
基于新型混合深度学习的风电机组功率预测模型开发及应用
2022-02-23 06:20王丽杰唐宏芬张真真张路娜
电力科技与环保 2022年1期
王丽杰,唐宏芬,张真真,张路娜
(中国大唐集团新能源科学技术研究院有限公司,北京 100052)
1 引言
近年来,风力发电机在全球范围内得到大量推广,在满足电力需求降低电价的同时减少了温室气体的排放,极大的推动了全球绿色能源可持续发展的进程。预计未来风力发电量将继续增加,以实现2030年可再生能源占总发电量50%的能源目标[1]。但是如果没有采取适当的措施,如电力精准预测、建立储能系统等,那么风力发电的性能劣化可能会严重破坏供电可靠性、安全性和经济性[2]。建立储能系统虽然可以起到降低风力发电性能劣化的作用,但是在处理过程中所需面临的环境问题、土地使用问题以及费用问题极大的增加了投入成本。发电功率预测模型是一种环保经济的解决方案,可以协助管理部门对风电机组的运行状态进行评价判断。当风电机组出现发电性能劣化时,发出预警并提醒工作人员关注风电机组运行状态,同时指导维护人员完成相关设备维护,杜绝发电性能劣化的持续发生,保证风电机组发电效率,有效提高风电机场的运行水平[3]。
目前,风电机组发电性能判断主要依赖发电功率曲线进行判断。具体而言,通过设备采集到的运行数据,建立机组发电功率曲线模型,并通过该模型实时监测风电机组发电功率变化,准确发出风电机组性能劣化预警[4]。然而,由于自然环境中的风速具有非线性特征且有高变化率,且大气温度和压力等也会影响风电机组发电功率,使得发电功率预测模型准确性较差[5]。现阶段,还没有典型的风电功率预测模型。因此如何通过提前调度来提取特征和建立准确预测发电功率的模型以确保电力系统可靠、安全运行成为国内外专家研究的重点。
预测风电机组发电功率的预测方法有很多,包括物理模型、统计模型、混合人工神经网络模型等[6-7]。物理模型方法主要在考虑初始值和边界条件的基础上通过物理和大气的水动力和热力学模型进行预测,该方法的发电功率预测性能较差[8-9]。常见的统计学方法如概率自回归模型和概率质量偏差模型等,可建立风力发电与解释变量之间的关系,但该方法存在适应性和学习能力较差的问题,并其性能随着预测时间段的增加而降低[10-11]。人工神经网络具有映射非线性关系、自学习能力强等优点,在风力发电预测中得到广泛的应用[12-14]。该技术的主要优点是不需要任何数学模型来建立输入和输出数据之间的关系,虽然人工神经网络在预测风力发电功率方面表现出了良好的性能,但它也存在着模型过拟合和欠拟合的问题以及在更新隐藏层权重和偏差方面效率低下[15]。针对这些缺点,Lu等提出了一种使用支持向量机(Support Vector Machine,SVM)算法预测短期风电发电功率的框架,即在支持向量机模型中采用灰狼算法调整核函数的参数[16]。Li等提出了一种支持向量机与改进蜻蜓算法相结合的风力发电预测模型,其中采用自适应学习因子和微分进化方法改进的蜻蜓算法,对支持向量机的参数进行优化选择[17]。
深度学习模型因其具备较高预测准确性,且能克服传统神经网络缺点如训练时间长和收敛速度慢等而受到国内外学者的广泛关注。Abedinia 等提出了一种二维卷积神经网络(Convolutional Neural Network,CNN),用于预测短期和长期风力发电功率,其中小波变换方法用于分解数据,粒子群优化算法用于调整CNN的权重以提高模型的预测精度[18]。
Li等通过使用梯度下降法训练LSTM(long short-term memory,LSTM)神经网络来预测短期风力发电功率[19]。Sun等提出了一种由LSTM、小波分解和主成分分析法组成的超短期概率预测方法,通过建立正态分布模型以解释预测中的不确定误差[20]。Wang等设计了一种贝叶斯平均和集合学习的混合模型来预测短期风电机组发电功率[21]。Niu等提出了一种基于注意力的门控循环单元(Attention-based Gated Recurrent Unit,AGRU),并开发一种识别基本输入变量的注意力机制作为功能选择方法用于预测短期风力发电功率[22]。
He等通过小波变换分解风速序列,并使用深度置信网络提取特征,开发了深度学习和集成学习的组合以预测风力发电功率。然而,通过机器学习等方法建立的风电机组发电功率预测模型需要通过大量数据进行训练,其中输入数据为监测系统采集到的影响发电功率和性能的相关因素[23]。郭鹏等基于风电机组的运行原理,分析了环境因素、变桨系统、偏航系统和控制系统对风电机组性能和发电功率的影响[24]。谢生清等在上述研究基础上对风向标、风速仪、叶片机械对零等几个影响发电功率的外部因素进行了分析总结[25]。马东等考虑了风速、桨距角、偏航误差、叶轮转速等其他变量对发电功率的影响[5]。但是上述文献并没有将影响风电机组发电功率的所有因素全部考虑进去,因此构建的发电功率预测模型存在一定偏差。
综上所述,现有文献针对风电机组发电功率预测模型的研究存在以下问题:预测输入变量种类多需求量大,同时这些变量需要进行预测,导致附加误差;通过公式将预测风速转换为风力发电功率时会导致累积误差;由于技术局限性,无法使用数据分解技术处理大量数据如季节性影响的数据;忽略预测模型的参数调整等。
针对现有预测模型的局限性,本文设计了一种新型混合深度学习预测模型提高对风电机组发电功率的预测准确性。该预测模型由卷积层(convolution layers),门控循环单元(gated recurrent units,GRU)和神经网络(neural network)组成,首先通过卷积层提取复杂数据集的高维特征,然后使用这些特征训练门控循环单元以获取基本特征的长期存储,最后通过神经网络建立由前一层处理的输出和输入数据集之间的关系。新型混合深度学习预测模型的参数通过网格搜索技术进行系统调整,以提高预测准确性。
2 基于混合深度学习预测模型设计与实现
2.1 混合深度学习模型
传统风力发电功率预测模型中,首先需要通过其他预测方法对影响风力发电功率的影响因素如风速,风向,气温,气压数据等进行预测估计,然后依据这些预测数据通过预测模型对发电功率进行预测,因此会导致更多的预测误差。本文设计的基于混合深度学习预测模型通过时间序列法预测风力发电功率,不需要对影响风力发电功率的影响因素进行先验预测,只需要通过分析过去数据的模式来预测风力发电量。时间序列法中X=x1,x2,……xt是一段时间范围内的观察序列,其中表示在时间t处的观察数据值,X表示观察数值的总数目。混合深度学习模型的输入和输出数据集通过滑动窗口方法从时序数据中获得,如图1所示。其中,Sw代表滑动窗口,fh代表预测范围区间,d(t)代表在时间t处的时间序列,Y代表输出数据。在滑动窗口范围内的时间序列作为模型的输入数据,预测范围区间内的数据为输出数据,滑动窗口每次移动一个单位时间步长。图1展示了用于训练和测试模型的数据集,其中n代表输出数据集中的时间步长。

