
面向随案电子卷宗的知识森林自动构建方法
2022-02-26 06:58:02屈垠岑赵银亮酒冲冲
计算机应用 2022年1期
屈垠岑,赵银亮,酒冲冲,刘 硕
(西安交通大学计算机科学与技术学院,西安 710049)
0 引言
阅卷一直是司法诉讼工作中不可缺少的一步,充当着串联诉讼各阶段的重要角色。刑事、民事和行政等诉讼案件在不同程序环节都需要相关人员对卷宗进行阅卷,一份卷宗往往包含大量文件材料,阅卷者通常需要阅读所有的文件材料来发现案件的实体事实和程序事实,避免遗漏和错误。比如在审查起诉环节,办案人需要在有关利害关系人参与下,对侦查过程及结论进行审查,并确定是否起诉。审查的方式主要是书面阅卷,同时也必须讯问有关利害关系人的意见。其中,书面阅卷审查的内容重点为犯罪嫌疑人的情况、犯罪事实与情节、证据材料、诉讼文书和法律手续、有无遗漏罪行、是否应予追究刑事责任、侦查活动是否合法等[1]。伴随多样化阅卷目标和大量的卷宗文书,阅卷审查所需思维过程复杂、工作量大。在诉讼实践中,办案人错误地认定事实、错误地定性、错误地起诉的深层次原因在于人类的认知能力,包括侦查发现事实的能力、公诉中判断证据与事实及其性质的能力都是有限的[2]。
面对大量文书数据和多样化阅卷目标,由于普通人的认知能力有限,在阅卷过程中常会面临信息过载和知识迷航两大挑战[3]。其中,信息过载是指阅卷者接收了太多的信息却无法有效整合、组织成自己需要的信息[4]。知识迷航是指阅卷者在信息收集过程中可能出现类似在大海中航行迷失方向而不知所措的现象[5]。在司法实践中,通过对办案实践的总结形成阅卷流程和方法,并制作阅卷笔录[6]可以一定程度上缓解这两个问题,如“先简后繁”“先供后证”的阅读方式有利于减轻阅卷迷航的问题,“对照阅读”“边阅边问”的阅读方式有利于减轻认知负载的问题,但这些方法依然需要阅卷者有丰富的阅卷经验,并且需要花费阅卷者大量的时间精力。
为了解决上述问题,采用一个合适的模型来自动组织卷宗知识、表达卷宗内容信息是很有必要的,知识森林模型采用与人类认知更一致的方式表示卷宗内容,利用主题分面树以及主题间关系作为卷宗的知识化表示,已在教育领域显示出显著缓解信息过载和知识迷航的效果。本文以随案电子卷宗为研究对象,研究目标是为每一份案件卷宗数据自动构建卷宗知识森林,展现卷宗完整信息。本文的主要工作如下:
1)提出随案电子卷宗的知识森林模型,它由主题分面树和主题关系组成,主题分面树组织卷宗主题的相关信息,从而缓解信息过载问题,主题关系展示卷宗主题间的关系链路来缓解迷航问题。通过该模型的知识组织形式,选择部分主题和少量卷宗碎片实现阅卷目标成为可能,避免了全面浏览卷宗内容以完成阅卷任务的困难。
2)提出了一种自动构建卷宗知识森林的方法,包括信息抽取、知识融合等,并验证了该方法的准确性与有效性。
1 相关工作
卷宗知识是事实和数据的集合,这些分散的事实和数据需要被组织成有序的结构。针对卷宗文书的研究,常见的知识组织模型有主题图和知识图谱。在主题图领域,刘秀如等[7]分析了公安案件中文书数据的主题及主题间的关联,并实现了主题图可视化;Jungiewicz 等[8]利用波兰法院的判决文书集生成了主题图;Chen 等[9]利用公安案件的主题图实现了案件导航系统。利用主题图的主题关系可以方便地进行信息总览和信息导航,从而能在一定程度上解决迷航问题,但主题图在组织知识片段时粒度太大,忽略了主题信息,因此难以解决信息过载的问题。