
分布式环境下大规模维表关联技术优化
2022-02-23 10:03赵恒泰赵宇海季航旭乔百友王国仁
计算机与生活 2022年2期
赵恒泰,赵宇海+,袁 野,季航旭,乔百友,王国仁
1.东北大学 计算机科学与工程学院,沈阳110169
2.北京理工大学 计算机学院,北京100081
随着互联网的发展和普及,网络中每天产生的数据量在迅速增加。传统的数据处理方式已经无法面对当前的数据规模,为了获取这些海量的数据中潜在的价值,开发者们提出了大数据处理技术。随着大数据处理技术的不断发展和计算需求的不断更迭,到现在为止大数据处理技术已经经历了三代计算引擎的变化。第一代大数据计算引擎以Apache Hadoop为代表,利用MapReduce进行大数据处理。这一代计算的显著特点基于物理存储的计算模式。这类计算有着非常高的吞吐量,但由于每一步的计算操作都要写入到物理存储中,基于内存的计算速度与磁盘的I/O 开销的不匹配导致了非常高的处理延迟。这一代计算引擎适合处理实时性要求不高的离线批处理任务。这个时代的大数据分析技术以离线分析为主,需要先统计和获取全部数据再进行分析,对分析结果的实时性要求不高,更偏重于对历史数据的总结。第二代大数据计算引擎以Apache Spark为代表,利用内存进行批处理计算。相对于第一代技术,这一代的显著特点是将计算数据移入了内存中,基于内存的数据进行计算。这种基于内存的计算方式大大降低了第一代技术中每一步计算都需要把结果写入磁盘产生的I/O 开销所带来的延迟。但是由于技术仍然是建立在批处理的计算模式之上,每一个批次的数据处理都有一定的时间间隔,在面对一些实时性比较强的计算任务时仍无法保证极低的延迟。这个时代的大数据分析技术逐渐向在线分析靠拢,已经有了对实时数据处理的需求。第三代大数据计算引擎以Apache Flink为代表,是完全基于流计算的数据处理引擎。Apache Flink 所提供的计算平台可以在实现毫秒级的延迟下,每秒处理上亿次的消息或者事件。极高的数据处理能力和极低的延迟,使以Apache Flink 为代表的流计算技术成为了实时大数据分析的首选。越来越多的公司使用流计算技术构建自己的实时数据分析引擎来替代传统的数据仓库分析。在这类数据处理和分析过程中,实时产生的流数据往往信息量不足,需要与离线存储的数据进行关联,扩充数据属性。离线存储的数据称为维表数据,流数据和维表数据进行关联的过程称为维表关联。
维表关联是当前在线大数据分析的关键技术之一。针对维表关联技术在分布式环境下的优化,主要是对维表数据查询进行优化以降低查询维表数据所带来的I/O 开销和延迟。维表关联的数据查询优化主要是通过异步I/O 技术增加单位时间的查询数量和通过使用数据缓存技术将查询到的维表缓存在分布式引擎的计算节点的内存中加速查询。通常有缓存查询结果和缓存整个维表两种缓存模式,其原理如图1 所示。

图1 传统维表关联逻辑Fig.1 Traditional dimension table connection
