
多类别文本分类方法比较研究
2022-02-22 12:20于卫红
计算机技术与发展 2022年1期
于卫红
(大连海事大学 航运经济与管理学院,辽宁 大连 116026)
0 引 言
文本分类是指对于一个特定的文档,判断其是否属于某个类别。根据目标类别的不同,通常将文本分类问题分为三种类型:
(1)二分类:表示分类任务中有两个类别(0或者1),如垃圾邮件分类。
(2)多类别分类:表示分类任务中有多个类别,如客户的评论情感可分为5个类别:非常满意、满意、一般、不满意、非常不满意。
(3)多标签分类:表示给每个样本分配一个标签集。如,一个文本可能被同时认为是与宗教、政治或教育都相关的话题,或全部无关。
在文本挖掘的实际应用中,多类别分类问题更加常见,并且,多标签分类问题也可以转化为多类别分类问题来加以解决。多类别分类问题较之二分类问题更加复杂,如何选择合适的算法,构建出性能较优的多类别分类模型至关重要。
决策树、随机森林、朴素贝叶斯等算法都可用于多类别分类问题,但每个算法都是基于某些特定的假设的,都具有各自的优缺点,没有任何一种分类算法可以在所有的问题解决中都有良好的表现。因此,只有比较了多种算法的性能才能为具体的问题选择出较佳的模型。
1 文本分类的流程、方法与性能评价指标
1.1 文本分类的流程
如图1所示,无论何种类型的文本分类问题,其处理过程大都包括文本预处理、文本特征表示、分类模型构建、模型评估几个步骤。其中,文本特征表示和分类模型的构建是文本分类问题的核心。
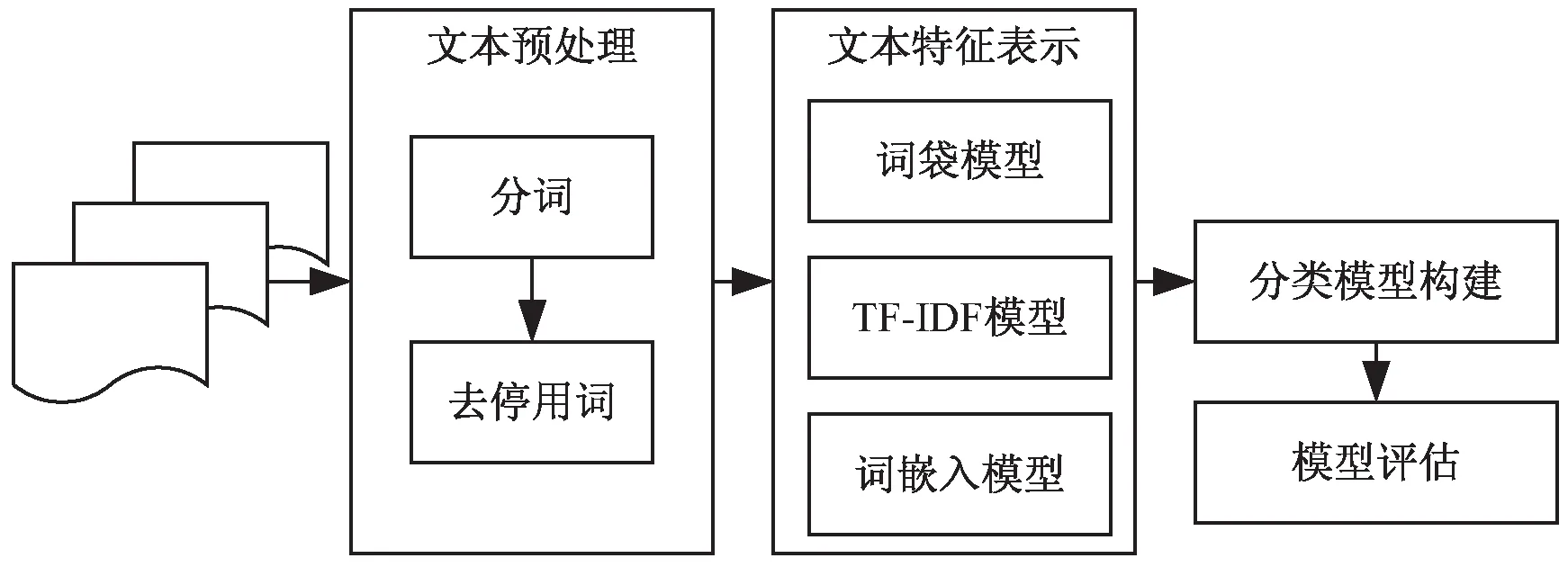
图1 文本分类的流程
1.2 文本特征表示的几种方法
1.2.1 词袋模型
词袋模型是一种基于词频的对文档进行特征提取的方法,即将文档看作词的集合,对文档中出现的所有词进行词频统计,用词频向量来表示文档。词袋模型忽略了文本的语法和语序等要素,只考虑词在文档中出现的次数。
1.2.2 TF-IDF模型
TF-IDF模型在考虑词频的基础上考虑了词对于一篇文章的重要性。TF(term frequency)指的是一个单词在某个文档中出现的频率。通常,一个词在一篇文档中出现的频率越高,这个词对于该文档越重要。IDF(inverse document frequency)指的是逆向文档频率,代表了词对于文档的区分度,如果一个词在一篇文档中多次出现,但在其他文档中很少出现,则认为这个词对于该文档的区分能力较强。一个词的TF-IDF值的计算公式为:
