
基于双重检测的气门识别方法
2022-02-26 06:58:42李英豪
计算机应用 2022年1期
佘 维,郑 倩,田 钊,刘 炜,李英豪*
(1.郑州大学软件学院,郑州 450002;2.互联网医疗与健康服务河南省协同创新中心(郑州大学),郑州 450052)
0 引言
工业中的气门识别过程是通过相机拍摄气门所在的区域,由视觉系统根据图中物料的情况优先判定距离最近、最上层的气门毛胚件,然后返回目标的位置信息以及中心点坐标给机器人,机器人控制系统将驱动机器手臂在适当的区域执行抓取工作。
在实际的工业流程中,如何快速精准地分拣工件是一个至关重要的问题。传统的分拣过程中采用示教或离线编程的方法,需要专业的操作人员精准把控目标的放置和机器人的移动轨迹,对操作人员和流程有一定的要求,不具备普遍性和实时性,无法适应较复杂的工作环境[1]。将视觉系统与现有的机器人相结合具有较高的灵活性和可靠性,在提高生产效率的同时还节约了人工成本,提高了机器人的智能化程度[2]。基于机器视觉技术的工业分拣系统已经在工业自动化生产领域广泛应用[3]。
在基于视觉系统的工业流程中,目标的识别与检测是视觉定位的核心。圆形目标的自动检测与定位是工件气门识别中的关键技术。目前基于圆形目标的识别算法主要分为两类:基于人工设计特征的提取算法和基于深度学习的算法。其中,在基于人工设计特征的提取算法中,霍夫圆变换(Circle Hough Transform,CHT)[4]是最早用来识别圆形目标的经典算法,通过将数据从原始图像空间变换到定义的参数空间,并根据参数空间中的投票结果峰值来确定圆形的参数。该方法在部分图像区域不完整的情况下有较好的鲁棒性,但其检测精度有待提高且随机性大。针对Hough 圆变换算法中产生的问题,Xu 等[5]提出了一种随机霍夫变换(Randomized Hough Transform,RHT)的圆检测方法,随机选取圆周上的3 个点并以这些点为圆心画圆,经过若干次迭代后找到在容忍阈值内最优的圆,该算法提高了圆的检测效率。近年来,不少学者以此为基础进行了各种改进,熊雪琴[6]提出了一种基于像素比的圆检测算法,只根据第一个样本总结出的滑动窗进行遍历找圆,极大地缩短了对目标的检测时间。
目前,深度学习的目标检测算法主要分为两类:Twostage 算法和One-stage 算法。Two-stage 算法对应R-CNN(Region Convolutional Neural Network)[7]、Fast R-CNN(Fast Region Convolutional Neural Network)[8]、Faster R-CNN(Faster Region Convolutional Neural Network)[9]这一系列基于深度学习的分类方法,这类算法先从输入图像中选取可能包含待检测目标的候选框,然后用分类器评估这些候选框中的目标,整个流程执行下来较慢,但是精度较高[10]。
One-stage 算法以YOLO(You Only Look Once)系列的算法为代表,自提出后在工业领域有广泛的应用前景,其中心思想是利用整张图像作为输入,通过卷积神经网络将预测框的位置、大小和物体分类直接预测出来。YOLO 将目标检测重新定义为单个回归问题,在提升速度的同时尽量保证了精度的可靠性。YOLOv1(YOLO version 1)[11]作为整个YOLO系列的开山之作,奠定了“分而治之”的中心思想。