
知识图谱在海洋领域的应用及前景分析综述
2022-02-24 12:31熊中敏马海宇
计算机工程与应用 2022年3期
熊中敏,马海宇,李 帅,张 娜
1.上海海洋大学 信息学院,上海201306
2.成都理工大学 旅游与城乡规划学院,成都 610059
广袤的海洋占据了地球表面近70%的区域,孕育了海量的生物、矿物资源以及能源等。近年来,由于陆地资源的开采与消耗日趋饱和,国家对海洋资源、数据的重视程度进一步提升,提出了坚持陆海统筹,发展海洋经济,建设海洋强国的迫切要求[1]。加之随着人工智能等技术的兴起,一方面推动海洋领域的数据与海洋领域知识海量发展的同时,也极大推进了海洋领域科学研究的发展。当前海洋领域研究方向繁多,海洋经济、海洋遥感、海洋工程等数不胜数,这些条目之间不仅存在着深层次的联系,而且其内还存在着大量的冗余数据和尚待开发的知识文本。如何高效地利用数据的内在关联性与知识间的关联性实现信息检索和信息推理,是当前海洋数据研究与处理的瓶颈之一。
知识图谱(knowledge graph,KG)最早由语义网络发展而来[2],实质上是一个涵盖图结构的知识库,这种存储结构就使得知识图谱能有效存储基于数据与知识间的关联关系。图谱中的节点用以表示实体或者概念,边用以表示实体间或者概念间的语义关系,通过将各类数据和连接关系以节点、边的形式聚合成知识,使得知识图谱可以通过相关的图匹配算法来实现高效的数据以及领域知识的检索[3]。知识图谱的另外一个优点是具备推理能力[4],可以智能地从现有知识挖掘出多方面的隐含知识。也正得益于知识图谱对现实世界中知识的高效组织与整理,促进了人与机器的有效沟通,因此已广泛应用于搜索引擎领域、金融领域[5]、教育领域[6]、农业领域等[7]。由于知识图谱可以通过实体间关系的挖掘找到实体之间更为深层次的联系,应用于海洋领域不仅可以通过相关软件可视化分析来明确领域研究的当前热点、为未来研究方向的推理提供强有力的数据支撑,还可以通过构建海洋特点领域的知识图谱来打破不同场景之间的数据隔阂,为海洋数据面向应用提供助力。
虽然当前知识图谱相关的技术和理论在飞速进步,但当前海洋领域与知识图谱技术的结合还不够深入,无法有效利用相关技术实现对海洋领域知识的进一步获取,且知识图谱在近几年才在海洋领域有了比较大规模的研究,针对知识图谱在海洋领域的应用过程所带来的优势还不明显。另外针对海洋领域,知识图谱的应用场景模糊,当前涉足海洋领域的专业人员无法深入利用知识图谱。针对以上出现的问题,本文总结了应用于海洋领域的知识图谱相关技术的研究进展以及落地实例,为以后海洋领域中采用知识图谱技术提供理论支撑以及技术参考。
知识图谱这一概念自提出以来,涌现了大批学者利用知识图谱出色的关联性表达能力实现相关领域文献的可视化分析[8]。如图1中利用海洋领域的相关文献,通过关键词聚类的方法绘制出海洋领域一段时期内的研究热点与重心,可以把握当前研究态势,紧跟国际研究热潮。伴随着大数据的发展,数据量的上升也催生了相当数量的知识库,例如DBpedia、Freebase、Wikidata等。但以上知识库均存储的是通用领域知识,目前仍然缺乏针对海洋领域的知识图谱型知识库。
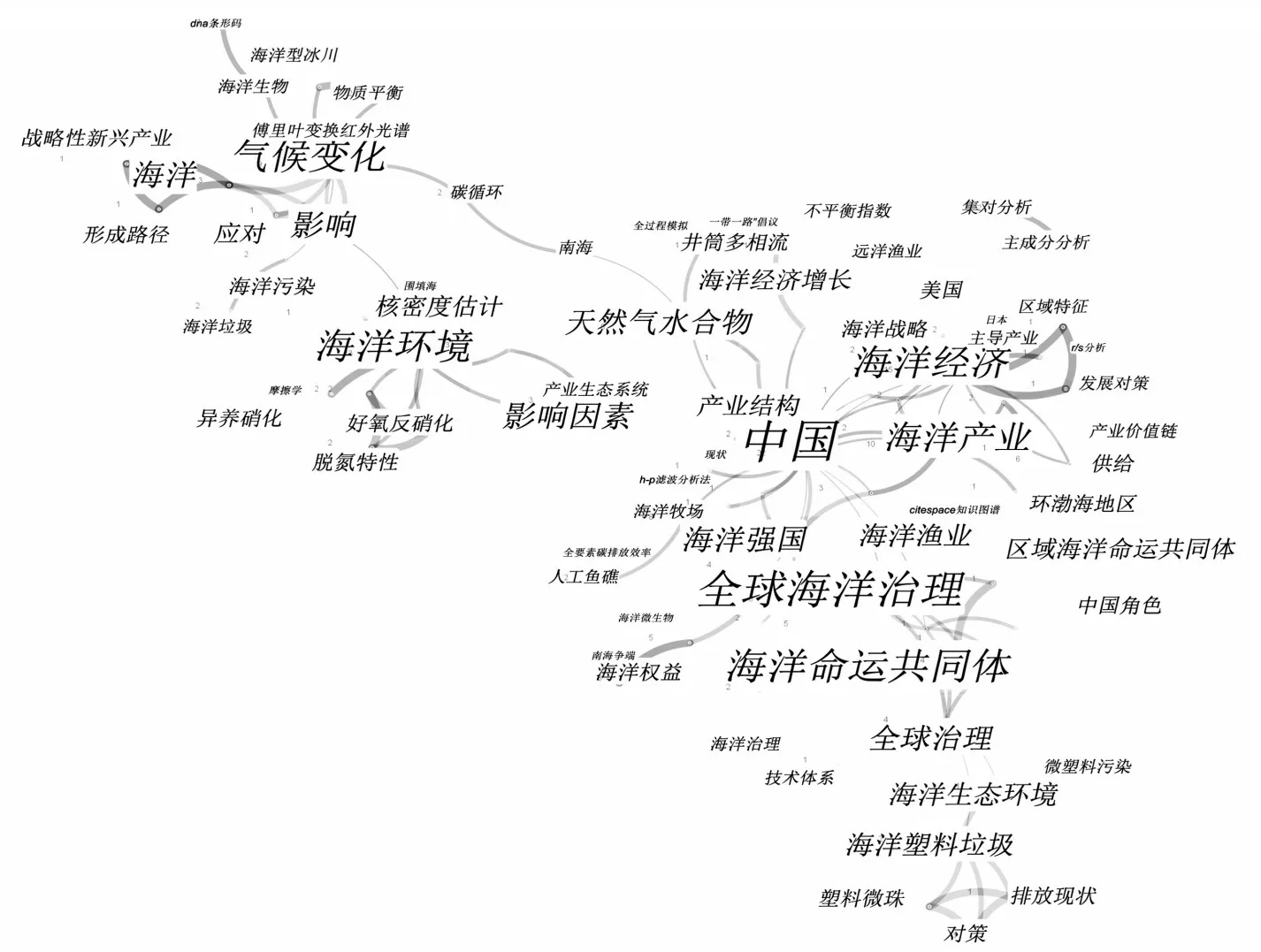
图1 海洋领域文献关键词可视化图谱Fig.1 Visual map of keywords in marine literature
当前阶段,针对国内海洋领域所采用的知识图谱技术尚未出现统一的梳理,本文将当前应用于海洋领域内的知识图谱技术主要分为以下两个方面:(1)以大量文献的统计分析为主,利用构建领域相关分析目标的节点链接图为辅,实现相关领域研究的针对性梳理,用于确定当前的研究热点,进而推理出未来的研究方向。(2)通过知识抽取、知识融合、知识计算和知识应用等关键方法来构建海洋领域的垂直知识图谱,实现对目标的相关知识数据的快速检索。
1 海洋领域知识图谱研究进展
2012年,谷歌将知识图谱这一概念引入学术界[9],利用多源数据增强搜索引擎的匹配精准度。相较于传统的词匹配搜索引擎,基于知识图谱的搜索引擎能够从用户的搜索关键词进行关联分析,准确且清晰反馈给用户问题结果。如图2所示,利用基于知识图谱搜索引擎Magi(https://magi.com)搜索关于“海洋”的信息,可以清楚看到,搜索完毕后显示的界面不仅包含了与海洋有关的页面链接,还在知识图谱的辅助下将海洋相关描述、标签一一对应到网址中。用户可以依此信息快速跳转到自己的搜索目标。这种方式极大地提升了人们的查询效果,也进一步催生了知识图谱的广泛应用。

图2 基于知识图谱引擎的搜索Fig.2 Search based on knowledge graph engine
1.1 海洋领域文献的可视化分析
面对浩如烟海的文献数据,对于科研工作者来说,最为关键的是如何高效、准确地获取有用信息。利用这些信息可以清楚研究方向的发展历程,分析出国家或区域间最为前沿的研究方向以及关注研究的发展趋势。文献计量工具正是基于这些方面,能够有利地帮助研究人员对文献进行快速且准确的分析。本文以六种代表性的辅助工具名称为关键字在CNKI中进行搜索,从中提取了8 295篇文献进行统计分析。在不考虑同时使用多种辅助工具的条件下,得出各项辅助工具在文献中的使用频率占比依次为Citespace(84.68%)、VOSviewer(4.56%)、Ucinet(3.51%)、Histcite(1.65%)、Pajek(1.01%)以及Bibexcel(0.70%)。据此本文对文献分析领域最为常用的前三种可视化分析工具Citespace、VOSviewer以及Ucinet的关键性分析方法进行探究,并对海洋领域文献分析的可用辅助工具进行总结。
1.1.1 CiteSpace
2003年,李杰等人[10]开发出可视化分析工具Star-Walker软件,后又命名为CiteSpace,能够分析众多文献内蕴含的潜在信息,利用相关的可视化方法呈现出探究方向、研究演变规律及分布信息等。最初仅提供文献的共引分析功能,后又引入各个知识间信息的共现分析,如作者、国家、机构等。Citespace支持WoS、CNKI等多个中英文平台文献数据的直接导入,能对科研文献数据进行高效分析,因此广泛应用于领域文献分析工作。本文通过分析海洋领域知识图谱应用的34篇文献,发现最为海洋领域科学工作者常用的CiteSpace分析功能为共被引和耦合网络分析、科研合作网络分析以及主题和领域共现网络分析。
共被引关系是指在文献引用时,若A文献与B文献共同被C文献所引用,则A与B文献之间就存在共被引关系[11]。而耦合关系指的是,在A文献与B文献共同引用C文献时,A文献与B文献之间就存在了耦合关系[12]。在一个文献集中,通过共被引和耦合网络关系挖掘就能找出研究主题相近的文献。
