
深度学习的人-物体交互检测研究进展
2022-02-23 10:03:02阮晨钊张祥森赵增顺
计算机与生活 2022年2期
阮晨钊,张祥森,刘 科,赵增顺
山东科技大学 电子信息工程学院,山东 青岛266590
随着信息技术的发展,计算机已经能够协助人们完成很多工作,帮助解决人们无法解决的难题,甚至在某些领域已经可以取代人类。图像是人类获取信息的主要形式,有80%的信息都是以图像的形式获取的。常见的图像任务,如目标检测、动作识别和图像分割等都属于计算机视觉任务的范畴。而近几年,这些任务也随着深度学习在计算机视觉领域的深入应用得到了快速发展。在此基础上针对个体对象更高层的图像语义研究,如人的动作识别、姿态估计等也取得了较为明显的进步。但是仅凭这样的个体对象识别还远远不能理解图像中发生的事情,还需要识别出不同对象之间的关系。由于人与物的交互占据了大多数的人类活动,检测和识别每个人与周围物体的交互方式对于有效理解图像内容十分重要,这个任务被称为人-物体交互检测,主要目的是定位人体、物体,并识别它们之间的交互关系。简单来说,就是检测图像中的<人体,动词,物体>三元组,如图1 所示。这样的输出能够帮助回答很多与图像相关的问题。它可以告诉更多关于图像中描绘的场景的当前状态,帮助更好地预测未来,还能够反过来帮助理解动作。人-物体交互检测(human-object interaction,HOI)技术已经被运用在监控视频的自动识别检测中,识别检测出视频图像中的异常行为,做到及时预警。此外,该技术对于智能交通、信息检索以及人机交互等诸多领域的研究有重要帮助。

图1 HOI检测任务实例Fig.1 Examples of HOI detection
拥有广阔研究前景的同时,这个问题的研究也是具有挑战性的,因为图像中可能包含多个执行相同交互的人,同一个人可能同时与多个物体交互,同一个物体可能同时与多个人交互以及细粒度交互等。这些复杂多样的交互场景都会给设计HOI 检测解决方案带来相当大的难度。本文围绕着基于深度学习的人-物体交互检测技术,主要对以下几点进行了综述:(1)人-物体交互检测任务的提出;(2)人-物体交互检测关键方法类别和发展现状;(3)人-物体交互检测的评价指标和常用数据集。
1 HOI检测方法
从2009 年开始,陆续出现了与HOI 检测相关的研究,这些早期研究主要使用了手工制作的局部特征,通过捕捉这些特征将其分到特定的类别中。这些基于手工制作的特征主要是颜色、HOG和SIFT。其中Gupta 等人研究使用贝叶斯模型来进行HOI分类,Yao 等人使用人和物体之间的上下文关系,Delaitre 等人使用具有空间交互和上下文的结构化表示,Desai等人使用合成模型,Hu 等人则是参考了一组HOI 样本。但是在这些早期的HOI 识别研究中都没有在HOI 检测中进行直接评估,其中文献[8,11,13]首先进行动作分类,然后进行人与物关系的判断;文献[9]是目标检测之后进行评估;文献[12]是基于人体姿势的结果进行评判。该技术真正快速发展是在2015 年以后。
随着深度学习的发展,计算机视觉的性能得到了极大的提升,人们可以从规模庞大的数据集中提取特征而不是局限于手工提取的特征,加之专门用于HOI检测的数据集的出现,HOI检测任务迎来了新的发展阶段。2015 年,Gupta 和Malik 提出了首个用于HOI 检测的数据集,并且提出了“视觉语义角色标注”这一概念,对这一任务进行了明确的定义:推理图像中细粒度的动作并检测出与该动作相关的语义角色(使用边界框标记出动作区域以及做出这个动作人与物)。其首先真正解决了人-物体交互识别检测问题。
Chao 等人于2018 年提出的基于人-物体区域的卷积神经网络(human-object region-based convolutional neural networks,HO-RCNN)对HOI 检测的研究具有十分重要的意义。它是一个多流网络结构,包含三个流:一个人流、一个物体流以及一个成对流。其中人流和物体流分别编码人和物体的外观特征,而成对流的目的则是编码人和物体之间的空间关系。值得一提的是它没有直接将边界框坐标作为输入,而是提出了交互模式这一特殊类型的深度神经网络(deep neural networks,DNN)输入,用来描述两个边界框的相对位置。这个模型首先使用人体和物体检测器生成人体-物体区域对的建议,然后将每个人-物对的建议送入卷积神经网络以生成HOI 分类分数,再将三个流中的分数以后期融合的方式进行融合,最后根据动作得分进行交互识别,网络结构如图2所示。
