
面向行人重识别的多域批归一化问题研究
2022-02-22 14:20张誉馨张索非王文龙吴晓富
计算机技术与发展 2022年1期
张誉馨,张索非,王文龙,吴晓富
(1.南京邮电大学 通信与信息工程学院,江苏 南京 210003;2.南京邮电大学 物联网学院,江苏 南京 210003)
0 引 言
行人重识别(pedestrian re-identification,Re-ID)是利用计算机视觉技术判断图像或者视频序列中是否存在特定行人的技术。给定一个待检行人图像,Re-ID任务一般要求检索出跨监控摄像头下的该行人图像。随着安防需求的不断增长以及计算机视觉技术的迅猛发展,行人重识别技术已成为当前计算视觉研究的一个热点方向。
传统的行人重识别主要关注设计手工视觉特征与度量相似性两个问题。随着深度学习的发展,用深度神经网络来有效提取行人重识别特征的技术取得了飞速发展。文献[8]提出一种基于分块的卷积基准网络(part based convolutional baseline,PCB),通过将行人均等分为六分块引导网络更加关注局部粒度信息;文献[9]中提出的(batch drop block,BDB)算法,通过对数据随机局部遮挡,使网络获得更为全面的空间特征;文献[10]提出一种将判别信息与各粒度相结合的多粒度网络(multiple granularity network,MGN)。这些算法可以有效提升单一数据集下训练的模型泛化能力,但是对于现实中的复杂场景,往往训练集中包含两种甚至更多种风格的图像(例如不同背景和不同光照下拍摄的照片)。当数据集中出现明显的数据风格分歧时,大部分算法并没有基于多域数据的风格差异问题进行训练优化。
