
基于多层注意力机制的服装电商评论情感分析
2022-02-22 12:20胡新荣刘军平何儒汉
计算机技术与发展 2022年1期
胡新荣,王 哲,刘军平*,彭 涛,何儒汉
(1.湖北省服装信息化工程技术研究中心,湖北 武汉 430200;2.武汉纺织大学 数学与计算机学院,湖北 武汉 430200)
0 引 言
Web2.0时代,网购逐渐走入人们生活,网购后会留下大量评论。这些文本会蕴含一些买家的使用信息和使用态度。通过深度神经网络算法对这些文本进行分析,提取商品评论中蕴含的情感倾向,广泛运用于商品的推荐中,为推荐系统提供参考。
目前,关于商品评论的情感分析,主流方法有如下两种:一种是通过人工构建对应的情感词典,然后用规则词典去完成情感分析。步骤是,首先需要通过人工构建一系列的情绪词典,然后去指定一些规则,通过构建的词典把文本中非结构化的情绪特征提取出来。但人工构建词典会浪费许多时间,在鲁棒性方面表现很一般。另外一种就是通过机器学习算法来完成情感分类,人工标注好实验数据集,然后运用机器学习算法来提取文本的情感特征,最后完成文本的情感预测结果。主要的机器学习分类算法有支持向量机(SVM)、决策树等。这些算法虽然可以很简单快速地对文本进行情感分类,但是在文本情感特征提取方面比较弱,而且忽略了文本上下的结构关系。很难达到比较高的准确率。
近几年,随着深度学习的飞速发展,各类的神经网络模型也被运用于很多方面,在自然语言处理中也得到了广泛的运用。但是因为文本存在一定的口语表达,缺乏逻辑性,情感特征表现不明显,而且很容易忽略文本上下文的结构信息,因此深度学习方法虽然取得了不错的效果,但仍然存在一定的缺陷。
为了解决以上问题,该文提出一种基于多层注意力机制(SD-Attention),融合双向门控循环网络(BiGRU)的服装电商评论情感分析模型(BiGRU-SD-Attention)。因为学术界缺乏现有的数据集,难以对模型的准确性进行验证。因此,该文首先采用了分布式爬虫框架从各大电商网站采集到服装评论数据集,对数据集进行清洗,通过gensim训练出文本专有的情感词向量,对词向量进行一定的拼接并作为服装电商评论情感模型的输入。利用双向门控循环网络来提取文本的情感特征,并针对词语级和句子级分别使用注意力机制,重新加权计算得到最后的情感特征权重,输出分析结果并进行可视化。实验结果表明,该模型相对目前的机器学习和深度学习循环神经网络在各方面都取得了不错的效果,验证了模型的有效性。
