
面向小样本学习的嵌入学习方法研究综述
2022-02-24 12:31黄彦乾迟冬祥徐玲玲
计算机工程与应用 2022年3期
黄彦乾,迟冬祥,徐玲玲
上海电机学院 电子信息学院,上海 201306
在十几年来,计算机科学技术的迅猛发展,产生的数据也随之爆炸性增长,对大量数据强大的处理分析能力的需求使得机器学习跻身当今时代热门的话题之一。作为人工智能的子领域,看似无所不能的机器学习,在数据分析的进程中逐渐暴露出一系列问题[1-2],其最突出的问题便是过于依赖丰富的数据。现实生活中诸多应用领域[3-4],对大规模数据的采集以及标注代价昂贵,在样本量较少时,机器学习更是遭遇了极大的阻碍。对于人类而言,这些问题极少存在,其原因莫过于人类具有强大的思考能力,能积累过去各种信息,因此可以从少量的样本中快速学习,并进一步延伸到新的未知事物中,而这却是机器学习很难实现的关键点[5],也是人工智能拟人之路得以实现的转折点。人们进一步细分机器学习,提出了小样本学习的概念,即模仿人类学习,基于此利用少量样本学习并快速泛化到新任务中。近年来,如何进行小样本学习并提高学习效率引发了一股研究热潮,研究人员从各个角度出发,提出一系列在小样本条件下进行快速学习及提高泛化能力的方法,且在图像领域[6]中取得巨大成果。嵌入学习方法作为其中的代表方法之一,引发了不少热议。
1 小样本学习
1.1 小样本学习概述
为了方便描述对小样本学习进行阐述,首先引入机器学习的定义,Mitchell等人[7]认为,若一个计算机程序利用经验E在任务T中改善了其性能,即提升了度量P(评估计算机程序在某类任务的性能),则称计算机程序对经验E进行了学习。这与人类针对某一个问题进行思考得出解决问题的经验去处理其他问题的过程是类似的。
然而,尽管机器学习在人工智能的拟人之路上实现了突破,但在数据不充足的设定下,保证模型能够对样本进行快速学习和提高泛化能力给研究者带来了巨大挑战,也是人工智能向人类智能进一步突破的关键。基于实践价值和领域需求,研究者给机器学习领域中划分了新的子领域——小样本学习[8],小样本学习期望使用远小于机器学习的样本量,实现在保证模型性能的同时进一步提升样本学习和泛化的能力,可以通过场景数据量(本质是单位样本产生的模型收益[9],即经验E)来区分它们。
虽然小样本学习在各行各业中被频繁提出,但目前对小样本的定义还没有统一的看法和公认的标准。由于目前小样本学习在图像学习领域[10-11]发展比较成熟,图像领域常用的标准小样本集都是取自于大样本集[12](用于深度学习),通过对小样本集与其来源的大样本集进行对比分析,发现无论是小样本还是大样本,在每类样本数基本一致的情况下,决定样本是“小”还是“大”的关键是样本类别的数量。因此,本文尝试给小样本定义如下,当一个样本集与常规大样本集的样本类别比达到1∶100甚至以上时,则可以认为该样本集为小样本。小样本的学习任务都是针对每个类别下的少数样本[13]展开的,当每个类别下的训练样本只有一个的情况下,小样本即为特殊的单样本学习(One-shot learning)[14],而每个类别下的训练样本有多个时则划分为常规的小样本学习(Few-shot learning)。
1.2 小样本学习的分类
在小样本场景中,训练得到的模型易陷入对目标任务样本的过拟合[15],实际表现较差,与最优模型表现的差距也无法通过多次训练和超参数调整有效缩小。不少研究者[16]认为,小样本学习过程中忽略了一个关键点,即先验知识[17]的存在,人类能够对小样本进行快速学习往往依赖于对先验知识的理解和应用。因此,让给定模型具备相关任务的先验知识已然成为小样本学习的基础。
可见,如何结合先验知识是实现小样本学习的核心。按照结合先验知识的途径,本文提出将现有的小样本学习的研究工作划分为三类:数据类、模型类和算法类,汇总并阐述它们的核心思想,同时进行简单地对比分析,如表1所示。
根据表1,对比其他两类方法,模型类的解决方法通俗易懂且实现成本较低,能够在保持目标任务样本不变的同时避免受限于数据量和模型精度不足的问题,并可以更快地调整和寻找合适参数来得到优质的模型(限制获得最优模型所需要寻找的参数组合的范围,去除无效参数组合),大大降低过拟合问题的风险。

表1 小样本学习的解决方法Table 1 Solutions of few-shot learning
近些年来,作为较为经典的模型类的解决方法,嵌入学习方法在小样本的图像分类[26-27]等领域取得不俗的研究成果,吸引了不少研究人员进行研究。因此,本文将针对嵌入学习方法,探索模型类方法如何结合先验知识解决小样本学习问题。
2 嵌入学习方法实现小样本学习
2.1 嵌入学习方法概述
2.1.1 方法定义
嵌入学习方法,又称表示学习,嵌入即映射,与降维类似,核心思想是将样本嵌入到低维空间中,将样本特征转化特征向量的形式保存在低维特征空间[28-29]中,减少假设空间的范围,通过较小的嵌入空间来进一步扩大嵌入样本间的区分度,使得同类样本联系更加紧密,而异类样本分布则更加分散,它的关键在于如何嵌入样本特征以及特征嵌入之后如何学习。
2.1.2 通用框架及基本流程
小样本场景中,嵌入学习方法的核心思想是训练优秀的特征嵌入函数[30]来实现对样本的映射,旨在让样本在较小的样本特征嵌入空间具有更加清晰的区分度。嵌入学习方法主要由嵌入模块和度量模块组成,嵌入模块的功能是利用卷积神经网络(convolutional neural network,CNN)构建并训练特征嵌入函数,将样本以特征向量的形式映射到特征空间中;度量模块则选择合适的度量函数计算样本的相似度度量,完成对样本的分类。