如何处理训练数据之间的分布差异并利用多个不同风格的数据集来训练提升模型的泛化能力是行人重识别领域需要认真考虑的一个问题。利用多个风格不同的数据集来训练深度神经网络的一个主要障碍来自于深度神经网络模型中广泛应用的批归一化(batch normalization,BN)模块。BN模块最初由Sergey等提出,用于有效控制层间信号的取值范围,其已被证明能大幅提高深度神经网络的训练收敛以及最终性能。然而,BN模块应用于多域数据却存在先天的逻辑缺陷。例如,当一个批次的训练数据中呈现两种不同分布时,以该批次计算的均值与方差会大幅震荡,导致训练过程中归一化效果恶化。因此,多域行人重识别面临的一个重要问题是如何解决多域数据分布差异导致的BN模块设计问题。
为讨论行人重识别使用多个风格数据库的多域训练问题,该文尝试将两个典型的行人数据集Market1501和DukeMTMC-reID进行合并训练,以此分析多域批归一化问题并提供解决问题的思路。通过将不同数据集下的图片进行分域归一化处理,从而规避了数据分布差异导致的批归一化应用困境,基于此思路该文尝试了一种并行训练模式下的多域归一化方案。实验分析表明:采用该方案可以有效提升模型的泛化能力,在Market1501和DukeMTMC-reID数据集上获得了明显的性能提升。
1 问题研究
1.1 BN算法
深度神经网络的BN层原理如下:设一个训练批次的输入数据为B
={x
1,2,…,},输出为Y
={y
1,2,…,},则BN层进行归一化处理的关键是计算这一批次样本的均值和方差。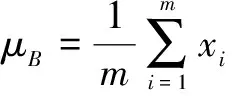
(1)

(2)
根据该批次样本统计得到的均值和方差对数据进行归一化后再缩放和平移,具体过程为:
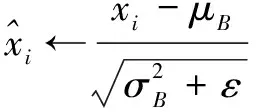
(3)
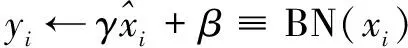
(4)
其中,γ
和β
分别为缩放和平移参数。由式(1)和式(2)可知:当训练集中出现两种甚至多种呈现明显分布差异的数据时,短时间窗口所得到的均值与方差必然不稳定,表现为不同训练批次计算出的均值和方差存在振荡现象,导致模型的归一化效果恶化。1.2 多域归一化问题
