
基于深度强化学习的恶意软件混淆对抗样本生成
2022-02-19 10:24严莹子王小平庄葛巍
计算机应用与软件 2022年2期
严莹子 王小平* 庄葛巍 顾 臻 贺 青 史 扬
1(同济大学电子与信息工程学院 上海 200092) 2(国网上海市电力公司电力科学研究院 上海 200436) 3(同济大学软件学院 上海 200092)
0 引 言
据卡巴斯基实验室统计报道,在2016年被恶意软件攻击的设备多达2 871 965台,2017年多达1 126 701台,2018年多达830 135台。面对如此大量的恶意软件攻击案例,传统的基于签名的检测技术[1]已经难以覆盖大量新型恶意程序,而机器学习可以更加快速准确地将海量信息应用到恶意代码检测任务当中,以应对层出不穷、复杂且不确定的攻击方式。在机器学习中,特征提取是非常关键的数据处理步骤。恶意软件的特征提取方法分为静态特征提取和动态特征提取[2]。静态检测的优势在于检测速度较快,但检测结果容易受到代码混淆、加密和压缩等代码变换的影响,很难应对未知的恶意软件以及恶意软件变种[3];动态检测虽有不易受到代码变换影响的优势,但由于需要代码在沙箱环境中实际运行,因此可能因执行环境配置不完善而无法触发程序的恶意攻击行为,并且比静态分析需要更多时间。考虑到机器学习方法需要大量样本,本文主要关注静态特征提取方法。
近年来,基于机器学习的静态检测方法相继被提出,比如基于卷积神经网络(CNN)[4-5]、循环神经网络(RNN)[6]、长短时记忆网络(LSTM)[7-8]和门控循环单元(GRU)[9]等模型,但这些模型在包含混淆样本的数据上,漏检率和误判率都比较高。这是因为基于机器学习的检测模型存在独立同分布的要求,未知的恶意软件与已知的作为模型训练集的恶意软件需要有相似的特征分布,而代码混淆技术可以一定程度上更改样本原本的特征分布,因此机器学习模型容易受到基于代码混淆的攻击。
