
基于迁移学习和注意力机制的伪装图像分割
2022-02-23 07:48:58王伦文朱敬成
系统工程与电子技术 2022年2期
吴 涛, 王伦文, 朱敬成
(国防科技大学电子对抗学院, 安徽 合肥 230037)
0 引 言
自然界中,伪装是一些动植物赖以生存的基本技能。变色龙被认为是自然界里的伪装高手;枯叶蝶在处于危险中时,会将自己藏于植物叶片中,宛似一片干枯的叶子。许多动物为了躲避捕食,会将自己很好地融入于周围的环境中,使之不易被察觉和发现,从而躲避被捕食的命运。颜色、整体形状和纹理,是伪装的重要特征,利用好这些特征,就能实现与周围环境的有效融合。伪装是自然界动植物能够长久安全生存的有力武器,被用来说明自然选择的力量。第二次世界大战期间,英军狙击手将颜料涂在作训服上,实现自己的伪装。二战后,德国人首先设计并研制出一种迷彩装饰衣,在作战中发挥了较好的伪装效果。作战人员伪装、作战装备伪装愈来成为军事中不可或缺的一环,也是非常关键的一环。
对伪装的研究由来已久,但大多是对伪装产生的机理进行研究,与基于深度学习的目标检测和分割研究不同,两者的侧重点不一样。在计算机视觉领域,伪装研究,就是从背景中识别出伪装目标的存在,对图像进行逐像素的分类标记,并识别出每个分割区域的语义信息,具有重要的理论意义和实践价值。例如,在医学检测中,对病变器官的分割等,虽然不是属于直接的伪装范畴,但是与伪装图像在本质上有很多相似之处;在稀有物种检测和发掘中,以及军事上都有着巨大的应用价值。
语义分割的方法有很多,传统的目标检测分割算法包括基于区域的分割方法、基于边缘检测的分割方法、基于阈值的分割方法等。传统的分割算法虽然计算不复杂、效率高,但是选取的特征较为简单,大多是一些浅层的特征,缺乏对样本数据特征的深入挖掘,分割效果往往不是十分理想;细节信息捕捉不够,分割结果较为模糊;传统分割方法还有一个较为明显的局限性,即对噪声十分敏感,因此传统分割方法并不适用于伪装目标的研究。随着深度学习的不断发展,利用卷积神经网络进行目标分割的研究越来越多,并取得较好的分割效果。Carreira等人在2012年提出了采用CPMC(constrained parametric minCut)进行候选区域划分的提议,取得了较好的分割结果。后续的Girshick等人、Hariharan等人提出了相应的分割算法或在前者工作上进行了改进提高。由于基于候选区域的提议分割结果缺少空间信息,小物体的分割效果不理想,为很好地解决这个问题,Long等人提出了完全卷积网络(fully convolutional networks,FCN)分割网络模型,语义分割精度得到了很好地提升;在FCN基础上,许多对称分割网络被提出来,例如SegNet、UNet等。
1 算法描述
本文提出的算法包括2个框架1个模块:① 利用视觉几何组(visual geometry group,VGG)迁移网络进行模型的前半部分训练,去掉全连接层的VGG网络的下采样部分与Unet的编码网络进行了有效衔接与对应;网络的后半部分是Unet的上采样过程,恢复原始图像尺寸并进行预测;② 嵌入了有效通道注意力(effective channel attention,ECA)机制模块,对提取到的有效特征进行加权处理,提高有效特征在网络中的权重值。
1.1 UNet网络结构
UNet是一种十分对称的端到端的分割算法,包含了编解码2个模块。编码阶段是一段连续的下采样过程,用于不断提取更深层次的特征信息。下采样过程主要是通过3×3的卷积层和2×2的最大池化层来实现的,图像的尺寸不断被压缩,特征通道数不断增加,提取到的特征更抽象,更丰富,对目标的表达能力更强,更具有鲁棒性能。但是,由于对图像的不断压缩,许多目标的细节信息存在丢失的问题,所以在解码阶段,通过上采样或反卷积的手段,逐像素还原原图像精度,恢复细节信息。图1展示了UNet的网络结构,分为编码和解码两个部分,左侧部分用于编码,右侧部分用于解码。
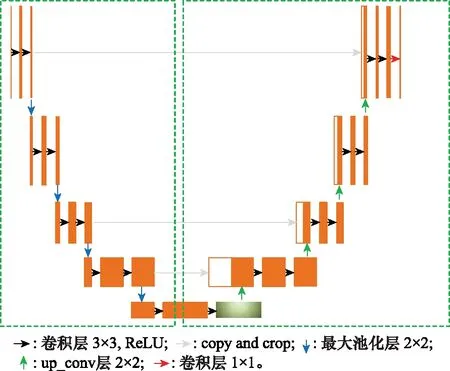
图1 UNet网络模型结构Fig.1 Structure of UNet model
1.2 迁移学习
迁移学习在大量的实验中被证明是一种有效的模型改进方式,尤其是当目标数据不足时,迁移的方式能够在小样本的情况下获得比较好的训练结果,提升模型的训练精度和鲁棒性能。迁移学习是模型训练效果的一种泛化,文献[12]从模型复杂性和学习算法的稳定出发,导出了模型泛化的理论边界。
对于假设空间,定义对称差假设空间Δ为
Δ={()⊕′():,′∈}
(1)
式中:⊕表示异或函数。则在不同分布,之间的对称差距离定义为