这两种基于计算节点的优化方式,都存在着各自的不足。数据全部缓存的方式因为内存问题无法支持过大规模的维表。缓存查询结果的方式对每条未缓存数据的处理时间受限于数据库I/O 能力,会随着维表数据规模的增大而线性上升。当数据流速处于一个较低水平,保证数据有效性的缓存超时机制会让每一次数据查询都指向数据库,使本地缓存无效化,降低数据处理效率。
针对单节点优化技术的不足,本文首先提出了一种可以用于离线存储的数据和实时生成的数据进行混合计算的计算模型,然后基于该模型设计了一种新型的维表关联技术优化方案,其原理如图2所示。

图2 优化的维表关联逻辑Fig.2 Optimized dimension table connection
该方案单点读取维表数据,将数据切分后分发到计算节点,然后与流数据进行关联。这个优化方案每个计算节点只需缓存部分维表数据,提高了维表数据的缓存规模,同时大幅降低维表数据查询所产生的消耗。该方案将批处理技术和流计算技术进行了结合,同是对离线的批数据和实时的流数据进行混合计算的一种探究。
本文主要贡献如下:
(1)提出了一种适用于对离线的批数据和实时的流数据进行混合计算的计算模型,该计算模型可以在一套API(application programming interface)中同时处理流数据和批数据,也可以单独处理流数据或单独处理批数据。
(2)提出了一种单点读取维表数据,切分后进行分发和计算的维表关联数据缓存方式,降低了维表数据查询对数据库产生的压力并提高了集群环境中计算系统对维表规模支持的上限。同时针对维表关联计算逻辑进行了优化,使维表关联技术不再局限于对数据的连接。
(3)在流计算引擎Apache Flink 中对该优化的维表关联技术和传统的维表关联技术进行了实现。通过实验对该维表关联技术进行了验证,实验结果对比显示该方法相对于同等条件下传统的维表关联方法,可以使计算任务的吞吐量有8~9 倍的提升,同时在计算能力满足的情况下降低40%以上的计算延迟。
1 相关工作
在过去的几年时间中,针对分布式环境下维表关联操作以及以其为代表的典型的流数据与静态数据交互的计算的优化研究已经存在不少的进展。
为了解决海量数据关联计算问题,文献[9]提出了一种MESHJOIN 算法,该算法优化了单点计算时连续数据流和维度数据的连接过程,但该算法对内存分配的方式不够高效。为此,文献[10]提出了一种改进的算法用于改善内存分配问题。文献[11]提出基于分块思想的算法来提高MESHJOIN 算法的连接性能。文献[12]提出MESHJOIN*算法,该算法采用多线程并发连接技术,并根据工程学原理,实现了连接操作和关系R 读取操作的最佳调度,保证了连接算法效率的最大化,进一步提高连接效率。在MESHJOIN 算法的基础上,文献[13]又提出EHJOIN 算法,对传统散列连接方法进行改进,利用索引将部分频繁使用的主数据存储在内存中,解决了高速数据流下的磁盘频繁访问问题。以上的算法都是基于维度数据的角度对维表连接过程进行优化,没有考虑流数据的倾斜问题,据此文献[14]提出了CSJR(cachedbased stream-relation join)算法,优化了在流数据倾斜环境下的数据连接效率。