TF-IDF=TF*IDF;


(1)
1.2.3 词嵌入模型
基于词嵌入的文本特征表示是一种文本深度表示模型,其主要思想是将文本转换为较低维度空间的矢量表示。首先基于大量的语料库训练出词嵌入模型,即将每个词映射成K
维实数向量(通常K
=50~200),并且使得这些向量能较好地表达不同词之间的相似和类比关系,以引入一定的语义信息。常用的词嵌入算法有Word2Vec和Glove。本研究使用Word2Vec算法,Word2Vec有两种实现词嵌入的方式,即CBOW(连续词袋)和SKIP-GRAM(跳字模型)。CBOW方法以上下文单词作为输入,预测目标单词;而SKIP-GRAM方法以目标单词作为输入,预测单词周围的上下文。最后,基于训练好的词嵌入模型,使用Doc2Vec算法生成文本的向量表示模型,即将每个文本映射成K
维实数向量。1.3 构建文本分类模型的常用算法
构建文本分类模型的算法有很多,如传统算法:决策树、多层感知器、朴素贝叶斯、逻辑回归和SVM;集成学习算法:随机森林、AdaBoost、lightGBM和xgBoost;以及深度学习算法:前馈神经网络和LSTM。对所有算法进行比较,工作量巨大,本研究只比较常用的5种算法:决策树、KNN、朴素贝叶斯、SVM和随机森林。
1.3.1 决策树
决策树是一种以树形结构来展示决策规则和分类结果的模型,其思想是通过ID3、C4.5、CART等算法将看似无序、杂乱的训练数据转化成可以预测未知实例的树状模型。决策树中每一条从根节点(对最终分类结果贡献最大的属性)到叶子节点(最终分类结果)的路径都代表一条决策规则。
1.3.2 KNN
KNN算法又称K
邻近算法、K
最近邻算法,其核心思想是如果一个样本在特征空间中的K
个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性。1.3.3 朴素贝叶斯
朴素贝叶斯算法的核心思想非常朴素:对于给出的待分类项,求解在此项出现的条件下各个类别出现的概率,哪个最大,就认为此待分类项属于哪个类别。
1.3.4 SVM
SVM即支持向量机算法,最初提出是为了解决二分类问题,核心思想是基于训练集在样本空间中找到最优的一条线(超平面),将不同类别的样本分开。所谓的“支持向量”就是那些落在分离超平面边缘的数据点形成的线。SVM算法也可以用于解决多类别分类问题,此时,支持向量机仍将问题视为二分类问题,但会引入多个支持向量机用来两两区分每一个类,直到所有的类之间都有区别。