将输入的图像划分为S×S个网格,当网格内包含待检测对象的中心时,就负责生成B个检测框(bounding box)以及C个类别的概率,每个检测框包含5 个矢量信息:位置信息(x,y,w,h)和置信度(confidence)。其中,置信度包含两重信息,即检测框中包含对象的可信度和检测框与实际标注框的交并比(Intersection Over Union,IOU)。YOLOv1 具有较快的检测速度,但一个网格只能预测两个框和一个类别,极大地限制了预测框的数量。针对YOLOv1 中的缺陷,YOLOv2(YOLO version 2)[12]在原YOLO 的基础上加 入了批归一化(Batch Normalization,BN)[13]加速了 网络的收敛,同时采 用Darknet-19 作为新的主干特征提取网络;另外,YOLOv2 还参考anchor 机制运用k-means 聚类算法[14]来生成适合数据集大小的先验框,以提升模型的召回率,获得更快更准确的检测效果。YOLOv3(YOLO version 3)方法[15]在YOLOv2 的基础上做了进一步改进,采用Darknet-53 作为主干特征提取网络,同时借助残差网络(Residual Network,ResNet)[16]中的跳跃连接来防止有效信息的丢失,解决深层网络退化等问题;YOLOv3 中通过改变卷积核的步长来实现特征图尺寸的缩小,在每个残差网络前添加一个步长为2 的卷积层用于下采样,且主干网络中包含分别由1、2、8、8、4 个残差块组成的5个残差网络,故共经过5 次下采样来获取特征;除此之外,YOLOv3 还采用特征金字塔网络(Feature Pyramid Network,FPN)[17]作为加强特征提取网络,经过上采样(up-sample)和拼接(concat)操作,将不同特征层之间的特征融合得到13×13、26×26、52×52 的分辨率,同时进行通道调整得到3 个不同尺度的检测头用于大、中、小目标的检测,YOLOv3 模型基本满足任何尺寸的目标检测且符合预期效果。YOLOv4(YOLO version 4)[18]在目标检测上没有革命性的改变,而是在YOLOv3 的基础上结合了很多先进的小技巧,可以大致分为4 个方向。首先,通过Mosaic 数据增强、自对抗训练(Self Adversarial Training,SAT)和跨小批量标准化(Cross mini-Batch Normalization,CmBN)对输入端进行改进;其次,在特征提取网络的创新上采用跨阶段部分连接(Cross-Stage-Partial-connection,CSP)的Darknet-53 为主干网络,同时使用Mish 激活函数并采取Dropblock 正则化的方法来丰富局部特征;接着,从Neck 入手,构建加入空间金字塔池化层(Spatial Pyramid Pooling,SPP)和 路径聚合网络(Path Aggregation Network,PAN)的加强特征提取网络;最后,采用DIOU(Distance Intersection Over Union)作为新的损失函数。
在实际的目标检测过程中,圆形目标识别的速度影响最终的抓取效率,而识别的精度影响结果的可靠性[19]。基于深度学习的目标检测算法可以从海量的数据中自动提取特征进行识别定位,具有较高的准确率和较快的检测速率。其中,One-stage 模式比Two-stage 模式更有优势[20],因此YOLO方法更符合工业气门中的识别定位环节。然而,在整个工件气门识别的流程中零件数目庞大,目标堆叠个数较多,基于深度学习的检测算法仍存在检测精度较低、重叠目标漏检率高以及目标包裹度差、圆心定位不准的问题。
