
融合XGBoost和Multi-GRU的数据中心服务器能耗优化算法
2022-02-26 06:58:26申明尧杜诗语张春砚
计算机应用 2022年1期
申明尧,韩 萌,杜诗语,孙 蕊,张春砚
(北方民族大学计算机科学与工程学院,银川 750021)
0 引言
近年来,云计算技术飞速发展,正逐渐被应用于各种计算环境之中。作为计算、存储和各种服务的提供商,数据中心在其中扮演着至关重要的角色。早在2010 年,执行互联网应用的数据中心已经消耗了全球1.3%的能源,当时预计到2020 年年底,这一比例将提升至8%左右[1]。2017 年我国数据中心的耗电量为1 200 亿千瓦时,约占全社会总耗电量的2%[2]。2018 年,我国数据中心的用电量为1 608.89 亿千瓦时,占全社会总用电量的2.35%。预计到2023 年,全国数据中心的总用电量将达到或超过2 660 亿千瓦时[3]。
观察组治疗后显效20例,有效10例,无效1例,治疗总有效率为96.77%;对照组治疗后显效15例,有效9例,无效6例,治疗总有效率为80.00%,观察组治疗总有效率高于对照组(P<0.05)。
为了保证数据中心的可靠性,通常会有大量的冗余服务器。同时,数据中心服务器的使用也有类似的周期性,但是能耗总是相对恒定的,这导致了巨大的能耗浪费[4]。
对于数据中心,能耗主要来源于以下几个方面[5],如表1所示。最常见的是计算设备,包括服务器、交换机和路由器等。同时,为了保护设备,数据中心还配备了空调和制冷系统,它们也有一定的能耗。此外,变压器、不间断电源供电系统和照明设备等也有少量的能耗。
教育学家杜威说,学校首要责任是给孩子提供一个简化的环境,以排除社会环境中丑陋现象对儿童的影响。面对社会功利化的竞争环境,家庭和学校更应当正确引导孩子的竞争意识。儿童的价值体系还没有健全,对于竞争概念的判断不清晰,所谓的竞争意识也是我们强加给孩子的,如果因为“比较”、因为“竞争”,他们心里容不下比自己强的伙伴,这算不算一种心理缺失?
多层感知机也称人工神经网络(Artificial Neural Network,ANN)[19],它是一种具有迭代训练方法的前馈监督学习神经网络。MLP 包含输入层、输出层和隐藏层,其中输入层和输出层分别各一个,隐藏层可有一个或多个。每一层都包含多个神经元,每层的各个神经元都与下一层的神经元高度互联,即上一层的任何一个神经元与下一层的所有神经元相连接,然后通过加权的方式建立起一种能够学习变量集之间关系的结构。

表1 数据中心能耗构成Tab.1 Composition of data center energy consumption
针对这一现象,研究者们从不同角度对能耗问题进行了大量的研究。首先,在建立能耗预测模型方面,Lin 等[7]提出了一种计算机服务器关键部件(CPU、内存和磁盘)能耗的建模方法,揭示了关键部件的资源使用与系统能耗之间的数学关系。所提出的分布式电能表(Distributed Energy Meter,DEM)系统不仅能够估计异构集群环境(Linux 和Windows NT)的能耗,而且能够支持各种CPU 功耗模型。Liang 等[8]提出了一种基于多能源相关特性的能耗方法,该方法筛选出CPU 利用率、内存使用量等12 个与能量相关的关键特征,并使用深度神经网络模型进行训练,来预测数据中心的能源消耗。Diouani 等[9]根据多种模型、计算公式、算法、技术中的虚拟机伸缩、虚拟机CPU 和内存大小的调整、CPU 频率调整以及服务器级资源分配的设备功率控制等推导出了一个简化和完整的能耗估算公式以降低能耗。
随后,研究者们对数据中心的节能目标展开了研究。Stamatescu 等[10]将数据中心所需资源不同自由度的问题考虑为一个混合整数线性规划问题,提出了一种数据中心能耗优化算法。该算法通过将虚拟机分配给物理服务器来降低数据中心能耗,并将其中的传递函数、约束函数和目标函数都以线性形式表达,减少了计算时间。Yadav 等[11]提出了一种自适应启发式算法,即用于检测过载主机的最小二乘回归算法和用于从过载主机中选择虚拟机的最小利用率预测算法,其中虚拟机选择算法考虑了不同时间段虚拟机上运行的应用类型和它的CPU 利用率,该启发式算法以最小的服务级别协议(Service Level Agreement,SLA)降低了数据中心的能耗。Mahjoub 等[12]定义了一个资源管理策略,该策略实现了从过度使用的服务器到未使用的服务器之间的任务迁移。该策略的优点是平衡了负荷,降低了能耗。由于在执行进程时,虚拟机可以从主机服务器迁移到客户服务器,Duolikun等[13]提出了一种基于能量感知的虚拟机迁移算法,虚拟机上的进程可以迁移到消耗更少电能的客户服务器,并且可以在集群中高效地执行。Song 等[14]提出了一种名为C2vmMap的虚拟机迁移模型,它基于计算和冷却能耗之间的有效权衡,将冷却能耗考虑其中,可以最大限度地降低总能耗,以减少运行时数据中心的总能耗。Choi[15]提出了通过虚拟化技术整合服务器,即在每台服务器上运行多个虚拟机满足用户和服务的需要,这样可以减少运行服务器的数量,以此来实现云数据中心服务器的节能。但是,虚拟机并不是全天候运行,亦会有空闲的时候,也会造成资源的浪费。