图1 滑动窗口方法获取数据
2.2 卷积神经网络
混合深度学习模型架如图2所示。
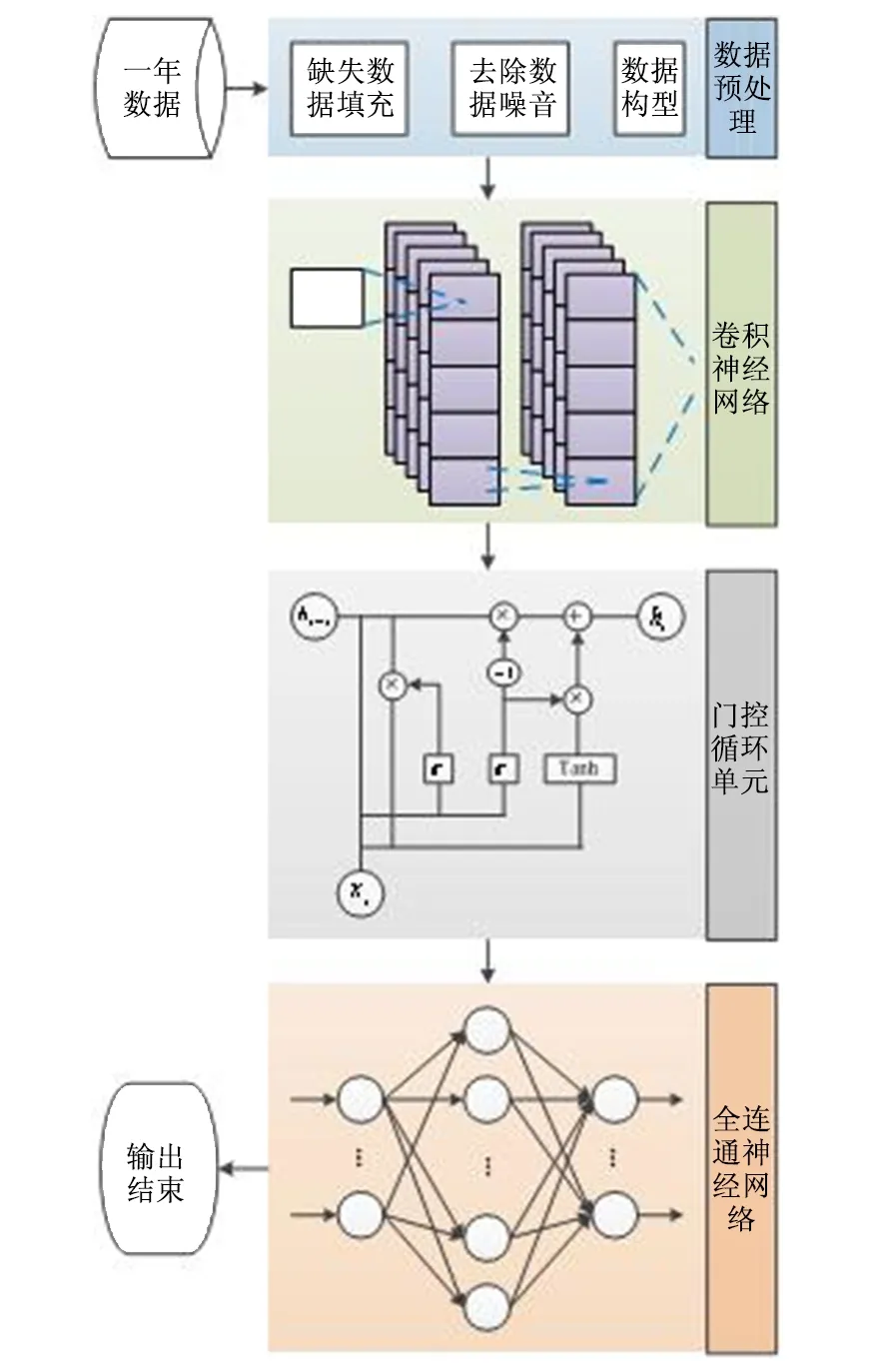
图2 混合深度学习模型框架
卷积神经网络CNN由卷积层,池化层和全连接层组成,具有捕获相同数据模式的能力,可以成功用于复杂较高的数据格式。CNN主要用于的网格状拓扑结构,例如视觉图像的二维或三维数据,但同时它也可用于一维的数据,例如作为单变量时间序列数据。在本文中,一维CNN用于提取短期风力发电的非线性输入和输出数据集之间复杂关系的特征。
卷积层的功能是通过数学卷积算子和求解交叉相关对输入数据进行特征提取,卷积运算公式如下:

(1)

在卷积层进行特征提取后,输出的特征图会被传递至池化层(pooling layer)进行特征选择和信息过滤,通过将混合一层的神经元簇输出到下一层中的单个神经中来减小数据的大小。
池化层包含预设定的池化函数,其功能是将特征图中单个点的结果替换为其相邻区域的特征图统计量。上一层中每个神经元簇的最大值用于最大池,而神经元簇的平均值用于平均池,在本文基于深度学习模型中使用平均池。每个特征图都分类为一组子区域,并且每个子区域通过下采样进行组合以生成新元素。通过顺序向下采样可以创建一个新的低维特征图,其表示如下:
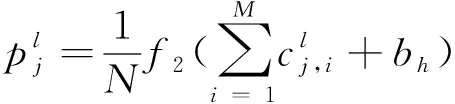
(2)
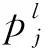
2.3 门控循环单元
GRU由Kyunghyun Cho在2014年提出的循环网络的门控机制,是LSTM的简化版本。GRU解决了梯度消失的问题,即长期依赖关系中的梯度传播失败,类似于LSTM模型,但参数较少。GRU网络的主要思想是利用具有简单结构的特定神经元在长时间内存储和传输信息,以获得永久性记忆,减少信息破坏的速度,捕获长期依赖性。在GRU架构,只有两个栅极,复位栅极和更新栅极,如图2中所示。数学建模可以表示如下:
zt=σ(Wzg[ht-1,xt]+bz)
(3)
rt=σ(Wrg[ht-1,xt]+br)
(4)
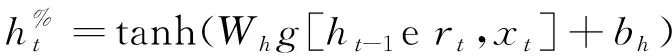
(5)

(6)

2.4 人工神经网络
通过使用输入和输出数据集训练网络来执行这些操作,从而建立它们之间的关系。提供输入数据后,将经过训练的网络用作预测输出的模型。在训练中,网络会更新其权重以尽可能准确地了解这种关系。为了学习输入和输出数据之间的复杂关系,本研究使用ReLU激活函数来简化训练并获得更好的性能。