(2)
式中:Δ是空间的子集合。
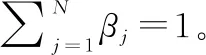
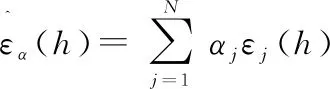
(3)
则最小风险误差为

(4)
式中:是假设空间。由此,可得出在较为理想的情况下迁移学习的理论边界:

(5)
式(5)表明迁移学习泛化边界函数收敛,存在上边界,说明迁移学习应用到模型训练中是可行的且有效的。
1.3 ECA注意力机制
注意力机制被广泛用在自然语言处理、计算机视觉等任务中,是一种能提高特征权重的有效手段,在许多实验中都表现出较好的性能。注意力是模仿人类大脑处理大量信息时的一种机制,即关注重点区域,而忽视不重要的部分,这样做的目的就是增加了有用特征的权重,从而获得更多待分割目标的细节信息,提高分割精度。
ECA_Net提供了一种十分有效的产生特征权重的方式,在不增加模型复杂度的情况下,能够获得十分明显的性能增益。与SENet等其他注意力机制不同的是,ECA采用不降维的方式产生权重,避免降维对利用注意力机制学习特征十分重要;ECA利用1×1的卷积实现局部交叉通道交互策略,卷积核的大小为,代表了局部通道交互的覆盖率,这是一个超参数,但ECA实现了对的自适应调节。ECA网络模块如图2所示。

图2 ECA注意力机制模块Fig.2 ECA attention mechanism module
从图2可以看出,ECA是一种通道维度上生成特征权重的方式,首先将输入的特征图进行全局自适应平均池化,与SENet不同之处在于,SENet会先进行降维操作,降低通道数量为原来的1/。ECA避免了降维这一操作,直接生成一组特征向量:

算法 1 生成有效通道注意力机制的权重向量输入 维度为W×H×C的张量 输出 1×1×C维度的权重向量W步骤 1 对张量x进行全局平均池化得到1×1×C的向量W=Adaptive Avg{Pool2d}(1)步骤 2 设定自适应卷积核大小为k_size=t if t%2 else t+1步骤 3 对该向量进行一维卷积,得到交互后的向量Wconv=Conv1d(1,1,k_size,padding=(k_size-1)∥2)W=conv(W)步骤 4 将向量W经过激活函数sigmoid得到权重值yW=sigmoid(W)步骤 5 将生成的权重值加权到原有的张量x中,得到新的张量return x×W.expand_as(x)
ECA利用1×1的卷积实现局部通道之间的交互,卷积核的大小_size代表了交互的覆盖率。这是一个超参数,但ECA实现了对的自适应调节。
=()
(6)
对的构造中,有两种较为常见的方式:

(7)
在第一种方式中采用的是对角矩阵的方式,第二种则是一个完全矩阵。这两种方式的区别在于第二种矩阵权重之间存在交互,采用对角矩阵的方式则权重之间相对独立。如果卷积核大小设置为,则经过卷积之后得到的向量为

