
社交网络中一种基于偏好的隐私度量方法研究
2022-02-22 01:04路太宇李晓会张馨予吕维新
辽宁工业大学学报(自然科学版) 2022年6期
路太宇,李晓会,张馨予,吕维新,邓 倩
社交网络中一种基于偏好的隐私度量方法研究
路太宇,李晓会,张馨予,吕维新,邓 倩
(辽宁工业大学 电子与信息工程学院,辽宁 锦州 121001)
针对现有社交网络中的度量模型很少考虑到用户的主观感受,导致度量不准确等问题,提出了一种结合隐私偏好的隐私度量方法。对用户属性的可提取度、获取难度和隐私偏好度进行量化,使用CMDPC(coefficient of variation and multi cluster merging strategy density peaks clustering)算法对用户进行聚类,结合属性的敏感度,得到用户的隐私分数。利用用户属性的隐私偏好度反映了用户主观感受。CMDPC算法对用户进行聚类提升了效率和准确性,实现了对用户属性的快速准确度量。实验结果表明,该模型反映了用户的主观感受,并提高了度量结果的时效性和准确性。
隐私度量;CMDPC算法;隐私偏好度;社交网络
随着科技的高速发展和社交软件的普及,在社交网络上与朋友分享生活、讨论新闻等成为了人们的日常。社交网络已经融入到人们的生活,加快了信息获取和分享速度。社交网络中的用户将自己的属性上传到网络,让服务商根据特定的属性给自己带来更好的服务。近些年,大数据、云计算和人工智能逐渐兴起,利用数据挖掘技术对用户的隐私属性进行获取、分析变得更加简单,不法分子使用一些手段分析出用户的隐私信息,造成隐私泄露。隐私保护[1]技术应运而生,隐私度量[2]作为隐私保护的重要支撑,在社交网络中对用户属性进行隐私度量的研究变得格外重要。通过隐私度量框架,度量出用户的隐私分数,让用户知道自己的隐私状态来增强用户的隐私意识。
如今越来越多的学者开始注意到社交网络中隐私度量的问题,早在2010年,Li等[3]使用项目响应理论和信息传播模型,提供一种可以计算出OSNs中用户隐私分数的方法,该方法考虑用户个人资料中的属性信息,以用户为中心解决社交网络中的隐私保护问题,并利用实验证明该方法的可行性。Jain等[4]以用户为中心设计了一个在OSNs中计算用户隐私指数的框架,该指数代表了用户是否知道自己个人信息中所蕴含的个人信息。Aghasian等[5]考虑到多个社交网站的共享信息对用户隐私信息的影响,通过确定影响隐私泄露的主要因素,使用应用统计和模糊计算提出了社交网络用户隐私泄露评分(privacy disclosure score,PDS)的方法。张盼盼等[6]提出了对隐私偏好进行定义和量化,提出了基于隐私偏好的博弈度量模型,全面考虑了隐私偏好对服务商的影响。彭长根等[7]基于Shannon信息论提出了4种隐私度量模型,引入了隐私泄露度量和背景知识的隐私泄露度量,并且提出了带主观感受的信息熵隐私度量,以用户为中心是社交网络隐私度量的核心,随着科技的发展带主观感受的隐私度量模型已经被学者们重视。
考虑到用户的主观感受和用户间的内部关系,提出了一个基于隐私偏好的属性度量方法,利用隐私偏好度反映了用户主观感受,使用变异系数改进的DPC算法处理用户间的内部关系。因此,该算法不仅对量化后的属性信息依据密度进行快速准确地聚类,而且该算法利用合并分配策略提高了聚类的速度和准确率。
1 相关概念
本节主要阐述一些基本定义及相关概念,包括IRT模型[8]、DPC算法[9]、变异系数[10]、多簇合并分配策略[11]、社交网络中用户属性的提取难度[12]、可获取度[12]和用户隐私偏好度[13]。
1.1 IRT模型
项目反映理论(item response theory,IRT)模型起源于心理学,被应用于分析考试成绩的数学模型。目的是衡量考生的能力、问题的难度和考生正确回答给定问题的可能性。通过该模型获得提取难度、可获取度和用户隐私偏好度。
1.2 CMDPC算法
(1)DPC算法
密度峰值聚类算法是根据密度对样本进行聚类的算法。该算法原理简单,能够处理任意非球型类簇,并能快速有效地确定聚类中心点和类簇个数。DPC算法定义了2个重要的概念:局部密度,距离值
算法主要分为2个部分:确定聚类中心点,分配非中心点。
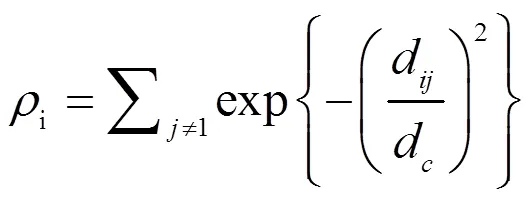

