提升,随机森林是基于决策树的Bagging 集成[15],XGBoost 也是基于树的Boosting 提升[16]。Stacking 集成方法被应用在网页检测[17]、网贷违约检测[18]等领域,可以有效融合不同种类的机器学习分类器,从而有效提升预测准确率。
本文的主要工作有:1)通过Up-Down 集成采样技术解决随机上采样容易发生过拟合问题与随机下采样的信息利用不足的问题,找到了上下采样之间的平衡点,提高信息利用率的同时防止发生过拟合问题,从而提高算法性能;2)通过Tomek link 对训练集数据进行清洗,降低SMOTE 算法在人工合成数据时发生边界划分的不清晰,一定程度上提高了财务预警的预测准确率。3)构建SBV(Stacking-Bagging-Vote)多源信息融合模型,综合多个集成技术,相较于单独集成方法,多层次多框架的SBV 模型,将数据层次与模型层次进行交互式融合,进一步较为全面地提高了财务预警的各项指标,为不同的利益相关者提供更为契合的财务预警模型。
1 不平衡数据集成采样算法
1.1 Up-Down集成采样算法
上采样是指二次采样中,随机重复抽取小样本,使得样本均衡的方法。比如训练集中,有80%的数据属于类别I,20%的数据属于类别Ⅱ,该训练集的数据存在不平衡现象,上采样就是将类别Ⅱ数据重复采样,从而使样本比例均衡。下采样与上采样相反,是通过随机筛除大样本,使得大样本的数量与小样本相等。比如上述的训练集,就是将80%的类别I 的数量降为与20%的类别Ⅱ的数量相等,因此,训练集一共使用了40%的数据。
由于小样本的数据远远小于大样本的数据,在本文的研究中,小样本数据仅占全体样本的2.86%,因此若单独使用上采样技术,会使小样本重复的次数过高,造成模型产生过拟合现象;而单独使用下采样技术,大量的样本信息将被抛弃而无法被模型所学习,只能学习到不到6%的数据集,分类器的学习效果并不尽如人意。因此,在本文的研究中,尝试将上采样和下采样算法进行集成,具体的过程如图1所示。

图1 Up-Down集成采样算法的过程Fig.1 Process of Up-Down ensemble sampling algorithm
在集成Up-Down 过程中,将训练集中的大样本和小样本进行不同比例的集成,将使用的上采样比例记为over ratio,代表少数类样本进行随机上采样后,占到的全体训练集样本的比例。然后对训练集样本数据用10 折的交叉验证进行训练。本文将over ratio 作为控制变量,以5%为间隔,基于数据有效性和过拟合的考虑,在初步的实验中,将over ratio 的取值范围控制在0%~50%,根据实验表现逐步确定所有over ratio 的取值范围,最终得到的训练集可以在一定程度上有效避免过拟合与欠拟合的发生。
1.2 Tomek-Smote采样算法
SMOTE 算法属于上采样技术,其基本思想是分析少数类样本,并根据少数类样本的数据特征,人工合成后向数据集添加新的样本。样本合成方式为对样本X以欧氏距离为标准,计算X到少数类的样本集Smin中所有样本的距离,并得到其k最近邻。根据样本的不平衡比例设置采样比以确定采样率n,对于每个少数样本X,从其k个最近邻随机选择几个样本,假设所选的最近邻为Xn。对于每个随机选择的最近邻Xn,根据式(1)构造新样本。