1 相关工作
文本情感分类任务主要是通过算法分析文本中蕴含的情感倾向,来判断用户存在的主观态度。最早期Pang在文本情感分类方面,运用人工构建的词袋模型来进行研究。后续有研究人员尝试设计更合理的词典来提高情感分类的准确率,但是这些方法都是基于词典规则的。Taboada等人根据不同的词性构建了不同强度的情感词典,然后对文本中进行加权得分最后实现文本情感分类。肖红等人通过人工构建情感词典,然后与文本句法相结合,最后运用于网络舆情的情感分析研究。杨鑫等人通过人工构建民宿方面的情感词典,来完成民宿评论的情感分析。
为了解决传统机器学习方法中构建特征工程存在的问题,人们开始将深度学习方法运用于文本情感分类中。Hinton首次提出了词向量的概念。主要对分词处理后的文本,运用对应的映射关系,将文本词语投影到低维向量空间,从而极大地保留了文本词语之间的语义关系。Bengio实现了n-gram三层神经网络语言模型,Mikolov首次提出Word2Vec模型,还实现了CBOW方法。随着词向量的提出,极大地促进了深度学习在自然语言处理文本情感分类方面的运用。如Kim等将卷积神经网络(CNN)运用于电影评论文本的情感分析。虽然这些深度学习方法相比传统的机器学习和人工构建情感词典的方法取得了不错的效果,但是也存在一定的缺陷。因为忽略了文本之间存在的上下文关系,无法获取到文本的结构信息。对此,Mikolov首次将循环神经网络(RNN)运用于文本情感分类,取得了比CNN更好的效果,但是在处理时序性文本的时候,也会出现梯度爆炸、梯度消失等现象。Wang等在Twitter文本数据集上采用了LSTM网络模型来进行情感倾向的预测。
注意力机制最先应用在图像处理方面。随后Bahdanau等将注意力机制运用于机器翻译,Google也采用了这项技术。而后注意力机制得到了广泛应用,比如在关联提取、命名体识别、文本摘要中都有不错的效果。
深度学习神经网络已经在人工智能领域取得了不错的效果,但是作为算法模型验证的基础,一个良好的数据集,加上优秀的算法模型,才能更好地解决遇到的各种实际问题。针对目前学术界尚未存在公开的服装电商评论文本数据集的问题,该文首先设计了一种分布式爬虫系统,可以有效地从各类电商网站采集到服装评论文本,并经过清洗处理制作成文本实验所需数据集。其次针对现有算法存在的缺陷,提出了一种融合多层注意力机制的电商服装情感分类模型(BiGRU-SD-Attention)。经过实验验证,得出该模型可以更有效地提取到评论文本中的情感倾向特征,通过多层注意力机制对这些情感特征加权,达到提高准确率的效果。
