
基于Lance距离和信度熵的冲突证据融合方法
2022-02-23 08:32:24尹东亮
系统工程与电子技术 2022年2期
王 旋, 狄 鹏,*, 尹东亮
(1. 海军工程大学管理工程与装备经济系, 湖北 武汉 430033; 2. 海军工程大学作战运筹与规划系, 湖北 武汉 430033)
0 引 言
D-S(Dempster-Shafer)证据理论自19世纪诞生后,在不确定推理、多传感器融合等领域发展迅速,可有效解决多传感器多源信息融合问题。然而,证据融合作为D-S证据理论应用的关键一步,由于证据源并非完全可靠以及Dempster合成规则是基于乘法原理建立的,当其融合了冲突证据时,在其合成的标准化过程中常出现悖论现象。
基于以往学者对证据冲突的定义,可表述为:某一证据以很高的信度支持命题A,而另一个证据则以很高的信度支持另一个命题B,同时命题A和B相互独立。当前,关于已有的冲突数据融合策略研究主要有两方面,一是改进Dempster合成规则,二是修正证据本身。
在改进Dempster合成规则的方法中,主要针对的是冲突重新分配问题。文献[2]否定了所有冲突证据,冲突通过未知项来表示,使得融合后证据的不确定性程度增大。文献[7]引入了可信度的概念,但其认为所有证据的可信度都相同,通过加权求和的方法修改合成规则。文献[8-9]通过计算证据距离来度量证据可信度,但其在计算证据集有效性系数的方法上有所差异。文献[10]认为上述方法具有一定的主观性,因此提出通过分配证据冲突概率的方式来权衡不同证据冲突程度的差异。文献[11]通过计算证据间支持度矩阵来度量各证据的可信度,并基于证据可信度的加权平均法处理各证据。以上方法是从全局冲突分配的角度来考虑,而未从局部冲突角度,文献[12-13]分别提出了两种局部冲突分配方法,但存在违背Dempster合成规则的交换性和结合性等理论的情况。
在修正证据本身的方法中,文献[14-15]分别用加权证据和平均证据取代了原始证据,但均没有考虑各证据的重要程度。文献[16] 从各证据重要程度的角度出发,通过引入证据权修正原始证据的mass函数,得到了同等重要的新证据,但该方法具有不稳定性。文献[17]通过对证据进行冲突检验,加权融合冲突证据,可降低证据之间的冲突影响,但该方法对于判定冲突证据阈值的选取具有主观性。文献[18]利用皮尔逊相关系数进行相关性限制,以及结合零因子修正原始证据,再利用修正后的基本信任分配函数进行D-S组合规则计算,得到最终融合结果。除了上述方法外,还有通过定义不同证据距离的方法来修改证据本身的研究,文献[19]引入了K-L(Kullback-Leibler)距离函数,提出了一种新的冲突证据融合方法。考虑到不同距离函数对证据可信度的描述效果不同,文献[20]提出了一种基于Mahalanobis距离函数的融合方法,然而Mahalanobis距离函数需要矩阵的协方差计算,不适合大规模数据处理。文献[21]通过计算Jousselme距离函数来度量证据的可信度,可有效利用各证据的全局信息。文献[22]提出了基于Lance距离函数的融合方法,较基于其他距离函数的方法融合效果更好,但其未考虑各证据的不确定性因素。