1.3.5 随机森林
随机森林是一种集成学习算法,通过构建并结合多个学习器来完成学习任务。随机森林的出现主要是为了解决单一决策树可能出现的很大误差和过拟合的问题,其核心思想是将多个不同的决策树进行组合,利用这种组合降低单一决策树有可能带来的片面性和判断不准确性。随机森林中的每一棵决策树都是独立、无关联的,当对一个新的样本进行判断或预测时,让森林中的每一棵决策树分别进行判断,看看这个样本应该属于哪一类,然后统计哪一类被选择最多,就预测这个样本为哪一类。
1.4 分类模型的评估指标
二分类问题常用准确率、查准率、召回率等指标评估模型的优劣,而对于多类别分类问题,有些二分类的评价指标则不适用。
通常使用Kappa系数对多类别分类模型进行评估。Kappa系数是统计学中用于评估一致性的一种方法,分类问题的一致性就是模型的预测结果与实际分类结果是否一致。Kappa系数的取值范围是[-1,1],值越大,则表示模型的分类性能越好。
Kappa系数的计算公式为:
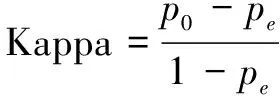
(2)
其中,p
是每一类正确分类的样本数量之和除以总样本数,也就是总体分类精度。假设每一类的真实样本个数分别为a
,a
,…,a
;而预测出来的每一类的样本个数分别为b
,b
,…,b
;总样本个数为n
,则有: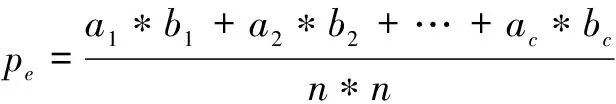
(3)
2 多类别文本分类方法比较方案的设计
2.1 比较对象
本研究在比较对象上考虑了文本特征表示方法和分类算法两个维度。其中,文本特征表示选取了TF-IDF、词嵌入CBOW和词嵌入SKIP-GRAM三种方法;分类算法包括5种:决策树、SVM、KNN、朴素贝叶斯和随机森林。对不同的文本特征表示方法和分类算法进行组合,构成15种分类模型,以这15种分类模型为比较对象。
2.2 比较指标
在比较指标上考虑了时间和分类效果。分类效果使用Kappa系数来衡量,时间方面包括:(1)文本特征表示的处理时间;(2)分类模型的构建时间与测试样本的预测时间之和。时间均以秒为单位。
2.3 比较流程
在比较流程上考虑了数据规模与比较次数。基本思路是:
(1)在原始数据集中随机采样N
条数据;(2)分别使用TF-IDF、词嵌入CBOW、词嵌入SKIP-GRAM方法构建这N
条数据的文本特征矩阵,将这N