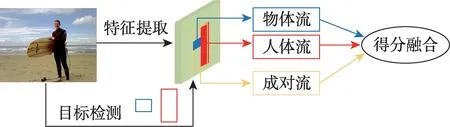
图2 多流网络模型Fig.2 Multi-stream model
这一经典的多流网络结构是两阶段方法的开端,同时为后续研究提供了基准和思路,后来出现的很多方法是在它的基础上进行深入研究。例如,加入注意力机制、使用图模型、引入人体姿态或身体部位信息。
1.1 两阶段方法
两阶段方法的思想就是把HOI 检测任务分为目标检测和交互推理两个子任务。目标检测阶段使用预训练的目标检测模型检测图像中的人和物体,然后将其逐一匹配为成对的建议,而交互推理阶段则是根据人-物体对的特征来推断交互。近两年的方法大多使用多流体系结构来进行交互推理。
通过关注早期预测进而对结构化输出进行建模的想法在以前被成功地应用于各类计算机视觉和自然语言处理任务中。一些突出的例子包括机器翻译模型、图像字幕、语音识别和人体姿态估计。注意力也被融入到HOI检测的方法中。
Georgia等人于2018年提出了一个以人为中心的模型InteractNet 来识别人与物的交互,通过扩展Faster R-CNN 模型,增加了一个分支,对目标对象位置上的动作和特定动作的概率密度估计进行分类。Kolesnikov 等人提出了一种用于检测视觉关系的联合概率模型BAR-CNN(box attention R-CNN),使用链式规则将概率模型分解成两个更简单的模型:第一检测模型定位输入图像中的所有目标;对于每个检测到的目标,第二个模型检测与该目标交互的所有其他对象。该模型的核心是框注意机制,该机制增强了第二个模型的能力,使其能够专注于第一个检测模型定位的对象。具体来说,就是将第一个模型检测到的对象表示其空间位置的二进制编码,这些编码作为第二检测模型的附加输入。该方法没有引入新的超参,并且在数据集上取得了不错的效果。
与BAR-CNN 通过单独分析人和物体而不考虑两者之间关系的思路不同,Gao 等人认为除了需要人、物的外观特征以及人-物体对的空间特征以外,还需要上下文信息来识别HOI。因此,在HO-RCNN 的基础上,他们提出的用于人机交互检测的以实例为中心的注意网络(instance-centric attention network for human-object interaction detection,ICAN)采用以实例为中心的注意力模块来提取与局部区域(人/物框)的外观特征互补的上下文特征,以提高HOI 检测效果,而不是像HO-RCNN 那样只是简单地用DNN 来提取特征,ICAN 模块如图3 所示。与之前手动设计的上下文特征的方法(基于姿势、整个图像或次要区域的交互检测方法)不同,ICAN 的注意力图是自动学习的,并与网络的其余部分联合训练,以提高性能。此外,与为图像级分类设计的注意力模块相比,ICAN的以实例为中心的注意力图提供了更大的灵活性,因为它允许根据不同的对象实例关注图像中的不同区域。
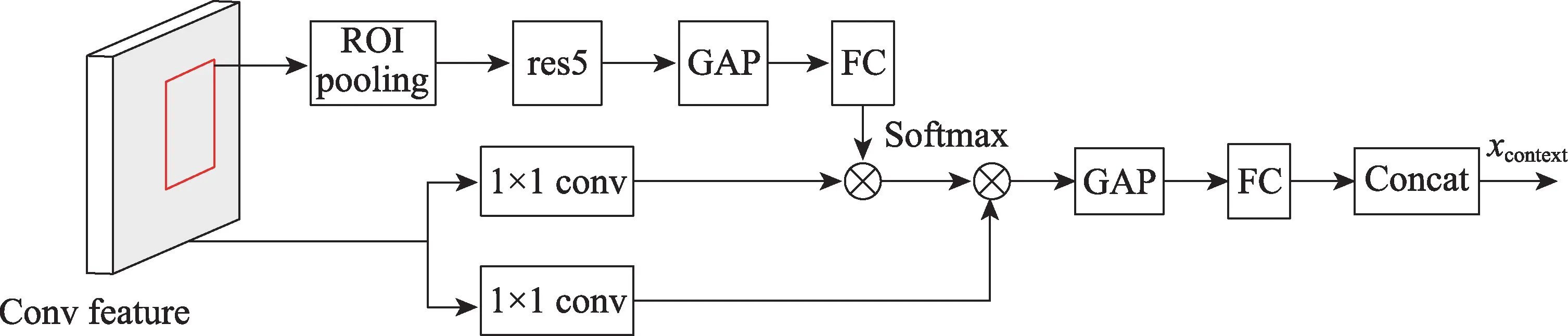
图3 ICAN 模块Fig.3 ICAN module
Wang 等人提出的用于人-物交互检测的上下文注意框架与ICAN 使用标准外观特征构建注意力图不同,他们使用上下文外观特征构建注意力图,并且注意力图集中在人和物体分支中的相关区域,这些区域可能包含人和物体的相互作用。此外,对于单个和多个人-物交互,与ICAN 模型相比,这个方法能够产生更多的固定注意力图。该方法也是基于HORCNN 框架,在人流和物体流中引入了上下文感知的外观模块和上下文注意模块。其中上下文感知的外观模块产生由外观和上下文信息编码而成的上下文外观特征;注意力模块抑制全局上下文产生的背景噪声,同时保留相关的上下文信息,自适应地选择相关的以实例为中心的上下文信息,以突出可能包含人-对象交互的图像区域。
注意力机制的加入有效提高了HOI 检测模型提取上下文特征的能力,使模型的检测效果得到了很大的提升,尤其是ICAN,其准确率比HO-RCNN 提升了一倍,但是由于其分支结构与HO-RCNN 相比并没有明显变化,仍然只是利用人与物体的视觉特征以及空间特征来进行推理判断。除此以外并没有额外信息的加入,因此其准确率还有较大的提升空间。
利用图模型或者图卷积是解决HOI 检测问题的一个重要思路。已经有一些工作将网络结构与图形模型集成在一起,并在场景理解、目标检测与解析和视觉问答(visual question answering,VQA)等应用中取得了可观的结果。在HOI检测中,图模型的基本思想是用节点表示人和物体,用边表示人和物体间的交互,人与物体间的交互相关性越大,则边的强度就越高。