在知识图谱领域,Filtz[10]和Marković 等[11]提出了法律的表示方法,并构建了法律知识图谱;洪文兴等[12]通过实体抽取和关系抽取等方法针对相关法律和裁判文书构建了司法知识图谱;Lian 等[13]针对裁判文书和相关社交媒体信息构建了案件知识图谱。上述工作通过知识图谱可视化和后续的知识搜索等功能可以在一定程度上缓解信息过载问题,但实体没有经过层次化组织直接展示,无法提供清晰的主题间关系路径,因此难以解决迷航的问题。
为了改善知识迷航和信息过载的问题,Zheng 等[14]提出了知识森林的概念。知识森林由主题分面树和主题间关系构成,其中主题是指课程中的知识概念,主题分面树围绕相应主题以层次化的形式组织wikipedia 相关描述和网络爬取的知识碎片,主题间关系指主题间的学习依赖性。在在线教育场景中,以数据结构课程为例,该课程中包含栈、线性表等知识概念,将它们作为知识森林中的主题,线性表和栈的学习依赖性由线性表主题指向栈主题的主题关系表示,代表了应该先学线性表再学栈。知识森林模型既可以表达主题间的关系链路,又可以展示主题的相关信息,有利于缓解迷航和信息过载的问题。但上述知识森林模型针对的是教育场景,因此针对卷宗文书特殊的知识形式和主题信息,本文根据卷宗文书的特点研究卷宗知识森林的定义和表示,并构建卷宗知识森林。
2 卷宗知识森林模型
卷宗本体是卷宗知识森林的表示基础,本章利用司法相关本体论和行业标准定义了卷宗本体,并利用卷宗本体定义了卷宗知识森林的基本构成。
2.1 卷宗本体定义
本体是对一个特定领域的重要概念的形式化描述。卷宗本体定义了卷宗常见概念及其相关信息和相互关系,对卷宗内容进行系统描述。首先,本文给出卷宗本体的形式化定义,定义卷宗本体为一个五元组O={C,A,R,H,X},其中:C为卷宗中的概念集合,A为属性集,R为卷宗概念之间的关系集合,H为卷宗中的概念层次,X为公理集。C中每个概念ci表示相同类型的一组对象,A(ci)表示概念ci的属性集,关系集合R中每个关系表示概念cp和概念cq的二元关系,H表示了概念集C中的父子关系,X中的公理是对卷宗本体的概念、关系或者概念对象的关系的限制。
基于“一案一卷”原则,本文依据案件要素本体论[15]对卷宗本体结构进行定义。本文以案件“人物事时空”五要素论为基础,参照法院行业标准中的电子卷宗阅卷目录规范(FYB/T 52021—2018)对本体结构做出调整,得到卷宗本体中4 个顶层概念:案件相关人、案件相关物、案件相关行为、卷宗基本信息。对各顶层概念简要概述如下:
1)案件相关人概念包括辩护人、被告、原告、诉讼代理人等实体类,被告和原告分别有年龄、身份证号码、民族、籍贯等数据属性,如果是法人,则有单位的全称和所在地址等数据属性,并且在卷宗中有被告身份证明等相关文件或文本片段对原告、被告进行描述。
2)案件相关物概念包括涉案工具,犯罪、侵权痕迹等实体类,如书证、物证、笔录等证据材料均是一种物化的形式[16]。涉案工具指实施犯罪、侵权行为所用之物,如刀、枪、信件等,有长、宽、高、型号、数量、价值等数据属性,在卷宗中有物证处理材料等相关文件或起诉书等文本片段进行描述;犯罪、侵权痕迹是指犯罪、侵权行为引起的客观变化,包括相关行为形成之物和针对之物、相关人员遗留和黏附之物,如现场留下的指纹、足迹、工具破坏痕迹、赃款赃物等,相关属性包括勘验人、勘验地点等实体,在卷宗中有勘验笔录、鉴定意见等相关文件或文本片段对犯罪、侵权痕迹进行描述。