多域数据分布差异广泛存在于行人重识别研究中,例如不同摄像头、不同光照下采集得到的行人数据集。鉴于目前公开的不同行人数据集的固有分布差异,该文以多个行人数据集合并训练存在的多域归一化问题作为主要研究案例。以Market1501和DukeMTMC-reID为例,Market1501于2015年夏采集自清华大学校园内,包含1 501个行人ID,共有32 668张图片;DukeMTMC-reID于2015年冬采集自杜克大学校园内,包含1 812个行人ID,共有36 411张图片。由于数据采集的地理位置和所处的季节不同,这两种行人数据集在行人着装、背景颜色、镜头风格方面都存在明显差异。图1分别展示了来自Market1501和DukeMTMC-reID的图片样例。

图1 图片样例
通过对比图片样例可发现两种数据集中采集的行人图片存在显著差异,例如在Market1501中行人多为身着夏装的亚洲人群,而Duke-MTMC中多为身着冬装的欧美人群。在模型训练中,图片的差异将导致模型BN层中的统计值也呈现出两种不同的分布,图2中展示了采用ResNet50模型分别在Market1501和DukeMTMC-reID训练下各BN层的均值分布差异。
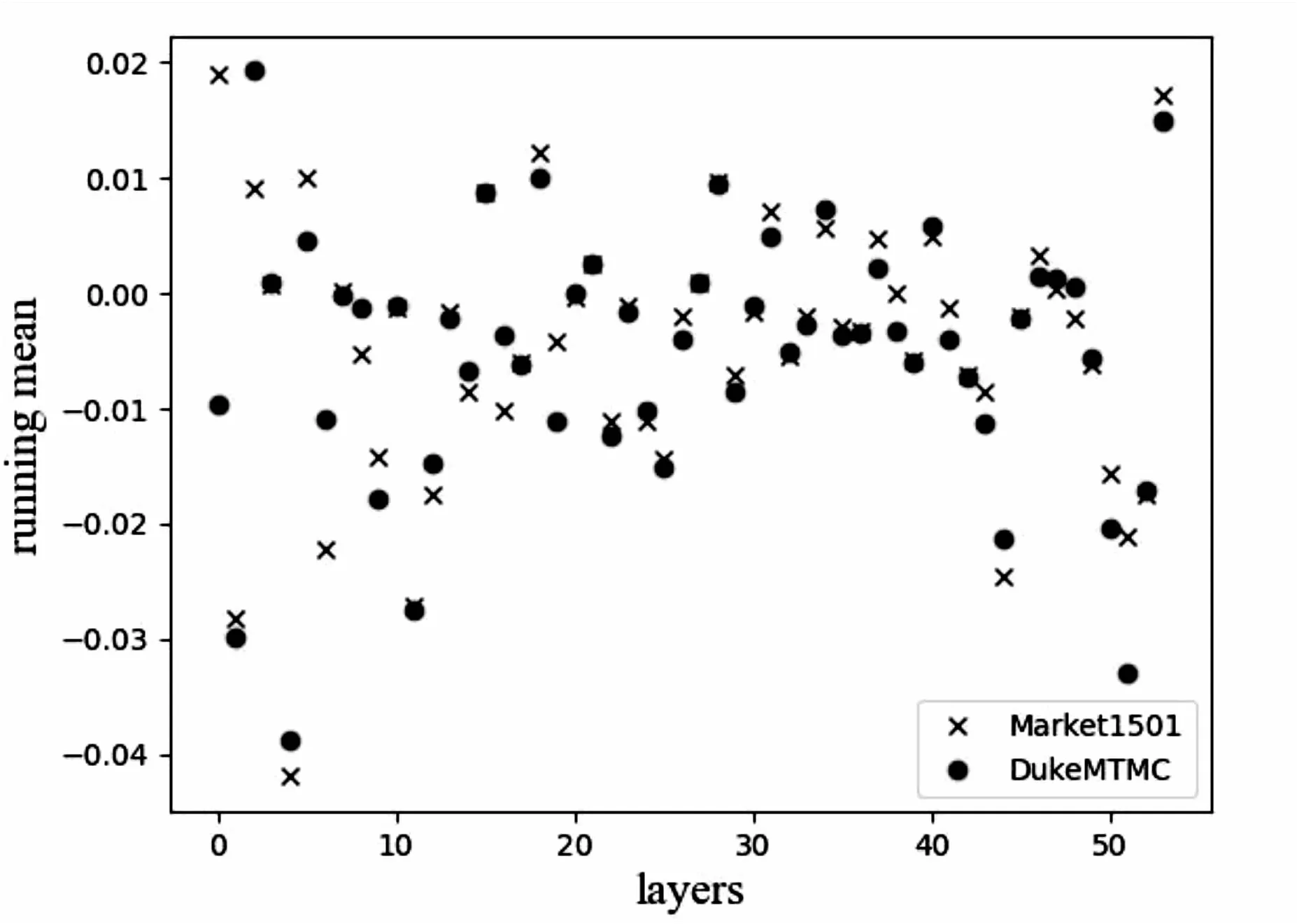
图2 Market1501和DukeMTMC-reID训练下的 BN层均值分布差异
为评估由于数据集之间的分布差异导致的多域归一化问题的影响,将两种不同的行人数据集进行合并,再用于训练行人重识别模型,最终将合并训练的模型与单一数据集训练的模型进行性能比较。表1展示了使用ResNet50网络作为基线模型训练后在Market1501和DukeMTMC-reID测试集上进行交叉测试的性能对比。