通常,为了保证小样本学习的性能,嵌入学习方法采用了Episodic Training的跨任务学习模式(借鉴元学习(Meta-Learning)[31]的思想),旨在将对整个目标任务样本集的学习转换为多个子任务的多次学习(以N-wayK-shot的方式),嵌入学习方法的通用学习流程如图1所示。
首先,每次学习(Episode)时,嵌入学习方法从目标任务样本集所有类别的样本中随机选出N个类别,每个类别随机选择K个样本组成支持集a(已知类别样本);再从之前选取的N个类别剩下的样本中随机抽取一批样本(每个类别抽取一个或者多个,数量不限)组成查询集b(待分类样本),支持集和查询集共同组成一个子任务(支持集a和查询集b的样本两两随机组合成样本对(a,b))。然后,分别采用两个特征嵌入函数f、g对子任务中的样本对(a,b)进行特征嵌入(f嵌入a,g嵌入b),提取样本特征并以样本特征对(a′,b′)的形式保存到训练好的特征嵌入空间中,构建特征嵌入空间即学习特征嵌入函数,这是嵌入学习方法的关键。嵌入学习方法一般借助辅助数据构建和训练两个CNN来训练两个特征嵌入函数(f和g),如图1所示的虚线框部分,辅助数据一般来源于外界包含足够多种类样本的大规模数据集,也可以从目标任务样本中抽取。辅助数据D′也采用了Episodic Training的学习模式进行训练(多次采样,多次训练),旨在让辅助数据D′与目标任务样本的场景设置保持一致,保证特征嵌入函数的有效性。每次训练时,随机采样辅助数据D′构建辅助数据D′的支持集m与查询集n,并将它们以样本对(m,n)的形式组合成一个子任务,样本对(m,n)分别输入到两个CNN中进行预训练,通过多次抽样和训练,使得CNN获取足够的先验知识对特征嵌入函数的参数θf和θg(θf≠θg)更新与优化,最终完成特征嵌入函数(空间)的构建与训练。接下来,选择合适的相似性度量函数S(可以是一个简单的距离度量,也可以是动态学习的神经网络)构建度量模块,将特征嵌入空间的样本对的特征一同输入到度量模块中,计算样本对中样本之间的度量值,依据度量准则[32]预测查询集(待分类样本)样本的类别。最后,嵌入学习方法经过多次学习,完成对所有待分类样本的分类。
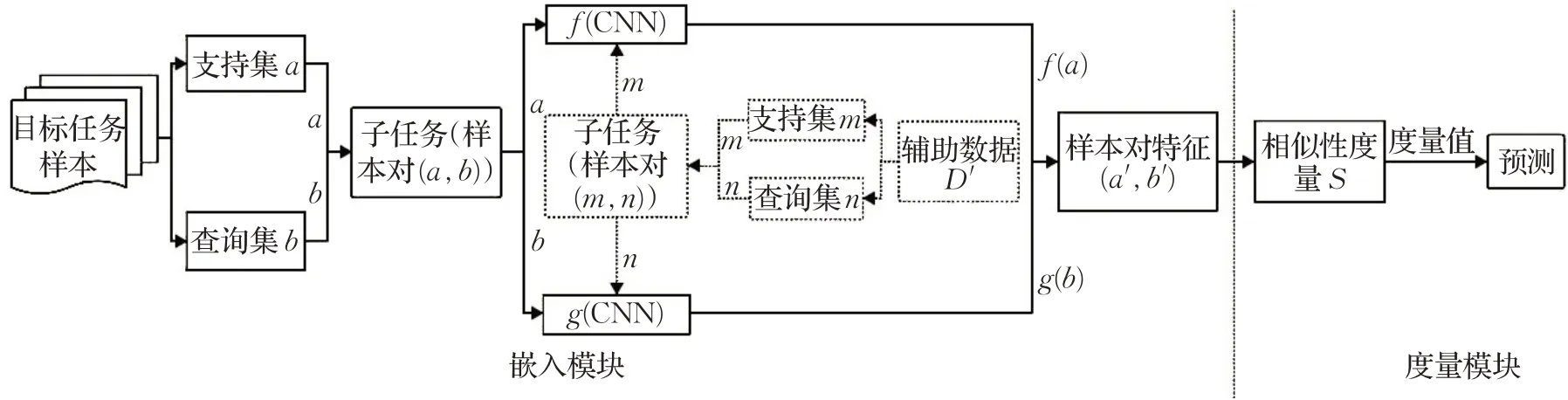
图1 常规嵌入学习方法Fig.1 Conventional embedded learning methods
2.1.3 嵌入学习方法分类
一般情况下,嵌入学习方法对特征嵌入函数的训练很大程度依赖于辅助数据[33],在辅助数据中学习的是通用特征信息[34](外部先验知识),而在目标任务样本中学习的是特定特征信息[35](内部先验知识)。嵌入学习方法可以只利用辅助数据的外部先验知识或目标样本的内部先验知识来训练特征嵌入函数,也可以同时结合两种特征信息来获得特征嵌入函数。因此,依据训练特征嵌入函数的过程中结合任务特征信息的方式,本文将嵌入学习方法划分为单一嵌入模型和混合嵌入模型。
下面,本文就两类嵌入模型和它们的代表性方法进行阐述、讨论与分析。
2.2 单一嵌入模型
单一嵌入模型通常只结合样本的通用特征信息或者特定特征信息(只结合一种特征信息)来训练特征嵌入函数,相应地称为一般嵌入模型和特定嵌入模型。
一般嵌入模型只通过辅助数据来获取通用特征信息并训练特征嵌入函数,特征嵌入函数可以直接用于嵌入目标任务的样本,无需再用目标任务样本重新训练,即特征嵌入函数的参数不再随所嵌入的目标任务样本的特征信息发生改变。
不同于一般嵌入模型,特定嵌入模型不依赖辅助数据,它只依赖目标任务样本获取特定特征信息并训练特征嵌入函数。每次学习时,嵌入模块会根据当前任务的样本特征信息,为当前子任务训练对应的特征嵌入函数,每进行一次任务,就需要结合当前任务样本的特定特征信息训练一个特征嵌入函数,因而不同任务对应不同的特征嵌入函数。
下面,本文对几种典型的单一嵌入模型方法进行介绍和讨论。
2.2.1 孪生网络(SN)
孪生网络(siamese network,SN),早在1993年就已经作为一个神经网络模型[36]被提出来。2015年,Koch等人[37]用其进行了单样本的图像识别,验证了其处理小样本学习问题的可行性。
SN的基本流程如图2所示。它的创新点主要为两点,一是嵌入模块采用了两个一样的CNN网络(相互对称,双网络之间的参数例如权重W等共享)来构建并训练两个一样的通用的特征嵌入函数(即f和g等价);二是在度量模块中,SN采用了欧式距离作为距离度量。
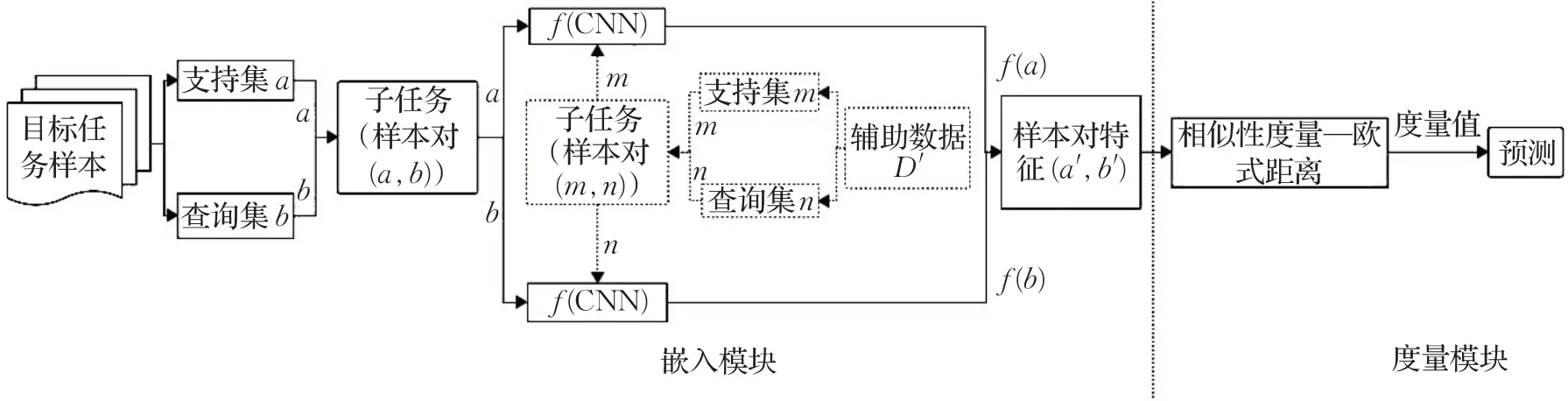
图2 孪生网络Fig.2 Siamese network
对于SN而言,它简化了嵌入模块架构,采用了相同且相互对称的两个CNN网络有助于提升特征嵌入函数训练的效率。然而,它对外部先验知识极度依赖,当辅助数据的样本量极少或样本较为复杂时(缺乏足够的先验知识),SN无法训练出优质的特征嵌入函数来准确并快速对样本分类。于是,Sameer等人[38]提出深度孪生网络(deep siamese network,DSN),DSN在有限的数据下增强了训练空间,进一步加强特征嵌入函数对于复杂样本的特征提取能力。另外,Zhao等人[39]提出了孪生密集神经网络(siamese dense neural network,SDNN),SDNN采用更多层的网络来训练特征嵌入函数,一级级地学习样本特征,最终捕获最高水平的相似度特征,克服了训练数据不足的问题。
