
多损失融合的小样本光伏组件隐裂检测算法
2022-02-23 10:03:56那峙雄谢祥颖3来广志
计算机与生活 2022年2期
那峙雄,樊 涛,孙 涛,谢祥颖3,,来广志
1.国网电子商务有限公司,北京100053
2.国家电网有限公司,北京100031
3.北京航空航天大学,北京100191
随着我国“碳达峰、碳中和”的政策不断推进,清洁能源的发展迎来了快速增长。光伏发电与传统发电技术相比,更加灵活且环保,尤其在西北地区地广人稀,光照条件充足,给光伏发电的推广应用提供了良好的环境。为提高光伏电池的发电能力,在实际应用中,常将一定数量的单片光伏电池以串、并联的方式进行组合,形成光伏组件。然而光伏组件大规模生产过程中易产生隐裂,在长期发电过程中,组件隐裂会对发电性能造成影响,从而降低组件的使用寿命。因此在生产过程中对光伏组件进行隐裂检测是提高光伏产品质量的关键环节之一。常用的隐裂检测方法依靠于电致发光(electroluminescence,EL)配合人眼观测,EL 图像能够显示组件表面的细微缺陷,但是这种方法需要投入大量人力,并且具有一定主观性。随着光伏发电产业规模的扩大,人工检测方法逐渐难以匹配生产速度和需求,各大光伏组件生产厂商也急需对光伏隐裂检测进行自动化升级。
如今以深度学习为代表的人工智能技术快速发展,计算机视觉中的图像处理技术已经应用在各个领域,在电池片生产的隐裂检测阶段引入深度学习手段能够降低人力成本,提高生产效率。基于深度学习的检测模型需要大规模数据的支持,少量的数据提供的经验十分有限,可能导致模型训练不充分导致过拟合现象,降低检测精度。但是在实际生产线中,含有隐裂的样本较少,收集并标注组件图像需要投入大量的人力成本,工业生产场景下不易满足基于大规模数据集的深度模型训练条件。另一方面,光伏产品更新迭代迅速,不同产品外观结构均有所差异,已有模型未必适合新型产品,而针对每批产品重复训练模型也会浪费大部分历史经验。
针对上述应用需求,本文面向光伏单晶组件的隐裂检测问题,提出了多损失融合的小样本光伏组件隐裂检测算法。在特征提取网络引入了Transformer 的多头注意力机制,针对数据集的特点设计了隐式分类损失衡量方法,并在训练阶段与标签平滑后的交叉熵损失、三元组损失相融合,从不同角度优化特征提取从而丰富隐裂语义信息。此外,本文通过衡量待测特征与少量样本参照特征间的相似度完成少量样本支持下的隐裂检测。该方法可以使模型适应训练集组件批次和隐裂的多样性,减少对无关因素的关注,提取分辨隐裂的关键特征。本文的研究内容可概括为以下三点:
(1)构建了基于小样本学习的隐裂检测框架,能够减少样本收集和标记的开销,缓解缺陷样本稀少的问题。
(2)针对电池片上隐裂分布不规则的问题,引入了基于特征的自注意力机制,增强模型的表达能力,保证模型在不同产品间的鲁棒性。
(3)设计了多损失融合约束模型训练的策略,使得模型从不同类型的电池片中提取隐裂的共性特征,充分利用历史采集数据。
基于光伏组件公开数据集与产线数据集,本文方法的实验结果能够优于其他小样本学习方法,验证了本文方法的有效性。
1 相关工作
