
可编程数据平面下基于DDPG的路由优化方法
2022-02-24 12:33周建国
计算机工程与应用 2022年3期
徐 博,周建国,吴 静,罗 威
1.武汉大学 电子信息学院,武汉 430072
2.中国舰船研究设计中心,武汉 430064
软件定义网络(software-defined network,SDN)由于其转控分离、软件可编程和开放接口等特性,正变得越来越受欢迎。在使用OpenFlow的SDN框架下,数据平面处理数据包时的匹配域是协议相关的,并具有固定动作集,软件可编程仅局限于控制平面。为了进一步提高网络的可编程性和开放程度,McKeown等人提出了可编程数据平面和可编程协议无关报文处理语言P4,以及相应的抽象转发模型RMT[1]。RMT模型主要由用于解析数据包包头的解析器、多级匹配动作表和多个缓存队列组成。P4语言能够对RMT模型中的解析器和匹配动作表进行编程,从而使网络管理者能够对数据平面的数据包处理逻辑和行为进行深度定制。同时,新的南向协议P4Runtime被提出来。
在具有可编程数据平面的SDN框架下,控制平面不仅拥有全网视图,还可以通过编程对网络行为进行灵活的配置和管理。处于数据平面的交换设备可以只根据P4程序完成数据包的解析、修改和转发,传统网络架构下交换设备需要完成的路由算法可以作为一个应用单独运行在具有更强通用算力的控制平面上,这使得部署更复杂的路由算法成为可能。
近年来,机器学习方法在图像识别、自然语言处理等领域得到了十分广泛的应用。机器学习方法不需要对问题进行复杂的假设和精确的数学建模,经过训练的机器学习模型能够将任意输入映射到确定的输出,得到局部最优解。因此利用机器学习方法进行路由优化,将使网络变得更加智能。目前,用于路由优化的机器学习算法主要是监督学习和强化学习,由于SDN网络下的路由优化问题可以看成是在给定网络环境状态下的决策问题,因此更适合使用强化学习方法求解[2-3]。
文献[4]提出在SDN网络下实现基于强化学习的智能路由协议,但没有使用SDN控制器进行路由决策,而是采用传统网络架构下的分布式自适应路由,并且通过修改模拟软件将智能算法添加到路由协议中,无法在实际物理网络中部署。文献[5]提出了一种基于深度强化学习的、由经验驱动的控制框架DRL-TE,用于解决通信网络中的流量工程问题。实验结果表明,相比于广泛使用的最短路径、负载均衡等方法,DRL-TE能够提供更好的吞吐量,并显著降低端到端的总时延,体现了使用强化学习解决网络问题的优势。文献[6]将深度强化学习算法DDPG与长短期记忆网络LSTM结合在一起,用于增强路由算法对流之间上下文相关性的感知能力,以适应空间-地面集成网络环境下不断变化的流和链路状态。
受固定功能交换机的限制,在不具备可编程数据平面的SDN环境下利用强化学习进行路由优化的研究[7-11]多采用流量矩阵等作为强化学习模型的状态输入,只考虑到了网络中的流量特征和链路状况,忽视了交换机对路由决策的影响。同时,通过粗粒度、不精确的测量方法获得状态参数不能真实准确地反映网络状态,容易导致强化学习出现决策偏差,使路由性能受限。同时,最终得到的路由路径多为单路径,没有有效利用网络中的多条端到端传输路径,导致网络吞吐量较低,资源利用率不够,容易造成网络拥塞,丢包率和传输时延增加。
本文针对SDN架构下进行路由优化存在的上述问题,利用具有可编程数据平面的SDN交换机,设计了一种基于强化学习的多路径路由机制,具体而言主要是:
(1)利用可编程数据平面和P4Runtime协议,设计了一种新的细粒度、高精度的网络测量方法,使控制器可以灵活获取当前网络中交换机的状态参数。
(2)引入深度强化学习算法DDPG,根据网络测量获得的网状状态参数和路由优化目标确定网络中每条链路用于路由选择的权值。
(3)在数据中心网络下,利用具有可编程数据平面的交换机设计了一种新的源路由协议,以实现多路径路由,进一步提高网络吞吐量,降低传输时延,同时减小数据平面和控制平面之间的南向通信开销。
1 路由优化方法
本文研究的路由优化问题表述如下:考虑一个具有K个端到端通信会话的网络,其中每个通信会话k由其五元组信息,即源IP地址、目的IP地址、传输层协议、源端口和目的端口标识,本文需要解决的问题是在网络中一组连接源节点和目的节点的可选路径中,选择路径权值最大的路径p ik作为路由路径,使会话k的吞吐量最大,并降低时延和丢包率,其中w k i,j=f(P k)表示由某种方法f得到的会话k的第i条可选路径上的第j个链路的权值。
为了解决上述问题,本文在具有可编程数据平面的数据中心网络下提出了一种基于强化学习和多路径传输的路由优化方法。如图1所示,该方法主要由四个部分组成,分别是网络状态感知、链路权值计算、多路径路由计算和流表规则下发,本章将对这四个部分做设计分析,并描述其主要实现过程。
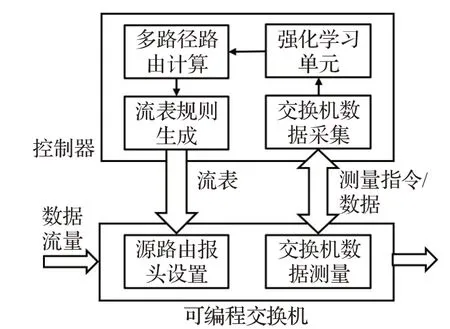
图1 总体结构图Fig.1 Overall structure diagram
1.1 网络状态感知
传统网络架构下,网络管理员一般通过Sflow、Netflow等工具在网络边缘的终端设备来间接获取滞后且不精确的网络测量数据。可编程数据平面的出现为自定义交换机数据包处理逻辑提供了更大的灵活度。Kim等人提出了INT测量方法[12],该方法是基于路径的,通过在数据包中设置指示位,可编程交换机解析到该指示位之后,将选择的交换机的内部元数据(例如队列深度、排队时延等)或自定义数据(例如丢包个数、传输的流量大小等)嵌入至数据包中,并在路径终端解析数据包,提取相关数据。该方法需要在网络的入口和出口处设置额外主机用于注入和提取INT信息,同时基于路径的方式使得INT难以快速获取全网数据,且将遥测指令和数据封装到正常数据包中会产生较高的探测开销和部署运维复杂性[13]。为了克服INT方法存在的问题,同时保留其灵活、细粒度特性,本文设计了一种基于设备的轮询式测量方法,用于获取网络状态参数。
如图2所示,SDN控制器使用P4Runtime南向协议向指定的可编程交换机发送自定义的PacketOut消息,该消息由携带指令的元数据包头和空负载组成。为了区分不同功能的PacketOut消息,在元数据报头中设置一个用于指示消息类型的字段req_t,其值为1时表示该消息为控制器向数据平面发送的测量请求。为了根据需要获取指定的测量数据,将需要的测量项以Bitmap的形式编码,作为元数据报头中的第二个字段inst。Bitmap中的每一位与可编程交换机提供的测量项相关联,值为1时表示控制器需要该项测量数据。根据测量项与路由选择的相关性,本文选择的测量项如表1所示。
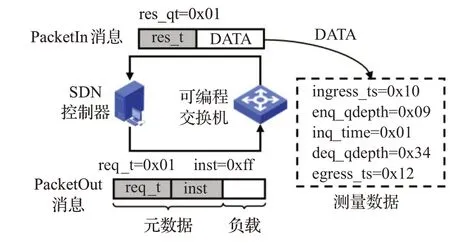
图2 网络参数获取Fig.2 Network parameter acquisition