3)案件相关行为概念包括案件事实。案件事实是指在案件发生过程中的事件,有事件的施加者、承受者、发生时间、发生空间属性,并且在卷宗中有起诉书、判决书等相关文件片段对案件事实进行描述。
4)卷宗基本信息概念包括判决结果、卷宗编号和案件流程。判决结果指法院做出的具有法律效力的书面文书处理决定,判决结果通常依据相关法律条文,因此有审批依据属性,在卷宗中有判决书等相关文件片段对判决结果进行描述。每份卷宗都有独特的编号,编号是卷宗中重要的信息,在卷宗各文件重复出现。案件流程指立案、司法拘留等与案件执行有关的程序,在卷宗中有立案审批表、案件审判流程管理信息表等相关文件对案件流程进行描述。
基于上述本体的概念集合、概念层次和属性集,可以推断出关系集合和公理集,关系集合包括包含关系、依据关系、执行关系、判定关系、顺承关系、参与关系、被影响关系、产生关系、持有关系、证明关系、起诉关系、代理关系、辩护关系,并对关系的domain(定义域)和range(值域)进行约束得到公理集。
本文使用资源描述框架(Resource Description Framework,RDF)进行卷宗本体的知识表示和存储,基于RDF 的本体论描述了卷宗中4 类顶层概念、10 类底层概念、10 类关系和5 类数据属性。本体结构如图1 所示,其中内层为顶层概念,外层为底层概念,最外层为底层概念对应的数据属性。
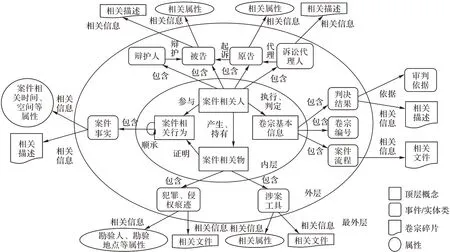
图1 卷宗本体结构Fig.1 Structure of case file ontology
2.2 卷宗知识森林基本构成
卷宗知识森林由主题分面树结合主题关系构成,可以表示为二元组KF=(FT,TR)。其中,对于卷宗主题集T={t1,t2,…,tn},FT={FTi|ti∈T}是指与T中元素一一对应的主题分面树的集合,TR⊆T×T表示T中主题关系的多重集合。
卷宗主题ti∈T为卷宗中具有实际意义的事物,即本体中底层概念对应的所有实体类和事件。根据XTM(eXtensive markup language Topic Maps)1.0 标准,主题就是现实事物的具体化,它可以是表示任何事物对象的名词。本文依据卷宗本体顶层概念,将卷宗主题分为案件相关人物、物体或司法概念,以及案件发生经过4 类。比如,被告某某属于案件相关人主题类、某某组织吸毒事件属于案件相关行为主题类,卷宗主题集为卷宗中所有的主题,包括被告某某、某某组织吸毒事件、贩毒罪、现场证据等。
主题分面树是指围绕一定主题将实体、事件、属性、卷宗碎片形成层次化的树。主题ti的主题分面树可以表示为元组FTi=(Fi,RFi)。其中Fi是指与ti相关的分面集合,对应本体中最外层底层概念的数据属性,包括属性、卷宗碎片和非主题实体,属性指对某主题相关概念特征或性质的描述,卷宗碎片指卷宗中对同主题进行描述的最小文本片段或文件,非主题类实体指不属于任一主题类但是和主题存在特定关系的实体,形式化描述为Fi=A(ci),ci为主题ti的对应本体概念,A(ci)表示概念ci的属性集。RFi⊆({ti}∪Fi)×Fi表示主题ti和分面的关系,对应本体结构中底层概念和最外层数据属性之间的关系,形式化描述为RFi=(ci,A(ci))。主题分面树将多方面的分面、碎片通过层次化的形式组织起来,针对阅卷目标中的不同关注点,用户都可以在使用过程中方便地定位相关知识、理解相关内容。比如,在勘验笔录主题中,勘验笔录主题的分面表示为F勘验笔录={事故时间,二月一日,勘验人,丁某,…},而勘验笔录主题的主题和分面关系可以表示为RF勘验笔录={(勘验笔录,勘验人),(勘验人,丁某),…}。