考虑到混淆对基于机器学习的恶意软件检测模型造成的干扰,本文认为混淆样本和机器学习中的对抗样本[10]有共通之处。在机器学习中,对抗样本是在数据集中通过故意添加细微的干扰所形成的输入样本,这种样本导致模型以高置信度给出一个错误的输出。虽然对抗样本给机器学习、深度学习带来了质疑,但其实这也提供了一个修正模型的机会,因为可以反过来利用对抗样本来提高模型的抗干扰能力,因此提出了对抗机器学习(Adversarial Machine Learning,AML)的概念。在恶意代码检测的领域中,结合GANs的思想,Hu等[11]提出一种基于GANs的方法,从代码中提取系统级别API特征,首先生成固定长度的二进制特征向量;然后通过在特征向量中添加随机噪声的方式产生对抗样本,以扰乱判别模型对样本是否属于恶意代码的判断;最终在生成模型和判别模型的交替训练下,生成模型能生成更具有迷惑性的恶意代码对抗样本,判别模型也能更好地抵抗样本中随机噪声的干扰。类似文献[11]对恶意代码在特征级别上进行混淆的研究思路还有文献[12]和文献[13]。但比起在PE二进制文件提取的特征上进行混淆,对PE二进制文件先进行代码混淆再提取特征更贴近于真实的应用场景,因此本文研究的混淆是针对原始恶意代码的,即使用机器学习算法模拟真实的恶意代码混淆,对恶意代码检测模型进行检测逃避攻击。
Suciu等[14]提出了两种针对原始代码的对抗样本生成方式:(1)在PE二进制文件的末尾加入对抗噪声。(2) 在PE文件中寻找不会映射到内存的部分加入对抗噪声。该研究对不同方式生成的对抗噪声进行实验,包括随机产生字符、基于梯度产生字符和从合法样本中提取字符。文中提到基于梯度的恶意代码对抗样本生成方法也是一个热门的研究方向,与之类似的研究还有文献[15]和文献[16]。但使用基于梯度的方法生成对抗样本是在白盒攻击模式下的,要求攻击者完全知晓恶意代码检测器的模型和参数,这在现实情况下通常难以实现。
Anserson等[17-18]在2017年首次提出一种基于RL的恶意样本逃逸攻击方法,结合了多种代码混淆算法对基于机器学习的恶意软件检测模型进行黑盒攻击。