CiteSpace中提供了学者、机构以及国家和地区合作三种分析方式,能够深入探究微观和宏观层次学术间的联系。主题和领域共现针对从文献标题、关键词和摘要中提取的名词性短语以及科学领域名称进行分析,使得每篇被引文献主题更为突出和直观,便于进一步地分析处理。通过以上功能实现的可视化分析能够揭示数据间的复杂联系和隐含联系,在分析和研究学科的动态发展规律上具有显著的优势[13]。
1.1.2 VOSviewer
Van Eck与Waltman在2010年开发出文献计量软件VOSviewer[14],其适用范围不仅涵盖了学术出版物,对于社交媒体及网络上的一些半结构化数据都有着较强的适用性。
VOSviewer能够基于共现数据进行文献作者、期刊以及关键词等的聚类网络构建,且该程序采用了基于距离的图谱构建方式,使得节点的距离远近可以清晰地反馈关系的强弱程度,距离越近则联系越紧密[15]。这种做法易于聚类但网络中存在大量未标记数据时不利于为节点添加标签。
VOSviewer的一大优势是支持从CNKI、WoS、PubMed等一众中英文文献平台的数据信息读取。其操作简单、页面简洁,而且生成的图谱网络能够快速配置,不容易造成节点的堆叠现象。另外网络可视化、时间演变可视化以及密度可视化三种呈现方式大大提高了关键信息的获取能力,故其应用一直较为广泛,但也存在聚类方法固定、不支持对图谱网络的节点细节信息的调整等问题。
1.1.3 Ucinet
Ucinet的问世可追溯至由Freeman[16]创建的版本,后又经Borgatti与Everett的不断完善,迄今为止支持txt、csv、xls、vna格式以及其他程序格式,譬如Pajek、Negopy、Krackplot。
较为特殊的是,Ucinet中的所有数据均采用矩阵的形式存储,因此可以便捷地对数据进行多元统计、凝聚子群检测、等效节点分析与网络的假设检验等,但也限定了读入数据的内容只能为共现矩阵形式。故需对数据进行预处理,较为便捷的做法是利用STAI程序[17]对待分析的文献关键词进行词频统计,将生成的共现关系矩阵导入Ucinet[18]。
此外,对关键词进行可视化分析还需使用Ucinet内置的NetDraw工具,通过节点中心性分析使得在网络中作用强的节点在图谱中更大,在同篇文章中共现强度大的线条更粗。
针对不同作者、地区等来源的文献分析实质上属于整体网络的研究,这种对于众多待分析文献之间的关系进行探究更侧重于关系的传递、整体网密度、距离等,能够深入分析文献之间的结构[19],这也是Ucinet最为明显的优势。但因其还需针对数据进行预处理,无法直接针对各种平台的导出文献直接进行分析,而且无法对聚类网络进行动态呈现及调整,因此近年来在领域文献分析应用上并不广泛。
如表1所示,海洋文献数据量多,在利用Ucinet做领域文献分析时,虽然可以对生成的图谱网络进行自定义操作,但其不能够直接对平台数据进行利用,相较于VOSviewer缺乏了便捷性,且关键词等数据信息过多时,标签的堆叠会影响可视化效果。VOSviewer学习成本低,使用便捷且附带的密度可视化功能能够最大程度上提供关键信息,适合处理大型复杂数据。但其聚类核心算法较为单一且固定,而且难以对聚类图谱的节点进行自由调整。Citespace结合了Ucient与VOSviewer的优势,既能够直接对中英文文献数据进行分析,还提供了集群视图、时间轴视图等呈现方式,功能更加丰富,可操控性更强,因此Citespace广泛应用于各领域文献分析中。本文将重点探究利用Citespace进行海洋领域文献分析的演变历程。

表1 常用文献计量工具对比表Table1 Comparison table of commonly used bibliometric tools
1.1.4 海洋文献的可视化分析演变
早在2012年知识图谱正式被谷歌提出之前,贠强等人[20]将主题共现分析引入海洋水产业,通过梳理各国海洋水产养殖论文的高频关键词,绘制出类图谱形式的网络,从而得出了不同国家针对海洋水产领域养殖的主要关注点。但众多关键词属于并列存在,图谱中每个节点都堆叠了大量的关键词,既增加了分析的难度,也没有很好地凸显主要关键词的重要性,起到的辅助效果并不显著。
2016年,韩增林等人[21]将当时已经较为成熟的CiteSpace软件应用到了中国海洋资源分析上,通过将关键词以及作者图谱化,已经能够做到将相关重点信息突出显示,正式拉开了将CiteSpace可视化工具引入海洋领域文献分析的序幕。CiteSpace可视化有利于彰显关键信息,但不利于多项详细数据的对比,针对这一问题,2017年,张福俊等人[22]结合关键词统计三线表和基于共词分析的知识图谱用于海洋科学领域内的分析。
从2018年开始,以关键词、作者以及研究机构数据对比三线表和关键词图谱的联合分析已渐成主流分析方式,诸如海洋药物[23]、珊瑚礁[24]、海洋油气安全等[25]研究方向较为具体的领域也开始沿用这一方式。2019年和2020年,针对海洋领域的相关文献分析实现井喷式增长,上海海洋大学[26-31]、中国海洋大学[32-33]等高校科研机构开始大量将知识图谱应用于海洋领域进行文献分析,也标志着知识图谱技术在海洋领域文献分析地位的正式确立,但依托可视化图谱工具形成的聚类网络缺乏分析,还需科研人员的深入研究和知识再加工,而且针对海洋领域文献的探究尚停留在分析阶段,如何有效地将学术联系实际数据,真正与实际应用相结合是目前海洋学术领域有待商榷的问题。
1.2 海洋领域垂直图谱构建
海洋领域的知识图谱可以表示海洋领域数据与知识属性、数据与知识间的内在关联。如图3,利用数据层和方法层的构建,就能够做到很好地服务于应用层。大体上,服务于海洋领域的知识图谱与服务于通用知识的图谱结构上相同,但又有以下几个特性[34]:(1)不同于通用知识图谱的全面概括性,海洋领域的数据与知识只涵盖海洋领域范畴内的研究对象。例如海洋生物、海洋环境等。相较于通用知识图谱具备更高的精度以及更为严格的可解释性,利于海洋领域专家及研究人员对其结果进行验证分析与理解。(2)通用知识图谱可以利用网络的开放资源进行构建,面向的服务对象较为宽泛,数据来源也不作过多要求,但海洋领域垂直图谱对数据来源要求苛刻,多数源于自身的数据观测与积累以及相关权威机构的数据发布,部分难以直接从网络中获得,因此有很大的局限性。以上这些特性也决定了海洋领域垂直图谱的构建方式。
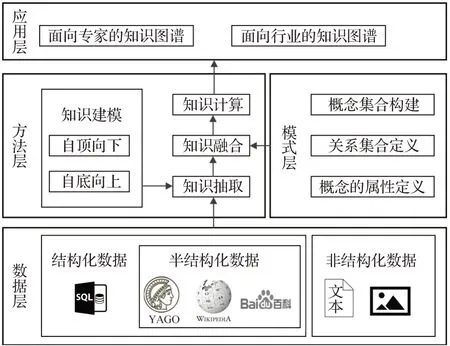
图3 知识图谱结构Fig.3 Knowledge graph structure
当前服务于特定领域的知识图谱构建主要分为自顶向下和自底向上两种方法[35]。自顶向下方法主要依托完善的高质量结构化数据,需要人工事先定义好本体框架,再抽取输入数据的相关实体、关系等信息完成图谱的构建,这种方法主要针对行业知识图谱、特定领域知识图谱等。而自底向上的方式则是从网络上的开放数据集和非结构化文本中提取出置信度高的知识数据,这种方法能够大批量地获取广泛数据,因此适用于通用知识图谱的构建,在缺乏专业数据时,自底向上同样可以应用于海洋领域,不仅能够节省人力成本,而且在高质量数据缺乏时构建效果要优于自顶向上的方式。本文主要针对面向海洋领域的垂直图谱构建技术进行分析与探究。
