
基于改进U-net网络的气胸分割方法
2022-02-24 12:35王康健何灵敏胥智杰王修晖
计算机工程与应用 2022年3期
余 昇,王康健,何灵敏,胥智杰,王修晖
1.中国计量大学 信息工程学院,杭州 310018
2.中国计量大学 浙江省电磁波信息技术与计量检测重点实验室,杭州 310018
气胸属于胸外科和呼吸内科急症[1],是肺部常见疾病之一,约有30%~39%的胸部外伤患者存在气胸,大多是由钝性胸部损伤、潜在肺部疾病造成的。气胸是指空气从肺部泄漏到肺和胸壁之间的一种病状,会对肺部产生压迫阻止肺部的正常扩展,导致病人呼吸困难甚至不能呼吸。如果不治疗,就会导致死亡。在欧美等西方国家,平均每年大约有13万~21万例气胸[2],而且复发率高达35%[3]。更可怕的是,该疾病的发作没有任何明显的征兆。因此,如何有效地检测潜在气胸成为一个很有价值的问题。
诊断该疾病的传统方法是由放射科医生通过胸部X光(胸片)根据经验用肉眼进行检测。但是因为气胸的病灶形状、大小有很大差异,通常与肋骨、锁骨等组织重叠,而且基于人工的检测结果易受医生经验等主观影响,在临床上存在较大的漏诊。即便对于经验丰富的放射科医生来说,阅片也是一项复杂、耗时的任务,且存在漏检的风险。据报道[2]美国平均每年约有7.4万气胸患者因延迟诊断或误诊而耽误治疗,同时在中国对于少量或微量的气胸,也存在较大的漏诊情况[4]。因此希望借助于计算机辅助诊断(computer-aided diagnosis,CAD)系统,实现X线气胸的自动检测,协助医生提高诊断效率和准确率,减少漏诊。
实际应用中,实现胸部X线气胸的自动检测面临以下问题:受患者气胸形状、大小、拍摄角度、图像质量以及放射参数等因素影响,胸片图上气胸的特征变得模糊。此外,气胸容易与皮肤褶皱、肩胛骨、锁骨以及胸腔引流位置重叠,也在一定程度上干扰气胸特征的提取。而传统的气胸检测方法需要手动设计不同的特征提取算法,如:Geva等[5]首先对局部异常进行纹理分析处理。在纹理分析过程中提取带标记的图像小块,然后将局部分析值合并到新的全局图像表示中,再用于图像层面的异常训练和检测。基于肺的独特形状,考虑到典型气胸异常的特征,提出了结合局部和全局纹理特征分析方法。Sanada等[6]首先确定易出现轻微气胸的上肺各区域的感兴趣区域(ROIs)。然后,通过在有限的方向范围内选择边缘梯度来确定的后肋和胸膜的位置,并去除包括在边缘增强图像中的肋边缘。最后利用霍夫变换检测出气胸引起的细微曲线。Chan等[7]首先利用局部二值模式从肺图像中提取特征,然后利用支持向量机对气胸进行分类。另一方面提出了一种基于多尺度强度纹理分割的气胸自动检测方法:通过去除胸腔图像中的背景和噪声,对肺异常区域进行分割。这些特征提取的过程十分复杂,且提取的特征可能存在信息涵盖不全等现象,从而导致气胸的检测精度不高。因为上述气胸检测方法对特征提取的准确性要求非常严格,而气胸特征提取的准确性决定了检测结果的精度,导致传统气胸检测方法的鲁棒性不够。
随着深度学习的发展,以卷积神经网络(convolutional neural network,CNN)为代表的神经网络在计算机视觉领域的成功应用为CNN在医学图像病变检测方面的应用奠定了基础。CNN一般由输入层、卷积层、池化层、激活层以及全连接层组成,自动学习从原始输入到期望输出间的特征映射。相较于传统算法复杂的特征提取过程,CNN在高级抽象特征提取上的能力更显著,尤其是对细粒度图像的识别具有极大的优势和潜力[8]。