该方法使用了ACER(Actor Critic with Experience Replay)算法[19],用神经网络来估计一个价值函数,根据价值选取一个策略对恶意样本进行多次混淆尝试,如果当前样本在有限的混淆次数内成功逃避了恶意软件检测器的检测,则会产生一个较大的奖励值,若逃逸失败,则无法得到奖励。通过奖励值的引导,最终算法会学习到一个有效的混淆策略,在尽可能少的混淆次数内使样本更大概率地逃逸检测。该方法巧妙地将恶意代码混淆对抗样本生成的问题建模为一个马尔可夫决策过程(MDP),为恶意软件逃逸攻击提供了一种新颖的解决方案。但该方法的效果还有待提升。该模型在200个样本组成的测试集上的逃逸率仅24%,只比随机混淆算法高出1%。
本文面向代码混淆的恶意软件对抗样本,借鉴了Anserson等[17-18]提出的基于RL的恶意软件逃逸攻击框架,对模型进行了如下改进:
(1) 在RL的状态空间中加入了“历史帧”。
(2) 本文在ACER模型中加入了具有记忆性的历史帧模块和LSTM模块,提高了测试集上的检测逃逸率。
(3) 将混淆分为了预混淆阶段和RL混淆阶段。
1 相关理论和技术
1.1 PE文件的结构框架
PE文件是在Windows操作系统上执行的二进制映像的标准文件格式,扩展名通常为“.exe”“.dll”或“.sys”,它们会首先被操作系统加载器加载到系统内存中,然后由系统执行。
PE文件不是作为单一内存映射文件被装入内存的。PE文件在二进制文件映像中包含多个部分,每个PE部分都可以看作一个文件夹,其中包含各种二进制对象(比如图像文件),由Windows加载器遍历PE文件并决定文件的哪一部分被映射,然后这些被映射二进制对象在运行时被执行。PE文件的框架结构如图1所示。
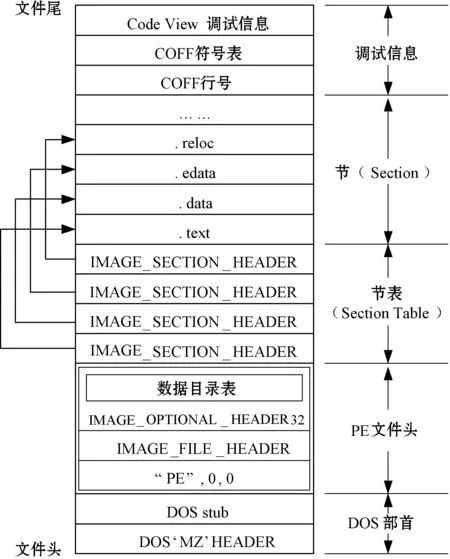
图1 PE文件的框架结构
在PE文件中,最需要关注的是PE文件头、节表(Section Table)和节(Section,也称为块、段)这三个部分。PE文件头包含了有关用于存储代码和数据的不同部分的信息(包括签名)以及从其他库(DLL)请求的导入或所提供的导出。节表包含每个节在映像中的信息(如位置、长度、属性),分别指向不同的节实体。节是PE文件中代码或数据的基本单位,逻辑上将不同的功能区(例如代码区和数据区)划分为多个节。从PE文件的结构组成中可以得知,PE文件中存在许多冗余字段和空间,这可能会为藏匿恶意软件创造机会。