在分布式计算引擎领域,大量的开发贡献都来自于社区。而主流的分布式系统Apache Spark 和Apache Flink 都针对维表关联这种场景做出了自己的适配。
Apache Spark 提出了Spark Streaming用以改善计算延迟并提供流计算支持,这一计算模式通过将无限的流数据拆分成离散流(discretized stream),尽可能缩小每个弹性分布式数据集(resilient distributed dataset,RDD)的大小,构建微量批数据集,来达到近似于流计算的效果,这个阶段流计算的延迟在100 ms 级。在Spark Streaming 的技术背景下,Apache Spark 可以将维表数据定义为一个独立的RDD,并缓存到每一个关联节点上,在每一个批次的微量批数据集到达后,以局部批处理的方式进行关联。同时可以对RDD 内容进行更新以达到和离线维表数据相同的状态。以上的更新操作需要用户自己定义更新的逻辑。
由于Spark Streaming 的数据传输是基于微量批数据集的方式进行数据传输而不是真正意义上的持续传输,Spark 又提出了结构化流计算(structured streaming)。在该计算模式中引入了连续处理的概念,将流计算的延迟降低到了1 ms 级的层面。同时Structured Streaming原生地支持了Stream-Static Join,但是其底层的实现逻辑仍是针对每个计算节点进行独立的缓存操作。
Apache Flink 本身是基于流计算的分布式计算引擎,但是为了兼容批处理,仍独立维护了一套用于批处理的DataSet API。Apache Flink 在1.8 版本中并未提供对维表关联计算的官方支持,需要用户通过一些算子手动实现流计算中对维表关联计算的支持。
阿里巴巴公司基于Apache Flink 而构建的开源引擎Blink 在Table API 的层面上提出了维表关联的操作模式,用户需要手动实现对维表数据的查询逻辑。依靠异步查询维表数据并缓存查询结果的方式降低数据库I/O 开销,提高查询效率。该方案的缓存模式有数据全部缓存并定时更新和LRU Cache两种,都是基于计算节点的缓存方式。
以上的维表关联计算设计,实质上都是在流计算过程中直接向数据库发起查询,将查询逻辑都绑定在每个独立的计算节点中,所有的计算节点都要同时访问数据源或缓存完整的维表信息。
在面对高速流数据输入时,异步查询数据库的方式会对数据库造成极大的压力;在面对海量的维表数据时,由于每个计算节点的内存限制,维表数据无法完整地写入内存中并导致执行引擎产生内存异常。
2 维表关联技术的设计与优化
