
注意力与多尺度有效融合的SSD 目标检测算法
2022-02-23 10:03:44王燕妮余丽仙
计算机与生活 2022年2期
王燕妮,余丽仙
西安建筑科技大学 信息与控制工程学院,西安710055
目标检测是计算机视觉中最基本也是最关键的一项任务,在视频监控、智慧医疗等领域中都具有广泛的应用价值。高精度目标检测要求当给出一张图片或一段视频流时,可以准确地对图片或视频中的目标进行定位并识别出所属类别。然而目标自身的形状、颜色、姿势等因素,以及外界的遮挡、光照等条件,都对目标检测任务产生了巨大的干扰。常见的目标检测方法有基于像素分析的方法、基于特征匹配的方法、基于频域的方法和基于识别的检测方法。使用较为广泛的检测器通常分为特征提取和目标分类两大步骤,常用的传统特征提取方法有方向梯度直方图(histogram of oriented gradient,HOG)、尺度不变特征变换(scale-invariant feature transform,SIFT)、局部二值模式(local binary pattern,LBP)等。与这些特征提取方法搭配使用的分类器有支持向量机(support vector machine,SVM)、随机森林(random forests)、AdaBoost等。同时还有一系列基于上述方法改进得到的目标检测器,如由TPIHOG(thermal-position-intensity-histogram of oriented gradient)和AKSVM(additive kernel SVM)组合得到的TPIHOG-AKSVM检测器,还有融合Haar-Cascade 和HOG-SVM 得到的新的检测器。但是这些方法的鲁棒性较差,当检测目标较为复杂时,检测精度和实时性都比较低。
随着人工智能的发展,深度学习在目标检测领域越来越受欢迎,目前主流的目标检测方法主要分为两阶段检测法和单阶段检测法。Fast R-CNN、Faster R-CNN、RefineNet等都是经典的两阶段检测法。YOLO(you only look once)、SSD(single shot multibox detector)、RetinaNet等都属于典型的单阶段检测法。两阶段检测法主要是将候选框的提取和目标检测分为两个步骤执行,首先进行候选对象的筛选,然后对候选对象进行分类和回归操作。而单阶段目标检测则是将其融合到一个网络中,直接输出检测结果。单阶段检测算法在精度上稍优于两阶段检测法,但在检测速度上远超于两阶段检测法。