Tomek links 的定义为:假设样本点Xa和Xb属于不同的类别,d(Xa,Xb)表示两个样本点之间的距离,如果不存在第三个样本点Xc使得d(Xc,Xa)<d(Xa,Xb)或者d(Xc,Xb)<d(Xa,Xb)成立,称(Xa,Xb)为一个Tomek link 对。从定义容易看出,如果两个样本点为Tomek link 对,则其中某个样本为噪声(偏离正常分布太多)或者两个样本都在两类的边界上,容易造成误判。Tomek-Smote 算法的思想是用Tomek links 对训练集数据中的正常上市企业样本进行清洗,筛除位于边界的样本对,然后用SMOTE 算法产生基于训练集的人工合成新样本,进行模型构建与运行。
2 SBV多源信息融合模型
2.1 Stacking框架
Stacking 算法使用10× 10 折嵌套交叉验证,对训练集样本进行训练,并将得到的值输出到下一层,用初级分类器对回测结果进行堆叠。由于Stacking 模型使用初级分类器的预测值作为第二层的输入,因此初级分类器和次级分类器学习到的数据应该有所不同,在不能动用测试集数据的情况下,本文使用交叉验证解决了这一问题。
使用了三个元分类器——弹性网、随机森林和XGBoost,作为初级分类器,分别使用决策树(Decision Tree,DT)、逻辑回归(Logistic Regression,LR)、支持向量机(Support Vector Machine,SVM)作为次级分类器,构建Stacking 融合模型,构建流程如图2 所示。

图2 Stacking融合框架工作流程Fig.2 Workflow of Stacking fusion framework
将每家公司的经营状态设为Y,为0-1 属性的类别变量,即正常上市和被特别处理。每家公司的财务特征指标与市场特征指标集设为X,包括营业状况指标、财务风险指标、资产配比、股票价差等。将实验数据分为训练集和测试集,在实验中,测试集数据不进行处理变动。
首先,将训练集样本特征作为输入变量,使用集成分类器随机森林、弹性网和XGBoost,分别产生三个初级分类模型,得到三组的预测概率Pi(Y=0|X)和Pi(Y=1|X)。通过随机搜索的方式得到三个初级分类器的最优参数,使用10×10 折嵌套交叉验证,解决Stacking 策略中可能出现的交叉学习现象。
然后用基础分类器决策树、Logistic 回归和SVM 作为次级分类器,将初级分类器进行依次堆叠,输出三组预测概率,完成模型构建。
最后,用最终输出的Stacking 策略模型,对测试集数据进行预测,并对最终的预测结果进行对比分析。
2.2 Bagging-Vote算法
装袋(Bagging)是一种集成的元算法,通过对训练集数据自行复制,并获得汇总的预测变量,从而生成基础分类器的多个版本,提高了算法模型的稳定性和准确率,并减少了过拟合的问题。投票装袋(Bagging-Vote,BV)是本文基于Bagging 基本理论,结合投票集成思想设计的算法。
Bagging-Vote 算法的集成工作流程如图3 所示。
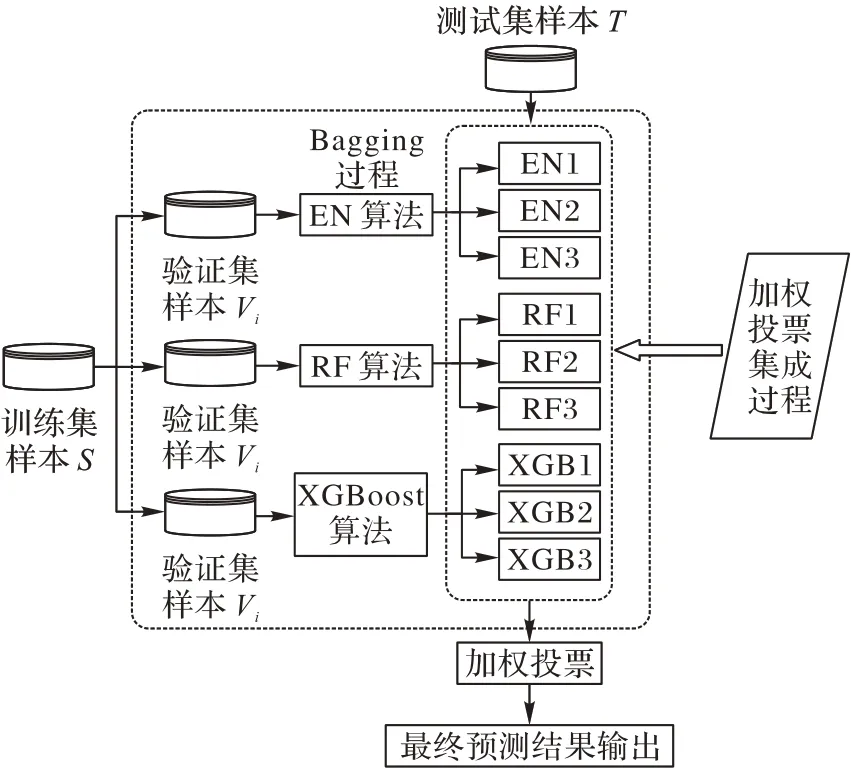
图3 基于Bagging-Vote算法的集成工作流程Fig.3 Ensemble workflow based on Bagging-Vote algorithm