条数据按照一定的比例(如8∶2)拆分成训练集和测试集;(3)分别使用SVM、KNN等不同的分类算法基于不同的文本特征表示构建分类模型,并对测试集进行预测,统计各模型的Kappa系数、运行时间等指标;
(4)重复步骤(1)~(3)M
次(如M
=50)后,计算在数据规模为N
条数据时,M
次比较后各比较指标的平均值;(5)增加数据规模后继续执行步骤(1)~步骤(4),如设定每次增加200条数据,即N
=N
+200,得到新的数据规模下M
次比较后各比较指标的平均值;(6)当数据规模超过了原始数据集的条数后停止比较,综合评估不同数据规模下不同模型的性能。
3 多类别文本分类方法比较实例
3.1 数据集
3.1.1 原始数据集
使用八爪鱼采集器从好奇心日报、新浪网、网易等媒体阅读网站爬取了3 000条不同类别的资讯文本,整理成研究所需要的原始数据集,保存到CSV格式的文件中。该数据集由分类、标题、正文三个字段组成,如图2所示。

图2 原始数据集示例
其中,文本类别有6个:商业、娱乐、游戏、文化、智能和时尚,各类别文本的数据量在原始数据集中大致呈平均分布,数据集适合做多类别文本分类研究。
3.1.2 训练数据集与测试数据集
本实例只研究文本标题的自动分类,因此训练集和测试集只涉及到类别和标题两个字段。如前文所述,在比较过程中,每次从原始数据集中采样一定规模的数据,将这些数据按照8∶2的比例拆分成训练集和测试集。采样规模从400条逐渐递增到3 000条,步长为200,并且,同一规模的训练集和测试集进行50次建模比较。
3.1.3 原始数据集中“正文”字段的作用
原始数据集中每一条数据的正文都是一个长文本,正文总字数达到了7 854 428,完全可以将正文内容作为训练词嵌入模型的语料库。
3.2 标题文本的特征表示
3.2.1 TF-IDF文本特征表示
在R语言环境下使用quanteda包中的corpus()、tokens()、dfm()、dfm_tfidf等函数构建标题的TF-IDF文本特征表示模型,主要语法如下:
原始文件<-read.csv(文件名.csv)
标题内容<-corpus(原始文件$标题)
分词<-tokens(标题内容)
分词<-tokens_remove(分词, stopwords(language="zh",source="misc"))
文档词条矩阵<-dfm(分词)
TF-IDF文本特征表示<-dfm_tfidf(文档词条矩阵)
以采样400条数据为例,得到的标题文本的TF-IDF文本特征矩阵如图3所示。

图3 标题文本的TF-IDF表示矩阵示例