将多数据集进行合并训练在理论上可提升模型的整体泛化性能,但表1中的数据显示将Market1501和DukeMTMC合并后训练的模型性能却在首位配准率(Rank-1)和平均精度均值(mean average precision,mAP)两项测试指标下均弱于单一数据集下训练的结果。这表明在多数据库合并训练下,多个数据集之间的分布差异导致的多域归一化问题很大程度影响了模型的训练效果,造成模型最终的性能下降。
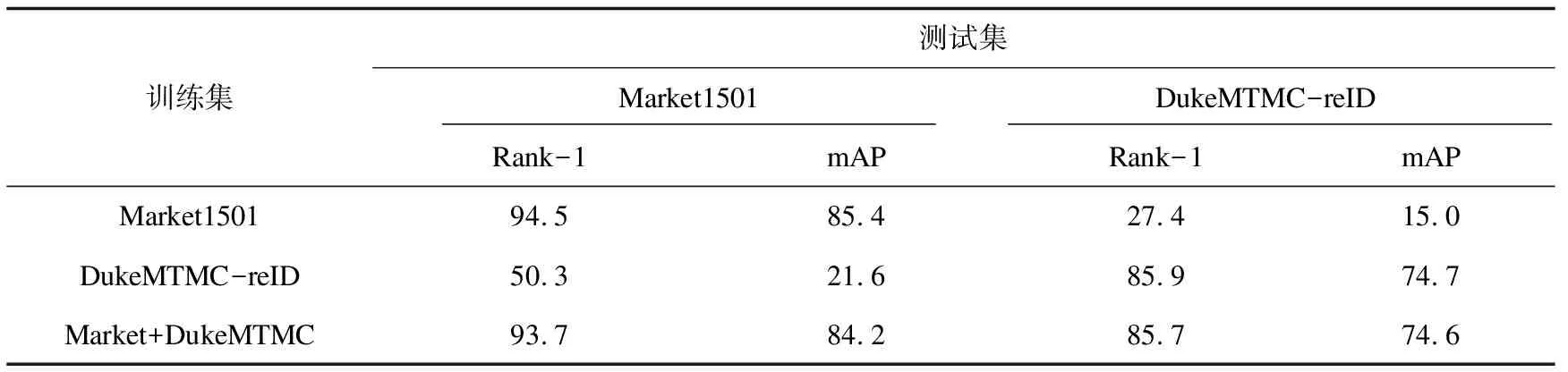
表1 Market1501与DukeMTMC-reID数据集交叉测试结果 %
2 文中方案
2.1 多域归一化方法
针对多数据集分布差异导致的多域归一化问题,该文尝试一种简单的解决方案。在模型的批归一化处理模块中,将数据流根据所属域进行分离,对不同域下的数据进行单独的归一化,以此有效缓解归一化过程中出现的统计值波动困扰。根据此思路,提出一种针对特定域数据的批归一化方法(domain-specific batch normalization,DSBN),图3展示了DSBN模块的基本流程。
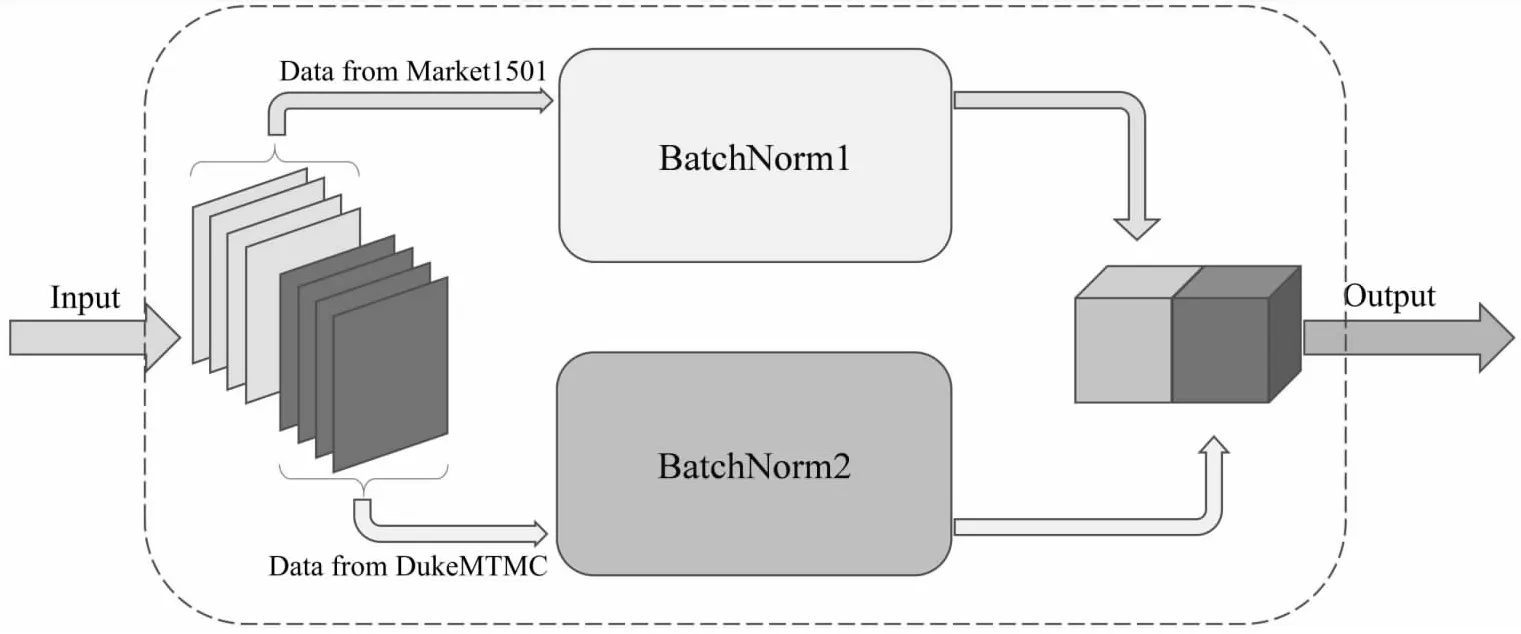
图3 DSBN模块数据处理流程
如图3所示,DSBN模块的每个训练批次是由两个子批次(mini-batch)组成,每个子批次的样本分别取自于两种不同的数据库。一个完整的训练批次(super-batch)可表示为B
=2×B
,子批次样本分别送入两个独立的BN模块中进行批归一化处理。为使子批次中的图片来自不同数据库,该方案采用多数据集并行训练方式,整体的训练流程如图4所示。使用ResNet50作为主干网络,并将其中所有的BN层替换为DSBN模块,其余层的参数设置不变。在并行训练中,模型中所有的归一化层对来自不同数据集的样本进行独立的归一化,同时模型中其他层的参数则共享两个数据集的信息。
采用此方案的优势是避免了由于多域数据分布差异导致的归一化问题,同时可以有效利用多数据集训练来提升模型的整体泛化能力。
但是在处理数据集更大、面对更复杂的多域问题时,该方案的实现复杂度相对较高,如何改进还有待进一步研究。
