
基于BERT的三阶段式问答模型
2022-02-26 06:57李晓瑜胡世杰刘晓磊钱伟中
计算机应用 2022年1期
彭 宇,李晓瑜,胡世杰,刘晓磊,钱伟中
(电子科技大学信息与软件工程学院,成都 610054)
0 引言
机器阅读理解(Machine Reading Comprehension,MRC)是一项评估机器理解自然语言能力的任务,它要求机器能根据给定的上下文和问题找到对应的答案。教会机器理解人类的语言也是自然语言处理(Natural Language Processing,NLP)领域的终极目标[1-3]。在早期的机器阅读理解数据集[4]中,问题都是可以被回答的,也就是一定能在上下文中找到对应的答案,因此早期的问答模型[5-8]是在问题都可被回答的前提假设下进行构建的。然而现实世界中常常存在不可被回答的问题,因此早期的数据集不符合现实情况。为了弥补这种不足,许多研究机构和学者新提出了包含不可被回答问题的数据集[9-10]来模拟现实世界中的真实场景,但这也给传统的问答模型提出了新的挑战。当面对这样的新数据集时,传统模型的问答表现非常差。
在预训练语言模型出现之前,基于深度学习的问答模型通常被拆分为如图1(a)所示的5 个网络层:嵌入层、编码层、交互层、模型层和输出层。传统模型的改进与发展依赖于每一层的设计与实现。作为一个经典的传统问答模型,BiDAF(BiDirectional Attention Flow)[6]设计了6 个网络层来解决问答任务,并使用双向注意力流结构来捕获给定上下文和问题之间的交互信息。QANet(Question Answering Network)[11]融合局部卷积和全局自注意力机制来加速训练和推断。Wang等[12]也提出了一个端到端并融合Match-LSTM(Long Short-Term Memory)和Answer Pointer 结构的神经网络来完成问答任务。尽管这些模型已经非常巧妙,但它们在包含不可被回答问题的数据集上的表现提升也十分有限。这是因为传统的词嵌入方法难以解决一词多义的问题[13-14],即便有像ELMo(Embeddings from Language Model)[15]这样的动态词嵌入方法被提出,所带来的提升也不明显。

图1 传统问答模型与基于BERT的已有模型的对比Fig.1 Comparison between traditional and existing BERT-based question answering models
预训练语言模型[16-17]如BERT(Bidirectional Encoder Representation from Transformers)[16]的出现极大地 提升了机器阅读理解模型的性能,在某些数据集上甚至超越了人类的表现。这是因为预训练语言模型可以生成“上下文-问题”对基于语义特征和上下文关系的词向量表达。通过在大量的文本语料上进行预训练,预训练语言模型可以捕获单词、序列之间更深层次的交互关系。研究人员只需要针对特定任务在预训练模型之后设计恰当的结构搭建模型进行微调(fine-tune)就能获得相当不错的表现。如图1(b)所示,大多数使用BERT 的问答模型将BERT 看作传统问答模型五个层次中的嵌入层、编码层和交互层。
尽管只利用经BERT 完全编码后的高层特征来设计模型已经取得了不错的性能,但是BERT 中的低层特征却没有得到充分利用[18-19]。高层特征拥有更多的语义和上下文关联信息,而低层特征则包含更少这样的信息。通过使用低层特征,并联合高层特征,可以改进已有方法对浅层信息利用不足的现状,并进一步提高问答模型的性能。基于此,本文提出了一种基于BERT 的三阶段式问答模型,通过设计三个阶段来模拟人类渐进式阅读文本的方式:1)阶段一使用低层特征来做预回答,预生成一个答案;2)阶段二使用高层特征来做再回答,再生成一个答案;3)阶段三将回顾前两个阶段生成的答案并进行调整,给出最终预测结果。该模型通过融合不同层次特征对给定上下文及问题进行两次回答和一次调整,提高了模型预测答案的准确性。实验结果也表明,本模型相较于基准模型在精准匹配度(Exact Match,EM)和F1(F1 score)两个指标上均有了不错的提升。
本文的主要工作如下:
1)为了解决已有模型未充分利用BERT 中浅层特征的问题,提出了一种融合BERT 中高、低两种层次编码特征的方法,能够有效地提高BERT 各层信息的利用率,且改进后的模型复杂度较低。
2)针对抽取式的问答任务,模拟现实世界中人类由浅入深阅读文本的方式,提出了三阶式问答的概念,经过三个阶段调整后的答案比直接生成的答案准确率更高。
3)设计相关实验在公开数据集上对本文所提出模型的性能进行验证,并和其他基准模型进行了对比。
1 三阶段式问答
如图2 所示,本文所提出的问答模型包含三个阶段:预回答、再回答以及答案调整。利用从预训练语言模型BERT中获取到的浅层特征表达和深层特征表达,在不同阶段完成相应的操作。此外,对于包含不可被回答问题的数据集,还需要对“上下文-问题”对的可回答性(即给定一对上下文和问题,是否存在答案)进行计算,以应对不可回答问题对答案的预测带来的干扰。本文模型将针对可回答性的计算操作放在第二个阶段中。

