
基于模糊规则学习的无监督异构领域自适应
2022-02-23 10:03邓赵红娄琼丹王士同
计算机与生活 2022年2期
孙 武,邓赵红,2,3+,娄琼丹,顾 鑫,王士同
1.江南大学 人工智能与计算机学院,江苏 无锡214122
2.复旦大学 计算神经科学与类脑智能教育部重点实验室,上海200433
3.张江实验室,上海200120
4.江苏北方湖光光电有限公司,江苏 无锡214000
传统机器学习的前提是假设训练集和测试集具有相同的特征空间和数据分布。然而,当两个相关数据集的特征空间或数据分布存在差异时,传统机器学习的训练模型并不能得到满意的效果。因此,解决此类问题的迁移学习被广泛研究。随着迁移学习的关注度越来越高,迁移学习在理论和实践上都取得了很大的进步。领域自适应作为迁移学习的一个分支,在执行两个相似任务的领域之间传递知识。根据特征空间的异同,领域自适应模型可以分为两类:同构领域自适应和异构领域自适应。
同构领域自适应是为了解决源域和目标域之间特征维度相同但数据分布不同的问题。对于目标域中存在部分已标签样本的情况,Aytar 等人提出了一种基于模型的迁移支持向量机算法,Yang 等人提出了一种自适应支持向量机模型,与其相似的是Bergamo 等人也提出一种通过学习自适应支持向量机进行领域自适应的模型。上述几种常见的同构领域自适应方法也被称为半监督同构领域自适应模型。当目标域中都是无标签实例时,具有代表性的模型有TCA(transfer component analysis)、JDA(joint distribution adaptation)和GFK(geodesic flow kernel)等。绝大部分的同构领域自适应模型的目标是最小化两个域之间的分布差异。常见的跨域数据之间度量距离的方式有最大均值差异(maximum mean discrepancy,MMD)、Bregmann 距离、KL 距离和Wasserstein 距离等。
异构领域自适应是为了解决源域和目标域之间特征维度不同且数据分布不同的问题。相比于同构领域自适应模型,异构领域自适应模型的应用范围更广。HeMap(heterogeneous spectral mapping)利用光谱映射将源域数据和目标域数据投影到一个公共子空间,在保持源域和目标域原始数据结构的前提下最大化两个域之间的相似性;DAMA(domain adaptation using manifold alignment)是一种流行对齐的方法,利用标签信息将源域数据和目标域数据映射到一个公共子空间进行学习;ARC-t(asymmetric regularized cross-domain transfer)是一种基于度量学习的方法,通过训练非对称变换将一个域映射到核空间中对齐另一个域;HFA通过学习两个特征变换矩阵,将源域数据和目标域数据分别映射到一个公共子空间,在保持原始特征结构的同时利用标准SVM 分类器进行学习;MMDT(max-margin domain transforms)对目标域数据学习一个线性变换矩阵来对齐源域,并同时优化变换矩阵和分类目标;CTSVM(correlation-transfer SVM)利用核CCA 对两个域中的无标签实例进行特征变换;ADMM(alternating direction method of multipliers)提出了一种基于稀疏特征变换的无监督方法;SFER(shared fuzzy equivalence relations)通过学习模糊等价关系提出了一种无监督异构领域自适应模型。因为异构领域自适应具有更广的普适性,所以本文的重点是研究异构领域自适应。
然而,上述异构领域自适应模型大多数属于半监督的方法,需要借助目标域中部分已标签样本来获得良好的性能。为了拓展异构领域自适应在无监督方法上的应用,本文提出了一种新颖的基于TSK模糊系统(Takagi-Sugeno-Kang fuzzy system,TSK-FS)的无监督异构领域自适应算法(unsupervised heterogeneous domain adaptive with TSK-FS,FUHDA)。(1)本文通过TSK-FS 的模糊前件将源域数据和目标域数据分别映射到两个特征隐空间。(2)本文通过训练两个后件参数矩阵将源域数据和目标域数据线性映射到同一个公共特征子空间。(3)线性判别分析(linear discriminant analysis,LDA)和主成分分析(principal component analysis,PCA)分别被用于减少源域数据和目标域数据因特征变换所造成的信息损失。为了最大化两个域数据之间的相关性,本文还采用了典型相关性分析(canonical correlation analysis,CCA)作为约束项。(4)为了有效减少公共特征子空间中两个域之间的分布差异,本文采用了一种比较流行的MMD 度量方法。为了验证本文算法的有效性,本文将线性SVM 作为基准分类器,通过训练公共特征子空间中的源域数据来测试目标域数据的标签。
本文的主要贡献归纳如下:
(1)提出了一种基于模糊规则学习的无监督异构领域自适应算法(FUHDA)。该算法通过TSK-FS的模糊前件将两个域数据非线性映射到两个特征隐空间,再学习两个后件参数矩阵分别将源域特征隐空间数据和目标域特征隐空间数据线性映射到一个公共的特征子空间。
(2)采用了多种信息保持策略作为约束项来减少因特征变换所造成的信息损失,并且通过CCA 最大化两个域数据之间的相关性。
(3)通过组织大量的实验,证明了所提算法的有效性,实验结果优于现有的异构领域自适应模型。
1 相关工作
1.1 领域自适应相关概念