Wang等[9]首次提出用残差网络(residual network,ResNet)来检测胸部疾病,并公开了一个超大规模的胸部数据集:ChestXray14,该算法在气胸检测上取得了较好的结果,曲线下面积(area under curve,AUC)为0.79。虽然现有基于深度学习的气胸检测方法能有效提升检测性能,但是因为传统的卷积神经网络主要用来处理分类问题或者回归问题。当使用CNN来检测疾病时,因为缺乏解释性,对医生的帮助有限。Long等[10]在CNN的基础上,创造性地提出了一种全卷积神经网络(fully convolutional network,FCN)。他们用卷积层替换CNN中的全连接层以获得图像中每个像素的分类结果,最终实现图像分割。U-net[11]是下采样和上采样结合的编解码结构的分割模型,在2015年ISBI细胞追踪竞赛中获得了冠军,被广泛应用于医学影像学中。Oktay等[12]在U-net的基础上引入注意力机制提出Attention Unet,对编码器在各个分辨率上的特征与解码器中对应特征进行拼接之前,使用了一个注意力模块,重新调整了编码器的输出特征。注意力权重倾向于在目标器官区域取得大的值,在背景区域取得较小的值,提高了图像分割的精度。Xiao等[13]提出了一个带有注意力机制和跳跃连接结构的ResUnet模型用于处理视网膜血管分割中小而薄的血管分割困难以及视盘区识别能力低等问题。Chen等[14]提出了空洞空间金字塔池化结构,该结构能够获取不同尺度的特征信息,结合多种先进的方法设计了DeepLabV3+,是目前最优秀的通用分割网络。然而,虽然图像分割在医学影像学中有被应用的先例,但在气胸分割方面还没有得到很好的应用。
本文的主要创新如下:
(1)网络结构:基于U-net网络架构,结合MBConv-Block编码模块和一种新的解码模块设计了EfficientUnet卷积神经网络X线气胸分割模型。该模型能有效提取图像特征,预测图像中是否含有气胸并进行图像语义分割。
(2)损失函数:在语义分割中Dice相似系数(Dice similarity coefficient,DSC)损失函数的基础上,结合Focal损失函数,组成混合损失函数。该混合损失函数保证了网络能够稳定且有针对地对难以学习的样本进行优化,从而缓解类不平衡问题,改善网络的分割结果。
(3)阈值分割策略:针对小面积气胸的漏检及误检,提出三重阈值分割策略,降低假阴性的概率。
(4)由于成像设备、个体自身差异的影响,医学图像一般会含有很多噪声。对胸片进行对比度限制自适应直方图均衡化,去除噪点并还原图像细节。
1 基于卷积神经网络的气胸分割方法
本文结合了目前深度学习领域中的最佳工作,提出了一种结合MBConvBlock编码器模块的EfficientUnet卷积神经网络X线气胸分割模型。对输入的胸部X线图像进行处理,从而预测胸片中是否含有气胸。针对卷积神经网络存在解释性不够的问题,进行图像语义分割,并给检测含有气胸的胸片输出相对应的掩码,最后通过游程编码(RLE)可视化掩码,医生可以很直观地判断患者是否患有气胸并降低诊断的假阴性概率。
1.1 EfficientUnet
基于卷积神经网络实现的任务,无论是目标检测还是分类的算法,特征提取部分永远是最重要的基础。目前的深度学习理论已经证明增加特征提取的网络深度可以获得更多的语义信息,提高分类准确度。除了传统的卷积神经网络模型,也可以利用空间金字塔模型,通过融合多个不同尺度的特征图得到更加丰富的特征信息来提高分类准确度。而与目标检测或分类算法不同的是,图像语义分割算法不仅需要获取目标的特征信息做到像素级的分类,而且还需对图像进行还原到原尺寸的恢复,图像像素位置信息恢复得更加准确,分割结果更好。