在光伏组件隐裂检测问题中,由于隐裂细微且出现不规律,采用人工判别需要耗费大量的人力。利用计算机视觉技术实现隐裂自动检测能够有效降低人力开销,提高检测效率。实现隐裂智能检测的方法主要包括传统的图像处理方法和基于深度学习的方法两方面。传统图像处理方法中手工设计的特征灵活性较低,对数据集的特点依赖性较强。随着人工智能深度学习的进步,基于深度学习的检测和分类方法在光伏电池隐裂检测领域也得到了应用,相比于传统的特征提取方法能够取得更高的检测准确率。Deitsch 等将VGG19(visual geometry group)的两个全连接层替换为全局平均池化,通过最小化均方误差构建了基于深度卷积神经网络的隐裂检测模型。Chen 等提出了一种两阶段的深度检测方法,首先将原始EL 图像按大小相等的网格切分为几个局部,利用基于HAAR 小波特征和Canny 边缘特征的方法提取可能存在隐裂的候选区域,将上述候选区域作为第二阶段的输入,通过卷积神经网络进行监督训练。Zhang 等利用深层神经网络可以学习更多的可转移特征以实现域自适应,将迁移学习引入到了隐裂检测任务中,实现单晶组件的隐裂检测任务到多晶组件的迁移。Ji 等提出了一种自标记算法对EL 图像进行二分,首先通过聚类头给图像设初始标签,并以ResNet50为基础架构建立随机初始化的表征学习模型,然后通过Sinkhorn-Knopp 算法衡量图像和标签之间的距离,进而给图像分配标签,实现聚类。该方法能够充分利用大量未标记数据,减少人工标记的成本。
使用深度学习技术能够检测光伏组件的隐裂缺陷,然而深度模型对数据量要求较高,在少量样本上易产生过拟合问题。在工业、医药等领域,收集并标记大量样本比较困难,耗时耗力,需求促进发展,近年来小样本学习方法支持在缺乏大量数据训练的基础上实现对新物体归类,在有限有监督数据集上仍能取得良好的效果。
一些小样本学习方法还提出了训练模式、网络结构和优化方法等方面的解决方案。Snell 等提出了原型网络,通过少量的几个样本找到相应类别在特征空间的原型中心,计算待预测样本到每一类原型的欧氏距离,在训练过程中最大化正确识别的概率。Sung 等提出了一种利用卷积神经网络预测特征间相似度的方法,通过输出相似性得分进行分类。另一方面,历史经验也能够指导当前任务的学习,弥补训练数据稀少的问题。如Ye 等设计了一种通过集合自适应方法对特征提取模型进行适配的方法,学习任务间的空间映射,利用已有模型提取与目标任务相关的特征,提高在目标任务上的准确率。基于元学习的方法在小样本问题上也有丰富的应用,如Finn 等提出了一种跨任务、不受任务影响的初始化方法,学习一个较好的初始化权重,使得模型能快速适应当前任务,在小规模样本上迅速收敛并取得较好的效果。Ravi 等基于长短期记忆网络(long short-term memory,LSTM)模拟梯度下降规则,学习一个易于后续微调的初始化参数,自动生成搜索方向和步长,解决了传统梯度下降的优化算法在面临小样本时失效的问题。Ren 等在处理基于元学习的小样本分类任务时,利用了未标记的数据,对原型网络进行了半监督扩展,利用已有类别的原型特征对未标记数据进行预测,根据待测数据属于各类别的概率更新每一类的原型,减少标记成本。
上述小样本学习方法能够有效缓解样本稀缺的问题,但是在数据集同类样本的多样性方面还有待研究。针对多种类型的电池片和隐裂,本文提出基于小样本的多损失融合隐裂检测方法,借助小样本学习的优势,降低对训练样本的依赖性,实现对新型光伏产品隐裂检测任务的快速适配。