基于以上问题,本文提出了一种基于双重检测的气门识别方法进行目标圆的预测定位过程。首先,本文使用数据增强对样本进行轻量扩充;然后,融合YOLOv3 及YOLOv4 框架,构建适合气门检测的深度卷积网络架构,识别单个气门所在的矩形区域;最后,结合传统算法中的霍夫圆变换对气门进行精准识别。实验结果表明,本文提出的方法在满足定位精度的基础上,既能提高模型识别的准确率,又能改进目标的包裹度,在实际应用中有一定的实用价值。
1 气门识别方法
本文提出了一种基于双重检测的气门识别方法得到最终的气门检测定位结果。首先使用数据增强技术扩充训练的样本,然后从网络结构、先验框预测、损失函数三个方面改进YOLO 模型以提高检测结果的识别精度,接着引入霍夫变换进行二次识别来提高目标的包裹度及圆心的定位精度,最后将改进后的深度卷积网络模型与二次识别技术相结合,大致流程和每步的预测结果展示如图1 所示。以下介绍每一步的主要工作。
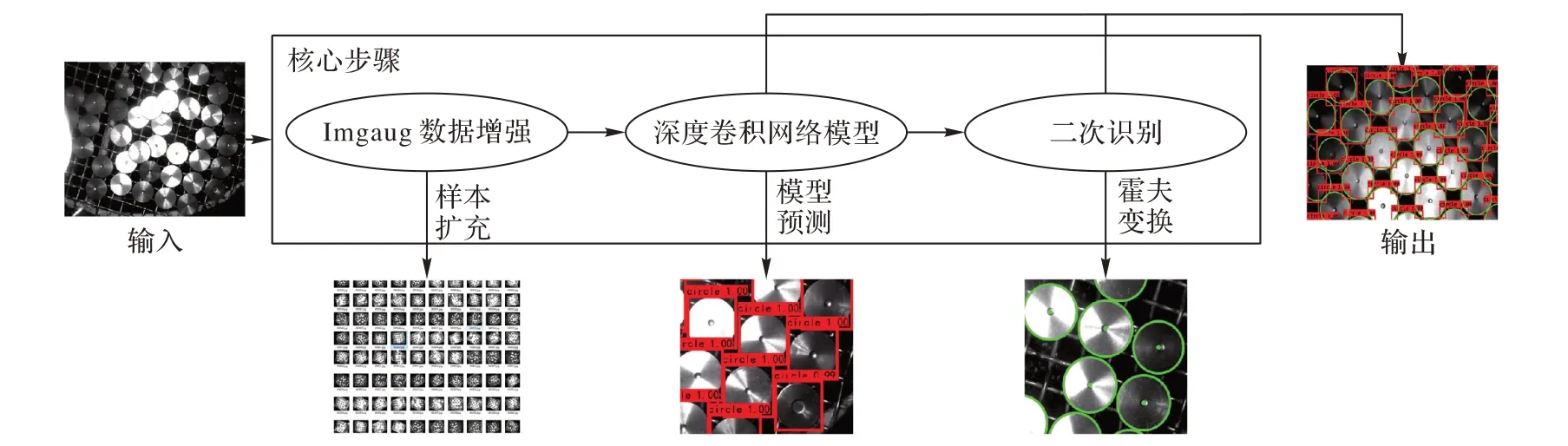
图1 基于深度卷积网络与霍夫变换的工件气门识别过程Fig.1 Identification process of workpiece valves based on deep convolutional network and Hough transform
1.1 数据预处理
在数据预处理阶段,本文重点使用了数据增强技术。深度学习中数据集的样本数量直接影响最终训练模型的好坏,本文对训练集中的每张图像进行数据增强。数据增强通过对原始图像进行旋转、平移、调整曝光度等操作,增添了样本的多样性。该方法可以在扩充数据集的同时,对原始图像中的手工标注框进行相应的坐标变换,生成对应的xml 文件,不仅节省了标注的人工成本,还可以自定义扩充的图像数量。
1.2 模型构建
本文构建卷积神经网络模型用于气门识别,以YOLOv3[15]模型为基础,分别从网络结构、先验框预测、损失函数三个方面进行改进,以提升预测结果的准确度和模型的泛化能力。
1.2.1 网络结构
本文提出的气门识别深度卷积网络结构如图2 所示。

图2 本文提出的气门识别深度卷积网络结构Fig.2 Deep convolutional network structure for valve identification proposed in this paper
当输入图像尺寸为(416,416,3)时,该模型在保持原有的主干网络(Darknet53)的基础上,依然保留(52,52,256)、(26,26,512)、(13,13,1 024)这三个特征层。同时,本文模型将(13,13,1 024)这一输出经过三次卷积,同时引入SPP 结构,使用不同池化核大小的最大池化分离出显著的上下文特征,与原YOLOv3 相比增大了网络的感受野,保留了输出的空间尺寸大小。接着,本文模型将经过SPP 结构的输出进行卷积和上采样,与(26,26,512)这一特征层进行拼接操作,再和(52,52,256)的特征层进行拼接和卷积。最后,引入PAN结构,使用下采样加卷积的方式自底向上传达强定位特征,使层之间信息流动的方式发生了改变,与原YOLOv3 相比能获取到更加细粒度的局部特征,减少有效信息的流失。
1.2.2 先验框预测