2 研究内容及框架模型
该文构建的用于情感分析的模型结构如图1所示。
该算法框架主要包含文本输入层、多层情感特征提取层、多层注意力机制层和情感分析输出层。
2.1 文本输入层
对于文中算法模型,在学术界缺乏相关的服装电商评论文本。而文本数据集作为算法模型最重要的部分,数据集的质量往往对算法模型起着至关重要的作用。为了解决这一问题,采用分布式爬虫技术从各类服装电商网站采集了众多服装电商评论文本,经过清洗整理后,作为文中算法模型的验证数据集和输入。
因为服装评论文本包含了人们评价的主观色彩,具有很强的口语化,因此在使用文中算法模型训练的时候,需要将采集好的电商文本情感数据集进行清洗。删除掉重复文本,去掉停用词及一些特除的符号,然后分词。如“这件、衣服、质量、还不错,手感、舒服、颜色、鲜艳”,将切分好的词语文本进行词向量训练,通过Word2Vec模型生成服装电商文本的词向量,将获取到的词向量输入到后续的词编码器。
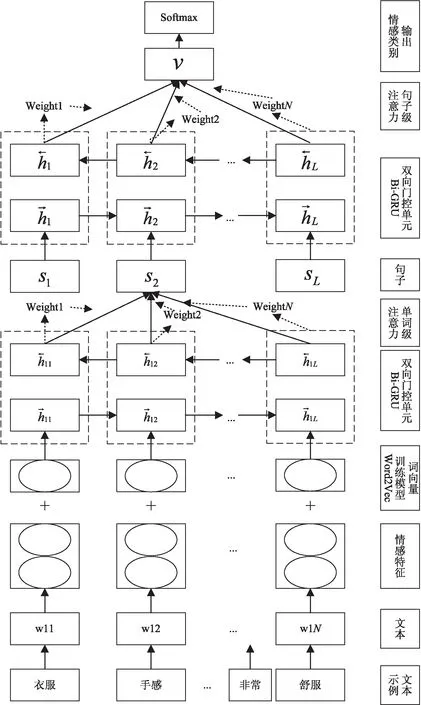
图1 算法框架
2.2 多层BiGRU特征提取层
GRU作为LSTM的一种变体模型,取消了单元状态,通过隐藏状态来传递信息。相对于LSTM更加简单高效,提高了训练的速度。BiGRU模型如图2所示。
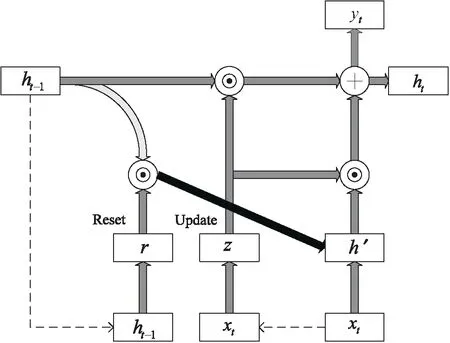
图2 BiGRU模型
z
=σ
(x
+h
-1)(1)
其中,x
为输入序列X
的第t
个分量,通过线性变换与矩阵相乘。h
-1为前一时刻t
-1的分量,通过线性变换与矩阵相乘,相加输入到Sigmoid中并压缩。更新门决定多少信息传输到未来。r
=σ
(x
+h
-1)(2)
重置门r
与更新门一样,x
和h
-1通过线性变换与矩阵相乘然后相加。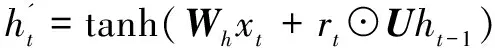
(3)
x
和h
-1通过线性变换,分别右乘矩阵和,然后计算与重置门的Hadamard乘积,该乘积决定需要保留和遗忘的信息。
(4)
最后需要计算h
,它表示当前单元信息传递到下一个单元。z
为更新门的激活结果,它同样控制了信息的输入。
(5)
GRU作为一种前向传播算法,但是单向传播忽略了反向的特征信息,因此本模型针对服装电商评论文本的特殊性,采用了双向的GRU算法Bi-GRU作为提取到文本的前后有用信息。