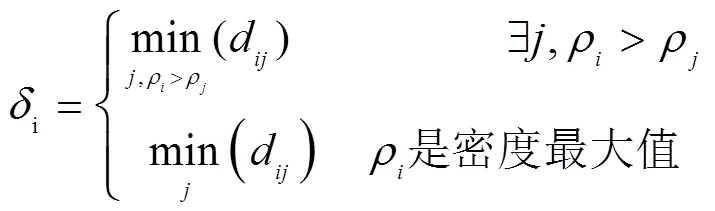
在上述公式中,d是样本点X、X的欧式距离,d为截断距离,手工设定其值时需考虑样本的近邻数大约是整个数据集规模的1%~2%[14]。距离是数据点与密度最大点欧氏距离的最大值,小于距离的所有样本构成该密度最大的数据集群。与其中一个密度最大的数据点的距离是最大的,该数据点一定是类中心点,经过反复迭代将样本点分配到各个密度最大数据点的数据集群中。
再分配中心点过程中,如果数据点X不是类中心点,则将其归入密度比X大且距离X最近的数据点X所在的类。该过程只需执行1次,没有迭代更新。传统的DPC算法未考虑到样本的内部结构和分配策略会产生分配连带错误导致后续一连串样本分配错误。利用变异系数和多簇分配策略解决这2个问题。
(2)变异系数
在高维数据集中欧氏距离仅能反映出2个样本

和
之间的直线距离,每个维度对最后对聚类的影响是相同的,不能完全反映样本点之间的相似性。变异系数考虑了数据的分布情况,利用变异系数对欧氏距离加权提升了高维数据的聚类准确性。
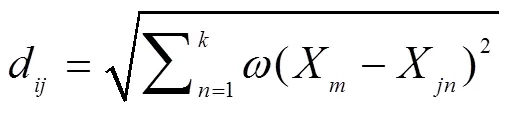


由公式得出加权欧式距离的局部密度定义,利用高斯核完成对局部密度的计算。
(3)多簇合并分配策略

CMDPC(coefficient of variation and Multi cluster merging strategy density peaks clustering)算法改进了DPC算法的分配策略,并且处理了样本间的内部结构,提升了聚类的准确率和效率。
1.3 隐私度量
隐私度量代表了用户的隐私保护程度。将用户的用户属性度量成一个具体的数值,通过数值让用户了解自己的隐私分数。

表示度量结果,()表示用户属性的可见度,()表示用户属性的敏感度,代表属性数量,最终得到的隐私度量结果,越小代表隐私保护程度越高。
(1)提取难度
提取难度ε表示从某个社交网络中获得这个属性的难易程度。为了表示社交网络中用户属性的提取难度,定义了3个难度:1代表困难;2代表相对困难;3代表容易。1表示结合用户属性和用户发布信息分析推断出的属性;2表示通过用户发布的内容分析出的用户属性;3表示从用户公开属性中直接获取。数值越小表示属性提取难度越高,数值越大表示属性提取难度越小。
(2)可获取度
可获取度表示OSNs运营商允许用户对自身属性和发布内容上设置可见范围。根据社交网络中大多数情况,定义了4个不同的等级:1仅自己可见;2对分组可见;3对好友可见;4对所有人可见。仅对自己可见的信息对研究是没有任何意义的,最终定义可获取度的范围为(1,4]。可获取度的数值越小表示获取难度越高,反之,可获取度数值越大表示获取难度越低。
(3)敏感度
敏感度表示社交网络用户属性信息的重要程度,属性信息越重要,则该属性信息的敏感度越高。对于灵敏度的量化,引用Srivastava等[15]导出的敏感度值,如表1所示。