2.2.2 匹配网络(MN)
2016年,Vinyals以及Cai等人[40-41]在SN的基础上提出了匹配网络(matching network,MN),他们认为可以结合外部机制来训练出更好的特征嵌入函数,MN的创新点为以下两点。
一是MN在构建通用特征嵌入函数的过程中加入了优化过程。优化通过记忆机制完成,它的本质是特征信息的接收反馈和适应调整(网络参数的优化),以消除辅助数据随机选择支持集与查询集样本的差异性。如图3所示,MN引入了双路LSTM[42]网络(BiLSTM)作为记忆模块,连接f和g所在的CNN网络,再训练和优化两个特征嵌入函数(将辅助数据D′的支持集m重新编码成一个序列m′[43],利用LSTM将其同时输入到f和g所在的CNN网络中,再训练和优化形成新的特征嵌入函数′和′)。
图3 匹配网络Fig.3 Matching network
二是MN在度量模块中加入了注意力(Attention)机制,并不直接采用度量距离(余弦距离)来对样本分类,而是通过带注意力机制的核函数来归类样本。
归类的过程如公式(1)所示:

式(1)类似一个加权求和[44]过程,y代表支持集样本a的类别,代表预测类别值,α是注意力核函数[45]。
MN通过外部机制的融合实现了对传统的通用特征嵌入函数的优化,提升了其对目标任务样本的特征嵌入能力,使其更加适应新的任务样本,极大提升了学习的性能。研究人员还提出不少MN的变体[46-47]对其优势进行延伸和完善,如Bachman等人[48]在原有的MN上做出小改变,结合主动学习[49]思想,采用了样本选择机制,标注最有益的未标注样本,来增强训练样本,使得训练的特征嵌入函数对目标任务样本的特征概括能力更强。
现有的研究工作大多只关注样本特征信息,对样本的类别标签关注较少。因此,Wang等人[50]提出了多注意力网络模型(multi-atteniton matching network,MAMN),MANN构建了样本特征以及类别语义标签的带多注意力机制的嵌入模块,用样本的类别标签来引导注意力机制判断样本哪些部分与类别语义标签相关(多个对应多注意力),训练并更新特征嵌入函数,以求获取更好的样本特征表示。
尽管上述MN及相关变体方法取得不错的成果,但它们需要引入外部机制让模型架构复杂化以提升样本学习性能,大大增加了样本学习的负担和成本,不利于提升样本学习的效率。另外,MN与SN一样,主要都是针对单样本学习问题,对于常规的小样本学习问题而言,还没有权威的实验证明MN能取得同样的学习效果。
2.2.3 原型网络(PN)
在一般的小样本学习任务中,每个待分类样本需要一一计算与每个已知类别样本的度量(相似度),依次比较然后归类。Snell等人[51]认为上述过程较为繁琐,他们参照聚类思想,提出了原型网络(prototypical network,PN)。
原型的计算如公式(2)所示:

式(2)中,xi、y i代表支持集的某个样本及其对应类别,fφ代表特征嵌入函数,S K是类别k的样本总数,φ是可学习的参数,C K是每一类的原型(M维)。
PN主要有两个创新点,首先,PN提出了原型[52]的概念,即每个类都存在一个“嵌入”,每一类样本点都围绕其进行聚类。如图4所示,嵌入模块在嵌入目标任务样本后还增加了计算样本的类原型a~的步骤;其次,度量模块调整了计算样本相似性度量(采用欧式距离作为度量)的过程也做出了调整,只计算查询集样本与支持集类原型(已知类)的度量。
图4 原型网络Fig.4 Prototypical network
对比之前几种方法,PN将嵌入学习方法的思想进一步延伸到于非单样本的常规小样本学习问题中,验证了嵌入学习方法的思想有助于提升小样本的学习效果,后续不少小样本学习的研究工作都是围绕它展开;另外,PN减少了复杂的模型扩展,它提出的“原型”概念不仅简化了度量模块的度量流程,还进一步明确了小样本学习的思想,让学习的效果更稳定有效。
PN一般采用带标注信息的样本(支持集样本)来计算类原型,然而当目标任务样本的数据量较少时(较少的标注信息),会使得到的类原型不一定是类别中心,可能会使得后续样本分类出现较大分类偏差。为了缓解问题,不少人将PN以与其他机器学习问题[53-54]相结合来减少误差。Ren等人[55]参照了半监督学习[56]的思想,在训练时加入了不带标签的样本来修正原型,缩小了样本的分类偏差。Sun等人[57]提出了将三级注意力机制与PN结合的层次注意力原型网络(hierarchical attention prototypical network,HAPN),用于保存和获取可用于样本分类的重要特征(标注信息),提升类原型的有效性。
然而,在不少PN的研究工作中(例如语音识别中)存在有不少样本离原型较远容易被忽视的情况,尤其在带噪音的语音识别场景中会更加影响样本学习的效果。考虑到这个问题,在语音关键字捕捉领域中,Seth等人[58]提出不同类别的样本具有不同的重要程度(类别),引入了原型损失(用不同的权重来代表不同类样本的重要程度,获得更具表达力的加权原型),同时将PN与迁移学习[59]结合起来,用深度语音微调原型解决了关键字缺失以及噪音被错误划分到语音类的影响。
2.2.4 关系网络(RN)
2018年,Sung等研究人员[60]从完善距离度量函数的角度出发,提出用关系网络(relation network,RN)来解决小样本学习问题。