图2 本文三阶段式问答模型整体框架Fig.2 Overall framework of proposed three-stage question answering model
1.1 任务定义
本文只关注抽取式的问答任务,在抽取式问答任务中,问题的答案是给定上下文中的一个片段,可能是一个词、一个词组,也可能是一个句子。因此抽取式问答模型的任务实际上就是预测出答案在原始上下文中的开始位置和结束位置。
1.2 预回答阶段
1.2.1 低层特征表达
神经网络模型不能直接处理文本序列,因此需要将文本表示为向量形式才能被模型所处理,这一过程称为词嵌入(Embedding)。在进行词嵌入前,还需要将文本序列进行分词,即将一段文本表示为字或词的有序列表集合。使用Q={q1,q2,…,qm}来表示给定问题分词后的长度为m的单词序列,P={p1,p2,…,pn}表示给定上下文分词后的长度为n的单词序列。对于基于BERT 的问答模型而言,需要将问题及上下文按照先后顺序拼接在一起,定义T={[CLS],q1,q2,…,qm,[SEP],p1,p2,…,pn,[SEP]}表示拼接后长度为L的输入序列,并且L=m+n+3。在BERT 中,[CLS]是添加在每个输入的序列样本前的特殊标记,用于指示序列的开始;[SEP]是特殊的分隔标记,T中第一个[SEP]用于分隔问题和上下文,第二个[SEP]用于指示样本的结束位置。嵌入层的作用是将输入文本转化为向量的形式以便被模型所处理,如图3 所示,BERT 中嵌入层最终输出的嵌入向量由三种嵌入向量相加而得:词嵌入(token embedding)、句子词嵌入(segment embedding)和位置词嵌入(position embedding)。定义E={e1,e2,…,eL}表示BERT 中嵌入层最终的输出特征,L表示E的长度,ei∈表示序列T中对应位置的单词由文本转换嵌入至特征空间的向量形式。随后嵌入层的输出E将被输入至BERT 中的Transformer 结构进行深层次的编码,以获得具有更多语义及上下文关联信息的特征表达。