很显然,使用TF-IDF进行文本特征表示文档词条矩阵过于庞大并高度稀疏。
3.2.2 基于词嵌入的文本特征表示
使用R语言的word2vec包构建基于词嵌入的文本表示,主要步骤如下:
步骤1:词嵌入模型训练文本的分词、去停用词等处理。
如前文所述,本实例将原始数据集中“正文”字段的所有文本作为训练词嵌入模型的语料库。由于word2vec算法的输入是词语列表而不是整篇文章,因此首先需要对训练语料库进行分词、去停用词、去符号、去数字等处理,并将分词后的语料文件保存成CSV格式文件以备后续训练词嵌入模型使用。
步骤2:使用语料文件训练词嵌入模型。
使用步骤1形成的语料文件和word2vec函数生成词嵌入模型。主要语法如下:
词嵌入语料<-read.csv(语料文件.csv)
CBOW词嵌入模型<- word2vec(x=词嵌入语料$语料库词条,type="cbow",dim=50,iter=20,split=" ")
将word2vec函数中的参数type设定为“skip-gram”则可以训练出SKIP-GRAM词嵌入模型,即:
SKIPGRAM词嵌入模型<- word2vec(x=词嵌入语料$语料库词条, type="skip-gram",dim=50,iter=20,split=" ")
步骤3:使用词嵌入模型对标题文本进行特征表示。
基于步骤2训练出的词向量模型,使用doc2vec函数将分词后的标题内容表示成向量模型,即将每个标题内容映射成50维实数向量。主要语法如下:
文档ID<-seq(1:采样条数))
数据框<- data.frame(doc_id=文档ID,text=标题文本分词后的词表, stringsAsFactors=FALSE)
基于CBOW词嵌入的文本特征表示<-doc2vec(CBOW词嵌入模型,数据框,type="embedding")
基于SKIP-GRAM词嵌入的文本特征表示<-doc2vec(SKIPGRAM词嵌入模型, 数据框, type="embedding")
通过上述过程,将每一个标题文本映射成50维的实数向量。
3.3 文本分类模型的构建及性能评估
对于本研究所涉及的SVM、KNN、决策树、朴素贝叶斯、随机森林五种分类算法,在R语言环境下,使用party、e1071、randomForest等包中提供的函数进行文本分类模型的构建。
以使用randomForest包中的随机森林算法构建基于不同特征表示的分类模型为例:
(1)基于TF-IDF的文本特征表示。
TFIDF分类模型<-randomForest(类别~.,TFIDF特征表示的训练数据集,ntree=30,na.action=na.roughfix)
TFIDF预测结果<-predict(TFIDF分类模型,TFIDF特征表示的测试数据集,proximity=TRUE)
(2)基于词嵌入CBOW的文本特征表示。
CBOW分类模型<-randomForest(类别~.,CBOW特征表示的训练数据集,ntree=30,na.action=na.roughfix )
CBOW预测结果<- predict(CBOW分类模型,CBOW特征表示的测试数据集,proximity=TRUE)
(3)基于词嵌入SKIP-GRAM的文本特征表示。
SKIP-GRAM分类模型<-randomForest(类别~.,SKIP-GRAM特征表示的训练数据集,ntree=30,na.action=na.roughfix )
SKIP-GRAM预测结果<- predict(SKIP-GRAM分类模型,SKIP-GRAM特征表示的测试数据集,proximity=TRUE)
在模型构建及对测试数据集进行预测的过程中统计运行时间,并且在预测之后构建预测值与真实值的混淆矩阵,使用VCD包中的Kappa函数基于混淆矩阵计算模型的Kappa系数,衡量模型的分类效果。
3.4 模型的比较结果
3.4.1 文本特征表示处理时间的比较
在不同的数据规模下,使用TF-IDF、词嵌入CBOW和词嵌入SKIP-GRAM三种方法对文本进行特征表示的处理时间变化如图4所示。
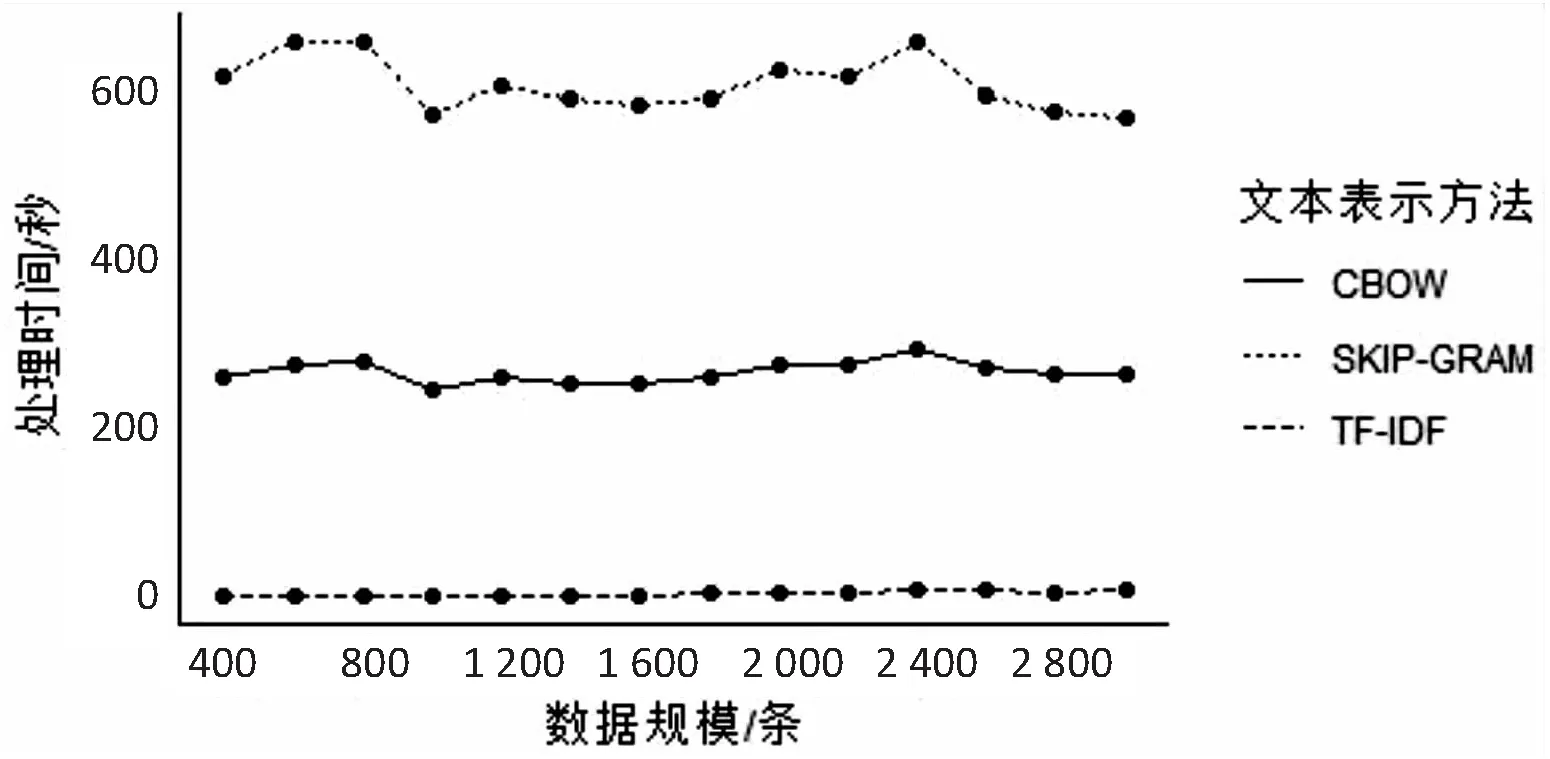
图4 不同数据规模下使用不同方法进行 文本特征表示的处理时间
从图4可以看出:
在相同的数据规模下,词嵌入的文本特征表示处理时间都远远超过TF-IDF,这是因为词嵌入需要对大量的语料库进行训练,而在两种词嵌入方法中,SKIP-GRAM比CBOW的训练时间更长(大约是2.5倍)。
三种特征表示的处理时间与数据规模的相关系数如表1所示。
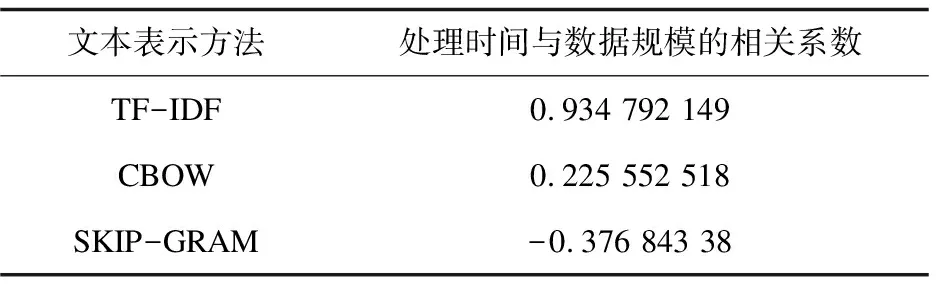
表1 文本表示处理时间与数据规模的相关性
从表1可以看出:
(1)TF-IDF文本特征表示的处理时间与数据规模高度正相关,采样数据越多,处理的词条数越多,TF-IDF文本特征表示的处理时间越长;
(2)两种词嵌入特征表示的处理时间与所处理数据的数据规模之间的相关性不强。