在以上两大类方法中,改进Dempster合成规则的方法忽视了证据之间的关联性、交互性。当出现证据冲突问题时,采用改进Dempster合成规则的方法并不能明显提升最终的融合精度。因此,通过修正证据将能够更加有效地解决冲突证据融合问题,但其重点在于度量证据冲突的程度。通过结合原始证据来度量冲突,从多维度考虑证据的有用信息,达到合理修正证据和有效融合冲突证据的目的。
因此,本文提出一种基于考虑证据之间关系及其本身特性的证据融合方法。首先,分别引入Lance距离和信度熵来度量各证据的可信度和不确定度。其次,结合各证据的可信度和不确定度来确定最终融合的折扣系数,通过对原始证据进行折扣处理得到修正后的证据。最后,利用Dempster合成规则实现证据融合。通过算例结果分析,表明在原始证据源正常和有冲突时,本文方法均能够更有效地降低证据冲突问题带来的不利影响,收敛速度更快,融合结果更可靠。
1 基于可信度和不确定度的冲突证据融合方法
1.1 基于Lance距离的证据可信度确定
随着当前D-S证据理论的应用愈来愈广泛,基于证据距离的研究受到国内外学者的青睐,因此出现了许多度量证据间距离的方法,其中有Minkowski距离、Jousselme距离和Mahalanobis距离等,但Minkowski距离函数需要各证据有同样的属性维数,这会失去证据的一致性;Jousselme距离函数受证据基本信任分配函数的分散程度影响,在度量证据冲突程度方面具有一定缺陷;而Mahalanobis距离函数则需要矩阵的协方差计算,不适合处理大规模数据。因此,本文引入了更为理想的距离测量方法——Lance距离。
定义系统辨识框架为={,,…,},系统共有个证据,,…,,对应的mass函数分别为,,…,,其中={(),(),…,()}。假设其中两个证据为、,则证据、之间的Lance距离为
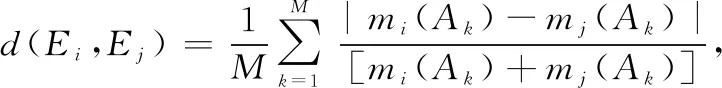
(1)
,=1,2,…,;=1,2,…,。
根据各证据之间的Lance距离,任意两个证据间的距离可用Lance距离矩阵的形式表示,定义如下:

(2)
式中:即(,),表示证据、之间的Lance距离,当=时,=0。
通过计算证据距离能度量其之间的相似程度,而 1-可度量证据之间的相似度,因此定义(,)为
(,)==1-=1-(,), 0≤≤1
(3)
定义相似度矩阵为

(4)
相似度矩阵中的元素反映了证据与的一致性程度,值越大,一致性程度越高,否则越低。而证据的不确定性会随着其包含的不确定信息增多而增加,考虑到不同证据在辨识框架下的权重各不相同,因此利用证据的可信度确定其权重,则证据的可信度Rel定义为

(5)
1.2 基于信度熵的证据不确定度确定