图3 BERT的输入表示Fig.3 BERT input representation
文献[20]中通过提出一种配对探针(Pairwise Probe)的机制来探索BERT 微调对机器阅读理解任务的影响,发现微调对基础和低层次信息以及一般语义任务的影响很小,而对于下游任务所需的特定能力,微调BERT 优于预先训练好的BERT。即BERT 中越底层结构学习到的特征表达所蕴含语义特征和文本信息的通用性就越强,与下游任务的相关性就越疏远;而越高层结构学习到的特征表达所蕴含语义特征和文本信息的通用性就越弱,与下游任务的相关性就越密切。嵌入层是BERT 中能够学习到文本特征表示的最底层,所以该层的输出蕴含通用性相对强的语义特征和文本信息,与下游机器阅读理解任务的关联性足够弱,因此可将嵌入层的输出E视作文本序列在BERT 中浅层次的特征表达。第一个阶段中的预回答过程将对E进行处理,以生成这个阶段预测的答案在上下文中的开始位置和结束位置。当然也可以使用其他表示学习模型的输出来代替BERT 中的浅层特征,但这样会引入外部的网络结构,增加模型整体的复杂度,并增加模型预测和推断时间。此外,本文主要是对BERT 在机器阅读理解任务上的表现进行改进,挖掘BERT 中浅层特征的价值,因此引入外部表示学习模型来获取浅层特征可以放在接下来的研究工作中。
1.2.2 答案预生成
文献[21]中通过进行详尽的实验,研究了BERT 在文本分类任务上的不同微调方法,发现利用BERT 中不同层次特征表示来做文本分类任务,层次越低,分类效果越差,并且随着层次的降低,分类错误率从5.42%上升至11.07%。此外文献[21]还对BERT 中各层特征的组合方式进行了探索和实验,主要是直接对各层特征进行拼接、求均值或求最大值这三个操作来获取文本的最终特征表示,并完成下游的文本分类任务,发现这些方式都不如直接使用最高层特征表示来做文本分类任务的效果好,甚至显著降低了在分类任务上的表现。因此直接对各层特征进行拼接、求均值或求最大值等方式处理各层特征不能提升BERT 在特定任务上的表现,这是因为直接按照上述方式处理各层特征会破坏微调BERT时高层结构针对特定下游任务已经学习到的特征表达,所以才会获得适得其反的效果。本文将不采取文献[21]中的方式对各层特征进行处理,而是对BERT 中的浅层信息和高层信息分别生成针对特定下游任务的预测结果,然后对两个预测结果进行组合以获取更好的预测结果。
抽取式问答任务的目标是根据给定问题在原文中找出答案片段,即答案是从原文中抽取出来的,不作任何改变。具体到模型的实现,一般是预测出答案在原文中的开始位置和结束位置。因此该阶段将E直接输入至一个没有任何激活函数的全连接层Linear,获得针对答案开始位置的输出和结束位置的输出:
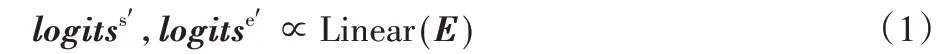

其中:表示答案开始位置的概率,表示答案结束位置的概率,二者都由阶段一产生。
1.3 再回答阶段
1.3.1 高层特征表达
BERT 中对嵌入向量进行深层次编码的核心结构是双向的Transformer 层[22],Transformer 使用注意力机制捕获文本之间的关联。如图4 所示,BERT 内部就是数个这样的Transformer 层的堆叠。BERT 之所以在众多NLP 任务中表现优异,不仅是因为它在大量无监督文本上进行了漫长的预训练过程,更重要的原因是Transformer 出色的编码能力。本文把第l个Transformer 层的输出定义为Xl,通过Xl=Transformer(Xl-1)计算得来,并且X0=E。
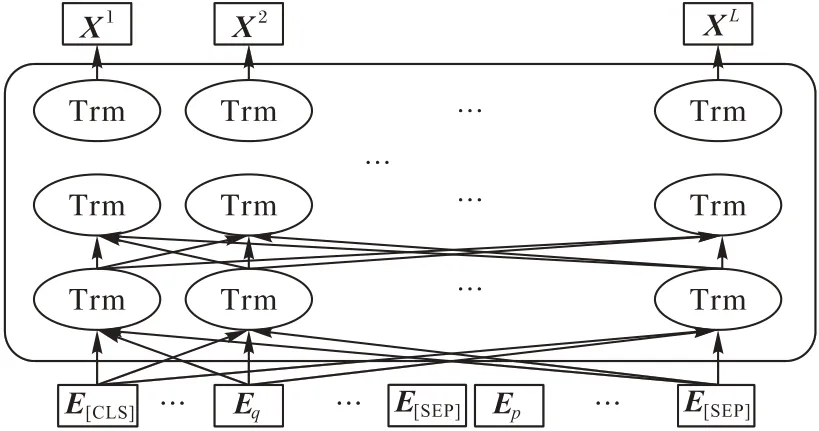
图4 BERT深层次特征编码过程Fig.4 Deep feature encoding process of BERT
对于每一层Transformer,通过多头注意力机制进行编码,定义多头注意力计算后的输出为,并按式(3)计算:

对于基于BERT 的问答模型,通常是直接使用最后一个隐藏层的输出状态作为后续模型的输入特征H,设BERT 中Transformer 层的个数为S,则H=HS=。
相较于嵌入层的输出E,经过深层次编码后的输出H蕴含更加丰富的语义信息以及上下文和问题之间的交互关系,可将H视作文本序列在BERT 中深层次的特征表达,事实上大多数已有的基于BERT 的NLP 模型都是在H的处理方式上进行网络模型的再设计。本文所提出模型的第二个阶段中的再回答过程将会对H进行处理,以生成这个阶段预测的答案在上下文中的开始位置和结束位置。
1.3.2 答案再生成
不同于预回答阶段,再回答阶段将使用具有更丰富语义和上下文信息的特征表达H来进行答案的预测。但与预回答阶段相同的是,这个也只使用一个独立的全连接层Linear来处理输入的特征表达,获得针对答案开始位置的输出logitss和结束位置的输出logitse:

其中:logitss和logitse的计算使用到了经过BERT 编码后更深层次的特征表达H,这与人类阅读文本的方式类似,第一次阅读一段文本时仅能利用到文本中较浅的信息进行阅读理解,而再次阅读文本时便能获取到更深层次的信息。这个阶段中答案开始位置的概率ps和结束位置的概率pe也由softmax 函数计算得到:

1.3.3 可回答性计算
现实世界中总是存在不可被回答的问题,问答模型需要巧妙地避免回答这些问题;并且近几年新提出的问答数据集中均包含不可被回答的问题,这给问答模型的设计带来了新的挑战。因此在模型中需要计算每一个“上下文-问题”对的可回答性(即给定一对上下文和问题,是否存在答案)。对于BERT 组后一层隐藏层的输出序列H而言,特殊标记[CLS]位置上的隐藏层向量h[CLS]∈H可以视作拼接后的文本序列在整体上的特征表达向量,对于问答模型来说就是“上下文-问题”对整体的特征。因此可以利用h[CLS]来计算对应“上下文-问题”对的可回答性。同样使用另一个独立的全连接层Linear 和softmax 函数来处理h[CLS],并使用交叉熵损失函数来计算针对可回答性的损失函数:
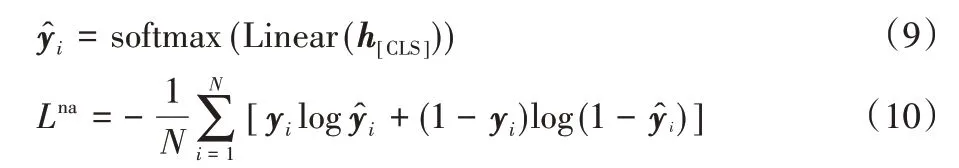
其中:表示预测出的可回答性,yi表示真实的可回答性,N表示训练时的样本数量。
1.4 答案调整阶段
在三阶段式问答模型的最后一个阶段,将利用前两个阶段预测出来的答案片段所在的位置进行位置的调整,改进预测答案的准确性,以获取最终的预测结果。使用logitsstart表示答案调整后的开始位置,logitsend表示答案调整后的结束位置。在本文方法中,logitsstart和logitsend按照式(11)~(12)进行计算:
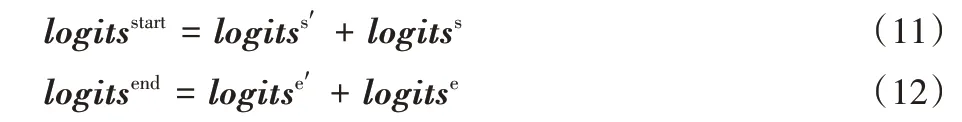
与前两个阶段相同,使用soft max 函数计算调整后的答案开始位置和结束位置在输入序列中每个位置上的概率:
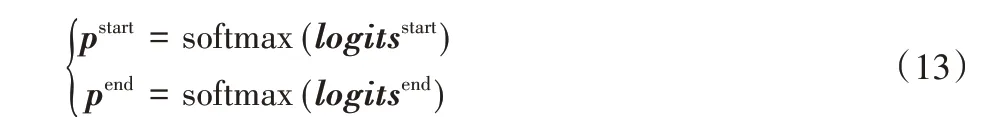
其中:pstart为答案开始位置的概率,pend为结束位置的概率。
最终调整后的答案预测的损失函数由交叉熵损失函数计算得来:

最终本文将针对“问题-答案”对的可回答性损失Lna加上调整后答案的损失Lans,作为整个模型的目标损失函数。使用Loss表示模型整体的目标损失函数,且计算式如下:

模型的目标就是在训练过程中最小化损失函数Loss的值,并在测试集上获得最好的效果。
2 实验与结果分析
2.1 实验数据
SQuAD(Stanford Question Answering Dataset)数据集[9]是抽取式问答任务的代表性数据集,数据来自于维基百科,目前SQuAD 数据集已经成为机器阅读理解任务中的基准数据集。SQuAD 数据集是由斯坦福大学的研究人员提出,最初的1.1 版本[3]中只存在可回答的问题,不符合现实世界中的情形,因此斯坦福大学在其基础之上增加了50 000 个不可回答问题,提出了SQuAD2.0(SQuAD 2.0)[9],进一步提高了数据集难度。2018 年第二届“讯飞杯”在其评测任务中发布了首个人工标注的中文篇章片段抽取式阅读理解数据集CMRC2018(Chinese Machine Reading Comprehension 2018)[2],填补了中文在这方面的空白,进一步促进了中文机器阅读理解的研究。
本文模型在英文数据集SQuAD2.0 和中文数据集CMRC2018 上进行评估,用以验证模型的性能和有效性。
如表1 所示,SQuAD2.0 中训练集样本数和测试集样本数均明显多于CMRC2018。本文使用CMRC2018 数据来评估模型,主要是验证本文模型在中文上的有效性。以CMRC2018 为例,展示抽取式问答任务的一个样本示例,如图5 所示。

表1 实验数据集统计信息Tab.1 Statistics of experimental datasets

图5 来自CMRC2018的某个问答样本Fig.5 A question answering example from CMRC2018 dataset
2.2 评估指标
抽取式阅读理解任务需要对模型预测的答案字符串和真实答案进行比对,因此一般使用SQuAD 数据集的发布者Rajpurkar 等[4]提出的EM(Exact Match)和F1(F1 score)值对模型进行评估。EM 是指数据集中模型预测的答案与标准答案相同的百分比,F1 是指数据集中模型预测的答案和标准答案之间的平均单词的覆盖率。
由于中文在结构和形式上与英文不同,因此EM 值和F1值的计算也略有不同,采用CMRC2018 数据集的发布者Cui等[2]改进后的EM 和F1 计算方式对模型在CRMC2018 数据集上的性能进行评估。
2.3 实验配置
本文的实验环境为:操作系统为Ubuntu18.04,CPU 为Intel Core-i9(3.60 GHz),内存为32GB,显卡为NVIDIA GTX2080TI 11 GB。模型的搭建采用深度学习框架PyTorch实现,并选择Base 版本的BERT 作为基准预训练模型进行三阶段问答模型的搭建和实现。首先针对中文和英文分别下载训练好的BERT-Base 模型参数;然后设置恰当的迭代次数(epochs)并使用训练对网络模型进行微调(fine-tune),按照显存容量设置合适的批样本容量(batch_size)和样本最大序列长度(max_seq_length)。同时根据随机失活率(dropout)、学习率(learning rate)与学习率的衰减值(warm-up rate)进行微调,直到训练的损失稳定收敛。上述参数的具体设置如表2 所示。