本文从特征提取部分和恢复像素位置信息两个方面入手,根据基本的U-net网络结构,结合MBConv-Block编码器模块和新的解码模块设计了一种改进的EfficientUnet模型,其网络结构如图1所示。
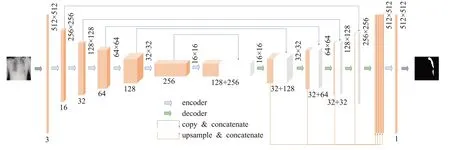
图1 EfficientUnet网络结构Fig.1 EfficientUnet network structure
本文采用的MBConvBlock编码器模块来自于EfficientNet[15]卷积神经网络。该模型在ImageNet数据集上获得84.4%的Top-1精度和97.1%的Top-5精度,超越了此前表现最好的GPipe,并且速度相比GPipe提高了6.1倍。和已有的CNN模型进行对比,EfficientNet模型准确率更高、效率更高,其参数量和FLOPS都下降了一个数量级。而且模型大小方面,EfficientNet也比其他模型要小得多。对比工业界使用最多的ResNet-50[16],准确率也是胜出一筹(ResNet-50的76.0%,EfficientNet-B4的82.6%)。如表1所示。
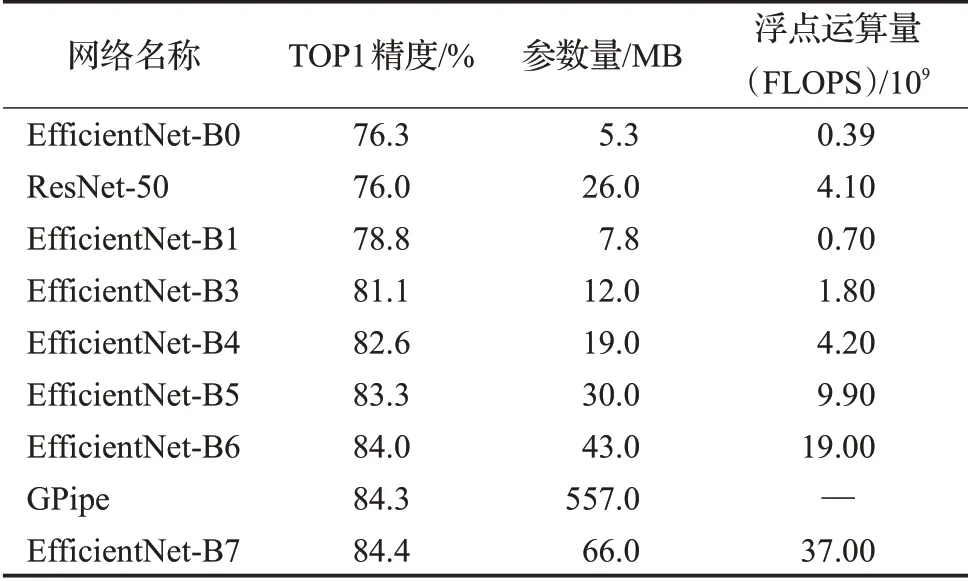
表1 模型性能对比Table 1 Model performance comparison
EfficientNet模型综合考虑网络深度、网络宽度以及图片分辨率这三个影响卷积神经网络处理图片性能的因素。单独增加其中任意一项都会提高结果的精度,但是任意一项参数的不断增加又会导致参数增加的精度回报率降低,所以抽象出网络深度、宽度、分辨率这三个维度的最优组合问题,其定义如下:
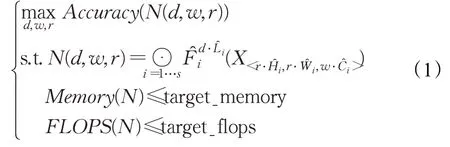
其中,N代表整个卷积网络,d、w、r分别是网络高度、网络宽度、分辨率的倍率,X i为输入张量,<Hi,Wi,C i>为网络的输出维度(省略了Batch维度)。文献[15]通过三个维度的网络搜索,最后得到了EfficientNet-B0。在计算量相当的情况下得到了比之前提出的模型更高的精度,更小的模型体积(参数数量),兼顾了速度和精度。
EfficientNet-B0主体是由16个MBConvBlock堆叠构成,MBConvBlock的结构如图2左侧所示,其总体的设计思路是Inverted Residuals结构和残差结构,每个模块主要包含四个卷积层,一个深度可分离卷积和一次特征融合操作。在3×3网络结构前利用1×1卷积升维,在3×3网络结构后增加了一个关于通道的注意力机制,最后利用1×1卷积降维后增加一个残差边。对于输入MBConvBlock模块的特征图,在每经过一系列卷积操作后,所产生的特征图便与最原始的特征图进行融合形成新的特征图,最后再将特征图输入下一个MBConv-Block模块。此外,每个卷积层后面均添加了批量归一化(batch normalization,BN)层和(Swish)激活层[16],定义如公式(2)所示:

图2 编码/解码模块示意图Fig.2 Schematic diagram of encoding/decoding module

其中,批量归一化层是为了解决网络的训练效果容易受到初始数据分布的影响,模型泛化能力差等问题而提出的,会对输入数据进行归一化操作。EfficientNet-B0是整个系列的基石,其他的版本都是在B0基础上增加MBConvBlock的数量。EfficientNet根据不同尺度的图片构建了8个模型,本文根据实验效果选择了EfficientNet-B3。