根据国家海洋科学中心(http://mds.nmdis.org.cn)的分类,海洋数据大体可分为两种属性:(1)海洋水文、海洋气象、海洋生物、海洋化学、海洋地质、海洋地球物理以及海洋地形等实测数据。(2)海洋环境遥感产品、遥感影响、海底地形以及矢量地图数据等地理与遥感数据。以上涉及海洋领域的数据类型可分为非结构化与结构化两种[36],其中结构化数据中又包含半结构化数据。本文主要基于较难提取的半结构化以及非结构化这两种数据进行海洋垂直图谱的构建分析。其中涉及的关键技术主要有海洋领域知识抽取、海洋领域知识融合以及针对融合后知识的计算。下面将介绍知识抽取涉及到的关键技术、知识融合和知识计算的方法,为应用于海洋领域的知识图谱技术提供合适的方法参考。
1.2.1 针对海洋领域非结构化数据的抽取
构建大型的知识图谱离不开知识抽取,知识抽取本质上就是从异源异构的数据中提炼出知识并存入知识图谱中[37]。海洋领域非结构化的数据涵盖政府发布海洋灾害文件、海洋生物新闻报道以及海洋类科技文献等,Wiki百科数据由于数据量多、覆盖面广,因此也是分析的重点。利用命名实体识别技术、关系抽取技术、事件抽取技术可以从非结构化的数据中抽取出相应的知识。
(1)命名实体识别
命名实体即含有名称的短语,涵盖人名、地名、机构名、时间以及数量[38]。海洋领域命名实体识别的关键在于从众多文本中挖掘出命名实体,诸如海洋生物名称、地理位置、时间和日期等,并将这些信息分配至预先定义的类别中。如图4所示,给定一句文本数据“蓝鲸主要分布于南极海域,以磷虾和浮游动物为食”,其中“蓝鲸”“磷虾”“浮游动物”归属为名称类型实体,而“南极海域”归属为地理位置类型的实体。命名实体识别技术可分为基于规则、基于统计模型以及基于深度学习三种[39]。
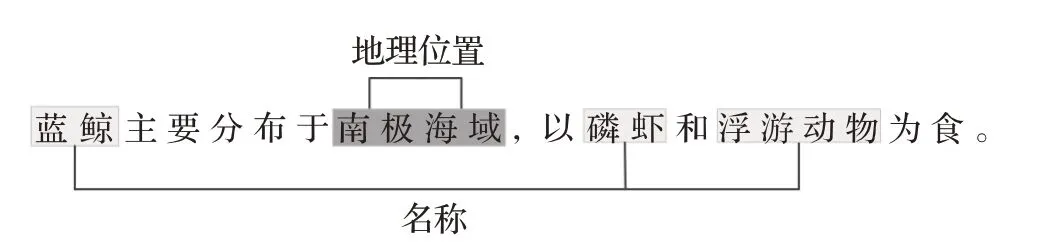
图4 实体抽取举例Fig.4 Entity extraction example
基于规则的技术涉及到大量人工规则的制订,高度依赖规则的准确性,因此规则制定人员局限于特定领域专家,在面对较大数据集时,构建周期较为漫长且可移植性差,不如基于统计模型与基于深度学习的技术较为常用。
②基于统计模型
基于统计模型的技术囊括了隐马尔可夫模型(hidden Markov model,HMM),条件马尔可夫模型(conditional Markov model,CMM)、条件随机场模型(conditional random fields,CRF)与最大熵模型(maximum entropy model,MEM)。其中HMM模型和CRF模型在实体抽取方面最为常用,这两种模型采用标注过的语料对模型进行训练,能够在当前输入特征与先前预测标签之间建立相互依赖关系,使得模型一步步修正。
HMM模型[40]如图5所示,其结构为有向图,本质为概率模型,在统计学习模型的应用中包含可观测序列和隐藏状态序列,在一段语句中,可被观察到的语句称为可观测序列,而起潜在表达作用的就是隐藏状态序列,在命名实体识别应用中,词标注序列和待标注的观测序列对应可观测序列与隐藏状态序列。其中随机变量x t为t时刻的词标注,随机变量y t为t时刻的待标注观测值,箭头表示条件依赖关系。HMM模型有两个基本假设:
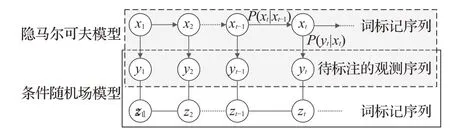
图5 HMM模型结构与线性链CRF模型结构Fig.5 HMM model structure and linear chain CRF model structure
假设1 HMM模型具有明显的相关性,在任意t时刻的标注信息仅且只依赖t-1时刻的标注信息。
假设2针对任意t时刻的待标注数据仅且只依赖t时刻的马尔可夫链状态信息。可以看出HMM高度注重依赖关系。
郑鹏[41]针对海洋季风,构建了季风专用HMM模型,较早地将HMM模型引入了海洋领域。但因HMM模型仅与状态及其对应的观察对象相关,故难以避免地忽视了观测序列长度信息以及语句信息的上下文等重要信息。
CRF模型[42]规避了HMM模型苛刻的假设条件,因此能够囊括任意位置的上下文信息,在一定程度上针对HMM模型的不足做了弥补。CRF模型其实质是一个条件概率模型,利用给定输入标记序列来预测待标记的观测序列,通过给定的数据训练集,该模型利用极大似然估计生成条件概率模型。在对新数据进行标注时,给定输入序列y,模型输出使P(z|y)该条件概率最大的z。
在海洋领域中,命名实体识别技术很少只采用统计学模型的方法进行,一方面原因就是只采用统计学模型进行实体抽取往往精度不高,再者就是伴随着深度学习技术的愈发成熟,更多学者选择将统计模型和深度学习方法综合起来,达到省去人工定义特征和一些外部资源的效果。
③基于深度学习
2016年起,针对神经网络的研究成果迎来了高产期,因其网络中包含许多隐藏层与隐藏节点,使得神经网络具有出色的表达能力以及对数据的拟合能力,因此也普遍应用在了自然语言处理(natural language processing,NLP)领域[43],命名实体识别也得益于此,有了进一步发展。其典型代表包含卷积神经网络(convolutional neural network,CNN)、循环神经网络(recurrent neural network,RNN)和融合注意力机制的神经网络[44]。2016年Lample等人[45]提出BiLSTM-CRF模型,率先将统计模型与深度学习技术相融合应用于命名实体识别,如图6,应用双向长短时记忆神经网络(bidirectional long shotterm memory neural network,BiLSTM)将每个词的左侧l n、右侧r n向量进行连接,构成词的向量c n输出给CRF层后,再由CRF层标注句子中的实体。与单一CRF相比,能够引入与单个词相关的左右含义,进一步提高了标注的精准度。
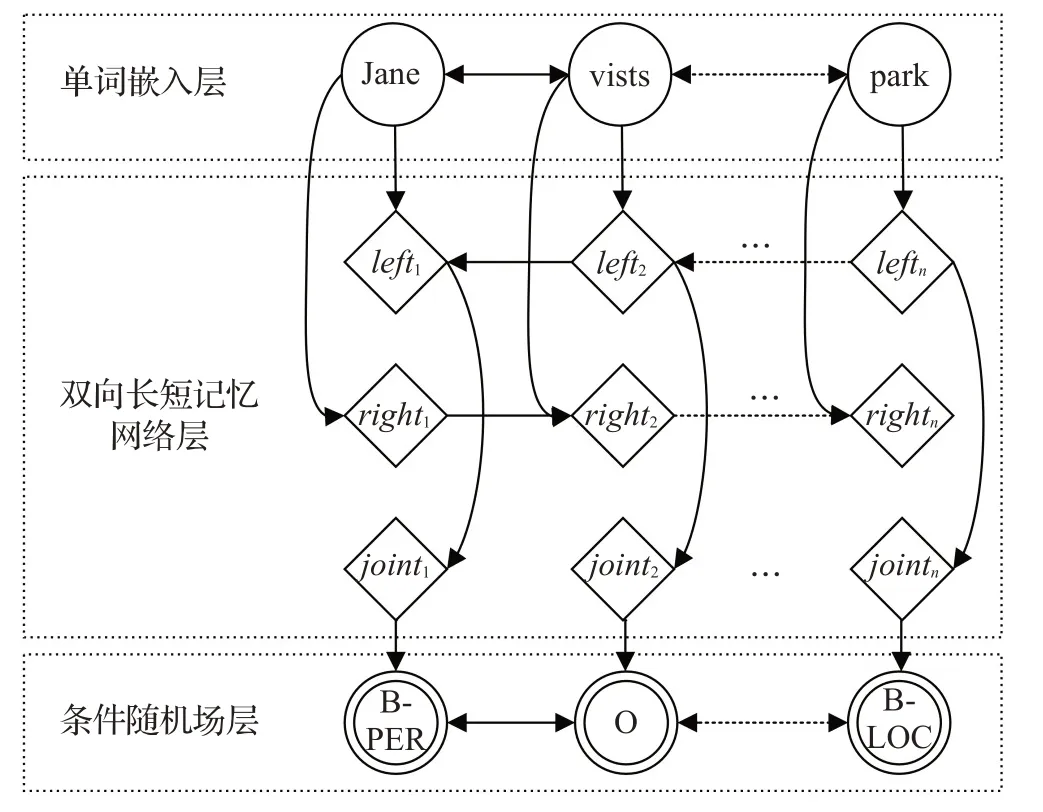
图6 BiLSTM-CRF结构图Fig.6 BiLSTM-CRF structure diagram
Ma等人[46]在BiLSTM-CRF模型的基础上又引入了卷积神经网络,提出了BiLSTM-CNNs-CRF模型,相较于前一模型,该模型通过在嵌入层引入CNN来从单词字符中提取词形信息,并将提取的信息编码为能被机器开发的神经表征,能够解决当前深度学习中过于依赖领域知识和手工定义特征的问题。如图7,用于实体识别的CNN[47]是将字符嵌入经过Dropout抑制过拟合后再进行卷积,通过最大值池化处理降低特征向量的大小,再生成字符级的向量表示。这种在嵌入层的处理方式不再基于标注数据,能自动化抽取相关实体并且能够最大化地提取实体特征,使得F1值进一步提高。