表1 用户属性的敏感性评分
(4)隐私偏好度
为了反映用户对自己属性信息的主观感受,对用户的隐私偏好进行度量,称为隐私偏好度。隐私偏好度从主观上反映了用户对自身属性信息的重视程度,可以根据用户的自身需求和特定环境进行设定。定义的公式:

()表示用户的隐私偏好度,()表示用户的隐私偏好系数,()min表示用户的最小隐私偏好系数。根据用户对自身属性信息保护的倾向不同,将用户的隐私偏好等级分为3个等级:1高;2中;3低。其中1代表用户对属性的重视程度低;2表示用户对该属性的重视程度一般;3代表用户对该属性的重视程度高,数值越小表示用户对该属性的重视程度越高。
2 社交网络用户隐私度量方法
2.1 度量方法设计思路
在社交网络中,用户通过公开自己的属性信息给服务商,这样获得更好的个性化服务,从而增加了隐私泄露的风险。为了对用户属性信息进行更加准确的度量,考虑到用户的隐私偏好程度来反映用户的主观感受,这样采用IRT模型分别用对户属性的提取难度、可获取度和用户的隐私偏好度进行量化,从而形成一个三维向量。然后,采用CMDPC算法对样本进行分类,根据局部密度和截断距离找到聚类中心,将截断距离设置为2%[15],利用加权欧氏距离分配样本点,分配完成后,建立簇间相似度矩阵,将相似度最高簇和簇C合并形成一个新簇。
2.2 算法描述
算法1:计算可获取度
(1)输入:一个行列的响应矩阵
(2)输出:每个属性的可获取度得分
(3)初始化temp矩阵
(4)for=1:do
(5)提取出第行将其放入到col变量中
(6)根据输入删除不符合条件的条目
(7)检查定义的条目后计算平均值
(8)循环结束
(9)for=1:do
(10) 设置一个初始值和变量都为0的计数器
(11)for=1:do
(12) iftemp(,)!=0 then
(13) sum=sum+input(,);
(14) counter=counter+1;
(15)结束计数器循环
(16)显示出计算的可获取度
(17)means(1,)=sum/counter;
算法2:CMDPC算法
(1) for=0tolength():
(2) for=+1tolength()
//将数据的距离存储到矩阵中
(3) distlist[,]和distlist[,]←distance((),())
(4) for=0tolength(dist):
(5) 利用公式(2)计算的局部密度
(6) rho[]←ρXi
(7) for=1tolength(dist):
(8) for=+1to length(dist)
(9) if ρXi<ρXjanddist (,)
(10) 利用公式(4)计算距离属性(,)
(11) delta←(,)
(12) for=0tolength (dist):
//和较高的点标记为簇中心
(13) ifrho[]>maxrho并且delta[]>maxdelat
(14) 将第个数据点定为簇中心
(15) ifrho[]
(16) 将第个数据点标记为噪音点
(17) 将剩余点分配到密度较大的最近邻簇中
2.3 设计框架
首先将社交网络中用户的属性信息提取出来,对属性信息的提取难度、可获取度和隐私偏好度利用IRT模型进行量化,形成一个三维向量,使用CMDPC算法将样本分类,计算出属性可见度。属性可见度和属性敏感度经过计算,就可以得到用户的隐私度量值。最终的隐私分数表示用户的隐私状态,经过计算用户的隐私分数在[0, 1.455637]之间,整体框架如图1所示。