2.3 多层注意力机制层
该文将采集好的服装电商评论文本数据集,按照词语级别和句子级别进行划分,然后分别对词语级别和句子级别使用注意力机制,通过不断的调整计算,分权求和,最后求出最终影响较大的权重特征,有效提高了情感分类的准确效果。
基于词语级别的注意力机制的具体流程如下所示:
u
=tanh(W
h
+b
)(6)
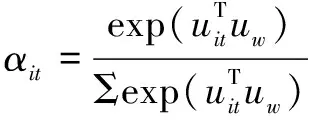
(7)
s
=Σα
h
(8)
式(6)中的u
表示为BiGRU输出h
的隐藏单元,然后通过式(7)中softmax归一化得到更新后的权重系数α
。u
是一个初始训练参数,s
是最后得到第i
个句子的向量。基于句子级别的注意力机制的具体流程如下所示:
u
=tanh(W
h
+b
)(9)
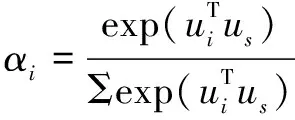
(10)
v
=Σα
h
(11)
在句子级别方面,式(9)~式(11)计算方式类似于上面,最后通过双层的注意力机制,输出得到最终整条评论基于单词和句子文本的情感特征向量v
。2.4 情感分类输出层
服装文本情感向量v
是文本的高级表示方法,在向量v
上通过式(12)softmax分类输出服装电商评论文本的最后情感倾向。p
=softmax(W
v
+b
)(12)
与其对应的损失函数如式(13)所示:
L
=-∑logp
(13)
3 实验设计与分析
3.1 实验环境设置
实验环境配置如表1所示。
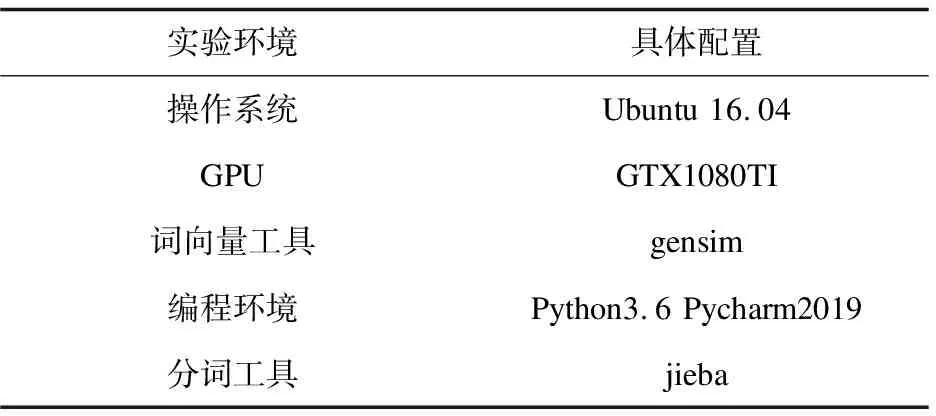
表1 实验环境配置
3.2 实验流程
实验流程如图3所示。
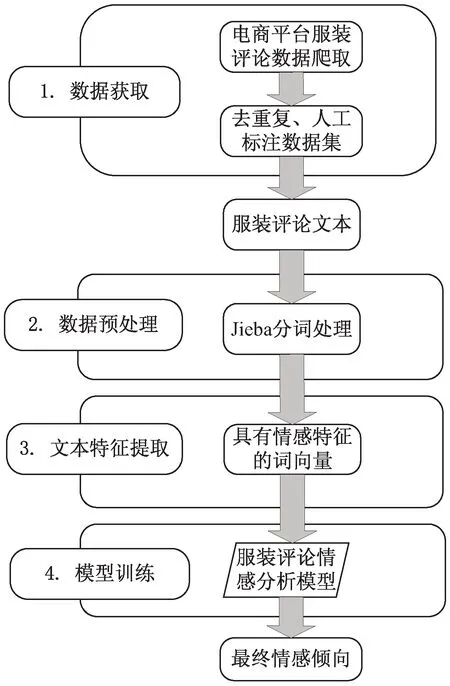
图3 实验流程
3.2.1 数据的获取和处理
数据的获取和预处理作为算法模型的第一步,任何一个算法模型的训练都离不开基础数据的获取和处理。而文中的算法模型,服装电商评论文本情感分析,现有的学术界难以找到存在的相关数据集。为了验证算法模型的有效性,文中利用相关技术,从服装电商网站采集了相关的服装电商评论文本数据。
首先搭建了一个分布式爬虫系统,通过本系统的相关功能,从主流电商平台爬取了关于电商服装的评论。各类电商网站,为了防止恶意访问和采集数据,也设置了一定的反爬虫措施,禁止同一时刻多次采集网站内容,从而影响了服装电商评论文本数据的采集效率。文中的分布式爬虫系统,通过设置IP代理池,伪造请求头,采用分布式Redis缓存,可以高效采集文本数据集。