主题关系ri,j∈TR指卷宗中主题ti和主题tj之间某种预定义类型的关系,对应本体结构中顶层概念之间的关系和外层底层概念之间的关系,形式化描述为ri,j∈R(ci,cj),ci为主题ti的对应本体概念,cj为主题tj的对应本体概念。主题之间以关系连接形成主题链路,通过选择链路上的相关主题实现阅卷目标,可以避免寻找阅卷内容重点时全面浏览卷宗带来的困难。如被告某某主题和某某组织吸毒主题是参与关系,表明被告参与了某某组织组织吸毒的事件,针对查找嫌疑人有无遗漏罪行的阅卷目标,可以确定嫌疑人相关的犯罪事件,并依据事件间的顺承关系可确定阅卷范围和顺序。
2.3 问题分析及解决
卷宗文书中除了包含丰富的主题和关系以及随时间变化的案情发展逻辑之外,也存在重复的信息。针对上述特点,构建卷宗知识森林存在一定的挑战性,本文结合卷宗知识森林和卷宗文书的特点,对于构建卷宗知识森林过程中存在的问题提出了相应的解决方法。
1)卷宗中有丰富的主题。卷宗中包含多个文书,不同文书有不同的主题,同一份文书也会包含多个主题。通过碎片化将多主题文书分割为单一主题的碎片,使碎片内部具有最大的主题相关性,碎片之间具有最小的主题相关性,避免了多主题混合对阅卷带来的认知负担。
2)卷宗存在案情发展逻辑。卷宗中的案情以事件作为最小单元,随着事件发展可以构建案情发展逻辑,事件作为卷宗发展的主线,是信息关联的关键节点。因此除了常规的实体抽取、关系抽取之外,还需要对卷宗中的相关部分进行事件抽取,并通过顺承关系形成事件链,展现案件的发展经过。
3)卷宗中存在重复的信息。在卷宗不同文书中部分信息会反复出现,如果不处理重复的信息,会带来阅卷认知上的阻碍和信息过载问题。因此,通过实体对齐、事件共指等方法合并同义主题,提炼卷宗内容,避免重复阅读的认知过载问题。
4)卷宗主题包含多样化的信息,主题之间存在复杂的关系。依据卷宗本体结构,将复杂的卷宗内容映射到知识森林的主题分面树和主题关系,以与人的认知更一致的方式展示卷宗内容。其中,卷宗知识森林通过主题分面树多样化的分面和与其相关联的卷宗碎片来表达卷宗中丰富的主题信息,满足阅卷中不同的关注目标。卷宗知识森林中主题关系形成的关系链路,为选择阅卷目标相关主题实现阅卷目标提供了可能,缓解阅卷过程中出现的迷航问题。
3 卷宗知识森林构建
知识森林的构建可以看作是卷宗知识的再组织过程,依据上述卷宗知识森林模型的相关问题分析,本章实现了一种卷宗知识森林构建方法,该方法可以在实际卷宗数据中构建出知识森林模型。
3.1 卷宗知识森林构建方法
如图2 所示,面向随案电子卷宗的知识森林构建的总体框架包含5 步。
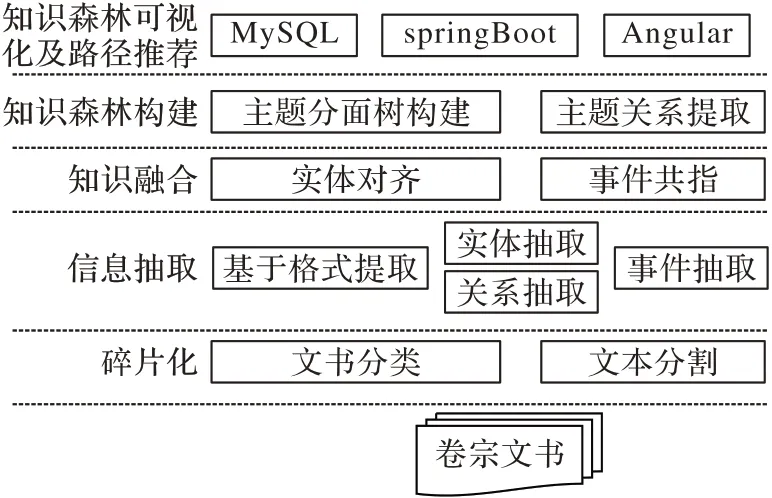
图2 卷宗知识森林构建方法Fig.2 Case file knowledge forest construction method