Qi 等人首次将图模型和神经网络整合到一起来实现HOI 识别,他们提出了一个图解析神经网络(graph parsing neural network,GPNN),它是消息传递神经网络(message passing neural network,MPNN)的推广,继承了神经网络的学习能力和图形模型的表示能力。相较于之前的研究,能够更好地解释并明确地利用空间和时间相关性以及人-物关系,其示例如图4 中的上图所示。不同于大多数以前图形或结构化DNN 模型采用预固定图形结构的方法,为了寻求更好的泛化能力,图解析神经网络引入了一个重要的连接函数来解决图结构学习的问题。它学会以端到端的方式推断邻接矩阵,因此可以推断出明确解释HOI 关系的解析图,从而迭代学习并推断图形结构和消息传递。将人和物用节点表示,它们的关系定义为边。以节点和边缘特征作为输入,并以消息传递方式输出解析图。
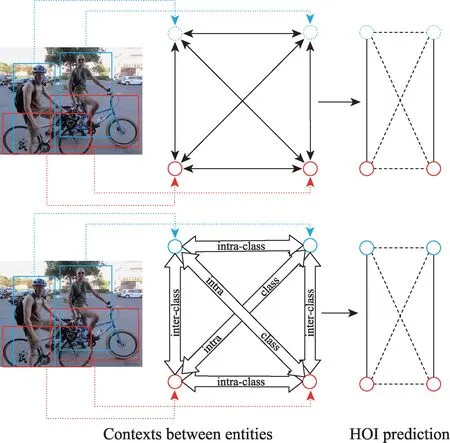
图4 GPNN 与上下文异构图网络区别Fig.4 Difference between GPNN and context heterogeneous graph network
GPNN 将人和物用相同类型节点表示的方法并不够完善,因为在HOI 中人和物体所扮演的角色不同(人是交互的主体,物是交互的客体),活动场景中异构实体(人和物)之间存在类间语境,而同构实体(人与人、物与物)之间存在类内语境,这意味着它们之间的关系不尽相同。基于这一考虑,Wang等人在2020年提出了一个上下文异构的图网络,将人和物用不同的节点表示,同时人和物体的空间关系是识别交互的基本信息,因此它被编码到连接异构节点的边中。连接同类节点的边表示类内上下文,反映同类节点的相关性,连接异类节点的边表示类间上下文,反映交互性,其示例如图4 中下图所示。此外,他们还将上下文学习与图注意力方法相结合,以提高节点从其邻居节点收集知识的有效性。
吴伟等人利用图结构对图像中潜在的HOI 进行建模,并通过引入注意力机制的特征处理网络将图像上下文信息融入到图节点的特征表示中去,最后联合图注意力网络(graph attention network,GAT)对真实的HOI 加以推断。Liang 等人也使用了GAT,他们发现大多数工作仅使用来自单个人-物对的局部特征进行推断,很少有学者研究如何通过图网络来消除附属关系的歧义,也很少有人研究如何有效地利用视觉线索以及包含在HOI中的内在语义规则。他们构建了一个视觉语义图注意网络(visualsemantic graph attention networks,VS-GATs),这是一个并行聚合视觉空间和语义信息的双图注意网络,它通过注意力机制有效地从主要的人-物关系以及附属关系中动态地聚集上下文视觉、空间和语义信息,具有很强的消除歧义能力。
由Ulutan 等人提出的视觉空间图网络(visualspatial-graph network,VSGNet)在传统的三分支网络上进行了改进,不仅利用了人-物体对的空间配置来细化视觉特征,还加入了图卷积分支。其中视觉分支从人-物对中提取人的特征、物的特征以及上下文特征,空间分支使用人-物对的空间配置来细化视觉特征,图卷积分支使用图卷积结构连接,图形卷积使用交互提议分数作为人-对象节点之间的边缘强度。最后,由三个分支的交互建议得分共同推理交互动作。
然而,Zhang 等人对VSGNet 进行测试发现,当使用一次以上的消息传递迭代时,它的二分图本身的性能要差得多。于是他们推测这是因为邻接值没有适当地标准化,导致节点编码被传入的消息所支配。而在他们提出的用于检测人-物交互的时空注意力图神经网络(spatio-attentive graphs,SAG)中,消息传递算法没有显示出这种问题,并且更加稳定。与现有的分离外观和空间特征的方法不同,他们的方法将这两个线索融合在一个图形模型中,使用它们共同推理交互,允许以两种形式为条件的信息影响与相邻节点的交互预测,从而消除在视觉上相似但空间上不同的交互之间的歧义。
Gao 等人先使用抽象的空间语义表示来描述每个人-物体对,然后利用双重关系图(dual relation graph,DRG)来聚合场景的上下文信息,其中一个以人为中心,一个以物体为中心。该模型能有效地捕捉来自场景的区别性线索,以解决局部预测时的歧义。不同于从其他物体、身体部位或场景背景中聚合上下文信息的方法,DRG 利用不同HOI 之间的关系来细化预测。