1.2 强化学习模型
强化学习由马尔可夫决策过程(MDP)发展而来,用于解决连续决策寻找最优解的问题。与各种形式的机器学习算法相比,强化学习(RL)的特点是实现了一种试错模式的自动学习,其学习过程不是基于训练数据集进行的,而是基于智能体(Agent)与环境(Environment)之间的相互交互进行的。RL具有以下要素:
(1) 智能体Agent。
(2) 环境Environment(对真实用例建模而成,与智能体进行交互)。
(3) 状态states(智能体当前到达的地方或当前看见的视野)。
(4) 动作Actions(智能体采取不同动作以达到不同状态)。
(5) 策略Policy(智能体根据策略来采取不同动作)。
(6) 反馈Reward(智能体采取正确的动作会得到正向的反馈)。
智能体在具体环境下基于一定策略执行动作,然后得到环境的奖励并迁移到下一个状态,这就是强化学习中的一个典型的交互过程。随着强化学习的进行,智能体会探索在当前状态下用怎样的策略来执行动作才能使最终得到的奖励达到最大。
2 混淆对抗样本生成方法
2.1 方案概述
在RL中,智能体在某一状态S下执行某一动作A,环境会根据设定来判断该动作的好坏,然后反馈给智能体相应的奖励R,并且转移到下一个状态S’。RL恶意样本混淆对抗样本生成模型的框架如图2所示。在框架中分为两个混淆阶段,分别是预混淆和RL混淆,其中RL混淆主要包含四个模块:PE特征提取算法、PE代码混淆算法、RL环境和RL智能体。
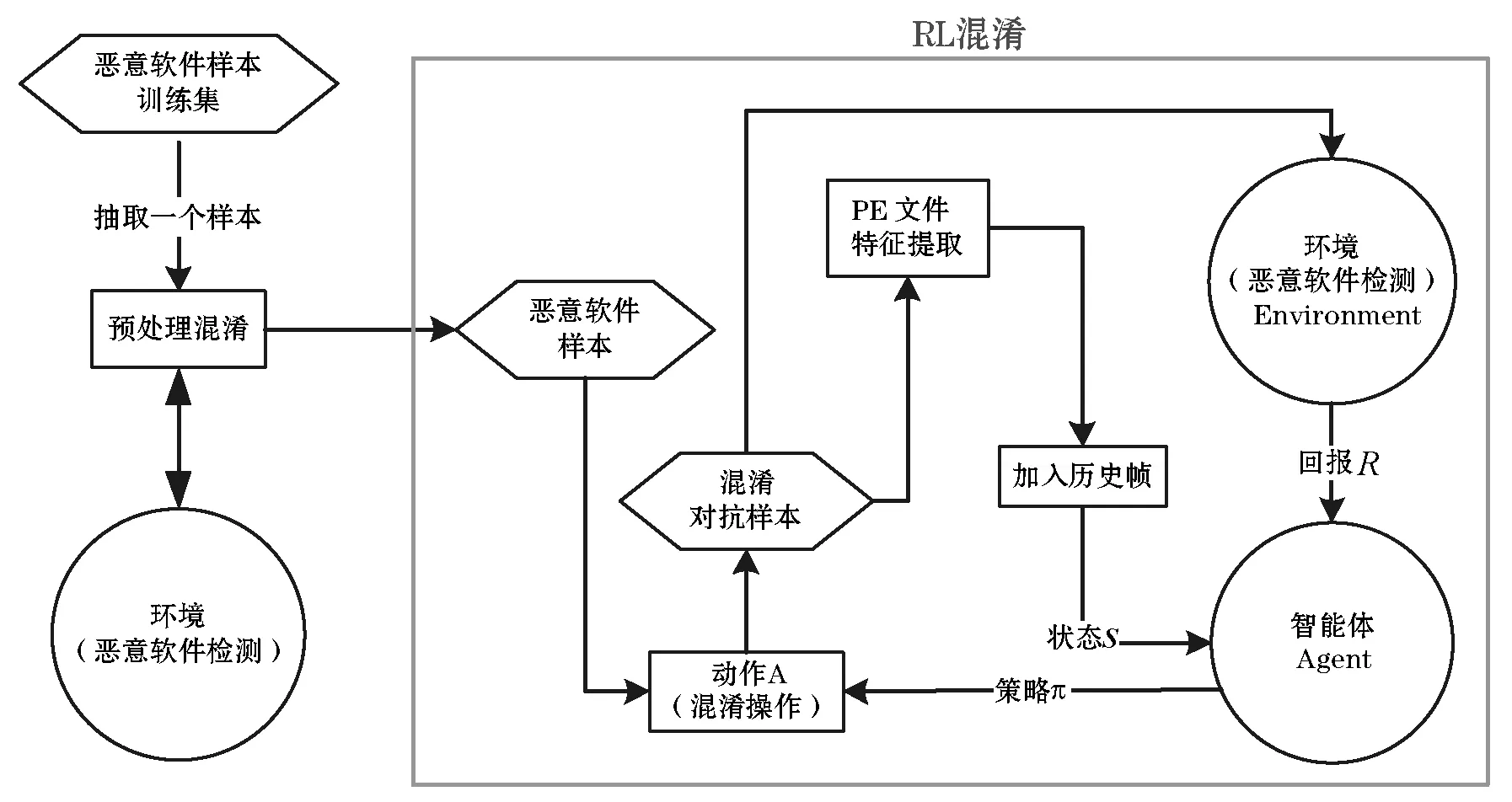
图2 恶意样本混淆对抗样本生成模型框架
本文的RL环境是一个恶意软件检测器,它可以是任何一个检测模型,也可以是一个线上的病毒监测引擎,对本文RL模型而言是一个独立的黑盒检测系统,RL不需要知道它的模型结构或参数,只需要输入一个恶意软件样本,得到一个检测是否为恶意样本的结果。