考虑到通过聚类生成的先验框不太稳定,YOLOv3 中使用k-means 聚类算法仅对先验框的宽高进行聚类,本文方法基于不同聚类数对于识别结果的影响,选择初始聚类数,并以此确定先验框。本文中数据集是工业零件中的气门毛胚件,原先的9 组先验框增加了正负样本不均衡的比例,对气门的识别检测精度较低。因此本文重新对先验框进行聚类分析,将各检测框与其人工标注框的交并比的平均值记为AugIOU,该值越大表示检测框预测的结果越准确。这里分别取k=1~9 时,平均交并比AugIOU 随k值变化,在k=1~5 时AugIOU 的值显著增加,而k=6~9 时AugIOU 的值逐渐趋于平缓,因此k=5 为本文最优的预测框数量解。经重新聚类后的先验框 尺寸分别为:68×89、90×112、130×151、166×149、188×200。
1.2.3 损失函数
损失函数直接决定网络效果的好坏,YOLOv3 网络使用均方和误差作为损失函数。本文中只标注气门这一类目标,因此不再计算由分类带来的损失,简化YOLOv3 中的原损失函数以加速网络的收敛,只考虑检验框的坐标预测误差(Location Loss)和置信度预测误差(Confidence Loss)。即:
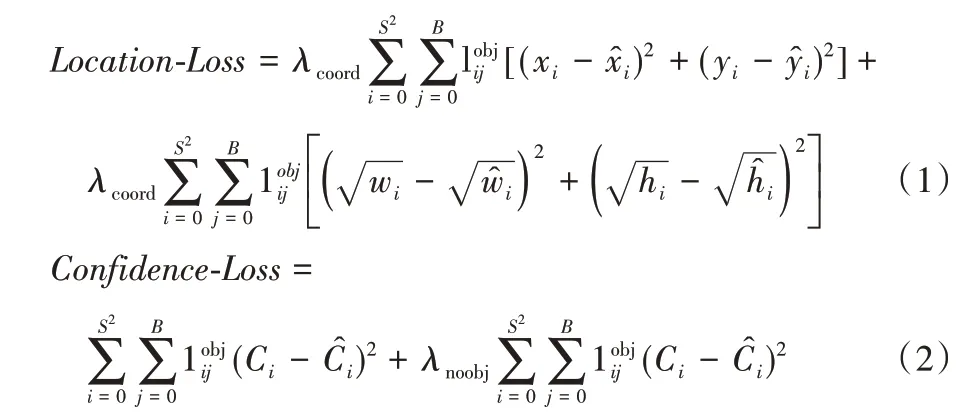
另外,对Location-Loss使用对比度归一化的方法[21]把式(1)中的平方和改为绝对值形式,提高算法的抗干扰性,改进后的Location-Loss′为:
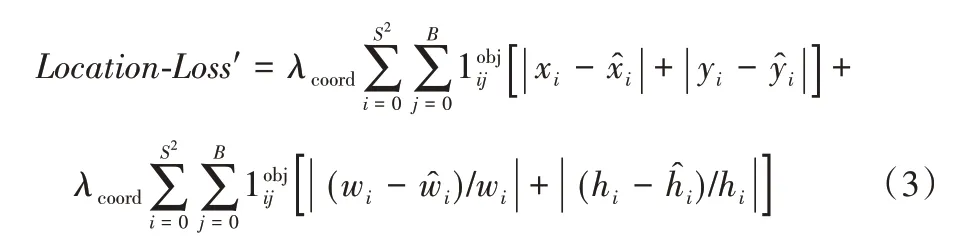
其中:S2表示图像划分的单元格数;B表示每个网格单元生成的预测框个数;表示第i个网格的第j个检测框是否负责检测这个目标物体,如果负责取值1,否则为0;λcoord表示坐标预测误差权重,设为5;λnoobj表示不含对象的置信度误差惩罚权重,设为0.5;xi、yi、wi、hi表示真实框的中心点横纵坐标以及框的宽度和高度,表示预测框的中心点横纵坐标以及框的宽度和高度;Ci表示拟合值、表示真实值,该值由网格的检测框是否负责预测这个对象决定,若负责取值为1,否则取值为0。
1.3 二次识别
基于本文提出的深度卷积模型输出的检测结果是贴合物体外部轮廓的矩形[22],不能精准识别出气门所在的圆形区域;同时,将矩形框对角线的交点作为气门的中心定位点也存在一定误差。因此本文采用霍夫圆变换的方法对输出的结果进行目标定位处理,将气门的中心点(圆心)进行矫正。然而直接使用传统的CHT 在相互遮挡的目标圆检测上表现欠佳,无法适应较复杂的环境,检测精度有待提高。综上,本文提出了二次识别的方法:对于深度卷积网络的检测结果,获取目标的类别和位置信息,然后根据检测结果对图像进行区域截图得到细化框,再对细化框进行CHT 检测得到最终的气门识别结果。二次识别过程的详细步骤如下:
1)取位置坐标:根据本文提出的深度卷积网络得到预测框的位置信息,该位置信息是指预测框的左下角顶点A=(au,av)和右上角顶点B=(bu,bv)的坐标。
2)扩充像素:考虑到个别检测框可能没有完全包裹气门的轮廓,故对A、B两点的值分别扩充5 个像素得到A′=(au-5,av-5)、B′=(bu+5,bv+5)。
3)局部区域截图:根据扩充后的坐标A′、B′在原图上进行截图得到细化框。
4)细化框预处理:①灰度化处理;②中值滤波去噪;③平滑处理。
5)边缘提取:对所得截图用Canny 算法进行边缘提取,得到较完整的圆边缘。
6)霍夫圆变换:使用CHT 进行识别得到检测圆,获取矫正后的圆心定位结果,并输出每个目标的圆心坐标和半径。
1.4 识别区域融合