图1 整体框架
2.4 度量结果分析
(1)隐私偏好度
在社交网络中,用户提供隐私属性给服务商来换取更好的服务,其中包含用户的主观感受,大部分研究对用户的属性进行度量时,没有考虑到用户的主观感受。CMDPC算法建立的模型是将用户属性信息的提取难度、可获取度和隐私偏好度进行了量化,通过对隐私偏好的量化反映了用户的主观感受。并且,在最终的隐私度量结果中结合了隐私偏好度也提高了结果的准确性。
(2)CMDPC算法
在社交网络中,用户量十分巨大,要对用户的属性进行准确的隐私度量是一个十分庞大的工程,采用CMDPC算法对样本进行分类,CMDPC算法可以快速准确地找到聚类中心点,采用多簇合并分配策略将样本点进行分配,相比其他计算方法,可以减少大量的计算时间并提升聚类准确率,提升隐私度量准确性和时效性。
3 实验数据分析
3.1 实验环境
CMDPC算法由python语言和anaconda编译环境完成。实验硬件环境为Inter(R)酷睿I59400CPU2.9 GHz处理器,16 G内存;Linux作为操作系统;Hadoop为实验平台;spark作系统框架。在实验数据方面,使用的数据集包含了Telephone、Mailbox、Address、Birthday、Hometown、Current residence、Career information、Emotional state、Interest、Religious Belief、Political intention等属性,其中Political intention和Address是比较敏感的属性信息。所有的属性信息类型都为数值型。
3.2 CMDPC算法分析
本节将CMDPC算法与现有的一些其他聚类方法做了对比,主要从算法效率和准确率上做了对比。参与比较的算法是通过寻找最大参数似然估计的EM算法[16]和按照样本距离划分个簇的K-means聚类算法[17]。
(1)效率分析
随着用户属性数量的增加,CMDPC算法的效率受到的影响最小。CMDPC算法根据样本密度确定聚类中心。EM算法的核心思想是将样本点经过多次的迭代最终完成聚类,随着样本属性的增多,迭代次数指数性增长,导致效率减慢。K-means聚类算法的核心对聚类中心点的个数要求极为严格,值选取过大过小都会影响聚类的成功率和算法的执行效率。经过实验分析,CMDPC算法相比于其他2种算法拥有更高的效率。执行结果如图2所示。

图2 效率分析
(2)准确率分析
伴随着属性数量的增多,K-means算法对初始聚类中心选择敏感,可能只能做到局部最优解,影响了聚类的准确率。EM算法在样本点不符合高斯分布时聚类准确率就会下降。CMDPC算法根据密度进行聚类,利用变异系数和多簇合并分配策略,解决了样本内部结构问题。执行结果如图3所示。
3.3 IRT模型分析
采用IRT模型对样本进行分析,IRT模型对于单一实验源非常实用。为了验证本实验的正确性,通过与Li等[3]的算法进行实验对比,来保证本实验的正确性,并从样本中挑选有代表性的用户在图中进行对比。由于文献[3]的方法没考虑隐私偏好对隐私度量结果的影响,所以得出的结果大部分都是文献[3]的方法隐私度量值偏高,但用户6得出的数值要偏低,因为用户6有良好的隐私意识,社交网络中一部分人的隐私意识很强,在设置隐私偏好的时候会考虑到隐私泄露问题。但是,社交网路中大部分用户的隐私意识还是非常的薄弱。实验结果如图4所示。

图3 准确率分析

图4 隐私分数
3.4 缓解隐私泄露的方法
最终的隐私度量值就是最后的隐私分数,该隐私分数能反映用户隐私泄露的风险程度。在OSNs中,用户属性的敏感度都是不一样的,所以,将通过合理修改用户的隐私偏好度,减小用户的隐私分数。修改后的实验结果如图5所示。