如图5所示,与传统的嵌入学习方法相比,RN创新性地做出两点突破。一是将传统度量模块由一个简单的固定度量替换成一个可学习的深度CNN,提出了关系分数的新式可学习度量。二是加入级联机制(级联块)连接嵌入模块与度量模块的网络,并对所有样本对特征进行拼接,级联机制通过对嵌入的不同样本的特征进行拼接来计算样本的相似性度量,提升了度量模块的灵活性。

图5 关系网络Fig.5 Relation network
关系分数公式如下:
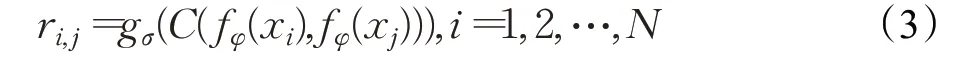
式(3)中,fφ代表特征嵌入函数,C(fφ(xi),fφ(x j))代表级联机制,gσ代表连接单元;r i,j代表关系分数(非线性度量)。
RN提升了对与任务无关样本的泛化能力和学习能力,这是大部分单一嵌入模型中所不具备的;除此之外,它突破了传统度量的限制,不再用固定的距离函数来计算样本间的相似性度量,实现了距离度量函数的参数化,扩展度量的适用性(应用于某些特定任务),利用深度CNN来学习度量(模拟了人类比较学习的能力)可以更好地判断每个样本类别中哪些特征信息对于类别划分很重要,同时一定程度上减少了对样本的特征信息标注量,减少了对特征嵌入函数的过度依赖,让度量标准更加合理有效。然而,RN在学习动态度量所采用的深度CNN算法还不够合理,存在较大的改善空间;另外,对度量模块的创新在一定程度上提高了网路架构的构建要求,增加了模型复杂性,加重了成本负担。
另外,虽然RN的特征嵌入能力有所提升,但是在面对某些复杂目标任务样本时,特征嵌入函数对复杂样本特征的映射能力仍有待提高。于是Zhang等人[61]提出了深度比较网络(deep comparison network,DCN),DCN将嵌入模块和度量模块同时进行分层,并用更优秀的SENET网络取代了原有的Conv-4网络,嵌入模块按层次训练特征嵌入函数,然后一层层地嵌入样本特征,实现对嵌入特征的联合嵌入学习,有效地利用了复杂样本的特征,提升了模型性能。
上述方法都只考虑到成对的支持集和查询集样本间的关系,忽略了支持集样本间的关系,容易导致训练得到的特征嵌入函数不够可靠。于是,He等人[62]提出了记忆增强关系网络(memory-augmented relation network,MARN),它加入了记忆架构[63],存储样本信息来增强样本[64],然后结合转化学习思想探索支持集中样本的联系,同时采用无向图替代CNN来训练特征嵌入函数,对支持集样本进行信息传播,提高特征嵌入嵌入能力以获取更好的特征表示。
2.2.5 图神经网络(GNN)
2005年,由Scarselli等人[65]提出用图模型来专门处理图结构的数据,可以保存重要的拓扑信息,提升模型的可解释性和性能。GNN[66-67]是CNN在非欧空间[68]的扩展,可以看做是CNN的特例[69]。Garcia等人[70]认为图结构对样本特征的学习能力和表示能力都较强,于是提出用图神经网络(graph neural network,GNN)来解决小样本分类问题。
GNN方法是常规的一般嵌入模型的扩展,与以往的工作不同的是,GNN方法做出以下两点改变。首先,在嵌入模块方面,它只采用一个CNN来构建并训练通用特征嵌入函数f(采样的样本直接作为子任务参与训练);其次,GNN方法的关键变化在于度量模块,它采用图网络来训练距离度量函数,通过无向图的遍历完成样本的度量以及归类。结合图6,嵌入的目标任务样本特征作为输入进入图网络(GNN)中,拼接样本特征与自身标签,初始化图模型节点的。然后通过公式(4)构建图邻接矩阵[71],构建节点连边,边的功能是用来评估样本的相似度,边上的权重[72]即为相似度,权重是可训练的(更新边,重新学习边上的权重);后面经过两次图卷积,通过公式(4)更新边向量进而更新边上的节点(更新节点的标签信息),实现信息传递。
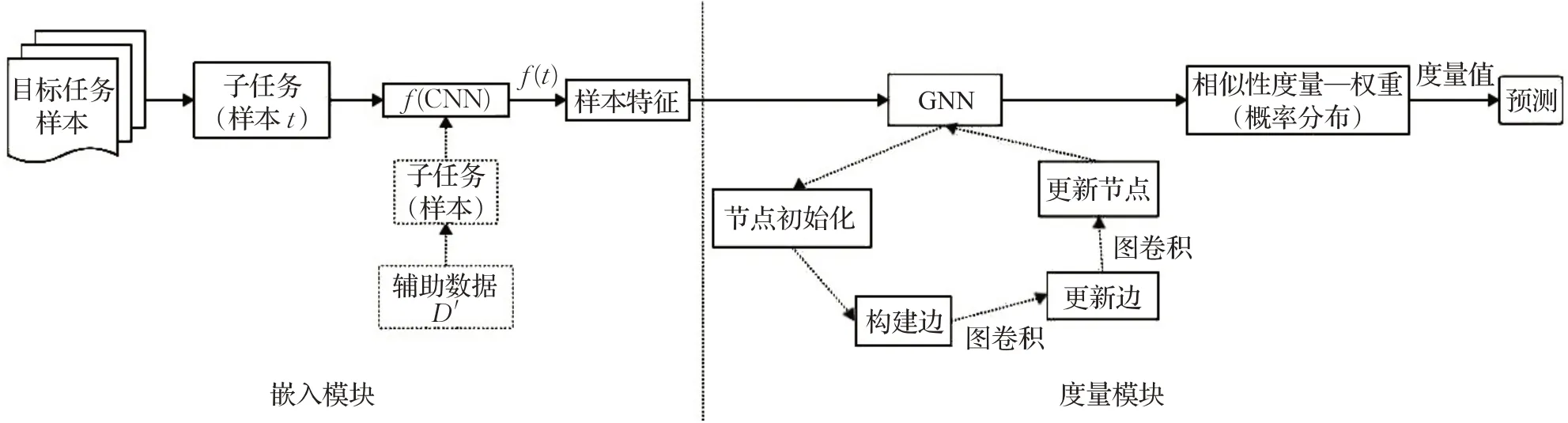
图6 图神经网络Fig.6 Graph neural network

GNN方法在一定程度上提升了特征嵌入函数的嵌入能力,加速其训练过程,同时它采用的任务驱动的消息传递算法提升了样本学习的效率;除此之外,GNN的框架极易让其能快速与其他框架结合,框架的扩展帮助GNN拥有更好的小样本学习能力;另外,它借鉴了RN采用可学习度量的思想,隐式地构建了可学习的权重作为相似性度量,实现优势的结合,在保证小样本学习的准确率的同时极大提升了学习的效率,不少GNN的变体也沿用了该思路。例如,Liu等人[73]于2019年提出GNN的变体—转换传播网络(transductive prototypical network,TPN),本质也是实现图中节点分类。不同的是它引入了转换学习[74]方法,将标签传播模块和图网络构建的模块分开,实现节点嵌入参数与节点更新的参数的联合学习。
Kim等人[75]从另一个角度出发,提出边缘标记图神经网络(edge-labeling graph neural network,ELGNN)。与GNN和TPN相反,ELGNN对图的边进行分类,主要是利用边中节点的类内相似性和类间差异性进行迭代更新,以此带动对节点的更新,显式地构建了样本间的度量完成样本分类。
然而,GNN及其变体的度量模块对计算能力要求较高,当目标任务样本的数据量越大,边需要大量地被更新,不断地计算调整权重使得计算量急剧上升,高昂的计算成本会使实际场景的应用变得困难。
2.2.6 信息检索法(IRL)
Triantafillou等人[76]另辟蹊径,他们于2017年提出一个新的方法,尝试从信息检索的角度去处理小样本学习问题,该方法的思路是不借助辅助数据来获取先验知识,将小样本分类问题转化为信息优化问题,本文总结其为信息检索法(information retrieval lens,IRL)。