经过人工删除部分重复的评论和少数没有情感倾向的评论,最终收集到服装电商评论文本10 000条。通过人工对采集好的服装电商文本进行简单的标注。Pos、Neg倾向分别标注为1、0。最后根据实验需要,划分好数据比例,如表2所示。
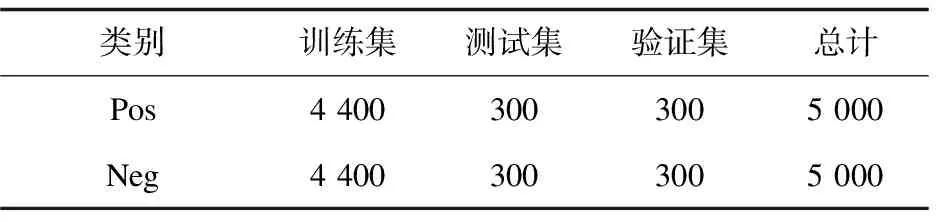
表2 商品评论数据集划分
而电商文本通常具有一定的口语化特征,也会融入一些特殊的字符和表情符号,例如,好评:“面料不错,穿起来很舒服,夏天穿着很凉爽”,差评:“质量不是一般的差,褪色粘毛,还起球”。在算法模型训练之前需要对这些电商文本进行预处理。去掉重复字、繁体字及特殊字符,划分好服装电商评论文本,然后用jieba进行分词,用Word2Vec训练文本的情感词向量,作为后续算法模型的输入。
3.2.2 模型的训练与参数设置
本模型是在PyCharm开发工具上面,基于TensorFlow深度学习框架搭建的服装商品评论模型。通过清洗、划分、训练词向量,输入到本文构建的服装商品评论模型中。训练过程中,为了使得模型训练参数最优,模型最后输出结果最佳,采用了网格调参法。
为了得到更好的模型参数,对采集到的服装电商评论文本做了简单的分析,如图4所示。
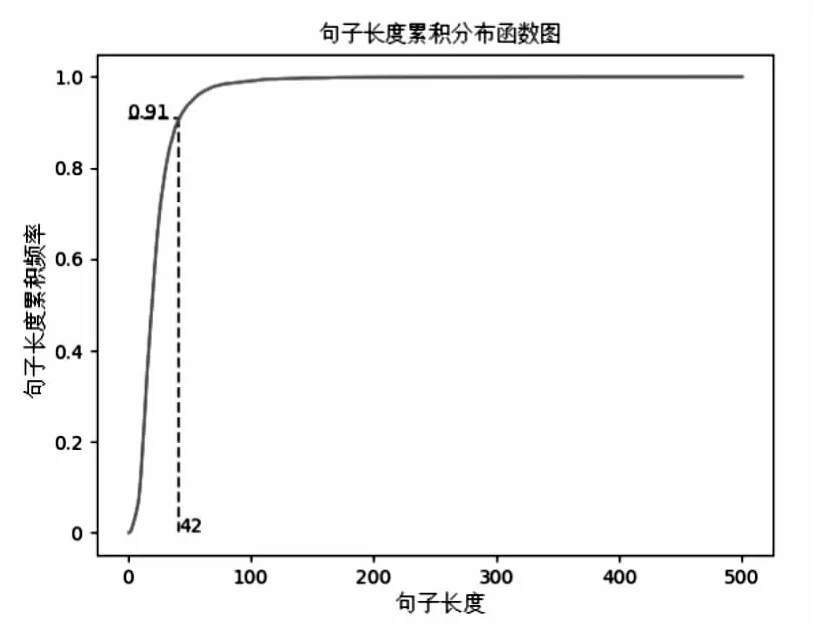
图4 服装文本数据长度分布
根据文本数据长度得知,当选取长度为42时,可以覆盖91%的长度文本。具体的参数设置如表3所示。

表3 模型参数设置
最后根据模型在验证集上的效果,来决定是否进行下一次迭代。
3.2.3 实验结果分析
在模型验证过程中,设置了对比实验。分别采用SVM、LSTM、BILSTM、BiLSM-Attention与文中提出的基于多层注意力机制的BiGRU-SD-Attention进行对比。在服装电商评论文本分类过程中,为了验证模型的优劣,主要采用精确率(Precision)、准确率(Accuracy)、召回率(Recall)和F1值(F1-score)作为评价指标,结果如表4所示。
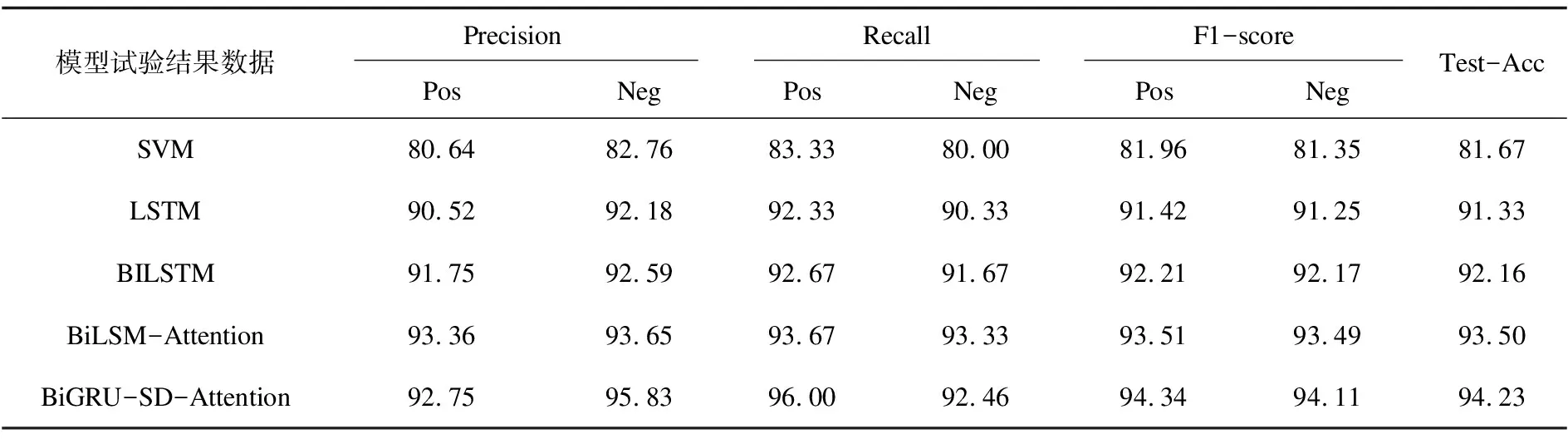
表4 实验结果比较 %
根据表4的实验数据进行分析对比:
(1)基于深度学习的循环神经网络模型LSTM、BILSTM对比机器学习模型SVM在性能上有了显著的提升,考虑了服装电商文本存在一定的时序性,因此证明循环神经网络对比传统的机器学习算法在性能上有了不错的提升。