BV 的步骤可以大致分为5 部分:
步骤1 从训练集数据中创建验证集样本。
步骤2 在每个训练集和验证集样本上训练模型。
步骤3 根据各算法创建分类模型并保存结果。
步骤4 将分类模型对测试数据进行预测,并保存预测结果。
步骤5 对训练集数据进行统计分析对比,加入预测结果池,实现数据层面与模型层面的交互。
步骤6 基于模型的性能,对预测概率进行加权投票,输出最终预测结果。
用装袋算法分别对多个元分类器进行集成,对得到的分类模型进行分别排列组合式投票集成,结合了多个分类器的最终分类结果。在此基础上,将训练集的数据特征结果进行统计对比分析,将统计结果作为预测值放入投票池中,实现了模型与数据层面的交互预测。最终将得到的模型组进行对比分析,选择预测准确率与整体均衡性最高的模型。
2.3 SBV多源信息融合优化
在Bagging-Vote 算法和Stacking 融合框架的基础上,结合不平衡数据集成采样算法,尝试将Tomek-Smote-Stacking 框架与Up-Down-Bagging-Vote 集成算法相融合,并加入经过卡尔曼滤波技术过滤后的收益率数据,形成数据层面与模型层面的交互式优化提升,构建SBV 多源信息融合模型,其构建流程如图4 所示。
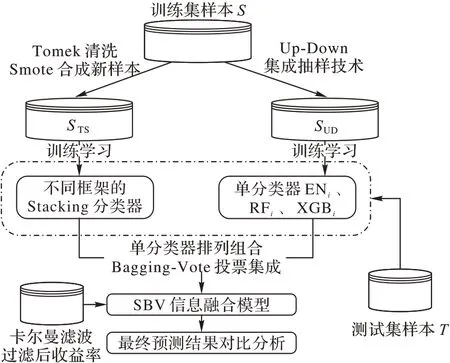
图4 SBV信息融合模型构建流程Fig.4 Construction process of SBV information fusion model
对于SBV 信息融合模型的构建流程大致分为如下几个步骤:
步骤1 对训练集样本进行Tomek 清洗后用SMOTE 算法人工样本合成新样本得到STS,用不同框架下的Stacking 分类器进行训练学习,具体流程如图2 所示。
步骤2 对训练集样本进行Up-Down 集成抽样,得到SUD,用单分类器模型弹性网、随机森林和XGBoost 对处理过的SUD样本集进行训练学习,得到若干个单分类器ENi、RFi和XGBi,具体流程如图3 所示。
步骤3 用在步骤1 和步骤2 得到的分类器对测试集样本进行预测,得到对样本集的预测概率。
步骤4 参考卡尔曼滤波方法在β 估计中的应用[19],结合资本资产定价模型,过滤掉样本集的收益率中大盘的影响,并进行分析比较,形成数据层次与模型层次的交互式融合。
步骤5 基于Stacking 融合框架、BV 集成算法与过滤后收益率的直接融合,得到若干个基于不同框架与不同层次的信息融合模型,并将最终的预测结果进行对比分析,得到合适的模型。
3 实验与结果分析
3.1 评价准则
本文的模型设计与结果验证基于Rstudio 编程实现,设定的分类结果矩阵如表1,其中TP(True Positive)和TN(True Negative)代表预测和真实值一致的情况,FP(False Positive)和FN(False Negative)代表预测值和真实值不一致的情况。

表1 分类结果矩阵Tab.1 Matrix of classification results
本文的正类样本为财务预警企业,负类样本为正常上市企业,使用的4 个指标公式如下所示。
召回率(Recall)表示正类样本被正确分类的完整度,是指分类器对正例样本分类“能力”的度量,即正确挑选出财务预警企业样本的概率。