图模型的强大推理能力对于HOI 检测有重要的帮助,但是像GPNN 与VSGNet,只是简单地根据人与物体的视觉特征来构建图模型,这样的表示方法存在一定的局限性,它们不仅忽略了两者在交互中扮演着不同的角色,也没有考虑如何使用其他的信息来完善图模型。吴伟等人通过引入注意力机制的特征处理网络来完善图模型的构建,VS-GATs 与DRG 则是根据不同的信息分别构建了两个不同的图模型来共同分析这一问题。除此之外,GAT 也在一些方法中被应用进来。
现有的研究表明,仅仅依靠人和物的外观特征以及两者的空间关系远远不能满足HOI 检测的需要。因此,一些研究开始引入额外的信息以提高HOI检测的精确度,其中人的身体部位和姿态就是一种重要的信息。
传统方法将人体视为一个整体,并对整个身体区域给予相同的关注,但是它们忽略了通常情况下人类只使用身体的某些部分与物体进行交互。2018年,Fang 等人认为不同的身体部位应该得到不同的重视,并且不同身体部位之间的相关性也应该进一步考虑,这是因为身体部位总是协同工作,于是他们提出了一个新的成对的身体部位注意模型,其结构如图5 所示。它可以通过学习来关注关键部位以及它们之间的相关性,用来进行HOI 识别。对于人体部位及其成对相关性,使用成对感兴趣区域(region of interest,ROI)池化,将成对的身体部位的联合特征映射池化,并舍弃其他身体部位的特征。此外,该模型首次将注意力机制应用于人体部位相关性来检测HOI。
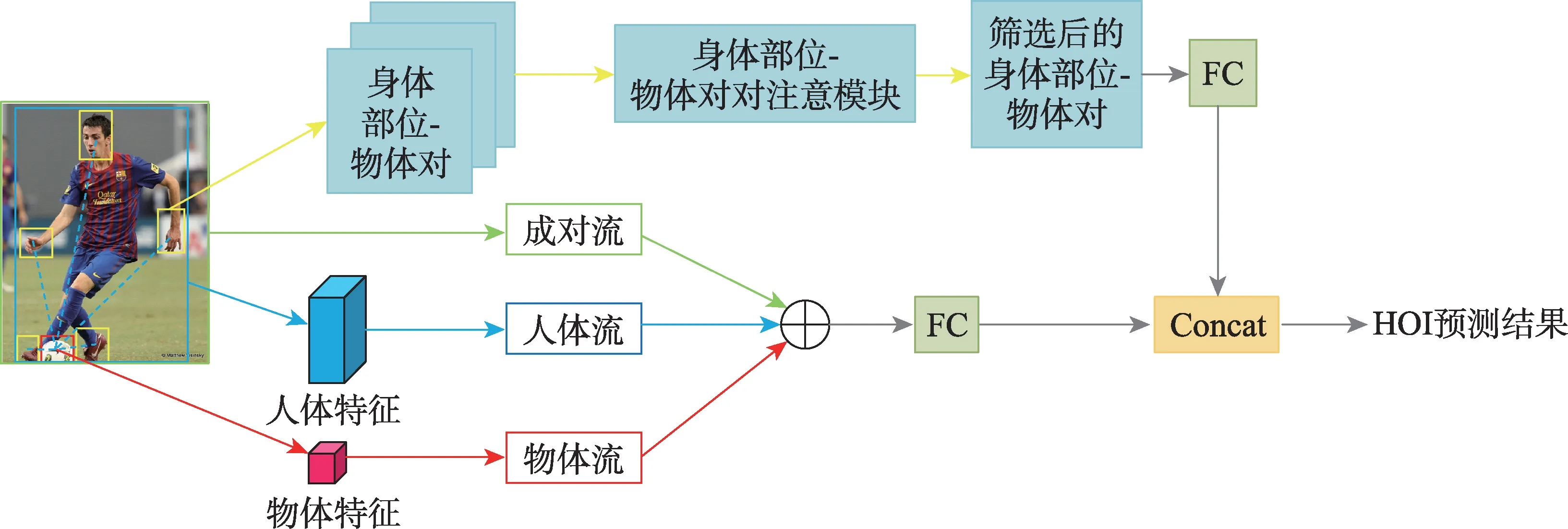
图5 成对的身体部位注意模型Fig.5 Model of pairwise body-part attention
虽然交互性是HOI 检测的一个基本要素,但是它可以用于提高网络检测性能的作用往往被忽视,并且与具体的HOI 类别相比,互动性包含更多的基本信息,而这种属性使得交互性更容易在数据集之间传递。受到这一启发,Li等人提出了一种交互识别方法TIN(transferable interactiveness knowledge network),其核心思想是利用交互网络从多个HOI 数据集学习一般的交互知识,并在推理过程中的HOI 分类之前执行非交互抑制(non-interaction suppression,NIS)。也就是说,在HOI 分类之前,就明确区分非交互对并抑制它们,从而减少过多非互动候选对造成的干扰。交互网络使用人、物体和空间姿态流从人和物体的外观、空间位置和人的姿态信息中提取特征,然后三个流的输出连接起来并输入到交互鉴别器中。由于交互性提供了额外的信息来帮助HOI 分类,并且独立于HOI 分类之外,这使得它拥有良好的泛化性从而可以跨数据集传输,并且可以与任何HOI检测模型相结合,从而增强为不同HOI 环境设计的HOI模型。
相较于上述两种只是将人体姿态作为人体部分和物体之间的空间约束的方法,Wan 等人考虑到人-物体外观和空间配置的巨大差异以及相似关系间的细微差异,于2019 年提出了姿态感知多级特征网络(pose-aware multi-level feature network,PMFNet),它利用人体姿态线索来捕捉关系的全局空间配置,并作为一种注意力机制来动态放大人体部分级别的相关区域的多级关系检测策略。具体来说,使用一个多分支深层网络来学习三个语义层次上的姿态增强关系表示,包括交互上下文、目标特征和详细的局部线索。
Zhou 和Chi则是将图模型与身体部位相结合,提出了关系解析神经网络(relation parsing neural network,RPNN),该网络由两个基于注意力的图表示,一个是动态捕捉身体部位和周围对象之间关系的物体-身体部位图,一个是推理人体与身体部位之间关系的人-身体部位图,并组合身体部位上下文来预测动作。RPNN 引入了详细的身体部位特征,并且模型结合了用于特征细化的图结构,而不是GPNN 中的基于粗略的人/物体外观特征来扩展可学习的图模型以获取强有力的表示。它与以实例为中心的图像注意ICAN 不同,该研究认为物体和身体部位才是需要注意的最有趣的区域。因此,基于检测到的身体部位和对象,明确引入物体-身体部位注意机制和人体-身体部位注意机制来聚焦感兴趣的对象和身体部位区域。相较于成对的身体部位注意模型为身体各部分之间的配对关系建模,RPNN 则是把重点放在了对物-身体部分对以及人-身体部分对之间的关系进行建模。此外,这是第一个在HOI 检测中关注身体部位和物体之间的成对相关性的研究。
