
面向视觉问答的多模块协同注意模型
2022-02-24 05:06:58邹品荣张文娟张万玉王晨阳
计算机工程 2022年2期
邹品荣,肖 锋,张文娟,张万玉,王晨阳
(1.西安工业大学 兵器科学与技术学院,西安 710021;2.西安工业大学 计算机科学与工程学院,西安 710021;3.西安工业大学 基础学院,西安 710021)
0 概述
深度学习的不断发展使得神经网络具有接收与处理多模态信息的能力,如图像描述[1]、图像文本匹配[2]、视觉问答[3-5]等模态间交互转换的视觉任务都取得了较大的进展。与传统多模态表征任务相比,视觉问答(Visual Question Answering,VQA)更具挑战性,其目标是训练一个能够实现对多模态输入和视觉语言高层语义全面理解的模型,并将图像中的视觉特征和问题中的语义特征联系起来,使算法模型能够针对自然语言问题生成符合人类思维的答案。
早期的研究主要介绍图像和问题的联合表示学习,使用卷积神经网络(Convolutional Neural Network,CNN)作为视觉特征提取器[6-8],问题特征则使用循环神经网络(Recurrent Neural Network,RNN)编码[9-10]。从视觉特征编码器中获得一组稀疏图像区域后,应用多模态融合嵌入来学习每个区域与文本特征之间的联合表示,然后采用全局特征输入答案分类器中预测问题答案。
上述框架是有效且合理的,但在图像和自然语言之间仍然存在很大的语义鸿沟。例如,给定一个男孩拿着三明治的图像,问:图像中男孩左手中拿的是什么?模型可能会丢失关键视觉位置信息与核心问题语义信息,无法正确定位局部区域中的物体,因此,采用联合嵌入方法训练的VQA 模型存在缺陷,且有局限性。为更好地检测到图像中与自然问题相关的部分并提升跨模态间的聚合能力,受人类视觉注意力和深度学习相关技术的启发,在视觉问答模型中加入注意力机制[11]。
然而,多数方法所采用的注意力机制是根据自然语言问题,聚焦图像中与文本特征密切相关的区域[5,12-13]。这类方法经过不断迭代训练,通过处理图像区域中各个空间信息权重来选择性地关注CNN中隐层特征,但却忽略了模态间的动作语义和位置依赖关系。如给定两只长颈鹿并列站的图片,模型能识别长颈鹿的耳朵和身上的斑块,但不能识别斑块来自哪个长颈鹿。很难回答“最左边的长颈鹿是小长颈鹿吗?”或“长颈鹿都在吃树叶吗?”等问题。一种好的VQA 网络不仅要能识别对象“长颈鹿”和环境中的“树叶”,同时需识别图像和问题中关于动作“吃”和位置“最左边”的语义。
为捕获图像中对象间动作关系和局部位置信息,模型不仅要在单纯的目标检测上融入语言信息,还应通过解释图像中对象之间的交互作用来加强对高层语义信息的理解,以缩小多模态之间的语义鸿沟;同时,网络需将注意力集中在相关视觉区域并丢弃对自然语言问题无用的信息,通过较好地学习整个场景以解决多模态表征问题。为此,一种解决方案是学习对象之间的语义依赖关系来捕捉视觉场景中的动态交互,根据自然文本序列特征进行关系推理来生成高质量答案;另一种方案是级联图像和问题特征的注意力模块,使问题适应对象间特征来丰富图像表示,以提高VQA 性能。
基于上述两种方案,本文构建一个多模块协同注意网络(Muti-Module Co-Attention Network,MMCAN),分别使用Faster R-CNN[14]和门控循环单元(Gated Recurrent Unit,GRU)生成多模态特征,将每个区域的卷积特征输入图注意力网络(Graph Attention Network,GAT)[15],自适应感知图像中对象间的动态语义关系,进而提供整体场景解释来回答语义复杂的问题。此外,受机器翻译中Transformer 模型[16]的启发,设计自注意力(Self-Attention,SA)和引导注意力(Guided-Attention,GA)这2 个注意力单元,通过注意力单元的模块化组合提取特征,关注物体层级的视觉语义信息。最后将关系感知视觉特征和问题嵌入输入到多模态融合模块中,得到问题和图像特征的联合表示,用于生成最终答案。
1 相关工作
1.1 注意力机制