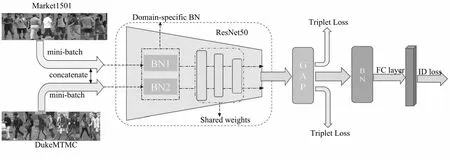
图4 多数据集并行训练流程
2.2 损失函数设置
采用了两种损失函数对网络进行优化,分别为交叉熵损失函数(cross entropy loss)和三元组损失函数(triplet loss),交叉熵函数用于计算行人ID的分类误差,记为ID loss;triplet loss优化特征之间的度量距离,使正样本之间的间距更近,负样本之间的间距更远。
具体而言,该方案主干网络输出的特征图经过全局均值池化层(global average pooling,GAP)后获得通道维数为2 048的全局特征向量,分别计算各子批次的triplet loss,即:
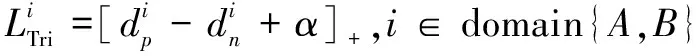
(5)
其中,d
和d
分别表示正样本对和负样本对的特征距离,{A
,B
}为数据所属的两个不同域,[z
]表示max(z
,0),α
表示距离余量,该方案中将其设为0.3。经过GAP得到的特征向量依次经过BNNeck和全连接层(fully connected layer,FC)后输出行人的分类预测,总类别为两个数据集的行人ID数量总和。采用交叉熵损失函数直接计算总的ID loss,表示为:
(6)
其中,N表示总的行人ID数目,p
表示FC层输出的对应各ID的预测概率值,当类别预测与行人实际标签相符时q
=1,否则q
=0。最终的loss表示为: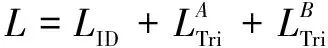
(7)
3 实验及分析
3.1 实验环境及参数配置
实验所用的行人数据集为Market1501和DukeMTMC-reID。在并行训练方案中,每个子批次(mini-batch)的batch size设为64,合并后的super-batch大小为128。由于两种数据集的大小存在差异,因此以其中图片数量较多的数据集完全训练一次作为一个epoch,数量较少的数据集存在少量图片的重复遍历。