信息熵被定义为描述一个随机变量的状态所包含的信息量。Shannon在信息熵的基础上提出了Shannon熵用于度量证据的不确定程度,而邓勇提出的信度熵则是对Shannon熵进行了普适化改进。信度熵越小,表明证据提供的信息量越小,则证据的不确定程度越小;反之,信度熵越大,表明证据提供的信息量越大,则证据的不确定程度越大。因此,本文引入信度熵理论来度量证据的不确定度。信度熵基本概念介绍如下。设定(=1,2,…,)为系统辨识框架的子集,()(=1,2,…,)为证据对应的mass函数,||表示子集所包含元素的个数,则关于证据的信度熵Ed为
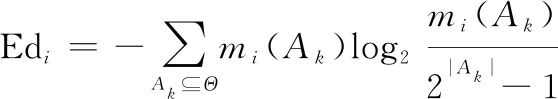
(6)
当子集只包含一个元素时,即||=1,信度熵退化为Shannon熵,此时信度熵为
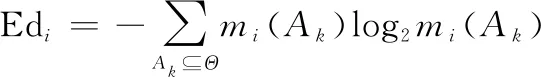
(7)
子集包含的元素越多,证据的信度熵Ed就越大,表明证据的不确定度也越大;子集包含的元素越少,证据的信度熵Ed就越小,表明证据的不确定度就越小,则证据对应的权重应越大。
但为了避免在某些情况下赋予证据零权重,本文通过计算信度熵的指数形式来确定证据权重的大小:
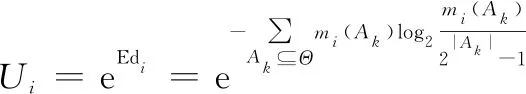
(8)
经归一化处理后,证据的不确定度Unc为
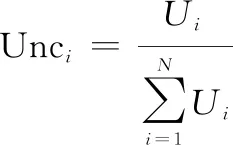
(9)
1.3 可信度和不确定度相结合的证据加权融合
Murphy提出的证据加权融合方法为:计算所有证据mass函数值的平均值,并将其代替所有证据的mass函数值,使用Dempster合成规则进行-1次(为所有用于融合的证据总数)融合得出最终结果。Deng在其基础上进行了改进,通过计算证据距离得到证据对应的权重,再利用加权平均法对证据进行处理,最后使用Dempster合成规则进行-1次融合。本文充分通过计算证据可信度和不确定度确定最终融合权重,再利用Dempster合成规则进行-1次融合。
通过前文分析,当某个证据被其他证据支持程度越高时,表明此证据与其他证据差异程度越小,即其可信度越高,则在进行证据加权融合时应赋予更大的权重。同理,当某个证据不确定度非常低时,表明此证据更加明确清晰,也应被赋予更大的权重。因此,将可信度和不确定度相结合来确定证据融合权重的方法更加合理。
基于可信度和不确定度的证据加权融合方法具体如下。
(1) 通过式(1)~式(5)计算得到证据的可信度Rel。
(2) 通过式(8)和式(9)计算得到证据的不确定度Unc。
(3) 依据证据可信度和不确定度确定的融合权重进行折扣处理,最终融合的权重大小即折扣处理时折扣系数的大小,则证据的折扣系数为
=Rel·Unc
(10)
对折扣系数进行归一化处理:
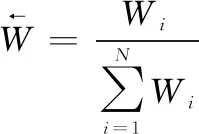