第1 步 碎片化。本文通过对卷宗进行碎片化,分割出案件相关人、案件相关行为、案件相关物、卷宗基本信息这4种类型的多个碎片。本文利用关键词对结构化文书和非结构化文书进行分类,由于文书名称的规范性,本文总结了卷宗文书的常见类型并整理了文书分类的触发词词表,利用触发词分类出案件相关人、卷宗基本信息、案件相关物三种类型的结构化文书。本文对得到的非结构化文书进行文本分割,采用SECTOR(SEgmentation and TOpic Classification)模型[17]通过BiLSTM(Bidirectional Long Short-Term Memory)网络学习文档潜在主题的向量表示,对向量进行主题分类,并利用主题的变化对文档进行分割,将文书分割出案件相关人、案件相关行为、案件相关物、卷宗基本信息4 种类型的碎片。碎片化的流程如图3 所示。
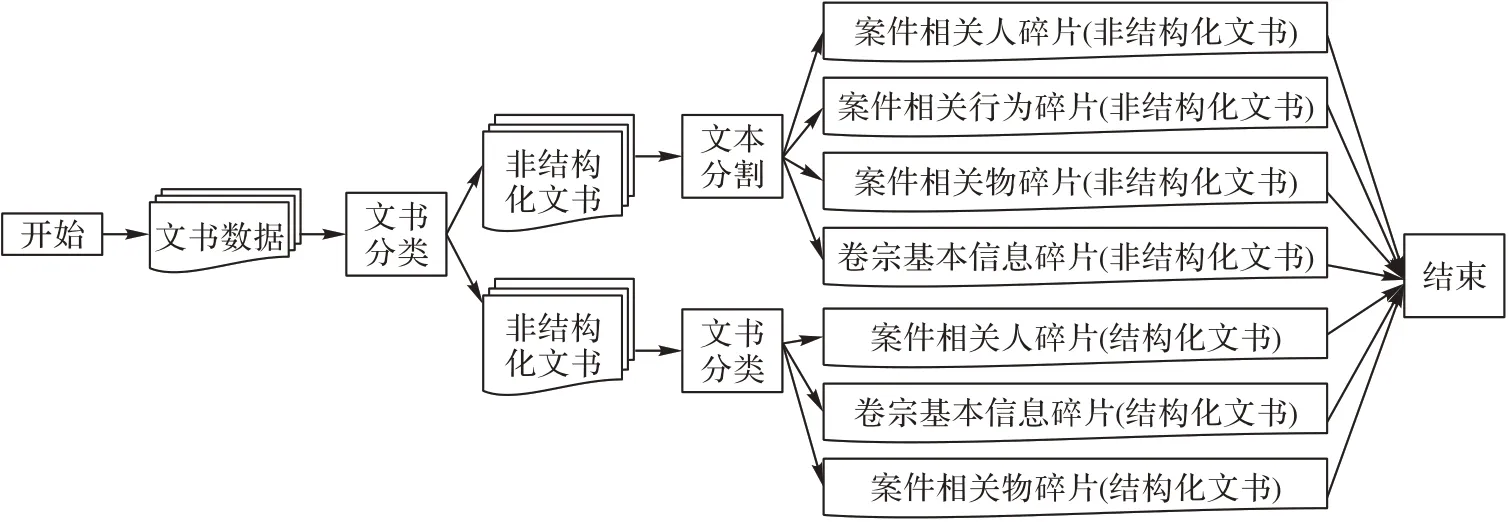
图3 碎片化流程Fig.3 Fragmentation flowchart
第2 步 信息抽取。结构化文书通过文书格式提取出固定类型的信息,非结构化文书本文通过划分不同的语义段落来针对性地提取不同信息。在结构化文书中,本文利用相应文书格式模板和Tabula表格提取工具抽取结构化文书的信息,获得相关实体和实体的属性信息,如“现场勘验记录”作为犯罪痕迹类实体,抽取出的“勘验时间”和“勘验地点”等值作为该实体的属性。在非结构化文书中,本文参考Wang等[18]的方法使用语义角色标注(Semantic Role Labeling,SRL)结合启发式规则的方法进行事件抽取,抽取出事件的施加者、承受者、时间、地点、动作、方式属性;其余碎片本文采用LSTM-CRF(Long Short-Term Memory-Conditional Random Field)模型[19]进行实体抽取和 GRU-attention(Gated Recurrent Unit with attention mechanism)模型[20-21]进行关系抽取,抽取卷宗本体中定义的实体和实体关系。信息抽取的流程图如图4所示。
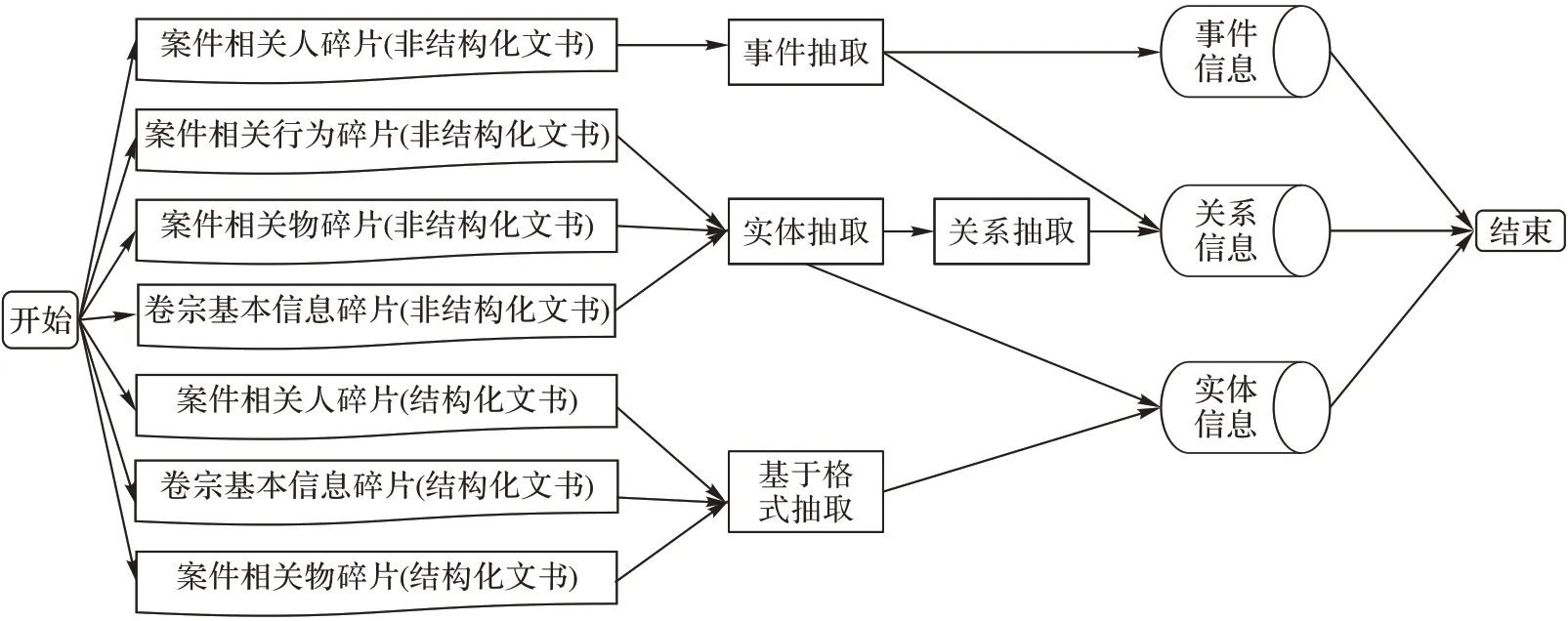
图4 信息抽取流程Fig.4 Information extraction flowchart
第3 步 知识融合,主要分为实体对齐和事件共指两方面。在结构化文档和非结构化的文档中抽取的实体可能是同一实体的不同名称,因此实体对齐主要采用基于同义词表的方法,手动标注出领域同义词表,对齐后的实体属性为合并前两个实体属性的并集。由于卷宗中不同文本文书会对同一事件重复描述,因此还需要识别出共指事件并合并,事件共指主要采用平均事件句的Word2Vec 词向量计算余弦相似度的方法,如果大于给定阈值,则认为事件共指,将两个事件合并到一起,认为这个新事件对应两个事件句,新事件的事件属性为合并前两个事件的事件属性的并集。