精确率(Precision)表示正确挑选出正类样本的概率,用来度量被预测为财务预警企业的样本真实值为财务预警企业的概率。

G-mean 综合考虑了正类分类和负类分类的准确率,表示正例分类准确率和负例分类准确率的均衡值。
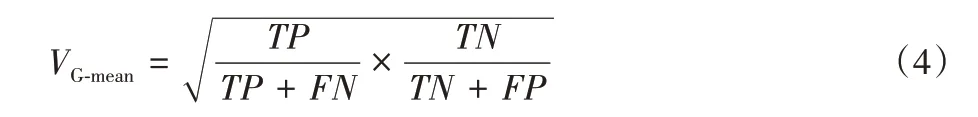
F1 值综合了准确率和召回率的结果,当F1 值较高时说明算法分类结果比较理想。

3.2 数据来源与指标设计
本文的数据来自国泰安数据库,在A 股上市公司中,选取在2019 年由正常上市状态转为特殊处理的84 家企业,记为财务危机样本;将剩下的正常上市公司,筛除数据严重缺失的样本后,得到2 854 家上市企业,记为财务正常样本。选取样本公司2018 年第一季度到第三季度的财务指标数据和股票市场数据,进行分析处理:其中,本文将股票市场的日度数据转化为季度数据,留下数据较为齐全且有一定代表性的财务指标,筛除数据缺失严重的企业。对剩下的缺失值用RF 算法补齐。将第一季度和第二季度的数据作为训练集,用于训练模型;将第三季度的数据作为测试集,来对模型的预测结果进行评估。本文对训练集数据使用不平衡数据的集成采样算法使其平衡,但是测试集数据用于模型预测效果的验证,故而不进行任何处理。
在财务预警模型的构建中,将是否发生财务预警记为因变量Y,将财务指标和市场指标记为自变量Xi。
将在2019 年由正常上市公司转变为被特殊处理的企业记为发生财务预警的因变量Y=1,将在2019 年未存在特殊处理、退市或被证交所警告的正常上市企业记为因变量Y=0,剔除掉样本严重缺失的企业后,得到样本分布情况如表2 所示。ST 代表被特别处理,财务状况异常;ST*代表存在退市风险警示。表2 中,将在2019 年当年发生财务状况异常、存在退市风险警示和发生退市的企业记为财务预警企业。如表2 所示,AB 代表企业在2019 年被证监会特别处理,由正常上市状态转变为ST 企业;AD 代表在该企业在当年由正常企业转换为ST*企业;AX 代表该企业由正常上市状态转为退市;AA 代表该企业为正常上市状态。
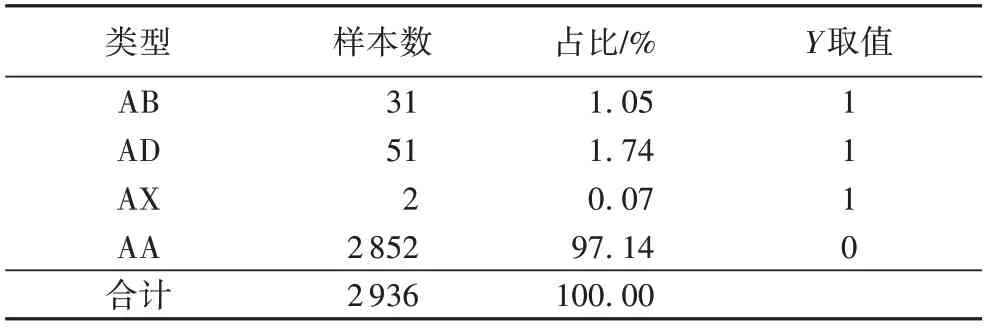
表2 样本分布情况Tab.2 Distribution of samples
本文的解释变量在财务指标的基础上,加入股票市场指标,更契合财务预警成因,以提高财务预警预测的准确性。核心解释变量体系的构建如图5 所示,包括资本结构指标、营运能力指标、盈利能力指标和股票市场指标。资本结构指标包括流动比率等的流动资产分布,资产与负债、权益分布,现金流的分布和应收账款与收入比的分布;营运能力指标包括周转率与存货收入比等;盈利能力指标包括利润率、成本率与费用率等;股票市场指标包括季度回报率、股票流动性指标和大盘指标离差等。

图5 解释变量体系的构建Fig.5 Construction of explanation variable system
3.3 结果分析
3.3.1 基于Stacking和BV模型的财务预警预测
本节将Bagging-Vote 信息融合模型与多框架Stacking 融合模型分别应用到财务预警领域,并依次通过集成Up-Down采样技术、SMOTE 采样技术与Tomek-Smote 采样技术对数据样本进行处理,改变样本的不平衡性,提高模型性能。实验结果如表3 所示。