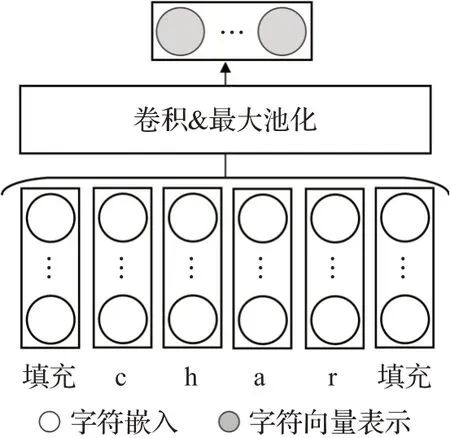
图7 CNN神经表征生成图Fig.7 CNN neural representation generation map
贺琳等人[48]为解决外来海洋生物实体识别效果较差的问题,在前两个模型的基础上,为了减少参数量,优化网络结构,将BiLSTM模块替换为双向门控循环单元(bidirectional gated recurrent unit,BiGRU),提出了CNN-BiGRU-CRF模型。由于注意力机制借鉴了人类对不同事物的关注度不同,因此引入注意力机制可以有选择地重视部分关键信息,而相应忽视同时接收到的其他信息[49],将其引入文本处理中可以赋予重点文本较高权重,而相应减少其他文本权重。贺琳等人在Bi GRUCRF层中采用了图8所示的融合注意力机制(attention mechanism,AM)[50]的向量组合方法。模型先通过BiGRU学习和表示外来生物文本级别数据的上下文信息,再利用注意力机制来获取海洋生物实体的重点语义特征,能够避免文本数据中的长距离依赖问题,提高了海洋生物的实体识别准确度,也为今后海洋生物、概念等信息识别提供了参考借鉴。
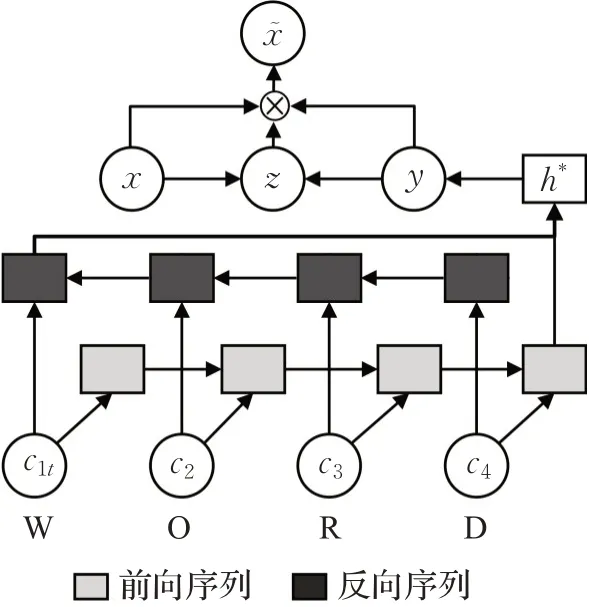
图8 融合AM的词向量与字符级向量结构Fig.8 Combining AM’s word vector and characterlevel vector structure
因为注意力机制更依赖外在因素,He等人[51]将图9所示的多头自注意力机制引入中国海洋文本数据的实体识别中,利用知识图嵌入向量和BiLSTM的输出向量共同作为自注意力机制的输入向量,同时兼顾了特征的内部相关性和长序列依赖关系,进一步提高了外来海洋生物实体识别的准确度,提升了对语料库的实体识别能力。在海洋数据上的出色应用也进一步明确了多头注意力机制在海洋领域的使用前景。
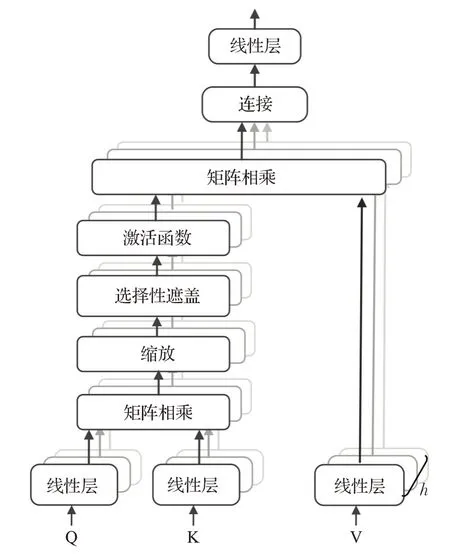
图9 多头注意力机制结构Fig.9 Multi-head attention mechanism structure
④海洋领域命名实体识别难点及技术分析
相较于通用的实体识别,海洋领域的部分名词实体过长,例如鱼类“魏氏小公鱼”与“西伯利亚多棘牛尾鱼”等,其中“魏氏”“小公鱼”“西伯利亚”“牛尾鱼”等又是一个独立的实体单位,这就造成了长实体中往往会包含多个短实体,因此海洋领域实体边界较为模糊,识别难度大。再者,如“新月锦鱼”又称“青衣鱼”“花面龙”“花面绿龙”等,海洋生物的别称较多,同种物体别称可达数种,也进一步增加了实体识别的难度。另一就是数据的质量问题,标注海洋领域实体数据对专业素质要求严苛,因此利用未标注数据训练模型来进行实体识别就显得尤为重要。
如表2所示,可以看出在小规模数据集上,手工编写规则依靠人力进行,因而可以考虑到海洋生物数据的多种指代现象,其精准度更高。然而这种方法要求规则编写者对海洋数据有相当程度的了解,而且构建规则费时费力,故仅局限于小规模简单数据集。HMM模型以及CRF模型能够节省人力成本,但对于序列文本的上下文信息获取乏力,在丢失了上下文可能对当前实体识别数据造成的影响后,容易造成实体的识别误差,但上下文数据不可能对后续所有实体识别都造成影响,因此也要避免当前的实体不受较长时间的状态的干扰。BiLSTM-CRF模型能够解决当前状态被很长时间前状态影响的问题,CNN-BiGRU-CRF模型和BiLSTM-MultiAtt-CRF模型则是在BiLSTM-CRF的基础上对内外依赖关系做出了调整。在海洋类数据集较小且短序列文本居多时,可以采用CRF以及融合BiLSTM与CRF的模型,因其网络结构简单,能够有效地提升运行速度。当需要处理较大规模海洋数据且存在长序列复杂关系时,CNNBiGRU-CRF模型能够在更为轻量化的网络结构中处理数据,更加适合这种大型数据的处理,当需处理的海洋类数据对精度较为敏感时,可以采用BiLSTM-Multi-Att-CRF模型,有效捕捉特征的内部相关性,进一步提升结果精准度。
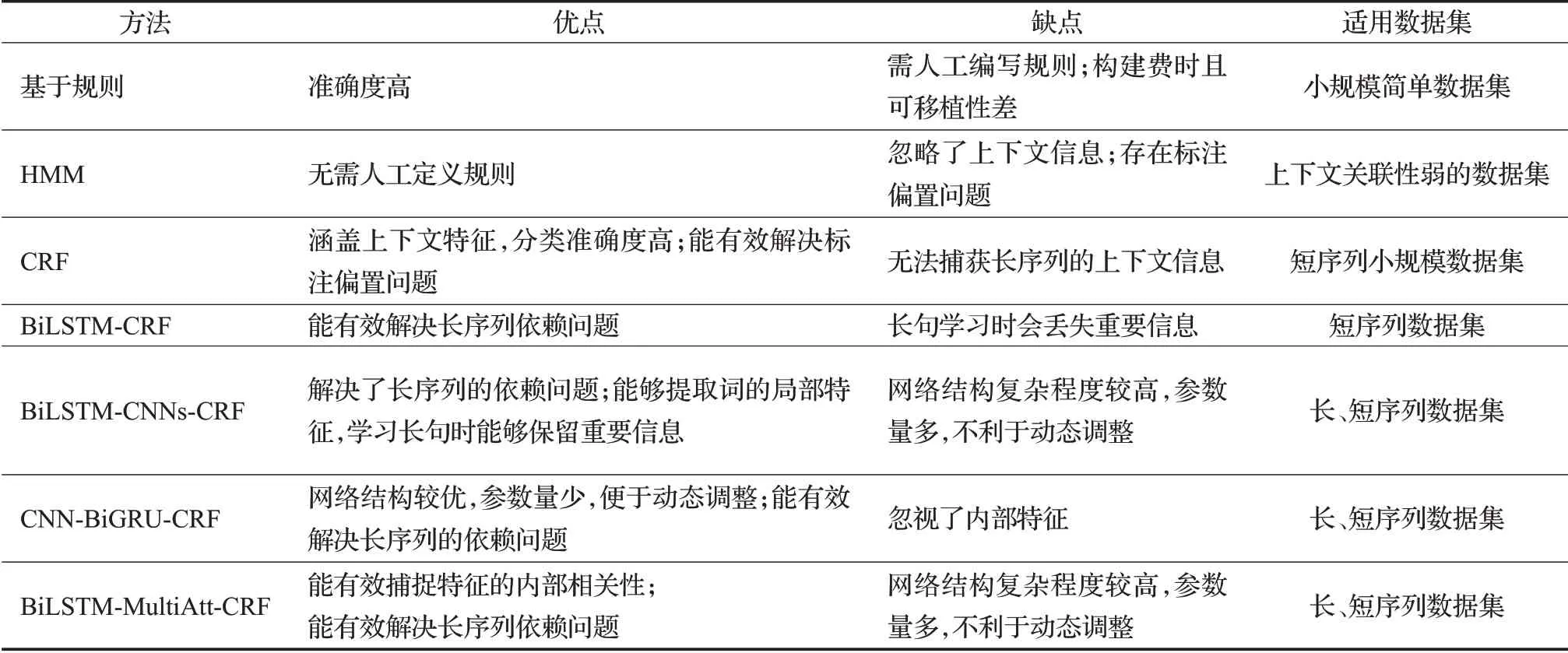
表2 命名实体识别方法优缺对比表Table 2 Comparison of advantages and disadvantages of named entity recognition methods
(2)关系抽取
海洋数据语料在通过实体抽取后,生成一些离散的命名实体,为能够获取语义方面的信息,需从对应文本语料中捕获实体内的存在的相互关系,利用这种相互关系将实体与对应关系关联起来,最终构成网状的结构数据[52]。作为NLP的重点内容之一,关系抽取目的在于发现给定的非结构化数据中实体对间的首尾关系,其方法可分为模板匹配法、监督学习法与弱监督学习法。
①手工模板匹配
早期利用手工建立模板匹配的方法可以对简单的小规模数据做到快速抽取,例如对“蓝鲸分布于南极海域。”进行模板化处理可以得到“X分布于Y。”运用该模板进行文本数据匹配就可捕获到含有“分布”关系的实体。但由于海洋类数据集较大,关系错综复杂,且手工构建需要海洋领域专家具备一定的语言学基础,同时又要求对NLP领域有着深层次的理解,制定难度较大,因此鲜有海洋类数据关系依托手工模板进行抽取。
②基于监督学习
基于监督学习的关系抽取避免了手工制订模板的短板,利用大量标注数据来训练模型后对特定关系进行匹配识别与抽取。在深度学习中,关系抽取被等同于分类进行处理,Zeng等人[53]率先将CNN用于关系分类,将单词转换为向量,参照输入词汇进行词级特征抽取,同时采用CNN进行语句级特征的捕获,将词级特征与句子级特征进行简单拼接并运用激活函数得到最终结果,由于兼顾考虑了词汇与语句的特征,在关系分类中优于当时最为先进的方法。
虽然这种关注位置特征的模型有其优越性,但将重点放在位置特征上时忽视了一些起着关键作用的信息。为解决这一问题,Wang等人[54]提出Attention CNNs模型,把成熟的注意力机制融合到CNN中,经过在输入层融入词与实体关联的注意力并在池化层中融合目标关系的注意力这两种针对性的方式,有效提升关系抽取的精度。
随着预处理模型Bert在NLP分类任务上取得显著的提升效果,Wu等人脱离了CNN架构,首先将预处理模型用于关系分类,提出了一个结合目标信息与预训练Bert模型的新模型[55]。如图10,该模型在目标实体前后插入用以识别特定目标实体的特殊标记,再将处理过的文本输入Bert预训练模型中进行参数微调,最后利用Bert模型的输出嵌入以及句子编码作为多层神经网络的输入进行分,该模型能够兼顾获取语句以及实体间的语义关系,在SemEval-2010 task 8数据集上得到了最为先进的成果。预处理模型不仅在关系分类上表现不俗,在各个方面应用也较为广泛,但目前在海洋领域还鲜有预处理模型的应用,这也是以后的研究趋势之一。