1.2 TSK 模糊系统
TSK-FS 是一种基于模糊规则的推理系统。因为规则库简单且具有良好的学习能力,TSK-FS 已成功应用于许多迁移学习场景。在特征学习领域,TSK-FS 通过模糊规则将原始特征映射到新的特征空间。在含有条规则的TSK-FS 中,第条规则可定义为如下形式:



当前件参数确定时,TSK-FS 可以将原始特征投影到一个由模糊规则映射的新特征空间。进一步的,式(5)可表示为式(6)中的线性模型:

其中,x表示原始特征向量经过模糊规则映射得到的新特征向量,p表示后件参数向量。在已知x的前提下,p可通过最小二乘法解得。
2 基于TSK-FS 的无监督异构领域自适应
本章提出了一种新的基于模糊规则学习的无监督异构领域自适应方法,即FUHDA。FUHDA 从三方面对变换后的源域数据和目标域数据进行约束。(1)在公共特征空间内,最小化源域数据与目标域数据之间的分布差异;(2)在公共特征空间内,最大化源域数据与目标域数据之间的相关性;(3)在公共特征空间内,分别最小化源域数据与目标域数据的信息损失。因此,本文算法的目标公式可定义为式(8)。

其中,第一项表示变换后的源域与目标域之间的分布差异;第二项表示公共特征子空间中源域数据与目标域数据之间的相关性信息损失;第三项和第四项分别为源域和目标域特征变换后的信息损失。是一个多输出的TSK-FS。
2.1 公共特征子空间的构造
公共特征子空间的构建是学习式(8)的基础。图1 展示了FUHDA 特征变换的具体过程。首先,FUHDA 采用两个TSK-FS。经过模糊前件非线性映射,源域和目标域数据分别被映射到两个特征隐空间。然后,FUHDA 训练两个后件参数矩阵分别将源域隐空间特征和目标域隐空间特征线性映射到同一个公共特征子空间。具体映射过程被定义如下。

图1 基于TSK-FS 的特征变换Fig.1 Feature transformation based on TSK-FS

其中,和分别表示源域数据和目标域数据经过TSK-FS 前件参数映射所得到的新特征。和分别表示多输出TSK-FS 的维后件参数矩阵。则样本x和x经过TSK-FS 特征变换后的输出为式(10a)和式(10b)。

则对于源域数据和目标域数据中的所有样本,经特征变换到公共特征子空间后,可表示为:

需要注意的是,本算法中源域和目标域使用的是两个TSK-FS,因此后件参数和是两个不同的变换矩阵,并且前件参数采用了一种确定性的聚类算法Var-Part分别进行计算。
2.2 分布差异最小化
为了有效地降低源域数据和目标域数据之间的分布差异,本文算法引入最小化边缘分布差异和条件分布差异这两个策略。
首先,本文采用MMD 算法来度量公共特征子空间中源域数据和目标域数据之间的边缘分布差异。MMD 是领域自适应中应用最广泛的距离度量方法,该方法通过映射函数将原始数据映射到再生核希尔伯特空间(reproducing kernel Hilbert space,RKHS)。MMD 通过计算两类分布不同的样本在上的均值差,来判断这两类数据分布之间的差异程度。根据式(10)所构造的映射函数,MMD 函数具体如下:
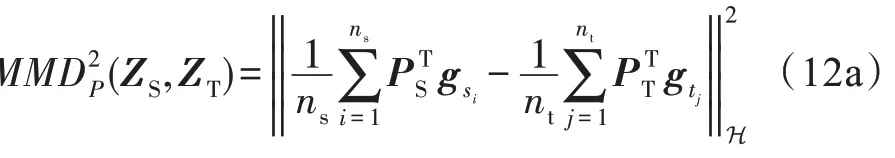
其次,本文采用Long 等人提出的联合分布差异度量方法JDA。该算法利用源域训练的分类器来预测目标域数据,再将预测标签作为目标域伪标签来表示目标域中的类条件分布。通过对伪标签进行迭代更新,该算法能够进一步减小两个领域之间条件分布的差异。因此,本文最小化领域之间条件分布差异的公式可具体如下所示:

通过综合边缘分布差异和条件分布差异这两个角度来最小化源域数据与目标域数据之间的分布差异,则目标式(8)中的第一项即为:

2.3 领域相关性最大化
CCA 是一种常用的降维算法,该算法能够有效度量两组数据之间的相关性,为了有效地最大化源域和目标域数据的相关性,本文采用了CCA 算法作为约束项。这里将式(7e)中的和作为CCA 中的一组投影向量,则CCA的目标函数可以表示如下:
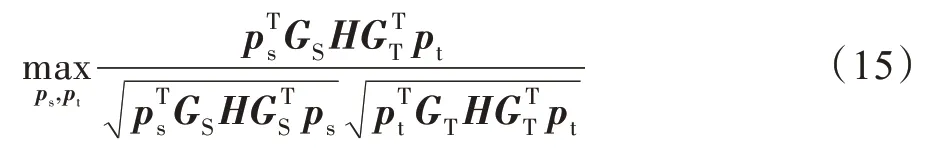
其中,=-(1/)11(==)为中心化矩阵,1 ∈R是元素全为1 的列向量。为了将两个领域数据投影到维空间,将、拓展为式(9e)和式(9f)中的投影矩阵、。因为投影向量的缩放不会影响式(15)中的最优解,所以可将式(14)中的目标函数优化为如下形式:

其中,式(16)中的约束条件作用是限制投影矩阵的大小从而优化其方向。为了同时优化投影矩阵和,可以将式(16)重新定义为式(17)。



2.4 源域判别信息保持
LDA 算法是一种有监督的数据降维方法,该方法通过寻找最优的投影方向使得同类的样本之间距离更近,不同类的样本之间距离更远,同时还能最大化保持原始样本的信息,因此本文采用LDA 算法作为约束项来保持源域数据的判别信息。LDA 的具体优化公式如下:

其中,叫作类间散度矩阵,叫作类内散度矩阵,两者的具体定义如下:


2.5 目标域结构信息保持
因为目标域数据没有标签,所以为了有效地保持目标域数据在特征映射后的结构信息,本文通过最大化目标域数据在映射子空间的方差进行约束。因此,该约束项的目标函数可以表示如下:



2.6 目标函数优化


其中,、、、为权衡参数,用来平衡每项的重要性。式(24)中还通过最小化tr()来防止过拟合。注意,式(24)不因的缩放而影响最终优化结果,因此,目标函数可以重写为式(25):

对式(25)使用拉格朗日函数可得:

令∂/∂=0,则有:

其中,=diag(,,…,ϕ)是含有个特征值的对角矩阵,一般可通过广义特征值分解进行求解。
根据上述公式推导过程,本文算法的具体伪代码如算法1 所示。
FUHDA

输出:目标域数据的预测标签。
1.根据式(2)、式(3)、式(4)、式(7)和式(9)得到两个隐空间数据和;
2.计算式(14c)、式(18)、式(21)和式(23)中的、、、和;
3.for=1,2,…,do
4.根据式(14d)更新M;
5.求解式(27),得到,根据获得变换和;
6.根据式(11a)和式(11b)更新和;

8.end for
3 实验结果和分析
3.1 数据集
为了充分验证本文算法的有效性,本文选取了Office-Caltech 数据集、Wiki 数据集和Reuters 数据集进行了实验验证,每个数据集的具体信息如表1所示。

表1 数据集的统计信息Table 1 Statistical information of datasets
Office-Caltech 由Office-31 数据集和Caltech-256数据集组成,是一个视觉目标识别数据集,该数据集包括4个子数据集:A(Amazon)、D(DSLR)、W(Webcam)和C(Caltech)。这4 个子数据集均具有相同的10 种标签类别,其中A、D 和W 来自Office-31 数据集,C 来自Caltech-256 数据集。在Office-Caltech 数据集的4个子数据集A、D、W 和C 中,每个子数据集可被划分为两个领域(即SURF(800 维)和DeCAF6(4 096维)),分别作为源域和目标域(或目标域和源域)。因此,该数据集可构造8 个迁移任务。
Wiki 数据集是一个文本图像数据集,每个样本都包含了一个图像和其对应的文本描述。这里使用SIFT(scale-invariant feature transform)特征提取方法将图片特征降低到128 维,使用LDA 方法将文本特征降低到10 维。本文把图像和文本领域作为源域和目标域(或目标域和源域),因此,可构造2 个迁移任务。
Reuters 是一个跨语言文本数据集,该数据集中包含了18 758 篇文章,分别选自5 种语言(English、French、German、Italian、Spanish)的6 个类别。本文将English、French、German 和Italian 4 个视角的数据作为源域,Spanish 视角的数据作为目标域。因此,可构造4 个迁移任务。
3.2 实验设置
实验中,本文算法将与6 个对比算法进行比较。其中,Linear CCA、CTSVM、CDLS 是已有的异构迁移学习算法;算法FUHDA-noCCA 是去除CCA 数据相关性约束项所形成的对比算法,用于验证最大化数据之间相关性的有效性;对于算法FUHDA-noSP和FUHDA-noTP,它们是分别去除源域和目标域的信息保持项所形成的对比算法,用于验证信息保持项的有效性。本文将线性SVM 作为基准分类器来检验算法的迁移效果。本文将6 个算法的公共子空间特征维度都设置为100,其他参数设置具体如表2所示。

表2 算法的参数设置Table 2 Parameter settings of algorithms
对比算法的简要介绍如下:
LinearCCA:该算法用线性CCA 对源域和目标域中的实例进行建模,得到一个公共的特征空间。
CTSVM:该算法是一个简化核CCA 方法,通过优化核CCA 对源域和目标域中的实例进行学习,得到一个公共的特征空间。
CDLS:该算法获得一个领域不变的公共子空间,并且学习具有代表性的跨域标记,以达到异构领域自适应的目的。
FUHDA-noCCA:该方法是所提算法的一种变型,去除了CCA 数据相关性约束项。
FUHDA-noSP:该方法是所提算法的一种变型,去除了源域数据的结构信息保持项。
FUHDA-noTP:该方法是所提算法的一种变型,去除了目标域数据的判别信息保持项。
3.3 实验结果分析
本文算法与6 个对比算法在14 个迁移任务中的实验结果具体如表3、表4 和表5 所示。