RL智能体作为算法的主角,与其相关的主要模块如下:
(1) 状态S:状态是智能体的输入,在本文背景下就是恶意软件样本的特征相关信息。本文在RL的状态空间中引入了历史帧(History Frame,HF)技术。
(2) 策略Pi:策略是智能体执行决策的方法,在本文使用的RL模型ACER算法中,智能体执行决策的过程由价值函数神经网络和策略函数神经网络来完成。本文在RL模型中融合了全连接神经网络(FCN)与LSTM神经网络。
(3) 回报R:回报是智能体每执行一个动作后得到的环境的反馈,正确的动作会得到正向反馈,也就是比较大的回报值;错误的动作会得到负向反馈作为惩罚,也就是比较小的回报值。
2.2 RL环境
本文在构建RL模型之前预先训练了一个基于XGBoost[20]的恶意软件检测器作为RL模型进行逃逸攻击的黑盒攻击对象,同时也作为RL的环境,给智能体提供反馈。检测器的输入为PE文件的二进制字节,通过文献[4]所述的算法进行特征提取,然后使用XGBoost二分类模型进行训练和测试。模型的数据集由3 192个合法样本与2 918个恶意样本组成,其中合法样本来自于PortableApps网站[21](包含教育、游戏、影音、网络、安全和工具等类型的软件安装包),恶意软件来自于VirusTotal[22]网站。其中随机抽取了1 192个合法样本和918个恶意样本作为测试集,余下2 000个合法样本和2 000个恶意样本作为训练集。
在进行114次迭代之后,该检测器在训练集上准确率达到100%,在测试集上准确率达到99.57%。
需要注意的是,对于RL模型而言,这个检测器是一个黑箱,即RL模型无法获取这个检测器的模型结构、参数等信息,只能输入一个PE文件的二进制字节,得到检测器反馈的恶意软件指数评分,评分取值在0到1区间,得分越高代表该样本的恶意程度越高。
2.3 RL状态空间