如表3 所示,集成Up-Down 采样技术下的BV-EN、BV-RF和BV-XGBoost 分别代表不同采样比例与不同参数下的弹性网、随机森林和XGBoost 分类器的BV 集成模型;BV-Models代表弹性网、随机森林和XGBoost 分类器三类分类器同时进行BV 集成得到的融合模型;Stacking-DT、Stacking-SVM 和Stacking-LR 分别表示以决策树、支持向量机与逻辑回归为次级分类器的Stacking 融合模型。

表3 基于不同采样算法的模型预测结果Tab.3 Model prediction results based on different sampling algorithms
通过对比分析研究可以发现:Bagging-Vote 算法与集成Up-Down 采样技术的适配性更高。就召回率而言,最高的为Up-Down-Stack-SVM 模型,但此时的G-mean 值明显偏低,可以最大限度上避免遗漏财务预警企业;从总体样本的预测准确率来看,Up-Down-BV-Models 的综合预测性能较为均衡,G-mean 值达到90.44%。
通过对比分析可知,多层次的BV(Bagging-Vote)融合模型与不同框架下的Stacking 融合模型对分类器都有一定的提升,但是二者各有特点。BV 算法对多个分类器的集成的提升效果在对数据进行集成Up-Down 采样的环境下,有一定的提升,可以相对均衡地提高召回率与精确率,但是提升幅度有 限;Stacking 融合框 架则与SMOTE 和Tomek-Smote 采样技术的适配性更高,在牺牲了模型精确率的基础上,对召回率有明显的提升。
基于此,实验进一步考虑将Tomek-Smote-Stacking 框架融合到Up-Down-Bagging-Vote 集成算法中,得到SBV 融合模型。
3.3.2 基于SBV多源信息融合模型的财务预警预测
Bagging-Vote 算法的优点在于对融合的分类器类型没有严格的限制,因此实验考虑进行数据层次与模型层次的交互式融合,尝试对模型性能进行进一步的提升。
在数据层次,公司收益率受大盘短期波动因素的影响,较难很好地对经营状况形成真实的反映。基于此,通过使用卡尔曼滤波技术对样本公司的收益率数据进行处理,过滤掉公司收益率中受大盘短期波动影响的部分。过滤后的收益率,对公司的真实经营状况具有一定的诠释性,并加入模型池中,用Bagging 算法与分类模型和Stacking 框架进行融合。卡尔曼滤波过滤后的收益率数据分布如图6 所示。
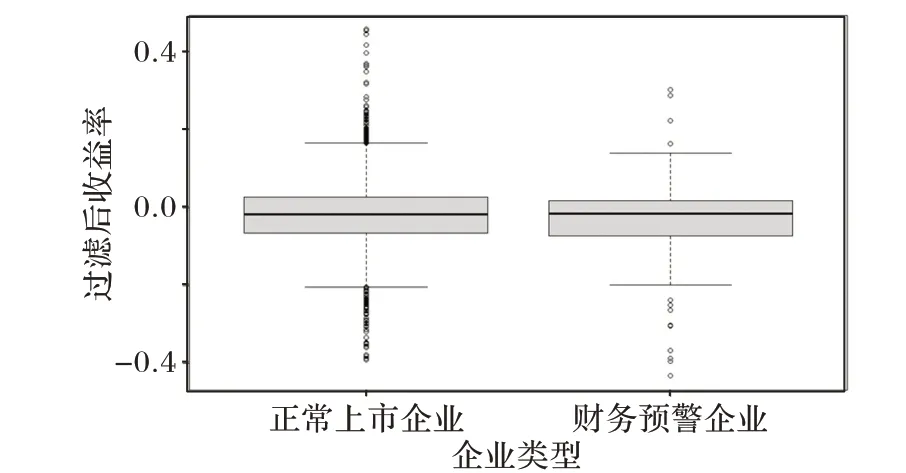
图6 卡尔曼滤波过滤后的收益率分布Fig.6 Distribution of return rates after Kalman filtering
如图6 所示,财务预警企业的数量远少于正常上市企业,就极值的分布而言,正常上市企业的收益率分布区间为[-0.389 0,0.456 2],存在财务风险的企业的收益率分布区间为[-0.431 1,0.301 1]。根据收益率上下限和数据分布的数据结构,进行数据层面和模型层面的融合分析。
SBV 多源信息融合模型的构建思路参考了BV 模型的排列组合与投票集成的方式,从而得到可以应用在不同场景,适合不同对象的,以单框架融合(SBV-S)的、多框架融合(SBV-M)的与多框架多层次融合(SBV-MF)的总计420 个模型。