表2 参数设置Tab.2 Parameter setting
SQuAD2.0 数据集和CMRC2018 数据中采用官方划分的训练集对模型进行训练,在训练结束后采用官方划分的测试集对模型进行评估,并计算出EM 值和F1 值。
2.4 结果分析
对本文构建的三阶段问答模型、传统问答模型,以及只使用BERT 高层特征信息的模型分别使用相同数据集进行对比实验。
表3 展示了不同模型在英文数据集SQuAD 上的性能表现,包括V1.1(只包含可回答问题)和V2.0(包含不可回答问题)两个版本的结果。作为经典的传统问答模型,BiDAF[6]、Match-LSTM[12]、SAN(Stochastic Answer Networks)[18]、QANet[11]在V1.1 上的表现优异,但当问题中存在不可回答问题时(V2.0),EM 值和F1 值只能达到60%~70%,这说明传统模型无法应对现实世界中不存在答案的问题。而基准模型BERTbase只使用一个全连接层来处理高层特征编码,其EM和F1 就能分别达到74.4%和77.1%,这说明了BERT 对文本强大的编码能力,也是传统模型难以提升的瓶颈所在。即传统方法虽然在图1(a)所示的5 个网络层中都设计了非常巧妙的结构来搭建问答模型,但由于其采用的词向量技术具有非常大的局限性,如上下文信息不足、难以解决一词多义等问题,因此传统模型难以应对存在不可回答问题的真实场景。而基于前文可知,经过BERT 编码后的特征表达具有更丰富语义和上下文信息,于是在BERTbase之上融合这些经典的模型(+BiDAF、+SAN)来处理高层特征编码,以解决传统词向量技术不足带来的瓶颈,但相较于在BERT 后只使用一层全连接网络(BERTbase),+BiDAF、+SAN 的提升并不明显,且由此带来的问题是训练速度和推断速度的大幅下降,这也说明只利用BERT 深层编码特征进行答案预测已经无法显著提升问答模型的表现。而本文所提出的模型(+本文模型)在SQuAD2.0 上EM 值达到了76.8%,F1 值达到了78.7%,相较于BERTbase分别提升了2.4 和1.6 个百分点,同时在SQuAD1.1 上也能达到较高的水准。此外本文模型并未在模型中添加复杂的网络结构,而仅使用一个额外的全连接层对BERT 嵌入层输出进行处理以生成“预回答”阶段的答案,在获得不错效果提升的同时,训练速度和推断速度也没有明显下降。
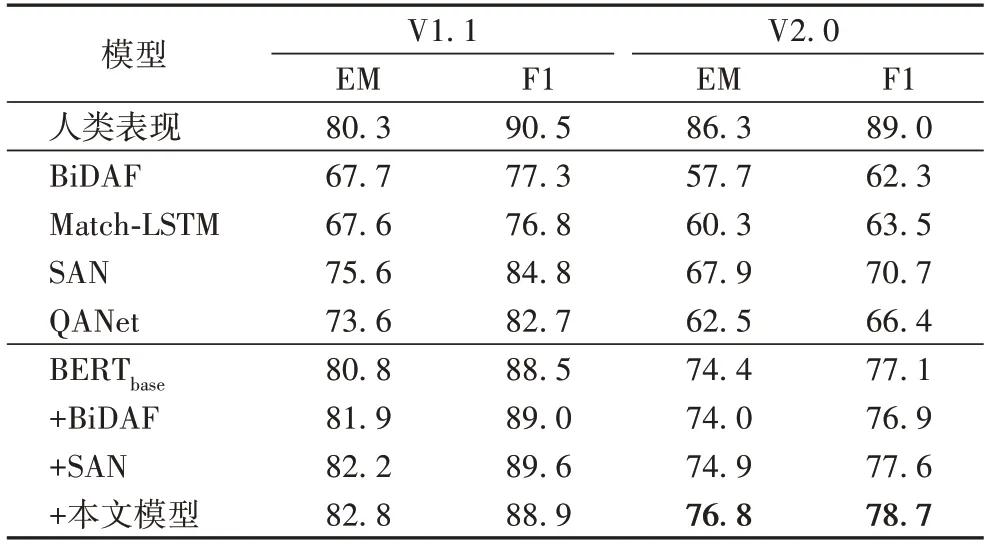
表3 SQuAD数据集上不同模型的结果对比 单位:%Tab.3 Result comparison of different models on SQuAD dataset unit:%
由于针对中文语料库CMRC2018 的抽取式问答研究较少,本文只选择了五个典型的传统模型和BERT 基准模型,与本文所提出的三阶段式问答模型进行了对比,对比结果如表4 所示。从表4 可以看出,基于BERT 三阶段式问答模型的预测准确性明显高于五个典型的传统问答模型,EM 达到了65.0%,F1 达到了85.1%,相较于基准模型BERTbase分别提升了1.4 和1.2 个百分点,这说明三阶段式的问答过程在中文上也同样适用。