传统的解码器(Decoder)对提取到的特征映射进行插值重构得到每个像素的二分类结果。本文扩展路径所用的解码模块是通过多次测试出来的最优结构,如图2右侧所示。解码器模块主要包含两个3×3卷积和两个scSE(spatial and channel squeeze&excitation block)注意力机制模块[17]。scSE将空间注意力机制(sSE)模块和通道注意力机制(cSE)模块并联,结合空间和通道注意力机制。具体就是将输入特征图分别通过sSE和cSE模块后,然后将两个模块的输出相加,得到更为精准的Feature map,scSE的结构如图3所示。每个卷积层后面均添加了批量归一化层和修正线性单元(rectified linear unit,ReLu)激活层。激活层之后加入scSE模块可以带来细粒度的语义分割提升,能够让分割边缘更加平滑。在EfficientUnet的扩展路径中,反卷积的输出层先合并左边特征提取网络的跳跃接模块,然后通过解码器结构进行挤压激活操作,增加层与层之间的联系。最后利用上采样和反卷积到原图像大小,通过分割输出模块产生所需掩码的通道数,做像素级的分类。

图3 scSE模块示意图Fig.3 Schematic diagram of scSE module
1.2 损失函数
在以Dice指数为指标的二分类医学图像分割任务中,常用的损失函数是Dice相似系数损失函数,其定义如下:

Dice相似系数损失函数能够指导网络通过不断学习,让预测结果逐渐逼近真实结果。但是一旦预测结果中有部分像素预测错误,会导致预测目标的梯度变化剧烈,甚至出现无法收敛的情况。训练误差曲线非常混乱,很难看出关于收敛的信息,从而使得网络的训练变得困难。另外,虽然Dice相似系数损失函数能在一定程度上缓解类不平衡问题,但是对于微小气胸效果不够显著。因此本文提出一种改进的混合损失函数解决该问题,损失函数分为两部分,表达式如公式(4)所示:

LFocal是Focal损失函数[18],其引入主要是为了缓解类别不平衡问题。ypred反映了模型对这个样本的识别能力;α代表类别权重,用来平衡正负样本的比例不均,经过多次实验设定为10;(1-ypred)γ代表难度权重,调节参数γ来减少易分类样本的损失;对于ypred越大的样本,越要抑制它对loss的贡献。Focal损失函数的定义如下:

训练时迭代次数的选择对网络的分割性能十分重要。如果训练迭代次数太少,图片中的气胸特征信息没有被充分挖掘,模型无法很好地拟合训练数据的分布会出现欠拟合状态。但是,如果训练迭代次数过多,模型过度依赖训练数据的分布会容易出现过拟合状态(Overfitting),即神经网络过分追求拟合效果,学习到了在训练数据中完全没有意义的特征。为了防止上述情况,训练过程中通过对比验证集上的Loss值,自动选择小的保存模型权重。通过观察实验过程中验证集上的Loss的变化确定合适的训练迭代次数。图4展示了在训练过程中EfficientUnet在训练集和验证集上的损失值随着训练迭代次数变化的曲线图。从图中可以看出网络的损失值随着训练迭代次数的增加而不断降低,当训练迭代次数接近60时,验证集的损失值趋于稳定。因此,本文第一阶段实验中的训练迭代次数设置为60。
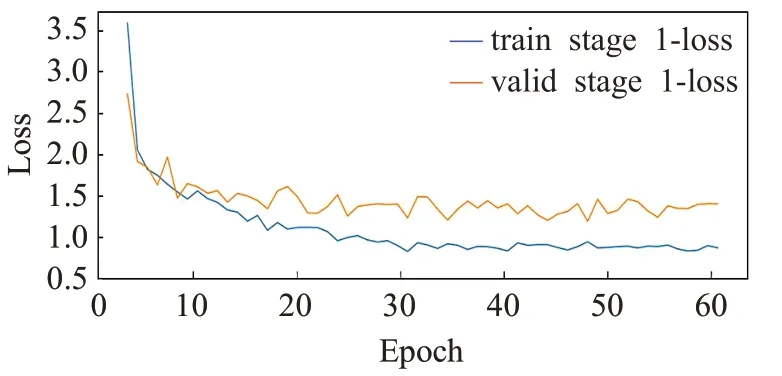
图4 EfficientUnet损失值变化Fig.4 Change of EfficientUnet loss value
1.3 三重阈值策略