(8)
2 网络结构
2.1 迁移学习网络
深度学习需要大量高质量的标注数据,可以通过迁移学习的方式,在已有的大规模优质数据集上进行预训练,将预训练的结果迁移到待分割的网络中,可以实现特征迁移和参数共享,提高模型的泛化能力,降低训练结果对数据集的依赖,减少训练成本,并通过微调的方式,将部分网络层加入到新的网络中进行训练,以更好适应新网络特性。
观察VGG网络结构可知,VGG系列网络与Unet网络具有十分类似的上采样结构,可以不改变Unet网络的基本结构而进行网络的迁移学习。VGG系列包含了VGG11、VGG13、VGG16和VGG19等。VGG相较于AlexNet,采用了连续的小卷积核代替大卷积核,大大减少了训练参数,保证了在增加网络深度时仍具有很好的学习能力。VGG网络结构如表1所示(不包含全连接层)。

表1 VGG系列模型各层结构及参数
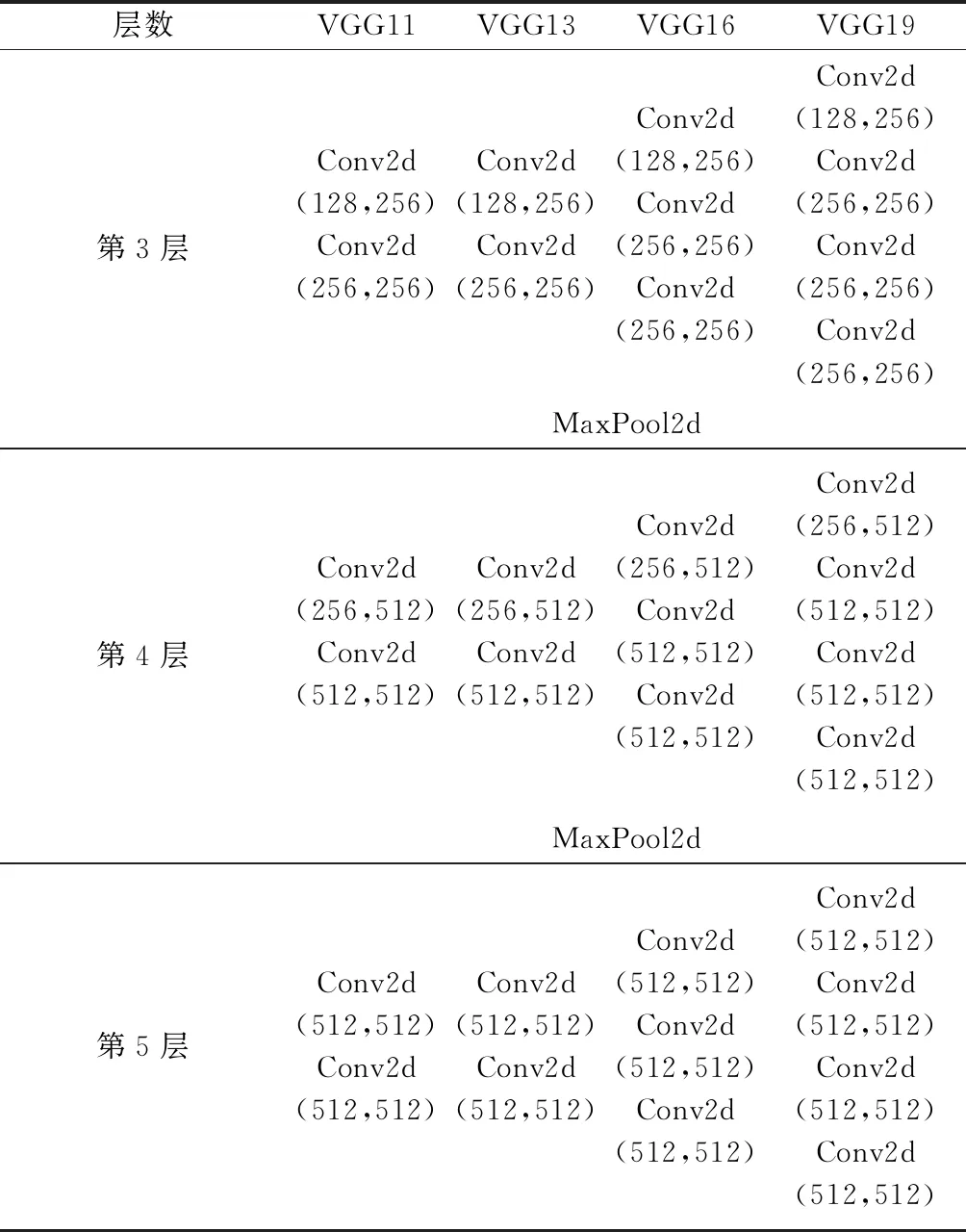
续表1
2.2 模型改进
由于伪装目标特征模糊,与背景融合度较高,目前运用深度神经网络进行伪装图像分割的研究较少,伪装图像分割任务的准确程度还不是很高。本文将经典的基于深度卷积神经网络的算法在伪装图像分割中进行了诸多尝试,并对其中的UNet模型进行了相关改进,以适应伪装目标分割任务,提高分割精度,如图3所示。
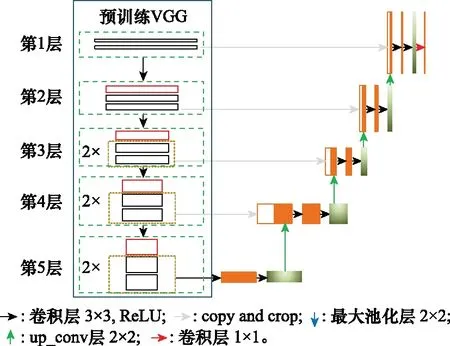
图3 改进后的模型Fig.3 Improved model
本文对于UNet的改进点在于:
(1) 针对伪装目标特征模糊的问题,本文在网络编码-解码阶段均引入了有效通道注意力ECA,将其嵌入到UNet的采样过程中,贯穿模型训练全过程,使模型在训练过程中能始终关注目标区域,很大程度上克服了伪装图像因其目标“被伪装”而带来分割上的困难;
(2) 利用在大型数据集ImageNet上预训练的VGG模型,将其训练参数和训练特征迁移到伪装目标分割网络,实现特征迁移和参数共享,提高网络的泛化能力,减小模型对训练样本的依赖,降低训练成本。
3 实验过程及结果分析
3.1 实验条件设置和数据集
实验计算机配置如下:Intel(R) Core(TM) i7-9700 CPU @3.00 GHz, GeForce 1060Ti GPU (6 GB显存) 的Windows操作系统。实验采用pytorch架构,在训练过程中,采用AdamW优化器进行优化,采用FocalLoss损失函数。具体实验细节如表2所示。