表1 测量项编码Table 1 Measurement item coding
PacketOut消息通过P4Runtime发送至运行在可编程交换机CPU上的P4Runtime服务器端,服务器端再通过CPU_PORT将元数据和负载以数据包的形式发送至可编程交换芯片。可编程交换芯片收到来自控制器的数据包后,根据解析得到信息类型req_t和测量项inst,将相应的测量数据封装至数据包中并发送至CPU_PORT。服务器端将该数据包通过P4Runtime中的PacketIn信息发送至控制器。与PacketOut消息一致,PacketIn消息也是由元数据和负载组成,但由于测量项是不确定的,因此将测量数据作为PacketIn消息的负载,元数据仅包含指示该PacketIn消息类型的字段res_t。
为了获取交换机端口网络流的发送速率,在P4程序中为交换机的每一个端口定义一个计数器,在处理数据包时计算其五元组的哈希值,值相等的数据包属于同一个网络流。以哈希值作为网络流转发端口的计数器的索引,记录端口转发的该网络流的总字节数。控制器通过P4Runtime定时地读取计数器值,即可计算出每个网络流和每个端口的数据发送速率,再根据端口带宽计算得到链路利用率。在可编程数据平面上实现上述方法的算法如算法1所示。

上述方法不需要引入新的测量工具,测量任务直接由交换机芯片以线速转发的方式完成,能够在降低资源消耗的同时实现包级细粒度测量。并且控制器可以根据应用需求选择需要测量的交换机、测量时间和测量项,具有较高的灵活性。
1.2 链路权值计算
本文的链路权值是对网络中交换机和对应链路组成的网络基本转发单元的综合剩余负载能力的描述,区别于仅以带宽表征负载能力,此处综合考虑网络测量得到的多个指标:交换机处理时延、交换机队列深度、链路利用率等。链路权值计算是根据上述多个测量指标组成的网络状态描述,得到确定输出值的回归问题,可以使用机器学习方法。由于SDN网络下的路由优化问题可以看成是在给定网络环境状态下的决策问题,因此更适合使用机器学习方法中的强化学习方法求解[2-3]。
强化学习主要用于解决智能体通过与动态环境不断交互来学习其行为的问题。具体而言如图3所示,智能体在每个时间点t获得环境的当前状态s t,并依据某一策略函数π执行行动a,使环境转移到另一个状态s t+1,同时收到环境反馈的奖励r t。强化学习的目标是寻找到一个最优策略π*:s→a,能最大化长期折扣奖励(回报):

图3 强化学习模型Fig.3 Reinforcement learning model
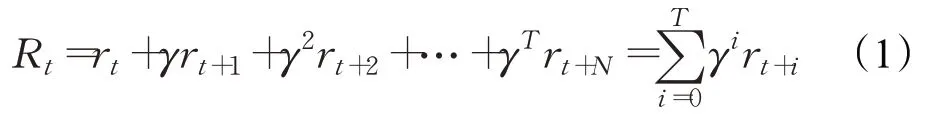
其中,γ∈[0,1]为奖励衰减系数,表示对长期奖励的关注程度。为了评估不同策略的优劣程度,强化学习定义了值函数Q来表示给定策略下期望获得的回报,例如动作值函数:

表示智能体在状态s下依据策略π采取行动a后获得的期望回报。
在文本研究的SDN网络路由优化问题中,环境为部署了可编程交换机的SDN网络,智能体为控制器,状态、动作和奖励的具体定义如下:
状态:利用1.1节提出的网络测量方法,控制器在某一时刻t进行一次网络测量后可以获得当前时刻交换机的内部状态参数和链路利用率,这些测量数据是对当前网络状态的描述,可用作DDPG模型的状态输入,表示为s t=[dt,qd t,qt,ut],其中dt表示t时刻各交换机的处理时延,由进出交换机时间戳相减可得,qd t表示t时刻各交换机的平均队列深度,为进出交换机队列时队列深度的平均值,q t表示t时刻各交换机的排队时延,u t表示t时刻可选路径上各链路的链路利用率。