语义分割模型的输出为Sigmod激活函数输出的每个像素的分类概率,因此关键需要对每一个像素点判断其是否为气胸像素。针对小面积气胸的漏检情况,本文提出一种新的阈值策略:三重阈值策略。本策略主要对模型最后的输出采用了三重不同的阈值策略:对经过最大阈值(top score threshold)的掩码图片,统计整张图片中预测为气胸像素的面积和,若小于该最小面积阈值(min contour area),则认为是无气胸图片。如图5左侧所示,对于相同的阈值参数:最大阈值0.5,最小面积阈值3,上面这张图的气胸像素面积为4,认定该图片含有气胸。而下面这张图的气胸像素面积为2,认定为不含气胸图片。这是目前图像分割领域比较主流的阈值策略,相比原始的单阈值策略更加严谨,但是对于医学图像分割任务来说适用性不够。本文在此基础上追加了一个最小阈值(bottom score threshold),经过双重阈值筛选后再次判断像素输出概率值大于最小阈值0.3就会被最终认定为是气胸像素。算法流程如图5右侧所示,发现使用该策略后最终两张图都检测出含有气胸。此举是为了在满足传统的阈值判断前提下,适当降低分割阈值,尽量检测可能存在的病灶区域。该策略虽然可能会增大检测结果中假阳性的概率,导致模型评估指标降低。但是从实际医学的角度来看,在可能存在气胸的情况下,对病人来说假阴性比假阳性更严重。
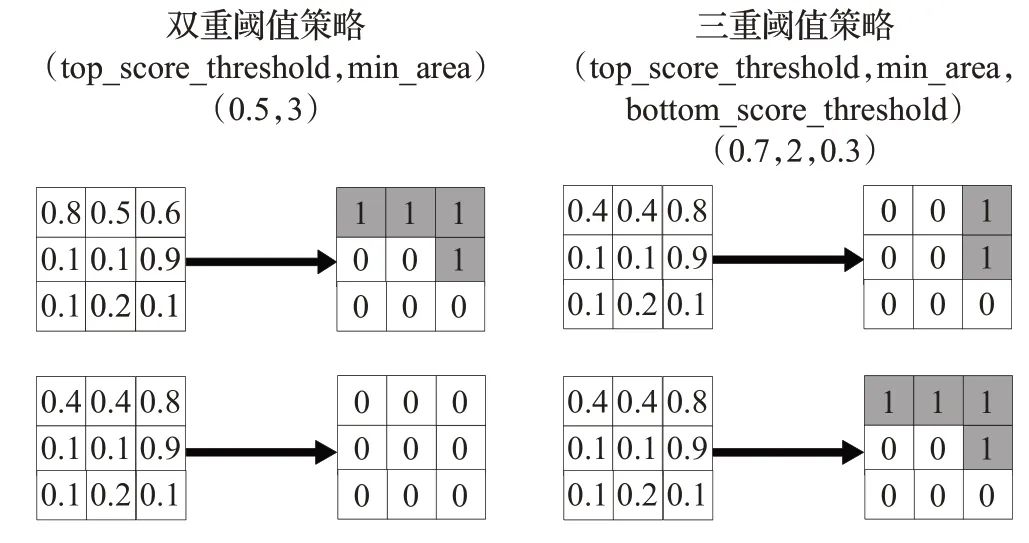
图5 双重/三重阈值策略Fig.5 Dual/triple threshold strategy
2 实验与分析
2.1 实验设置
2.1.1 数据集及评价指标
本文实验所用的SIIM-ACR Pneumothorax数据集是由美国医学图像信息学会(society for imaging informatics in medicine,SIIM)和美国放射学院(American college of radiology,ACR)提供的,开源在Kaggle平台。数据集包含12 089个DICOM文件作为训练集,3 205个DICOM文件作为测试集(digital imaging and communications in medicine,DICOM),即医学数字成像和通信。DICOM被广泛应用于放射医疗,心血管成像以及放射诊疗诊断设备(X射线、CT、核磁共振、超声等),并且在眼科和牙科等其他医学领域得到越来越深入广泛的应用。所有患者的医学图像都以DICOM文件格式进行存储。这个格式包含患者的PHI(protected health information)信息,例如姓名、性别、年龄,以及其他图像相关信息。医学图像设备生成DICOM文件,医生使用DICOM阅读器(能够显示DICOM图像的计算机软件)阅读并对图像中发现的问题进行诊断。
实验分成两个阶段,第一阶段将训练集划分成10 712个DICOM文件的训练集,1 377个DICOM文件的测试集。使用了3种评价指标:Dice、Recall、Precision,表达式如式(6)~(8):
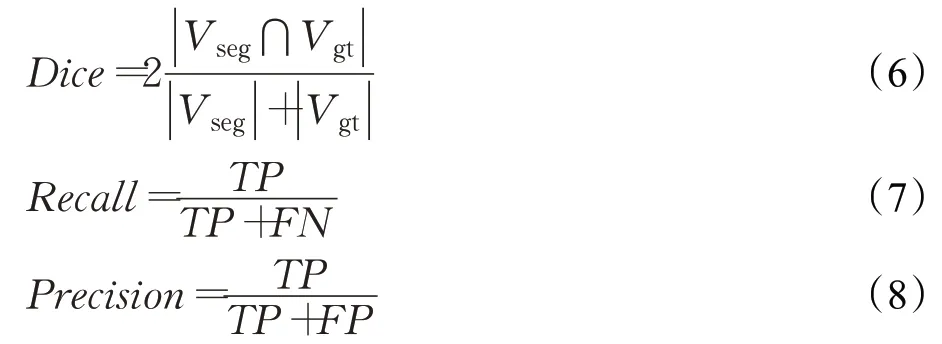
TP、TN、FP和FN分别表示真阳性、真阴性、假阳性和假阴性的数量。Dice指标是医学图像中的常见指标,可用于比较预测的分割结果与其对应的真实情况之间的像素方式一致性,常用于评价图像分割算法的好坏。准确率是指被正确预测为气胸的像素总数占被预测为气胸的像素总数的比例。召回率是指被正确预测为气胸的像素总数占实际像素总数的比例。上述指标用于气胸分割结果的综合评估,它们的值越大代表分割结果越好。第二阶段将第一阶段的训练集和测试集合并成新的训练集,另有包含3 205个DICOM文件的测试集。因为测试集的标签未公开,所以第二阶段的实验结果以竞赛中排行榜得分为准,即测试集中所有图像的Dice系数的平均值。