表2 实验参数
本次实验采用公开的COD10K数据集,该数据集是专门针对伪装目标研究而制定的,包含了海洋生物、陆地生物、两栖动物以及飞禽等共69个类别,物种丰富,涵盖范围广泛;其中训练数据集6 000张,测试数据集4 000张,为提高算法模型的鲁棒性,数据集中还包括非伪装目标数据4 934张。表3和图4展示了训练集和测试集中伪装目标和非伪装目标的统计情况。

表3 训练和测试数据集统计信息

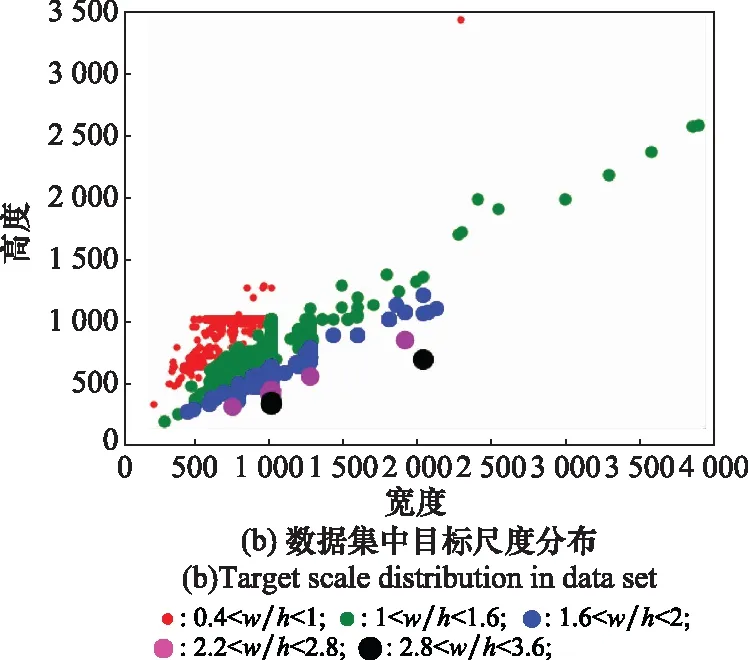
图4 数据集种类与尺度大小分布Fig.4 Data set types and scale size distribution
同时,算法还在其他2个公开数据集上进行测试。其中CHAMELEON数据集共有图片76张,CAMO数据集共有图片2 500张。图5是伪装数据的部分展示。