在训练策略上,采用Adam优化算法,一阶动量系数设置为0.9,二阶动量系数设为0.999,权重衰减系数为0.000 5。初始学习率为0.000 035。采用的WarmUp策略——经过20个epoch将学习率从0.0线性提升到0.000 35;再每隔30个epoch将学习率降低为0.2倍,共训练140个epoch。
在图片预处理上,对两个域的数据均采用了随机擦除(random erasing)和随机翻转(random flip)算法进行处理,并且将输入图像的尺寸统一设置宽128像素、高256像素。
该方案采用ResNet50作为基础主干网络,将其中的BN层替换为DSBN层,并且载入了ImageNet预训练参数。训练过程中同时对DSBN中的两套归一化模块参数进行优化,在测试过程中,模型载入对应数据集的归一化参数对各个测试集进行单独性能测试。
实验测试集包含待检索图片集Query和检索图片库Gallery两部分。在测试过程中,先通过网络推理得到测试集所有测试图片对应的特征,然后根据特征间的欧氏距离计算出待检索图Query与检索库Gallery中所有图片的相似度并进行排序,最终计算首位准确度(Rank-1)和平均精度均值(mean average precision,mAP)作为模型性能评价指标。其中首位准确度主要用于模型对简单样本配准性能的评估,而平均精度均值则兼顾了模型对困难样本配准性能的评估。
实验运行环境为Ubuntu16.04操作系统,使用Pytorch1.1深度学习框架实现,并在NVIDIA Tesla P40 GPU上进行模型训练。
3.2 实验结果对比
将采用DSBN模块的模型性能与优化之前的结果进行比较,所对比的网络结构区别仅在于改变了其中一个网络的归一化模块,所采用的训练方式包括单一数据集训练和多数据集并行方式两种。对比结果如表2所示。
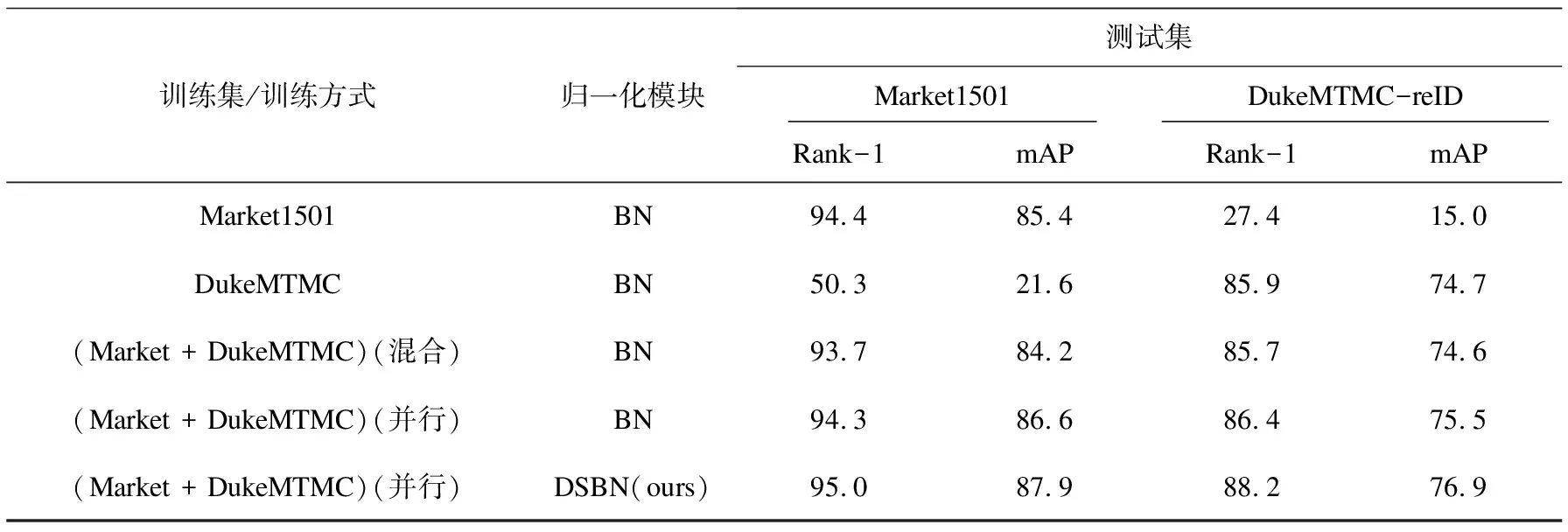
表2 采用DSBN的并行训练与普通训练方式性能对比 %