2.1.2 实验环境
硬件环境为NVIDIA TITAN X显卡,128 GB运行内存,Intel E5-2678V3处理器。软件环境为Ubuntu16系统,Python3.6,Tensorflow1.12.0和Pytorch1.1开发环境。
2.2 实验细节
数据预处理:首先利用Pydicom库将全部DICOM文件转换成PNG文件。原图大小为1 024×1 024,先将图片缩放成512×512,为了加快训练时梯度下降求最优解的速度对图像再进行标准化(Normalize):mean=(0.485,0.456,0.406),std=(0.229,0.224,0.225)。为了进一步提升细节特征,方便神经网络提取更多特征,同时能够较好地抑制医学图像成像过程中产生噪点,本文采用对比度限制自适应直方图均衡化(CLAHE)算法对图像进行处理进行后续研究[19]。直方图均衡化算法(AHE)会将图像采集过程中的噪点增强,且增强幅度较大。CLAHE同普通的自适应直方图均衡化不同的地方主要是其对比度限幅。这个特性也可以应用到全局直方图均衡化中,即构成所谓的限制对比度直方图均衡。在CLAHE中,对于每个小区域都使用对比度限幅来克服AHE的过度放大噪音的问题。另外经过对比度限制自适应直方图均衡化之后,图像的对比度会有所增强,图像的细节能更清晰地展现出来,方便神经网络提取特征。从图6中可以看出处理后的图像噪点减少很多,而且气胸区域显得更加明显。
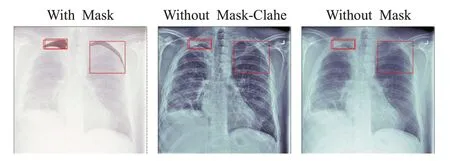
图6 对比度限制自适应直方图均衡化效果Fig.6 Contrast constrained adaptive histogram equalization
迁移学习以及数据增强:神经网络对特征的学习需要大量经过人工标记样本的训练以及测试样本,如用于视觉对象识别的ImageNet数据集[20]包含1 000个类别的超过120万张高分辨率图片。大部分情况下,数据集的规模是无法满足深度神经网络的训练要求的,往往会出现过拟合的现象。导致模型在测试集上的表现远没有在训练集上的那么好,网络不具有鲁棒性。本文使用多种数据增强方法扩大数据集,增强模型的抗过拟合和抗干扰能力,包括:高斯噪声、随机放射变换、随机垂直或水平翻转。另外为了加快模型的学习速度,本实验使用迁移学习,将已经在ImageNet数据集上训练好的EfficientNet参数作为特征提取模型的初始参数,在此基础上进行微调(fine tune),继承模型从ImageNet数据集上学习到的特征提取能力。
滑动采样训练策略:在原数据集中,有气胸的图片只占到了约28.37%,因此正负样本数量是不均衡的,对模型的收敛速度以及效果会造成较大影响。因此在训练中,对数据进行了滑动采样策略(sliding sample rate)。具体来说,就是在当前训练批次(batch),对数据进行随机采样,使正负样本达到1∶1的比例,如图7所示。

图7 滑动采样训练策略Fig.7 Sliding sampling training strategy
实验超参数设置:使用了Adam优化器,batch-size设置为2,初始学习率为0.000 1。学习率衰减方式为ReduceLROnPlateau,当连续训练3个epoch而模型性能不提升时,学习率衰减为原来的1/10。损失函数的参数以及训练迭代的次数按照1.2节中提到的策略设置。
2.3 对比模型