本文最终输出的是深度卷积网络模型生成的预测框和二次识别生成的检测圆。由于CHT 具有不稳定性,不能保证每个目标都得到有效识别,对于二次识别过程中存在的漏检现象,本文实验以原来的预测框为补充,同时生成带预测框和检测圆的结果。最终的检测结果中若有检测圆则以二次识别的结果为准,否则以深度卷积网络生成的预测框为准,同时返回所有预测框的位置信息以及中心点坐标。
2 实验设计
2.1 实验设置
2.1.1 实验环境
为了更直观地验证本文提出方法的有效性,本文所有的实验均在同一环境下进行。本文应用的硬件和软件配置如下:Ubuntu16.04 操作系统,Intel Core i7-8700 处理器,NVIDA 1080Ti 独立显卡,以及Tensorflow-gpu、Cudn10.0、Cudnn7.4.1.5 库。
2.1.2 参数设置
调整本文提出深度模型的配置文件以及训练过程中的参数:在配置文件中将类别数目class 设为1(本数据集中只有一类),检测头输出的维度层数设为18。在进行训练时,将一次训练所选取的样本数量Batch 设为16,迭代次数epoch设为2 000,学习率设为0.001,动量设为0.9,权重衰减值设为0.000 5。训练集与验证集的划分比例为9∶1。另外,在实验中加入冷冻训练用于通用的主干网络提取特征,加快网络的收敛。
根据数据集的实际情况对二次识别中的参数进行调整:首先将边缘检测Canny 算子中的双阈值分别设为100(大阈值)、50(小阈值);经过分析大量目标预测框的位置信息,得到参数最小的圆半径为100,最大的圆半径为200,两个圆心之间的最小距离为40。
2.1.3 矫正框
本文实验中将CHT 检测到的所有目标以圆心O=(xu,yv)、半径r的形式回归出来,并将原图中的圆形目标物体做最小外接矩形处理得到矫正框,这个矫正框将作为新的预测框。最终返回目标的位置信息即为矫正框的左下角坐标(Eu,Ev)、右上角坐标(Fu,Fv),其计算过程如下:

2.2 数据集
本文实验采用大恒MER-500-14GM 相机实地拍摄的图像作为原始样本,图像的分辨率为2 592×1 944,图像格式为.JPG。将实验数据集中的气门毛胚件码放在带间隙的框架上,气门之间会相互接触,相机装在篮筐上方的安装架上进行拍照取样。本项目分别采集顺光和逆光条件下,不同角度不同摆放位置的气门照片,为了不增加标注负担,这里只取50 张小样本作为原始数据集。
本文实验使用PASCAL VOC2007 数据集格式,对图像使用Labelimg 工具自带的标注框进行手工标注[23],并对目标的标注框类别进行自定义命名。数据集中的气门属于圆形目标,因此对气门命名为circle,标注完一张图中的所有目标即生成了一个对应的xml 文件,对原始的数据集均完成标注后共获得50 个xml 文件。
在完成图像的采集和标注后,实验使用数据增强方法对原始的样本进行1∶50 的扩充,共得到2 500 张的图片以及2 500 个对应的xml 文件。本文实验中只需要较小的数据集就可以达到预期的效果,所以这里只进行一个小规模的扩充。
2.3 对比方法
为了验证本文所提出的方法有利于解决工件气门识别过程中出现的问题,这里使用采集到的图像数据集,同时训练本文提出的模型以及原YOLOv3 模型、YOLOv4 模型。测试集共选取500 张图片,分别使用原YOLOv3、YOLOv4 检测方法和传统的CHT 方法,以及本文所设计的方法对测试集进行测试,将检测结果作为本文的对比实验。
2.4 评价指标