YOLOv1 算法是单尺度目标检测算法,因此对于多尺度目标检测任务不适用。SSD 相比于YOLOv1有较大的提升,它引入了多尺度检测方法,针对检测目标的大小不同,使用不同尺度的特征图进行检测,但是浅层目标无法充分利用上下文语义信息,因此对于小目标等困难样本存在较多的误检、漏检。为了解决小目标检测困难等问题,学者们又提出了多种特征融合方法,如最常见的FPN(feature pyramid network)和PAFPN(path aggression FPN)。通过简单的自下而上或自上而下的特征融合,得到特征信息更加丰富的特征图。通常直接通过特征相加或维度拼接进行特征融合,对于算法的性能提升具有有效性,但是容易引入噪声和冗余信息。文献[21]中提出了一种多尺度感受野注意力,通过引入注意力,增强图像目标信息权重,从而提升小目标的检测精度。
本文针对SSD 算法存在的检测缺点,引入注意力机制和新的特征融合模块,改善网络的漏检和误检情况。注意力机制可以提升网络对关键信息的学习能力,而特征融合可以丰富SSD 中用于目标检测的特征层信息,两者结合可以有效提升目标检测的准确率。
1 SSD 算法
SSD 是一种经典的多尺度单目标检测算法,以VGG-16作为基础骨干网络,算法结构如图1 所示。SSD 算法预先通过骨干网络提取出6 个由大到小的特征图,在每个尺度上预先定义多种长宽比的锚框,不同尺度的特征图对应检测的目标大小不同,浅层特征图检测小目标,深层特征图检测大目标。最后使用非极大值抑制(non-maximum suppression,NMS)删除重复的预测框,保留结果最好的预测框。

图1 SSD 算法结构图Fig.1 SSD algorithm structure diagram
SSD 采用了多尺度预测方法,浅层网络检测小目标,深层网络检测大目标。浅层网络虽然含有丰富的几何信息和较为准确的定位,但是感受野小,且语义信息表征能力弱。深层网络与浅层网络特性相反,其具有较大的感受野和丰富的语义信息,但是分辨率小,几何信息表征能力弱。因此,SSD 在进行目标检测时会存在严重的漏检和误检的情况。
为了提高SSD 的目标检测性能,本文在SSD 的基础上引入了注意力机制模块和特征融合模块。通过注意力机制模块,使网络将更多的关注点放置在关键信息上,增强网络对目标的识别能力;通过特征融合模块,将深层网络中的特征融合到浅层网络中,增强网络对小目标和复杂目标的检测能力。
2 改进SSD 算法
为了改善SSD 算法中存在的复杂目标检测困难等问题,在原始的网络中融入了注意力机制模块和特征融合模块。首先将原始SSD 提取出的6 个尺度不同的特征层依次输入到注意力机制模型中,增强特征图对关键信息的表达能力。其次,将深层网络和浅层网络相融合,提升浅层网络的语义信息表征能力。改进后的网络结构如图2 所示。
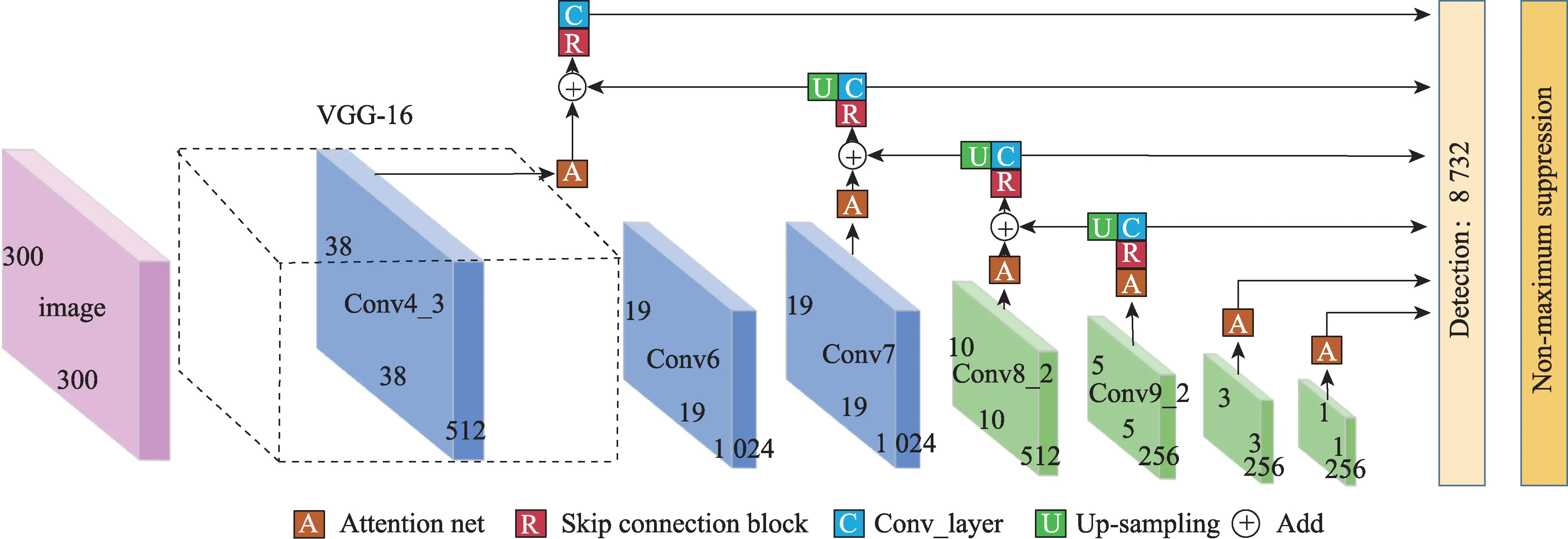
图2 改进的SSD 算法结构Fig.2 Improved SSD algorithm structure
2.1 引入注意力机制
注意力机制具有与人类视觉相似的特性,当出现物体时,会优先将更多的注意力放置在关键信息上,同时抑制无用信息。近几年来,计算机视觉任务与注意力机制之间的联系日益密切。如用于阿尔茨海默病(Alzheimer’s disease,AD)识别和分类的带有注意力机制的残差网络,使用带有注意力机制的网络对合成孔径雷达(synthetic aperture radar,SAR)图像中的桥梁进行检测。