如前所述,现有的大数据计算平台并没有支持缓存水平扩展的维表关联机制。在面对大规模维表数据时,全缓存模式下,维表无法完整地缓存到每一个计算节点中。而使用异步连接方式则会在高速计算时产生大量数据I/O,对数据库造成过大的压力,甚至导致数据库连接超时,失去响应。针对这个问题,本章设计并提出了一种面向大规模分布式计算的维表关联机制。
本章介绍了维表关联技术优化的几个具体设计。首先介绍了一种混合计算模型,做到了在同一个计算任务中统一批数据处理和流数据处理。然后介绍了维表关联技术的缓存优化,包含对维表数据源的缓存设计以及各个计算节点对维表数据的缓存设计。最后介绍了维表关联技术的计算设计,包含对并行计算下的数据分发的处理和每个计算节点对关联计算的处理。
2.1 定义和概念
本节给出了文中所涉及的一些基本定义和概念。
(维表)维表是指存储在外部数据库中的,具有数据规模大、更新时间慢等特征的一类数据表。
(算子)算子是指在计算过程中对数据处理的最小计算单位,不同的算子具有不同的计算逻辑。批处理和流计算拥有功能相同但运行逻辑不同的算子。
(混合计算)混合计算是指在同一个计算任务中,同时存在流计算算子和批处理算子,也被称作批流融合计算。
(维表关联)维表关联指数据流和维表之间存在一定关系,并根据这种关系进行的数据处理,根据关系确定连接信息并将数据表进行组合的过程称为连接。从广义上来看,维表关联包含但不限于连接操作,通过维表数据计算分析等操作也属于维表关联。
(背压)背压指当某个计算节点数据处理速度低于数据传输速度时,接收到的数据产生积压。进而使单个计算节点的输入缓存超出限制,拒绝接收新数据。最终让整个流计算系统从过载的节点开始的一系列上游节点直至数据源节点链式缓存溢出停止接收数据,等待过载节点处理数据。
2.2 混合计算模型
本节介绍本文所提出的混合计算模型。传统的批式计算架构中,计算的运行逻辑如图3 所示。计算节点分阶段启动,每一组计算只有全部完成以后才会解除同步等待,启动下一组计算任务,并将计算数据重新分发到下一轮的计算节点中。
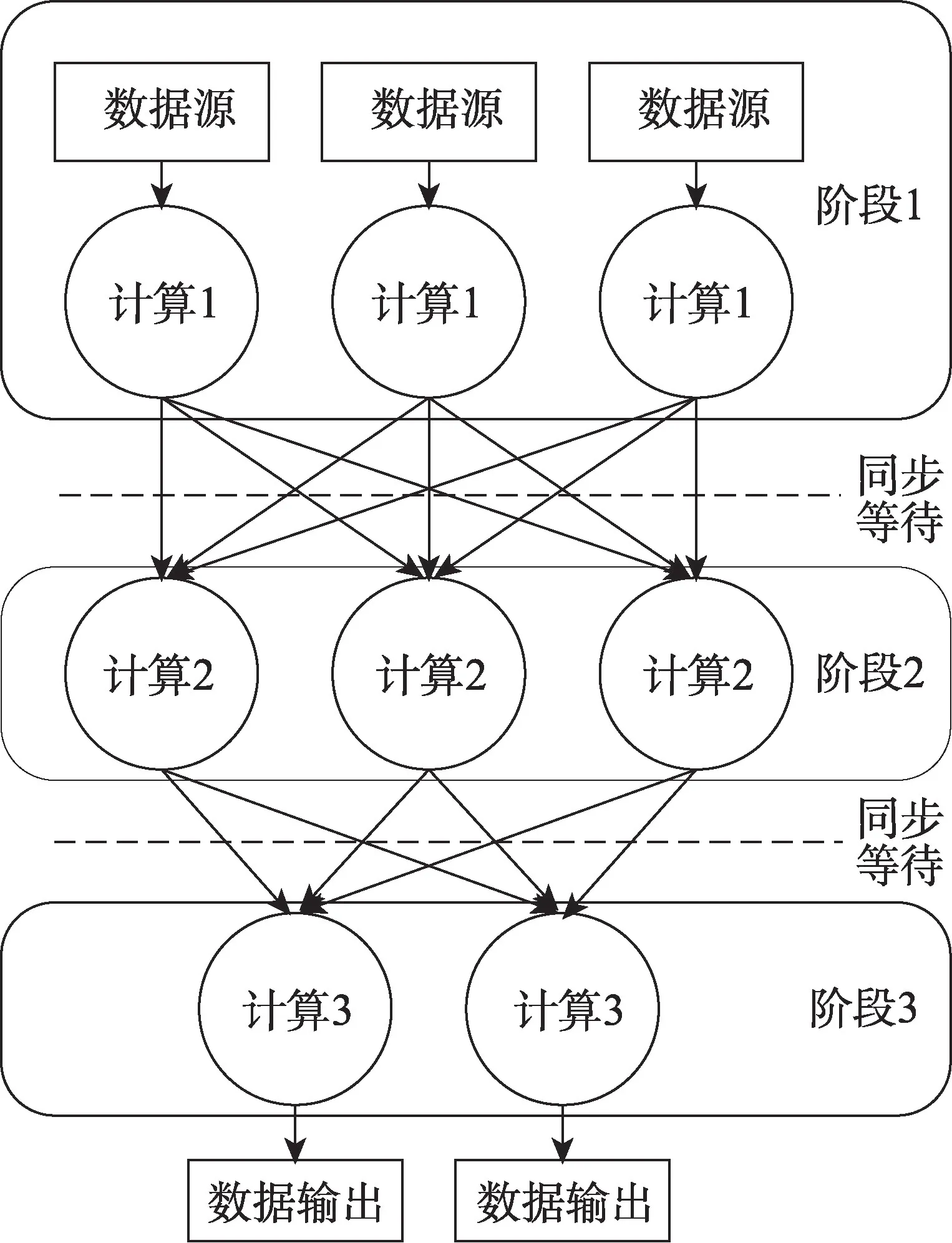
图3 批式计算架构Fig.3 Batch computing architecture
传统的流式计算架构中,计算的运行逻辑如图4所示。所有的计算节点在计算开始时全部创建,然后数据在计算节点之间不断流动,每个节点通过不断拉取和消费上游计算节点的数据,来做到持续不停的流式处理。流计算会尽可能地不进行数据重新分发操作,从而让数据连续处理。

图4 流式计算架构Fig.4 Stream computing architecture
为了做到在流式计算中兼容对批数据的处理,本文对计算算子进行了重新设计。在流计算中构建标志为批处理的算子,进而提出了混合计算模型,如图5 所示。该类模型算子分为三类:流计算算子、批处理算子、混合计算算子。该模型中的流算子仍和传统流计算的计算逻辑一致,随着数据流入实时计算。批处理算子通过修改流计算环境中的数据分发和计算逻辑,做到和传统的批式计算一样效果。混合计算算子用于流数据和批数据的混合计算,上游算子分别为流计算算子和批处理算子。混合计算算子在批数据完全到达之前,会阻塞流计算,等待批数据分发完成以后,开始进行计算。