Liu 等人认为PMFNet 和RPNN 的成对特征不够全面,导致不能更好地模拟身体部分和对象之间的微妙交互,而他们于2021 年提出的多级成对特征网络(multi-level pairwise feature network,PFNet)包含更全面的成对特征,主要有三个组成部分(身体部分的视觉特征、物体的视觉特征及其相对空间配置)。此外,当对象被部分遮挡时,对象的语义标签可以作为可靠的先验以及对象外观的替代。Sun 等人也发现了PMFNet 和RPNN 中存在的不足。首先,它们使用在目标检测数据集上经过预训练的卷积神经网络(convolutional neural networks,CNN)主干来提取用于HOI 推理的视觉特征,导致交互短语(人-物对的联合区域)和单个物体的外观分布存在显著的偏差。此外,它们根据检测到的实体和人体部分的边界框裁剪多级CNN 特征,以捕获详细的视觉线索,尽管利用了先前的位置信息,但是CNN 的特征仍然仅仅来源于图像。基于这两点,Sun 等人提出了一个多层次条件网络(multi-level conditioned network,MLCNet),旨在将额外的显性知识与多层次视觉特征相融合。他们构建了一个多分支CNN 作为多层次视觉表示的主干,然后通过仿射变换和注意机制,将包括人体结构和对象上下文在内的额外知识编码为条件,以动态影响CNN 的特征提取,最后融合调制的多模态特征来区分相互作用。
Liang 等人则是提出了基于姿态的模块化网络(pose-based modular network,PMN),该模块由一个独立处理每个关节相对空间姿态特征的分支和另一个使用图卷积更新每个关节绝对姿态特征的分支组成,最后把融合处理后的特征,送入动作分类器进行分类。该模块能够与现有网络完全兼容,并在性能上有显著的提高。
融入身体部位和姿势的方法在准确率上已经取得了很好的效果,虽然提取的上下文特征有利于特征表达,但是额外的注释和计算是不可或缺的,带来了很大的工作量和计算负担,并且基于姿态的方法离不开预先训练的人体姿态估计器,它对硬件设备的要求会更高。而TIN 与PMN 可以与不同方法进行结合,相较于其他方法灵活得多。
1.2 一阶段方法
两阶段的HOI 检测方法已经取得了很大的进展,但其缺陷也很明显,由于需要将检测到人和物体先配对再进行交互预测,会产生高昂的计算代价且灵活性不足,其效率和有效性都受到其串行结构的限制。随着一阶段目标检测器的发展,开始有一阶段的HOI 检测器被提出。现有的单级HOI 检测器将HOI检测公式化为并行检测问题,它能够直接从图像中检测HOI 三元组,一步到位的方法在效率和效果上都有较大的提高。
2020 年,Liao 等人提出了首个实时的一阶段HOI 检测方法PPDM(parallel point detection and matching),这一方法使用检测框的中心点表示人和物体点,用人点和物体点间的中点表示交互点。该模型使用两个并行分支分别进行点检测和匹配,其中点检测分支预测人、物体以及交互点,点匹配分支预测从交互点到其对应的人点和物体点的两个位移。源自同一交互点的人点和物体点被视为匹配对,而不太可能形成有意义的HOI 三元组的孤立检测框则会被抑制,增加了HOI 检测的精度。此外,人和物体检测框之间的匹配仅应用于有限数量的过滤后的候选交互点,节省了大量的计算成本。
受到无锚框物体检测研究的启发,Wang 等人也用点的思想解决HOI 检测问题,通过将人和物体之间的相互作用定义为相互作用点,将HOI 检测视为相互作用点估计问题,这是首个把HOI 检测作为关键点检测和分组问题的方法,被称作IP-Net(interaction point)。基于交互点,该方法学习生成关于人和物体中心点的交互向量,并进一步引入了一种交互分组方案,该方案将交互点和向量与来自检测分支的相应的人和物体边界框预测配对,以产生最终的交互预测。
与前两个基于点的方法不同,Kim 等人提出的面向实时人机交互检测的联合检测器(union-level detector towards real-time human-object interaction detection,UnionDet)是把从主干网络获得的特征金字塔同时送到联合分支和实例分支。在联合分支直接捕获交互区域的同时,实例分支执行传统的目标检测和动作分类,以获得更细粒度的HOI 检测结果。它不同于将每个目标对送入单独的神经网络来关联目标检测结果,而是使用提出的联合检测框架直接检测相互作用的人类对象对。这消除了在物体检测之后对繁重的神经网络推理的需要,并且其能够在现有物体检测器的基础上以最小的额外时间检测交互。UnionDet 还能与现有的单阶段目标检测器兼容,如SSD、RetinaNet和STDN,并且是端到端可训练的。