本节从参数确定和实验结果对比的角度对Multi-GRU 模型的实验结果进行分析。
通过对以上研究的分析发现,当服务器处于低利用率阶段,即服务器空闲时,服务器中的各部件仍然以较高的频率运行,此时服务器具有较大的电能消耗。因此,本文针对数据中心服务器的高能耗、低利用率问题,设计了一种具有多个门控循环单元(Gated Recurrent Unit,GRU)[16]的循环神经网络结构Multi-GRU,并在此基础上提出了一种融合极限梯度提升(eXtreme Gradient Boosting,XGBoost)[17]和Multi-GRU的数据中心服务器能耗优化(data center servers Energy Consumption Optimization combining XGBoost and Multi-GRU,ECOXG)算法。首先,使用Linux 终端监控命令收集不同负载下服务器的CPU、内存、磁盘和网络带宽等部件的资源利用率,同时使用功耗仪收集同一时刻的服务器能耗,并对其进行预处理;其次,利用服务器各部件的资源利用率数据(即负载)训练Multi-GRU 负载预测模型,并根据Multi-GRU 模型的预测结果对服务器进行模拟降频,得到降频后的负载数据;然后,再次利用服务器的资源利用率数据,并结合同一时刻的能耗数据训练XGBoost 能耗预测模型;最后,将降频后的负载数据输入到XGBoost 模型中,预测出降频后的服务器能耗,与真实能耗作对比,实现数据中心服务器的节能效果。实验结果表明,与传统算法相比,本文提出的算法在误差和预测效率上有一定的优势。
1 相关工作
本章详细介绍了常见的回归模型、负载模型和常用的模拟降频方法,并对各个模型在具体研究中的应用作了详细描述。
1.1 回归模型
回归模型是对统计关系进行抽象化描述的一种数学模型,它通过特定的数学公式来确定因变量与某些自变量的相关关系,建立一个相关性较好的回归方程。常用的回归模型有支持向量回归(Support Vector Regression,SVR)[18]和多层感知机(MultiLayer Perceptron,MLP)[19]。
支持向量机(Support Vector Machine,SVM)[20]是用于分类和回归分析数据的模型。当模型应用于连续值时,通常使用SVR。SVR 与其他预测连续变量的方法不同,它在引入以前未见过的数据时表现出高度的泛化能力。支持向量回归机也能够通过仅依赖于被称为支持向量的训练观察的子集来实现高度的一致性。
由表1 可得,现有数据中心的能耗主要集中在计算设备和冷却系统上,数据中心服务器在执行任务时消耗的能量最多,约占总能耗的40%。然而,现有数据中心的资源利用率不到30%[6]。计算任务随机出现,有时是突发的。当传入的任务很少时,许多服务器便处于空闲状态。2007 年,谷歌的一份报告指出,其数据中心的服务器在整体上平均资源利用率较低,其数值在10%~50%,但是数据中心的冷却能耗费用占总运营成本的40%~70%,呈现出高能耗、低利用率的浪费现象。实际上,全球数据中心具有相同的特性,即大都呈现出高能耗、低利用率的问题。
近年来,支持向量回归算法已被国内外的研究者们应用于科研和日常生活中的各个领域。在建筑能耗预测方面,Ma 等[21]提出了一种支持向量回归的方法预测华南地区的建筑能耗,将天气数据和经济因素等多个参数作为输入,并采用基于径向基函数核的网格搜索k重交叉验证方法对模型进行训练,提高了模型的性能。同时,Guo 等[22]通过比较随机森林回归、梯度推进回归和支持向量回归三种回归方法,确定了一种支持向量回归的混合模型。该模型将40 个气象因素作为输入变量,以建筑中消耗的电量作为目标变量进行研究,并证实了其优越性。此外,研究者们还对SVR 进行改进和变种。Liu 等[23]将建筑能耗数据视为一个时间序列,并采用一种支持向量回归和经验模态分解相结合的方式,对建筑能耗进行预测。经验模态分解方法将非平稳非线性的能耗时间序列分解成多个固有模态函数,然后利用支持向量回归对分解后的时间序列进行预测,每个预测子序列之和即为最终预测结果。在碳排放预测方面,Gou[24]利用SVR 在碳排放预测中的优势,建立了基于SVR 的碳排放预测模型,使用河南省1991—2016 年的碳排放数据和影响因素对模型进行训练,并根据模型对2017—2021 年的碳排放进行预测。在钢铁行业中,Huang 等[25]将自适应状态转换算法(Adaptive State Transition Algorithm,ASTA)与混合支持向量回归(Hybrid Support Vector Regression,HSVR)相结合进行建模,并对有色冶金行业的能源消耗进行预测。在该模型中,HSVR 是由ε-SVR 和ν-SVR 两种模型进行线性加权而组成。同时,在状态转移算法的基础上,提出了一种ASTA 对HSVR的参数进行优化。该模型在中国有色冶金行业的两个能耗案例中均表现出较优的性能。