区分于前面的几种方法,IRL属于单一嵌入模型中的特定嵌入模型。如图7所示,IRL的学习流程有较大的改变。首先,在嵌入模块中,IRL调整了Episodic Training的学习模式,直接用目标任务样本训练特征嵌入函数。每次训练(Episode)时,直接随机采样目标任务样本作为查询集u组成子任务,每个子任务会选定其中一个样本,定义其为“查询”,该任务内的其他样本为候选集样本。不同训练批的子任务需要训练不同的特征嵌入函数。
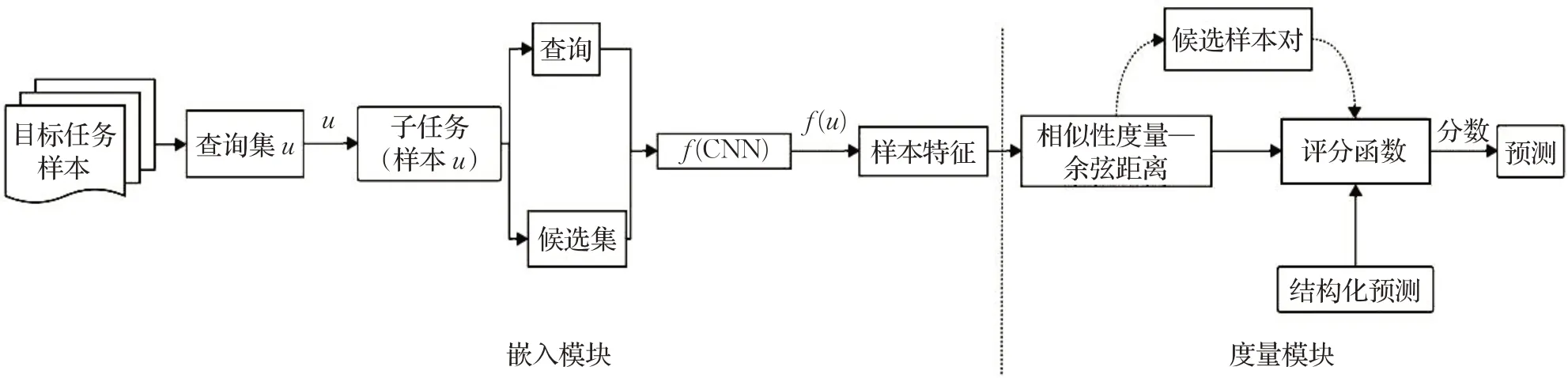
图7 信息检索法Fig.7 Information retrieval lens
其次,在度量模块,IRL借鉴了枚举的思想,用相似度排序(采用余弦距离作为度量)的方式取代原有的只计算样本度量的方式,并引入外部框架(结构化预测框架等)来对度量模块进行优化,筛选出更优秀的学习结果。IRL选定“查询”与候选集样本逐个进行对比,按照相似度高低对候选集样本排序组合成候选样本对,每次将“查询”与候选集中相似度最高的样本归为一类。最后,如公式(5)所示,IRL引入结构化预测框架(标准的结构性支持向量机以及直接损失最小化方法)来构建和优化评分函数,并采用了MAP函数作为优化的目标函数来辅助评分函数的优化,对候选样本对评分并选出最优的候选样本对,即得到最优的样本相似度排序,选取相似度排第一的样本的类别作为当前“查询”的类别,以此类推,预测每个任务批次的样本类别。
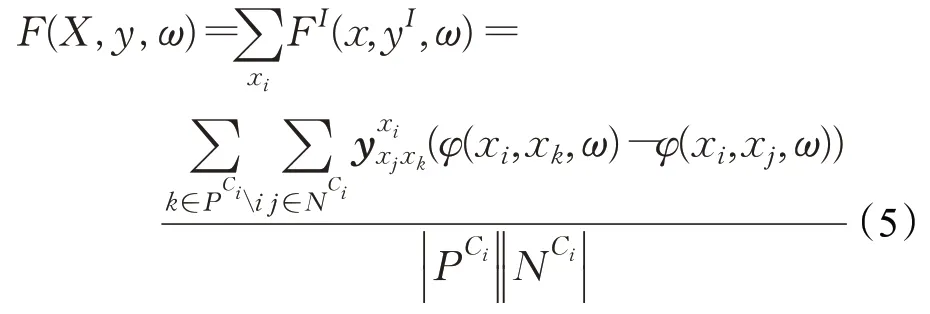
式(5)中,x i代表当前“查询”,x j和xk代表候选样本集的样本;X代表输入的候选样本相似度排序对,y代表最优的候选样本相似度排序对;ω代表评分函数的参数;表示与样本x i类别相同的样本集合;相反,代表与样本xi类别不同的样本集合;代表输出的结构化向量;φ是余弦函数。
目前关于特定嵌入模型的研究比较少,IRL是唯一的特定嵌入模型。IRL只对目标任务样本训练,可以对任务信息最大程度地挖掘和利用,非常适合于含有多标签样本的学习,对提升学习效果很有帮助,这是其最具特色的优势。
然而,IRL需要训练多个特征嵌入函数(每个子任务对应一个特征嵌入函数),训练量大,流程冗余导致的样本学习效率较低是其主要的劣势;而在目标任务样本较为复杂或者数量极少时,不同任务间的样本会有不小偏差,为每个任务来量身定制特征嵌入函数只能在理论上成立。事实上,IRL容易陷入到过拟合的困境,每个任务训练得到的特征嵌入函数与其他(新)任务样本的契合度不高。
2.3 混合嵌入模型
近年来,研究人员发现,当辅助数据与目标任务样本的任务相关性较低时,单一嵌入模型训练的特征嵌入函数对目标任务样本的特征提取能力会大大降低。因此,他们提出了混合嵌入模型的概念,旨在综合一般嵌入模型以及特定嵌入模型的特点,结合样本的通用特征信息(辅助数据)和特定特征信息(目标任务样本)作为先验知识来训练特征嵌入函数。该类模型会事先通过获取通用特征信息训练初始的特征嵌入函数,同时当进行目标任务样本的学习时,再结合当前任务样本的特定特征信息作为特征嵌入函数的适应标准,不断动态调整函数参数,构建适应性更好的混合特征嵌入函数。
该类模型借鉴了数据增强的思想,进一步提升了特征嵌入函数对与任务相关的样本特征的挖掘与保存能力,使特征嵌入函数能够更好地应对各种复杂场景下的小样本学习问题。
下面,本文将对混合嵌入模型的几种典型方法进行阐述。
2.3.1 孪生学习网络(SL)
鉴于原有的SN存在的诸多缺陷(例如学习场景的限制),Bertinetto等人[77]在SN基础上提出孪生学习网络(siamese learnet,SLN),探讨用于解决单样本学习的新思路。
SLN与以往研究工作有所区别,它在以下两个方面做出了创新。
一是整体架构的改变。如图8所示,它针对原有的SN网络做出了改变,只采用原有SN的一个CNN训练初始的特征嵌入函数;然后引入了动态卷积层,重新构建了一个新的CNN(学习网络——LearNet,LN)网络取缔了另外一边的CNN网络,对特征嵌入函数多次再训练与调整,结合了目标任务样本的特定特征信息,参数也随之动态地学习与优化(预测动态权重参数ω等,一个样本类别对应一个权重参数值),得到混合特征嵌入函数。
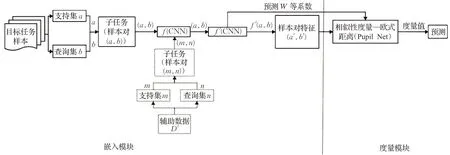
图8 孪生学习网络Fig.8 Siamese learnet
二是优化了原有的度量模块,将简单的固定度量替换成一个动态度量学习网络——Pupil Net(LN根据预测的动态权重参数ω学习到的子网络)。Pupil Net依据权重参数学习待分类样本(单样本)的相似性度量(加权欧式距离)。
目前,Bertinetto等人[78]又继续对SLN进行改进,主要是对学习网络(LN)的架构调整,取缔了全连接层,采用了岭回归(Ridge regression)和逻辑回归(Logistic regression)训练出更有用的嵌入参数,帮助训练出更好的特征嵌入函数。
SLN的出现是单样本学习问题的进一步延伸,使得混合嵌入模型的概念成为了现实。它给原先的CNN加入了许多动态学习要素(例如动态参数等),在网络架构上做出突破,同时加速先验知识融入样本学习的过程,同时结合离线训练和在线训练的方式,实现用一个网络学习另一个网络,帮助训练出性能更为优秀的特征嵌入函数并减少了不必要的参数调整,使得整个单样本学习流程是一次性的、高效的、实时的,提升了样本学习精度。