状态(state)又称为智能体的观察(observation),是对智能体的输入,而智能体作出的决策是输出。输入的内容对于智能体的决策过程及最终的输出具有决定性的影响。在恶意软件对抗样本生成的任务中,直观来看,智能体接收的输入信息就是PE二进制文件。但直接通过对PE二进制文件的观察来作出决策,这不论是对人类还是对机器而言都是十分困难的,为了降低RL的学习难度,本文将PE二进制文件进行特征提取,然后将特征进行标准化处理后作为RL智能体的输入。
Saxe等[3]总结前人的研究成果,给出了使用深度学习算法检测恶意软件的具体方法,该方法将PE文件特征提取方式主要分为两类,一类是通过PE文件可以直接获取到的特征,比如字节直方图、字节熵直方图和字符串特征等;另一类特征是需要解析PE文件结构,从各个节分析出的特征,比如节特征、导入表特征、导出表特征和文件头特征等。参考文献[4]提出的特征提取方法,本文从PE二进制文件中一共提取了2 349个特征。
由于RL中的状态转移过程服从马尔可夫性[23],因此RL在当前状态下执行动作并转移到下一个状态,并不考虑之前的状态。但是RL在对恶意软件进行多次混淆决策时,仅根据当前PE特征来选择下一次混淆的动作而不考虑前几次混淆后的特征,于RL而言会损失很多重要信息。为了提高RL的学习效率,本文在RL的状态空间里引入了历史帧(History Frame,HF)技术,在状态空间里保留N份PE特征的历史记录,其中第一份记录始终保持PE文件的初始特征,后续N-1份记录保持最近N-1次混淆产生的PE特征。第一份记录的作用是保留样本的原始信息,这有利于智能体对样本的初始特征进行判断;后续的N-1份记录可以有效引导智能体学习历史动作对样本产生的变化轨迹,学习每份记录之间的关系。
2.4 RL动作空间
RL的动作空间由代码混淆算法组成。为了保持代码的功能以及可执行性,本文采取了以下混淆算法:
(1) 在末尾添加随机字节(Overlay Append,OA)。
(2) 追加导入表[11](Import Append,IA)。
(3) 改变节名称(Section Rename,SR)。
(4) 添加新的节(Section Add,SA)。
(5) 节内末尾追加随机内容(Section Append,SP)。
(6) 删除签名信息(Remove Signature,RS)。