动作:使用强化学习解决路由优化问题时,最直接的动作是输出某个流在全网的路由表项,再由控制器下发至交换机中,但随着网络规模的增大,路由表项的数量将会出现指数爆炸问题[14]。一个可行的动作是改变网络链路的权值,控制器再通过其他方法确定路由路径,本文采用该方法,即将DDPG模型的输出表示为a t=[w1,t,w2,t,…,w|P k|,t],其中w i,t表示t时刻第i条可选路径上各链路权值构成的向量。该方法的另一个好处是控制器可以根据链路权值灵活确定路由方式,例如使用多路径路由。
奖励:强化学习中的奖励是对上一次动作,此处为设置的链路权重的优劣程度的评价,隐式地定了学习的目标。当由链路权值得到路由路径的策略确定时,链路权值的优劣与网络性能的优劣正相关。本文路由优化的目标是提高网络性能,即提高网络中所有数据流的平均吞吐量Tt并降低端到端平均时延Dt和平均丢包率L t,因此可以将DDPG模型的奖励定义为:

其中,α,β,θ∈[0,1]是各个优化目标的权重,由路由策略决定,本文中令其全等于1。
经典的强化学习方法,例如Q-Learning等使用的状态/动作空间是离散且小规模的,通常将值函数存储为表格的形式。但在网络路由优化问题中,状态和动作空间的维数很大,存储这些信息需要巨大的存储空间,且查表时间也会显著增加。在某些情况下,状态和动作空间甚至是连续的,无法用表格表示。深度强化学习使用深层神经网络做值函数近似,能够解决上述问题[15]。
深度强化学习将深度学习的感知能力与强化学习的决策能力结合起来。但是基于价值的深度强化学习机制如深度Q网络(deep Q network,DQN),不能解决连续动作的建模和控制,不适合动态实时的网络系统。基于策略的方法如确定性策略梯度(deterministic policy gradient,DPG),可以实现连续时间的控制与优化,但仅对线性函数生成策略函数,且存过拟合问题[9]。为了解决这些问题,DeepMind将DQN方法和DPG方法结合在一个Actor-Critic框架中,提出了DDPG[16]方法,实现了高效稳定的连续动作控制,适合于求解网络路由优化问题。
图4为DDPG框架,图中μ和Q分别表示神经网络生成的确定性策略函数和Q函数。其中Actor模块采用DPG方法,Critic模块采用DQN方法。两个模块都是由用于训练和学习的在线网络和用于防止训练数据相关性的目标网络组成,两个网络的初始参数和结构完全相同,在线网络定期地用自身参数更新目标网络的参数。DDPG在训练期间会将每次与环境交互的信息存储在经验池中,并通过在经验池中随机采样得到神经网络的学习样本。

图4 DDPG框架Fig.4 DDPG framework
DDPG中四个网络的功能描述如下[16]:
Actor在线网络:根据当前状态s t和策略函数μ选择动作at=μ(s t|θμ)与环境交互得到s t+1和rt,并依据损失梯度∇θμJ更新策略网络参数θμ。
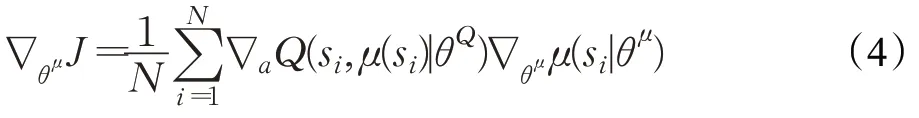
Actor目标网络:根据从经验池中采样得到的每个样本的样本状态s i+1选择动作
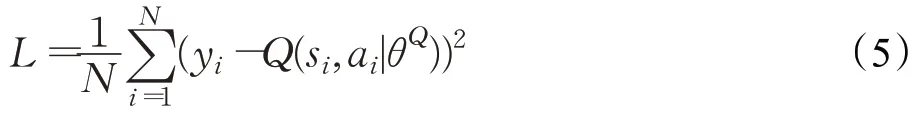