第4 步 知识森林构建。本文利用预构建的卷宗本体将卷宗信息映射到知识森林,依据卷宗本体结构,将所有事件和部分实体放入主题集,属性、非主题实体、卷宗碎片属于分面集,主题和分面的关系由主题对应的本体结构确定。对于特殊的“案件相关行为”类型主题,本文认为在同一个句子中的事件表达同一主题,因此将一句中所有事件的集合表示为一个主题,并通过依存句法分析将句子的主谓宾成分连接起来为该主题命名。知识森林的主题预定义关系由关系抽取的结果转化而来,本文保留主题分面树的主题间实体关系,但由于关系抽取的结果只限于实体之间,本文还需要进一步挖掘“案件相关行为”类主题分面树的主题关系。因此本文加入启发式规则作为补充:如果“案件相关行为”类主题分面树中事件的施加者、承受者属性和其他主题分面树的主题实体对齐,如果该主题是“案件相关人”类实体本文认为该分面树和“案件相关行为”类主题分面树的关系是参与,如果该主题是“案件相关物”类实体本文认为该分面树和“案件相关行为”类主题分面树的关系是证明;本文利用文档叙述事件的先后顺序作为“案件相关行为”类主题分面树之间的顺承关系。知识森林构建的伪代码如下。


第5 步 知识森林存储及可视化。本文将知识森林的数据写入关系型数据库Mysql 进行存储,使用SpringBoot 框架Java 开发的后端,并基于Angular 框架利用D3.js 和echarts插件实现前端进行可视化展示。
3.2 实验结果分析
为了验证知识森林自动构建方法,本文对部分方法做了小范围内的评估,包括卷宗碎片化、事件抽取、事件共指。本实验环境在1080Ti 8 GB GPU 环境下进行,使用PyTorch 框架进行开发。
3.2.1 数据集
本文在8 份完整脱敏的卷宗上进行了测试,其中有3 份刑事卷宗、1 份民事卷宗、4 份行政卷宗。平均每份卷宗包括31 份文件材料,最多的包含了52 份文件材料。对于单个文书来说,结构化文书2 页篇幅最为常见,非结构化文书平均篇幅5 页,最长可以达到9 页。
由于卷宗数据的特殊性,不能大量获取卷宗,在裁判文书网下载了300 份公开的裁判文书作为训练和测试的补充数据,考虑到刑事、民事、行政文书之间的内容和格式都有所不同,本文随机抽取100 份民事文书、100 份刑事文书、100 份行政文书。
3.2.2 卷宗碎片化
对于文书分类,本文在8 份完整卷宗上进行测试并交由人工审核,评估得到基于触发词进行分类的效果的精确率为89.4%,召回率为87.5%,F1 值为88.4% 。对于文本分割,本文对300 份判决书进行人工标注,最终获得标注数据6 481 条,随机选择5 833 条作为训练数据,648 条作为测试数据,评估结果如表1 所示,该结果表明该碎片化方法可以较为准确地分割实际卷宗文书。其中,“案件相关行为”类别的F1 分数为89.91%,与“案件相关人”类别和“案件相关物”类别相比,该类别分数较低,这是因为“案件相关行为”类碎片在判决书中出现在案件事实相关段落,文书中常多处提及案件事实且内容丰富多样,因此训练集和测试集差异较大,模型在测试集上拟合不够充分,考虑增加更多提及事实的文书进行训练。
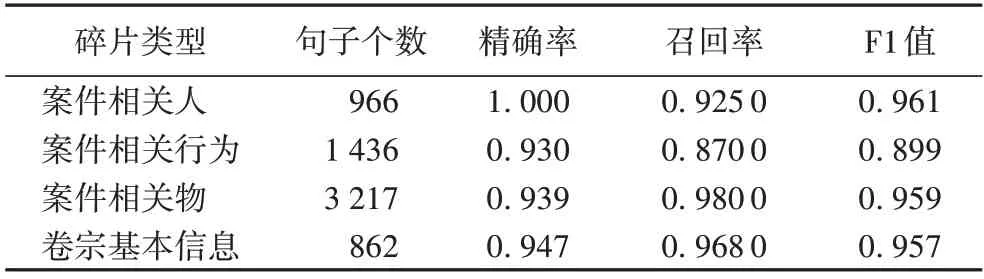
表1 文本分割结果Tab.1 Results of text segmentation
3.2.3 事件抽取
对于事件抽取,本文采用了一种比较元组的方法进行结果评估,如果只比较两个元组是否完全相同,会忽略掉那些部分正确的元组,因此本文参照Wang 等[18]的5W1H 事件属性抽取方法中的评估方式,采用字符串相似性度量来评估,结果如表2 所示。
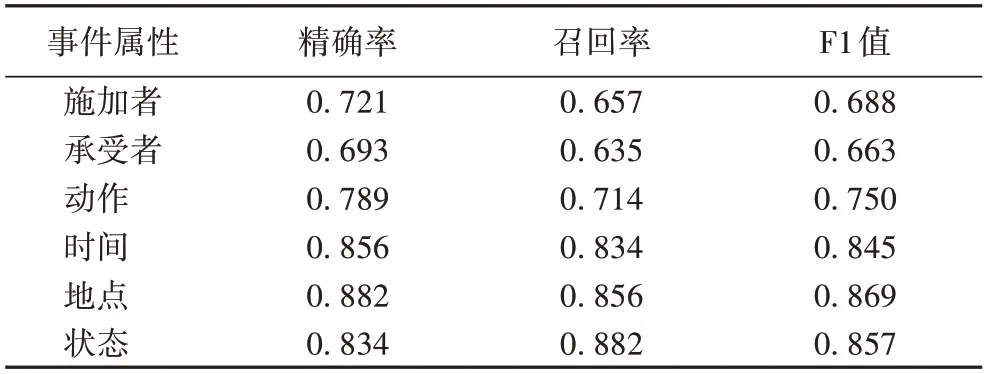
表2 事件抽取结果Tab.2 Results of event extraction