根据注意力关注的区域不同,注意力机制通常可分为通道域、空间域和混合域。SE-Net(squeezeand-excitation networks)是一种典型的通道域注意力机制,通过对各个通道的自主学习,辨别各个通道的重要程度,主动增强重要通道的权值。如图3 所示,为SE-Net 的结构模型图。但是SE-Net 中含有的降维运算会影响渠道相关性预测,同时对所有渠道都进行相关性捕获也会降低网络的效率。Jaderberg等提出的Spatial Transformer Networks 则是典型的空间域注意力机制,该机制可以将图像中的空间信息转换并保存到另一个空间,该模型结构如图4 所示。CBAM(convolutional block attention module)则是一种常见的混合域注意力机制,通过将空间域和通道域串联,可以更加有效地提升网络性能。
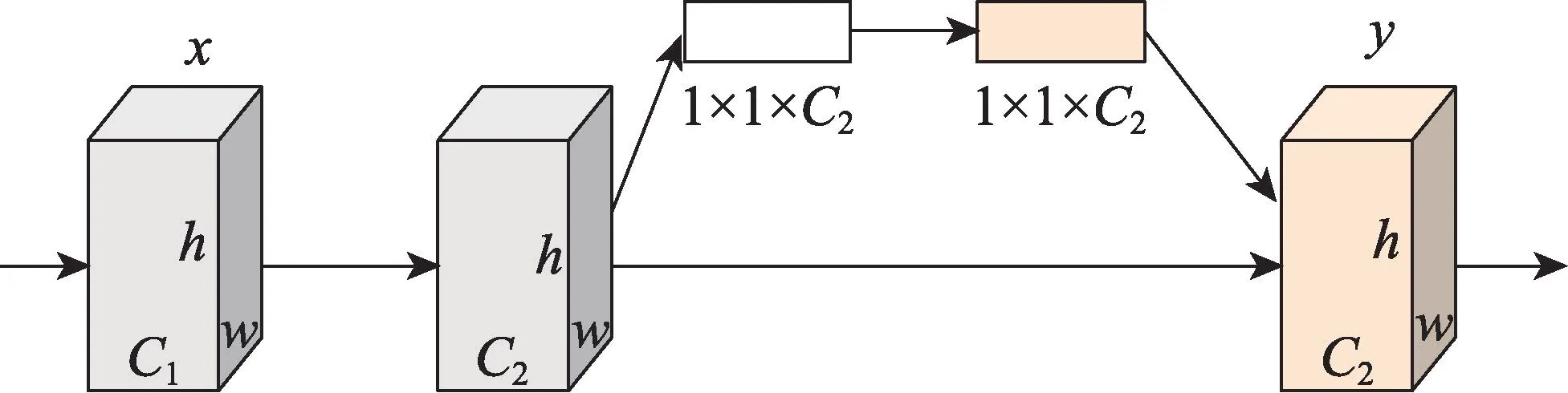
图3 挤压和激发网络模型图Fig.3 Squeeze-and-excitation networks model structure
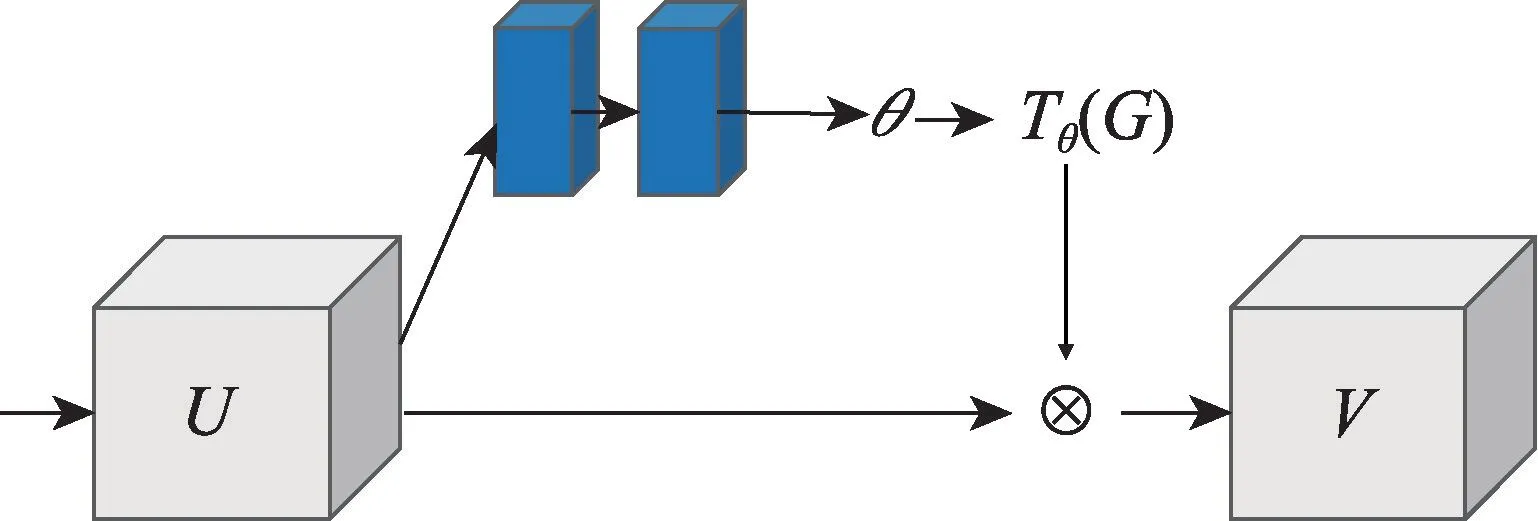
图4 空间域结构模型图Fig.4 Spatial transformer model structure
考虑到网络参数量和计算量,选择了一种轻量级注意力机制,即ECA-Net(efficient channel attention for deep convolutional neural networks),它 是SENet 的改进版本。ECA-Net 不仅参数量更少,性能也更优。如图5 所示,为ECA-Net 的架构图。该网络结构中取消了降维运算,当网络完成全局平均池化之后,直接进行局部跨通道连接,即将由池化操作得到的每个与其相邻最近的个通道进行一维卷积操作,的取值通过通道数自适应确定:
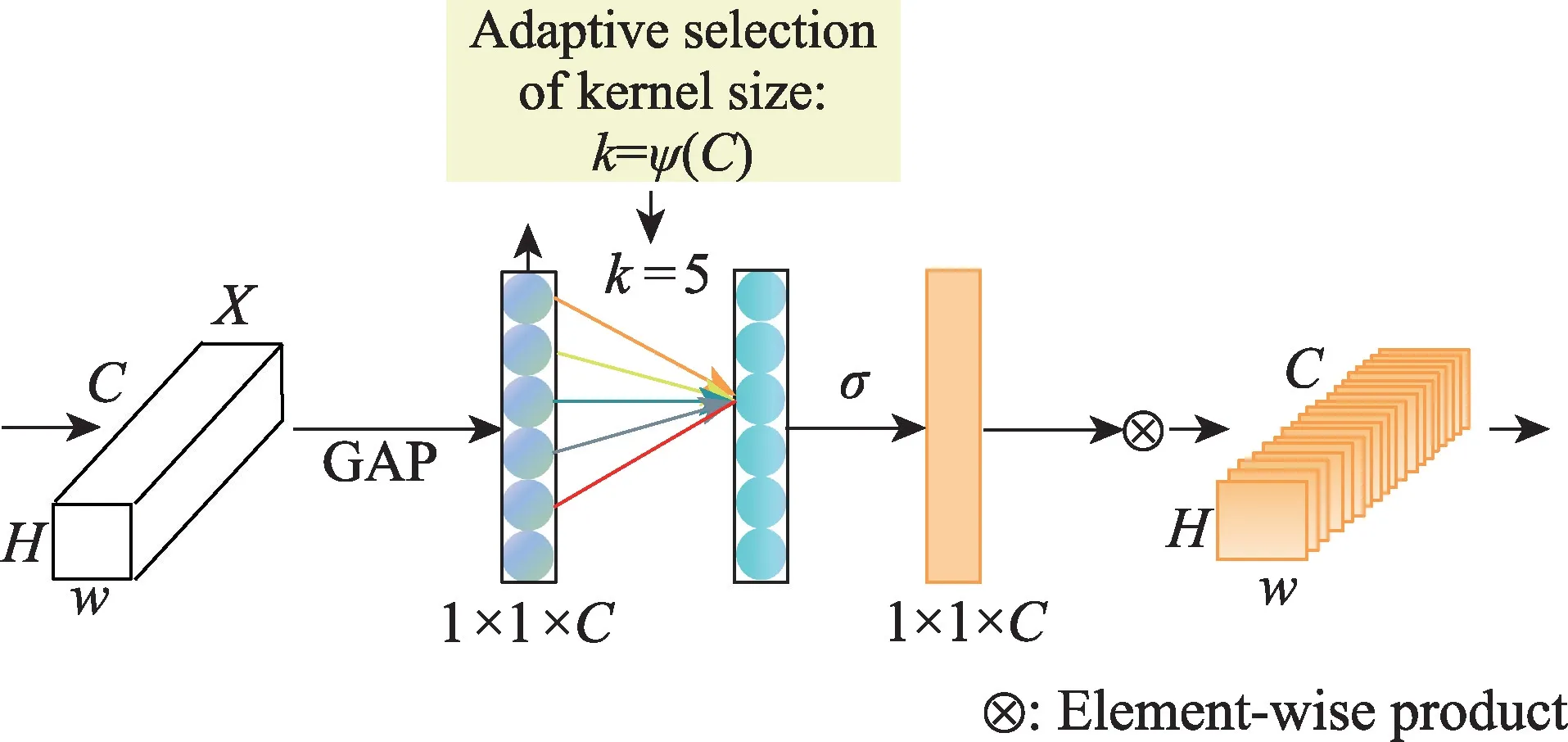
图5 深度卷积神经网络的有效通道注意Fig.5 Efficient channel attention for deep convolutional neural networks

其中,|·|表示取离结果最近的奇数;和表示常量,分别取值为2 和1。
ECA-Net 网络的注意力热图如图6 所示,图6(a)为原始图片,图6(b)为普通卷积输出热图,图6(c)为ECA-Net注意力热图。可以看到,含有注意力机制的热图中,背景信息明显被抑制,更加突出了关键目标信息。
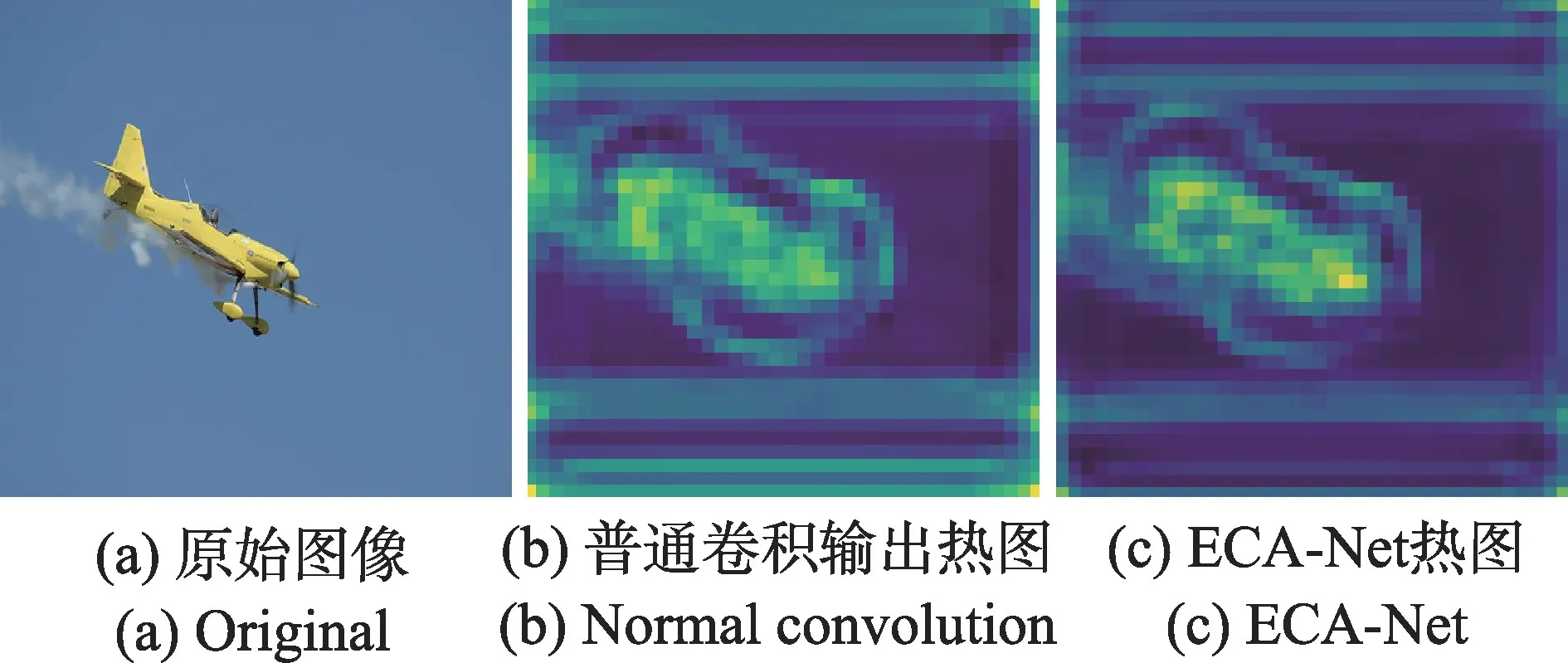