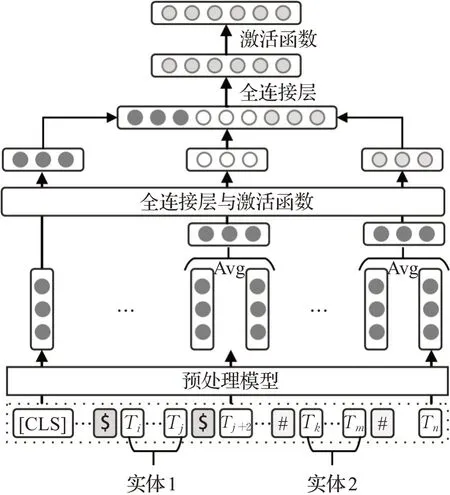
图10 预处理模型用于关系抽取Fig.10 Preprocessing model for relation extraction
尽管监督学习法在关系抽取中产生了很大的效用,但因监督学习需要大批量的训练数据,面对小批量数据时无法产生很好的效果。无监督学习的方法可解释性差,缺乏比较客观的评价指标,其优势在于无需人工标注数据且可以忽略实体对所蕴含的领域知识,但不适用于海洋领域。采用弱监督学习的关系抽取融合了监督学习以及无监督学习的长处,能够只运用小批量标注信息实现模型的训练,主要采用远程监督方法,该方法更为依赖现存知识库的知识信息。
早在2009年,Mintz等人[56]为应对训练样本不足的情况,在关系抽取中结合了远程监督的方法,其实质是利用现有知识库自动标注大规模训练数据。通过从Wikipedia等知识集合中提取出蕴含关系的实体对当作抽取标准,再从非结构性的语料中提取出此标准的语句当作训练样本,将该训练样本用于模型的训练后再进行关系的提取。这种通过知识图谱自动对齐语料来获取大量标注数据进行模型训练的方式有效减少了人工的主观干预,但训练数据集之中含有大批量噪声,这就使得一些语义出现有误标注。
为解决这一问题,Zeng等人[57]将CNN关系抽取模型运用于远程监督语料中,提出分段卷积神经网络(piecewise convolutional neural networks,PCNNs),将远程监督关系的抽取视作多实例问题,由未知标签的实例组成多个包,再由已知标签的众多包组成训练集。一定程度上保证了实体句子与知识库中关系的对应,提高了关系抽取的精度。
Ji等人[58]基于PCNNs模型,将PCNNs融合注意力机制,提出了APCNNs模型,通过句子层级的注意力模型在同一实体对的实例包中选取多个实例来最大化利用有效信息,相较于PCNNS性能有所提升。但其实质是引入实体对的描述来改进关系抽取能力,相对文本句等形式缺乏了上下文关系。
Qin等人[59]另辟蹊径,将生成对抗网络(generative adversarial network,GAN)用于稳健的远程监督关系抽取,通过对抗性训练提高模型的鲁棒性,提出了DSGAN模型,相较于APCNNs在t检验中P值有了明显提升。但由于Qin等人只对远程监督的关系抽取模型的噪声加以控制,来达到抑制训练集中噪声的影响,还是会存在一定量的错误标签数据。
Feng[60]与Zheng等人[61]利用强化学习(reinforcement learning,RL)的环境交互性,对比远程监督的已标记数据标签和模型预测数据标签的差异性来学习更正错误标签。与之前的PCNNs和APNNs着重实体对的描述不同,强化学习以文本句为单位,有效提升了在语句层面的关系分类性能。这种方式同样也适应于数据量较少的非结构化海洋数据,利用一系列相关文本文件,结合GAN或者强化学习来降低数据集噪声,达到抽取实体间关系的目的。
②海洋领域关系抽取难点及技术分析
不同于通用领域的实体关系抽取,海洋领域由于数据的特殊性,为保证关系抽取的精度,大多采用监督学习的方式进行,因而对于技术人员的海洋领域知识要求较高。另一方面,当海洋数据横跨多个子领域时,会造成关系间跨度过大,普通关系抽取方法难以为继等问题。
关系抽取的精度高度依靠于数据集的规模,如表3所示,手工模板匹配能够在小规模简单数据集中表现出色,但专业性人力的占用是不能够避免的缺陷。CNNs模型可以在通用语义评测数据集上捕获远距离特征,并且节省了人力资源,能够对实体关系做到高效抽取。当需要进行关系抽取的海洋类数据集规模较小且数据量较少时,可应用CNNs模型对实体间的关系进行提取,但由于模型结构简单,不能够对深层次的关系有效的识别,Attention CNNs应运而生,极大提升了关系抽取的精确度,并由于引入注意力机制,能够对横跨子领域的实体起到不错的识别作用。随着Bert模型在NLP领域内出色的表现,大量学者将其运用到关系抽取中来,这种预处理模型适用性非常强,但同时也对数据集的规模做出了严苛要求,小型数据集很容易过拟合,PCNNs、APCNNs、DSGAN也是如此。强化学习方法比前几种方法具备更强的适用性,由于不依赖模型,因此能够适用于绝大部分神经网络结构,目前鲜有在海洋类数据集上的应用,这也是未来有待探究的方向。
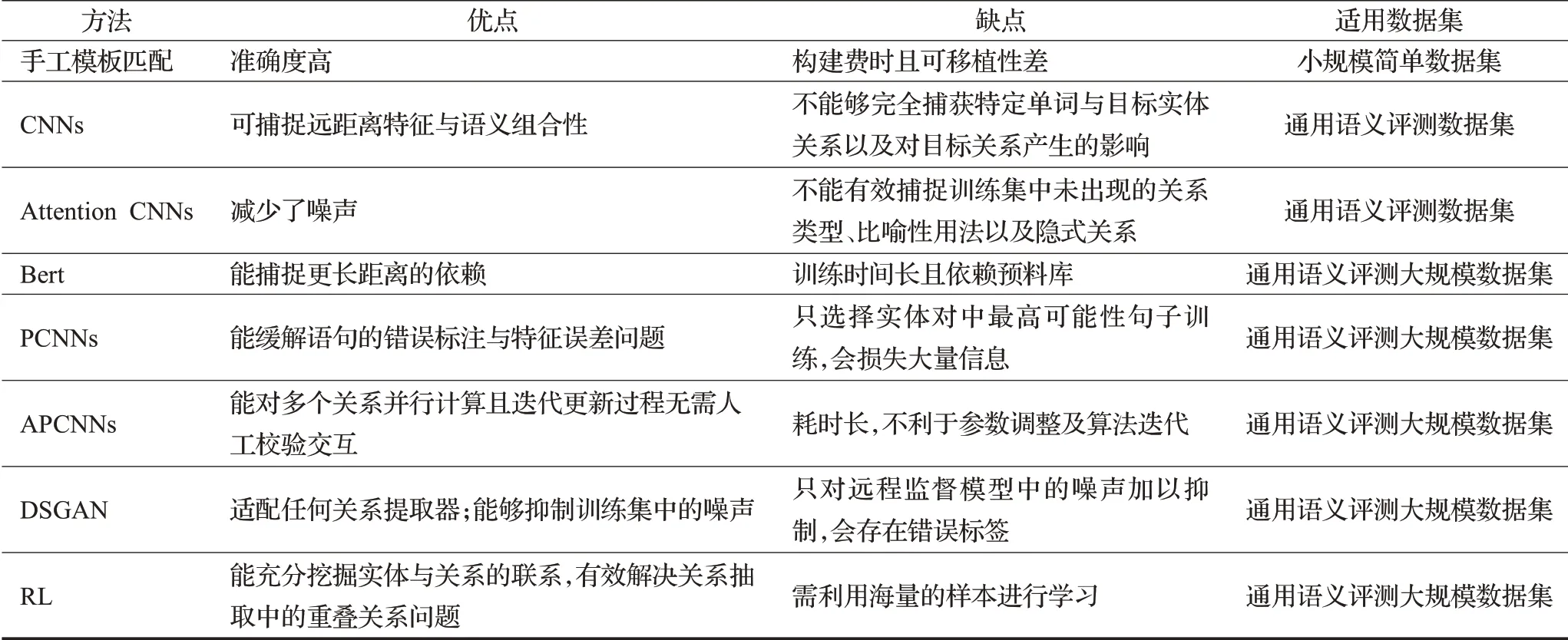
表3 关系抽取方法优缺点对比表Tab.3 Comparison table of advantages and disadvantages of relation extraction methods
(3)事件抽取
事件即实际发生的事实,一般情况下包含时间、地点、人物等属性信息[62],例如海洋灾害、海洋科技新闻等。事件抽取旨在从一系列非结构化类型的数据中提取出靶用户关注的事情,并辅以结构化形式表现出来,其依赖于实体识别与关系抽取的提取结果。
Ahn等人[63]将事件抽取流程进行了标准化制定,首先依据最能够准确表达事件发生的关键词为触发词识别出文本中蕴含的事件及类型,再从文本句中抽取出参与一个具体事件的元素并判断其与参与事件的关系,接着提取出描述事件的词汇或文本句后对事件进行属性标注和指代消解。通过以上的事件抽取方法,能够完成关于文本事件信息的自动提取。例如图11中,对给定的非结构化数据运用事件抽取技术,可以将其生成事件类型、时间、地点以及结果等结构化数据。但是这种将事件抽取建模成多分类问题的流水线式方法由于各阶段子任务相互独立,会难以防止误差累积传递现象的发生,使事件抽取的效果大打折扣。
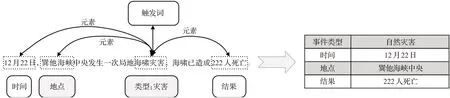
图11 事件抽取示例Fig.11 Event extraction example
①基本模型
Li等人[64]为解决这一问题,提出了一种联合模型,将事件中所有关联信息利用同一模型一起抽取,兼具了局部特征和全局特征,避免了累积误差对事件抽取造成的性能影响。但这种模型不仅需要人工来设计特征,还需借助外部工具抽取事件句的特征。
Chen等人[65]提出了动态多池卷积神经网络(dynamic multi-pooling convolutional neural networks,DMCNN)模型,该方法可以在不使用复杂外部工具的条件下,进行词汇级以及语句级特征的自动捕捉,并通过动态的多层池化卷积保留了多事件句中的重要信息,最大程度上捕捉了事件中的关键特征。
②混合处理模型
在Li等人成功将预处理模型用于关系抽取的同年,Tian等人[66]将Bert预处理模型用于事件抽取,将Bert模型与BiLSTM层和CRF结构相融合,此新模型能够将单个事件进行双向分析并兼顾对多事件信息运用关联分析,这种方式不仅能够获取参数间的联系,还可以捕捉到不同事件之间的共有关系。在F1-Score上相较于其他模型精进了4%~6%。这种引入预处理模型的方法虽然效果出众,但需要大量的标注训练数据,在利用大量数据对预处理模型进行微调后模型才能发挥最大的效果。