尽管如此,SLN仍然依赖大量辅助数据来训练和优化特征嵌入函数,这是后面Pupil Net能够只利用较少样本(单样本)便可完成样本类别预测的保证。另外,SLN属于复杂的大型动态学习网络,需要学习大量的参数,这会导致输出空间过大,影响参数的学习与优化,降低了样本学习的效率。
2.3.2 动态条件卷积网络(DCCN)
Zhao等人[79]发现在实际场景训练任务中,许多用于小样本学习任务的样本都携带不少标签信息(以老虎为例,它既可以被划分为食肉类动物,也可以是哺乳类动物,或者是猫科动物等)。因此,在样本数量足够的情况下,每个类别的样本就变得很少,不利于进行训练,容易出现过拟合问题。之前的工作大多没有考虑到这点(只考虑一个样本对应一个类别),于是他们针对该问题,提出动态条件卷积网络(dynamic conditional convolutional network,DCCN)。
DCCN从统计学角度出发,它主要在两个方面进行了创新。
一是网络架构的突破,将条件极值问题的求解应用到小样本学习当中。DCCN取缔了传统的嵌入学习方法的通用架构,以条件网络[80]模型(Condinet,CDN)为基础,同时结合动态卷积网络[81](DyConvNet,DCVN)组成双子网结构。
二是对训练特征嵌入函数的流程做出较大调整,取缔了传统的训练模式,采用双子网联合学习的方式训练混合特征嵌入函数和学习样本。如图9所示,DCCN让辅助数据和目标任务样本共同作为训练数据参与初始的特征嵌入函数f(基滤波器)的训练;与此同时,DCCN还随机将训练数据所携带的已有的样本类别信息训练(条件输入)得到另一个初始的条件嵌入函数g(CDN的CNN+LSTM),为每个样本类别预测一组自适应权值ω。接下来,DCVN再利用基滤波器来线性组合(动态卷积)目标任务样本,结合样本的特定特征信息(ω)再训练混合特征嵌入函数′。
DCCN的训练方式对网络架构的要求较高,成本负担较高。除此之外,DCCN在常规的简单任务(例如样本只有一个标签)中,它学习的效果不如其他的方法。另外,目前这种解决思路的应用范围较狭窄,只适合于一些特定场景下的小样本学习问题,并且鉴于目前只有DCCN这一种方法,有效性仍需进一步被验证。
尽管如此,DCCN适合于那些带有许多类别标签的复杂样本的挑战性应用场景,在处理包带诸多条件(类别)信息的样本的学习问题取得优秀的效果,而这对现实的诸多工业应用领域是极具价值的,这意味着许多情况下不需要再去采用数据合成等方式来保证小样本学习的效果,只采用原有的数据便可满足实际分析的需求,同时它在这些领域中还具备较为不错的泛化能力,有助于对实际数据进行建模学习。另外,DCCN在缓解过拟合问题方面也颇有成果,在未来的许多实际应用领域是极具研究价值的。
2.3.3 任务相关自适应度量(TDAM)
在辅助数据与目标任务样本相关性较低时,一般嵌入模型训练的特征嵌入函数对于目标任务样本的嵌入能力会变得比较糟糕。于是,Oreshkin等人[82]在原有PN的基础上,提出任务相关自适应度量(task dependent adaptive metric,TADAM)。
TADAM的创新之处主要体现在两个方面。首先,它对初始特征嵌入函数的训练过程做出部分调整,如图10所示,每次训练时,TADAM会让目标任务样本与辅助数据协同训练初始的特征嵌入函数。
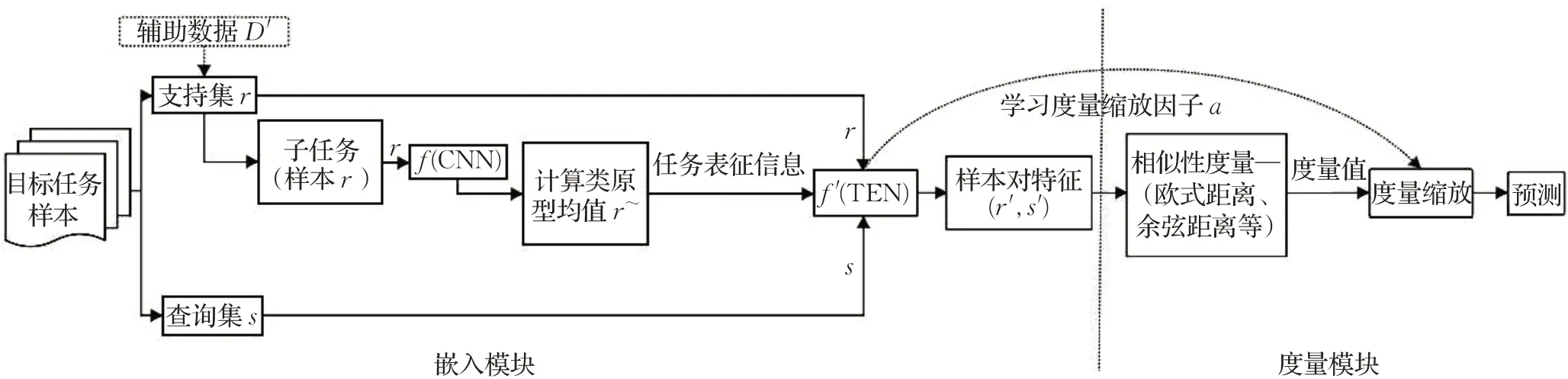
图10 任务相关自适应度量Fig.10 Task dependent adaptive metric
其次,TADAM构建了深度任务条件嵌入网络(TEN)再训练和优化初始的特征嵌入函数,同时突破了传统的相似性度量的思路,提出了度量缩放的概念,淡化了度量选择的重要性,这是该方法最大的创新点。TADAM借鉴了PN的思想,计算目标任务中已知类别样本(支持集)中每一类的类原型均值,将类原型均值作为任务表征信息输入到TEN中,TEN通过遍历所有的任务表征信息并动态地学习每个任务中样本的特定特征信息(任务相关系数和度量缩放因子α等),再训练获得混合特征嵌入函数f′。Oreshkin等人还先后对比了采用余弦距离作为度量和采用欧式距离作为度量的差异,发现差异产生的原因在于度量尺度的不同,于是他们提出了用一个度量因子来缩放度量,并验证了度量缩放能有效地提升样本学习的性能。
TADAM采用协同训练方式取代传统预训练方式取得不错的效果,可以实时地进行各种参数反馈与调整(类似人类的学习),提升特征嵌入函数的嵌入能力。另外,采用TEN再训练特征嵌入函数可以有效地捕捉样本的特定特征信息,有助于进一步提升特征嵌入函数对其他(新)任务样本的泛化能力。还有,采用度量缩放有助于提升小样本学习的性能,同时提高了在选择相似性度量的可解释性。
尽管如此,TADAM的协同训练模式对样本数据量的要求较高,因而在某些缺乏样本数据的实际场景中,它的应用价值较低。除此之外,TEN网络需要较强的任务表征信息来优化特征嵌入函数,目前的任务表征信息的设计仍有较大空间完善,另外构建TEN网络对整体架构要求较高,加重了工作成本负担。还有,目前关于度量缩放的研究工作较少,度量缩放的可行性束缚了方法推广的范围。
3 方法总结
本章将介绍各类嵌入学习方法在小样本学习任务(主要是图像领域)中采用的数据集,同时比较各类嵌入学习方法在最常用的数据集上的表现,分析各类嵌入学习方法的性能影响要素,最后详细地总结所有嵌入学习方法。
3.1 各类嵌入学习方法在常用数据集上的表现