本文选取目标检测方法的精确率(Precision)、召回率(Recall)、交并比(IOU)以及检测精度(Average Precision,AP)多个指标联合评价模型。其中,精确率和召回率的定义为:

以目标气门为例,TP表示被正确识别为气门的样本个数,FP表示被错误识别为气门的样本个数,FN表示未被检测到的样本个数。精确率表示正确识别出目标的检测精度,召回率表示能够正确识别目标的概率。检测框与人工标注框的交并比(IOU)定义为:

其中:Pred指代最终的预测框(矫正框),Truth表示人工标注的真实框。IOU 的值越大,表明预测目标的包裹度越好,检测结果的精度越高。平均检测精度(Mean Average Precision,MAP)的计算过程是通过给定一组IOU 阈值,在每个IOU 阈值下求所有类的精度AP 并将其平均得到,将其作为这个IOU 阈值下的检测性能。而本文检测单一目标,MAP即AP,且本文数据集对检测精度的要求较高,因此本文选取IOU 阈值为0.9 时的AP 作为最终的评价指标,记为AP@0.9。
3 结果分析
3.1 结果展示
为了方便对比,这里采取同一张测试图的检测结果进行对比,各模型结果的展示如图3 所示。从图3 中的方形预测框可以看出,YOLOv4 方法和本文的方法都准确地将框架边角处的两个气门检测出来,而图3(a)中原始的YOLOv3 模型漏检了这两个目标。观察预测框的置信度得分,可以看出图3(b)和图3(d)中正确识别目标的个数相同,但图3(d)中识别出目标的检测精度高于图3(b)中的检测精度,且图3(d)中大部分目标的置信度得分为1,远远高于图3(a)中的目标置信度分数。可见,原YOLOv3 方法对框架边角处的气门存在漏检的情况,而本文的方法可以有效地识别出框架上的目标,且相比原YOLOv3、YOLOv4 模型的检测结果在检测精度上有了进一步提升。接着通过观察CHT 得到的检测圆可知,图3(c)中传统的CHT 检测存在较多的漏检目标,且在检测重叠目标时,只能识别出上方的目标,下方被遮挡的目标并未检测到;而本文的方法可以将相互遮挡下的目标全都识别出来,且针对图中噪声较大的区域也有很好的识别率。通过对比实验的预测结果可以看出,本文提出的基于深度卷积网络与霍夫变换的方法不仅可以有效提高气门识别的精度,还能增强模型的泛化能力。

图3 不同模型结果对比展示Fig.3 Display of different model results comparison
3.2 评价指标对比分析
表1 给出了不同方法进行气门识别的Precision、Recall以及AP 值。从表1 可以看出,在精确率方面,原YOLOv3 方法的精确率为94.2%,YOLOv4 检测方法的精确率为96.9%,本文方法的精确率为97.1%,相较原YOLOv3 方法和YOLOv4 方法分别提高了2.9 个百分点和0.2 个百分点;在召回率方面,本文方法召回率为94.4%,与YOLOv4 方法相同,相较原YOLOv3 方法提高了1.8 个百分点;在IOU 阈值为0.9时的检测精度上,原YOLOv3 方法的AP 为76.5%,YOLOv4方法的AP 为81.4%,而本文方法的AP 为88.3%,相较原YOLOv3 方法和YOLOv4 方法分别提高了11.8 个百分点和6.9 个百分点。传统CHT 在精确率和召回率方面均低于其他三个目标检测方法,而在阈值为0.9 的检测精度上均高于YOLOv3 和YOLOv4 方法,本文方法与传统CHT 相比在AP 上提高了3.5 个百分点,另外在精确率和召回率方面也分别提高了11.8 个百分点和13.7 个百分点。