多层感知机作为一种最简单的神经网络算法,无论在精度和效率上均受到了学术界和工业界的青睐。Ilbeigi 等[26]设计了一种使用多层感知器模型创建、训练和测试鲁棒的人工神经网络,用来模拟建筑物中的能耗。该模型创建、训练和使用大量人工神经网络子模型来计算当前建筑物所需的能源,然后进行综合敏感度分析来评估输入因素对能源使用的影响,并通过使用人工神经网络来找到对能源消耗最有效的因素,最后通过人员数量和与墙体保温相关的墙体U值等参数来 优化模 型。Vergara 等[27]将MLP 与极限 学习机(Extreme Learning Machine,ELM)两种算法应用于建筑的能耗预测,并利用主成分分析法对建筑进行能耗分割。对比两种算法,MLP 获得了较小的误差。Zeng 等[28]开发了一种基于两层MLP 的人工神经网络模型,该模型通过试错法逐步优化每个模型的隐含层、神经元数量、激活函数和训练算法来预测驱动油泵管道的日耗电量。在实际数据的验证中,所提出的MLP 神经网络模型不仅在批量调度和泵送操作的有效评估中有较好的表现,而且在能耗目标设定中也有很好的性能。此外,MLP 在其他领域也有较好的性能表现。Dai等[29]针对质子交换膜燃料电池的寿命预测问题,提出了一种基于MLP 和局部加权散点图平滑的方法,对电池的寿命进行预测。该方法对法国燃料电池实验室(Fuel Cell LABoratory,FCLAB)研究联合会提供的数据进行重构,并输入到算法模型中进行预测。实验结果表明,与其他算法相比,该算法具有最高的准确率。
1.2 负载预测模型
近年来,随着云计算技术的快速发展,数据中心的规模不断增长,能耗问题变得非常重要。为了解决这一问题,一个有效的方法是提高数据中心的资源利用率[30]。研究人员发现,准确的负载预测能够帮助服务器提前感知下一时刻的状态,以此做出相应的操作,从而提高资源利用率,降低能耗。随着计算机技术的普及和发展,深度学习算法已经逐步应用于日常生活,神经网络在负载预测方面表现出很好的性能。Kollia 等[31]开发了一种基于深度卷积神经网络(Convolutional Neural Network,CNN)-循环神 经网络(Recurrent Neural Network,RNN)的深度学习框架,用于评估实际电力负载需求的短期预测,并分别对现实生活中的时间序列数据和二维信息数据进行算法验证,提高了预测的准确性。Zheng 等[32]提出了一种基于GRU 的住宅小区短期负荷预测方法,并采用最小绝对收缩选择算子(Least absolute shrinkage and selection operator,Lasso)和偏相关分析方法,分析了温度、湿度、降雨量和风速对负载的影响,取得了较好的性能。Bouktif 等[33]使用了一种基于长短期记忆(Long Short-Term Memory,LSTM)网络和元启发式搜索的算法对短期电力负载进行预测,通过遗传算法和粒子群优化算法来学习LSTM 模型中的超参数,以此提高精度。Inteha 等[34]基于短期负载预测的时间滞后性特征,提出了一种遗传算法(Genetic Algorithm,GA)和GRU 网络的集成模型,该模型使用遗传算法微调GRU 网络中的两个超参数——时滞和神经元的数量,使算法模型达到最优;同时,使用孟加拉国的电力负荷数据对模型进行评估,与其他算法相比,该模型的均方根误差(Root Mean Square Error,RMSE)和平均绝对百分比误差(Mean Absolute Percentage Error,MAPE)均显著降低。
此外,国内研究者们也进行了大量的研究。陆继翔等[35]针对负载数据的时序性和非线性的特点提出了一种基于CNN-LSTM 的混合网络模型,该模型采用CNN 提取数据特征向量,将特征向量以时间序列的方式构造数据集,作为LSTM网络的输入数据,最后再采用LSTM 网络进行短期负载预测。赵兵等[36]针对现有方法中存在的难以有效提取历史数据中潜在高维特征且当时序过长时重要信息易丢失的问题,提出了一种基于Attention 机制的CNN-GRU 网络的短期负载预测方法。该方法同样将从CNN 模型中提取出的特征向量输入到GRU 网络中,此时为了减少历史数据信息的丢失和加强对重要信息的关注,引入Attention 机制对GRU 网络的隐藏层赋予不同的权重,完成负载的预测。
1.3 模拟降频
数据中心服务器的能耗主要是由处理器(CPU)、内存、磁盘、网卡等部件的能耗组合而成,因此服务器的能耗可以进一步由式(1)表示为:

其中Pcomponenti表示第i个部件的能耗。因此,服务器的能耗优化问题可转化为各个部件的能耗优化问题,而降频是其中最有效的方法之一。
在Linux 系统中,内核的开发者们开发了一套CPU 频率动态调整的框架——CPUFreq(CPU Frequency)系统[37]。在Linux 的各个发行版本中,尽管前端软件稍有差异,但最终其都会通过Linux 内核的CPUFreq 系统来实现CPU 频率的动态调整。此外,在市面上还有很多关于调整内存、网卡等系统部件频率的工具,如串行存在检测工具(Serial Presence Detect Tool,SPDTool)、ethtool 等,数据中心管理人员可使用上述系统或工具对系统部件进行相关操作。
2 ECOXG算法
本章从算法模型、算法原理和算法流程等角度详细介绍了ECOXG 算法。
2.1 关键技术
本节详细描述了ECOXG 算法中所使用到的XGBoost 模型和GRU 模型,并对其中的原理进行简要概述。
由表3可以看出,改性沥青薄膜老化后针入度比值为68.3%,比原基质沥青薄膜老化后的针入度比63.6%有加大幅度的提高,表明沥青添加剂掺入,改性沥青的热稳定性得到改善。