在小样本学习任务中,各类嵌入学习方法采用了MiniImageNet[83]数据集、Omniglot[84-85]数据集和Tiered-ImageNet数据集以及CIFAR100[86]数据集等作为标准数据集。
表2选取5-way 1-shot以及5-way 5-shot这两种情况来对各个嵌入学习方法的表现进行分析,其中有些对应专用数据集或者只采用一种数据集的方法说服性和讨论性并不高,因此它们的表现并没有列出。
如表2所示,首先,无论采用哪个数据集作为小样本学习的标准数据集,5-shot的分类准确率都要比1-shot的高,这证明了用于学习的样本数量越多,获取到的特征越多,训练出的特征嵌入函数越好,最终的学习效果越佳;其次,不同的数据集对模型的影响也比较巨大,所有采用Omniglot数据集的方法在1-shot和5-shot的分类准确率均达到96%以上,进一步提升的空间已经比较小了;而在MiniImageNet数据集上1-shot和5-shot的分类准确率大多都只有50%/70%上下,这是因为MiniImageNet数据集的图片样本种类较多,样本特征信息较为复杂;除此之外,不同类别的嵌入学习方法的表现也不同,混合嵌入模型相对于单一嵌入模型的分类准确率有明显的提升,这凸显出同时结合两种特征信息训练得到的混合特征嵌入函数更有助于提升样本学习的有效性;另外,在MiniImageNet数据集中,表现最好的方法与表现最差的方法在1-shot/5-shot上的分类准确率相差15%到11%,这些都意味着嵌入学习方法还有较大的提升空间。
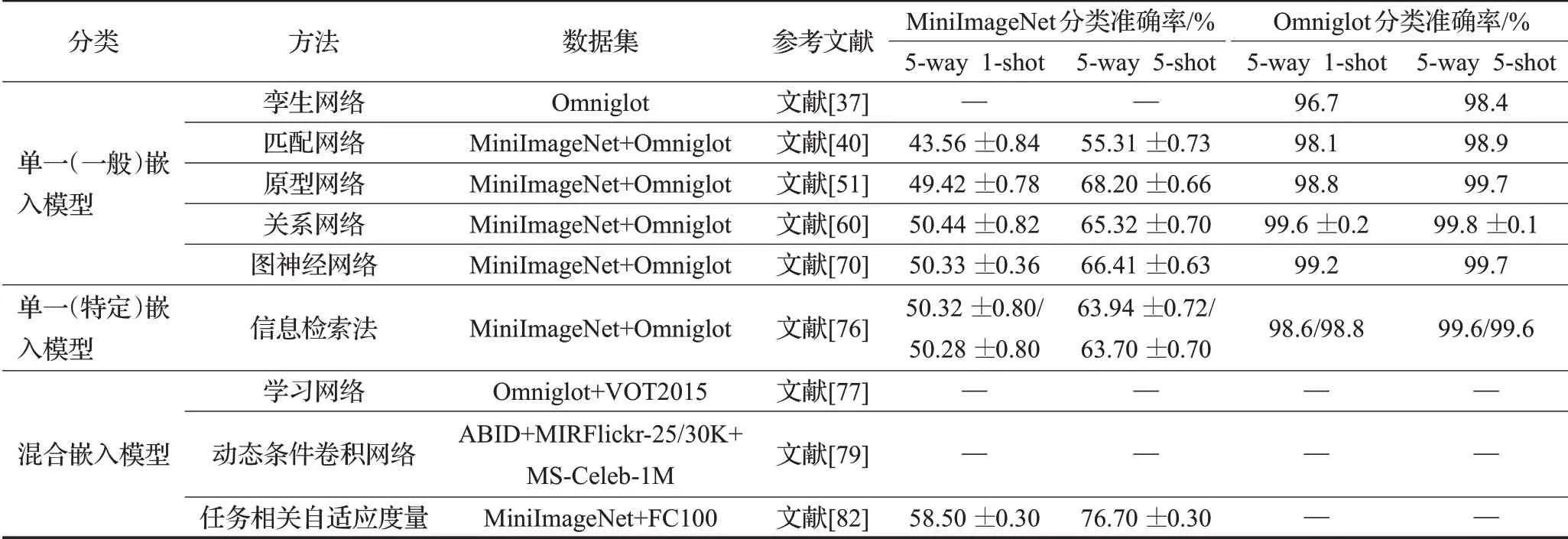
表2 各嵌入学习方法表现Table 2 Performance of embedded learning methods
3.2 性能影响因素分析
综合各个嵌入学习方法的表现,本文依据影响因素是否为方法所特有,将嵌入学习方法的影响小样本学习性能的因素划分为决定因素和一般因素,这里通过表格归纳和分析每个因素所起的作用,如表3所示。
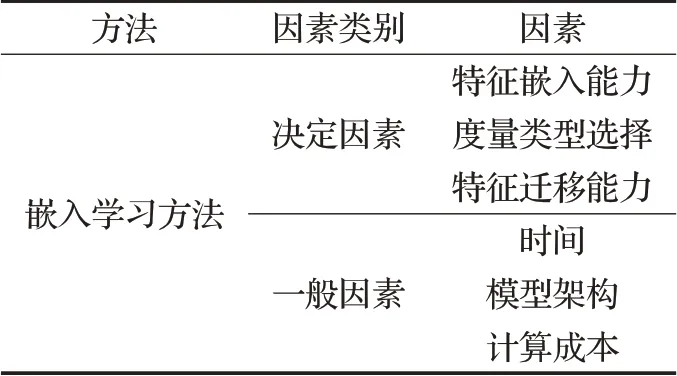
表3 性能影响因素Table 3 Influence factors
结合表3,决定因素是嵌入学习方法影响小样本学习性能的关键,首先是特征嵌入能力,它是小样本学习的基础,好的特征嵌入函数可以充分地提取样本的特征信息,学习到更好的特征表示;其次,度量类型包括固定度量和动态可学习的度量,结合前文所述,采用动态可学习度量方法的性能要比采用固定度量的方法的性能要好,选择不同类型的度量影响最终的学习性能;而特征迁移能力关系到特征嵌入函数对不同任务样本的适应能力,具备较好的特征迁移能力可以让小样本的快速学习和泛化事半功倍。另外,小样本学习的性能还受一般因素影响,一般因素不局限于在嵌入学习方法中施加影响,它们在所有的小样本学习方法中都可产生影响,可以通过灵活调整来影响小样本学习的性能。
3.3 各类嵌入学习方法小结
上一节已经阐述了各个嵌入学习方法,这里分别按方法类别和方法本身对它们总结归纳,对比各类别的嵌入学习方法的优劣势,然后深入各类别的具体方法,分析它们具体的方法机制、优越性、局限性以及它们的适用场景,具体如表4、表5所示。
结合表4和表5,总体而言,两类嵌入学习方法均以CNN为主体架构,主要是通过学习一个特征嵌入函数(空间)并借助相似性度量来进行分类,省略了分类器的参数训练,使整体便于计算和公式化。然而,在实际情况下,无论是辅助数据,还是目标任务样本,或者是其他任务样本,不同样本集的相似性一般,几乎所有方法训练得到的特征嵌入函数容易陷入到过拟合问题中(模型在训练数据上过拟合),基本上都需要额外的数据支持来帮助缓解;另外,大部分嵌入学习方法的可解释性都不高,实际应用价值仍有待提升。

表4 各类别嵌入学习方法的对比Table 4 Comparison of all kinds of embedding learning methods
具体而言,单一嵌入模型中的方法大多都过于依赖外部先验知识的获取,只能适用于那些带较多标注信息样本的应用场景,应用范围狭窄但应用难度小。而混合嵌入模型的方法减少了对先验知识的依赖,提升了对各类任务样本的特征嵌入能力,既保证了模型的可靠性和稳定性,也保证了学习性能的改善,但是成本较高,应用范围广泛但应用难度大。值得一提的是,当前的嵌入学习方法的研究工作大多数以单一嵌入模型为主,发展较为成熟,可供研究以及改进的地方比较有限;而混合嵌入模型作为一类新兴的方法,它主要是在原有的单一嵌入模型的基础上进行改进,目前还在起步阶段。因此,混合嵌入模型仍有很大空间可供研究和完善。
事实上,所有嵌入学习方法都期望以最低的成本实现对小样本的快速学习和泛化,但是现有研究工作无法再训练得到一个可靠且实用性高的特征嵌入函数(空间)的同时消除过拟合问题的影响,不可避免地需要增加成本优化(例如引入外部机制,模型架构改进等),因此目前仍需侧重这个问题进一步深入研究。
4 结论
4.1 面临的挑战
虽然目前嵌入学习方法在解决小样本学习问题取得一些进展,但仍面临着挑战。
(1)过度依赖于辅助数据,预训练的模式违背了小样本学习的本质定义。几乎所有的嵌入学习方法都需要通过大量辅助样本来预训练特征嵌入函数,但在实际应用场景中,很多时候数据量受限,使用辅助样本的思路显得不切实际。还有,使用的辅助数据与当前任务样本的相关性较低时,嵌入学习方法会学习到较差的特征嵌入函数,不利于后续准确地对样本分类,而各类嵌入学习模型或多或少都会面临这种问题,但目前没有较好的解决方法。