图5 混合计算架构Fig.5 Mixed computing architecture
2.3 维表关联技术的缓存优化
本节介绍大规模维表关联计算环境下对数据源节点缓存和计算节点缓存的设计和优化。
由于维表数据也是存在变化的,若每次都将读取到的数据全部发送给计算节点,在更新时仍会造成较大的网络传输开销并阻塞流数据的处理。本文参考数据库操作记录日志的思想,在数据更新时只分发需要修改的数据,降低网络传输开销。为了确定数据更新的具体内容,本文根据维表变化缓慢的特性,在数据源处建立了缓存机制缓存已分发数据记录。在缓存机制的键值对中,Key 值由关联所需主键列数据合并得出,Value 值则改为数组,存储主键相同其他数据不同的多版本的维表数据。但缓存完整的维表数据会占用数据源算子过多的内存,无法支持太大的维表。由于数据源并不需对数据进行操作,故而将维表数据拼接成字符串后计算哈希值,并存入对应的数组中,不保存原始数据。
每轮读取维表数据时,将数据主键和哈希值进行缓存,并根据上次缓存结果判断数据分发行为,数据存在则跳过,数据不存在则向下游计算节点发送新增行为,具体算法如算法1 所示。首先通过调用关联信息选择函数构建键值并构建整条数据的哈希值,然后将键值数据和哈希值写入新缓存,最后将键值与旧缓存进行比较,确定数据是否存在,存在则跳过数据并清理对应旧缓存,不存在则发出新增行为请求。
算法1 源节点新数据分发算法
输入:上一次分发所构建的数据缓存,本次数据分发所构建的数据缓存,待判断数据。
输出:无。
1.=buildKey();/*计算缓存主键*/
2.=Hash();/*计算维表哈希值*/
3.将与存入中;
4.If.()
5.If.().()
6.=“”;
7..().();
8.Else
9.Action=“ADD”;
10.End if
11.Else
12.Action=“ADD”;
13.End if
14.If Action==“ADD”;
15.将newData和Action 发送给下游计算节点;
16.End if
在第一次数据分发时旧缓存的初始值为空,因此第一次将会分发所有数据。在数据读取分发完成后,由于在数据读取过程中已经将读取的数据和旧缓存进行了匹配和删除操作,仍存在于旧缓存的数据则全部是需要删除的数据。此时执行针对过期数据的数据删除行为的分发,具体操作如算法2 所示。遍历数据读取完成后的旧缓存,针对旧缓存中的每一条数据生成数据删除请求并发送给下游计算节点,完成过期数据清理。
算法2 源节点过期数据删除算法
输入:上一次分发所构建的数据缓存。
输出:无。
1.遍历,获取每一个对应的列表;
2.遍历列表,获取存储在旧缓存中的;
3.针对每一个,发送=“”的数据删除行为,通知下游计算节点删除过期缓存;
4.清空旧缓存,释放空间.