Zhang等人[67]基于联合事件与关系抽取提出了一个联合抽取的新方法,与Tian等人联合Bert、BiLSTM、CRF相同的是,Zhang等人也采用BiLSTM学习事件关系。不同的是,如图12所示,Zhang引入注意力机制来获得事件文本句中的重要特征,将事件检测与关系抽取以迭代的方式交互学习,逐渐提高模型的性能,在较低资源配置的情况比以往方法取得了F1-Score精进1.6%~1.8%的效果。这些方法在海洋领域事件抽取时给出了一些启发,当海洋类型语料库较大,已标记事件文本句较为充足的条件下,Tian等人的方法更胜一筹,精度最高且事件抽取效果最好。在海洋类型数据量较少,缺乏一定程度的标记数据时,Zhang等人的事件抽取表现效果最佳。
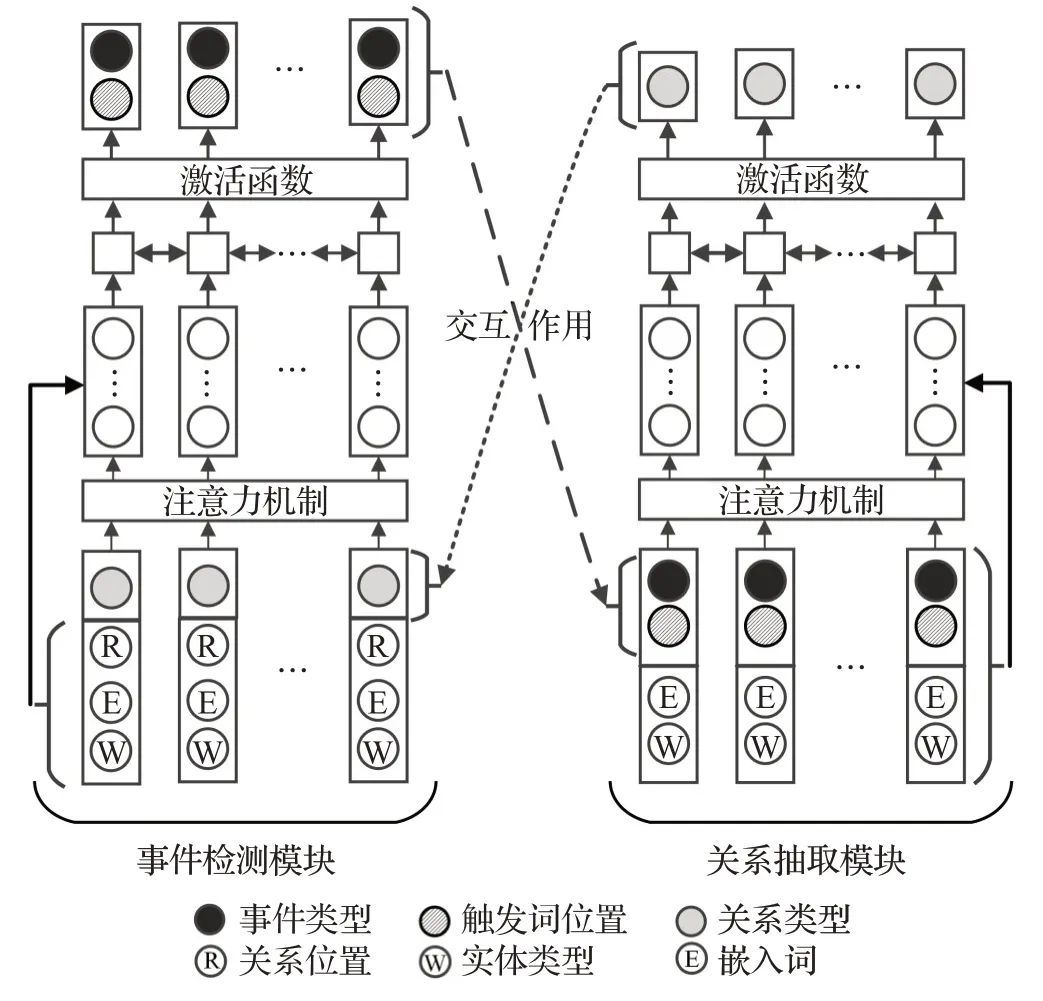
图12 小规模数据抽取模型Fig.12 Small-scale data extraction model
③海洋领域事件抽取难点及技术分析
海洋领域事件型数据以海洋灾害报告、海洋科技介绍等为主,使得海洋事件信息的来源具有局限性,可用资源较少。另外海洋数据中多有代指现象,譬如台风“杜鹃”,因此有可能会出现同一事件中实体名称相同但指代对象不同的情况。最后,海洋领域多个事件之间可能产生联系,譬如台风运动轨迹事件与台风灾害事件,加大了事件抽取的难度。
在事件抽取中,如表4所示,当事件内无联系或者存在弱联系时,通用的标准化方法就可以完成对事件的抽取,但这种方法无法解决海洋领域事件内同一名称实体的多种指代问题,DMCNN模型则能够很好地捕捉多事件句中的重要特征。但以上方法适用数据集较为局限,Bert-BiLSTM-CRF模型与BiLSTM-Att模型能够很好地对事件内和多个事件间的联系进行有效抽取,可以应用于海洋类数据集。当海洋类数据集较大时,利用Bert-BiLSTM-CRF模型进行事件的抽取可以获得更高的准确度,而当海洋类数据集较小时,利用BiLSTM-Att模型可以解决标注数据不足的问题,使得在小规模海洋数据集的应用上表现突出。

表4 事件抽取方法优缺对比表Table 4 Comparison table of advantages and disadvantages of event extraction methods
1.2.2 针对海洋领域半结构化数据的抽取
非结构化的数据在一定程度上造成了知识抽取的复杂性,随着Wikipedia、网页等百科类及网页数据的发展,一些半结构化类型的数据愈来愈丰富,由于半结构化数据类型较为特别,虽然与数据表的模式结构不一致,但涵盖了能够区分语义类型的相关标识,并且可以分割记录以及字段,因此也催生了相关知识抽取技术的应用。
(1)百科类数据抽取
以Wiki百科为典型代表知识数据库,不仅数据量庞大,且由于采用了质量控制机制,因此在数据海量发展的同时还能在一定程度上保证了信息的准确性,普遍作为建立大型知识图谱的关键数据来源[68]。当前大型且高度完善的知识库如Yago[69]与DBpedia[70]等旨在从Wiki百科中抽取数据进行半自动或自动化构建。其中Yago知识库从Wiki百科中抽取众多类型与信息框,并融合面向语义类型的英文词典WordNet,对知识的抽取具有相当程度的精准性与高效性,但Yago的知识抽取面对已定义好的文本范围以及语义关系时无法起到很好的效果[71],DBpedia直接从Wiki百科词条信息框中抽取出的结构化信息作为实体属性与实体关系[72],弥补了Yago知识库的不足。而且为了解决以上抽取方式所造成的不同表达实体名称具有相同语义关系的问题,DBpedia使用了基于映射的抽取方式,将信息框中的模板以及属性信息映射到手工定义的本体类型与本体属性中,利用本体词汇相关信息提取出结构化的信息,保证了数据的高度准确性。
王兰等人[73]利用Wiki百科数据构建了一个关于渔业的知识库,同时提取Wiki页面的鱼类实体标题与对应的URLs归入MySQL数据库作为主要信息来源,并利用相关鱼类实体摘要作为补充介绍,再通过实体消歧的技术来剔除冗余文本,构建了一个渔业知识库。这种Wiki页面信息的提取一般采用爬虫的方式提取,通过编辑规则代码,收集百科类数据,能够做到高效提取,但是后续的数据整理也离不开人工,且由于百科类数据条目的构建大多不是来自于权威专家,因此在利用百科类数据进行抽取时其数据信息的准确性高度依赖百科本身,这就限制了百科数据的选择范围。
(2)Web页面数据抽取
与百科类数据相同的是,部分网页也具备了大量的半结构化的数据,通过人工法、包装器归纳法以及自动抽取法可以从指定Web页面中提取出所需知识信息[74]。人工方法需要编写出适合指定抽取页面的提取表达式,优势在于能够精准化控制抽取信息,但局限于一个Web页面,对新页面进行知识提取时还需要重新编辑表达式。归纳方法在多页面上的抽取能力有所提升,利用监督学习方法从人工标注的训练数据中学习知识提取的规则,并应用于相同布局的Web页面,省去了比重较大的手工代码编辑时间。但这种方法不适用于类似布局的Web页面,且需要大量人工标注数据,普适性较差。自动抽取方法无须人工的参与,将布局相似的Web页面聚类为一组,捕获组内的共有布局方式,可以生成针对该类Web页面的包装器,将需要抽取数据的Web页面分配至对应的包装器就可以对知识数据进行高效抽取。
海洋类数据百科多集中在海洋生物、岛屿等方面,分类较为详尽具体,但数据可能存在质量问题且层次深度不够。结合NOAA、国家海洋科学数据中心及中国海岛网等国际数据网站中的科研数据就能够做到信息的准确性与深度性。
1.2.3 知识融合
在经过知识的抽取后,虽然获取了大量数据,但这些数据缺少逻辑关联以及存在着数据冗余、错误等情况,再者又因数据来源的差异,不可避免地会产生多个知识图谱。知识融合主要侧重于剔除无用信息,并将不同数据源但拥有相同实体及关系的散乱信息整合在一起形成一个庞大的知识库[75]。以下将阐述知识融合的关键技术:实体链接与知识合并。
(1)实体链接
实体链接旨在识别出非结构化数据中的实体,并匹配到知识库中的相应实体,一般化流程[76]分为:
实体指称识别:利用前文所述的命名实体识别技术从结构化数据如文本中提取实体指称项,其中按照自动内容抽取(automatic content extraction,ACE)阐述的定义,实体指称项共有命名性指称、名词性指称以及代词性指称项三类。
备选实体生成:确定文本数据中提取的实体指称有可能指向的实体集合。
备选实体消歧:对存在重名的实体指称项应用歧义消除,并对多个实体对象均指代相同实体的情况进行指代消解。
知识库链接:将处理后的实体匹配到知识库中与之对照的实体。
①指称识别与备选实体生成