(11)
(4)对证据的mass函数值() (=1,2,…,;=1,2,…,)分别赋予所对应的折扣系数,可得到修正后证据的mass函数值():
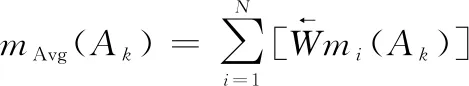
(12)
(5)进行证据融合。首先,将计算得到的mass函数值()用于修正原始证据源mass函数。其次,应用Dempster合成原则,将mass函数值合成-1次(当系统中原始证据有个时),得到的证据融合结果为
=((((⊕)⊕…))⊕)-1
(13)
式中:⊕遵循Dempster合成规则。
为了更直观表示融合过程,可用表格形式展示具体融合过程。
利用式(12)中得到的替代原始mass函数值(),(),…,(),如表1所示。

表1 替代原始mass函数值后的mass函数值
应用Dempster合成规则,将mass函数值合成-1次(当系统中原始证据有个时),最终得到第-1次融合的结果为′()⊕′()⊕…⊕′(),证据融合结果如表2所示。

表2 证据融合结果
根据最终证据融合结果的3个mass函数值′123…()、′123…()、′123…(),进行证据融合结果分析。
1.4 算法
假设收集到的一组原始证据源为={,,…,},对应的mass函数为={,,…,}。在收集到个证据后,通过算法计算生成融合结果,为决策提供支持。算法1描述了多个证据的加权融合方法。如算法1所示,第1~7行解释了如何计算证据之间的Lance距离,并为个证据构建Lance距离矩阵。第8~15行解释了如何度量个证据的可信度。第16~19行解释了如何计算个证据的信度熵大小。第20~23行表示如何度量个证据的不确定度。第24~27行说明了如何确定个证据的融合权重。第28~31行展示了如何对个证据的融合权重进行归一化。第32~33行描述了如何根据个证据确定修正后的证据。第34~37行描述了如何生成融合结果。

算法1 基于Lance距离和信度熵的多源冲突证据融合算法输入 一组原始证据源的mass函数;m={m1,m2,…,mi,mN};输出 融合结果mFus;步骤 1for i=1;i≤N do for j=1;j≤N do 通过式(1)计算证据Ei、Ej间的Lance距离dij; endend通过式(2)构造Lance距离矩阵D;步骤 2for i=1;i≤N do 通过式(3)和式(4)求得Sij;end步骤 3for i=1;i≤N do 通过式(5)计算可信度Reli;end步骤 4for i=1;i≤N do 通过式(7)和式(8)计算指数形式的信度熵Ui;end步骤 5for i=1; i≤N do 通过式(9)进行归一化后得到不确定度Unci;end步骤 6for i=1; i≤N do 通过式(10)求得依据证据可信度和不确定度确定的融合权重Wi;end步骤 7for i=1; i≤N do 通过式(11)求得归一化后的最终权重Wi;end步骤 8 通过式(12)得到修正后证据的mass函数mAvg;步骤 9for i=1;i≤N-1 do 通过式(13)得到最终融合结果mFus;end