2)评价指标。
采用SPSS 20.0统计学软件对数据分析。计数资料采用[n(%)]表示,行 χ2检验,计量资料采用(±s)表示,行t检验,P<0.05为差异有统计学意义。
XGBoost 是Boosting 算法其中的一种,Boosting 算法的思想是将许多弱分类器集成在一起,形成一个强分类器。因此XGBoost 是一种提升树模型,它将许多树模型集成起来,然后将每轮训练得到的弱分类器(树)加权求和得到最终的分类器。因此,模型的目标函数如式(2)、(3)所示:
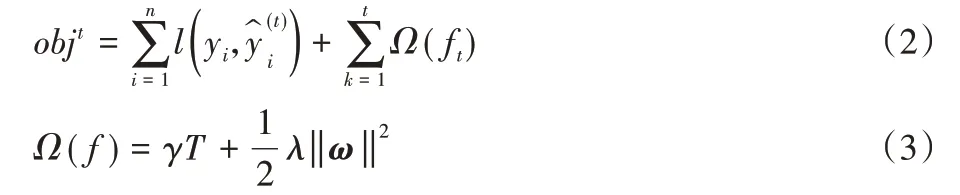
XGBoost 是相当成熟的基于梯度提升决策树(Gradient Boosting Decision Tree,GBDT)的机器学习范例。它是一个大规模的分布式梯度提升库,实现了寻找近似分裂点并允许并行计算的GBDT 算法。本节主要运用XGBoost 中的回归树模型,根据服务器的资源利用率实现对服务器能耗的回归预测。
2)GRU模型。
GRU 与长短期记忆(LSTM)网络都是循环神经网络的一种。LSTM 能够捕获与时间序列相关的长期依赖关系,但内部结构相对复杂,使得模型训练时间较长。其中,GRU 是LSTM 的一个特例,它对其进行了改进,在预测精度不变的同时,减少了参数的数量[38]。GRU 对LSTM 的3 个门函数进行优化,将遗忘门和输入门集成为单一的更新门[39]。与LSTM相比,GRU 模型的参数更少,收敛速度更快。更新门控制上一时刻的状态保留到当前状态中的程度,值越大表示上一时刻的状态信息保留越多;重置门控制当前状态与先前信息结合的程度,值越小说明忽略的信息越多。GRU 模型的结构如图1 所示。
2.缺乏系统的制度管理工作。内部控制建设成果的表现之一就是固化的管理制度,系统化的管理体系有利于建立高效的内部控制体系。我国公立医院虽然建立了许多适合医院经营的制度,但是建立的制度缺乏系统化的管理。医院各部门权责不明,各部门之间的协作性不高,部门的效率低。缺少制度化、系统化的制度管理部门,制度缺乏严谨性,不利于科学化、系统化的内部控制体系建设。
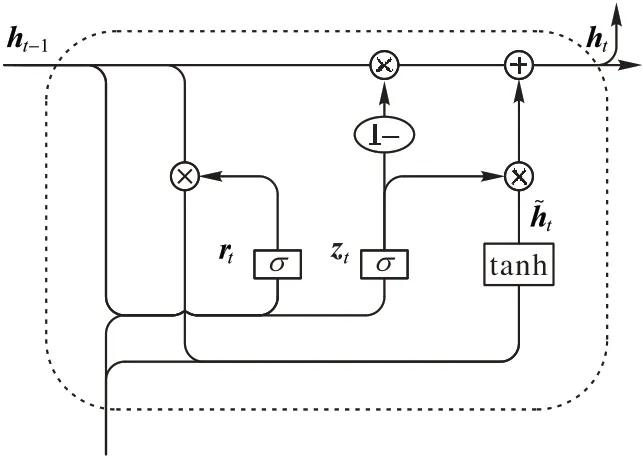
图1 GRU模型的结构Fig.1 GRU model structure
在图1 中,箭头的方向为数据输入的方向,其中,×为矩阵数乘,σ为Sigmoid 激活函数,tanh 也为激活函数,1-表示经过该路径的数据为1-zt。σ和tanh 的计算公式如式(4)、(5)所示:
结 合 W1、W2、W3及 3 个 子 系 统权重 w=[0.42,0.29,0.29], 利用公 式(1)求得相应的欧式贴近度,如图1。

图1 中,更新门和重置门分别为zt和rt,xt为输入,ht为隐藏层的输出。GRU 网络的前向传播公式如式(6)~(10)所示:

其中:xt为当前时刻的输入向量,rt、zt分别为重置门和更新门,ht-1为上一时刻的隐藏状态分别为当前时刻的隐藏状态和当前时刻候选的隐藏状态,yt为当前时刻的输出向量;Wr、Wz分别为重置门、更新门的权重矩阵,为当前时刻候选状态的权重矩阵,Wo为输出向量与当前时刻隐藏状态的权重矩阵;[]表示向量连接;“·”表示矩阵点乘;“*”表示矩阵乘积。
当算法和数据与所有公司标配时,只有创意和设计才能更好地适应这个时代。设计力是用户角度的审美策划,是新技术的整合,以流量人格化的模式,构建商业设计能力。
2.2 ECOXG算法描述
实验使用Linux 终端命令dstat、sar 等收集CPU、内存、磁盘和网络等系统部件的资源利用率数据,并使用Wondershaper、Netperf、IOzone、Memtester 等测试工具增加服务器的负载,能够全面覆盖服务器各功能部件,使其资源利用率呈现波动趋势,提高模型的预测精度。
由于服务器负载数据呈现时序性的特征,且GRU 模型在时序数据中具有良好的预测效果,因此本文设计了一种Multi-GRU 网络结构,可对时间序列负载数据进行预测。其中,每层的GRU 网络模型是以时间序列特征图作为输入,为了提高模型的精度,滑动窗口宽设为720 条记录,步长设为1,单位特征图的尺寸为720×4,输入的特征图也按时间序列排列。在Multi-GRU 网络模型中,由于输入数据维度较低,因此在GRU 层前加入一层全连接层来扩充数据特征。然后通过Multi-GRU 三层网络提取输入的负载时间序列并学习负载时间序列内部的潜在变化规律以实现预测负载的功能。最后通过全连接层输出与原始数据相同维度的预测结果,得到服务器的负载预测数据。Multi-GRU 网络的基本结构如图2 所示。
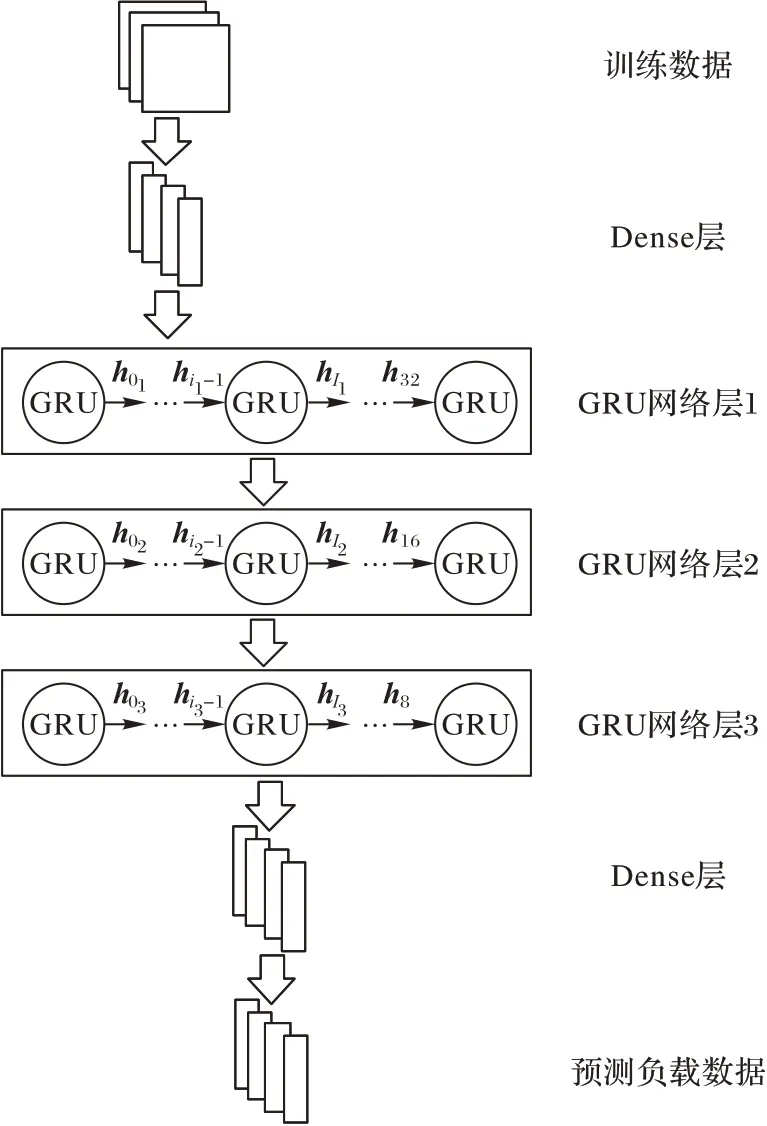
图2 Multi-GRU网络结构Fig.2 Multi-GRU network structure