2 多损失融合的小样本光伏组件隐裂检测算法
2.1 问题定义与算法流程
在光伏组件工业生产线上,能够获取的有隐裂数据量受限,从少量有标签样本入手进行研究更贴合实际应用需求。在进行小样本分类时,共个类别,每类给出个已知标签的样本,且值比较小,则可称该类问题为-way-shot 的小样本问题。进行基于少量样本的分类时,共有×张已确定标签的图像作为对照样本,判断待预测图像属于上述类中的哪一类。如图1 所示,本文主要任务是判断光伏组件上是否含有圈内标记所示的微小隐裂,可将图像分为有隐裂和无隐裂两类,构造2-way-shot小样本检测问题,以判断组件是否含有隐裂。

图1 有隐裂电池片Fig.1 Cracked cells
本文中多损失融合的小样本隐裂检测算法流程如图2 所示,本文各图中的表示图像批处理大小。首先对即将输入到特征提取网络的图像进行预处理。以区分有无隐裂为主分类,在训练阶段通过将模型的多头注意力机制和多损失函数优化配合,促使模型从多样化组件数据中关注隐裂信息,且允许同属隐裂的类型中仍可能包含多种子分类。进而有益于利用特征间相似度对未知样本进行预测,实现小样本支持下的隐裂检测。

图2 隐裂检测算法流程图Fig.2 Workflow of micro-cracks detection algorithm
2.2 隐裂特征提取网络
为了将图像映射到特征空间中,提取图像蕴含的语义信息,本文首先基于历史数据集提供的基类训练得到特征提取网络。为增强模型的信息提取、表达能力,本文选择了多层骨干网络,并引入多头注意力机制使图像特征提取网络在多样化的数据中侧重于获取能够分辨有无隐裂的特征。
在残差网络出现之前,人们希望通过增加神经网络层数提取更丰富的特征,但是实验证实,逐渐加深神经网络,模型准确率会先升高进而达到饱和,在此基础上继续增加层数反而会导致准确率下降。这是由于在反向传播过程中,较小的权值经过多层传播会产生梯度消失现象。在一个层数比较少且准确率达到饱和的网络后附加多个恒等映射层,可实现增加网络深度,He 等以此为灵感,设计引入跳跃(shortcut)结构的残差网络,如图3 所示,解决了由于网络层数增加导致的梯度消失问题。为了通过增加网络层数进而增强模型的信息提取能力,本文选用残差网络ResNet50作为特征提取网络的骨干网络。
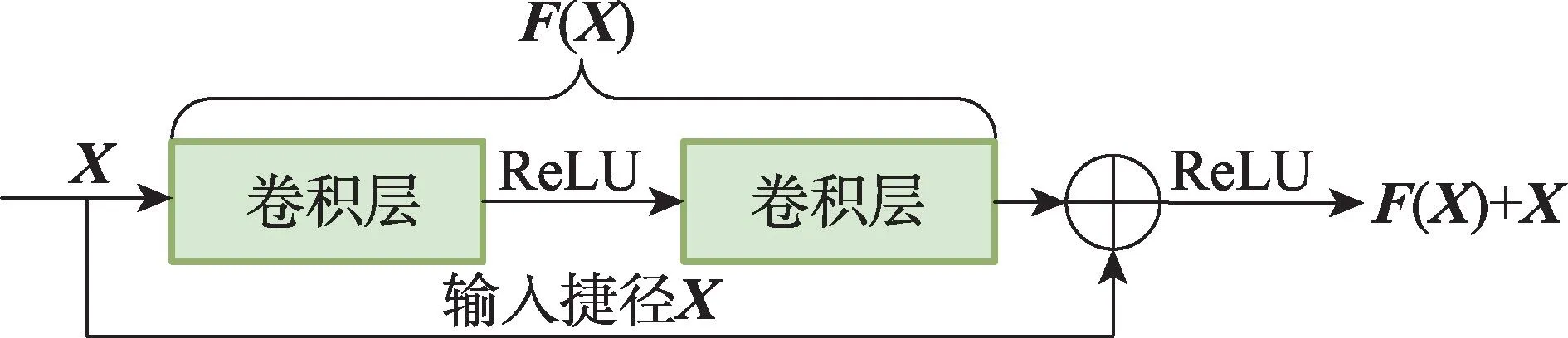
图3 残差结构示意图Fig.3 Diagram of residual structure
光伏组件产品不断更新换代,它们的外观和拍摄条件均存在差异,而隐裂检测任务的关注点在于判断是否有隐裂。因此本文通过在特征提取网络中引入注意力机制来降低不同产品间无关因素的干扰,该注意力机制通过两个串联的注意力计算模块(Transformer block)进行构建。在损失函数的约束下,给骨干网络的Layer3 输出的全局特征图附加侧重于隐裂识别的注意力,增强模型对隐裂的关注度。上述模块的结构如图4 所示,该模块输出的各元素能够拥有全局信息,并且通过不同的头获取多层面的语义信息,通过前馈层(feed forward)对输出向量进行特征转换,丰富模型的表达能力。

图4 注意力计算模块示意图Fig.4 Structure of Transformer block