对于任何大于零的值,ReLU都是线性的,但是对于任何负值,ReLU仍然是非线性的。由于该函数对于任何正值都是线性的,因此在使用反向传播训练网络期间,可以轻松更新其权重。
3 实验分析
本节通过分析预测风力发电功率来验证混合深度学习模型的预测结果以及对风电机组发电性能劣化的预警情况。首先,对混合深度学习网络的超参数调整,以确定最佳预测模型。通过网格搜索方法,从可能的参数设置中选择最佳参数。然后,针对同样的算例,对比不同预测方法LSTM、SVM、GRU、RNN下的预测结果,通过对比预测结果验证本文所提模型的有效性。预测模型和算例实验在处理器Intel Core i7 9th,主频3.00 GHz,内存16 G的测试平台上进行,编程语言环境为Python 3.7。
3.1 数据预处理
由于SCADA数据取自实际风电场,这些数据容易受到噪声,异常值和丢失数据的影响,进而影响到模型的准确度。通信失败是丢失数据的主要原因,数据的异常值被简单地删除并视为缺失值。
缺失值:风力发电的缺失值由缺失数据的前三个和下一个时间步的平均值填充;
数据转换:由于通过捕获风电机组发电记录的数据种类繁多,存在不同种类数据描述风电机组同一个属性特征的情况,首先要将关于风电机组同一属性特征的不同种类数据进行合并,在降低数据维度的同时可以得到更为全面的数据信息。故首先通过数据聚合技术对捕获的数据样本进行数据聚合。然后对聚合后的数据进行归一化处理,以消除参数间不同数量级对机器学习模型的差异性影响。
数据结构:为了在接下来的步骤中预测风电场的风力发电功率,通过使用移动窗口方法将输入时间序列转换为输入-输出对,将数据分为输入和输出格式,如下所示:
[xt+1,xt+2,…,xt+h]=f(xt,xt-1,…,xt-w)
(8)
式中:w输入数据的窗口大小;xt时间序列数据;h预测范围;f通过训练建立的深度学习模型。
3.2 超参数校验
通过网格搜索方法对混合深度学习模型进行的调整,以实现风力发电预测的最佳预测模型。由于混合深度学习模型是随机的,需要对模型进行多次评估以获得在预测方面的可靠配置,本文在校验参数时进行10次评估,并选择样本结果的中位数作为参数的最佳配置的标准。通过算例实验得出各个超参数的最佳标准:GRU层2层,神经网络层2层,卷积层中卷积核大小为3,过滤器尺寸为64。
3.3 评价指标
通过使用平均绝对误差(Mean Absolute Error,MAE)指标对所提出模型的性能进行不同预测方法对比评价。MAE是指实际值和预测值之间的绝对误差的平均值,MAE可用作性能指标,可以避免数据集中的异常值(极值)的影响,MAE的较小值表示预测的准确性较高。

(9)

3.4 预测模型验证
收集某地风电机场的1个自然年的数据样本用于训练和测试预测模型,样本时间间隔为5min,其中95%的数据用于训练预测模型,剩余5%的数据用于测试所提模型的有效性。该预测模型在5%数据下的测试结果如图3所示。