图6 ECA-Net热图Fig.6 ECA-Net heat map
引入注意力机制前后的主干网络多层输出特征图对比如图7 所示。上半部分的特征图为原SSD 网络的输出特征图,下半部分为引入ECA-Net 之后输出的特征图。通过特征图对比,发现在引入注意力机制之后,目标和背景差明显被放大,背景信息的亮度被抑制,在38×38 的特征图中表现得尤为明显。这有利于网络捕获更多的目标信息,同时减少背景对目标的影响。实验表明,引入ECA-Net 模块,网络的参数量个数依旧为59 719 217 个,说明引入的轻量级注意力机制并没有增加网络的计算量,即没有对网络的检测速度造成影响。
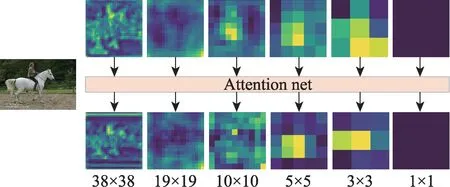
图7 特征图可视化对比图Fig.7 Visualized comparison chart of feature maps
2.2 增加特征融合模块
SSD 的浅层网络用于小目标检测,但是深层特征图感受野小,语义信息表征能力弱。为了增强SSD网络对小目标的检测能力,引入特征融合模块。
为了得到更好的目标检测效果,卷积神经网络结构开始向更深和更宽这两个方向发展。但是扩展神经网络的结构通常意味着带来更大的计算量,这会在一定程度上提高目标检测任务的成本。受CSPNet(cross stage paritial network)的启发,构造了简洁版的CSPNet结构模块,并将其融入特征融合模块中,如图8 所示为CSPNet 模块结构,图8(a)为改进前的结构图,图8(b)为改进后的结构图。本文设计的简单的跳变连接网络,首先将基础层特征图划分为两部分,然后通过跨阶段层次结构进行合并,可以在实现更加丰富的梯度组合的同时减少网络计算量。通过该结构可以增强卷积神经网络的学习能力,降低网络计算瓶颈。

图8 CSPNet结构图Fig.8 CSPNet structure diagram
不同尺度之间的特征融合需要对小的特征图进行上采样,本文使用的上采样方式为线性差值法中的最近邻插值算法,其基本原理是将已知像素的值赋予给最邻近的位置像素。如图9 所示,区域的像素值均由点(,)决定,区域的像素值则由点(+1,)决定,以此类推可以得到该区域的所有(+,+)的像素值。
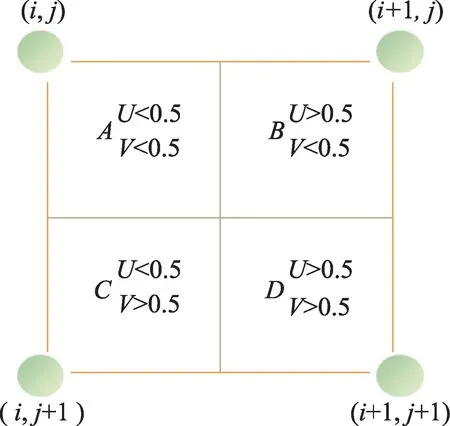
图9 最邻近插值法Fig.9 The nearest interpolation
完整的特征融合模块结构如图10 所示。首先将骨干网络输出的特征图送入轻量级注意力模块,通过注意力机制对无用信息进行抑制,增强网络对关键信息的捕获。然后通过改进后的CSPNet 结构,进一步优化网络特征。改进后的CSPNet网络由两个分支组成,主分支上由两个卷积核大小不同的卷积层串联组成;次分支为一个1×1 的卷积核。通过该结构可以先将上一层的特征映射划分为两部分,再使用跨层次合并操作,可以在保证网络精度的同时减少计算量。然后进行上采样将深层网络中的特征图尺寸扩展成待融合的浅层特征图大小,最后通过element-wise add 方式将对应的特征图相加,它可以在不增加特征通道数的同时丰富特征图信息。为了避免因不同尺度特征图之间存在的信息差异而引起的次优融合结果,再次经过卷积操作,输出最终得到的融合后的特征图。