为了验证本文方法在气胸X光图像上的分割性能,将本文方法与现有方法U-net方法[11]、Attention Unet方法[12]、ResUnet方法[13]、DeepLabV3+方法[14]进行了对比实验。两个阶段上述网络的训练过程和EfficientUnet网络的训练过程完全相同,均采用5折交叉验证(5-foldcross-validation),分别训练预处理后的5份数据集。两个阶段实验分别训练60和100个epoch(停止标准与第一阶段实验相同),保存得分最高的模型。
2.4 分割性能对比及分析
训练完成后,在SIIM-ACR Pneumothorax测试集上评估算法的分割性能。两个阶段的实验分别按照2.1.1小节中的评分标准和竞赛评分的标准(mean Dice)进行评估,两个阶段的对比实验结果如表2、表3所示。
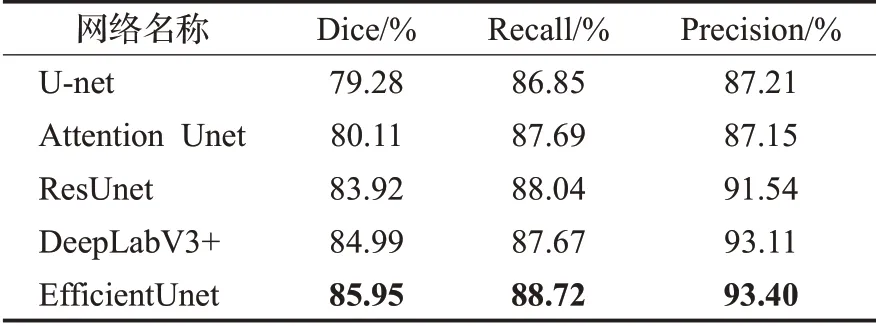
表2 第一阶段实验结果对比Table 2 Phase 1 comparison of experimental results

表3 第二阶段实验结果对比Table 3 Phase 2 comparison of experimental results
第一阶段实验在测试集上达到的Dice相似系数值、精确率和召回率分别为85.95%、93.40%和88.72%(不使用三重分割阈值策略),可以看出本文提出的Efficient-Unet相比之前提出的一系列医学图像分割网络性能均有较大的提升。与原始的Unet算法相比,分别提升了6.67、1.87和6.19个百分点。对比最先进的DeepLabV3+方法也有一定的提升,分别提升了0.96、1.05和0.29个百分点。第二阶段实验EfficientUnet在测试集上达到的Dice相似系数值对比U-net方法、Attention Unet方法、ResUnet方法、DeepLabV3+方法分别提升9.41、6.32、1.49和0.69个百分点。实验结果表明,本文提出的网络结构能够改善对气胸的分割效果。
为了验证三重阈值分割策略的有效性,做了一系列实验。表4展示了分割结果在不同阈值参数下对EfficientUnet性能的影响,第一行是使用双重阈值分割策略的结果,作为基准。从实验结果来看,三重阈值分割的效果与三个阈值的设置密切相关,改变参数会使三种指标均呈现不同的变化。作为分割任务,Dice相似系数值是衡量结果好坏的主要参考指标。从表中可以看出当最大阈值(表中为Top)取值为0.5、最小面积阈值(表中为Area)取值为2 500、最小阈值(表中为Bottom)取值为0.35时,网络的性能表现最佳。与使用双重阈值策略的EfficientUnet算法相比,三个指标分别提升了1.26、0.24和1.41个百分点。分析可知,相比双重阈值,表4第二行这种“宽容”的小参数设置能有效提高对小面积气胸的检测效果,Dice相似系数值和精确率都有较明显的提升。使用“严格”的大参数设置能有效提高召回率,但是Dice相似系数值和精确率基本没有改善,甚至有降低的表现。

表4 不同阈值参数对结果的影响Table 4 Influence of different threshold parameters on results
实验发现,最大阈值取0.5时,总体效果比取其他值都要好。分析得到最大阈值的取值和网络训练时阈值的取值相关。本实验网络训练时采用的阈值为0.5,故使用该策略分割时最大阈值应该选用网络训练时使用的阈值。另外,最小面积阈值取2 500和最小阈值取0.35作为组合时,是实验中各最大阈值分组中效果最好的。虽然该策略能有效提高分割的效果,但是增加了调参的难度。需要通过实验挑选有效的参数,不然效果反而会变差。