注意力机制已成功地应用于单模态任务(如视觉[17]、语言[18]和语音[19])以及简单多模态任务。文献[11]从VQA 的输入问题中学习图像区域的视觉注意力,使用注意力结构将问题嵌入视觉空间,并构造一个卷积核来搜索图像中所注意到的区域,有效促进了模型的表征能力;随后很多研究[5,7-8,12-13,20]介绍了利用视觉注意力来提取特征,并通过注意力机制减少图像和文本信息中冗余特征的干扰;此外,文献[21-22]则利用不同的多模态双线性池化方法,将图像空间中的网格视觉特征与问题中的文本特征相结合预测答案。研究结果表明,学习视觉和文本模态的注意力有助于增强图像和问题的细粒度表示,从而有效提升模型精确度。但是,这些粗糙的注意力模型不能推断出图像中区域和问题词之间的相关性,并且难以识别图像中对象间的语义关系,导致在自动视觉问答中性能较差。
VQA 过程不但需要理解图像的视觉内容,而且对自然语言问题的协同语义还需要予以更多关注,因此,通过学习双模态间的协同注意力能有效提高VQA 结果。文献[23]建立一个协同注意力学习框架,交替学习图像注意力和问题注意力。文献[24]将协同注意力方法简化为两个步骤,首先将问题输入到自注意力机制学习问题词间的依赖关系,然后在问题引导注意力模块中搜寻最相关的视觉区域。同时,文献[25]提出双线性注意网络,基于先前注意到的记忆特征来细化注意力。
虽然上述模型能学习到不同注意力分布,但忽略了每个问题与对应图像区域之间的语义逻辑关系,成为理解多模式特征表示的瓶颈。为解决该问题,本文提出视觉关系嵌入的协同注意模型,使得每个问题词和对应图像区域之间能够动态交互。与传统注意力模型相比,该关系推理模型具有更好的VQA 性能。
1.2 视觉关系推理
VQA 中注意力机制能聚焦文本关键词和视觉对象,但还需对整体内容有充分理解,对复杂问题则需基本常识和特定关系实例等先验知识的辅助推理。因此,一些研究[26-27]利用图像中的高级语义信息,如属性、字幕、视觉关系等加强学习,使模型更加强大并易于解释[28-29]。然而,文献[30]构建VQA 关系数据集,探索VQA 特定的事实关系,为模型提供额外的语义信息。同时,文献[10]引入MuRel 单元的双线性融合方法,用于图像和问题两两关系的建模,研究如何对于复杂的问题进行推理,这些关系在多模态任务中被证明是有效的。
此外,一些文献介绍了结合问题的图关系表示[31-38]。文献[31]在VQA 中使用图卷积神经网络(Graph Convolutional Network,GCN)[39],将问题的依赖性分析和抽象场景的场景图表示相结合,探索结构关系在表示学习中的重要作用,但其只在抽象场景数据集上有效。文献[32]直接引入一个空间图学习模块,该模块以问题表征为条件,使用成对注意力和空间图卷积来计算视觉表示,但其忽略了图像对象之间关系的多样性。文献[34]提出一个关系感知图注意网络模型,该方法将图像编码成一个代表视觉对象之间的关系图,在视觉基因组数据集上进行训练。文献[35]构建一种基于对象差异的图学习器,通过计算对象间的差异来学习语义关系。文献[36]使用预先提取的视觉关系作为先验知识来建模对象及其交互,但其推理过程高度依赖于先验关系。受图形中建模实体及其关系性质的启发,文献[40]使用基于知识图的GCN 来回答事实问题,该模型主要关注图像和知识图中提取的实体关系图,严重依赖于外部知识图。文献[41]则通过GAT 建模图像物体间的关系来推理答案,但其不能有效关注与问题相关的视觉对象。
与上述方法相比,本文VQA 体系结构利用图像的丰富信息,无需任何先验知识或预先训练,直接建模对象及其关系,其所学到的视觉关系特征是对先前研究的补充。同时,在图表示学习中给相同领域的节点分配不同的重要性,通过问题自适应性对象间关系来过滤掉与问题无关的关系,使用多层消息传递来执行关系推理,具有问题自适应性,能动态地捕获与问题最相关的视觉对象关系。
本文工作主要有2 个贡献:1)基于Transformer协同注意单元来提升模态间的聚合能力,使模型集中注意在问题与图像特征交融部分,抑制无关信息;2)基于GAT 学习视觉对象之间的语义关系,语义关系具有问题自适应性,可以动态地关注每个问题的特定关系。
2 多模块协同注意模型