图5 改进后的隐私分数
4 结束语
提出的基于偏好的隐私度量方法核心思想是在传统的用户属性隐私度量方法中结合用户的主观意识也就是隐私偏好,通过对IRT模型、CMDPC算法、属性敏感度的运用与结合,设计出一种在社交网络中用户属性度量的新方法,针对用户的主观意愿和社交网络数据量巨大导致聚类不准确等问题给予解决。首先,通过CMDPC算法对社交网络中的用户属性进行准确地分类,利用IRT模型对用户属性进行准确地度量,结合属性的敏感度计算出用户的隐私评分。最后,通过修改用户的隐私偏好度与修改前进行对比,证明了用户的主观感受对用户隐私评分的影响。旨在提升用户的隐私意识,通过提升用户的隐私意识来应对社交网络高速发展带来的改变。
[1] 杨少杰, 郑琨, 张辉, 等. 基于博弈论与区块链融合的k-匿名位置隐私保护方案[J]. 计算机应用研究, 2021, 38(5): 1320-1326.
[2] 谢明明, 彭长根, 吴睿雪, 等. 结构化数据的隐私与数据效用度量模型[J]. 计算机应用研究, 2020, 37(5): 1465-1469, 1473.
[3] Li K, Terzi E. Aframework for computing the privacy scores of users in online social networks[J]. ACM Transcctions on Knowledge Discovery form Data (TKDD), 2010, 5(1): 1-30.
[4] Jain S, Raghuwanshi S K. Fine Grained Privacy Measuring of User's Profile Over Online Social Network[M]. Singapore: Springer, 2018.
[5] Aghasian E, Garg S, Gao L, et al. Scoring Users' Privacy Disclosure Across Multiple Online Social Networks[J]. IEEE Access, 2017, 65(5): 13118-13130.
[6] 张盼盼, 彭长根, 郝晨艳. 一种基于隐私偏好的隐私保护模型及其量化方法[J]. 计算机科学, 2018, 45(6): 130-134.
[7] 彭长根, 丁红发, 朱义杰, 等. 隐私保护的信息熵模型及其度量方法[J]. 软件学报, 2016, 27(8): 1891-1903.
[8] 顾磊. 偏正态分布IRT模型的EM算法[D]. 南京:南京大学, 2018.
[9] 江平平, 曾庆鹏. 一种基于网格划分的密度峰值聚类改进算法[J]. 计算机应用与软件, 2019, 36(8): 268-274, 280.
[10] 杨渊超. 改进的密度峰值聚类算法研究[D]. 西安: 西安电子科技大学, 2020.
[11] 陈磊, 吴润秀, 李沛武, 等. 加权K近邻和多簇合并的密度峰值聚类算法[J]. 计算机科学与探索, 2022, 16(9): 2163-2176.
[12] 李雪峰. 社交网络中的隐私度量方法研究[D]. 北京: 北京邮电大学, 2020.
[13] 张盼盼. 理性隐私度量方法研究及其应用[D]. 贵阳: 贵州大学, 2018.
[14] 陈俊芬, 张明, 赵佳成. 复杂高维数据的密度峰值快速搜索聚类算法[J]. 计算机科学, 2020, 47(3): 79-86.
[15] Srivastava A, Geethakumari G. Measuring privacy leaks in Online Social Networks[C]//International Conference on Advances in Computing. IEEE, 2013.
[16] 张朋. 数据挖掘中聚类分析算法的研究与改进[D]. 无锡: 江南大学, 2016.
[17] 王林, 许郡蒙. 分布式K-means聚类在微博热点主题发现的应用[J]. 计算机仿真, 2020, 37(8): 121-125.
Research on Preference-based Privacy Measurement Method in Social Networks
LU Tai-yu, LI Xiao-hui, ZHANG Xin-yu, LV Wei-xin, DENG Qian
(School of Electronics & Information Engineering, Liaoning University of Technology, Jinzhou 121001, China)
To solve the problem that the users’subjective feelings are rarely taken into account inthe measurement models in existing social networks, which leads to inaccurate measurement, a privacy measurement method combined with privacy preference is proposed. The extractability, difficulty of acquisition and privacy preference of user attributes are quantified, and the CMDPC (Coefficient of variation and Multi cluster merging strategy Density Peaks Clustering) algorithm is used to cluster users, combined with the sensitivity of attributes, and the privacy score of users is obtained. The privacy preference of user attributes reflects the users’ subjective feelings. The CMDPC algorithm improves the efficiency and accuracy of user clustering, and realizes a fast accuracy measurement of user attributes. Experimental results show that the model reflects the user’s subjective feelings and improves the timeliness and accuracy of the measurement results.
privacy measurement; CMDPC algorithm; privacy preference; social network
10.15916/j.issn1674-3261.2022.06.009
TP311
A
1674-3261(2022)06-0393-06
2022-05-09
辽宁省应用基础研究计划项目(2022JH2/101300278);辽宁省教育厅科学研究经费项目(JZL202015402)
路太宇(1997-),男,辽宁铁岭人,硕士生。
李晓会(1978-),女,辽宁盘锦人,副教授,博士。
责任编辑:孙 林
猜你喜欢
上海文化(文化研究)(2022年3期)2022-06-28
意林彩版(2022年2期)2022-05-03
数学年刊A辑(中文版)(2022年4期)2022-02-16
好日子(2021年8期)2021-11-04
第一财经(2020年4期)2020-04-14
铁道通信信号(2019年6期)2019-10-08
数学年刊A辑(中文版)(2019年3期)2019-10-08
文苑(2018年17期)2018-11-09
雷达学报(2017年6期)2017-03-26
互联网天地(2016年1期)2016-05-04