为满足注意力计算模块的工作特性,首先对特征图进行序列化,其流程如图5 所示。维度调整后,将每个位置看作一块,经过注意力机制模块后恢复为原特征图大小,下采样并升维后作为特征提取的补充部分,共同参与特征表示。

图5 特征图序列化Fig.5 Feature graph serialization
2.3 多损失结合策略
该损失是约束模型训练的最基础的损失,通过交叉熵损失衡量由全连接层实现的分类器的输出,其计算方法可描述为式(1),其中的q在与真实标签对应时取1,否则取0。在本文的设计中也可用于对新产品是否含有隐裂进行直接预测,但考虑到历史产品和新产品间差异较大,可将其作为参照预测。

另一方面,为了避免特征提取网络对当前任务产生过拟合而不适应新的产品检测任务或受到标记不准确的标签影响,在计算上述交叉熵损失时,引入了标签平滑策略,将待预测图像属于另一类的可能性也纳入衡量范围内,对交叉熵损失中的值q进行如式(2)所示的修改。

引入三元组损失的目的在于拉近特征空间中同一类的距离,推开不同类之间的距离,使同一类的特征形成聚类,该损失的衡量方式可描述为式(3),其中作为锚点,为与同一类的正样本,为不同类的负样本,表示特征间的欧式距离,本文设置该损失的边距()值为0.3。在本文中三元组损失的应用可以促使模型将有隐裂的不同产品拉近,相同产品中有无隐裂的两类拉开。在基于小样本进行预测时,有助于根据少量参照样本将待预测图像进行归类。
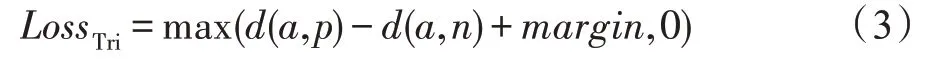
由于训练集中有多种类型的组件,且不同类型产品和隐裂间仍具有一定差异,本文提出了隐式分类的设计,以是否有隐裂作为主分类,每类对应个子分类,在本文将设置为3,则隐式分类器的输出对应6 个预测值,且经过图像输入后可以产生6 个特征向量。在模型训练阶段将是否有隐裂看作两个子分类任务,分别以有隐裂样本为正样本和以无隐裂样本为正样本,分别对应分类器输出的3 个值。如式(4)所示,在任意一个子分类任务中借鉴标签平滑技术的特点,对预测最大值给予较高权重,并与其他预测值均分剩余的权重1-,计算属于该主类的所有子分类的分数总和。

将该总和视为预测属于该主类的总分进行Softmax归一化,把分数转换到0~1 范围内以便计算如式(5)所示的二分类交叉熵损失,最后将两个子分类任务的二分类交叉熵损失进行加和以代表该隐式分类损失。在训练过程中,该隐式分类损失能够与注意力机制配合,促进模型提取有无隐裂的分辨特征,在同一类特征下仍可包含子分类,贴合训练集数据分布特点。
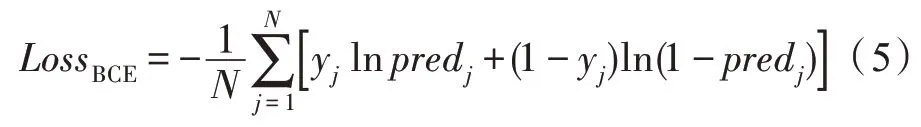
2.4 特征优化与预测
将上述三部分损失按权结合用于特征提取网络反向传播优化参数。本文特征提取网络输出的特征向量可表示为,其维度为1×2 048。将有无隐裂两类参照集中的样本映射为特征向量f(=1,2,…,2)。考虑到组件隐裂也有不同的形状、分布特点,同一主分类内特征可能有细微差异,本文选择保留每类的个参照特征,不对同一类特征向量进行压缩,即取平均值,则在预测阶段可与共2×个特征进行比较。如式(6)所示,本文采用余弦相似度衡量待测特征与各参照特征间的相似度,相似度值越大说明图像与对应类别越相似,进而如式(7)所示,可实现有限参照样本下的单晶组件隐裂检测。