最后在添加和删除请求都发送完成后将当前缓存赋值给旧缓存,即可完成一轮数据缓存和分发。
在传统的维表关联计算中,对数据的缓存均为Key-Value 的形式,其中Key 值通过关联的主键列计算得出,Value 值保存维表具体数据内容。这种传统的数据缓存模式,无法支持主键相同的多版本的维表数据缓存,进而无法支持对历史维表数据的全量缓存和查询。
本文针对该问题,在计算节点中提出了一种二层缓存策略。在原有的Key-Value 缓存模式下,对Value 格式进行优化,将Key 值相同的维表数据,转换为Json 字符串,并以数组的形式存储于Value 中,使缓存结构支持历史维表数据。同时相较于存储完整的维表结构,转换为Json 字符串可以降低一定的内存存储需求。
在计算节点获取数据的过程中,为了支持优化后的数据源节点的数据分发,数据获取算法也要进行重新设计,具体算法如算法3 所示。对数据变更的行为进行判断,如果是增加数据(ADD)就将数据写入缓存,如果是删除数据(DEL)就根据键值对缓存相关数据进行删除。
算法3 计算节点数据获取算法
输入:节点数据缓存,数据主键,数据文本,数据操作。
输出:更新后的节点数据缓存。
1.If=“”
2.根据存储数据在中;
3.Else
4.If=“”
5.根据,删除中数据;
6.End if
7.End if
8.Return.
2.4 维表关联技术的计算设计
维表关联技术的计算设计分为两部分:数据分区方式设计、数据计算模式设计。
传统的维表关联中,维表数据在各个计算节点间独立存储,因此流数据可以根据不同计算系统的分发策略进行分发,在流经计算节点时向远程数据库查询获取维表数据。全局分发的维表关联策略中,如果流数据分发规则与维表数据分发规则不匹配,则会导致关联结果为空。
因此,为了优化后的维表关联可以正常执行,将对流数据和维表数据的数据分发策略进行重新设计,统一计算出关联主键并对主键进行哈希计算获得对应的数据分区,计算分区方式的算法如算法4 所示。第1 行根据输入的记录通过调用关联信息选择函数构建键值,第2、3 行根据键值计算最终的数据分区。
算法4 Hash 分区算法
输入:待分区的记录,分区数量。
输出:待分区记录的分区编号。
1.key=()/*提取记录的key*/
2.=.;
3.=%;
4.Return.
传统的维表关联计算,通过指定输入数据和维表的主键列确定连接信息,输出的是关联以后的数据列集合。本文首先对数据缓存进行了重新设计,支持了分布式的缓存策略以及多版本的数据缓存。为了适配对多版本数据的连接选择问题,本文将数据关联计算模式进行了重新的设计。将关联逻辑和关联键值选择逻辑进行了抽象,独立出了用户可自行定义和实现的关联计算函数和关联键值选择函数。用户在连接计算的基础上,可以根据实际的计算需求,确定数据流和维表的数据关联键值,并自定义关联的计算输出结果。
由于关联计算函数每次的调用是传入通过关联信息选择函数所获取的全部版本维表数据,用户可以做到对维表关联的灵活处理,以支持指定关联特定历史版本、计算特定关系等需求。
在实际的生产生活场景中,一个典型的不是连接的关联场景为商品关联度计算。通过在计算函数处理输入商品和历史订单中的存在该商品的订单的相似关系,计算出与商品关联的其他商品,从而获得输入商品的关联商品。
3 实验分析
本章针对前文所提出的优化的维表关联技术在Apache Flink 进行了实现,同时也实现了传统的维表关联技术。然后对比和验证了在不同流数据和维表数据规模下,优化的维表关联技术和传统的维表关联技术的效率差异。
3.1 编码实现
编码实现分为传统的维表关联实现与优化后的维表关联实现。
在Apache Flink 1.8.0 中,DataStream API 并没有原生提供对维表关联计算的支持。由于传统的维表关联本质上还是流计算,本文根据计算逻辑,对流计算中的异步计算算子进行了改造,添加的对数据库查询的支持和基于LRU(least recently used)策略的数据缓存机制。然后对该算子进行了封装,使算子支持维表的定义和读取以及连接条件的设置。