单框架融合模型(SBV-S)是以Stacking 单框架融合BV集成的模型;多框架融合模型(SBV-M)是以多个Stacking 框架融合BV 集成的模型;多框架多层次融合模型(SBV-MF)是多个Stacking 框架结合BV 集成与数据层次的交互式融合得到的多层次多框架的融合模型。实验以召回率(Recall)、精确率(Precision)和G-mean 值度量指标,对信息融合模型进行排序,选取不同框架不同层次融合下的指标排名前两名,共计6 组模型进行对比分析。
如表4 所示,分别以召回率、精确率和G-mean 值作为模型预测结果排序的度量指标。

表4 基于不同排序指标的预测结果Tab.4 Prediction results based on different ranking indexes
召回率衡量了模型成功预测出财务困境企业的概率,最高达到97.62%,为多框架多层次的SBV 多源信息融合模型,此时的精确率有较大程度的下降,整体样本的预测准确率大约维持在89%。
精确率衡量了模型预测出来的财务预警企业的精准度,通过表4 可以发现,在以精确率排序的预测结果中,SBV-S 的精确率最高,达到26.92%。将Tomek-Smote-Stacking-LR 融合模型(表3)与SBV-S 进行对比,可以发现:两个模型在召回率相同的情况下,后者的精确率、F1 值和G-mean 都有一定的提升。
G-mean 衡量了模型预测性能的综合能力,均衡地衡量了财务预警企业和正常企业预测准确率。从表4 整体来看,SBV-MF 的G-mean 值相对比较低。SBV-MF 通过加大财务预警企业预测错误的惩罚系数,提高成功挑选出具有财务风险企业的概率,在一定程度上牺牲了正常企业的预测准确率。
对表4 进行对比分析可以发现,SBV 模型兼具BV 集成和Stacking 模型的优点,对于模型的性能在准确率和精确率上都有较为全面的提升,并且根据模型的特性,可以为不同需求的利益相关者提供一定的参考。
基于Stacking 多框架与多层次的BV 集成得到的模型(SBV-MF),能最大化地帮助投资者挑选出存在风险的企业,但与此同时,将财务正常的企业误判为财务风险企业的概率也较大。利益相关者可以通过投资需求选择恰当的模型,对于风险规避者,可以选择SBV-MF,有效规避投资失败的风险;对于风险中性者,可以选择SBV-M,得到较为均衡的预测结果;对于追求高风险者,可以选择SBV-S,在一定程度上可以减少将正常企业误判为财务风险企业的成本。
基于Stacking 单框架的BV 集成得到的模型(SBV-S),能得到较高的精确率和整体样本的预测准确率,能够较为精确地挑选出财务预警企业,从而降低对正常上市企业的误判成本。总体而言,SBV 信息融合模型显著提升了财务预警的预测准确率,相较于BV 集成模型和Stacking 融合框架又有了进一步的提升,与单分类器相比,提升效果更为显著,并且利益相关者可以通过实际需要挑选恰当的财务预警模型。
4 结语