上述多损失结合策略不仅可以从不同角度与注意力机制配合,约束模型从多样化数据中提取有利于分辨隐裂的特征,还可以给预测阶段带来更多的判别依据。在更困难的场景下,比如要完成在没有任何新产品样本作为参照时的隐裂检测任务时,本文方法利用直接预测得分,并衡量待测特征与历史训练集提取的多个隐式分类对应的特征间的相似度。在具体实现中,首先对相似度的值进行放大,再对其进行Softmax 归一化,以增大相似度间差异,将相似度转化为预测得分,进而可将相似度对应得分与直接预测得分按权结合,缓解参照样本缺失的问题。
3 实验验证
3.1 实验数据集
本实验采用两部分数据集,分别是公开隐裂数据集和某工业生产线提供的隐裂数据集。
公开数据集中包含多种类型的电池片产品,样本的标签为浮点数,表示每个样本含有隐裂的可能性大小,本文提取单晶组件的标签确定为0 或1 的电池片样本用于实验,共901 张图像,其中含有隐裂的图像有313 张,不含隐裂的有588 张。工业生产线采集的隐裂数据集共1 797 张单晶电池片图像,有隐裂的图像数量较少,仅149 张,无隐裂的共有1 648 张。
利用上述两部分数据集构建小样本学习条件,选取历史电池片数据集和新型待测电池片数据集。考虑到公开数据集中电池片类型丰富,且有隐裂样本的规模相对大一些,将该数据集设置为训练集,经过图像预处理后用于训练特征提取网络。为更贴合实际应用场景,来自产线的数据集则作为测试集,提供参照样本集和待预测的查询集。
3.2 实验配置
本文实验基于深度学习框架PyTorch 和GeForce GTX 1080Ti 型显卡,将图像尺寸统一设置为224×224。在构建特征提取网络的阶段采用网络公开单晶电池片隐裂数据集,将数据集中901 张单晶电池片图像打乱后按8∶2 划分为训练集和验证集两部分。经数据集划分后,验证集共包含181 张图像,其中含有隐裂的有53 张,不含隐裂的有128 张,可见验证数据中两类样本的分布较为不平衡。
训练过程中以0.5 的概率对图像进行水平翻转和垂直翻转以扩增数据,设置批处理大小为32,初始学习率为0.003,并采用随机梯度下降算法(stochastic gradient descent,SGD)更新网络参数,SGD 的动量和权重衰减分别设置为0.9 和0.000 5。
大部分小样本学习方法以构造小样本任务为基础进行模型训练和测试,一个-way-shot小样本分类的子任务中包含个类别,每类提供个参照样本。为统一各实验的测试标准,基于测试集随机构造100 个小样本子任务以计算评估指标均值,每个子任务中有无隐裂的两类产品均提供5 张参照样本,15 张待预测样本。
3.3 评估指标
本文的任务相对更侧重于识别出有隐裂的产品,以有隐裂为正样本,则在衡量模型对有隐裂类别的识别效果时,(true positive)表示预测结果为有隐裂且与实际标签一致的真正例,(true negative)表示预测为无隐裂且与实际标签一致的真反例,(false positive)表示预测为有隐裂而实际为无隐裂的假正例,(false negative)则表示预测为无隐裂而实际为有隐裂的假反例。