由表2可知:相较于单一数据集下的性能,最终采用DSBN的并行训练方案在两个数据集上分别在Rank-1和mAP上提高了0.6、2.5、2.3、2.2个百分点。由于并行训练模式下同批次中两种数据集的图片数量相同,训练时BN层的输入均值、方差也相对更均衡,因此采用并行训练方式得到的模型性能优于多数据集混合后训练所得性能。
DSBN模块针对两个域的数据分别进行归一化,因此DSBN中的两个BN模块分别对应了两种数据集。使用DSBN模块中两套对应不同数据集的BN参数分别在两个数据集上进行测试,结果如表3所示。
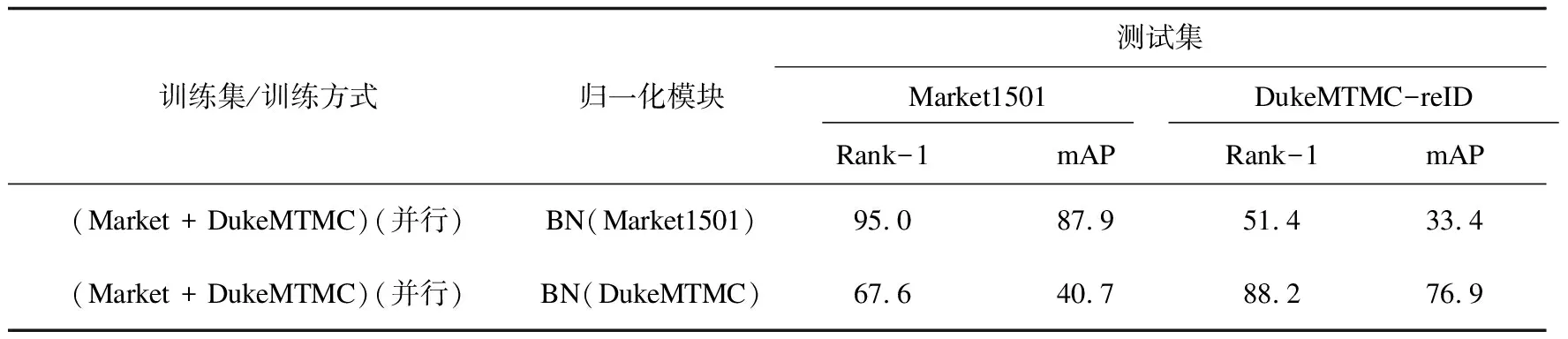
表3 DSBN中对应不同数据集的BN参数测试结果 %
在测试过程中采用与测试集相对应的BN模块参数时,模型识别的准确率较高;而使用对应另一测试集的BN参数则只能得到较低的识别准确率。这表明DSBN模块中的各BN只适于与其对应的一个数据域,从而避免了多域数据输入到同一BN模块中造成的归一化问题。表3中的对比数据同时也印证了前文提出的多数据域之间同步分布差异问题的存在,DSBN模块可在一定程度上缓解其带来的性能问题。
同时考察了在两种数据集上采用增量学习模式进行训练的效果。增量学习模式是指模型依次在多个数据集上进行训练,使网络在不断增加的训练数据集上持续学习以提升最终性能。这里采用原始ResNet50模型依次在两种数据集上训练,采用的训练配置与文中方案保持完全一致,并和提出的并行学习方式进行比较,得出的测试结果如表4所示。
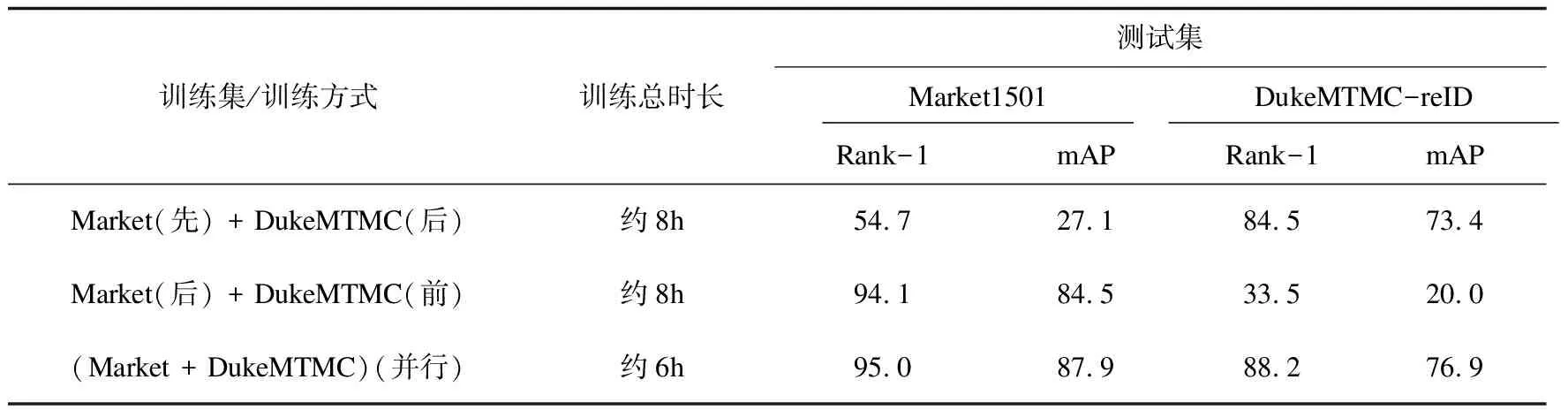
表4 与增量学习方案对比结果 %
由对比可以发现:该文所采用的DSBN方案在准确率上优于增量学习方案,分别在两个数据集Rank-1和mAP指标上相较于增量学习方案提高了0.9、3.4、3.7、3.5个百分点,并且在总训练时长上相较增量学习方案也具有一定优势。
3.3 与其他算法比较