表4 CMRC2018数据集上不同模型的结果对比 单位:%Tab.4 Result comparison of different models on CMRC2018 dataset unit:%
图6 以中文数据集CMRC2018 为例,对比展示了基准模型BERTbase和三阶段问答模型对某个“上下文-问题”对的答案片段的预测结果,可以看见本文模型与正确答案完全一致;而BERTbase的预测片段遗漏了“地区”这个词,预测结果不够完整。这说明在三阶段模型中的“答案调整”阶段,通过综合利用前两个阶段预测出的答案片段对片段所在位置进行调整,可以获得更加准确完善的答案片段,从而提高了模型的性能。

图6 CMRC2018数据集上的答案片段预测对比Fig.6 Answer fragment prediction comparison on CMRC2018 dataset
基于上述结果分析可知,本文所提出的基于BERT 的三阶段式问答模型在中英两种语言的数据集上都取得了较好的结果,且模型训练速度和推断速度没有明显降低,这说明融合BERT 嵌入层的浅层特征表达和完全编码后的深层特征表达可以显著提升问答模型的性能,实验结果也验证了本文模型的有效性,以及在多语言任务上的适用性。
3 结语
本文提出了一种基于BERT 的三阶段式问答模型,除使用经BERT 完全编码后的高层特征信息,还利用到了BERT嵌入层中浅层特征信息,然后通过预回答、再回答、答案调整三个阶段对模型预测的答案片段进行调整,生成更加准确的答案片段,并对问题的可回答性进行了评估以应对现实世界中往往存在不可回答问题的现状。通过这种方法,避免了BERT 中浅层信息的浪费,提高了问答模型预测答案片段的准确性,一定程度上解决了基准模型预测出的片段不完整的问题。此外,还在中英两种语言的数据集上进行了一系列实验,验证了本文模型在多语言上的适用性。
在未来的研究工作中,可以通过在“预回答”和“再回答”两个阶段加入其他结构如循环神经网络和注意力机制继续处理BERT 中的低层特征和高层特征,进一步提高三阶段式问答模型在公开数据集上的表现。另外,还可以引入外部表示学习模型如循环神经网络和卷积神经网络等结构的输出代替本文提出的BERT 浅层特征,用以改进模型性能。最后,对于“答案调整”阶段,可以加入其他辅助信息,如考虑将位置信息、外部知识等作为补充,使模型预测的结果片段更加精准。
猜你喜欢
黄河之声(2022年10期)2022-09-27
北京航空航天大学学报(2022年8期)2022-08-31
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化·高二版(2022年4期)2022-05-09
河南教育·职成教(2022年5期)2022-05-06
中国典型病例大全(2022年7期)2022-04-22
小学生学习指导(中年级)(2021年12期)2021-12-30
课堂内外(高中版)(2021年8期)2021-01-17
莫愁(2019年36期)2019-11-13