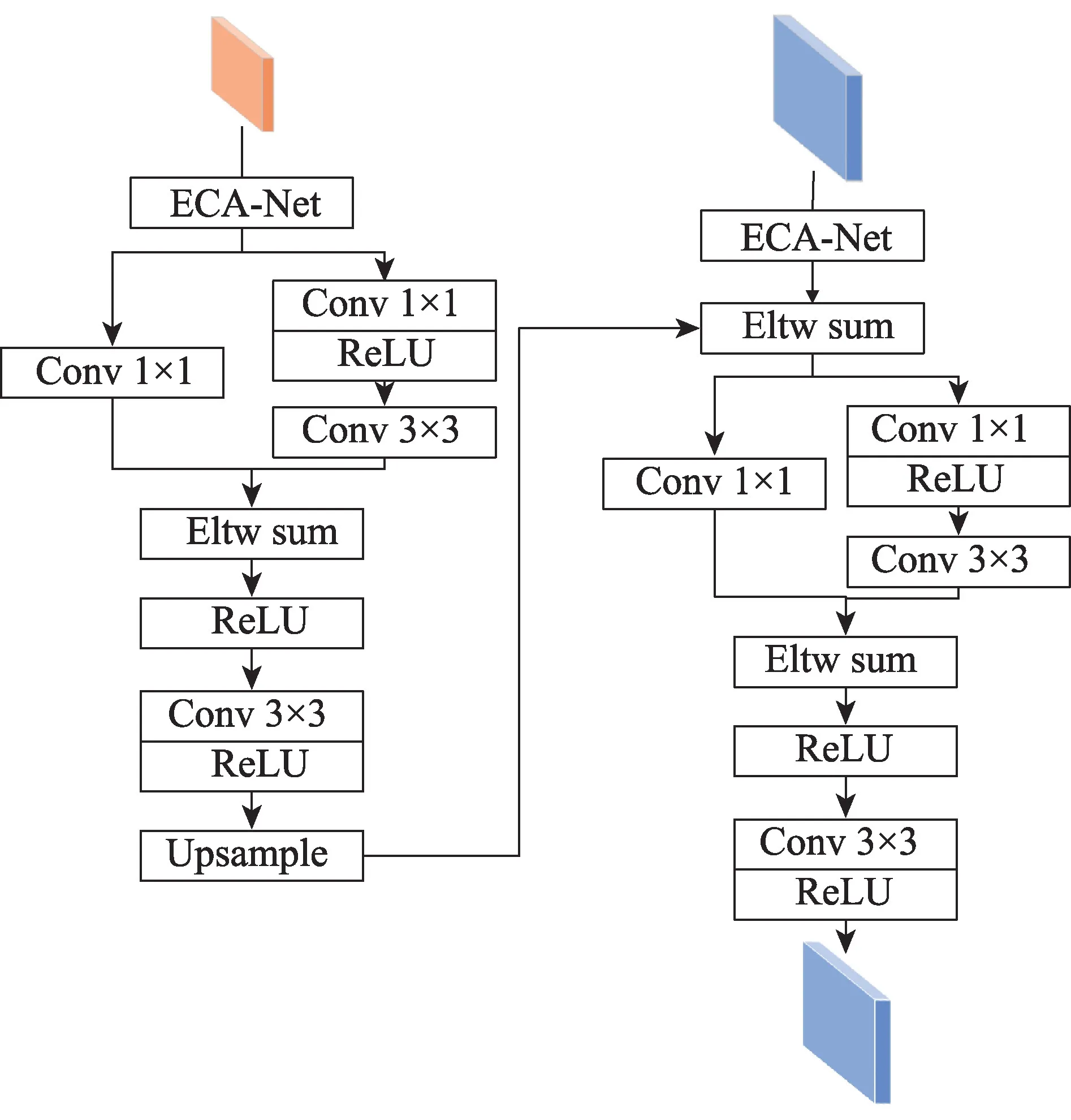
图10 特征融合模块Fig.10 Feature fusion module
融合模块虽然可以充分利用上下文语义信息,丰富浅层网络的特征信息,但是同时也增加了模型的复杂度。相比于改进前的SSD,改进后的网络多了3 个特征融合模块,在一定程度上增加了网络的计算量,对网络的总体实时性产生了影响,但是提升了整个网络的检测精度。
2.3 模型训练
在网络初始化时采用了迁移学习的思想,首先使用预训练好的SSD 模型对改进后的网络进行参数初始化,新增加的网络层采用He 初始化方法。然后进入微调阶段,对改进后的网络的权重参数进行微调,并在训练过程中引用数据增强策略。微调阶段采用了两步骤训练法,将骨干网络和检测网络分开训练。首先训练检测网络,即关闭骨干网络中的梯度更新命令。当网络达到稳定时,开启骨干网络的反向传播指令,然后从头训练整个网络。这样在训练初期可以防止骨干网络中的权重被破坏,同时也可以加快网络的训练速度。
优秀的训练数据集对于神经网络来说及其重要,在模型训练过程中参考了最新的SSD 训练策略,引入了一系列常规的数据增强方法,如水平翻转、颜色扭曲、随机裁剪等。通过数据增强策略,可以在训练过程中丰富训练数据集,从而达到提升网络性能的目的。
为了更好地检测各种大小和形状不同的目标,每一个特征图都需要预先设置好各种尺度的先验框。本文根据SSD 算法设置的先验框选取规则,进行锚框选定。候选区的尺寸选取原则如下:
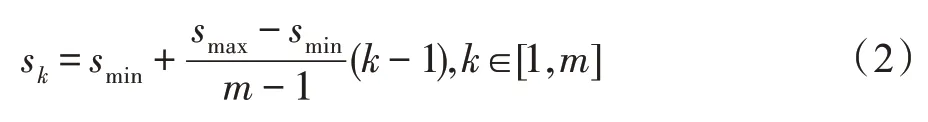
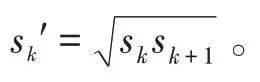



与原始SSD 相同,改进后的算法依旧通过分类和回归进行目标预测。分类时使用Softmax 函数进行分类置信度预测,定位时使用回归函数输出目标位置。目标损失函数由置信度误差和位置误差组成,即:
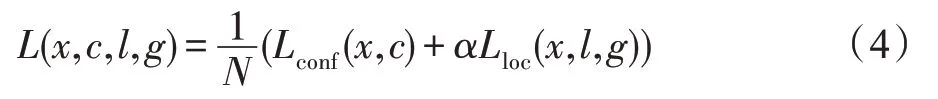
其中,通常默认设置为1;为匹配的候选框数量,当为0 时,则说明没有匹配的候选框,值为0;其中置信度误差计算公式如下:
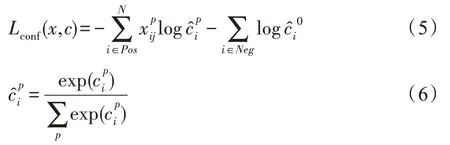
其中位置误差计算公式如下:
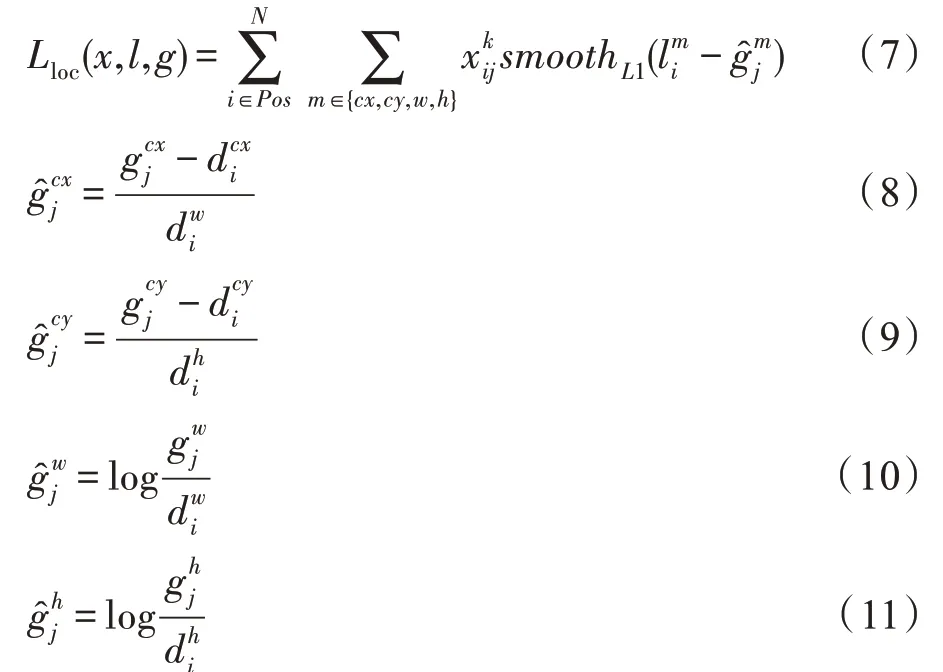
式中,(g,g,g,g) 表示真实框,(d,d,d,d) 表示候选框。