此外,由于能耗数据呈现出非线性的特征,且能耗预测属于回归问题,而XGBoost 中的回归树模型在非线性回归问题中具有较高的精度和较快的速度,因此,ECOXG 算法首先通过XGBoost 算法估算服务器单机能耗。该算法将收集到的服务器资源利用率作为能耗因子,同时将功耗仪实测功耗数据作为标签,训练XGBoost 回归模型,使其作为模拟功耗仪以供后期使用。同时,由于服务器资源利用率和功耗仪实测数据是相互独立的时间序列,因此为了耦合这些特征数据对于服务器负载的影响,参照自然语言处理(Natural Language Processing,NLP)中的词向量表示方法,对于某一时刻的负载数据由与其相关的特征串联成向量表示,进而构造成一个时间序列。然后,再使用滑动窗口的方法依次将构造的时间序列数据生成特征图输入到Multi-GRU 模型中,对负载进行预测。
在Multi-GRU 模型负载预测过程中,算法将CPU、内存、磁盘和网络等资源利用率数据输入到Multi-GRU 模型中,然后经过各个神经元的计算和模型的迭代,可预测出下一时刻的资源利用率数据,以供判断是否进行模拟降频和XGBoost模型预测能耗使用。在XGBoost 模型预测能耗过程中,算法将Multi-GRU 模型预测到的CPU、内存、磁盘和网络等资源利用率数据作为能耗因子进行回归预测,预测出模拟降频后的服务器能耗数据。
ECOXG 算法的整体流程如图3 所示,分为三部分:Multi-GRU 模型训练流程、XGBoost 模型训练流程和ECOXG 算法总流程。其中,图3(a)为Multi-GRU 模型的训练流程,模型首先将Linux 终端监控命令收集到的服务器CPU 利用率、内存利用率、磁盘利用率和网络带宽利用率等系统负载数据进行数据预处理,然后输入到Multi-GRU 模型中进行模型训练,经过一定的迭代次数后得到基于时间序列的Multi-GRU负载回归模型。图3(c)为XGBoost 模型的训练流程,XGBoost 模型首先将系统负载数据与功耗仪收集到的服务器实时能耗数据进行数据预处理,然后输入到XGBoost 模型中进行模型训练,并通过GridSearchCV 网格搜索法对模型的参数进行调整,得到XGBoost 能耗回归模型。图3(b)为ECOXG 算法的总流程,这是算法整体的设计思路。ECOXG算法首先将处理好的真实数据输入到图3(a)训练好的Multi-GRU 模型中,预测出下一时间序列的负载数据,其次根据值的大小对服务器进行模拟降频。具体降频方式如下:首先判断是否低于30%(经实验验证为30%时在满足服务等级协议的条件下能耗降幅最大),若不低于30%,保持负载数据不变;若低于30%,则将降低为原来的50%,以此来模拟降频。然后将模拟降频后的数据输入到图3(c)训练好的XGBoost 模型中,预测出降频后的服务器能耗值。最后,将降频后的能耗值与原始能耗值进行对比,计算二者之间的差值,实现数据中心服务器能耗的下降。
我国外贸企业产品在国际市场销售中,没有获得消费者的喜爱,从产品质量、品牌、企业服务等各方面都没有拥有很好的竞争力。尤其在网络技术日渐发展的当前时代,商场自建方面呈现不足,很多传统外贸企业或者没有自己的网站,或者有自己的网站,但是网站建设存在极大问题,其中的重要产品都没有能够很好予以展示,产品的质量、品牌都没有让客户予以全面认识,很多对产品有所需要的客户都无法从网站中获得更好的产品选择。部分外贸企业通过第三方平台方式进行产品宣传,但是极容易受到第三方平台的控制和限制,对于跨境产品宣传出售产生阻碍限制。
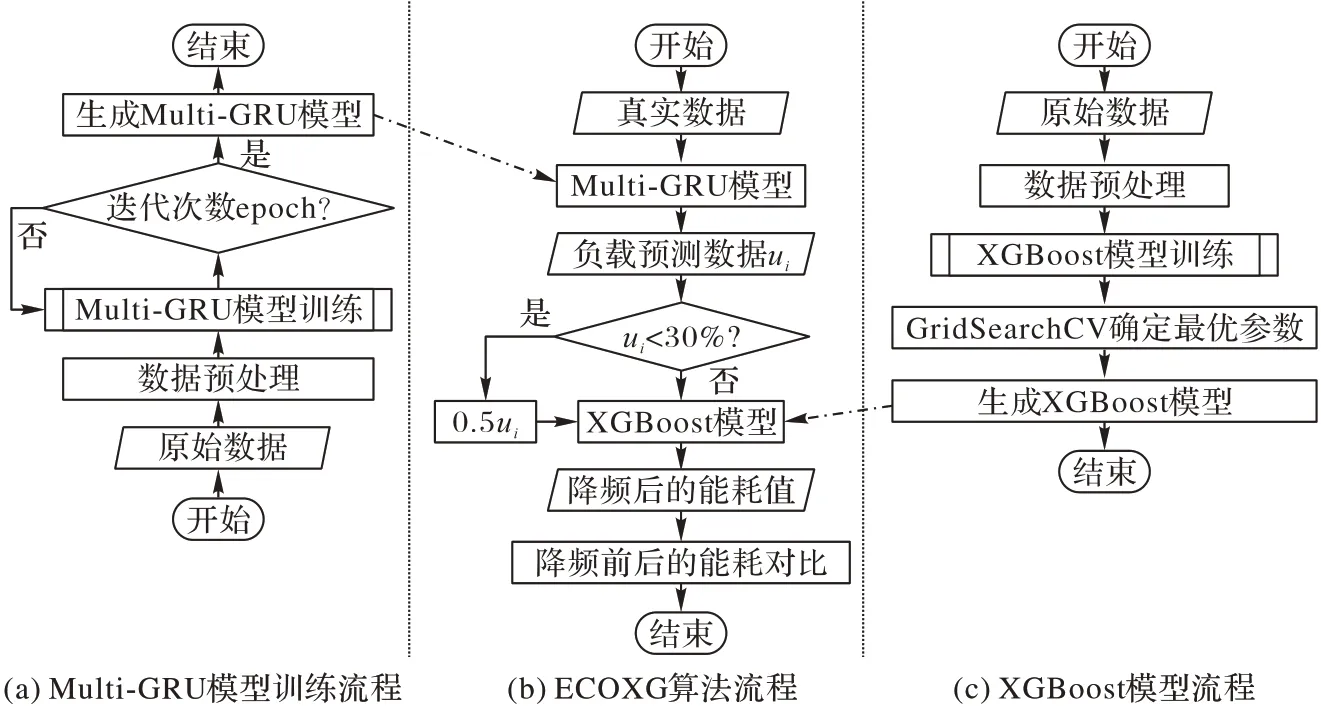
图3 ECOXG算法整体流程Fig.3 Overall flowchart of ECOXG algorithm
XGBoost 算法模型训练的过程中,使用sklearn 中的GridSearchCV 网格搜索方法对模型中的超参数进行选择。根据最低均方误差的得分标准确定以下超参数组合,如表2所示。

表2 XGBoost参数Tab.2 XGBoost parameters
Multi-GRU 网络模型训练的过程中,经过实验发现,通过增加一定数量GRU 单元的层数有助于提高模型的预测精度,但是当层数超过一定的数量时,模型会发生过拟合现象,本文将在第3 章中详细讨论。因此本节使用了3 层GRU 网络层,各层的神经元数量分别为32、16 和8。同时,中间神经元采用丢弃率为0.2 的Dropout 方法以防止模型过拟合。两层Dense 层所用的神经元数量分别为64 和4。模型中用到的所有神经网络层均采用ReLU 作为激活函数。此外,通过调整学习率的大小,以确定使模型的结构学习效能最大化的学习率系数learning_rate。
3 实验与结果分析
为验证本文算法的科学性和准确性,本章收集6 台物理服务器的实际资源利用率分别作为能耗因子与负载数据,并使用功耗仪实际测量服务器的能耗值构建数据集。使用所提算法进行训练,将实验结果与系统条件下的其他模型结果进行对比可知,本文所提算法取得了较好的预测性能。
3.1 数据收集与归一化
本节设计了一种Multi-GRU 结构,并提出了融合XGBoost 与Multi-GRU 的数据中心服务器能耗优化算法ECOXG,适用于数据中心服务器能耗优化问题。
本文对不同负载下的服务器进行监控,并每5 s 收集一次服务器资源利用率数据,为防止偶然性,将对服务器增加两轮负载,共收集38 500 s 的数据,即7 700 条数据。数据集按照7∶3 的比例将其划分为训练集和测试集,其中,训练集为5 390 条数据,测试集为2 310 条数据。为防止数据发生数据穿越现象,本文对相邻两条数据进行依次遍历对比,若数据相等,则取前面的数据;若不等,便对比下一条,以此类推。