图3 模型预测结果
其中图3(a)是整体预测结果,图3(b)是为进一步清晰展示预测结果,截取第600~1000的样本数据及其预测结果。可以看出预测值接近实际值,且在图所示的预测数据中存在几个峰值之后,预测值的误差也非常低。在预测测试数据时,预测值与实际值之间的平均绝对差为2.48,同时也没有出现过度拟合和拟合不足的问题。
3.5 风电机组劣化检测实例
在本节中通过预测某地风电场的风力发电功率,进一步评估了预测模型对风电机组发电性能劣化判断的可行性。选取实验机组为期1年的数据并对数据进行预处理。其中95%的数据用于训练预测模型,5%的数据用于测试验证。通过与对比预测模型LSTM、SVM、GRU、RNN进行比较,可以得到MAE性能指标的结果,如图4所示。
从图4可知,LSTM模型的MAE指数为2.34,GRU模型的MAE指数为2.35,SVM模型的MAE指数为2.37,RNN模型的MAE指数为2.37,而本文所提预测模型的MAE指数为2.32,性能最好。
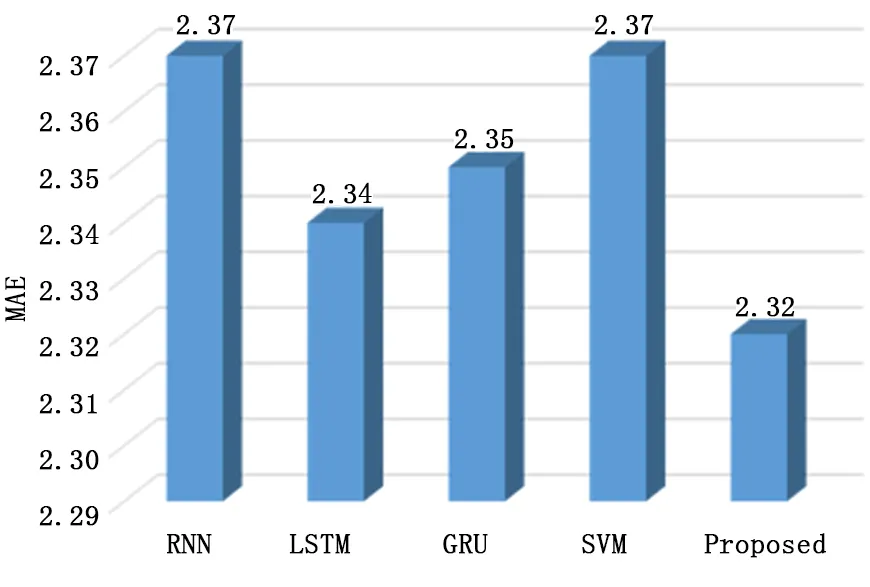
图4 不同预测模型预测结果比较
图5展示了本文所提预测模型对该地风电机组发电功率的预测曲线与实际发电功率曲线。
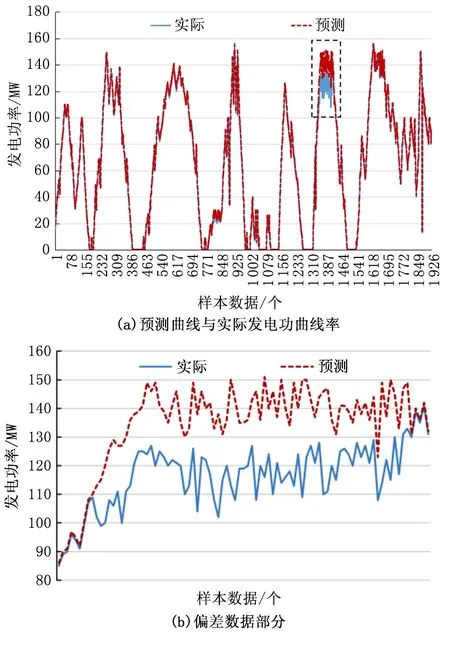
图5 基于混合深度学习预测模型预测结果
通过观察图5中(a)图可得:在统计数据时间刚开始时,发电机组运行正常,预测模型预测发电功率数据与实际发电功率数据高度吻合,但是存在部分时段实际发电功率数据与预测发电功率数据出现偏差,将图5(a)中虚线框内的偏差数据结果放大如图5中(b)图所示,此时预测数值大于实际数值。
同时对该部分样本数据进行统计指数加权移动平均值控制图法(Exponentially Weighted Moving-Average,EWMA)残差分析[5]可以得出此时超出EWMA控制图的上下控制限,如图6所示。

图6 EWMA残差分析
WMA统计量在该时间段内出现多次持续超过控制图下限,则此时说明发电机组出现性能劣化情况,系统发出警报。风电机组维护小组维护后,实际发电功率数据与预测发电功率数据重新高度吻合,此时风电机组性能得到恢复。
4 结论
(1)提出了一种新型混合深度学习模型预测风电机组发电功率,该模型由卷积层,门控循环单元层和神经网络层组成。卷积层提取数据特征,门控循环单元将信息保留在内存中,提高了预测准确性。通过风电场中实际风力发电的数据样本对预测模型进行训练和测试,系统地调整预测模型的参数,确保了预测模型的准确度。最后通过对比其他现有文献的预测模型,验证了本文所提预测模型的有效性。
(2)未来将考虑不同的大气条件的情况下,将短期风电功率预测的准确性与短期风能预测的准确性进行比较,进一步研究混合模型的有效性。
猜你喜欢
现代电力(2022年2期)2022-05-23
防爆电机(2022年1期)2022-02-16
北京航空航天大学学报(2021年9期)2021-11-02
建材发展导向(2021年13期)2021-07-28
海峡姐妹(2020年8期)2020-08-25
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
山东工业技术(2016年15期)2016-12-01
山东工业技术(2016年15期)2016-12-01