Critic目标网络:计算目标Q值

1.3 多路径路由计算
由于SDN网络架构可以实现灵活的集中控制,因此被广泛应用于数据中心网络。数据中心网络的流量主要是由分布式存储和计算产生的内部流量,因此多采用Fat-Tree、Leaf-Spine等高连通度网络拓扑[17]。在这类网络拓扑中,任意两台服务器之间存在多条物理路径,而传统单路径路由机制无法有效利用多条端到端的传输路径,导致网络吞吐量较低,资源利用率不够,容易造成网络拥塞,丢包率和传输时延增加。一个可行的办法是使用等价多路径路由(equal-cost multi-path,ECMP),通过计算数据流的五元组的哈希值,再根据哈希值在多个与目的节点具有相同最小跳数的下一跳中随机选择。ECMP方法没有考虑链路和流量的差异性,不能充分利用网络资源,容易造成网络负载失衡[18]。得益于可编程数据平面的灵活性和SDN的集中控制特性,本文针对于数据中心的Leaf-Spine网络结构设计了一种新的加权多路径路由,用于提高网络资源利用率。
在Leaf-Spine网络结构下,当与主机相连的Leaf交换机收到一个数据包后,计算其五元组的哈希值,具有相同哈希值的数据包属于同一个网络流,本文对流进行路由调度。当一条新流进入网络时,本文按照如下步骤确定多路径路由:
步骤1 Leaf交换机将该流的第一个数据包发送至控制器。如果流的目的主机和源主机在同一个Leaf节点下,则直接转发,否则执行步骤2。
步骤2 Leaf-Spine结构的网络中的任意两个不同Spine下的Leaf节点之间的路径是冗余且相对固定的,控制器在全局网络视图中根据流的目的节点可以直接确定多条不重叠可选路径,再通过1.1节描述的测量方法,向可选路径上的交换机发送测量请求。
步骤3控制器收集交换机的状态参数,并读取相应计数器值,计算链路利用率。
步骤4将步骤3中获得的数据作为DDPG模型的输入,得到可选路径上各段链路的链路权值。
步骤5定义可选路径上链路权值的最小值为路径权值,选择路径权值最大的路径为路由路径。
1.4 流表规则下发
受固定功能交换机的限制,在使用OpenFlow的SDN网络中,控制器得到的路由路径需要转换成单个交换机的流表,再通过南向接口下发,这增加了控制器的计算开销、南向通信开销和交换机的查表时延。因此本文借助于可编程数据平面可自定义数据包处理逻辑的优势,借鉴分段路由[19]的思想,设计了一种基于源路由的路由协议。
区别于使用路径标签的分段路由协议,本文提出的源路由协议直接将路由路径上各交换机的转发端口保存在数据包的包头中。如图5所示,该路由协议的包头由多个交换机的转发端口port和用于指示该交换机是否为最后一跳交换机的bos组成。控制器将流的转发规则,即路由路径上每个交换机的转发端口下发至流的源Leaf交换机,该交换机将后续交换机的转发端口按照协议格式嵌入至数据包中,再转发至下一跳。后续交换机解析嵌入在数据包中的第一个转发端口并将其弹出,再据此将数据包转发至下一跳,直至目的主机。该方式将多次流表规则的计算和下发缩减为单次,能够减少控制平面的计算开销和南向通信开销,同时,由于后续交换机不需要再进行查表操作,能减少交换机的处理时延。
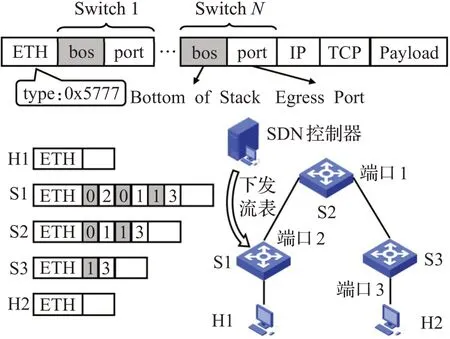
图5 源路由示意图Fig.5 Source routing diagram
2 实验与评估