3.4.2 模型构建与预测时间比较
15种模型在不同数据规模下运行时间的变化如图5所示。由于使用TF-IDF进行文本特征表示的模型与使用词嵌入进行文本特征表示的模型在运行时间上数值范围相差极大,所以在图5中用上下两幅图来阐释,上图表示使用TF-IDF进行文本特征表示的模型,下图表示使用词嵌入进行文本特征表示的模型。
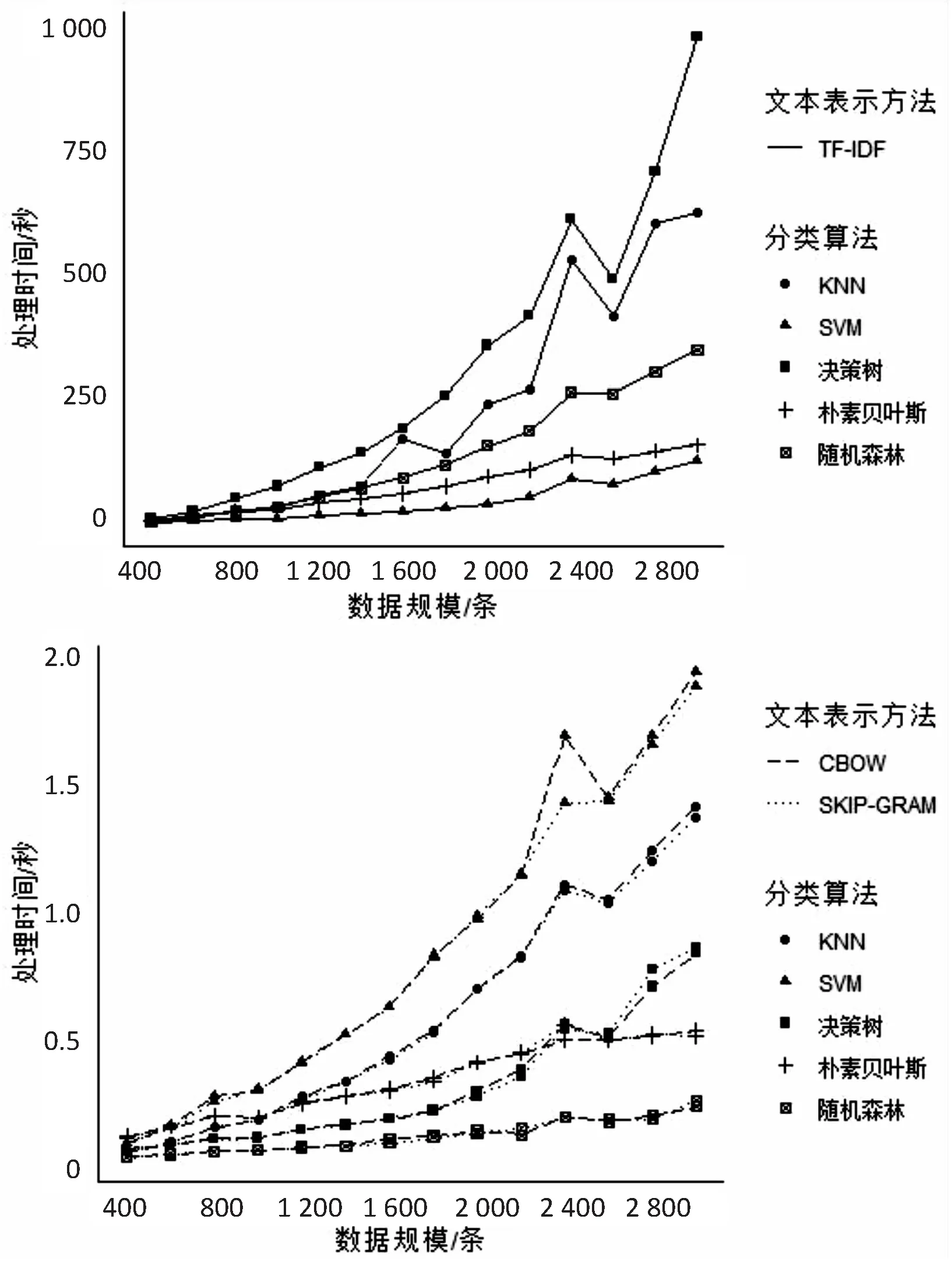
图5 不同数据规模下不同模型的分类建模与预测时间
从图5可以看出:
(1)15种模型的运行时间均与数据规模高度正相关,相关系数如表2所示。
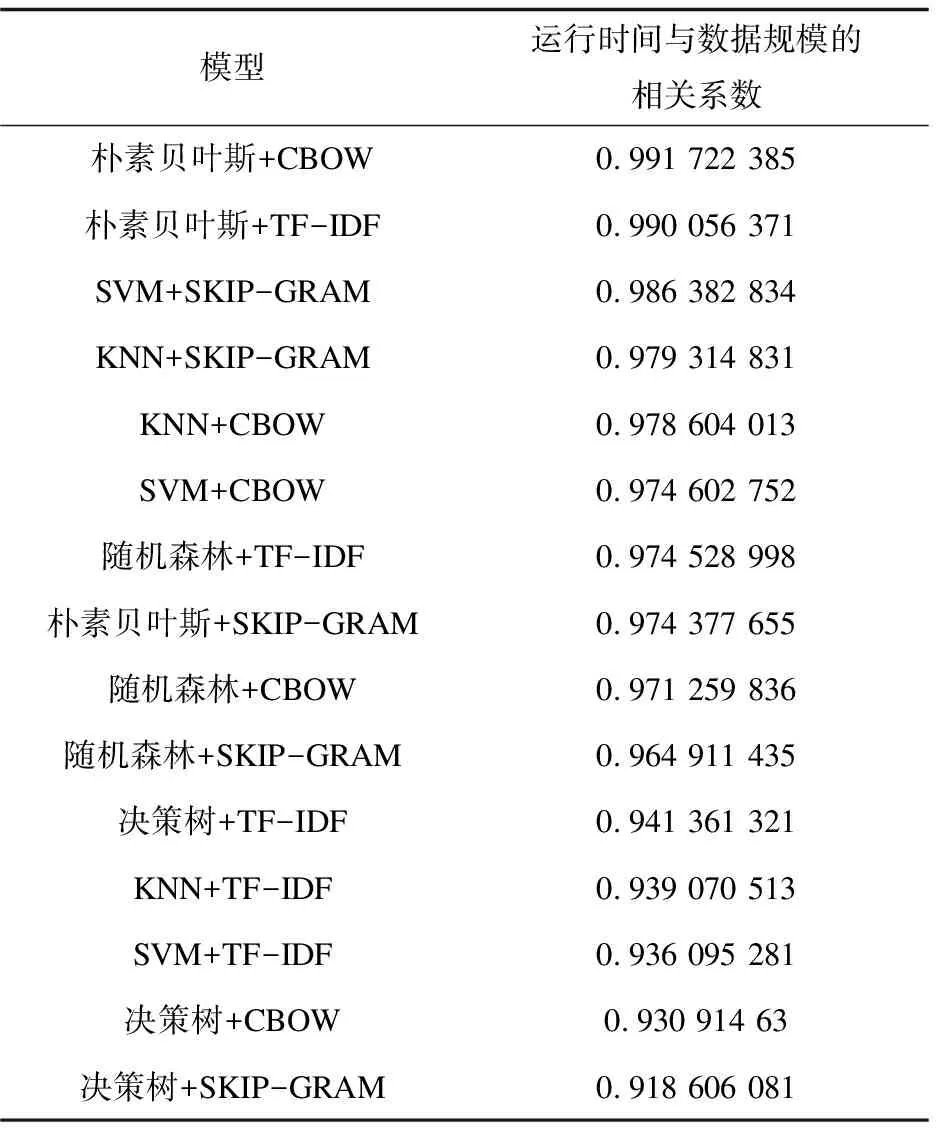
表2 模型的运行时间与数据规模的相关性
(2)在相同数据规模、相同的文本分类算法下,文本特征表示使用TF-IDF的模型运行时间远远超过文本特征表示使用词嵌入模型的运行时间。
(3)综合来看,在相同的数据规模下,随机森林+CBOW模型的运行时间最短;而决策树+TF-IDF模型的运行时间最长。最短时间与最长时间的线性拟合关系如图6所示。
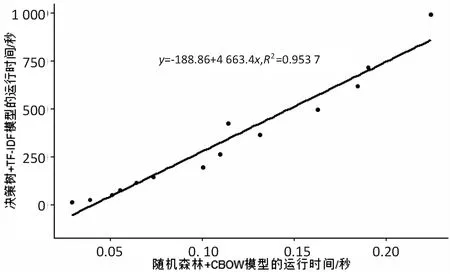
图6 随机森林+CBOW及决策树+TF-IDF模型 运行时间的线性拟合
3.4.3 模型的分类效果比较
文本多分类模型的分类效果使用Kappa系数来衡量,15种模型在不同数据规模下Kappa系数的变化如图7所示。
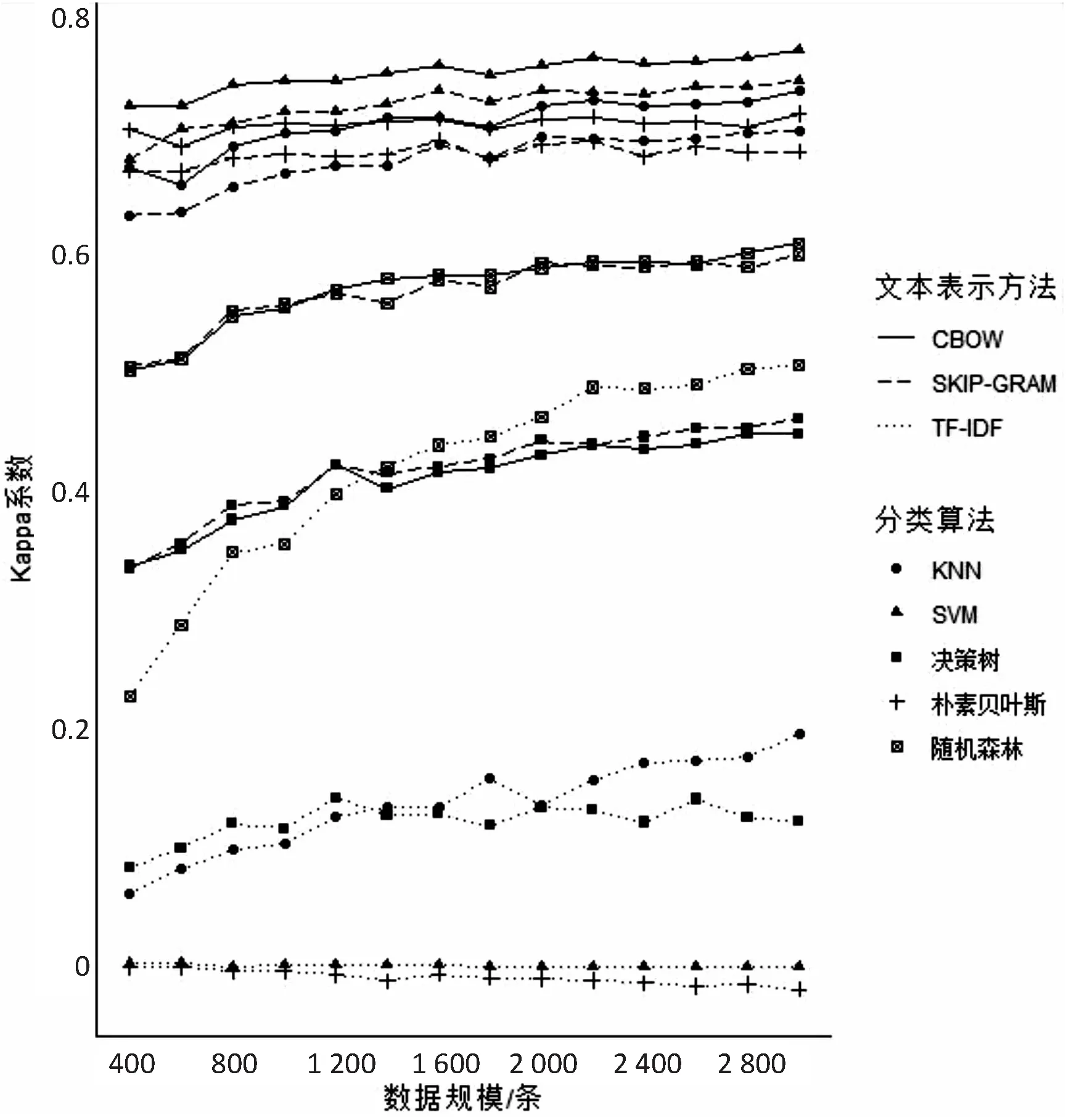
图7 不同数据规模下不同模型的分类效果
从图7可以看出:
(1)在本研究的任何一种数据规模下,SVM+CBOW模型的分类效果都是最好的;而朴素贝叶斯+TF-IDF模型的分类效果则最差。
(2)在相同的数据规模、相同的分类算法下,文本表示使用TF-IDF方法的模型分类效果都是最差的;使用词嵌入方法的分类模型的Kappa系数要比使用TF-IDF的模型的Kappa系数大很多;两种词嵌入模型的Kappa系数相差不大,总体来说,CBOW模型的分类效果略优于SKIP-GRAM模型。
(3)随机森林作为集成算法,容易给人造成的误解是:其性能一定比单一算法要好。但比较结果发现,在本研究中,当使用词嵌入进行文本特征表示时,随机森林的分类效果虽然比单一决策树的分类效果要好,但却比SVM、KNN、朴素贝叶斯的分类效果差;当使用TF-IDF进行文本特征表示时,随机森林的分类效果最好,然后依次是决策树、KNN、SVM和朴素贝叶斯。这说明:随机森林在高维度、大规模数据集的分类处理上具有一定的优势,但对于少量和低维数据集的分类不一定可以得到很好的分类效果。