2 算例分析结果及分析
为了验证本文提出的基于Lance距离和信度熵的冲突证据融合方法的效率和有效性,本文引用文献[20]的完整算例进行实验,并与Dempster合成规则以及改进的多种融合算法进行分析对比,并在原始证据源正常和含有冲突两种情况下对最终的融合结果进行详细分析。
2.1 原始证据源正常时的多源信息融合
假设某一系统的辨识框架为:={,,},有相互独立的5个证据、、、、,各自对应的mass函数值如表3所示。
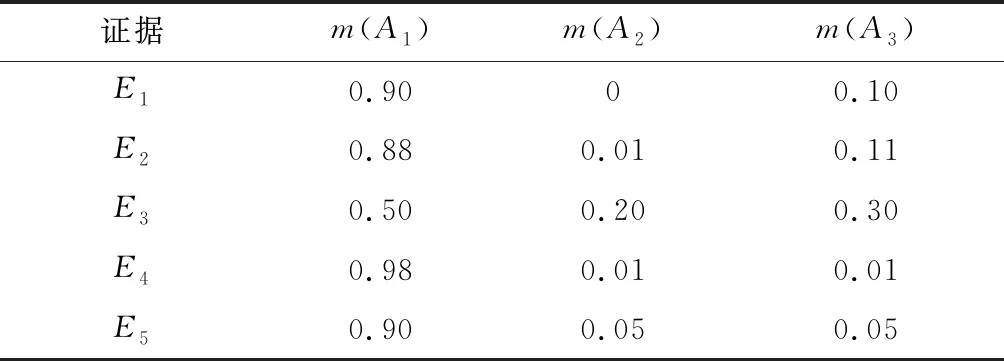
表3 原始证据源正常时mass函数值
直观分析发现,证据、、、、都支持命题,表明原始证据源正常。接下来,对本文方法进行有效性验证。
(1) 证据可信度Rel的计算
根据式(1)计算各证据间的Lance距离,则Lance距离矩阵为
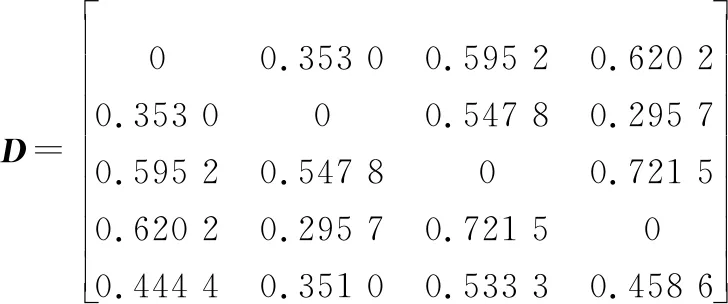
可得相似度矩阵为
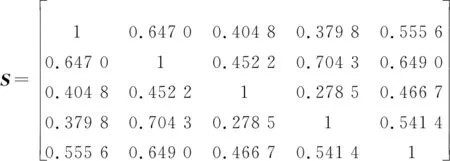
根据式(5)计算出各证据的可信度为Rel=0196 0,Rel=0239 0,Rel=0156 9,Rel=0193 6,Rel=0214 5。
(2) 证据不确定度Unc的计算
根据式(6)计算各证据的信度熵为Ed=0469 0,Ed=0579 0,Ed=1485 5,Ed=0161 4,Ed=0569 0。
根据式(8)和式(9)得到各证据的不确定度为Unc=0148 8,Unc=0166 1,Unc=0411 2,Unc=0109 4,Unc=0164 5。
(3) 证据折扣系数的计算
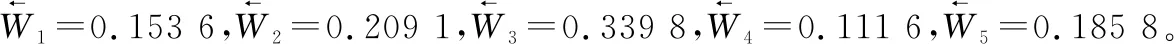
(4) 根据式(12),赋予各证据对应的折扣系数,可得到修正后证据的mass函数值为:()=0768 8,()=0080 5,()=0150 7。
(5) 进行证据融合
替换原始mass函数值后的mass函数值如表4所示。
融合-1(=5)次后,得到最终证据融合结果,如表5所示。
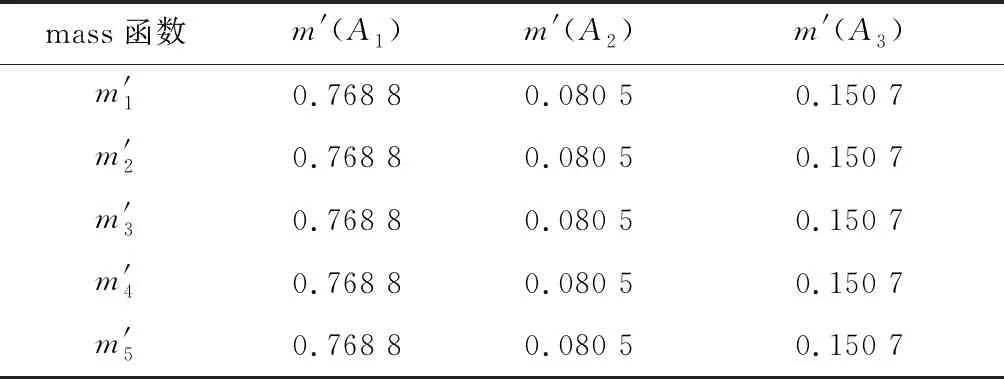
表4 替代后的mass函数值

表5 最终证据融合结果
(6) 不同证据融合方法的融合结果分析
在使用本文提出的融合方法计算得到融合结果后,再使用其他应用广泛的经典融合方法以及各种改进的融合方法分别计算相应的融合结果,并与本文方法进行对比,证据融合结果如表6所示。表6中的=∑1()()表示Dempster合成规则中两证据之间的冲突概率,其中,=1,2,…,;,=1,2,…,。在不同融合次数下,关于命题的融合结果变动情况如图1所示。下面对各方法的融合结果展开详细分析。