2.1 实验环境设置
本文利用Mininet网络仿真平台搭建了一个如图6所示的小型Leaf-Spine网络,其中任意2个Leaf交换机之间具有3条相连链路。网络中的软件交换机使用的是支持数据平面可编程的BMv2,南向协议使用的是P4Runtime,控制器使用Python语言编写。
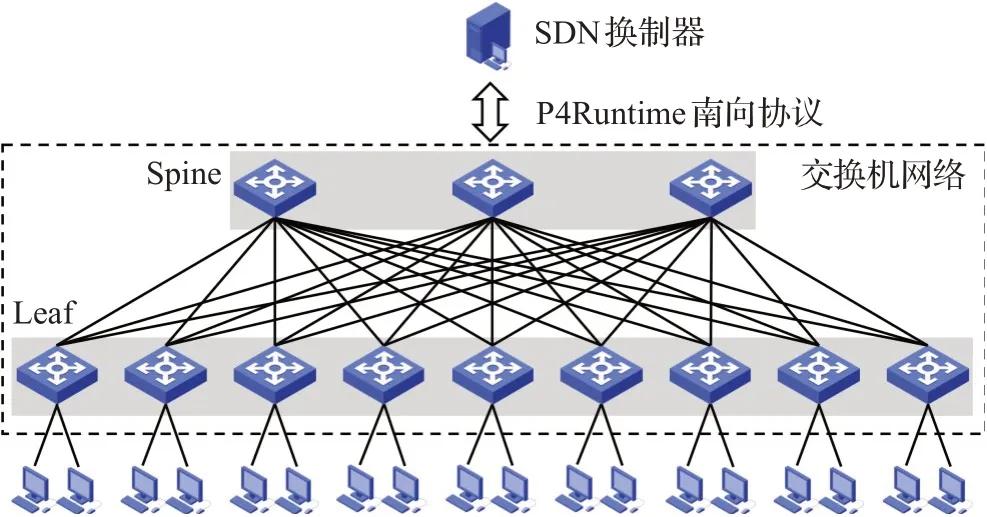
图6 Leaf-Spine网络拓扑Fig.6 Leaf-Spine network topology
为了模拟数据中心环境,网络中的链路带宽设置为50 Mb/s,延时设置为1 ms。通过随机选取K对源和目的主机,使用Iperf工具各产生一个网络会话,其中每个会话的带宽需求,即每个数据流的数据包发送速率R i(i=1,2,…,K)满足在长度为10 Mb/s的窗口内取值的泊松分布,均值λ为窗口中心:
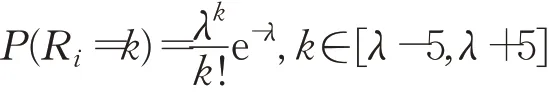
设置初始窗口为[0,10]Mb/s,并以5 Mb/s的步长滑动窗口来改变网络负载。使用Iperf和ping工具统计每个窗口内每个流的吞吐量、时延和丢包率,并取平均值,用以表示当前带宽需求下路由方法的性能。
本文在Ubuntu 16.04系统上使用机器学习平台TensorFlow和基于Python的深度学习库Keras,按照图4所示的DDPG框架,搭建了神经网络模型[20],并在上述实验环境中完成了模型训练。
2.2 性能比较
2.2.1 路由性能比较
为了验证本文提出的路由方法的性能优势,本小节选取网络平均吞吐量、时延和链路利用率作为性能评价指标,设置网络会话数K=6,与ECMP和RRMP(round robin multi-path,轮询多路径路由[21],该算法从所有端到端可选路径中循环选择不同的传输路径)两种多路径路由算法做对比分析。在ECMP和RRMP算法实验中,控制器根据全网视图计算路由路径,并转换成单个交换机的流表,下发至交换机。实验结果如图7所示。

图7 不同带宽需求下的路由性能比较Fig.7 Routing performance comparison under different bandwidth requireme
实验结果表明,在带宽需求比较小的情况下,三种路由算法的性能差异非常小,吞吐量、链路利用率与带宽需求近似成线性关系,因为此时的网络资源能够满足全部需求,没有产生拥塞。但本文提出的方法的时延要大于另外两种方法,这是由于在计算路由时使用强化学习模型计算链路权值需要更多的时间。随着带宽需求增加,吞吐量和链路利用率无法随带宽需求线性增加,组建趋于一个恒定值,此时网络资源无法满足全部需求,产生拥塞,并出现丢包现象。但本文提出的方法的三项性能指标都要优于另外两种,这是因为ECMP和RRMP无法感知链路状态和交换机负载情况的变化,不能根据网络状态改变流量在多条可选路径上的分配比例,容易造成数据包大量聚集在某些交换节点或多条大象流经过同一链路,使整个网络的负载不均衡,链路平均利用率低,导致吞吐量较早达到瓶颈。同时,数据包在交换机缓存队列中排队时间较长,使传输时延增加。而本文提出的方法可以在采集网络状态信息,计算网络链路在不同网络状况下的权值,能够在高带宽需求时为数据流选择链路资源较为充裕的路径,从而实现负载均衡,提高网络平均吞吐量和资源利用率,减小传输时延。因此本文提出的方法更适合在带宽需求较大的网络环境中使用,例如数据中心网络。