网络训练阶段使用Adam 优化器,采用两步骤训练法,可以防止通过预训练模型初始化得到的权重被破坏。首先冻结骨干网络,训练检测网络,batch_size 设置为32,初始学习率为0.000 5,总共迭代23 350 次,且每迭代一次,学习率下调5%。然后将被冻结的骨干网络参数释放,从头训练整个网络,batch_size 依旧设置为32,初始学习率为0.000 1,总共迭代23 350 次,且每迭代一次,学习率也下调5%。整个训练阶段总共迭代46 700 次。
3 实验结果与分析
3.1 数据集
为了评估改进后的网络性能,使用PASCAL VOC 数据集进行验证。该数据集总共包含20 个物体类别,如鸟、人、车、羊、牛、盆栽、沙发、椅子等。在训练阶段,使用PASCAL VOC2007 trainval 数据集和PASCALVOC2012 trainval数据集作为训练集和验证集,总共包含16 551 张图片。在测试阶段使用PASCAL VOC2007 test数据集作为网络评估数据集,总共包含4 952 张图片。
3.2 实验环境
实验过程中使用的显卡为Nvidia Tesla T4,显存为16 GB,采用Pytorch 进行神经网络构建,并为其配置了对应的CUDA 和CUDA 深层神经网络库。
3.3 检测性能比较
采用AP 和mAP 作为算法的性能评估指标。并且与SSD300、Faster R-CNN、DSSD321、ION300等目标检测算法进行对比。各类别检测精度详细结果如表1 所示。通过表1 可以发现,本文网络对各个类别的检测精度都有一定程度的提升。在罗列出的6 种方法中,最高单类别目标AP 值进行了加粗显示,其中DSSD 占有4 项,ION 占有5 项,本文方法占有12项。改进后的SSD 的mAP 比原SSD 提高了2.4 个百分点,比DSSD 提升了1 个百分点,比ION 提升了0.4个百分点。图11 为表1 的数据可视化结果,可以很直观地看到,本文方法基本在每一个类别上都处在最高点,说明本文提出的改进方法具有有效性。

图11 PASCAL VOC2007 test数据集上20 种类别AP 对比Fig.11 Comparison of AP of 20 classes on PASCAL VOC2007 test dataset

表1 PASCAL VOC2007 test数据集上20 种类别检测精度对比Table 1 Comparison of detection accuracy of 20 classes on PASCAL VOC2007 test dataset %