本文多模块协同注意模型如图1 所示。其中,SA 为自注意单元,GA 对应引导注意单元,att 为建模两两对象间关系的图注意力,AttEn 表示注意力增强模块,BCE Loss 为二元交叉熵损失函数。模型主要包括图像编码、问题编码、图关系编码和协同注意学习和注意力增强。在图像编码中,使用自底向上注意力机制提取图像中64 维的几何特征和2 048 维视觉特征[5];在问题编码中,使用GRU 进行问题词特征提取,所提取的特征为1 024 维。首先将双模态特征输入关系编码模块中建模对象间语义关系,关系编码后的视觉语义特征与初始视觉特征以残差方式融合,送入协同注意模块,接着通过自注意单元SA 与引导注意力单元GA 联合学习两者的丰富信息,最后经注意力后以简单的哈达玛乘积方式融合两者特征,送入分类器预测答案。
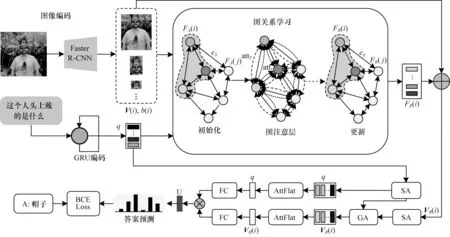
图1 多模块协同注意力网络Fig.1 Multi-module collaborative attention network
2.1 问题与图像表示
模型输入一张图像v∈I和一个与图像相关的问题q∈Q,使用在视觉基因组数据集[42]上预训练的Faster R-CNN 检测图像中目标特征(主骨架网络为ResNet-101),Faster R-CNN 训练共1 600 个选定的对象类和400 个属性类。对检测到的目标设置一个置信阈值,得到动态目标对象特征N∈[10,100],具体地,目标特征来自于RoI 池化后的特征图[8]。给定图像与文本问题,VQA 的目的是预测一个与真实答案a*最匹配的答案a^ ∈A,A表示候选答案的集合,在多数研究中,a^ 被定义为分类任务中常见的概率分数,如下:

其中:pθ表示训练好模型。输入模型的图像对应于一系列向量集合和每个回归框的特征向量b(i)=[x,y,w,h]。集合中V(i)∈表示图像中每个目标检测框的视觉特征,b(i)中(x,y)表示回归框的中心坐标,(w,h)对应回归框的高度和宽度。
对于输入问题,首先将每个问题词进行标记并使用600 维的词嵌入编码序列特征(包括300 维GloVe 词嵌入[43]),问题中每一个词进一步转化为向量。在每一个时间步将单词序列送入双向GRU 中编码得到问题特征q∈,GRU 隐藏层的尺寸设置为1 024,少于14 个单词的问题在末尾用零向量填充。
2.2 图关系编码器
如图2 所示的注意力机制是图关系模块的核心,其输入由维度为dv的“值”与维度为dk的“查询”和“键”组成。“查询”代表某种条件或者先验信息,注意力权值表示在给定“查询”信息的条件下,通过注意力机制从source 中提取信息,source 包含多种信息,每种信息通过“键-值”对的形式体现。在“查询”和所有“键”之间执行点乘操作获得两者相似度,然后经softmax 函数得到对应“值”的注意力权重。
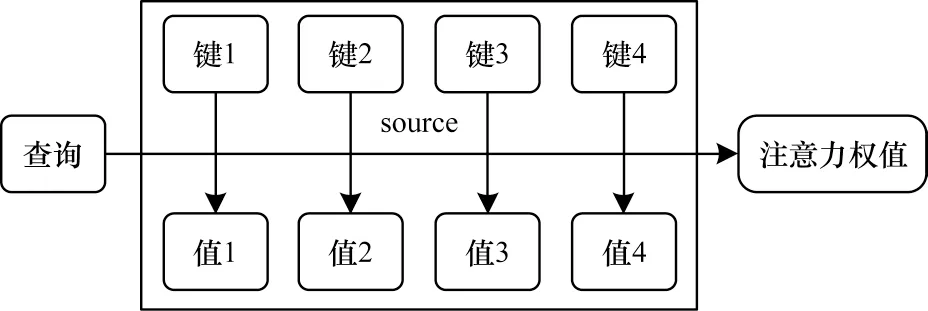
图2 自注意力机制Fig.2 Self-attention mechanism
给定一个“查询”Q、所有“键”组成的矩阵K和“值”组成的矩阵V,A表示注意力函数,带注意力权重的输出如下:

在关系编码之前,首先构建一个全连通无向图编码器G=(v,e),e是包含N×(N-1)条边的集合,每一条边表示两个目标之间的语义关系。然后通过类似于式(2)的图注意力机制[15]来对邻居节点做聚合操作,实现对不同邻居权重的自适应分配,所有边的注意力权重是在没有先验知识的情况下进行学习。
图关系编码器能动态捕获图像中目标对象间的动态关系,对于VQA 任务,不同问题类型可能有不同类型关系。因此,本文将问题嵌入特征q和视觉特征vi拼接起来作为图关系编码器的输入,表示如下:

其中:||表示拼接操作。在每个顶点上执行自注意力生成隐藏特征来描述目标对象和其相邻对象之间的语义关系,且每个关系图都要经过注意力机制,得到N个结合问题词和图像目标特征的关系特征是邻域中自适应问题视觉表征的权重加和,计算如下:
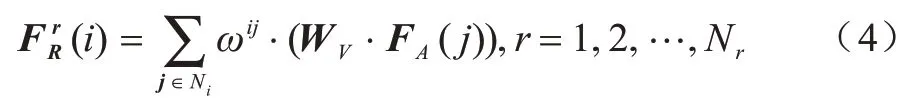
式(4)通过不同注意力系数ωij定义不同图关系类型,同时定义对象i与其他对象间关系的重要性,表示映射矩阵,Ni是目标对象i的邻居数。ωij计算如下:

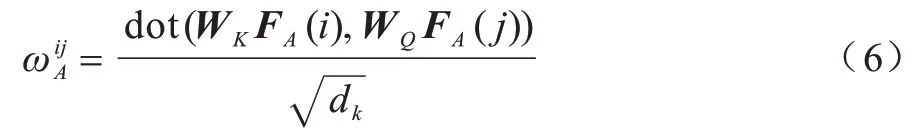
其中:dot 表示向量点积;矩阵WK和WQ与式(2)中的K和Q相似,它们把原始特征映射到子空间中采样两者间的匹配程度,特征映射后的维度为dk。