2.2.2 源路由性能比较
为了验证本文提出的源路由方法在降低交换机处理时延和南向通信开销的作用,本小节设置了一组对比实验,对比组中的控制器得到路由路径后转换成单个交换机的流表,逐一下发到路径上的每个交换机中,实验组采用本文提出的源路由方法。
(1)平均时延比较
由于数据流的时延变化主要是由交换机的处理时延变化造成,因此可以使用数据流平均时延反映交换机的处理时延。设置网络会话数K=6,实验结果如图8所示。
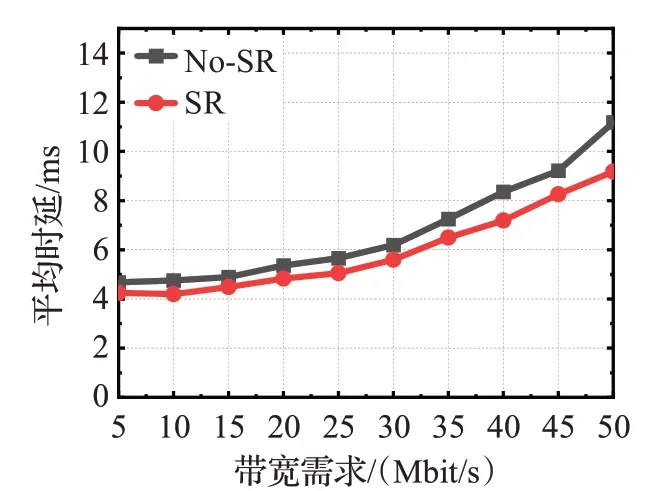
图8 平均时延比较Fig.8 Mean delay comparison
(2)南向通信开销比较
南向通信主要发生在新流进入网络时的网络测量和流表下发过程,与带宽需求无关,与网络中数据流数量相关,因此在某一带宽需求(10 Mb/s)下通过增加网络会话数K,统计南向协议P4Runtime所使用的端口上的网络流量,得到南向通信开销比较,实验结果如图9所示。

图9 南向通信开销比较Fig.9 Southbound communication overhead comparison
实验结果表明,相比于向单个交换机下发流表,本文提出的源路由方法能够在一定程度上减小数据流的传输时延,大幅减小南向通信开销。这是由于在本文提出的方法中,每一条新数据流进入网络时,仅需要入口交换机与控制器发生一次通信,路径上其他交换机直接根据数据包中的转发信息进行转发,而不需要与控制器进行通信,这减小了南向通信开销。同时其他交换机不需要执行查表操作,减小了处理时延,尤其是交换机中存在大量表项或有大量数据包需要转发时,这种优势将更加明显。
3 结束语
本文在具有可编程数据平面的SDN网络架构下,针对于具有Leaf-Spine拓扑结构的数据中心网络,提出了一种基于强化学习和多路径传输的路由优化方法。控制器通过南向协议直接获取网络中数据平面可编程交换机的状态参数,并使用DDPG强化学习算法根据网络状态参数得到不同网络状况下表示链路剩余负载能力的权值。通过选取具有最大最小链路权值的路径,使网络流量在网络中分布更加均衡,以提高网络资源利用率。同时,充分利用可编程数据平面带来的灵活性,设计了一种新的基于源路由的路由协议。对比实验结果表明,本文设计的路由优化方法能够在较高带宽需求下提高网络平均吞吐量和链路平均利用率,减小传输时延和南向通信开销,充分展示了可编程数据平面在新路由协议应用方面存在的巨大优势,以及将机器学习方法引入网络领域的巨大潜力。下一步将完善测量方法,实现网络快照,以获取同一时刻的网络状态参数。同时改进路由方法,使之适用于不同的网络拓扑,并更具鲁棒性和可拓展性。
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21
计算机与数字工程(2022年3期)2022-04-07
民用飞机设计与研究(2020年4期)2021-01-21
数码世界(2020年11期)2020-11-23
网络安全和信息化(2019年7期)2019-07-10
电子制作(2019年24期)2019-02-23
物联网技术(2018年8期)2018-12-06
计算机与数字工程(2018年5期)2018-05-29
计算机测量与控制(2018年3期)2018-03-27
自动化学报(2017年7期)2017-04-18