表4 各算法在Wiki数据集上的准确度Table 4 Accuracy of algorithms on Wiki dataset %

表5 各算法在Reuters数据集上的准确度Table 5 Accuracy of algorithms on Reuters dataset %
由表3 可知,在Office-Caltech 数据集的8 个任务中,所提算法在7 个任务中表现最好,在另外1 个任务中也达到次优的效果。在平均精度上,所提算法与其他对比算法相比也是最优的。对于算法Linear-CCA 和CTSVM,它们只对数据进行特征变换,而没有考虑特征变换所造成的信息损失,因此迁移效果较差。另外,通过与FUHDA-noCCA、FUHDA-noSP和FUHDA-noTP 进行对比分析,证明了本文考虑利用CCA 最大化数据之间的相关性,并且同时引入源域判别信息保持策略和目标域结构信息保持策略的优越性。

表3 各算法在Office-Caltech 数据集上的准确度Table 3 Accuracy of algorithms on Office-Caltech dataset %
由表4 可知,在Wiki 数据集的2 个任务中,所提算法均优于其他对比算法。
由表5 可知,在Reuters 数据集的4 个任务中,所提算法在3 个任务中表现最好,且平均精度在所有任务中也是最好的。
综上所述,本文算法在异构领域自适应任务中能够取得优异的结果,并且证明了相关性约束和多种信息保持策略的有效性。
3.4 参数分析
本节将从Office-Caltech 数据集和Wiki数据集的10 个领域自适应任务中分析算法的收敛性,以及模糊系统的规则数,权衡参数、和对算法准确度的影响。
分析图2 可知,随着规则数的增加,大部分领域自适应任务所获得精度呈现出一种平缓波动的趋势,只有少部分领域自适应任务的精度波动较大。值得注意的是,随着规则数的增加,模型的计算复杂度是呈指数级增长的。而从图2 可以看出,在规则数为3 时,所有任务都能获得较好的效果。因此,综合考虑模型复杂度和算法的性能,本文将模糊系统的规则数设置为3 是合理的。

图2 规则数分析Fig.2 Rule number analysis
图3 展示了10 个领域自适应任务在不同迭代次数下的精度。从图中可以看出,当迭代次数超过6 次时,所有任务的精度趋于稳定。因此,本文实验中将迭代次数设为15 是合理的,并且证明了所提算法具有良好的收敛性。

图3 收敛性分析Fig.3 Convergence analysis
图4 分别展示了在固定其他参数时,改变某一权衡参数、或对实验效果的影响。从图4(a)和图4(b)可以看出,当=2或=2时,大部分任务都能取得一个最优的精度。对于参数,从图4(c)可知,所有任务在区间(2,2)内都能取得较好的精度。

图4 参数敏感性分析Fig.4 Parameter sensitivity analysis
4 结论和展望
本文提出了一种新颖的无监督异构领域自适应算法FUHDA。首先,FUHDA 通过模糊前件的非线性变换将源域数据和目标域数据分别映射到两个特征隐空间。然后,FUHDA 训练两个后件参数矩阵将源域和目标域线性映射到同一个公共特征子空间。为了降低两个域数据之间的分布差异,FUHDA 将最大化两个域数据之间的相关性和相关信息保持策略作为约束项,有效地减少了因特征变换所造成的信息损失,同时也提升了算法的领域自适应能力。通过实验分析,证明了所提算法的优越性。但是,算法还存在一定的改进空间,比如FUHDA 在处理高维数据时,因为TSK-FS 的引入使计算复杂度变高,未来将致力于改进TSK-FS 使算法的计算复杂度降低。
猜你喜欢
中国交通信息化(2022年7期)2022-10-27
小学教学研究(2022年5期)2022-04-28
计算机技术与发展(2020年11期)2020-12-04
电子制作(2019年14期)2019-08-20
商周刊(2019年1期)2019-01-31
读与写·教育教学版(2017年10期)2017-11-10
青年文学家(2015年29期)2016-05-09
南都周刊(2015年4期)2015-09-10
南都周刊(2015年3期)2015-09-10
南都周刊(2015年1期)2015-09-10