网络的评价指标除了mAP 之外,还有检测速度。为了更全面地比较本文算法与其他主流的目标检测算法的差异,进一步对比了多种算法在PASCAL VOC2007 test数据集上的检测速度和检测精度,结果如表2 所示。从表中可以看出,当输入分辨率相近时,改进后的算法虽然在实时性上有所下降,但是在精度上具有优势。相比同样带有数据增强操作的原始SSD300 算法,本文方法在精度上提升了2.4 个百分点;相比于RSSD300,虽然在精度上只提升了1.1个百分点,但是检测速度远远高于该算法。当网络的输入分辨率大于本文算法时,在检测精度相近的情况下,本文算法具有更快的检测速度,如SSD512算法,在精测精度上与改进后的SSD 网络几乎相同,但是在检测速度上比本文方法要慢很多。综上,说明本文提出的改进方法具有有效性,不仅可以减少漏检、误检,还能保证检测速度,同时满足了高精度和高实时性。

表2 PASCAL VOC2007 test数据集上检测速度和检测精度对比Table 2 Comparison of detection speed and detection accuracy on PASCAL VOC2007 test dataset
3.4 检测结果对比图
为了更直观地显示本文算法的有效性,图12 展示了原SSD 和改进的SSD 方法在PASCAL VOC 2007 test 数据集上的检测结果图,两个算法的训练数据集输入分辨率均为300×300,且训练集均为PASCAL VOC 2007 trainval 数据集和PASCAL VOC 2012 trainval 数据集。图(a1)~(f1)为SSD 算法的检测结果,图(a2)~(f2)为本文算法的检测结果。通过图(a1)、(a2),(b1)、(b2)的对比,可以看到本文算法对行人的检测性能更好;通过图(c1)、(c2)的对比,可以看到本文算法对摩托车的检测性能更好;通过图(d1)、(d2),(e1)、(e2)的对比,可以看到本文算法对牛羊的检测性能更好;通过图(f1)、(f2)的对比,可以看到本文算法对自行车的检测性能更好。
从图12 可以看出,改进后的算法在复杂背景下的检测性能明显优于原SSD 算法,且对于一些相似物体的识别能力更强。图中红色椭圆为错误检测目标示例,如在图12(c1)中,原SSD 算法将摩托车识别成自行车;在图12(e1)中,原SSD 算法将牛识别成羊,而在本文算法中,这两张图片中的目标均被正确识别。另外,从被识别出的物体的置信度还可以发现,改进后的算法识别出的物体的置信度值更高,且当目标被遮挡时,改进后的算法也能准确检测目标。

图12 SSD 与本文算法检测结果对比Fig.12 Comparison of detection results between SSD and proposed method
为了进一步验证本文算法对遮挡目标的鲁棒性,从PASCAL VOC2007 测试集中挑选了100 张含有大量遮挡目标的图片,组成小型目标遮挡检测数据集,使用原始SSD 目标检测算法和改进后的目标检测算法对该数据集进行检测。如表3 所示为检测结果对比,图13 为检测结果可视化。改进后的算法的mAP 值比原SSD 提升了4.7 个百分点,说明改进后的算法对遮挡目标具有鲁棒性。