五种网络的分割结果的可视化如图8所示,图中第一列是输入模型的胸透图片以及医疗专家标注的气胸轮廓真实标签,最后一列是使用EfficientUnet结合三重阈值策略对气胸分割的结果。文献[12]和文献[13]方法相较于U-net,分割效果均有一定的提升。但是只能实现对气胸的大致定位,分割效果不够精细。对比观察图中前两行的图像,当气胸在图像中所占比例较小,且含有多个病灶区域时,上述方法均存在较大的漏检情况。未改进的U-net网络由于每一层所提取的特征通常只被学习一次,不同层次的特征之间联系不够密切,因此网络对于特征的利用率较低,更容易受到与病灶相似的干扰区域的影响,最终的分割准确率不够。其结果中有检测不出图片存在气胸的情况。文献[14]方法对大面积的气胸分割效果较好,分割出来的形状和边缘与真实标签比较接近。但是通过观察第一行和第四行,可以发现当图像中存在不连通的微小病灶区域时,也存在较严重的漏检情况。
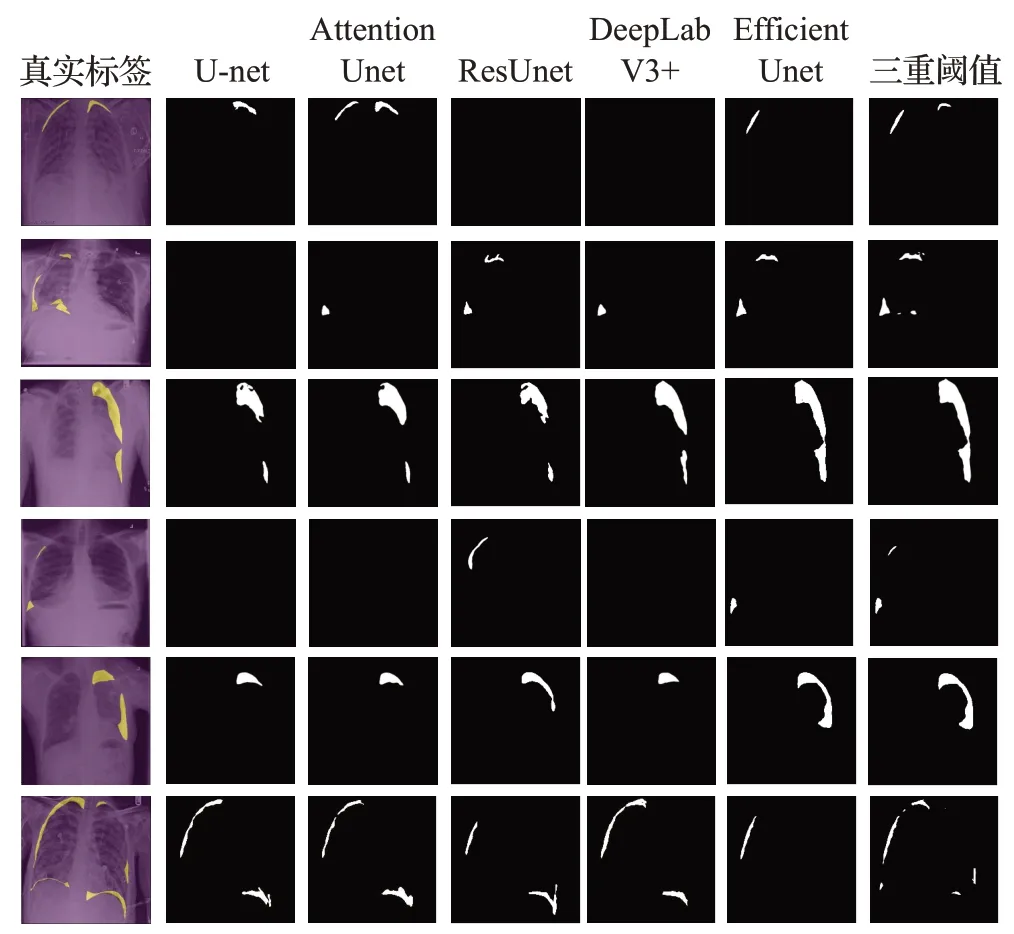
图8 不同模型的气胸分割结果图Fig.8 Pneumothorax segmentation results of different models
相比之下,本文提出的EfficientUnet能够有效地区分气胸与其他肺部组织,对气胸轮廓的预测更为精确。由于医学图像数量少,且目标区域与背景的比例差距较大,对其提取特征较为困难。该网络采用多个编码模块堆叠,加深网络的方式充分提取气胸特征更适合于医学图像分割任务。通过跳跃连接方式,利用简单特征用于像素准确定位以及抽象特征用于像素准确分类的特点,将两者结合从而帮助网络得到更为精细的分割结果。通过对比图8后两列,可以发现后处理时使用三重阈值分割策略有效的减少小面积气胸的漏检情况。综上所述,本文提出的气胸分割方法与其他分割算法相比,分割效果得到显著提升,在针对微小或边界模糊的气胸的分割过程中鲁棒性高,具有良好的性能。
3 结束语
气胸X线图像分割是实现气胸疾病精确显示、诊断、早期治疗和手术计划的关键一步。本文提出了一种新型的X线气胸分割方法,模型通过结合MBConv-Block模块,相比于其他医学图像分割网络在特征提取能力上有极大的提升,使得网络能够有效检测气胸。并且创造性地使用三重阈值分割策略更加准确地分割出小面积的病灶区域,在SIIM-ACR Pneumothorax数据集的实验中性能表现良好。实验采用对比度限制自适应直方图均衡化对图像进行预处理,发现该方法对特征提取有较大的帮助,能有效去除医学图像中存在的噪点。上述的方法具有一定的泛化性,不仅适用于气胸的检测与分割,对其他医学图像分割研究也有参考价值。另外,实验发现不同的数据增强和阈值参数都对实验结果有较大的影响。对于数据增强来说,现有的方法数量繁多。对于阈值参数来说,三个参数的不同组合也会产生很多不同的效果。上述两个方面都无法全部实验,只能尝试几种常见的组合。
因此在未来的工作中,除了考虑采用更好的特征提取网络结构之外,找出合适的数据增强方法,更好地挖掘胸透图片的信息,以及如何实现阈值参数的自动化选取将是下一步提高分割准确率的研究重点。
猜你喜欢
小哥白尼(军事科学)(2022年2期)2022-05-25
临床骨科杂志(2020年1期)2020-12-12
医学新知(2019年4期)2020-01-02
人人健康(2019年21期)2019-11-20
制造技术与机床(2019年9期)2019-09-10
中国保健营养(2019年4期)2019-09-10
红领巾·萌芽(2019年8期)2019-08-27
人人健康(2019年11期)2019-01-19
中国与非洲(法文版)(2017年10期)2017-11-23
CHIP新电脑(2016年3期)2016-03-10