实体指称识别就是将所需的实体在文本中进行匹配识别,但一个实体指称或许不仅与知识库中一个实体相匹配,会存在一对多的情况,例如“海豚”也对应“海狶”“海猪仔”等。备选实体生成的任务就是确定文本中的实体指称可能对应的全部实体集合[77],可以从以下方面来进行:
实体名称扩展:许多实体名称为缩略词或关键信息词,因而可以从实体名称出现的相关文本中识别出可能存在。通常有模式匹配算法以及监督学习法,其中模式匹配是利用实体的中涉及的缩写作为其扩展的形式,而监督学习法则是利用相关机器学习或深度学习技术抽取更为复杂的缩写以及关键信息词表示。
网络实体候选:利用文本存在的实体指称作为关键匹配信息,通过网络引擎或百科搜索获取得到更多的候选实体信息。实体的候选或者说备选,实际上是文本实体指称的变体,可能拥有不同的实体名称,但候选实体的含义与文本实体一致。
实体查询表:实际上是根据百科类网站提供的信息进行信息抽取并生成一个涉及实体提及以及实体的引用表。
②备选实体消歧
当文本数据中的实体指称以及备选的实体被确定后,需要消除备选实体其歧义性,本质上解决的是实体的重名性和多义性,其做法是利用一些消歧的技术将每一个实体指称与确定的实体相对应[78]。本文探究了当下最为先进的几种方法,并技术上将其分为深度学习应用法、图结构应用法和预处理模型应用法。
目前针对实体消歧的数据多集中在长文本数据方面,因其有着相对完备的上下文数据,实体的识别和消歧工作相对容易进行,因此针对长文本,Phan等人[79]探究了采用深度学习解决实体消歧的可行性,融合LSTM以及注意力机制,提出了NeuPL模型。如图13所示,该网络采用双向的LSTM捕获实体提及的左文本信息及右文本信息,利用注意力机制突出实体描述信息和实体ID,再对实体提及的上下文进行反馈调节,在Gerbil基准平台7种不同类型的数据集上均取得了领先。
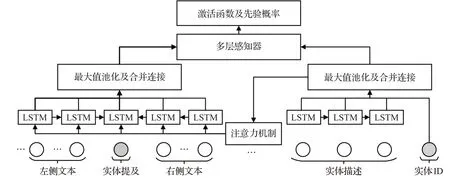
图13 结合Attention与LSTM的消歧网络结构Fig.13 Disambiguation network structure combining Attention and LSTM
但NeuPL模型只捕获了实体提及左右文本句的信息,忽视了全局信息。Hu等人[80]为弥补全局信息的确实,探究了基于端到端思想的消歧模型,通过构建文档的异构实体图来建模实体间的全局语义关系,运用图卷积网络(graph convolutional network,GCN)在实体提及和备选实体的嵌入过程中对同一文档中备选实体的全局语义进行了编码,再经过条件随机场来执行实体消歧处理,这种方式能够做到全局信息的利用,在2020年Gerbil基准测试中达到了最先进的性能。
短文本数据相较于长文本数据,缺乏完善的上下文信息,而且表述信息也不如长文本数据准确,实体的识别难度较大,因此Cheng等人[81]将Bert预处理模型应用于短文本的实体识别与消歧中,利用知识库对实体的信息进行挖掘来获得实体的向量嵌入,有效处理了短文本信息量缺乏的弊端,再通过Bert对实体及备选实体的实体名称识别,将获得的结果进行分类预测,确定概率最大的实体作为最终可信实体,其性能在2019年度全国知识图谱与语义计算大会上表现卓越。
③海洋领域实体链接难点及技术分析
海洋领域的同一实体可能存在多种指称,通过网络搜索虽然可以解决部分数据的实体指称识别问题,但一些专业化名词可能需要更具权威的数据来源。另外,海洋文本数据相较于通用文本数据多有不足,并且海洋部分数据库可能无法实时更新,例如海洋生物命名等,因此在数据量较少时,采用NeuPL模型反而要优于预处理模型,另外也可采用数据增强的方法扩充数据集,训练预处理模型再迁移到下游任务的方式,也会起到不俗的效果。
(2)知识合并
生成的知识库数据可能存在数据不完善的情况,可以通过知识合并的方法将第三方的知识库内容或定期更新的结构化数据补充进己方构建的知识库中,一方面可以解决知识库数据的单源主观性,另一方面可以弥补知识库内容缺乏动态更新性[82]。知识库的合并可以从外部知识库与关系数据库两个方面进行。
①合并外部数据库
外部数据库主要包括Wiki百科、DBpedia以及YAGO等含有海量数据的知识库,利用前文中涉及的数据抽取技术,可以得到多种有效数据,对这些数据的利用可以分为融合数据层和模型层两步[83]。在数据层面的融合涵盖实体指称、关系等,其关键是完成实体、关系间冗余情况的处理,模型层面主要是将融合后的数据层融入到现存的知识库。
数据层面的主要技术融合可以概括为以下步骤[84]:
步骤1实体匹配:多源数据对于实体名称及概念的表达可能存在差异性,利用实体匹配统一表达方式以及合并多个相同描述实体可以消除这种差异性,在去除冗余数据后能够使多源数据的表达内容统一,增强实体的可理解性。
步骤2知识评估:新增知识可能存在某些问题,为保证知识图谱内知识数据的合理性与准确性,必须对新添数据采用准确性验证与合理性评估,一般方法是赋予新加入知识可信度来进行筛选。
步骤3知识合并:经以上步骤融合好的数据层就融入到现有的知识库,完成外部数据库的合并。
②合并关系数据库
在知识库中,高质量的数据必不可少,这些数据往往来源于自建关系数据库,通过合并这些数据,可以使整体知识图谱的质量得到有效提升,在数据库定期更新的情况下,对这些数据库进行周期性合并就可以做到知识图谱的动态更新,进一步增加自建知识图谱的质量与新颖性。
结构化数据不可以直接融入知识图谱中,通过将关系数据库转换为资源描述框架(resource description framework,RDF)的三元组形式可以解决。当前能够将关系数据库转化为RDF的方法主要分为直接映射与R2RML两种[85],其中直接映射能够将关系数据库与数据输出为RDF图,采用的是数据库中列表名称与字段名称对应到RDF图中类术语与谓词术语,但是这种直接映射的方式无法将数据库中的相关数据映射到用户自定义的本体上。R2RML映射(RDB to RDF mapping language)其主要是将涵盖基本表、视图与R2RML视图的每一个逻辑表借由三元组映射表映射至RDF,具备了更高的灵活性,并且可以制定用户自己的映射规则。
1.2.4 知识图谱推理
通过数据的抽取以及知识的融合,可以得到现有数据的知识图谱,但此时的知识图谱尚不健全,其中的大量数据可以被二次开发,知识推理的任务就是从现有数据推理出图谱中所蕴含且未知的知识,可以分为传统方法、基于几何运算方法以及深度学习方法[86]。
(1)传统方法
早期因受限于低性能的设备及技术,多利用本体推理[87]、逻辑推理[88],这些推理技术需要严格的格式要求,且大多高度依赖于推理工具的表现,人工操作的复杂程度也较高,不利于大规模地推广使用。知识图谱NELL[89]采用手写规则推理算法对文本数据中的三元组数据进行抽取,能够快速建立起大规模的知识图谱,但这类图谱数据准确性存在问题,可能不利于推理的展开。为了解决推理准确性的问题,路径排序算法[90]应运而生,该方法基于图结构,采用了随机游走的思想,通过实体节点间存在的路径作为特征来进行推理预测,能够很好地解决知识图谱过多噪声对推理起到干扰的情况。但以上这些技术都要求对相关特征进行显示定义,有赖于人工制定推理步骤,耗时耗力。