如式(8)所示,直接采用准确率()评估模型在验证集上预测效果一定程度上会受到样本数量多的一类的预测结果影响,为避免产生无隐裂的数据预测结果好而掩盖了对有隐裂的数据预测能力较弱的问题,本实验选择加入召回率()和精确率()衡量模型的预测效果,如式(9)和式(10)所示,利用召回率衡量模型对有隐裂类别的识别能力,利用精确率衡量对有隐裂类别的预测准确程度。最后,采用式(11)计算召回率和精确率的调和平均数(1-score),综合判断模型的隐裂识别能力。

3.4 实验结果分析
特征提取网络在验证集上的预测准确率可达92.27%,其中对有隐裂类型的预测召回率为84.91%,精确率为88.26%,1-score 为0.865,在不同类型损失组合下训练特征提取网络的损失收敛曲线如图6所示。直接应用在测试集上,取特征提取网络结构中最后的输出,即将每张输入图像映射成维度为1×2 048 的特征向量。通过衡量待测特征与2个参照特征间的余弦相似度可知待预测图像更贴近于哪一类,进而完成基于少量样本的图像归类。在固定每个子任务中待检测样本数目为15 的情况下,本文模型基于不同大小的参照样本的检测召回率和精确率结果详见表1。
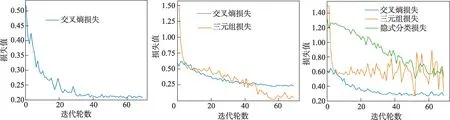
图6 训练损失收敛曲线Fig.6 Loss convergence curve of training
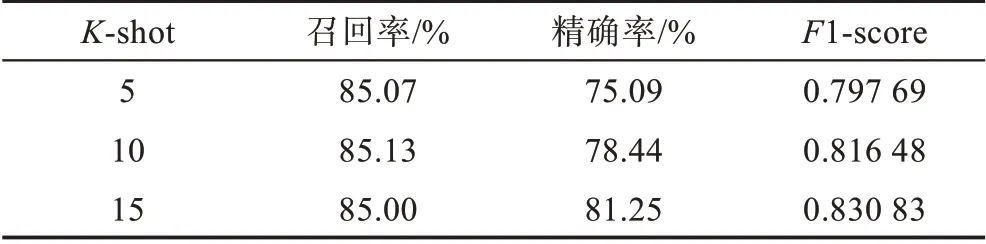
表1 K-shot下检测结果Table 1 Detection results under K-shot
表1 中=5 表示有无隐裂均给出5 张参照样本,模型检测效果中1-score 为0.797 69,在等于10和15时,1-score 相对于=5 分别增长了0.018 79和0.033 14。对比不同大小参照集下的模型效果可知,增加参照样本数量有利于提升预测精确率,但检测效果差距较小,可见本文模型能够充分利用已有参照特征,满足在样本稀少的条件下检测隐裂的需求。
本文直接使用特征提取网络从参照样本提取新产品特征,通过衡量从小样本得到的参照特征与待预测特征间的相似度避免了利用少量样本重新训练模型从而导致过拟合的问题。如图7 所示,仅基于有无隐裂每类5 张的极少量的样本对特征提取网络进行调整后再直接预测有无隐裂,调整效果十分微弱且在几轮迭代后有隐裂产品的召回率、精确率等指标会下滑,即产生过拟合。
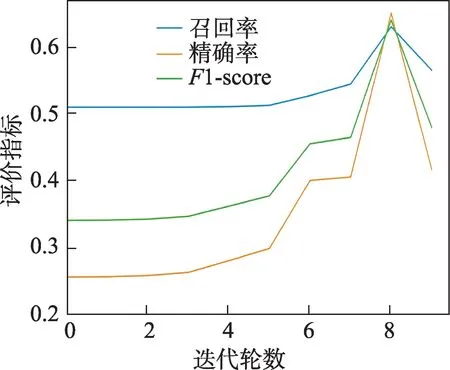
图7 仅基于少量样本调整模型时的检测效果Fig.7 Detection effect based on small sample adjustment
为验证本文方法中多头注意力机制与多损失结合策略的有效性,本小节从网络结构和损失结合方式对检测效果的影响两个角度,基于每类5 张参照样本,15 张待预测图像,设计了如下消融实验,结果如表2 所示。其中“交叉熵损失”表示只使用直接分类对应的交叉熵损失约束模型训练,“+三元组损失”表示在交叉熵损失的基础上引入三元组损失共同约束模型训练,“+三元组&隐式”表示直接分类损失、三元组损失以及隐式分类损失融合约束模型训练的策略。

表2 5-shot下消融实验结果Table 2 Results of ablation experiment under 5-shot