(7) 删除debug信息(Remove Debug,RD)。
在这些混淆算法中,RS和RD这两个混淆算法是“一次性”的,也就是说只有第一次执行这些混淆操作才会对样本产生变更,后续重复操作是无效的。因此本文将RS和RD这两个混淆算法放入了预处理阶段,也就是在RL环境setup时就对样本进行RS和RD的预处理。若预处理后样本已经成功逃逸,则跳过该样本,因为RL模型无法从中学到有用的知识。评估RL模型时也要先对样本进行同样的预处理,然后再进入测试阶段。OA、IA、SR、SA和SP五种混淆算法如表1所示。
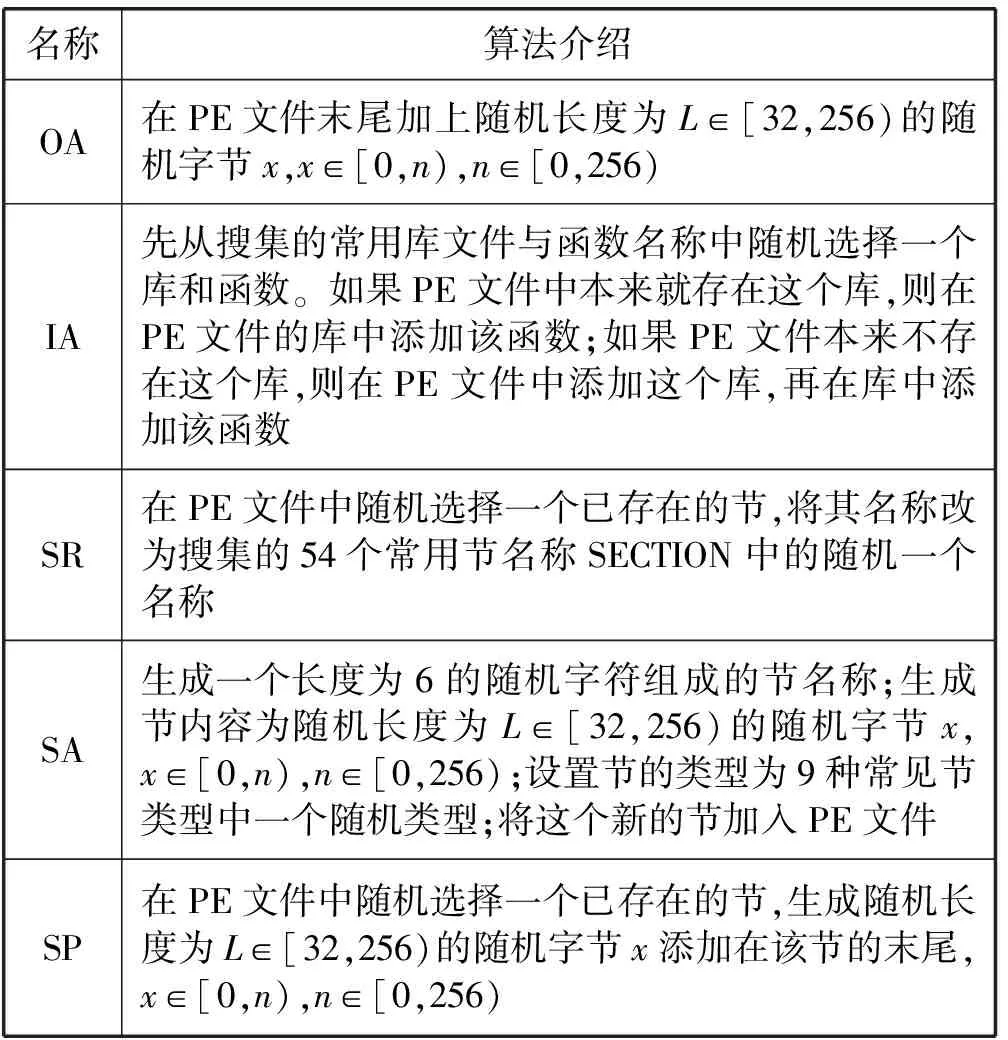
表1 混淆算法
2.5 RL模型设计
对于RL智能体,本文使用ACER算法来实现其功能。ACER是一种Actor-Critic模型,包含Actor和Critic两个部分,其中Actor参考Critic评估的价值函数Q来更新策略函数Pi,并且执行策略;Critic参考Actor执行策略的果效(得到的奖励)来评估策略Pi,并且更新价值函数Q。价值函数Q和策略函数Pi分别用一个深度神经网络来实现,两个神经网络的结构可以相同,也可以不同。在两个网络的结构相同的条件下可以实现部分网络参数共享,就是数据输入的底层网络参数共享,后续接入不共享的两个神经网络,这样做的好处是价值函数和策略函数对输入的数据进行了相同的预处理,并且节约了计算成本。但两个网络不进行参数共享(或者网络结构不同)也具有优势,可以使RL的Actor和Critic拥有独立的处理决策、增强模型稳定性。
对于价值函数Q而言,其输入是RL的状态空间,输出是当前状态下每个动作所对应的价值;对于策略函数Pi而言,其输入是RL的状态空间,输出是当前状态下执行每个动作的概率。
在HF模块(如图3所示)与LSTM模块(如图4所示)的基础上,本文构建了四种ACER模型结构,分别表示为HF、HF_LSTM、LSTM_HF和LSTM,四种结构如表2所示。