图5 部分伪装数据集Fig.5 Part of camouflage datasets
3.2 FocalLoss损失函数
FocalLoss不同于交叉熵损失,通过添加系数调节难易样本的损失权重。在类别不平衡问题中,交叉熵损失对所有样本赋予相同的关注,使得一些难分、错分的样本很难被挖掘出来。FocalLoss通过添加调节系数,降低易分样本的权重,提高难分、错分样本的损失值比重,使得模型在训练时对这类样本赋予更多的关注。伪装目标在检测过程中,由于特征模糊,难分错分的概率非常大,因此实验中采用FocalLoss作为损失函数,对难例样本进行挖掘。
=-(1-)log
(9)
式中:和是权重调节系数,通过改变调节系数可增加对难挖掘样本的关注程度。表示分类概率,越大,表示样本被正确分类的概率越大,1-就会越小,所以和对权重起到了很好的调节作用,可以控制样本分类比重。
3.3 评价指标
为了更好对比不同算法之间的性能,对改进后的模型进行合理正确的评估,我们在CHAMELEON、CAMO、COD10K3个数据集下采用以下指标进行衡量。
混淆矩阵:混淆矩阵是具有特定布局的统计类表格(见表4),所有其他评价指标都是基于混淆矩阵基础上的衍生。

表4 混淆矩阵
TP:真阳性,表示标签是伪装图像,且预测为伪装图像的像素点数;
FP:假阳性,表示标签是背景,但预测为伪装图像的像素点数;
TN:真阴性,表示标签是背景,且预测为背景的像素点数;
FN:假阴性,表示标签是伪装图像,但预测为背景的像素点数。
可以计算出,TP+TN是表示正确分类的像素总数量,TP+FN表示图像像素的总数量,FP+TN表示背景像素的总数量。通过以上计算可以得出以下衍生指标:
像素精度(pixel accuracy,PA):像素精度是衡量分割效果的最直接的衡量指标,代表的含义是分类正确的像素数量之和在所有像素数量中的占比。像素精度一定程度上能够反映出衡量的好坏,但存在一个明显的问题,当图像中正负样本极不均衡,负样本的数量远远大于正样本数量时,就会出现在完全预测为负样本的情况下有很高的像素精度值的情况,所以PA存在很高的下限值。计算公式如下:

(10)
也可以写成如下形式:

(11)

敏感度(Sensitivity):在分割任务中,可以用敏感度表示召回率,两者具有相同的含义。

(12)
重合率(Dice):重合率是衡量分割性能好坏的合理有效的指标,是两个物体重合度的一种测量,表示两个物体相交的面积占总面积的比值,是交并比(intersection over union,IoU)的另一种表达形式。