(2)模型的设计与训练都过于偏向当前特定的任务基准,对其他任务样本的适用性和泛化性不够。在现有的研究工作中,将模型推广到新的但与目标任务无关的样本并保证其能够对样本快速学习也是需要实现的目标,但是每一类嵌入模型都过度针对特定的基准任务(Episodic Training的子任务)和数据集(辅助数据与目标任务)设计,削弱了对其他任务(新任务)的适用性。
(3)特征嵌入函数的训练模型对信息的结合以及参数的迁移不够明确,缺乏足够的可解释性。人们只知道训练样本的特征嵌入函数时学习了网络参数,但对于训练过程中如何使用外部先验知识以及如何结合目标任务的特征信息等相关细节并不是特别清晰,需要更加明确信息(知识)结合以及参数迁移的过程。
(4)对度量选择依据的讨论不够明确,缺乏对每个方法的最优度量选择的分析。度量的选择会影响小样本学习的最终学习效果,然而各嵌入学习方法并没有权威地讨论本方法选择度量的依据以及选择何种距离度量是最佳的(取得最好的学习效果)。
(5)样本学习的过程中忽视了类内差异的影响。现阶段关于样本类内差异的研究相对较少,大部分嵌入学习方法关注的重点是类间差异,类内差异也会对样本学习的准确率产生影响,这是当前工作需要解决的点。
(6)当前研究工作的梯度迁移算法还不是很合理,大多是针对传统机器学习领域中的大数据集学习,算法实现过程中容易出现过拟合问题。在Episodic training中,每次训练时子任务在学习知识的过程中梯度下降是较缓慢的。当模型迁移到新任务时,受限于样本数量较少,模型期望快速收敛的目标显得十分关键,需要梯度快速下降,但梯度下降过快容易导致过拟合问题的出现。因此,目前还需要针对嵌入学习方法设计合理的梯度下降算法来完善当前的工作,满足小样本学习的需求。
(7)对各领域的应用大多在起步阶段,缺乏足够小样本标准数据集供研究。目前嵌入学习方法只有在图像应用领域的发展较为成熟,而对文本分类,声音分类等领域[87-88]的研究工作仍不成熟。在图像领域中,诸如MiniImagenet数据集和Omniglot数据集等带标注的数据集已经被广泛使用。而在其他应用领域中,标准数据集仅有少数个例,比较有代表性的是Han等人[89]在2018年提出的小样本关系抽取数据集FewRel,构建合适的标准小样本数据集是急需解决的问题。
4.2 展望
梳理目前嵌入学习方法的研究工作,本文对嵌入学习未来的发展方向进行展望。
(1)在数据角度上,可以尝试利用其他先验知识(知识图谱[90])进行特征嵌入函数的训练,探索不依赖模型预训练特征嵌入函数的可行性。训练时,辅助数据中利用较多的是已标注的数据,而现实场景的数据以无标注数据为主,往往无标注数据蕴含着许多有用的信息,值得进行挖掘和利用。因此,未来对无标注数据的合理利用是一个有价值的研究方向。
(2)混合嵌入模型的深入研究尤为必要。对比单一嵌入模型,无论是训练出更优秀且稳定的特征嵌入函数还是缓解过拟合问题方面,混合嵌入模型已经初步证明了自身的巨大优越性和潜力,未来混合嵌入模型势必会成为嵌入学习方法的主流,有必要深层次地研究与完善该类方法。
(3)优化Episodic Training训练模式,设计一个更加强大的元学习器。如今元学习作为新兴的代表,在模型应用上不够成熟,现有的元学习器无法学习到足够且有效的元知识。未来,如何设计好的元学习器并提升学习的有效性和丰富性也是至关重要的研究方向。
(4)设计性能更加优秀的神经网络算法。首先,构建以及训练特征嵌入函数的过程中离不开神经网络的支持,参数能否快速学习和优化决定了特征嵌入函数的有效性;另外,度量的有关研究已经较为成熟,固定度量的改进空间非常小,很可能会被动态的可学习度量取代,而动态度量的学习很大程度依赖于神经网络。综上所述,未来对于性能更优的神经网络算法的设计需求将会越来越大。
(5)尝试结合不同嵌入学习方法中各自的优势,或者在嵌入学习方法的基础上,融合其他小样本学习解决方法(不平衡学习、强化学习等先进机器学习框架)的思想,改进原有的方法,形成新的可靠且有效的解决方法。目前已经有一些组合解决方法的研究工作,后续研究工作不妨以这些优势作为切入点,优势结合或许可以带来性能的质变。例如,可以在学习动态度量时进行度量缩放;其次,鉴于嵌入学习方法中GNN特征表达能力较强,而基于外部记忆学习方法的记忆模块可以不断保存样本中的许多有效信息,同时结合这两种方法有望在样本学习过程中保留更关键的特征信息,设计出性能更为出色的特征嵌入函数;
(6)现有的嵌入学习方法的研究工作需扩展应用领域的范围,局限于较小的应用层次不利于进一步探索和完善该类方法,使得该类方法的整体有效性缺乏说服力。嵌入学习方法现有的应用领域主要集中在计算机视觉(图像处理)的小样本学习问题,而在诸如语音识别、自然语言处理等应用领域中,相关的研究较少,而这些领域的小样本学习问题也值得未来深入开展研究。
猜你喜欢
上海文化(文化研究)(2022年3期)2022-06-28
新世纪智能(数学备考)(2021年9期)2021-11-24
中学生数理化·中考版(2021年3期)2021-07-22
中学生数理化·高一版(2021年2期)2021-03-19
新世纪智能(数学备考)(2020年9期)2021-01-04
中学生数理化(高中版.高考数学)(2020年9期)2020-10-28
五邑大学学报(自然科学版)(2019年3期)2019-09-06
江西教育B(2019年2期)2019-04-12
中国诗歌(2018年6期)2018-11-14
领导决策信息(2018年16期)2018-09-27