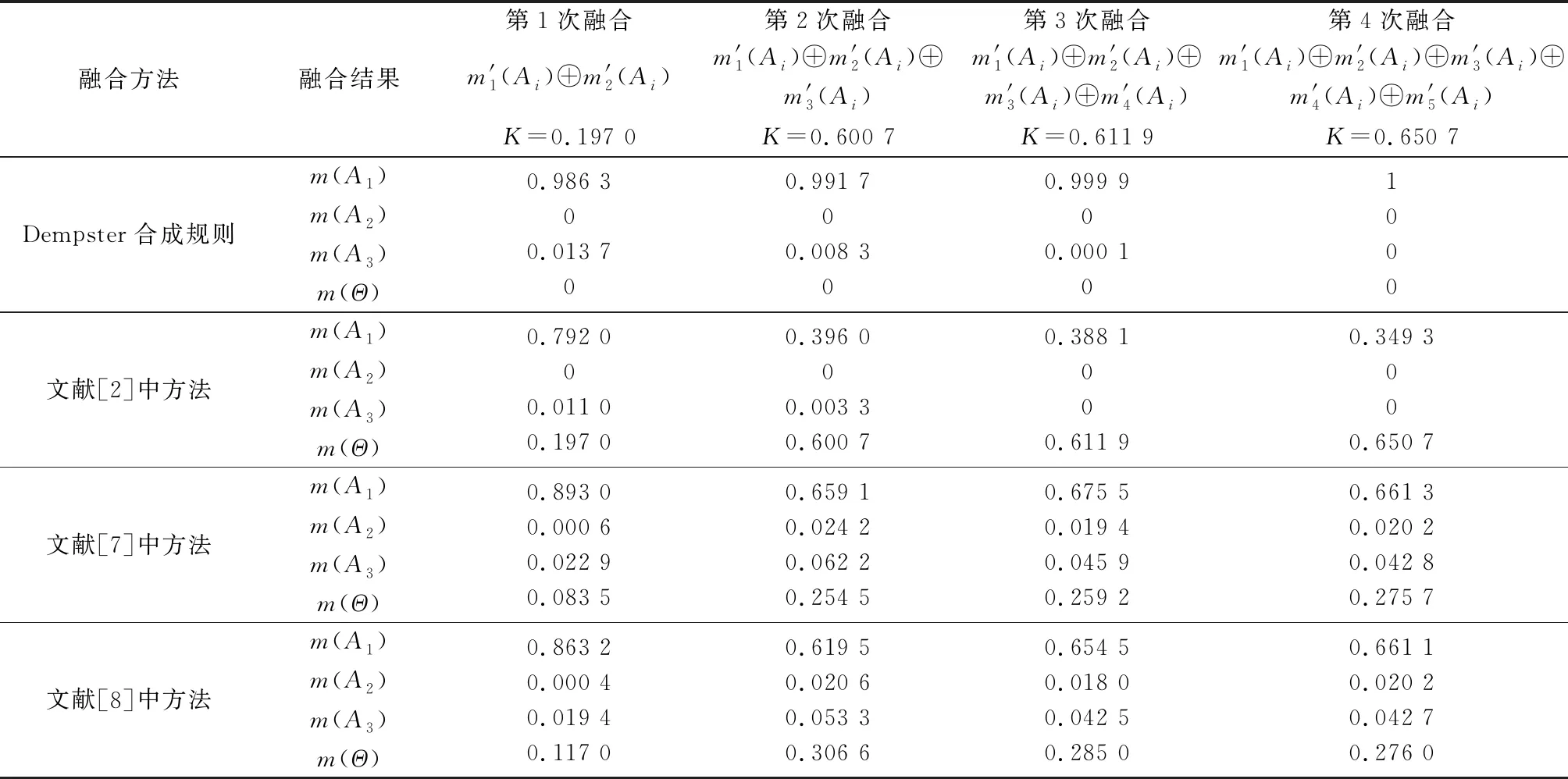
表6 原始证据源正常时不同证据融合方法的融合结果
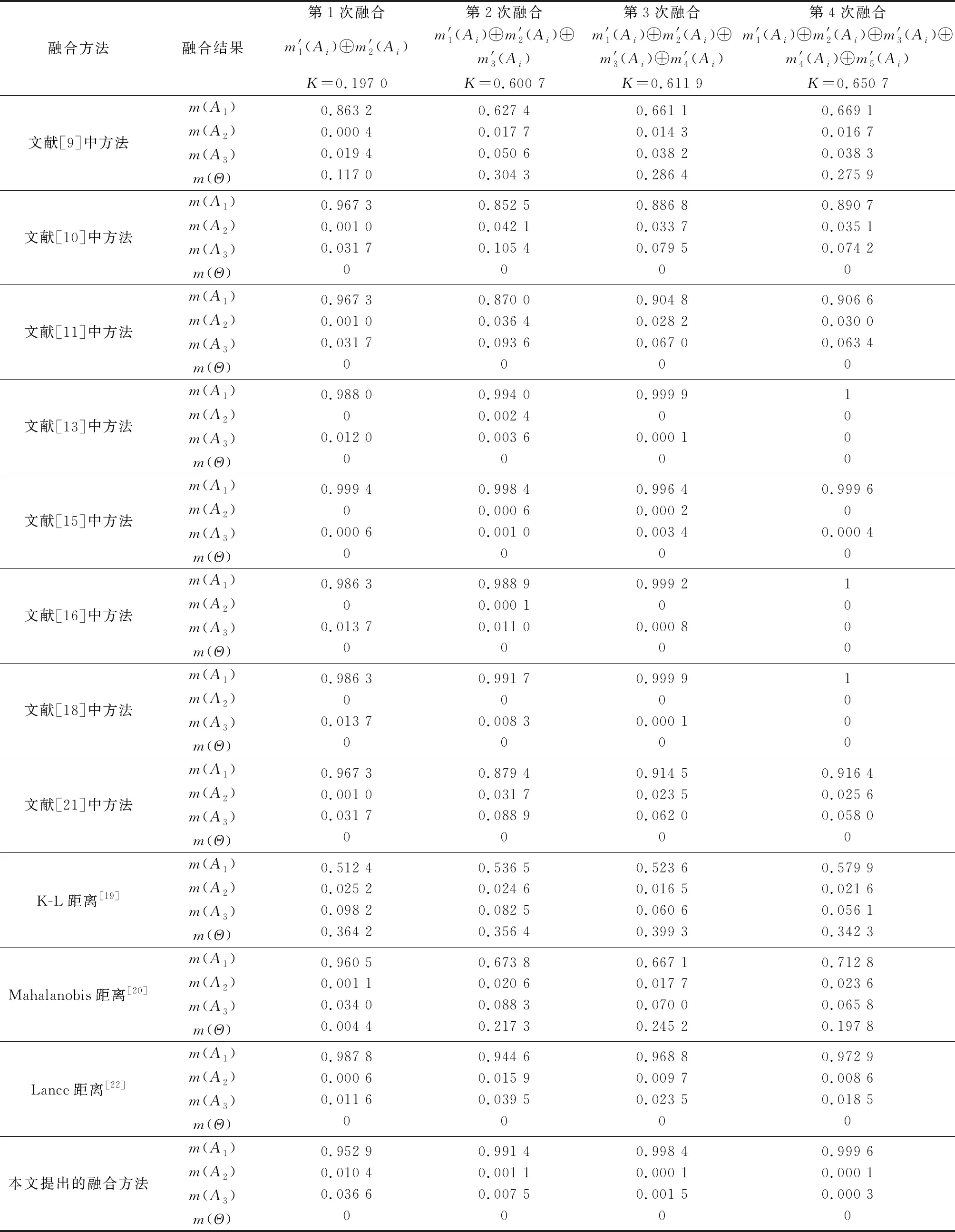
续表6

图1 原始证据源正常时不同证据融合方法在不同融合次数下命题A1的mass函数值Fig.1 Values of mass function of propositions A1 under different fusion times for different evidence fusion methods when the original evidence source is normal
观察表6和图1发现,当原始证据源正常时,随着融合次数的增加,Dempster合成规则与本文方法都能有效融合证据并识别出正确命题,且收敛速度均较快。而文献[2]和文献[7]中,随着融合次数的增加,未知项()的值也越来越大,由于未知项()来源于证据融合时存在的证据冲突问题,导致无法准确有效地对命题、、分配概率,因此将冲突赋予给()项,所以当未知项()增大时,代表了对命题、、分配概率时分配未知程度的增加。文献[2]和文献[7]中的方法最终融合结果显示()的值为0650 7和0275 7,表明两种方法的误差均较大。文献[8]和文献[9]中方法的融合结果相近,虽然二者()的值从第二次融合后开始递减,但最终融合结果显示命题的mass函数值均未达到070,融合精度仍较低。基于证据距离方面的融合方法中,通过观察在不同融合次数下命题的mass函数值变化情况和未知项()数值,发现基于Lance距离的证据融合方法在收敛速度和融合精度上,明显优于K-L距离和Mahalanobis距离。观察Dempster合成规则、文献[13]和基于修改原始证据源的方法中融合结果都出现了()=0的情况,通过分析表6中数据可知,除了证据之外,其他所有证据支持命题的概率均大于0,因此最终的融合结果必定满足()≠0。Dempster合成规则、文献[13]和文献[18]中方法最终融合结果都出现了()=1的情况,但观察表6中数据发现各证据支持命题的概率分别为090、088、050、098和090,均小于1,因此最终的融合结果必定满足()≠1,所以Dempster合成规则、文献[13]、文献[15-16]和文献[18]中方法的融合结果均不够准确和可靠。文献[10]、文献[11]和文献[21]中方法和基于Lance距离的证据融合方法的最终融合结果显示,命题的mass函数值分别为0890 7、0906 6、0916 4和0972 9,而本文方法的最终融合结果为0999 6,因此本文方法的融合精度更高。
通过上述分析可知,当原始证据源正常时,本文方法与其他大部分融合方法均能得到正确的识别结果,在收敛速度方面与Dempster合成规则相当,但由于本文方法不存在()=1、()=0和未知项()≠0的情况,因此本文方法相对更加可靠。