(13)
为了保证Dice的值域在0到1之间,添加了调节系数2,计算后得到的结果就能确保落在0到1之间。
本文通过上述指标对比分析所提算法预测的值与真实标签值之间的差异,上述指标值愈大,预测的精度越高,性能越好。
3.4 实验及结果分析
3.4.1 Canny检测算法
本文首先基于传统算法—Canny算法对伪装目标进行检测。在给定的伪装图像数据集中,部分显著图像轮廓十分清晰,与背景的区分度比较大,使用传统的边缘检测算法能够取得比较好的检测效果。首先对图像进行灰度化处理,得到原图的灰度图;然后通过降噪处理,传统的检测算法受噪声影响普遍较大,所以为了得到较好的检测处理效果,先需要进行降噪处理;接着,检测图像的边缘,图像的边缘是图像中梯度下降最快的地方;最后通过设置不同的阈值对检测的像素进行阈值筛选,低阈值取50,高阈值取150,筛选出图像中目标的强边缘像素,即大于高阈值的边缘像素,对低于低阈值的边缘像素进行剔除。对显著和伪装目标的分割结果如图6所示。
从图6中可以看到,Canny算法对显著图像的检测效果十分理想,能够十分清晰地勾勒出目标的轮廓;但对于伪装目标而言,传统的算法难以有效发挥其检测性能,由于伪装目标与周围环境高度融合,背景噪声大,特征模糊难以提取,Canny算法并不能很好地提取目标的位置信息和轮廓信息,说明了伪装目标相对于显著目标,检测难度更大。

图6 传统算法检测显著与伪装目标效果对比Fig.6 Traditional algorithm detecting salient and camouflaged targets
3.4.2 γ取值对结果的影响
FocalLoss中不同值代表了赋予样本损失值不同的权重, 值越大,表明对困难样本的关注程度更高,本文探究了不同的γ对伪装目标分割精度的影响。
从表5和图7中可以看出,当在训练过程中提高困难样本的权重时,能够一定程度上提高模型对伪装目标的分割效果。相较于其他数值,当γ=2时分割效果较好。

表5 不同γ在测试集上的定量评测结果

图7 不同γ对于分割结果的影响Fig.7 Impact of different γ on the segmentation results
3.4.3 改进模型的实验结果
同时,对VGG系列VGG11、VGG13、VGG16和VGG19等4种不同深度的网络进行了实验,这4种网络都在大型数据集ImageNet上进行了预训练,对这4种网络进行迁移学习,共享其参数和特征。实验对比结果如表6所示。
实验结果表明,在这4种VGG模型中,19层的模型结构对伪装图像的分割效果优于其他模型,如图8所示。
在上述对比结果下,本文模型选用了权重系数γ为2,迁移模型选用VGG19,并在CHAMELEON、CAMO、COD10K 3个数据集上分别进行了验证,与FCN8s、SegNet、UNet模型对PA、Dice和Sensitivity指标值进行了定量对比分析。实验结果如表7和图9所示。

表6 不同迁移模型的定量评测结果

图8 不同的迁移模型对分割结果的影响Fig.8 Effect of different migration models on segmentation results

表7 不同模型的定量评测结果

图9 不同模型在3个验证数据集上的Dice和SensitivityFig.9 Dice and Sensitivity of different models on three validation datasets
从表7和图9中可以看出,改进后的模型相较于改进前的模型,在性能上具有大幅度提升,相较于其他模型,部分数据集上具有较大提升,说明了改进后的模型的有效性。图10和图11展示了不同模型的分割结果图,改进后的模型具有更好的分割效果,分割结果的细节信息更加明显。

图10 不同模型的分割结果对比Fig.10 Comparison of segmentation results of different models

图11选择的部分分割结果Fig.11 Selected partial segmentation results
4 结 论
基于UNet基础模型,提出了一种结合迁移学习和注意力机制的UNet分割方法。在伪装目标分割研究中,迁移学习的方式,能够实现参数共享和特征迁移,减小训练结果对样本数据的依赖,降低训练成本;在网络的上采样过程中嵌入注意力机制,能够提高有效特征权重,提高模型分割精度。改进后的模型在一定程度上能够实现对伪装目标的分割。通过对实验数据的分析得知,与改进前的UNet相比,在CAMO、CHAMELEON和COD10K上进行验证,改进后的模型在Dice和Sensitivity指标上有了显著提升。
猜你喜欢
艺术家(2023年8期)2023-11-02 02:05:28
小哥白尼(军事科学)(2022年2期)2022-05-25 13:19:30
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
中学生数理化·高一版(2021年2期)2021-03-19 08:32:00
红领巾·萌芽(2019年8期)2019-08-27 15:30:15
电子制作(2019年11期)2019-07-04 00:34:38
知识经济·中国直销(2018年8期)2018-08-23 09:16:16
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
数学学习与研究(2017年3期)2017-03-09 18:12:42
CHIP新电脑(2016年3期)2016-03-10 14:22:03