Chen 等人于2021 年提出的基于自适应集合的一阶段框架(adaptive set-based one-stage framework,AS-Net)与之前方法都不同。PPDM 与IP-Net 都是基于点的方法,在每个交互关键点执行推理,例如每个对应的人-物体对的中点;UnionDet 则是基于框的方法,根据每个联合框预测交互。而AS-Net 将HOI 检测表述为一个集合预测问题,具有并行的实例分支和交互分支,突破了现有方法以实例为中心和位置为中心的限制,通过聚集来自全局上下文的交互相关特征,并将每个基本事实与交互预测进行匹配,该网络在特征聚集和监督两方面都表现出了自适应能力。此外,它的实例感知注意模块有助于增强有指导意义的实例特征,并且还引入了语义嵌入来提高性能。
针对以上介绍的不同HOI 检测方法,表1 分析了各类方法的优点、缺点、适用场景等。
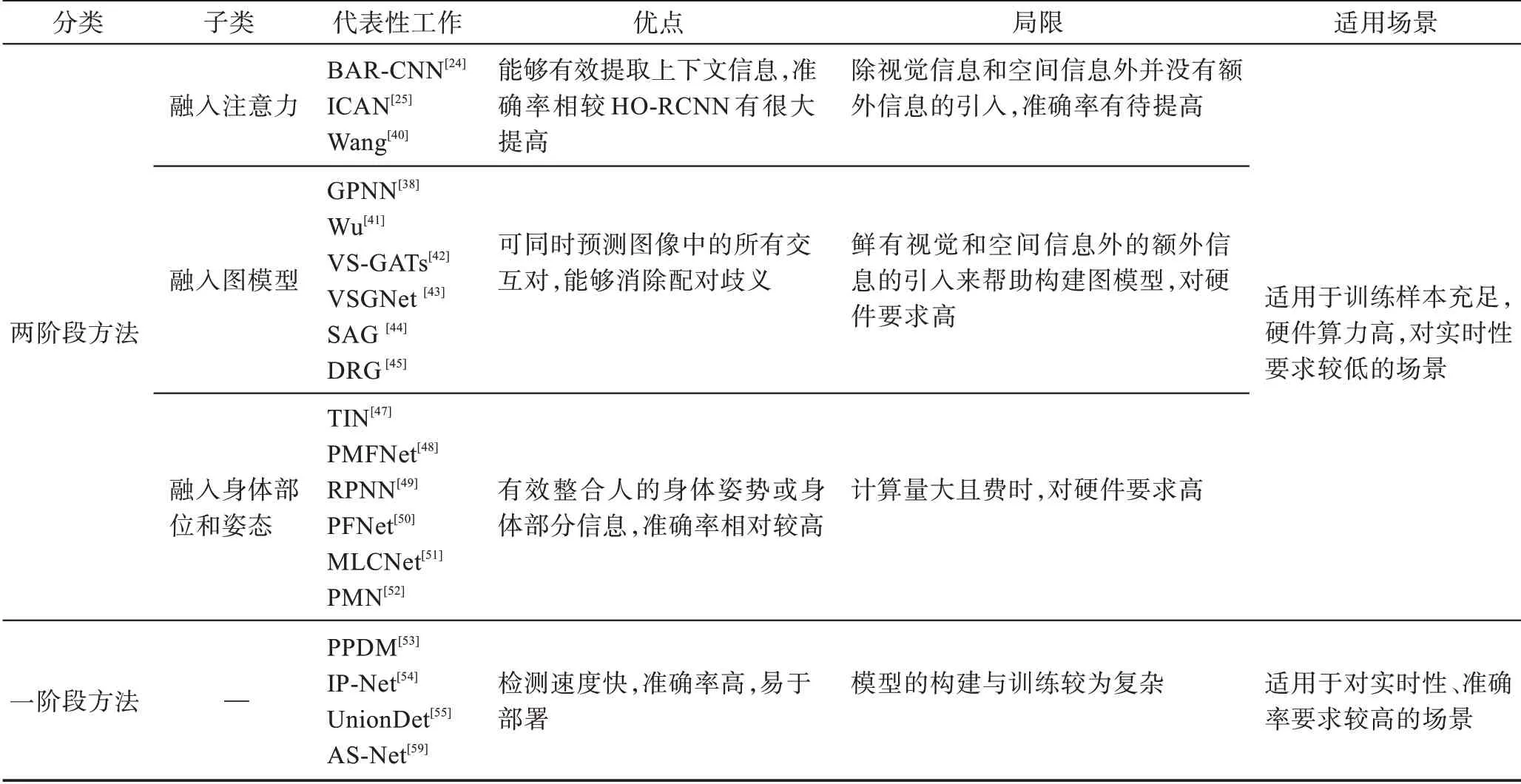
表1 不同HOI检测方法比较Table 1 Comparison of different HOI detection methods
2 数据集与评价指标
2.1 数据集
V-COCO(verbs in common objects in context)数据集派 生自Microsoft COCO 数 据集,是Gupta 等人使用AMT(Amazon mechanical turk)通过连接相互作用的人和物体并标记它们的语义角色扩充MSCOCO 而来。它由含2 533 幅图像的训练集、2 867 幅图像的验证集和4 946 幅图像的测试集三部分组成,其中训练集和验证集图像来自COCO 的训练集,测试集图像来自COCO 的验证集。V-COCO 数据集总共有10 346 幅图像,其中包含了16 199 个人的实例,每个带注释的人有26 个不同的二进制动作标签,同时含有80 个对象类别。过去大多数的数据集中每个人只有一个动作标签,每幅图像只有一个带注释的人,而V-COCO 中的人平均有2.87 个动作标签,平均每张图片上有1.57 个被标注了动作标签的人,约有2 000 张含两个人的图像,800 张含3 个人的图像。同时V-COCO 中的所有图像都继承了COCO 中的所有注释,使得它可满足各种研究任务的需求。
HICO-DET 数据集是一个专门用于HOI 研究任务的大型基准数据集,是Chao 等人在2018 年提出的,他们通过在AMT 上设置注释任务来收集实例注释,从而扩充只有图像级注释的HICO(humans interacting with common objects)数据集。HICO-DET比V-COCO 更大,也更多样化,共有47 776 幅图像,其中38 118 幅用于训练,9 658 幅用于测试,有超过15万个人类实例与600个HOI类别。同时,HICO-DET数据集包含与MS-COCO 相同的80 个对象类别。
虽然V-COCO 数据集与HICO-DET 数据集在近几年一直是评估HOI 检测任务的基准数据集,但是Liao 等人考虑到在实际应用中V-COCO 数据集与HICO-DET 数据集里需要特别注意的出现频繁的HOI 类别有限,于是构建了HOI-A(human-object interaction for application)数据集。HOI-A 数据集由38 668 个带注释的图像组成,其中包含11 种交互物体和10 种交互动作。具体来说,它包含43 820 个人体实例,60 438 个物体实例和96 160 个交互实例。此外,为了扩大数据的类内变化,HOI-A 数据集中每种类型的交互分为室内、室外和车内三种场景,包括了黑暗、自然和强烈的三种照明条件,以及各种不同的角度。
2.2 评价指标