(2)加入注意力机制的循环神经网络Attention-BILSTM相比LSTM、BILSTM在性能上有了显著的提升。因为注意力机制的引入,可以更好地分配不同词语特征之间的特征权重,从而得到更加准确的服装电商评论文本的最终情感倾向,进一步证明了注意力机制在本算法模型中的有效性。
(3)文中提出的基于多层注意力机制的BiGRU-SD-Attention模型,既考虑了服装电商文本的时序性,融入了BiGRU门控循环网络,又考虑了在不同层次之间情感特征权重的不同,在词语级别和句子级别分别引入了Attention注意力机制。最终的实验结果也很理想,其中准确率达到了94.23%,相比其他算法有了显著的提升。可以更好地解决文中提出的服装电商评论文本情感分析问题。因此,BiGRU-SD-Attention模型对比其他的算法模型取得了较高的性能提升和不错的效果。
3.3 实验结果可视化
为了验证模型算法的可靠性,将部分验证集的服装电商文本权重特征进行了可视化。通过不同的颜色深度反映在注意力权重计算中不同情感特征的影响力。颜色越深代表影响越重,反之如此。从图5可以看出,对于积极和消极影响权重较大的词语都做了标注,由此验证了BiGRU-SD-Attention模型的有效性。

图5 注意力机制情感特征可视化
4 结束语
针对传统的机器学习分类方法存在文本特征提取不足的缺陷,该文提出一种基于多层注意力机制的BiGRU-SD-Attention模型。通过实验表明,经过分布式爬虫采取到的数据集,通过预处理训练出来的词向量,通过双向门控网络来提取特征,最后融入注意力机制来提高重要特征的权重,进行电商文本的情感分类,得到了不错的效果。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
小雪花·成长指南(2022年1期)2022-04-09
小太阳画报(2019年3期)2019-06-11
米娜·女性大世界(2016年9期)2016-12-02
第二课堂(课外活动版)(2016年2期)2016-10-21
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
股市动态分析(2015年20期)2015-09-10
中学英语之友·高一版(2008年10期)2008-12-11
阅读(中年级)(2006年2期)2006-03-07