为满足平移和尺度变换不变性,使用φG计算4 维相对几何特征[16],该方法计算不同波长的余弦和正弦函数,从而将两个对象的几何特征嵌入到同一个空间学习目标特征的位置依赖关系。几何嵌入后特征维度为dg,计算如下:
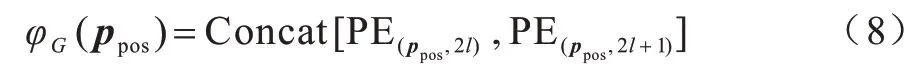
其中:Concat[]拼接操作用来聚合正弦波与余弦波;PE表示不同频率的信号,该信号的几何波长变化范围为[2π,10 000 × 2π],以产生独特的位置信息,其计算如下:

其中:dmodel=dk;ppos是位置向 量;l是几何向量的 维度。在计算几何特征前,使用log 函数对输入几何回归框的4 维位置特征作预处理如下:
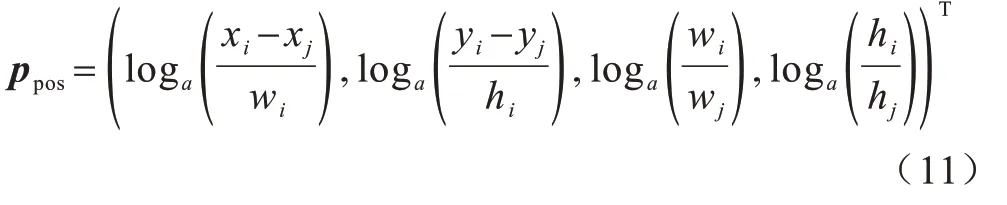
将嵌入特征通过WG∈ℝdh转化为标量权重,检测具有特定几何关系的对象之间的关系,计算过程中激活函数使用线性修正单元(Rectified Linear Unit,ReLU)。
采用多头注意力机制[15]增强图注意力学习,得到图关系编码器的输出。分别执行独立的自注意力,将子关系特征拼接起来得到输出关系特征,计算如下:
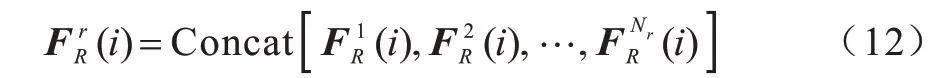
其中:Concat[]拼接用于聚合Nr种不同的关系特征。为匹配通道大小,每一个输出通道的维度设置为,然后使用残差方式增加输入对象的视觉特征V(i),得到图关系编码后的特征VR(i)如下:

在设计的关系模块中,允许从问题中输入语义信息到关系网络,为每个问题相关的关系分配更高的权重。因此,由关系编码器学习的特征不仅捕获到图像中的关系特征,而且能获得文本特征中的语义线索,动态地关注到问题中特定的关系类型和实例。图注意力机制编码如算法1 所示,运算过程如图3 所示,图中虚线表示3 头图注意力。

图3 图注意力机制关系编码Fig.3 Relationship encoding of graph attention mechanism
算法1图注意力机制编码

2.3 协同注意力
协同注意力模块由自注意单元SA 和协同注意单元GA 组成,用来处理VQA 的多模态输入特征。其中,SA 单元由多头注意力、LayerNorm[44]和前馈传播模块构成,对于多头注意力模块,先执行式(2)的“点乘”注意力,其输入中“查询”、“键”和“值”使用相同数据,即Q=K=V∈,数据维度为ds,输出为f=A(Q,K,V)。为提升注意力特征的表示能力,应用与式(12)类似的多头注意力(h头),如下:
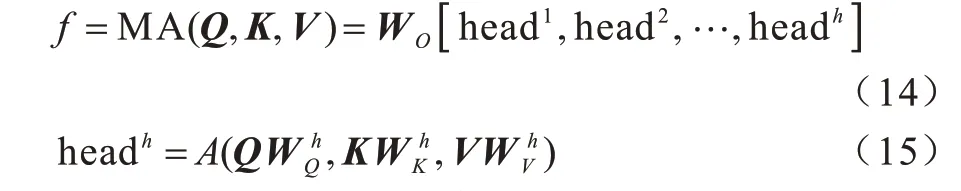
给定一组输入dx特征首先使用注意力学习成对样本<xm,xn>之间的关系,所有实例的加权求和输出注意力特征进一步通过前馈传播模块中两个全连接层(FC(4ds)-ReLU-Dropout(0.1)-FC(ds))转换输出特征E。此外,多头注意力和前馈传播模块分别使用残差连接融合输入特征,然后执行层归一化以便于反向传播的优化。
GA 单元内部构成与SA 单元一致,不同的是GA单元有维度分别为dy和dx的输入特征Y=Y引导X学习跨模态间成对样本(xm,yn),提升问题词和视觉区域间的紧密性。
协同注意力模块中X和Y是易扩展的,它们可以用来表示不同模态的特征(如文本和图像)。如图4 所示,基于SA 和GA 单元模块化组合得到协同注意力模块处理VQA 的多模态特征。在本文模型中,首先对文本特征q与带视觉关系属性的特征VR(i)进行SA 学习单模态表征;然后在GA 单元中使用q引导VR(i)对所有样本进行学习,以加强问题词与对应图像区域间的相关性。
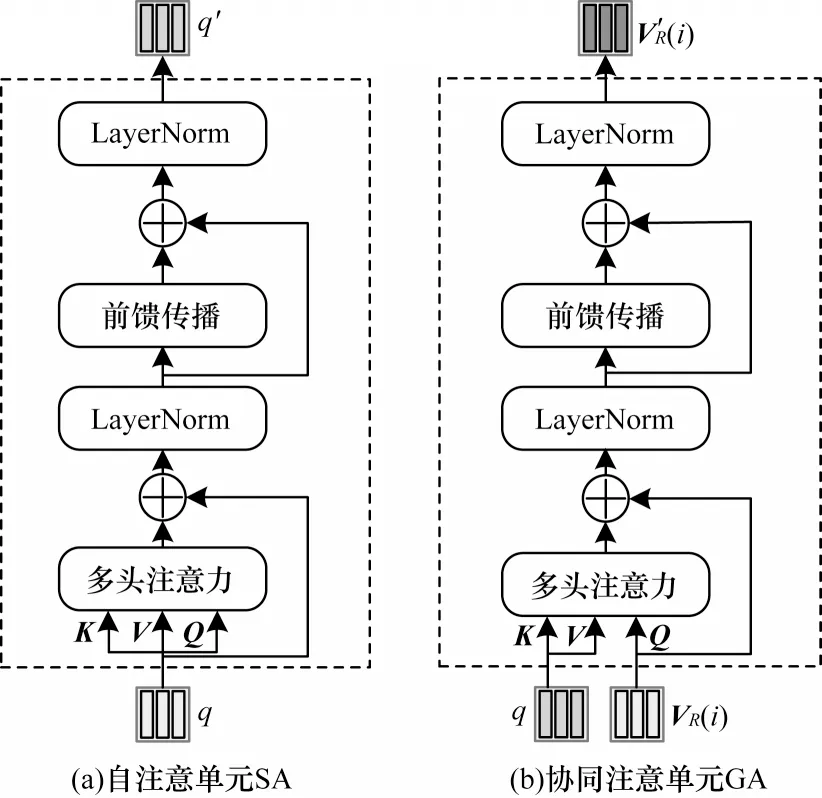
图4 协同注意力模块Fig.4 Collaborative attention module
2.4 注意力增强与答案预测
经协同注意力学习后,输出图像特征V′R(i)和文本特征q′包含关于问题词和视觉区域的注意力信息。但对于真实世界中千变万化的图像和丰富的问题形式,模型的辨识能力仍然不足。因此,本文设计一个包含多层感知机(Multi-Layer Perceptron,MLP)的注意力增强模块AttEn,以便于跨模态信息交互和增强模型拟合能力,模块内部构成为FC(ds)-ReLUDropout(0.1)-FC(1)。以GA 输出特征为例,注意力展平后特征计算如下:
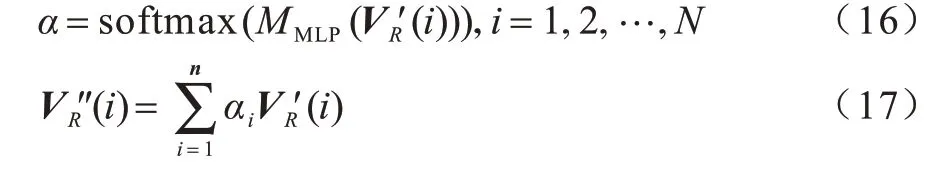
其中:α=[α1,α2,…,αn]∈ℝn是可学习的注意力权重,类似地,可以得到增强后的特征q″。

最后将融合特征U送入由两层MLP(FC(du)-ReLU-Dropout(0.5)-FC(dc))组成的答案预测模块中以预测问题答案。从预定义词汇表中选择候选答案的计算公式如下:
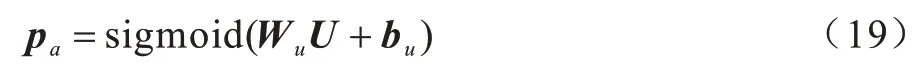
其中:Wu和bu是答案分类器中全连接层的参数矩阵;pa表示模型预测候选答案的软分数。
在VQA v2.0 数据集中,每个训练问题都与一个或多个答案相关联,可以预先确定的是:输出候选答案词表中出现9 次以上的为正确答案(3 129 类)。因此,将视觉问答视为一项多分类标签任务,使用二元交叉熵损失函数来优化模型,在融合特征的基础上训练一个多分类器。
3 实验
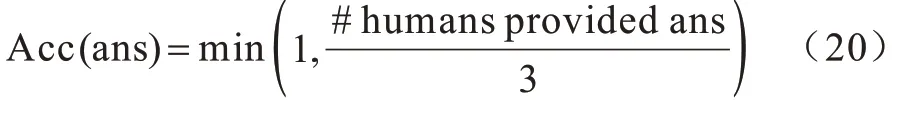
视觉问答通常被定义为多类别分类问题,其类别标签为预定义的候选答案集合。数据集的创建者设立了一个公开的评估服务器对测试集上候选答案进行盲测,使用一种投票机制来计算准确率,准确率的评估指标如下:其中:#humans provided ans 表示问题的准确答案数;ans 为问答模 型的预测答案。本文在VQA 2.0[45]和VQA-CP v2[46]数据集上训练并使用相同评估指标。
3.1 数据集
VQA 2.0 数据集由MSCOCO[47]中的自然图像组成,在训练集、验证集和测试集划分上与MSCOCO一致,是VQA 任务中公开的大规模数据集。训练集包含80K 幅图像和444K 个问题答案对,验证集包含40K 幅图像和214K 个问题答案对,测试集包含80K 幅图像和448K 个问题。另外,测试集被分成了4 个大致均匀的部分,分别是test-dev、test-standard、test-challenge 和test-reserve,用于防止模型的过拟合且使研究人员更灵活地测试开发的VQA 系统。其中test-dev 子集用于在线调试和验证实验,teststandard 子集默认为视觉问答比赛中评估模型性能的测试数据。对于每个图像,平均生成3 个问题,问题分为4 类:“总体”,“是/否”,“计数”和“其他”,标注答案由人类提供,每个图像问题对收集10 个答案,并选择出现次数最多的答案作为正确答案。数据集中问题有开放式和多选题两种,本文以开放式任务为重点,在执行过程中选择可能性最大的答案作为预测答案。
VQA-CP v2 数据集是VQA 2.0 数据集的派生,引入CP 版本是为了减少VQA 2.0 数据集中问题的偏差。在数据集中图像与VQA 2.0 相同并且为验证集提供答案注解,但图像对应的问题和问题答案分布不同。
3.2 训练细节及参数设置
实验基于Linux Ubuntu 18.04 系统,网络模型采用Pytorch 1.0.1 框架实现,使用英伟达GeForce GTX 1080 显卡进行训练。迭代优化方案使用Adamax 优化器,其中,β1=0.9,β2=0.999,权重衰减设置为0,批尺寸大小设置为128。学习率变化使用先增长后下降策略[48],初始学习率设置为0.000 5,在前4 个训练轮次依次线性增大,增大倍率为0.000 5,训练到15 轮次后,学习率每两个轮次下降1/2,模型总共迭代训练20 轮。
在图注意网络中,隐藏层中图像和问题特征维度dv=dq=1024,图注意力机制过程中dk=dg=dh=64,多头注意力个数Nr=16,输入的回归框几何特征尺寸设置为64。在协同注意单元中,文本特征输入维度dx=1 024,关系视觉输入维度dy=512,隐层维度ds=512,多头注意力数h=8。在多模态融合中,输入双模态特征维度ds=512,隐层维度du=1 024,输出预测答案维度dc=3 129。
3.3 消融实验分析
为了分析模型中每个部分的贡献和作用,本文对提出的完整模型进行大量消融实验,评估每个模块的作用并展示每个部分的有效性。如表1、表2 所示(加粗字体为最优结果),各个部分的消融模型如下:

表1 在VQA 2.0 上进行消融实验的准确率Table 1 Accuracy of ablation experiments on VQA 2.0 %
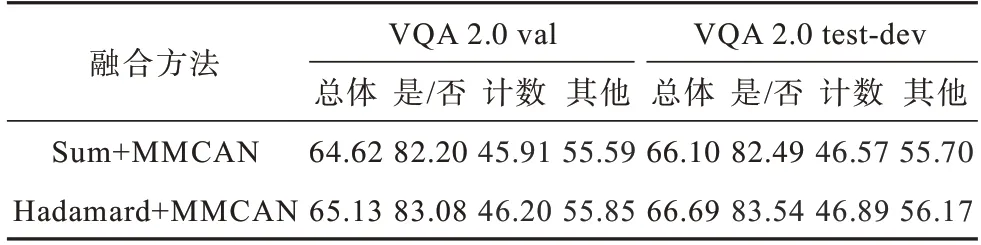
表2 在VQA 2.0 上多模态特征融合方法的比较Table 2 Comparison of multimodal feature fusion methods on VQA 2.0 %
Q+CNN:没有任何注意力的基准模型。
Q+R-CNN+co-Att:使用一个全连接层代替图2中的图网络建模,仅用协同注意力对双模态特征进行建模,是没有图关系编码的模型。
Q+R-CNN+Graph+co-Att:加图关系编码注意力模型。
Q+R-CNN+Graph+co-Att+AttEn:带注意力增强问题和自适应图关系编码的注意力模型。
Q(LSTM)+R-CNN+Graph+co-Att+AttEn:Q(LSTM)表示问题编码使用长短期记忆神经网络(LSTM)的注意力模型,本文其他消融模型中问题编码默认使用双向循环GRU 网络。
Q+R-CNN+Graph(Q-adaptive)+co-Att+AttEn(MMCAN):多模块协同注意力模型。
Sum+MMCAN:特征融合采用加和方式的协同注意力模型。
Hadamard+MMCAN:特征融合采用哈达玛乘积方式的协同注意力模型,是本文采用的多模态特征融合方式。
表1 中展示了消融模型在VQA 2.0 验证集上的性能,模型分数为“总体”类问题的准确率。除第一行基准模型使用ResNet-152 的卷积特征外,其余模型均采用Faster R-CNN 提取物体层级的特征。在相同的实验环境下,与没有任何注意力的基准模型相比,本文完整模型准确率的提高10.91 个百分点。第2 行~第6 行为本文模型不同模块的消融,可以看出,其中加图关系推理比简单注意力模型的准确率提高1.13 个百分点,证明在视觉问答任务中使用图关系编码目标对象间关系的优势;增加注意力增强后模型又获准确率提高0.29 个百分点,表明多模态融合时跨模态信息交互的重要性;同时,第5 行验证了本文模型的文本序列适用于GRU 编码;在最后一行,使用问题自适应辅助图像关系推理,准确率又提高0.40 个百分点,表明自适应问题的图像关系特征编码有助于模型学习到更多跨模态的知识,有助于提升模型的表征能力。
表2 中在val 和test-dev 验证子集上对比了两种多模态特征融合方法。其中,Sum+MMCAN 表示将两个模态特征进行简单的加和操作,Hadamard+MMCAN 则将双模态输出特征进行乘积操作。无论哪种问题类型,哈达玛乘积方式的准确率均高于加和方式,尤其在回答“是/否”类型的问题时准确率分别提高0.72、1.05 个百分点,表明本文采用Hadamard融合方式的优势。
3.4 收敛性分析
图5 和图6 分别展示了在模型训练过程中损失值和准确率的可视化情况。图5 结尾为train 表示模型仅在训练集上训练,为train+val 表示模型同时在训练集和验证集上训练。图6 结尾为val 表示验证集上的精确度,下文中train 和train+val 均表示相同含义。本节选用自下而上注意力模型[5]BUTD 和一阶双线性注意力模型[25]BAN_1 作为基线模型。
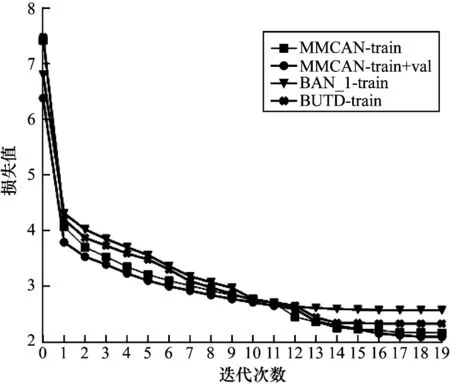
图5 训练过程中的损失变化曲线Fig.5 Loss change curve during training
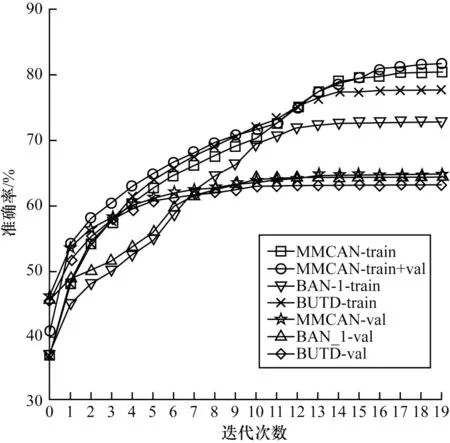
图6 训练过程中的准确率变化曲线Fig.6 Accuracy change curve during training
在图5 中,损失值随着迭代次数的不断增加保持下降趋势,在第1、12 轮处由于学习率变化导致损失曲线波动明显变化;在训练首轮,数据量扩充明显增强了模型的拟合能力;从第14 轮开始,损失函数值逐渐趋于稳定。在整体上,本文模型的收敛能力优于基线注意力模型。在图6 中,同样在损失明显下降处带来准确率的显著提升。随着训练轮次的增加,准确率逐渐增加,从14 轮处验证集精确度逐步趋于平稳,当epoch 值等于20 时,模型准确率最高。根据损失函数和准确率变化曲线,MMCAN 模型拟合能力和表示能力均优于其他模型。