优化后的维表关联基于Mixed API 进行实现。通过设计新的双输入算子,使一个输入为流数据,一个输入为维表数据,做到对混合计算的支持。然后单独设计了维表数据的数据源方法,并对系统中原有的数据分发过程进行改造以适应新的数据分发逻辑。最后对整个过程进行了封装,对数据连接信息选择函数和维表关联计算函数进行了抽象和默认逻辑的实现。对于缓存,依托Mixed API 的特性,在批数据计算和分发完成前,流数据处理是阻塞的,保证了维表缓存的完整性。
3.2 数据集
本文针对维表关联这一实际生产活动中所遇到的计算类型,使用了阿里巴巴“双十一”中的真实生产场景进行性能测试。该场景在数据脱敏和业务简化后,共涉及3 个数据表:用户信息表、商品信息表、用户点击数据表。本实验根据数据表格式在MySQL数据库中建立了对应数据表并进行相应的数据生成,数据表数据记录数及数据容量如表1所示。同时根据该表同比例构建了10 万条用户信息数据和100 万条用户信息数据的对应数据表,用于进行对比测试。查询所需的键值列均构建了索引,用于保证异步访问时的查询效率。

表1 数据表大小Table 1 Size of data table
该生产场景的具体业务为对用户进行广告投放,简化业务流程为:
(1)向推荐系统流入用户ID;
(2)系统根据用户ID 获取用户一天内的商品点击数据和用户信息数据,通过机器学习算法计算出推荐商品ID;
(3)通过推荐商品ID 获取商品具体信息并返回。
本实验为专注于测试维表关联效率,简化了推荐计算部分,只保留维表关联部分,修改后的业务逻辑如下:
(1)向测试系统流入用户ID;
(2)根据用户ID,扩展出用户具体信息和用户点击商品ID;
(3)对每个用户点击商品ID 追加一个随机数作为推荐商品ID;
(4)通过推荐商品ID 获取商品具体信息并返回。
3.3 实验环境
本文所描述的相关技术细节,均在Flink 1.8.0 中进行实现,采用Java 语言进行编写。实验的运行环境及软硬件环境如下。
(1)硬件环境。实验采用的分布式环境由4 台服务器组成,1 台主节点,3 台从节点。从节点采用的服务器配置为:①CPU Intel Xeon E5-2603 V4 *2,核心数目6 核心;主频1.7 GHz。②内存64 GB,主频2 400 MHz。③硬盘400 GB SSD。主节点配置为:①CPU Intel Xeon E5-2603 V4 *2,核心数目6 核心;主频1.7 GHz。②内存128 GB,主频2 400 MHz。③硬盘400 GB SSD。
(2)软件环境。①操作系统Centos 7;②存储环境MySQL 5.6.45;③Apache Flink 版本1.8.0,JDK 版本1.8.0。
3.4 实验结果与分析
本文通过使用阿里巴巴所提供的advertising测试工具,通过修改其中业务计算部分的逻辑来进行测试。该测试会在计算开始和结束时对数据添加时间戳并写入Redis,然后通过对Redis 中的数据进行分析获取相关统计结果。本实验所有计算的并行度固定为12,忽略维表全缓存的冷启动时间。生成100 万条流数据作为实验1,生成1 000 万条流数据作为实验2,对比流数据的数据量和维表的数据量对计算吞吐量和延迟的影响。
(1)吞吐量对比分析
吞吐量(throughput)是指单位时间内计算引擎所处理的数据量,反映了系统的负载能力。吞吐量越高,系统的极限负载就越大,有助于在单位时间内处理更多的数据。本实验通过计算在Redis 中单位时间写入的数据量来统计吞吐,吞吐量计算公式如下:

其中,代表当前读到的数据编号,表示前一次读到的数据编号,表示读取当前数据表编号所对应的时间,表示读取上一次数据编号所对应的时间。
在实验1 中,不同规模的维表数据量所产生的数据平均吞吐量如图6 所示。实验结果表明数据全量缓存可以有效提升计算吞吐量,在三种维表规模下,均有10 倍的提升。异步连接方式随着维表数据增大,吞吐量呈现下降趋势。经分析得出,这是由于异步连接所构建的缓存没有被命中,还有大量查询打入了数据库中。数据查询所用的时间延长了每条数据的处理时间,使单位时间内可以处理的数据量减少。