15种模型的分类效果与数据规模的相关性如表3所示。
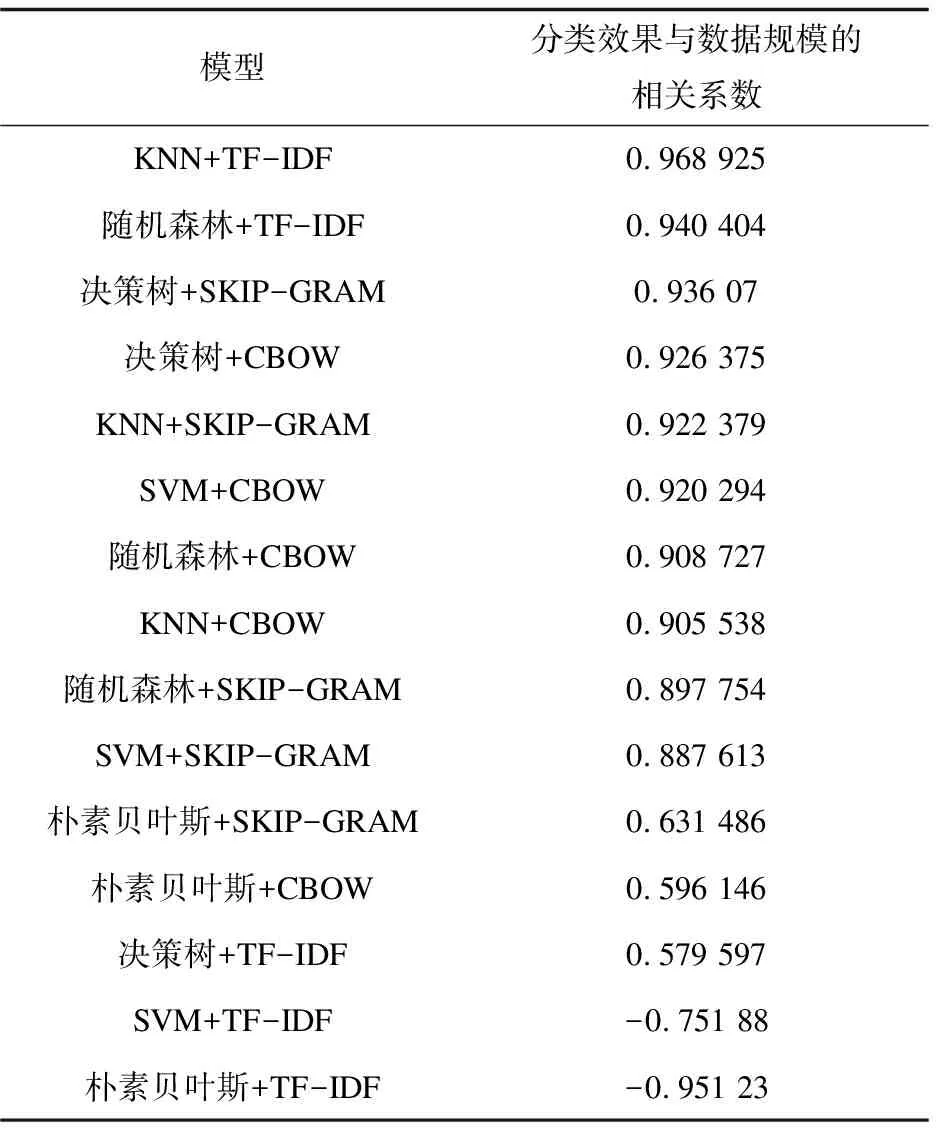
表3 模型的分类效果与数据规模的相关性
从表3可以看出:
(1)KNN算法和随机森林算法与高维的TF-IDF文本表示方法组合时,数据规模越大分类效果越好,说明这两种算法适合对数据量大、高维的数据集进行分类处理。
(2)决策树算法与低维的词嵌入文本表示方法组合时,分类数据量越大分类效果越好,说明决策树方法适合对大量的低维数据进行分类处理。
(3)朴素贝叶斯和SVM算法明显不适合对高维数据进行处理,当使用TF-IDF进行文本表示时,分类数据量越大,这两种算法的分类效果越差。
4 结束语
本研究综合考虑了数据规模、数据维度(文本表示方法)、分类算法三方面,设计了多类别文本分类方法比较方案,从时间和分类效果两个维度评估分类模型的性能。综合评估后认为,对于多类别文本分类问题:
(1)文本特征表示不建议使用TF-IDF方法。使用TF-IDF方法,尽管在前期文本特征表示的处理时间上有一定的优势,但是由于文本特征矩阵过于稀疏和庞大,导致分类模型的运行时间过长、分类效果亦极不理想。
(2)在两种word2vec词嵌入算法中,建议选择CBOW方法,该方法不仅在文本特征表示阶段具有明显的时间优势,而且在建模阶段,CBOW与朴素贝叶斯、SVM、KNN算法组合的模型分类效果均非常理想。
(3)在分类算法的选择上,当数据规模不是很大时,不建议选择随机森林等集成算法,随机森林算法的优势体现在对高维数据的处理上,其与词嵌入文本表示方法组合未必能达到非常理想的分类效果。
猜你喜欢
客联(2022年3期)2022-05-31
中国新闻周刊(2021年26期)2021-07-27
电脑爱好者(2021年9期)2021-05-12
少儿画王(3-6岁)(2020年4期)2020-09-13
科学与信息化(2019年28期)2019-10-21
东方教育(2018年20期)2018-08-22
电脑爱好者(2017年7期)2017-05-06
科学与财富(2016年32期)2017-03-04
决策与信息·下旬刊(2013年1期)2013-03-11
微型计算机(2009年4期)2009-12-23