本文随机选取30 份民事文书、30 份刑事文书、30 份行政文书,在90 份文书上进行测试,发现“时间”和“地点”属性的抽取效果比“施加者”和“承受者”属性更好,这是因为“施加者”和“承受者”在相同主语宾语的情况下经常被省略或用代词代替导致出现抽取结果出错的情况,且由于卷宗文书多长句,“承受者”和“施加者”属性和“行为”属性关联度更高,SRL 系统受到长句中多个“施加者”“行为”“承受者”属性的信息干扰,难以发现其潜在相关联系,因此“承受者”和“施加者”属性的抽取精度较低。SRL 系统输出的结果还会出现分词错误等问题,如触发词和属性分词错误,导致抽取的结果含义不清,从而影响事件抽取的结果,但这种情况对知识森林构建方法而言仅为独立影响并允许独立改善。
3.2.4 事件共指
本文将事件间余弦相似度大于给定阈值的事件识别为共指事件。本文选择一份卷宗中不同文书对同一事件进行描述的事件句作为正例,随机选择不同事件句作为负例,正负例比例为1∶1,共200 组数据,构建卷宗语义匹配数据集。为了确定最佳的阈值,本文在卷宗的语义匹配数据集上进行了实验,计算了不同阈值对结果的影响。表3 显示了不同阈值下对相似性判断结果的影响。最终,本文设定阈值为0.7,最佳的准确率(acc)值为0.73。
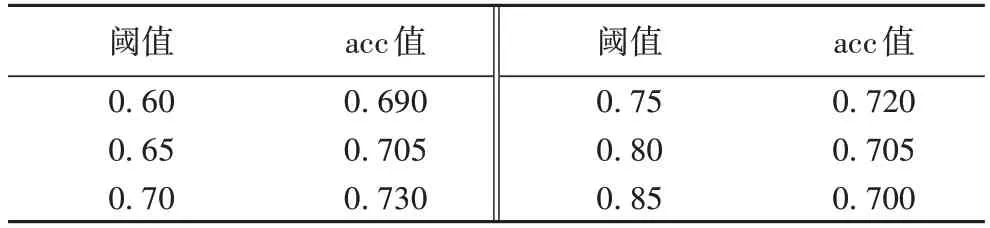
表3 事件共指结果Tab.3 Results of event coreference
4 应用实例
本文以一刑事初审卷宗为例,对该卷宗构建知识森林后,卷宗知识森林的主题及其对应分面碎片数量和主题关系数量统计情况如表4、5 所示。

表4 卷宗知识森林主题分面树构建结果Tab.4 Results of topic facet tree construction of case file knowledge forest
卷宗知识森林可视化界面如图5 所示,该界面由两个组件组成,包括知识森林概览和主题分面树展示。在知识森林概览部分可以总览所有的卷宗主题和主题关系,然后在主题分面树部分提供有关所选主题的主题分面树信息。可以看到在此案件中,在“案件相关人”“案件相关物”“案件相关行为”“卷宗基本信息”主题类下存在多个主题,如“案件相关人”主题类下对应的被告“卢*玲”等主题,“案件相关行为”主题类下对应的“于*海提供车辆”等主题,在此部分,用户可以针对具体的阅卷目标选择相关主题,避免了因阅卷目标难定位带来的迷航问题。
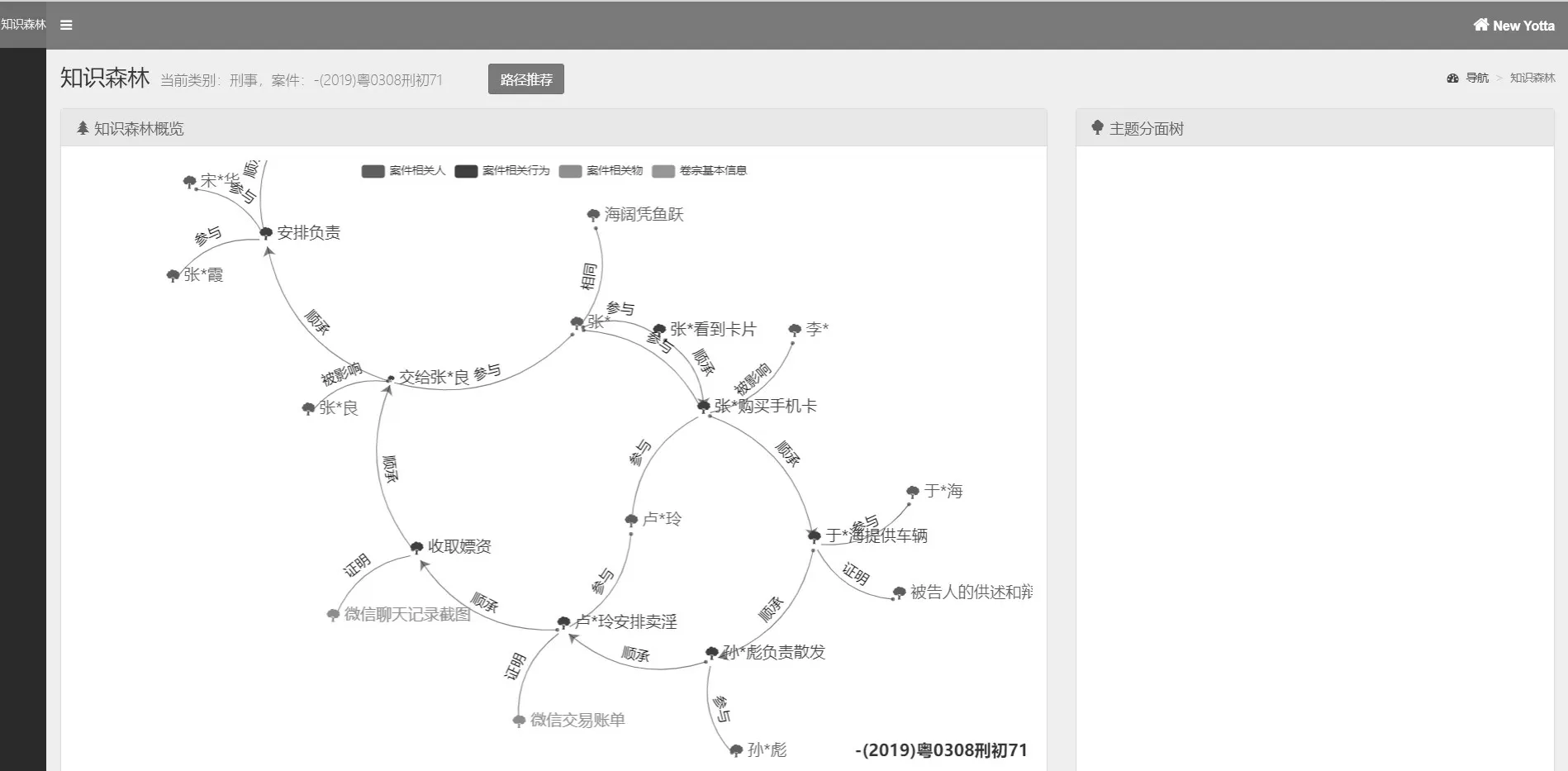
图5 卷宗知识森林可视化结果Fig.5 Case file knowledge forest visualization result

表5 卷宗知识森林主题关系构建结果Tab.5 Topic relationship construction results of case file knowledge forest
用户可以在知识森林概览部分点击某个主题,主题分面树部分会显示所选主题的主题分面树信息,同时知识森林概览部分也会展示只与该主题有关系的主题。如图6 所示,通过点击“于*海提供车辆”主题,可以看到该主题对应的主题分面树信息,包括事件属性和对应的卷宗碎片,并直接地展示该事件的参与者、该事件前后顺承发生的事件,以及证明该事件发生的证据。通过提供相关主题和主题分面树信息,用户可以选择阅读相关分面和对应的卷宗碎片来满足阅卷中不同的关注目标,“顺承”关系相连的事件展现了案情发展经过,提供该主题发生的上下文,“参与”和“证明”关系连接了与该事件相关的人或物,为针对不同阅卷目标选择相关主题进行阅卷提供了可能。