此外,为了更好地训练模型,实验对收集到的原始数据均采用Min-Max 标准化方法将其归一化在[0,1]区间,具体转换函数如式(11)所示:

其中:x*为标准化后的值;x为原始数据;xmax为样本数据中的最大值;xmin为样本数据中的最小值。
(1)矿山表层存在着严重的损害现象。作为矿区基本的土地利用类型,林地的经营发展有着较强的特殊性,目前林地管理主要采用集体管理模式。矿山区域内,有矸石堆积区、工人生活区以及开采区,在这些区域进行建设时,往往会破坏原有地面上的植被与地质。同时,采矿工作中会对地质结构产生较大的扰动,进而加剧土地资源与地质结构的破坏。
3.2 实验设计
本节详细介绍了实验的硬件环境配置和实验中所用到的评价指标。
3.3.1 XGBoost模型结果分析
试验设在庆阳市西峰区彭原镇周寨村白咀组,N 35°39′885″、E107°40′832″,海拔 1346m,年平均气温10℃左右,无霜期160~180 d,年降水量400~600mm。试验地块地势平坦,不具备灌溉条件,土壤肥力中等偏高,前茬作物为玉米。土壤类型为黑垆土,有机质含量为23.1g/kg、有效磷含量为24.1mg/kg、速效钾含量为168mg/kg、缓效钾含量为1213mg/kg、全氮含量为0.85g/kg、碱解氮含量为63.3mg/kg。
实验选取6 台金品KU2455 服务器作为数据中心服务器节点,1 台HP 服务器作为数据中心终端节点,服务器节点配置详细参数如表3 所示。
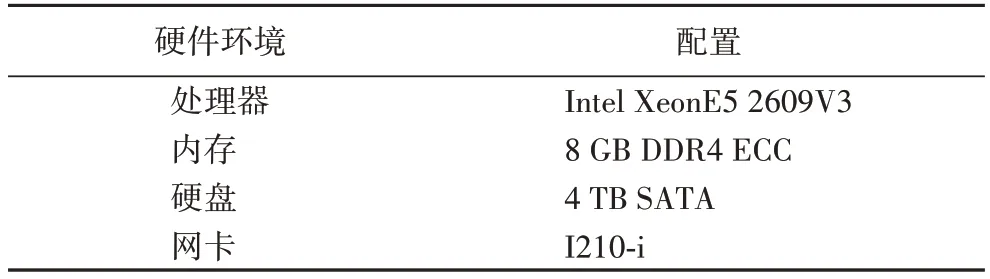
表3 服务器节点配置参数Tab.3 Server node configuration parameters
此外,本实验使用青智8788 功耗仪对服务器进行实时功耗收集。通过将其探头接入服务器电源线,获取服务器的实时电流输入值。同时运行外部监控程序,通过RS232 串口线连接至终端节点,实时读取功耗仪的输出,并保存在MySQL 数据库中进行处理。
对患者进行病史询问,并及时应用床头心电图检查,急诊心梗三联、D-二聚体、胸部X线及心超等检查,早期筛选病情危重患者,并及时分诊,进行有效救助。
1)XGBoost 模型。
为了分别评估XGBoost 模型和Multi-GRU 模型的性能,算法模型选取均方根误差(RMSE)和平均绝对值误差(Mean Absolute Error,MAE)两项指标作为损失函数,其表达式如式(12)、(13)所示:
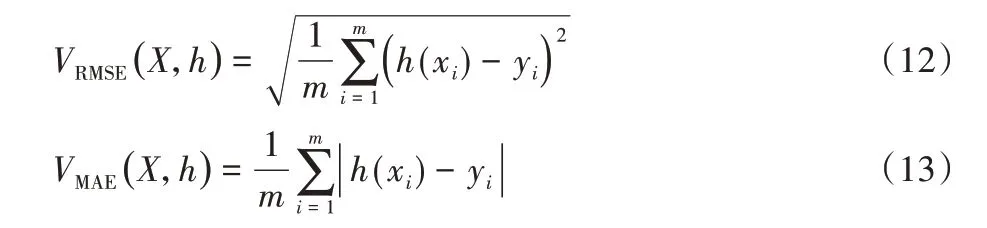
其中:m为样本个数,h(xi)为算法的输出值,yi为样本的实际值。此外,选取Adam 梯度下降法对Multi-GRU 模型的参数进行优化。
3.3 实验结果分析
1)实验环境。
实验采用控制变量法与GridSearchCV 网格搜索法对模型进行逐步调优,通过不断改变参数的取值范围和增加参数的数量来测试模型的性能,最终确定了表1 所示的参数取值,此时模型达到最优的效果。此外,当模型预测精度较高时,可以准确预测出当前服务器的能耗,对能耗的下降有更为直观的显示。在能耗数据集上,本节所用的XGBoost 模型的预测结果均优于其他方法,其中RMSE 为8.25,比第二小的CNN 模型低3.38,预测精度提高了29%;MAE 为6.65,比第二小的CNN 模型低7.94,预测精度提高了54%。具体数据如表4 所示。
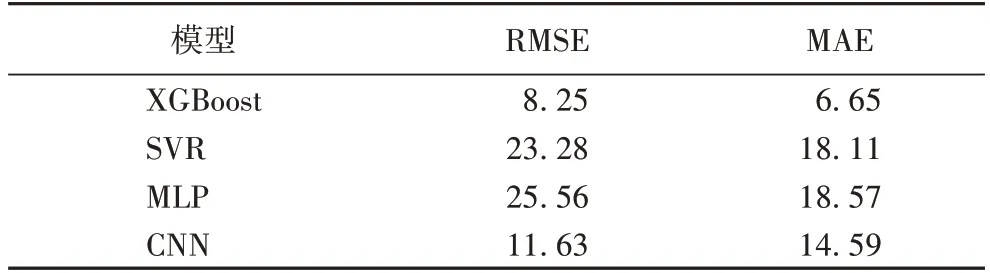
表4 能耗预测模型实验结果Tab.4 Experimental results of energy consumption prediction models
图4、5 分别为XGBoost 模型预测能耗值与真实值的折线对比和预测能耗值与真实值的绝对值误差散点图,其中,图5 中的点表示样本真实能耗值与模型预测值之间的误差绝对值。从图4 中可以看出,XGBoost 模型预测值与真实能耗值的折线变化基本一致,且误差大多数维持在较低的范围,即XGBoost 模型在很大程度上拟合了真实能耗值的变化趋势。这是由于XGBoost 模型对于非线性回归问题具有较高的精度,对非线性数据的学习具有良好的性能。因此,XGBoost 模型预测能耗可以达到模拟功耗仪的作用,但并不会影响服务器的能耗下降。
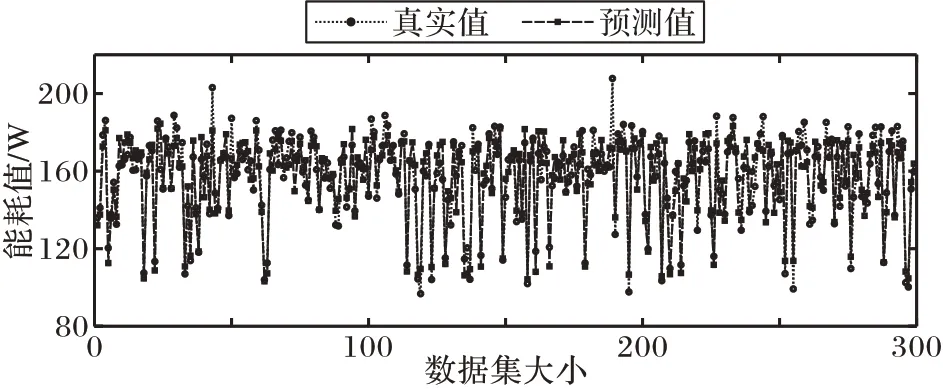
图4 能耗预测值与真实值的对比Fig.4 Comparison of predicted and true values of energy consumption
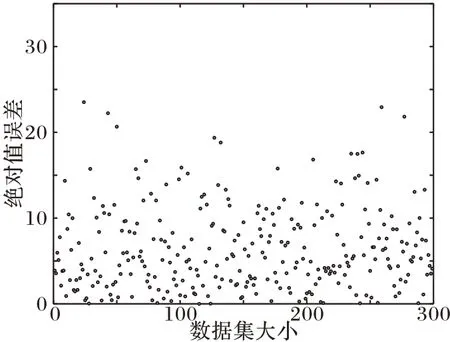
图5 绝对值误差散点图Fig.5 Scatter plot of absolute error
3.3.2 Multi-GRU模型结果分析