在人工智能财务预警研究中,财务风险的企业数量要远少于正常上市企业,由此产生了严重的样本不平衡问题。为了解决这一问题,重采样技术被应用到财务预警研究中,然而典型的重采样技术存在一定的缺陷,比如随机上采样容易产生过拟合问题,随机下采样则丢失了大部分的信息,SMOTE 人工合成的新样本容易产生样本分类的边界模糊问题等。此外,现有的研究大多使用基础分类器对财务预警问题进行研究,其分类器的提升始终有限。因此,通过对现有研究的梳理与对前沿技术的深入挖掘,将随机上采样与随机下采样进行结合,得到集成Up-Down 采样技术;将Tomek link对应用到SMOTE 采样中,降低人工合成新样本产生的边界模糊,得到Tomek-Smote 采样技术。集成不平衡采样技术有效提升了分类器的性能,一定程度上降低了样本不平衡对财务预警模型预测效果的影响。
在指标的选择上,考虑到企业遭受财务危机同时受到内因和外因的影响,因此在财务指标数据的基础上,加入了市场指标数据,将市场信息纳入考虑,使得指标体系的构建与财务预警风险的成因更加贴近。在进行模型的BV 集成预测中,加入了使用卡尔曼滤波过滤之后的收益率,过滤了大盘影响之后的企业个体收益率更为真实,并实现数据层次与模型层次的交互,一定程度上提高了模型的预测准确率。
本文的研究还尝试通过不同层次的Bagging-Vote 集成技术和不同框架的Stacking 模型来提高现有机器学习分类器的预测准确率。随机森林和XGBoost 作为当前性能较强的分类器,对其本身进行改进得到的提升有限,因此,本文通过融合Bagging-Vote 和Stacking 框架构建的SBV 多源信息融合模型,显著提高了预测准确率,并且可以根据利益相关者的实际需要选择对应的模型。对于市场监管者而言,可以选择精确率较高的模型,减少重点监管企业的数量,实现高效、准确的监管范围;对于投资者而言,可以选择召回率值较高的模型,一定程度上规避投资失败的风险,并降低投资失败的成本;对于上市公司自身而言,则可以利用多个模型对自己进行预测判别,及时发现并防范风险;对于债权人而言,可以通过财务预警模型判断债务人的财务境况,降低资金无法回收的风险。
在未来的研究中,可以从以下方面进行深入探讨:1)对于数据的真实性问题,由于上市公司公开的财务数据可能经过了一定的修饰与润色,并不能真实地反映企业的经营发展状况,在分类器的学习过程中,财务指标数据的失真问题在一定程度上会影响分类器的判断。在未来的研究中,将通过文本挖掘技术等方法,对财务数据的真实性进行进一步的审核与改进,使用更为真实的数据,来构建具有更广泛、更贴合实际应用的企业财务预警模型。2)在评估模型性能的指标方面,本文使用了较为传统的统计学指标。然而,基于财务预警的特殊性,统计指标并不能准确地衡量模型的性能。因此结合具体的实际情景,未来的研究中将构建更具有经济意义的指标,从契合财务预警研究的角度衡量模型的性能。
猜你喜欢
现代电子技术(2022年15期)2022-07-28
电子产品世界(2022年4期)2022-04-21
黑龙江大学自然科学学报(2022年1期)2022-03-29
包装工程(2022年1期)2022-01-26
小资CHIC!ELEGANCE(2022年1期)2022-01-11
意林原创版(2021年7期)2021-08-03
计算机系统应用(2021年2期)2021-02-23
现代职业教育·职业培训(2019年12期)2019-02-03
软件导刊(2017年4期)2017-06-20
小说月刊(2014年11期)2014-04-18