在目标检测任务中,如果算法预测的目标边框与真实边框(ground truth)重叠部分的交并比(intersection over union,IoU)大于0.5,则会被认为是真阳性(true positive,TP)。HOI 检测任务在此判别基础上进行了修改,认为只有同时满足以下条件才能被判定为真阳性:(1)预测的人类边框与其真实边框(ground truth)之间的IoU 大于或等于0.5;(2)预测的物体边框与真实的物体边框之间的IoU 大于或等于0.5;(3)预测出的人与物体之间的交互动作与标签标注的真实发生的交互动作一致。
遵循目标检测的标准评估标准,使用平均精度(mean average precision,mAP)来评估HOI 检测,它是AP(average precision)的平均值。要计算AP 需要用到混淆矩阵,如表2 所示。表2 中TP(true positive)表示模型的预测结果和样本的真实类别一致均是正例;FN(false negative)表示模型预测的结果是反例,而样本的真实类别是正例;FP(false positive)表示模型预测的结果是正例,而样本的真实类别是反例;TN(true negative)表示模型的预测结果和样本的真实类别均是反例。
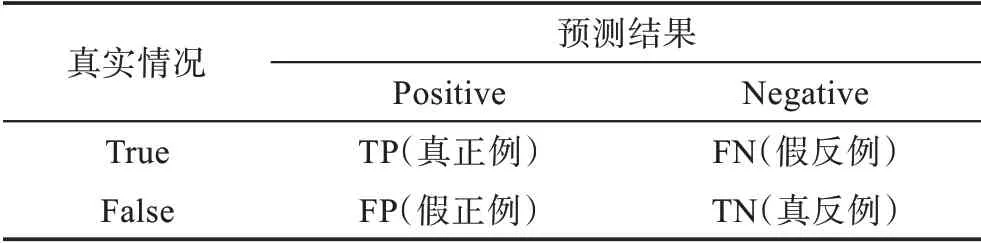
表2 混淆矩阵Table 2 Confusion matrix
准确率(precision)指的是真正的正样本占人-物体交互检测模型预测出的全部正样本的比例。定义如式(1)所示:

召回率(recall)指的是在所有真实的正样本中,人-物体交互检测模型预测为正确的正样本所占的比例。定义如式(2)所示:

AP 指的是所有准确率的和占该类别的图像数量的比例,它衡量的是在单个类别上模型判断结果的好坏。定义如式(3)所示:

其中,表示,表示,()是一个以为参数的函数,函数的积分表示的是平均精准率,该公式表示的AP 值也可以看作是PR(precision-recall curve)曲线以下部分的面积。PR 特征曲线,即准确率-召回率曲线,在目标检测、显著性检测等领域有广泛的应用。
mAP 指的是平均精确率(AP)的平均值,它衡量的是在所有类别上模型判断结果的好坏。定义如式(4)所示:

其中,表示HOI类的总数。
2.3 结果与分析
本文所述HOI 检测模型在V-COCO 数据集和HICO-DET数据集上的测试结果分别如表3、表4所示。

表3 V-COCO 数据集测试结果Table 3 Results on V-COCO data set
与最早使用V-COCO 进行测试的文献[15]相比,后面出现的方法在平均准确率上都取得了较高的提升,两阶段方法中融入注意力的方法将mAP 提升到了40%以上,融入人体姿势和身体部位的方法由于加入额外的信息与融入图模型方法准确率大都高于50%。一阶段方法中基于框的UnionDet 的准确率略低于基于点的方法的准确率。AS-Net不仅是一阶段方法中准确率最高的,与本文提到的其他方法相比,它也是效果最好的。
需要注意的是,在HICO-DET 数据集上提供了两种设置:(1)已知对象设置(Known Object),对于每个HOI 类别,仅在包含目标对象类别的图像上评估检测;(2)默认设置(Default),对于每个HOI 类别,在整个测试集上评估检测,包括包含和不包含目标对象类别的图像,这显然是更具难度的。这两种设置下都包含了full、rare、non-rare 三种类别,full 表示数据集中的全部600 个HOI 类,rare 表示138 个少于10 个实例的HOI 类,non-rare 表示462 个拥有10 个或更多实例的HOI类。
与在V-COCO 数据集上的结果类似,一阶段方法在HICO-DET数据集上也表现出了很好的结果,ASNet不仅在各种设置下都表现出了最高的准确率,并且明显领先于其他方法,而其他方法之间则没有如此明显的差距。
目前HOI 检测网络主要从以下两方面进行改进提升:
(1)替换主干网络。主干网络用于提取图像特征,提取图像特征是HOI检测的一个重要环节,从表3、表4 中可以看出,大多数模型使用的特征提取主干网 络是ResNet或是在其基础上融入特征金字塔(feature pyramid networks,FPN)、可变形卷积网络(deformable convolutional networks,DCN),也有方法使用CaffeNet、Hourglass-104来提取特征。
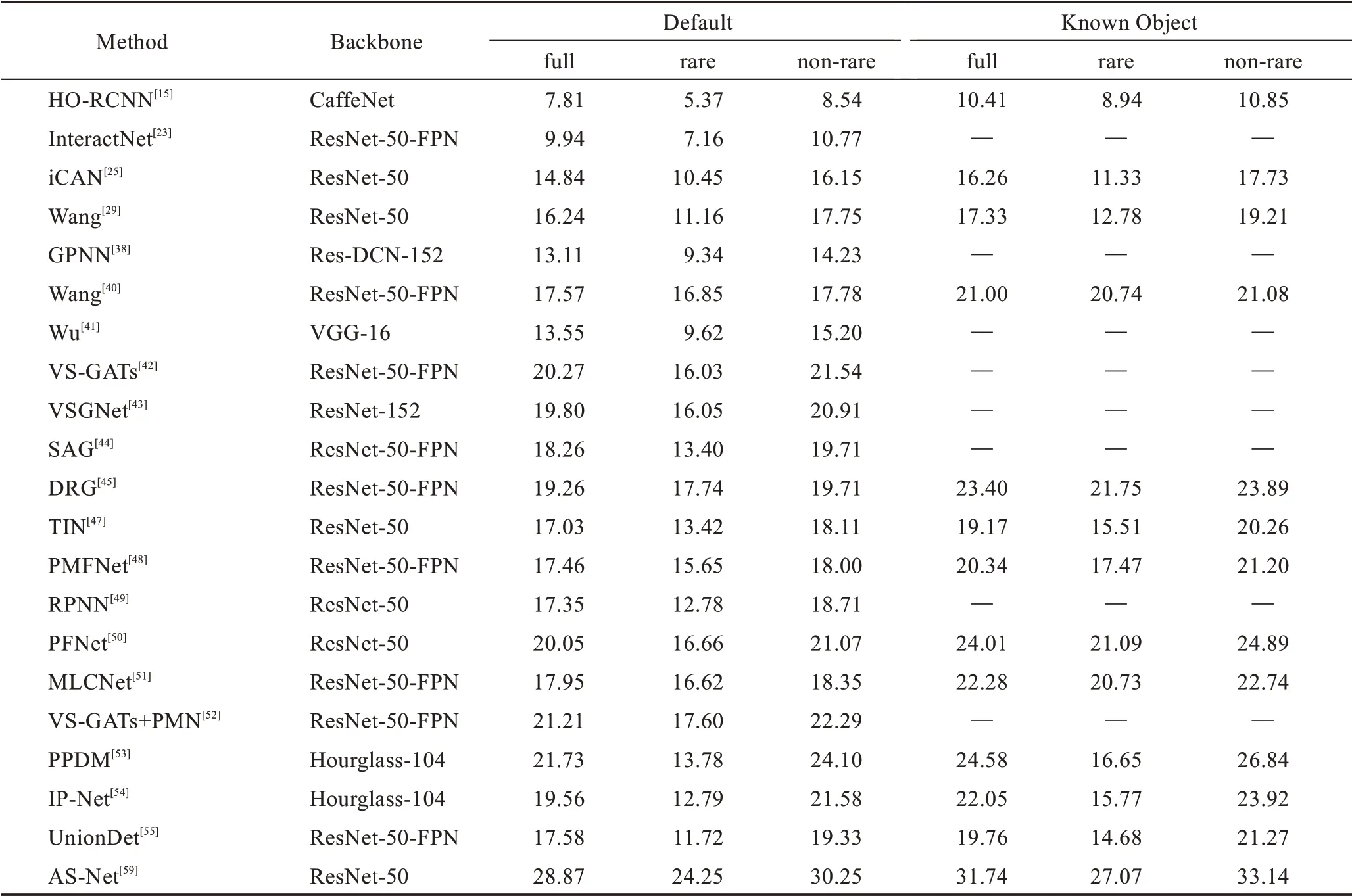
表4 HICO-DET 数据集测试结果Table 4 Results on HICO-DET data set %