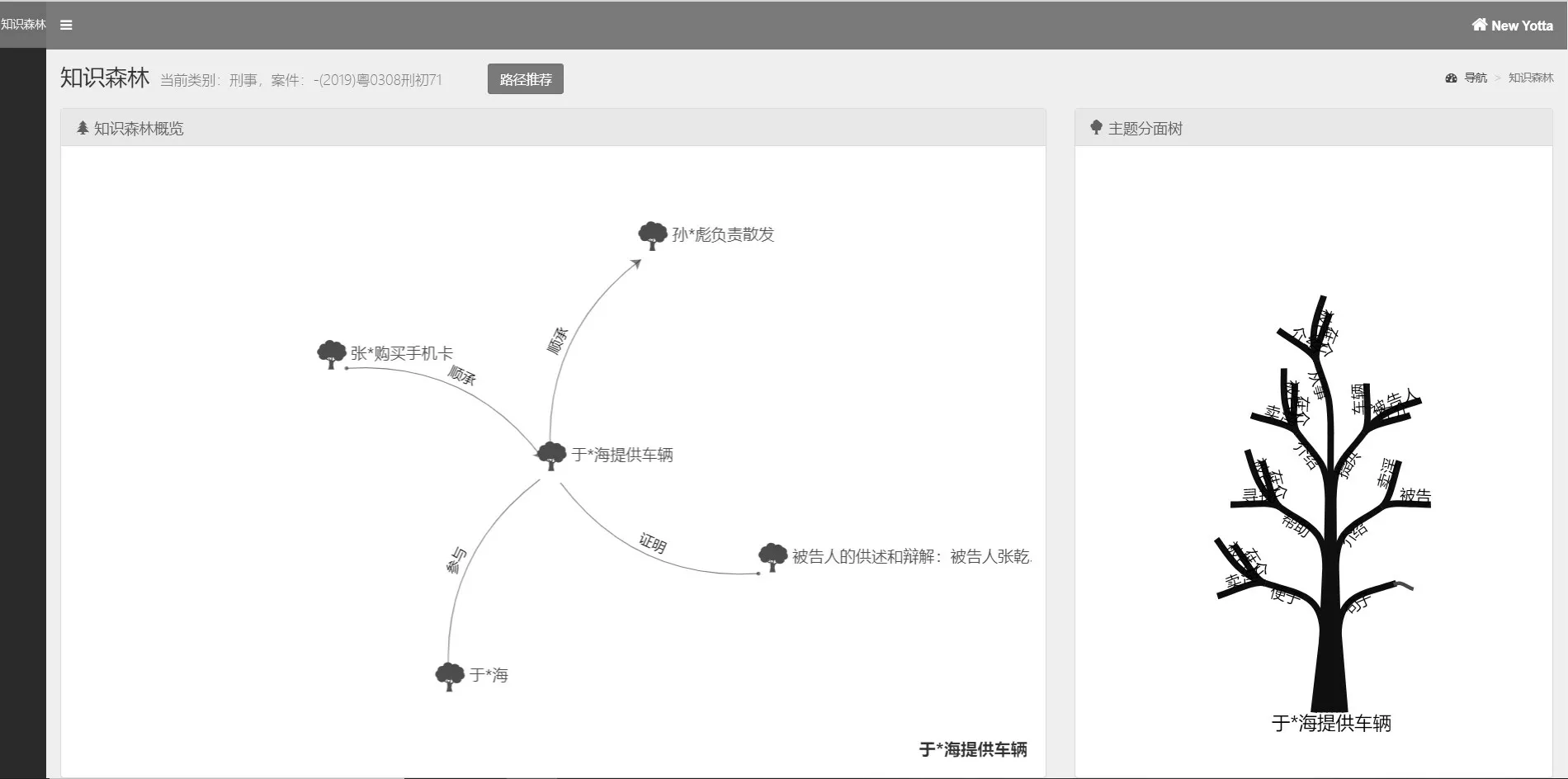
图6 卷宗知识森林点击效果Fig.6 Case file knowledge forest clicking result
本文认为提取的主题和主题关系能够满足用户阅卷中的不同的关注点。具体来说,案件相关行为类主题中分别包含从起诉书和上诉状中提取的多个案件事实,能够满足发现案件事实冲突等相关阅卷目标。案件相关人类主题中被告“张*”包含嫌疑人身份证明和起诉书案件相关人部分两个碎片,能够满足确定犯罪嫌疑人情况的阅卷目标。案件相关物类主题的“讯问笔录”和“补充侦查函”等主题能够满足确定侦察活动是否合法的阅卷需要。案件相关人和案件事实类主题之间的参与关系能够满足判断有无遗漏罪行、是否应予追究刑事责任的阅卷目标。案件相关物类主题和案件相关行为类主题之间的证明关系能够满足判断证据是否充分的阅卷目标。
知识森林提供了卷宗的相关内容展示,用户可以针对具体的阅卷目标选择相关主题,避免了因阅卷目标难定位带来的迷航问题,通过浏览主题分面树的相关分面,为针对不同阅卷目标选择相关主题进行阅卷提供了可能。同时,在知识融合、知识森林构建步骤中的信息处理方法可以缓解冗余信息带来的信息过载问题。在知识森林可视化界面中,用户通过选择特定卷宗和点击卷宗知识森林的树就能够实现卷宗内容的大致了解和问题定位,满足用户友好性和易用性的要求。
因此,本文认为知识森林的可视化结果能够满足用户的阅卷需求,且提高了阅卷效率,可以缓解阅卷过程中的信息过载和迷航问题。
5 结语
本文提出了一种表达卷宗内容的知识森林模型,可以较为完整、准确地展示卷宗信息,组织分散的知识碎片和复杂的卷宗主题,其中卷宗本体提供了一个系统性的卷宗内容表示框架。然后本文结合知识抽取、知识融合等方法实现了一种卷宗知识森林构建方法,并以实验验证了该方法可以在实际卷宗中构建知识森林,最后本文通过实例展示了本文方法的有效性和合理性。
在以后的工作中,如何将多媒体的知识比如现场照片或审问录音等视听资料类证据融入卷宗知识森林也是重要的研究内容。需要指出的是,本文提出的知识森林自动构建的实现方法还有待进一步改进,如面对复杂案件时,计算事件共指的方法错误率较高,可以结合结构化的事件抽取结果对其进行改进。
猜你喜欢
哲学分析(2023年4期)2023-12-21 05:30:27
机械工业标准化与质量(2022年6期)2022-08-12 02:07:06
邯郸学院学报(2022年2期)2022-07-05 07:26:30
浙江档案(2022年12期)2022-02-03 10:04:18
中国音乐学(2020年4期)2020-12-25 02:58:06
安徽警官职业学院学报(2020年6期)2020-07-21 01:38:56
方圆(2019年11期)2019-06-26 09:00:53
西夏学(2019年1期)2019-02-10 06:22:40
文学教育(2016年27期)2016-02-28 02:35:15
卷宗(2013年6期)2013-10-21 21:07:52