现代战争表现为多维度、多领域、多层面的激烈竞争,是综合国力的较量。无论哪种形态的战争,都需要强大的国防动员力量来支撑。人武部作为后备力量的基层建设部,应扎实开展国防动员潜力调查,提供包括武装力量动员、国民经济动员、科学技术动员、人民防空动员,以及政治动员等直接服务战争的人力、物力、财力资源等。准确掌握退出现役人员服预备役、地方与军事专业对口技术人员和分布情况,为战时征召完成支前、作战防卫任务提供可靠基础。对影响作战的交通地形、重要设施、重要目标进行现地勘察,做到基本情况心中有数。
1)参数确定。
实验采用控制变量法,保持模型的其他参数不变,改变GRU 网络的层数,计算RMSE 值。实验结果表明,通过增加一定数量的GRU 网络的层数有助于提升模型的预测精度,但是随着网络层数的增加,RMSE 损失值会不降反增。这是由于当GRU 网络层数达到一定的数量时,模型发生了过拟合现象。
不同GRU 网络层时的模型性能对比如表5 所示。表5分别从GRU 网络的层数、训练模型的迭代次数、训练的时间、测试的时间和模型的训练精度(RMSE)等角度对结果进行分析。由表5 可知,随着网络层数的增加,模型计算量会相应地增大,因此模型所需的训练时间和测试时间也会相应地增加。此外,由于当RMSE 取得最小值时模型最优或接近最优,从表5 中可知,当GRU 网络的层数d为3 时,RMSE 取得最小值,因此GRU 网络模型的层数为3 层。图6 为不同GRU 网络层的RMSE 损失变化,从图6 中可以更直观地观察不同GRU 网络层的RMSE 损失变化情况。
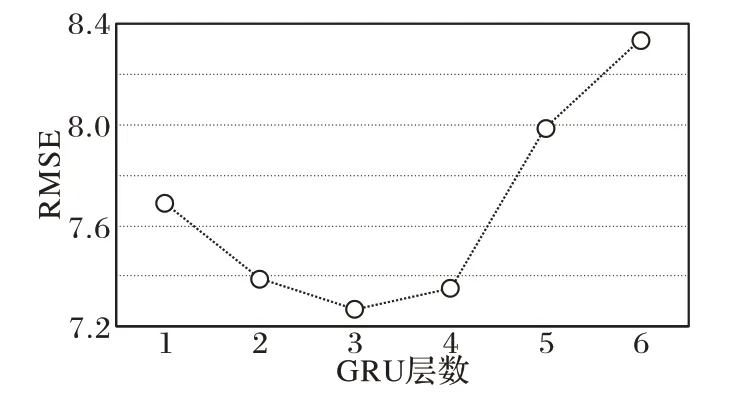
图6 不同GRU网络层的RMSE损失变化Fig.6 RMSE loss change of different GRU network layers
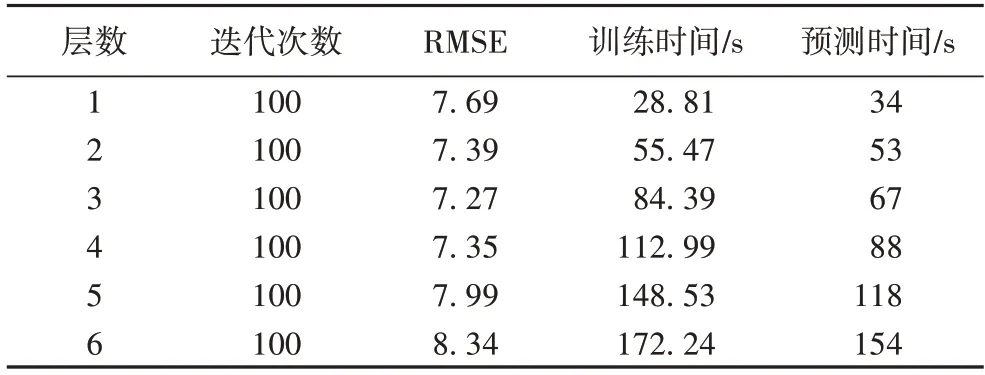
表5 不同GRU网络层的性能Tab.5 Performance of different GRU network layers
此外,在确定GRU 网络为3 层的基础上,分别调整Batchsize 和Adam 优化算法中的学习率learning_rate 的值,并计算模型每次的RMSE 损失,以找到模型RMSE 损失最小值时的Batchsize 和学习率参数组合,实验结果如图7 所示。由于Batchsize 的大小决定相邻迭代之间的梯度平滑程度:因此当Batchsize 太小时,容易造成相邻两次迭代的梯度震荡较为严重,不利于模型收敛;而当Batchsize 太大时相邻Batch 中的差异过小,梯度不会发生变化,容易变成局部最优。此外,学习率learning_rate 决定了参数移动到模型最优值速度的快慢:如果学习率设置得太小,模型的收敛过程将会变得非常缓慢,甚至无法收敛;如果学习率设置得太大,模型的梯度将会在最优值的附近震荡,也有可能无法收敛。在本章中,Batchsize 的值设置为128,学习率learning_rate 的值设置为0.001 时,网络模型的RMSE 损失取得最小值,即模型达到最优,最优时的模型精度对于下一时刻服务器负载的精准预测具有积极意义,同时也对是否进行模拟降频提供了理论支撑,为下一步的能耗下降奠定了基础。
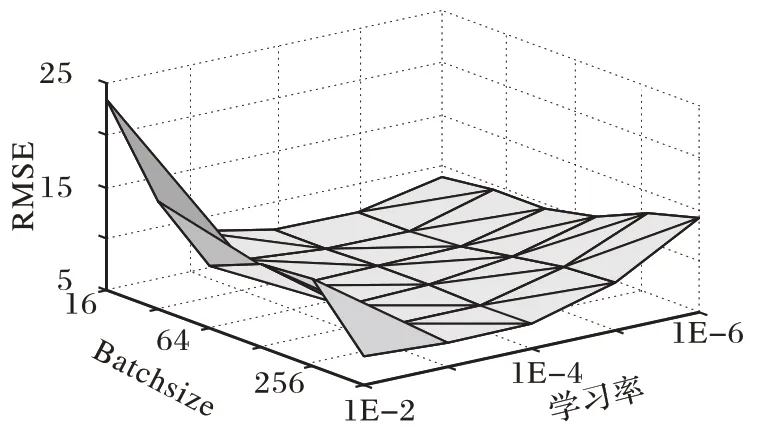
图7 Batchsize和学习率对模型损失RMSE的影响Fig.7 Influence of Batchsize and learning_rate on model loss RMSE
2)实验结果对比。
实验使用收集到的四种系统部件的资源利用率作为数据集,并分别采用Multi-GRU、LSTM、CNN-GRU、CNN-LSTM、CNN、MLP 以及SOTA(State-Of-The-Art)的方法Transformer 等模型进行训练和预测。在上述网络模型中,为保证算法的公正性,CNN-GRU 模型中的GRU 结构与本文所用Multi-GRU模型的网络层数一致,均由3 层GRU 层构成;CNN-LSTM 模型中的LSTM 结构也由3 层LSTM 单元构成;CNN 模型与CNN-GRU、CNN-LSTM 中的CNN 架构相同;MLP 的全连接层数与本节所提模型中的全连接层数相同。此外,本文在对CNN-LSTM 等其他模型进行训练时,分别对网络的层数和每层中神经元的数量进行参数调优,经实验验证可得,其性能均低于Multi-GRU 模型。
对于上述预测模型,计算其在负载测试数据中四种部件负载数据的均方根误差,对比结果如表6 所示。各负载预测模型运行效率的对比结果如表7 所示。综合表6、7 可知,与MLP、CNN、LSTM、CNN-GRU、CNN-LSTM 和Transformer 模型相比,本文所提算法的性能均有不同程度的提升,RMSE 分别降低了76.8%、50.9%、31.0%、32.7%、22.9%、74.0%。与LSTM、CNN-LSTM 和CNN-GRU 模型相 比,在预测精度(RMSE)大致相同的情况下,本节所提算法大大减少了训练时间和预测时间,其中训练时间分别缩短了43.2%、59.9%、47.1%,预测时间分别缩短了26.9%、38.8%、11.9%。

表6 负载模型RMSE结果对比Tab.6 Comparison of load model RMSE results
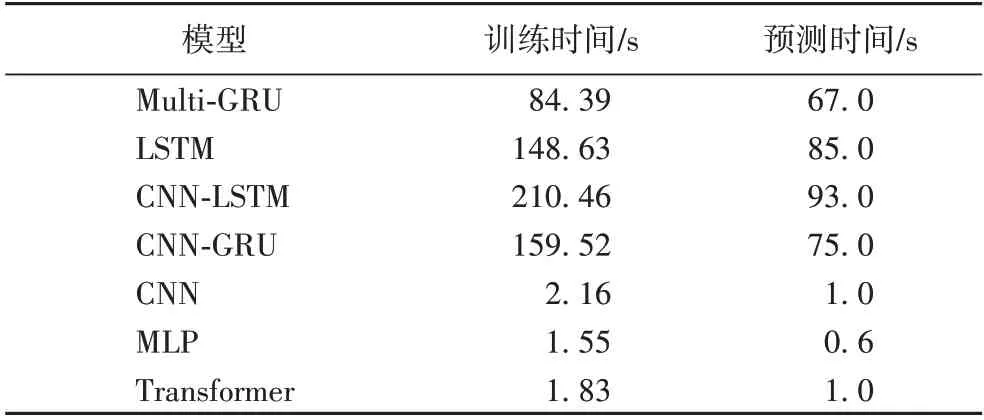