将文中方法在Market1501和DukeMTMC上与其他行人重识别算法进行比较,并尝试将文中方案迁移到其他公开报道的算法之上,提升其在多数据训练下的性能。
实验对比结果如表5所示,其中Ours+MGN、Ours+PLR-OSNet为文中方法与MGNPLR-OSNet算法相结合后得到的算法。

表5 与其他算法性能比较 %
表5中标有*的结果为实际复现结果。由于本方案采用的网络架构(Ours)仅利用了单分支网络的全局特征,因此性能仍有较大的提升空间,相较于未采用文中方案的基线模型(Baseline)有可观的性能提升,且与其他采用单分支网络的算法例如OSNet、BOT相比也具有一定优势。另外,Ours+MGN、Ours+PLR-OSNet的结果表明该方案可应用于已报道的其他行人重识别网络(如MGN、PLR-OSNet)并进一步提升其性能。
4 结束语
该文聚焦于多数据集合并下的行人重识别模型训练问题。针对多域混合训练,重点分析了多域数据分布差异引起的模型批归一化模块的不稳定性问题。在此基础上,提出了一种DSBN模块来替代传统的批归一化模块。初步实验表明:所提方案可在多数据集合并训练下有效缓解多域归一化的波动问题,提升模型的泛化能力。当然,该方案只是多域训练方向的一个简单尝试,多域训练问题的彻底解决还有待更为深入和细致的研究。
猜你喜欢
汽车实用技术(2022年10期)2022-06-09
音乐探索(2022年2期)2022-05-30
时代英语·高二(2021年4期)2021-07-29
时代英语·高二(2021年4期)2021-07-29
意林(2021年5期)2021-04-18
小天使·一年级语数英综合(2019年8期)2019-08-27
37°女人(2019年7期)2019-07-12
扬子江(2019年1期)2019-03-08
小天使·一年级语数英综合(2017年6期)2017-06-07
中学生数理化·高一版(2016年6期)2016-05-14