3.5 定性分析
本文在VQA 2.0 和VQA-CP v2 数据集上比较了MMCAN 模型和当前具有代表性的视觉问答模型,VQA 2.0 上的实验结果如表3 所示,在VQA-CP v2上的实验结果如表4 所示。其中,加粗字体为最优结果,—表示数据为空,* 表示重新执行的结果。为公平起见,仅报告单模型在各种设置下的性能。表3 中将对比模型按照不同方法分为4 个类别,类别1 不使用任何注意力机制,类别2 使用不同的注意力机制,类别3 使用图关系推理,类别4 为MMCAN 模型。
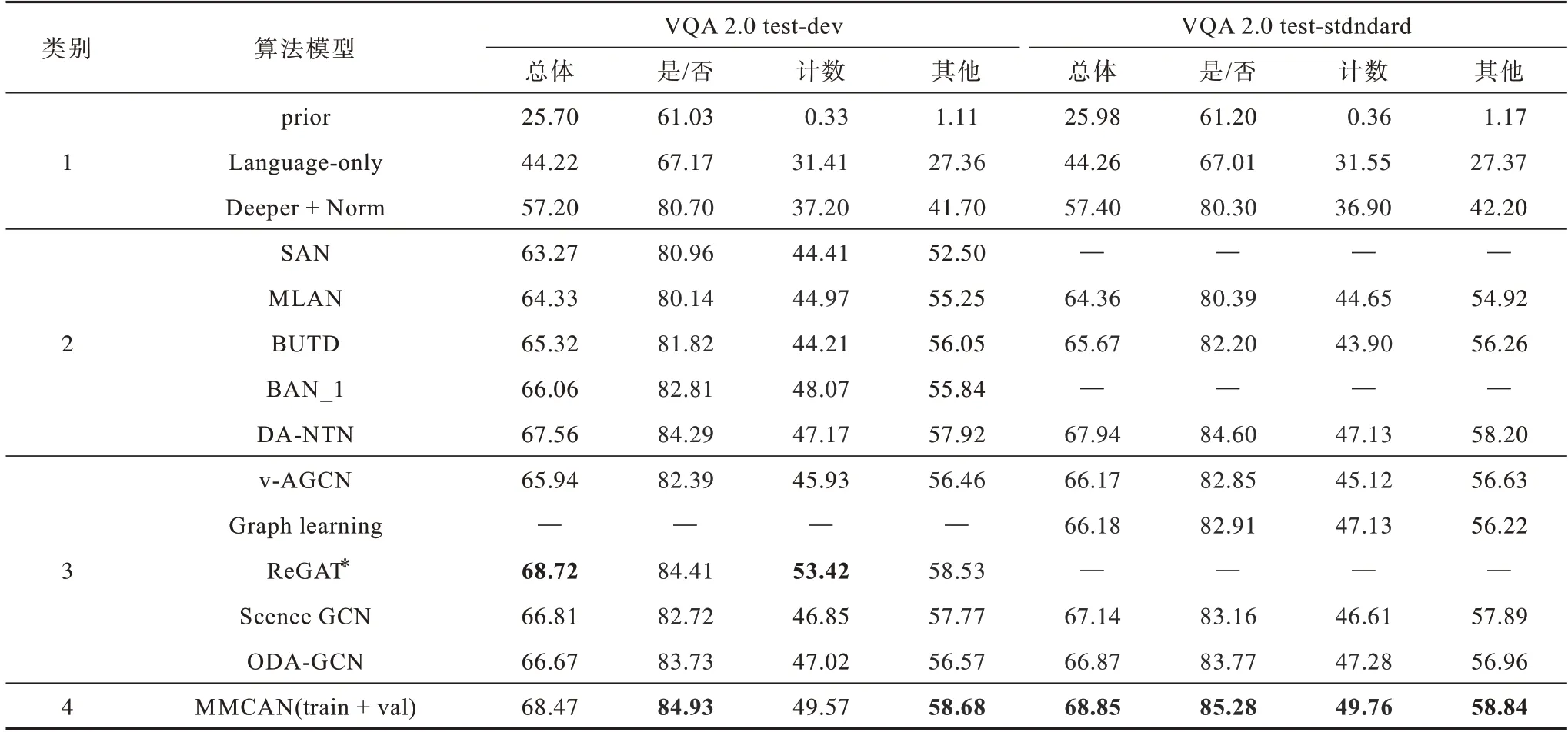
表3 不同模型在VQA 2.0 测试子集test-dev 和test-standard 上的性能比较Table 3 Performance comparison of different models on test-dev and test-standard of VQA 2.0 %
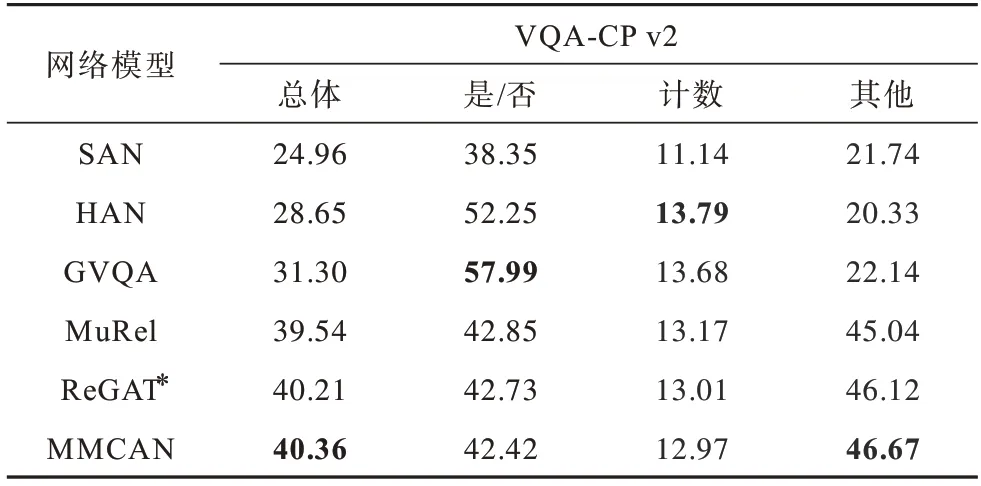
表4 不同模型在VQA-CP v2 上的性能比较Table 4 Performance comparison of different models on VQA-CP v2 %
与早期没有任何注意力基线模型prior、language-only 和Deeper+Norm 相比[3],本文模型获得大幅提高,在test-dev 上“总体”精确度分别提升42.67%、24.25% 和 11.27%,在 test-standard上有42.87%、24.59%和11.45%的提高。与使用不同注意力机制的算法SAN[12]、MLAN[13]、BUTD[8]、BAN_1[25]和DA-NTN[9]相比,本文模型在test-dev 上“总体”精确度分别提升5.20、4.14、3.45、2.41 和0.91 个百分点;在test-standard 上,相 比MLAN、BUTD 和DA-NTN,MMCAN 分别提升4.49、3.18 和0.91 个百分点。结果表明,通过图注意力网络自适应建模视觉对象间语义关系,动态地关注到每个问题的特定关系,有效提升视觉问答的准确率。值得注意的是,深度注意神经张量网络的性能接近MMCAN 模型,DA-NTN 是基于张量的切片式注意模块来选择最具区分性的对象间关系进行建模,这与本文的图关系模块类似,但其运算代价更大。
与使用图网络建模关系的算法v-AGCN[32]、Scence GCN[35]和ODA-GCN[34]相比,模型在test-dev上“总体”精确度分别提高2.53、1.66 和1.80 个百分点;与v-AGCN、Graph learning[33]、Scence GCN 和ODA-GCN相比,在test-standard 上MMCAN 分别提高2.68、2.67、1.71 和1.98 个百分点。结果表明,采用简单的GCN 对图像关系建模,本文模型采用图注意力机制,更好地捕获到视觉场景中对象间的语义依赖关系,通过自适应问题多样性来丰富动态的关系表示,较好地理解与问题相关的场景。在相同条件下,MMCAN 没有使用额外VG 数据集辅助训练,但总体性能与单模型的ReGAT 性能相当,并在“是/否”与“其他”类问题上提升0.52 和0.15 个百分点。结果表明,本文模型充分发挥图网络与协同注意模块的作用,有效融合了问题与图像特征。
同时,本文在派生数据集VQA-CP v2 上进行实验,表4 展示了测试集上不同问题类型的评估结果。无论是否使用关系推理,本文模型在“总体”和“其他”两类问题上都优于以往的工作,如SAN、HAN[49]、GVQA[46]、MuRel[10]和ReGAT。与两个基线算法SAN 和GVQA 相比,本文模型性能分别提高15.40%、11.91%和25.03%、26.34%,与具备关系推理的模型MuRel 和ReGAT 相比,分别提高0.82、1.63 和0.15、0.55 个百分点。可以看出,本文模型充分发挥了图注意网络和协同注意力的作用。协同注意力加强了双模态信息的交互,使模型集中注意在文本序列和视觉特征交融部分,减少冗余信息的干扰;图注意力机制能够聚焦于感知目标在图像中的区域位置,使模型根据问题动态捕获目标对象间关系,表明关系推理结构在视觉问答中有正向作用。实验结果证明了GVQA 网络重点关注“是/否”类问题的优势。