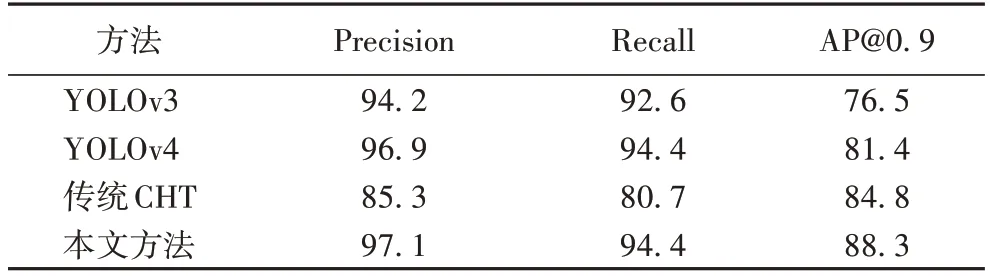
表1 不同目标检测方法性能对比 单位:%Tab.1 Performance comparison of different target detection methods unit:%
从图3 中目标气门的包裹度可以看出,图3(a)中预测框的包裹性最差,图3(b)其次,图3(c)和图3(d)不相上下。为了进一步验证本文目标检测结果的定位精度,这里将各方法得到的IOU 值进行对比,根据原500 张图像的测试集中的目标进行计算,结果如表2 所示。
表2 展示了不同方法的IOU 值。从表2 中可以看出,本文方法相较原YOLOv3、YOLOv4 方法的IOU 值分别提高了0.17 和0.09;传统CHT 的IOU 值为0.90,本文方法的IOU 值0.95,相较传统CHT 又提高了0.05。可见,与单独使用深度学习的目标检测方法相比,本文基于深度卷积网络与霍夫变换的方法得到的检测框与真实框的交并比更高,目标包裹度更好,目标中心点的定位更准确。

表2 交并比计算结果Tab.2 Calculation results of IOU
各目标检测方法的检测速率结果如表3 所示。从表3 中可以看出,本文方法在检测速率上相较YOLOv4 方法和传统的CHT 分别提高了2.2 frame/s 和6.6 frame/s,但低于原YOLOv3 方法。

表3 检测速率结果Tab.3 Detection rate results
4 结语
本文提出了一种基于双重检测的气门识别方法,旨在解决工业上气门识别任务中存在的检测精度较低、重叠目标漏检率高以及目标包裹度差、圆心定位不准的问题。通过将YOLOv3、YOLOv4、传统的CHT 方法与本文方法进行气门检测效果的对比,实验结果表明,本文提出的方法在检测精度上达到了97.1%,在召回率上达到了94.4%,与原YOLOv3 方法相比,在精度和召回率上分别提高了2.9 个百分点和1.8个百分点;且该方法使目标中心点的定位更准确,其矫正框和真实框的交并比达到了0.95,与传统CHT 相比提高了0.05。本文通过优化深度网络卷积结构并结合霍夫圆变换检测的方法,使其在目标相互遮挡、背景复杂度较高的情况下具有较好的鲁棒性,相较单一检测方法有效提高了模型识别的准确率,增强了圆心的定位精度以及目标的包裹程度,基本满足了工业上气门识别过程中的需求。本文实验中为了使目标检测的定位更准确而牺牲了部分检测速度,与达到实时的气门检测还存在一定的差距,未来可以在检测速度上进行改进以达到实际应用中的速率要求。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
汽车与新动力(2019年5期)2019-11-07 05:20:54
电子制作(2019年11期)2019-07-04 00:34:38
电子制作(2018年11期)2018-08-04 03:25:38
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
测绘科学与工程(2016年5期)2016-04-17 06:51:15
电子设计工程(2015年3期)2015-02-27 12:03:45
农机使用与维修(2014年6期)2014-09-23 01:37:32
河北农机(2014年2期)2014-03-30 00:38:54
电视技术(2014年19期)2014-03-11 15:38:20