(2)几何运算法
基于几何运算法能够平移或旋转知识图谱中的实体与关系,从而映射到低维的连续向量空间,使得算法自动捕捉和推理相关特征,省去了繁琐的人工操作。最具代表性的图嵌入模型TransE[91]将向量化后的(头实体、关系、尾实体)三元组之间的合理性评估视作为头实体向量A到尾实体向量B的翻译问题,如若A经过基于关系向量的变换能够得到B,就证明该三元组能够被知识图谱正确响应。
但TransE对于一对多、多对一以及多对多关系的情况无法很好地处理。TransH[92]将头实体向量与尾实体向量投影到同一平面上,再进行头实体向量A到尾实体向量B的翻译,弥补了TransE的不足,但TransH模糊了实体向量空间和关系向量空间,笼统地将分属不同概念的实体与关系置入同一空间,导致表达效果有所欠缺。TransR[93]拆分了实体向量空间与关系向量空间,通过对不同空间进行差异化的分析操作,进一步提升了表达能力,但是进一步增加了参数量。为减少TransR的参数量,TransD[94]将实体、关系相关向量做外积计算来动态得到关系投影矩阵,在减少参数量的同时最大限度地保留了其表示能力。
以上模型采取的是将头实体向量经过关系向量翻译得到尾实体向量的操作,但这种类型的模型无法细分多关系语义,同一关系可能在不同的头实体与尾实体的连接中有着截然不同的语义,TransG[95]采取贝叶斯非参数无限混合模型(Bayesian non-parametric infinite mixture model),将一个关系向量生成多个翻译内容,再依据三元组表达的特定语义获取其中的最优结果,能够很好地分析关系中存在的多语义,提升了三元组的分类精准度,在同时期的链接预测与三元组分类任务处理结果最优。
TransG模型通过在几何空间进行平移的任务,其成功取决于建模以及关系间模式的相关能力,在面对对称、逆以及合成关系模式时效果欠缺。RotatE[96]旋转模型利用向量空间中头实体到尾实体的旋转定义每个关系,能够做到对多种关系模型进行建模及推理,在WN18PR与FB15k-237数据集上的表现超越了过往的模型。
(3)深度学习法
卷积神经网络(convolutional neural networks,CNN)作为深度学习中最具代表性的结构之一,能够学习深层次的特征,ConvE[97]将CNN引入到知识图谱推理中,运用卷积网络捕捉深层次的实体间的关系缺失,弥补了以往链路预测的深度欠缺性,但这种方法仅仅考虑了局部不同维度的关系,而忽略了全局相同维度下的关系。ConvKB[98]将头实体、关系以及尾实体以列向量矩阵形式呈现,并送入卷积层,再经由卷积层的多个滤波器来产生多种特征,该方法考虑了实体与关系嵌入的全局关系,在WN18PR与FB15k-237两个基准数据集上做到了领先。
由于CNN处理模糊性语句时效果欠缺且不断地池化会引起重要信息的丢失,为保证重要信息的完整性,Vu等人[99]又将胶囊网络[100]应用于知识推理,提出CapsE模型,将每一个三元组都表示为矩阵,通过卷积学习其特征后构建各自的低级胶囊网络,再动态路由到高级胶囊网络,由于胶囊网络输出结果为向量,依托路由产生的向量长度就可以对三元组进行打分。其结果在相同基准数据集的表现超过了ConvKB。
(4)海洋领域知识图谱推理的难点
海洋领域涵盖范围广,群多子领域间也存在交叉情况,在利用所构建好的图谱知识进行扩充推理时难免出现大量干扰,又因本身数据集规模与来源的局限性,因此应用于海洋领域的知识推理可能会收效甚微。
2 海洋与图谱结合应用
2.1 实例
为应对海洋专业领域知识图谱稀缺的情况,阮彤等人[101]利用数据驱动的增量方式构建了海洋领域的中文知识图谱,将Word文本数据以及关系数据库分别利用Word封装器以及D2R映射工具完成知识子图的转化,并结合图书馆电子资源成功实现了语义检索,极大提升了海洋类信息的搜寻速度与精准度。
随着各国对海洋领域的持续重视,针对海运、船运产业链等重点海洋数据信息的分析利用就显得尤为重要,以往的船舶数据检测系统仅仅是简单地核查检索词与数据库内数据之间的关联程度,且每个数据相互之间并无联系,无法提供准确且便于理解的知识数据。为快速定位航线、港口、运营企业等重要船舶信息,李琦[102]利用知识图谱对航线、港口等数据进行了整合匹配,使得船舶信息查询系统更加智能化和便捷化。
任梦星[103]研究发现鲜有关于舰船知识的深入探究,导致相关人员面对数据分布稀缺的舰船相关知识往往无从下手,数据得不到有效的利用。为最大化利用舰船类型、行驶轨迹等重要数据信息,任梦星构建了一个关于舰船信息的垂直知识图谱,将数据辅以Neo4j图数据库来储存,并辅以知识问答系统作为知识图谱与查询人员的交互,大大提高了舰船工作人员的知识获取速度。
2.2 前景
海洋领域当前针对热点数据的研究主要集中在两方面:文献数据分析以及海洋垂直知识图谱构建。从文献分析角度来说,各个文献数据中蕴含着大批的未开发知识数据,但文献之间的联系较为松散,平常的文献调研分析无法做到高效且准确地找出海量文献间的关联,利用知识图谱的可视化工具可以快速提取出当前研究热点以及关注热点最为密切的作者和机构等信息,有利于海洋领域研究者进行热点的获取与追踪,能够大大提高其对实时热点研究的敏感度。另外除去目前可被直接观测到的海岛数据、海浪数据、海洋灾害数据等显性海洋数据外,海洋领域还有相当一部分有待开发的隐性数据,这些数据不仅内部间存在着难以发现的关联性,甚至数据间也会彼此影响,有些是直接联系,例如海底火山的爆发会对相关海域的海浪造成影响,还有些可能是多跳联系,由于数据的海量性及复杂性,依托人工去梳理这种隐性联系是不切实际的。通过构建海洋领域子领域的知识图谱,可以有效梳理隐性关系,为智能化精准分析提供了可能。
3 结论
本文首先总结了知识图谱可视化在海洋文献的应用,为后续海洋领域相关研究者进行热点分析与研究提供分析基础。其次探究了海洋垂直领域的流程与技术,从半结构化与非结构化数据抽取入手,根据传统方法的改进演变,分析介绍了目前的关键技术,并探究了海洋领域对于知识图谱的结合应用。希望可以为知识图谱相关技术在海洋领域的进一步应用提供理论支撑,同时为海洋领域相关工作者提供实际参考。
猜你喜欢
少先队活动(2020年12期)2021-01-14
中国外汇(2019年18期)2019-11-25
当代陕西(2019年5期)2019-03-21
琴童(2017年7期)2017-07-31
小学科学(2017年5期)2017-05-26
中成药(2017年3期)2017-05-17
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
领导科学论坛(2016年9期)2016-06-05
杂草学报(2012年1期)2012-11-06