在网络结构方面,首先为了说明适当增加网络层数有助于提高特征提取模块提取特征的能力,本文选取由19 层神经网络层构成的VGG19 与骨干网络ResNet50 进行对比,在同样采用“+三元组&隐式”的损失结合策略时,ResNet50 相比于VGG19 能将隐裂样本召回率、精确率分别提升6.40个百分点、4.03个百分点,使1-score 增长0.051 91。本文将ResNet50结合交叉熵损失视为实验基线。
为验证多头注意力机制(+Transformer Block)的有效性,本文在ResNet50 的5 个阶段中最后一阶段引入并测试了SE Block 和Non-local Block 对模型的提升效果。在采用“+三元组&隐式”策略时,引入SE Block、Non-local Block、Transformer Block 分别将模型的召回率提升了4.94 个百分点、6.14 个百分点、6.74 个百分点。可见在相同的损失策略下引入注意力机制能有效提升检测效果,其中多头注意力机制与多损失结合策略配合的效果较好。
在损失结合方面,三元组损失能够有效拉近有无隐裂样本的类间距离,在骨干网络ResNet50和引入多头注意力机制这两种网络结构下,“+三元组损失”能使模型的1-score 分别升高0.076 03 和0.090 56。增加三元组损失的基础上引入隐式分类损失能够进一步提高模型隐裂检测能力,相比于“+三元组损失”,两种网络结构下召回率分别提升3.26 个百分点和8.60 个百分点,精确率分别提升5.35 个百分点和1.04 个百分点。电池片表面隐裂难以辨别,且正常电池片表面也可能有一些细微的划痕,与表面完全干净的电池片存在一定差异,而隐式分类允许主分类内部存在多个子分类,对训练集内部多样化的电池片产品的包容性更强,可减少误判有隐裂的情况。
本文方法将多头注意力机制与多损失融合策略相结合,相比实验基线将1-score 提升了0.148 19,召回率和精确率分别提高了19.44 个百分点和10.71个百分点,确保了隐裂检测模型的可信度。
观察实验基线与本文方法对应的两模型依据相同输入提取的激活图,如图8 所示,相对于实验基线,本文的注意力机制结合多损失策略模型更能够关注有隐裂电池片的隐裂部分,而基线对隐裂的定位能力较差,会遗漏隐裂信息。如图9 所示,在处理无隐裂电池片时,注意力机制结合多损失策略能使模型减少对无隐裂区域的误判。在多损失策略的约束下引入注意力机制,能促进模型减少对无关因素的关注,更准确地定位有隐裂的区域,提取更多有关隐裂的可区分性强的特征。
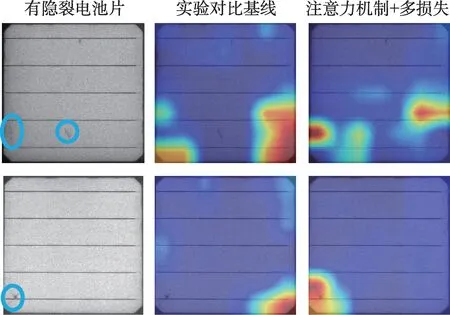
图8 有隐裂电池片激活图Fig.8 Activation maps on cracked cells
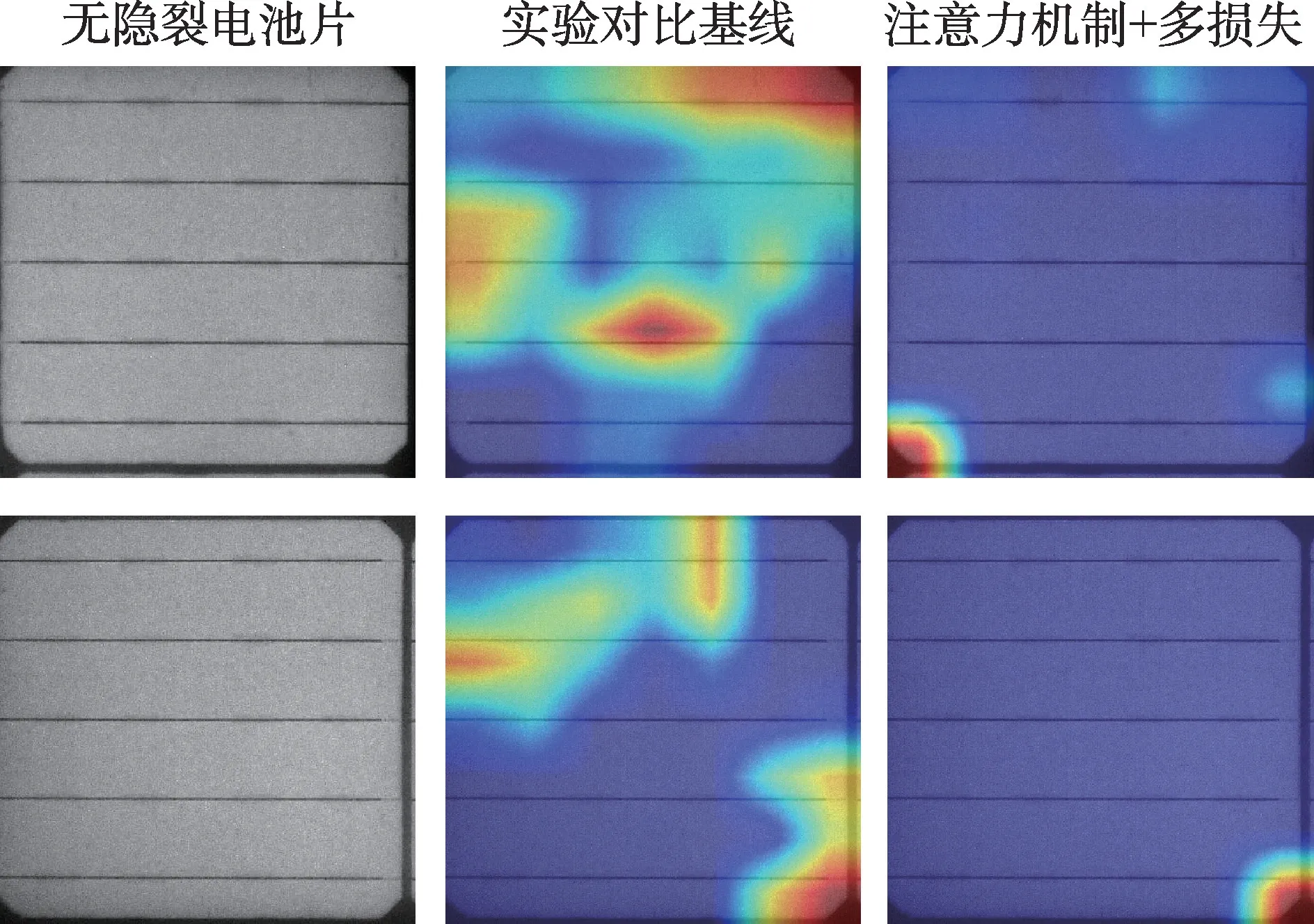
图9 无隐裂电池片激活图Fig.9 Activation maps on normal cells
表3 展示了在相同的损失结合策略“+三元组&隐式”下不同网络结构对应的模型的参数量、复杂度等属性。在骨干网络ResNet50 的基础上引入了多头注意力机制后模型参数量仅增加4.8×10,在相近的计算量和推理时间下,检测效果得到明显提升。