表7 负载模型效率对比Tab.7 Comparison of load model efficiency
图8~11 为服务器真实负载数据和不同方法的负载预测数据曲线对比。从图8~11 中可以看出,本文所提算法的预测数据能够更好地接近真实负载数据,具有更高的预测精度。这是由于Multi-GRU 模型能很好地拟合时序数据,并对负载数据有较高的预测性能。
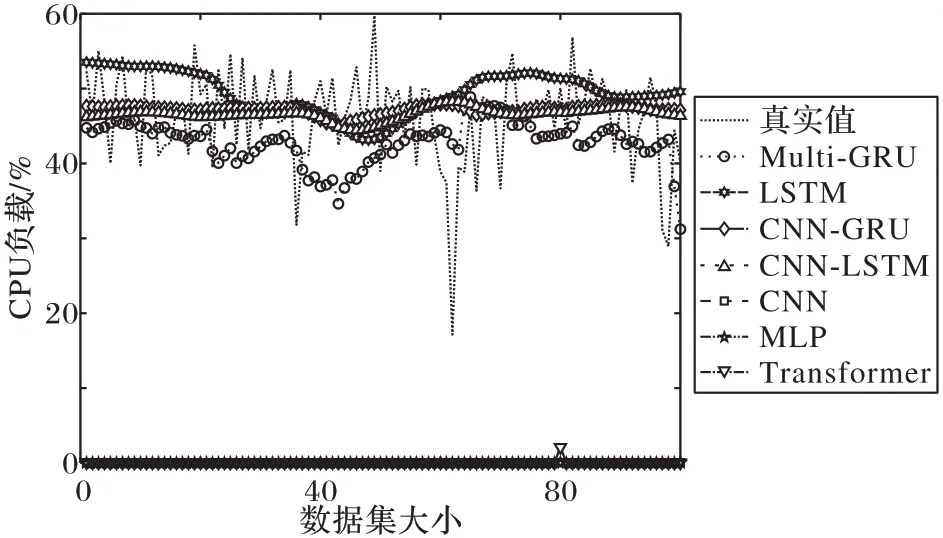
图8 部分CPU负载预测效果Fig.8 Part of CPU load prediction effect
根据Multi-GRU 模型所预测到的服务器负载,ECOXG 算法可对服务器进行模拟降频,并根据降频后的服务器资源利用率的值使用XGBoost 模型预测出降频后的服务器能耗,实现降耗的效果。
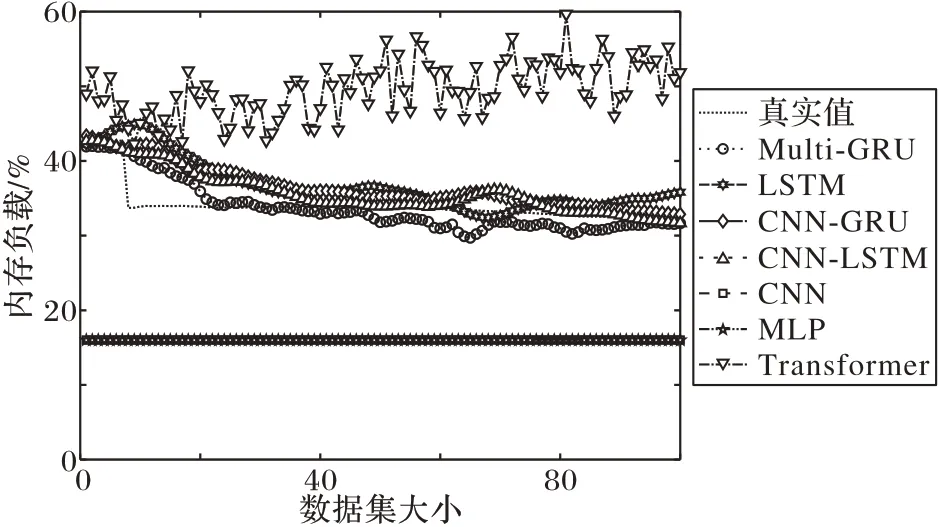
图9 部分内存负载预测效果Fig.9 Part of memory load prediction effect
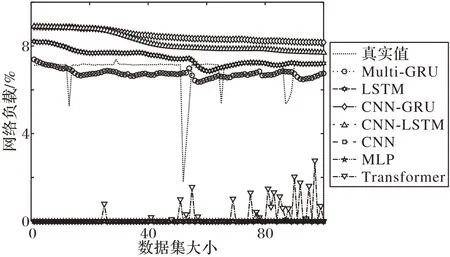
图10 部分网络负载预测效果Fig.10 Part of network load prediction effect
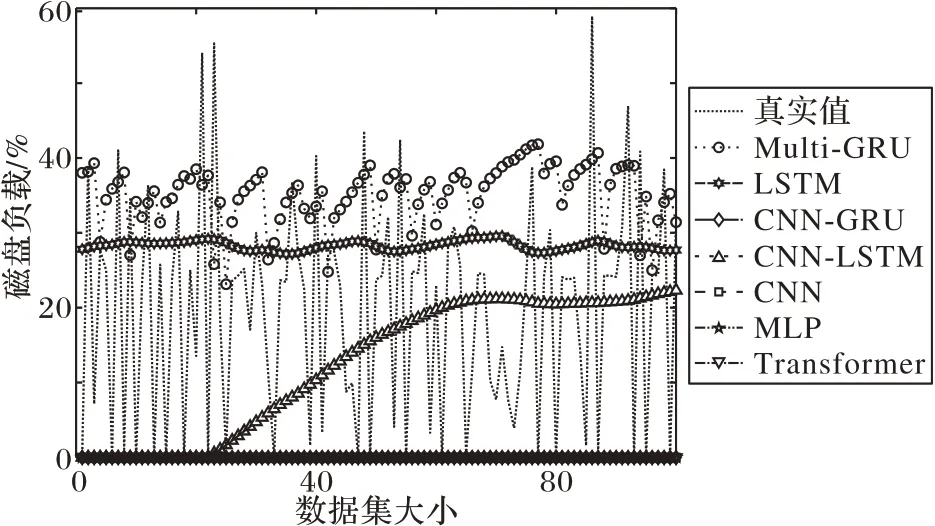
图11 部分磁盘负载预测效果Fig.11 Part of disk load prediction effect
综上,3.3 节所提XGBoost 模型与Multi-GRU 模型分别在能耗预测和负载预测的任务中具有良好的表现。
3.4 能耗对比
将3.3 节中预测的服务器负载数据进行模拟降频,然后将降频后的负载数据输入到之前训练好的XGBoost 模型中,输出降频后的能耗,并与原始能耗对比,如图12 所示。在图12 中,两条折线分别表示原始能耗数据和模拟降频之后的服务器能耗。结合图8~11 可知,负载有大有小,因此本文将负载手动划分为“高负载”“中负载”和“低负载”三种类型。图12(a)、(b)、(c)分别表示高、中、低负载时降频前后的能耗对比。其中,在图12(a)和图12(b)中,此时服务器处于高、中负载状态,即工作状态,为保证服务质量,服务器不进行降频。但是由于XGBoost 模型存在误差和真实能耗值波动较大,因此前期降频后的能耗值部分高于真实能耗,属于正常现象。图12(c)是服务器处于低负载时降频前后的能耗对比,此时服务器处于空闲状态,服务器将进行模拟降频,使得能耗下降,因此降频后的能耗变化曲线已明显低于原始能耗变化曲线。综上所述,模拟降频后的能耗已明显低于原始能耗,且在低负载时降耗效果显著。
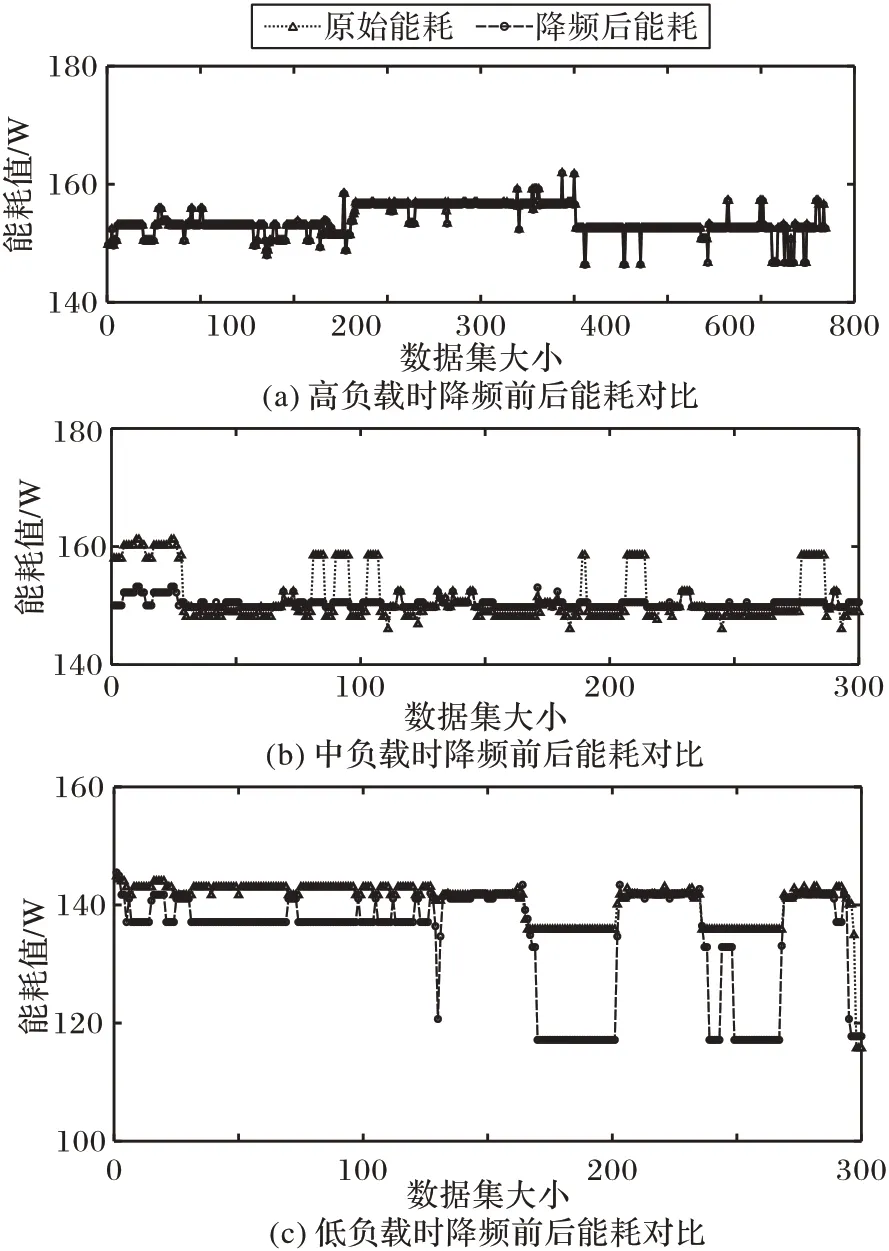
图12 不同负载时降频前后能耗对比Fig.12 Comparison of energy consumption before and after frequency reduction under different loads
4 结语
本文针对服务器能耗优化日益迫切的需求,提出了一种融合XGBoost 和Multi-GRU 的数据中心能耗优化算法ECOXG,该算法首先根据某一时刻的系统资源利用率构建时间序列向量,使用滑动窗口的方法依次将构造的时间序列向量生成特征图,然后以时间序列特征图作为输入,训练XGBoost 模型和Multi-GRU 模型,以预测服务器单机能耗及服务器资源利用率负载,并根据预测到的负载数据进行模拟降频,再输入到XGBoost 模型中,最后输出降频后的服务器能耗值,与原始能耗作对比。将本文算法分别与SVR、MLP、CNN、LSTM、CNN-GRU、CNN-LSTM 及Transformer 算法进行对比,所提算法获得了较低的误差和较高的效率,同时也具有巨大的应用潜力。
李永明等[18]研究报道,液体饲喂的猪只消化道结构发生改变,随着饲料水分的增加,小肠和回肠的长度增长,胃、小肠、回肠的质量增加,肚大过肥,屠宰率降低。
由于本文构造的数据集没有考虑更细粒度的因素,因此后续工作将进一步研究部件更细粒度的因素对服务器负载及能耗的影响,探究其内在的联系,进一步降低算法的误差,提升模型的性能。此外,由于算法是通过模拟降频的方式对服务器进行降耗,并没有进行实际的降频操作,因此,后续工作将进一步研究实际降频后服务器具体的功耗情况及降频后对完成负载任务的影响,进一步降低服务器的能耗。
猜你喜欢
机械研究与应用(2022年4期)2022-09-15 02:21:32
昆钢科技(2022年2期)2022-07-08 06:36:14
当代水产(2021年10期)2022-01-12 06:20:28
建材发展导向(2021年23期)2021-03-08 01:05:38
中国化肥信息(2019年6期)2019-01-19 13:10:42
经济技术协作信息(2018年5期)2019-01-19 08:39:16
华人时刊(2018年15期)2018-11-10 03:25:26
电子测试(2018年11期)2018-06-26 05:56:24
消费导刊(2017年24期)2018-01-31 01:29:29
印制电路信息(2015年6期)2015-12-30 12:57:48