2.2 原始证据源含有冲突证据时的多源信息融合
为了验证本文方法对于解决冲突问题的有效性和可靠程度,在第21节证据源的基础上修改并生成一条冲突证据。
假设某一系统的辨识框架为={,,},有相互独立的5个证据、、、、,各自对应的mass函数值如表7所示。
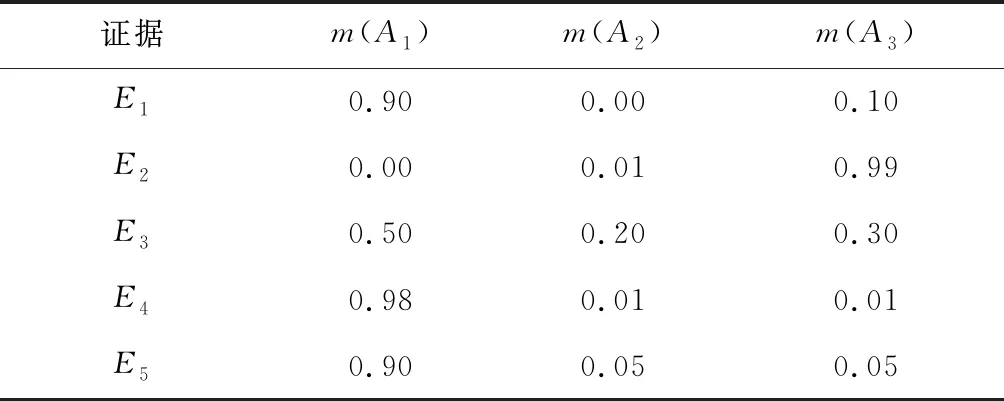
表7 原始证据源含有冲突证据的mass函数值
分析表7中数据可发现,证据、、、、都以较大概率支持命题,而证据以较大概率支持命题,显然证据是冲突证据。当原始证据源出现冲突时,应用本文方法及其他不同融合方法的融合结果如表8所示。
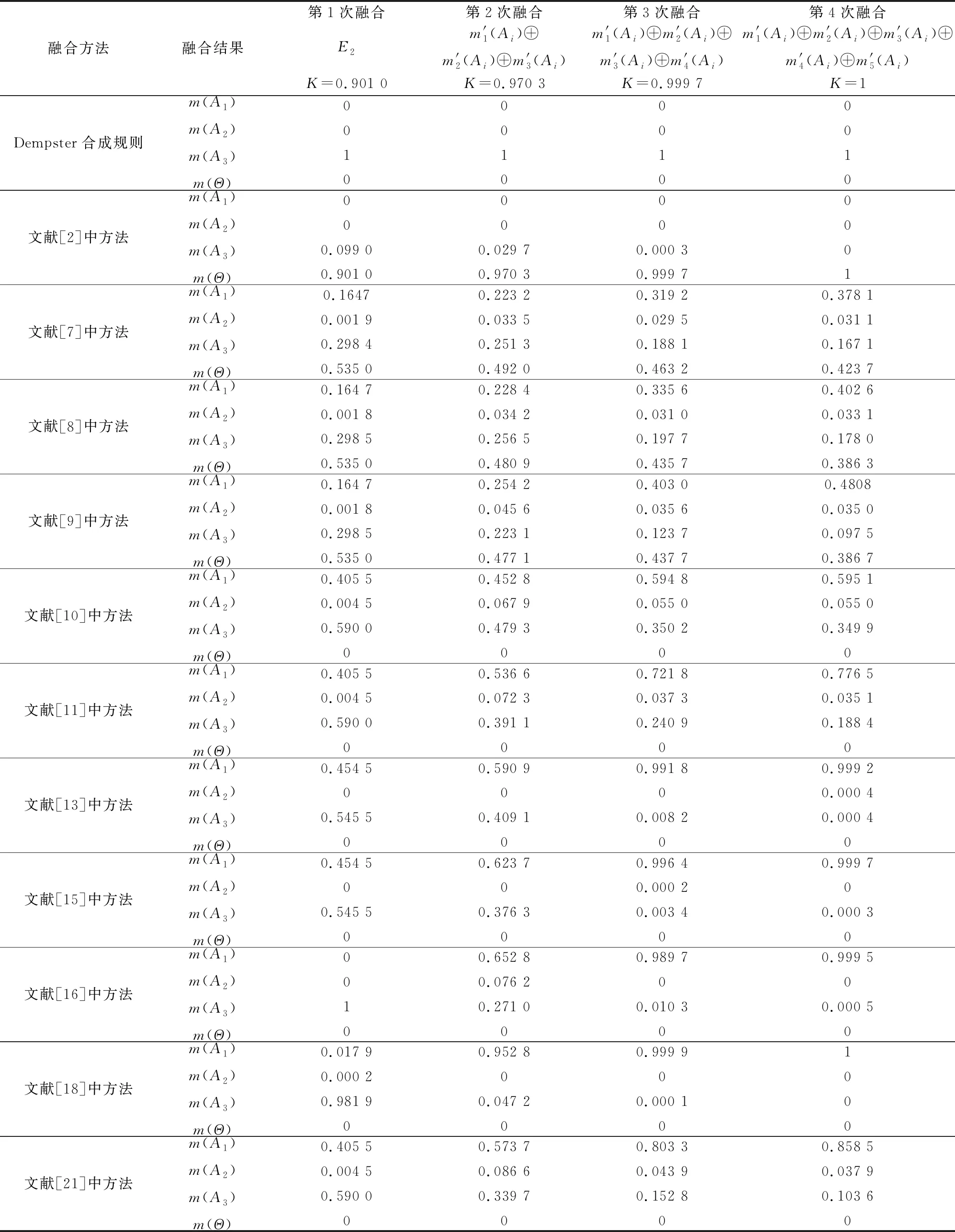
表8 原始证据源有冲突时不同证据融合方法的融合结果
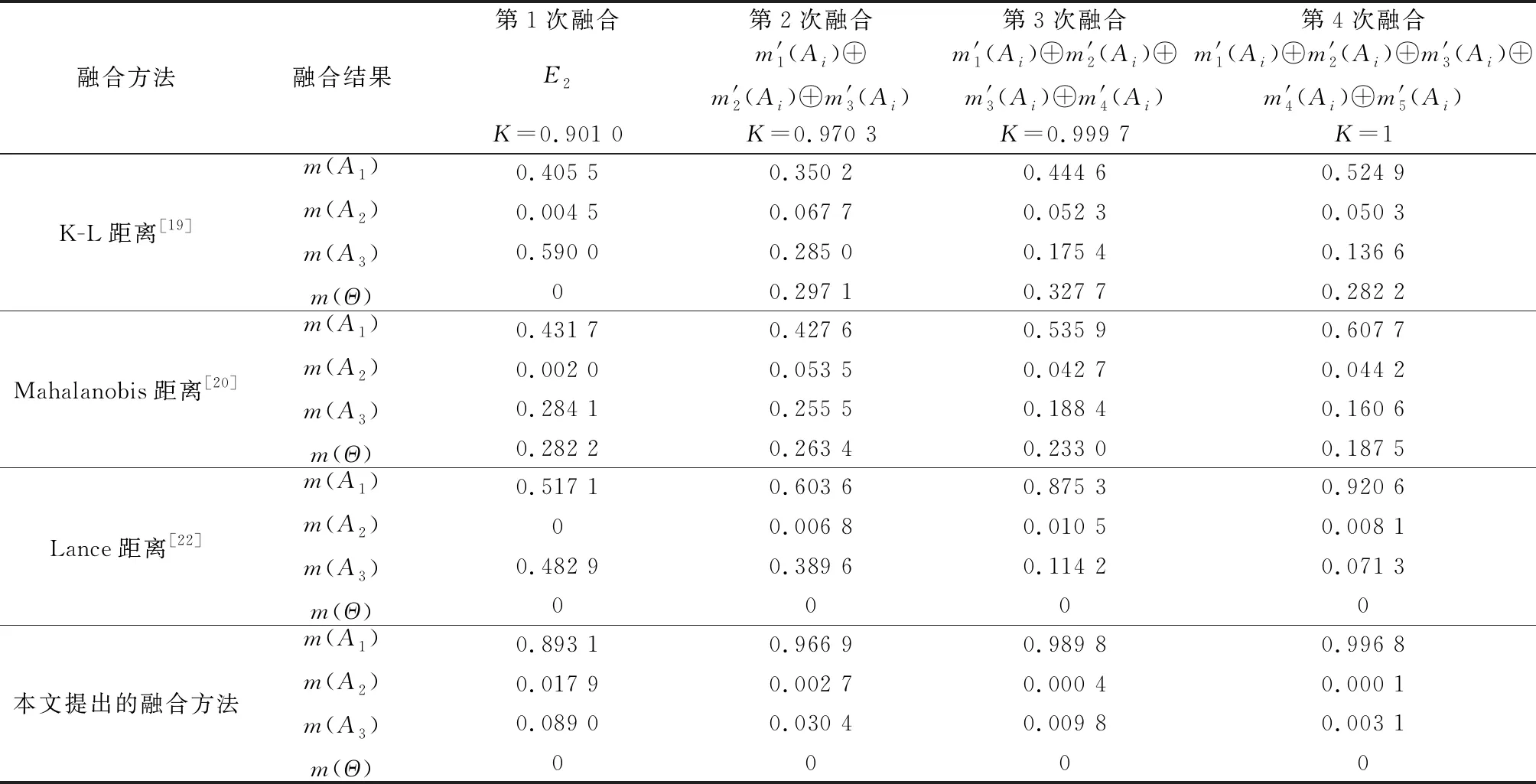
续表8
在不同融合次数下关于命题的融合结果变动情况如图2所示,下面对各方法的融合结果展开详细分析。
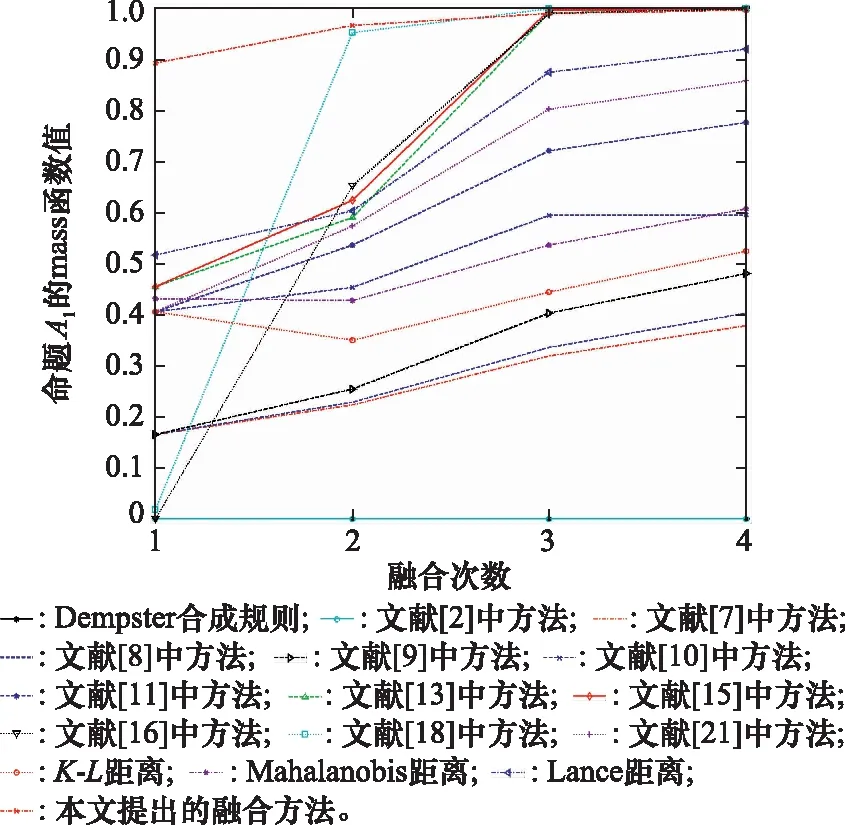
图2 有冲突时不同证据融合方法在不同融合次数下命题A1的mass函数值Fig.2 Values of mass function of propositions A1 under different fusion times of different evidence fusion methods when there is conflict
表7数据显示,原始证据源中有4个证据都支持命题,但分析表8发现,Dempster合成规则和文献[2]中方法由于证据的存在导致命题的融合结果始终为0,因此这两种方法都无法有效处理证据冲突问题。文献[7]中方法虽较能处理证据冲突问题,但其收敛速度较慢,且未知项()各次融合的值均高于04,表明证据融合时分配给未知项的概率过高,导致融合精度不够,无法有效识别出结果。文献[9]中方法在收敛速度和融合精度上均强于文献[8]中方法,主要是其融合模型合理分配了证据冲突的概率,但这两种方法的未知项()值都较大,均高于038,不利于决策。文献[10]中方法利用平均支持度作为权重,对证据冲突进行加权处理,当证据冲突时,其收敛速度受到一定影响,在前两次融合时,文献[10]最终融合结果中命题的mass函数值较为接近命题的mass函数值,甚至命题的值高于命题的值,显然悖于原始证据源支持命题的结论。文献[11]中方法虽能得到合理的融合结果,但其最终融合结果中命题的mass函数值为0776 5,融合精度仍略低。文献[13]中方法在前两次融合时,命题和的mass函数值接近,在第3次融合时才可靠地识别出命题,并且在前3次融合时均出现判决()=0的情况,与原始证据源支持命题的概率不为0的结论相悖。文献[15]与文献[13]中方法融合结果相近,在前两次融合时精度较低,且第1次、第2次和第4次融合时均出现判决()=0的情况。