图6 实验1 平均吞吐量统计Fig.6 Statistics of experiment 1 mean throughput
在实验2 中,不同规模的维表数据量所产生的数据平均吞吐量如图7 所示。与实验1 相同,全缓存方式吞吐量统计结果相似,说明数据处理效率已经和流入数据量无关,增大并行度可以进一步提高吞吐量。随着维表数据增大,异步连接吞吐量趋于稳定。这种现象的产生是由于流数据量增大,短时间内查询到的维表数据已经全部加载到了本地缓存中。异步计算方式吞吐量仍处于较低水平是异步连接机制并发度不足导致的,然而过高的并发度会在计算初期直接导致存储系统连接崩溃。

图7 实验2 平均吞吐量统计Fig.7 Statistics of experiment 2 mean throughput
(2)延迟对比分析
延迟(latency)是指数据从进入计算系统到真正被处理并输出所使用的时间,单位为毫秒(ms)。延迟的大小反映了系统对数据的处理速度和实时性。实时推荐的广告系统对延迟有较高的需求,延迟越小,用户体验越好。本实验通过在Redis中记录的每条数据的起止时间戳来计算延迟,延迟计算公式如下:

表示数据被处理完成的时间,指数据流入系统后被标记的时间。
在实验1 中,不同规模的维表数据量所产生的数据平均延迟如图8 所示。全缓存模式下,数据都已经写入到内存中,没有数据I/O 开销,因此平均延迟没有太大的起伏。异步连接的计算模式由于前期没有维表数据的缓存,需要与数据库进行大量的交互,随着维表规模的增大,单次查询的处理时间越来越高,导致平均延迟越来越大。

图8 实验1 平均延迟Fig.8 Experiment 1 mean delay
在实验2 中,不同规模的维表数据量所产生的数据平均延迟如图9 所示。全缓存模式下,延迟相对于实验1 有所增加是由于为了平摊内存压力,多次维表关联计算间没有共享计算槽,数据分发需要经历序列化与反序列化。过高的吞吐量和数据量导致数据传输压力过大,从而产生阻塞。同时由于缓存机制是手动实现的,没有对接Flink 计算系统的背压机制,导致计算节点数据过量积压。异步连接模式由于计算前期的大量I/O 已经暂时缓存了所有需要的维表数据。多次维表关联共享了计算槽,数据传输不需要经历序列化和反序列化过程,直接发给下游计算节点。同时由于Apache Flink 的背压机制,数据实际被标记的流入系统的时间可能晚于数据实际产生的时间。

图9 实验2 平均延迟Fig.9 Experiment 2 mean delay
4 总结
本文对面向分布式流计算的维表关联技术进行了研究和优化。与现有的大数据计算平台的关联机制相比,首先提供了一套可以实现流批处理一体化的数据处理逻辑,其次提供了一种可以支持纵向扩展的维表关联数据全缓存方案,并对数据分发进行了优化。大量实验结果表明,该优化技术可以有效提高全缓存条件下对维表数据的加载量,在高速处理环节最多可以提高10 倍的吞吐量,显著降低了数据的查询压力,提高了任务的并行度。在维表数据量较大的情况下,异步查询方式在高并行度时会有很大概率导致数据库假死,并且由于数据I/O 的关系,无法做到很高的吞吐量。普通全量缓存模式则直接会导致系统产生内存溢出异常。本文所提出的维表关联技术,支持在高并行度下运行,并且对数据库造成的读写压力不随并行度提高而提升。
猜你喜欢
心理学报(2022年4期)2022-04-12
云南大学学报(自然科学版)(2022年1期)2022-02-21
能源工程(2021年6期)2022-01-06
建材发展导向(2021年12期)2021-07-22
北京大学学报(自然科学版)(2021年3期)2021-07-16
电脑爱好者(2020年19期)2020-10-20
校园英语·上旬(2020年1期)2020-05-09
智富时代(2019年4期)2019-06-01
智富时代(2019年4期)2019-06-01
卷宗(2017年16期)2017-08-30