为进一步验证本文模型的有效性,本文在VQA 2.0验证集上与表3 中的注意力模型和图关系推理模型进行对比。如图7 所示,MMCAN 模型的总体准确率为65.13%;与注意力模型SAN、BUTD、BAN_1 和DA-NTN 相比,MMCAN 的总体精确度分别提高6.45、1.90、0.68 和0.55 个百分点;与图结构模型v-AGCN相比,MMCAN 的总体精 确度提高0.93 个百分点。由于MLAN、Graph learning 和Scence GCN并未报告其在VQA 2.0 上的性能,因此没有进行比较。可以看出,MMCAN 在验证集上的性能同样优于表3 中的模型。
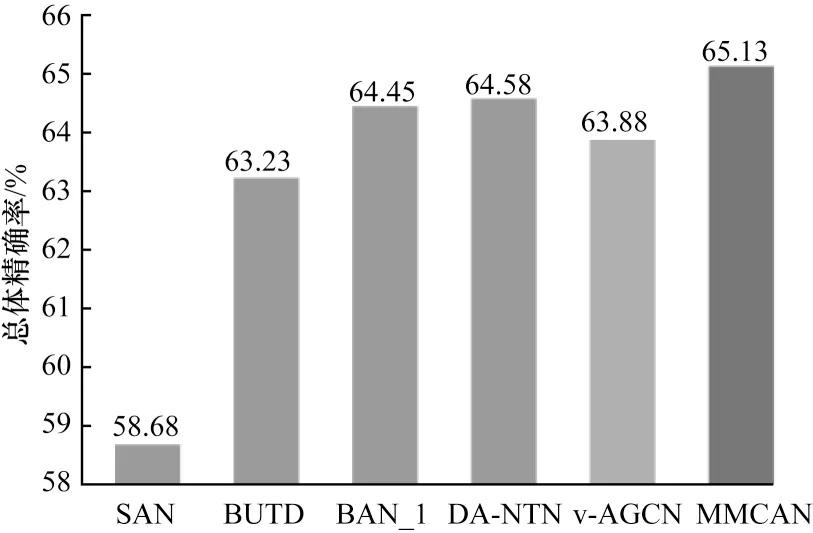
图7 不同模型在VQA 2.0 验证集上的精确度Fig.7 Accuracy of different models on VQA 2.0 validation sets
为对算法进行补充说明,将最优模型提交到VQA 2.0 在线服务器上评估,由于服务器资源的限制,这里仅测试MMCAN 模型。如图8 所示,在testdev 测试子集 上,MMCAN-tarin关于“总 体”、“是/否”、“计数”和“其他”4 类问题的精确度分别为66.69%、83.54%、46.89% 和56.17%,MMCAN-tarin+val 的精确度分别 为68.47%、84.93%、49.57% 和58.68%。在 图9 中,test-standard 测试子集 上MMCAN-tarin关于“总 体”、“是/否”、“计 数”和“其他”4 类问题精确度 为66.94%、83.73%、46.30% 和56.41%,MMCAN-tarin+val 分别为68.85%、85.28%、49.76%和58.84%。结果表明,在两个测试子集上,同时使用验证集辅助模型训练的精确度均优于单训练集,证明通过扩充数据集能有效提升模型性能。

图8 不同问题在VQA 2.0 test-dev 上的精确度Fig.8 Accuracy of different problems on VQA 2.0 test-dev

图9 不同问题在VQA 2.0 test-standard 上的精确度Fig.9 Accuracy of different problems on VQA 2.0 test-standard
4 结束语
本文提出一种面向视觉问答的多模块协同注意力网络(MMCAN)。MMCAN 由一系列模块化组件构成,通过自适应问题图注意力机制对多种类型的视觉对象关系进行建模,以协同方式模拟单模态内和多模态间的动态交互作用,学习与问题最相关的视觉特征,进而提供完整的场景解释,实现对复杂问题的有效回答。实验结果表明,本文算法能够有效利用区域级视觉对象间相关辅助答案的推理,在推理答案过程中使用问题语义特征使模型聚焦于相关的图像区域,促进视觉问答准确率的提升。尽管本文算法在视觉问答各种子任务上获得优良性能,但在“计数”和“其他”类复杂问题上的精确度相对较低。下一步将研究如何有效缩减多模态间的语义鸿沟,例如基于先验知识对不存在显式关系的边进行剪枝、增强图网络的关系编码能力等,同时还将预训练一个视觉语言模型,专注于解决视觉问答中的某些子问题,如物体计数、基于常识的推理等。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
开放教育研究(2020年2期)2020-03-31 01:54:14
传媒评论(2017年3期)2017-06-13 09:18:10
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
现代语文(2016年21期)2016-05-25 13:13:44
湖北经济学院学报·人文社科版(2015年8期)2015-12-29 05:53:07
上海电机学院学报(2015年4期)2015-02-28 14:30:00
大连民族大学学报(2015年2期)2015-02-27 08:28:11
计算物理(2014年2期)2014-03-11 17:01:39
外语学刊(2011年1期)2011-01-22 03:38:33