文献[16]中方法虽最终融合结果能正确识别命题,但在第1次、第3次和第4次融合时均出现判决()=0的情况且其收敛速度较慢。文献[18]中方法第1次融合结果识别的命题为,而第2次和第3次融合时均出现判决()=0的情况,在最终融合时命题的mass函数值达到1,表明此方法较为冒进。而文献[21]中方法虽然未出现判决()=0的情况,但其融合精度和收敛速度都不如本文提出的方法。在基于证据距离的融合方法中,基于K-L距离和Mahalanobis距离的证据融合方法中出现未知项()≠0,且最终融合结果中支持命题的概率均低于基于Lance距离的证据融合方法。在基于Lance距离的证据融合方法中,命题的mass函数值从第1次融合的结果为0517 1,到最终融合的结果为0920 6,而本文方法中,命题的mass函数值从第一次融合的结果为0893 1,到最终融合的结果为0996 8,对比表明本文方法收敛速度更快、融合精度更高。
基于以上分析,当原始证据源有冲突时,由于本文提出的基于Lance距离和信度熵的冲突证据融合方法充分考虑了证据的可信度、不确定度等因素,故能够较大程度地减少冲突证据造成的不利影响,能更有效地处理证据冲突问题,且能在较少证据的情况下就融合得到正确结果。譬如本文方法融合前两个证据时关于命题的mass函数值已达到0893 1,在所有16种方法中最高,可以更快地分辨出命题。同时从算例分析结果科研发现,当融合次数增加时,证据对命题支持度的增加,其mass函数值稳定提高,表明本文方法在证据融合过程中愈加可靠。
3 结 论
本文针对证据融合过程中出现的证据冲突问题展开了详细研究,提出了一种基于Lance距离和信度熵的冲突证据融合方法。首先,通过计算Lance距离来度量各证据的可信度,并通过计算信度熵来度量各证据的不确定度。其次,结合各证据的可信度和不确定度来确定最终折扣系数,并通过最终折扣系数修正原始证据。最后,采用Dempster合成规则计算得到最终融合结果。通过结合算例对比分析,结果表明本文提出的融合方法性能更优,能够更好地处理证据冲突问题。
猜你喜欢
环球时报(2022-04-16)2022-04-16 14:38:15
世界科学技术-中医药现代化(2021年7期)2021-11-04 08:12:00
井冈教育(2020年6期)2020-12-14 03:04:32
少年博览·小学低年级(2016年10期)2016-11-24 06:46:56
管理现代化(2016年6期)2016-01-23 02:10:58
上海体育学院学报(2015年6期)2015-12-25 02:04:38
中国康复理论与实践(2015年7期)2015-05-09 08:31:45
浙江人大(2014年6期)2014-03-20 16:20:40
中国火炬(2012年3期)2012-07-25 10:34:06
对联(2011年24期)2011-11-20 02:42:38