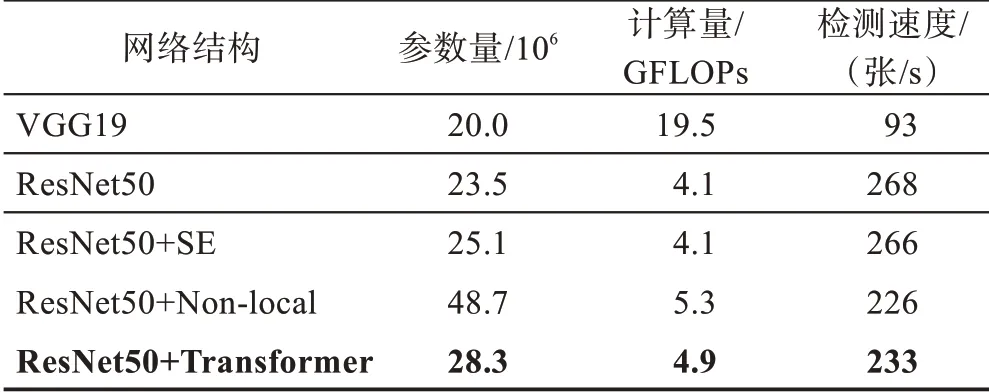
表3 模型属性对比结果Table 3 Comparison results of model attributes
本文方法与另外4个小样本学习方法对比的实验结果如表4 所示,其中原型网络(ProtoNet)使用欧氏距离度量特征相似度,每类的参照特征取均值生成原型特征以作为每一类的代表,该方法的1-score 为0.693 69。主动学习相似度衡量的方法(RelationNet)用卷积神经网络替换了人为预设的距离衡量策略,通过卷积神经网络探索更多的特征间的信息,扩充了相似度衡量的可能性。该方法的网络结构比较简单,其1-score 为0.611 94。MAML方法需要学习大量的元任务,其目标是找到对各个任务都合适的初始化策略,使模型经过少数次的微调后,在当前任务上能取得较好效果。可避免模型对某个任务过拟合而无法适应其他任务,实现快速适应。该方法的1-score 为0.680 26。学习适合小样本问题的优化器方法(OptNet)是基于MAML 方法的扩展,该方法利用LSTM 生成优化器,学习适合小样本问题的优化方向和步长,1-score 为0.624 65。本文方法构造的模型的召回率、精确率和1-score相比上述表现较好的ProtoNet分别升高了16.34 个百分点、5.07 个百分点和0.104,能够在保证识别精确率的同时,有效地检测出有隐裂的电池片。
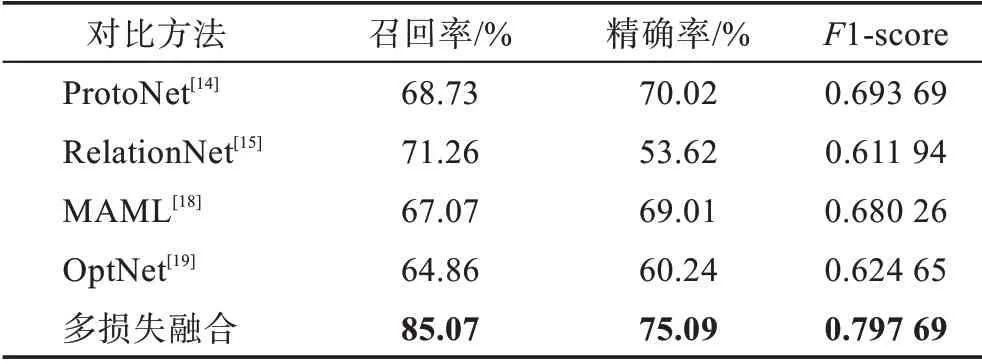
表4 5-shot 下对比实验结果Table 4 Comparison results under 5-shot
4 结束语
本文针对光伏电池产品更新迭代速度较快,隐裂训练数据量不足的问题,提出了基于小样本的单晶光伏电池隐裂检测方法。设计了多损失结合策略,实现以是否有隐裂作为主分类,不同类型产品作为子分类的目标。模型在多损失约束下,通过多头注意力机制使模型侧重于多类电池片中隐裂信息提取,在适应训练集中不同产品的多样性的同时,确保提取到有隐裂和无隐裂电池片的具备辨别性的特征。在测试阶段可以利用多损失的关注点不同,实现多种预测方式的按权组合,进而在极少的参照样本支持下,可以保证达到较好的对隐裂产品的召回率。
在接下来的研究中,可以继续细化隐裂的类型,而且考虑到不含隐裂的电池片占比较大、更易收集,可以利用不含隐裂的图像生成更多的参照特征,降低无关因素的干扰。
猜你喜欢
能源工程(2022年2期)2022-05-23 13:51:50
江西教育·职教版(2022年9期)2022-04-29 00:44:03
数学小灵通·3-4年级(2021年5期)2021-07-16 07:46:32
重型机械(2020年2期)2020-07-24 08:16:16
装备制造技术(2019年12期)2019-12-25 03:07:36
今日农业(2019年15期)2019-01-03 12:11:33
电子制作(2018年19期)2018-11-14 02:37:08
自动化学报(2017年11期)2017-04-04 02:52:58
广西民族大学学报(自然科学版)(2015年3期)2015-12-07 00:56:05
太阳能(2015年11期)2015-04-10 12:53:04