图13 SSD 与本文算法遮挡目标的检测结果对比Fig.13 Comparison of detection results of occluded objects between SSD and proposed method

表3 遮挡目标数据集上检测速度和检测精度对比Table 3 Comparison of detection speed and detection accuracy on occluded objects dataset
综上,改进后的算法不仅能准确识别出更多的目标数量,且对相似目标的辨别能力更强,对小目标和遮挡目标等困难目标的检测效果也更好。通过上述实验,充分说明改进后的方法有利于改善目标的误检、漏检等情况。
4 结束语
为了解决传统的SSD 算法存在的小目标、遮挡目标等困难目标检测效果差、相似目标辨别性能低等情况,对网络框架进行了改进。首先,在特征输出层之后引入轻量级注意力机制,使网络可以更好地区分背景和目标,从而增强网络对关键信息的辨识能力。其次,针对SSD 的浅层网络存在的缺点,设计了一款新的特征融合模块,将5×5、10×10、19×19 和38×38 这四层特征层自下而上进行有效的特征融合,可以减少融和时因信息差而产生的负面影响。使用公开的PASCAL VOC 数据集对算法进行验证,改进后的网络在PASCAL VOC2007 测试集上的检测精度达到了79.6%,比原始SSD 算法提升了2.4 个百分点,在自制小型遮挡目标数据集上提升了4.7 个百分点,充分证明了改进方法具有一定的时效性和鲁棒性。
由于引入了新的网络模块,增加了模型参数量,导致改进后的网络检测速度有所下降,但是改进后的模型的检测速度仍然满足实时性。本文算法虽然对小目标和遮挡目标的检测性能有一定的提升,但还需进一步完善。在后续工作中,将针对网络的各个模块继续进行优化,全面提升网络的检测性能。
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21 09:35:30
中学生数理化(高中版.高考理化)(2022年5期)2022-06-01 06:27:42
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
疯狂英语·新策略(2019年10期)2019-12-13 08:43:28
当代陕西(2019年10期)2019-06-03 10:12:04
数学小灵通·3-4年级(2017年9期)2017-10-13 08:10:54
传媒评论(2017年3期)2017-06-13 09:18:10
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
文理导航·教育研究与实践(2015年12期)2015-12-04 00:49:23
河南科技(2014年23期)2014-02-27 14:19:15