(2)融入额外的信息。例如加入人体姿态与身体部分信息可以提升模型的理解能力。此外,也有像一阶段方法一样,使用新思路来解决HOI 检测问题的方法出现。
3 目前挑战和未来发展趋势
3.1 主要挑战分析
(1)数据集中不同类别间的实例样本数量不平衡,一些常见的交互具有丰富的样本,而一些不常见的交互甚至只有不到10 个样本,这大大增加了训练难度,还会造成过拟合。
(2)由于一张图像中往往含有多个人和物体,若是将所有人和物体的组合穷举出来再逐对进行推理判断,则会给计算资源带来巨大的负担。
(3)两阶段模型虽然取得了不错的准确率,但是受其串行结构的限制,并不能用于对实时性要求较高的场景。
(4)目前的HOI 检测模型主要基于V-COCO 和HICO-DET 等少数几个公共基准数据集进行训练和测试,虽然有的数据集中的类别有几百个,但是由于缺少种类少而样本多的专门针对某种特定场景的数据集,无法训练出应用于特定使用场景的模型。
3.2 未来发展趋势
自2018 年HO-RCNN 出现以来,两阶段的HOI检测方法已经被广泛研究且逐渐趋于成熟,其中包括使用注意力机制、图模型以及引入身体部分和姿势等,而且最近的方法也不再仅仅是使用其中一种,而是融合两种或多种。就平均精确率来看,两阶段方法已经取得了不错的结果。
(1)在两阶段方法中,图网络的强大的推理能力非常适用于解决HOI 检测任务,但大多数以前的工作未能利用图形中的空间关系信息。因此,如何引入其他信息来完善图模型的构建还有较大的研究空间。
(2)与两阶段方法相比,一阶段方法更快、更高效,不需要在不同阶段之间切换模型,也不需要保存或加载中间结果,更容易在实际应用中部署,并且还拥有不输两阶段方法的准确率,在将来势必会成为HOI 检测领域的重要研究方向。此外,使用它扩展处理一些相关问题,如视觉关系检测和多目标跟踪等也是值得研究的方向。然而,刚刚起步的一阶段方法仍然有许多需要解决的问题,比如需要复杂的后期处理来对目标检测结果和交互预测进行分组,对相互作用区域或点的定义仍然相对粗糙等。因此,如何简化后期处理以及怎样处理好与交互区域相关的语义歧义是未来研究中亟需解决的问题。
(3)近两年有研究旨在直接解决不同类别样本数量不均衡所造成的长尾(long tail)问题以及人-物对组合爆炸问题,Shen 等人提出了一种弱监督模型,首次将零样本学习(zero-shot learning)扩展到HOI识别中,实现对数据集中未出现过的HOI类别的识别。Ji 等人提出的少样本HOI 检测方法SAPNet与DGIG-Net也能有效解决这两个问题。由于少样本的HOI 检测是为直接解决HOI 检测中最重要的两个问题而设计的,是解决HOI 检测问题必要深入研究的重要方向。
(4)为了能够更好地将HOI 检测技术应用于现实中的特定场景,迫切需要更多像HOI-A 这样包含更具针对性动作的或更具实际意义动作的数据集来进一步推动这项技术的发展与应用。在评价指标上,随着一阶段方法的兴起,除了模型的准确率外,检测速率也将会成为用于评价模型的重要指标。
4 结束语
随着深度学习和目标检测技术的发展,HOI检测技术得到了快速发展。本文将HOI 检测技术分两阶段方法与一阶段方法分别进行阐述,其中将两阶段方法分为三类着重进行介绍,而一阶段方法是2020年开始出现的,目前的研究相对较少。目前HOI 检测技术已经在多个领域发挥其作用,相信在将来,人-物交互检测技术会吸引越来越多研究者的目光,并且会有越来越多的突破性的进展出现。后续将会对使用图神经网络的HOI检测方法进行深入研究,同时也会对一阶段方法进行持续研究以提高模型的检测效率。
猜你喜欢
黑龙江大学自然科学学报(2022年4期)2022-11-17 08:08:06
作文小学中年级(2020年6期)2020-07-24 08:33:10
中学生数理化·高一版(2020年1期)2020-02-20 13:24:32
疯狂英语·新策略(2019年10期)2019-12-13 08:43:28
当代陕西(2019年10期)2019-06-03 10:12:04
中学生数理化·八年级物理人教版(2018年10期)2018-12-06 09:33:16
数学小灵通·3-4年级(2017年9期)2017-10-13 08:10:54
科普童话·百科探秘(2015年4期)2015-05-14 07:06:42
河南科技(2014年23期)2014-02-27 14:19:15
自然资源遥感(2014年3期)2014-02-27 11:56:38