在这四种模型中,当历史帧参数HISTORY_FRAME设置为1时,HF模型退化为不具有记忆性的普通全连接网络ACER模型,HF_LSTM模型退化为仅价值函数具有记忆性的ACER模型,LSTM_HF模型退化为仅策略函数具有记忆性的ACER模型,而LSTM模型本就是策略函数与价值函数都具有记忆性的ACER模型,不受HISTORY_FRAME参数设置的影响,因此其默认HISTORY_FRAME=1;当历史帧参数HISTORY_FRAME设置为大于1时,HF模型、HF_LSTM模型和LSTM_HF模型都属于策略函数与价值函数都具有记忆性的ACER模型。
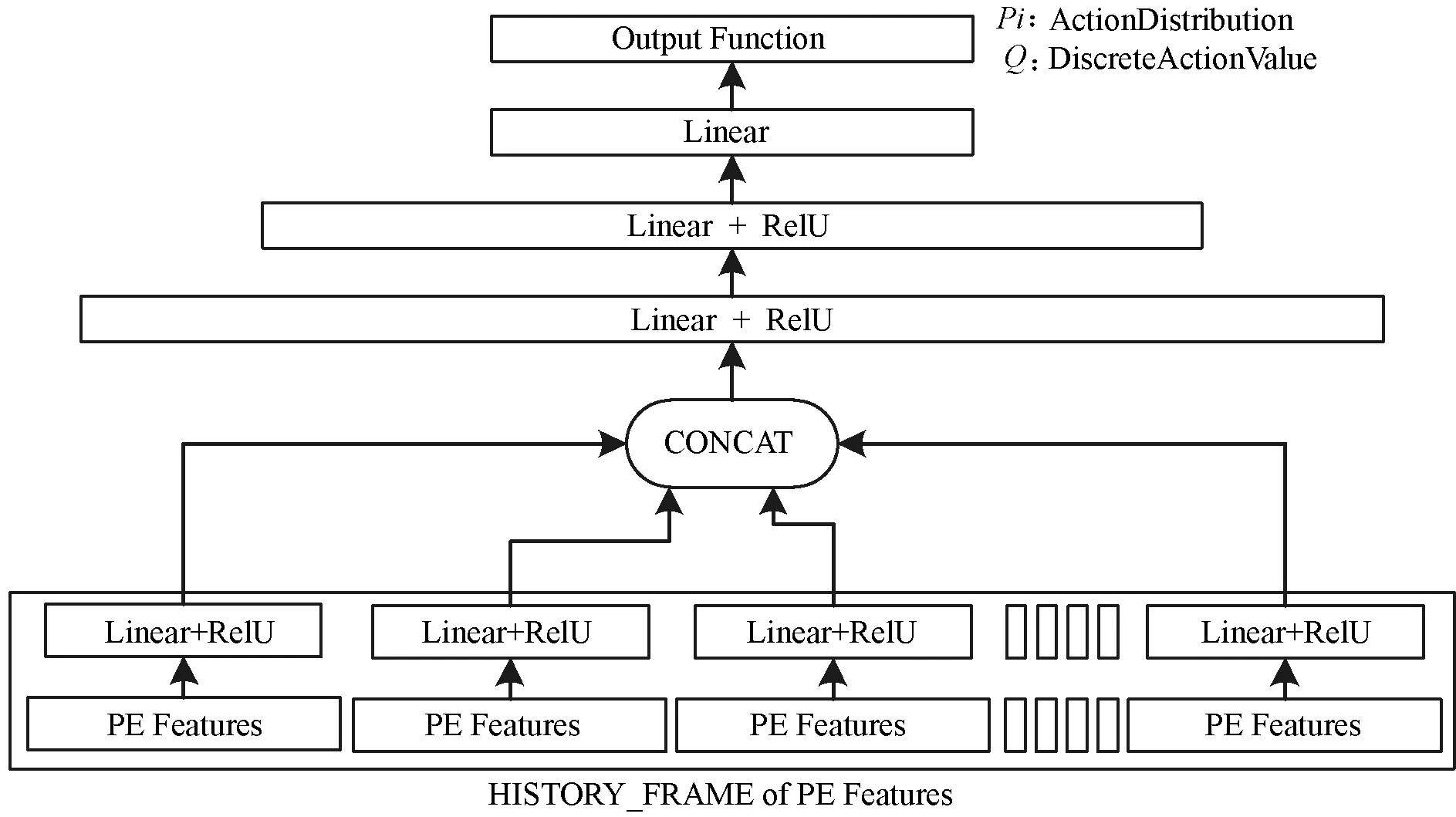
图3 HF模块
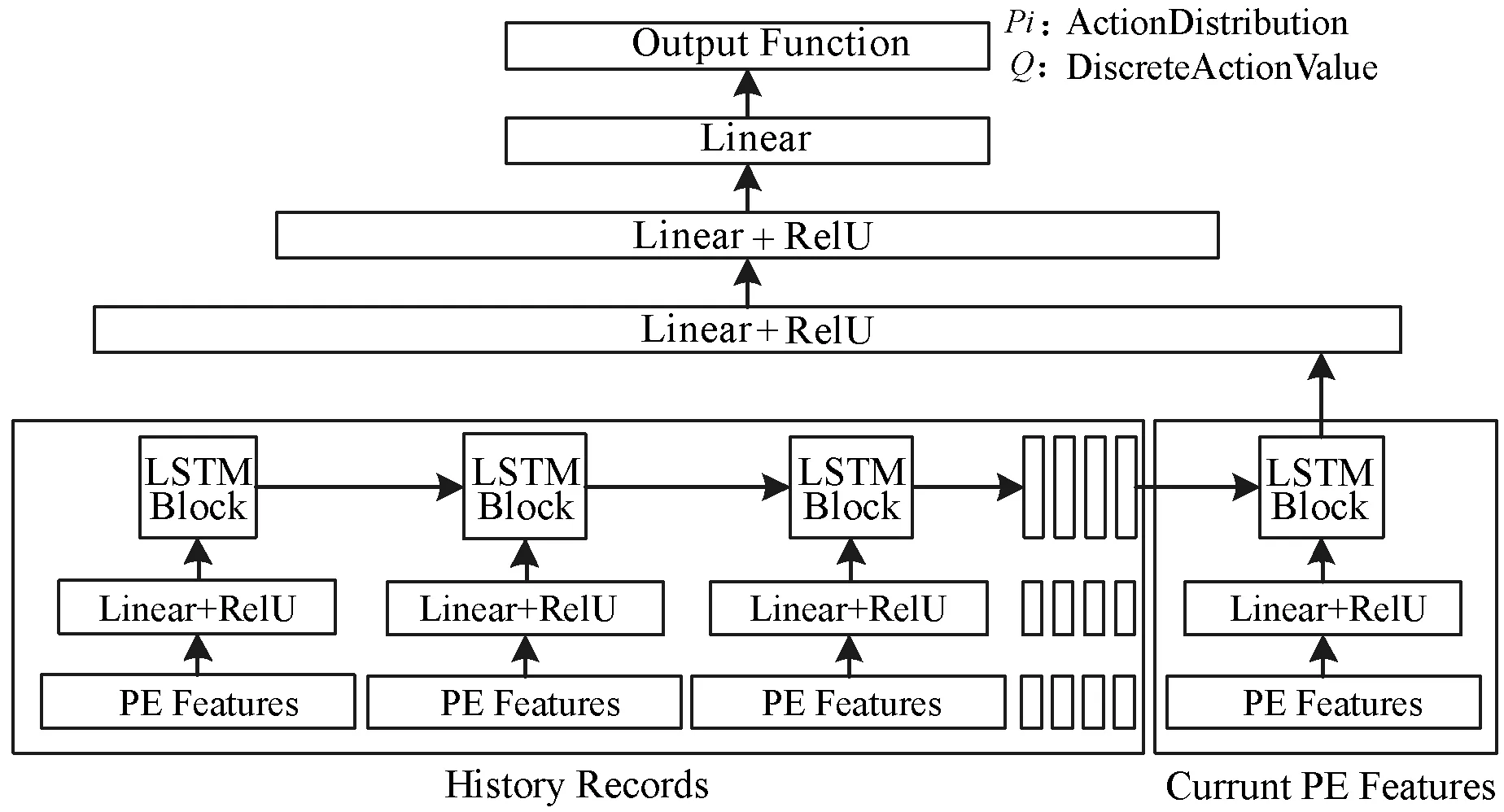
图4 LSTM模块

表2 四种ACER模型结构
2.6 RL回报函数设计
本文设计的RL回报函数如式(1)所示。
(1)
式中:Reward初始化为0,回合结束时Reward最大取值为100;Δmalscore表示上一次混淆后样本的恶意评分与现在混淆后样本的恶意评分的差值(若恶意评分在混淆后反而上升,则Δmalscore为负值);TURN表示目前的混淆次数;MAXTURN表示设置的最大混淆次数;这样设置回报函数有两个目的:
(1) 利用RL对恶意样本进行混淆使其逃逸检测,这原本是一个奖励值稀疏的环境,因为大部分情况下RL采取混淆操作并不能使样本逃逸成功,有时超过了最大阈值仍以失败告终。如果仅在回合结束且逃逸成功时才给予智能体正向奖励,则对RL的学习过程造成很大的挑战。因此在回报函数中加入了Δmalscore作为中间奖励,当一次混淆使样本的恶意评分稍有降低时智能体就能得到一个小小的正向奖励,从而引导它更有效地学习混淆策略,尽量以更高的置信度逃逸检测。
(2) 本文实现模型时将MAXTURN设置为80,如式(1)所示,当混淆后样本逃逸成功时,回报值的增量为70×15-(TURN-1)/MAXTURN,曲线如图5所示。其取值范围为4.67到70.00区间内,随着混淆次数的增加,所得到的回报值呈指数下降趋势,这可以引导RL学习在尽量少的混淆次数内使样本达到逃逸检测的目的。
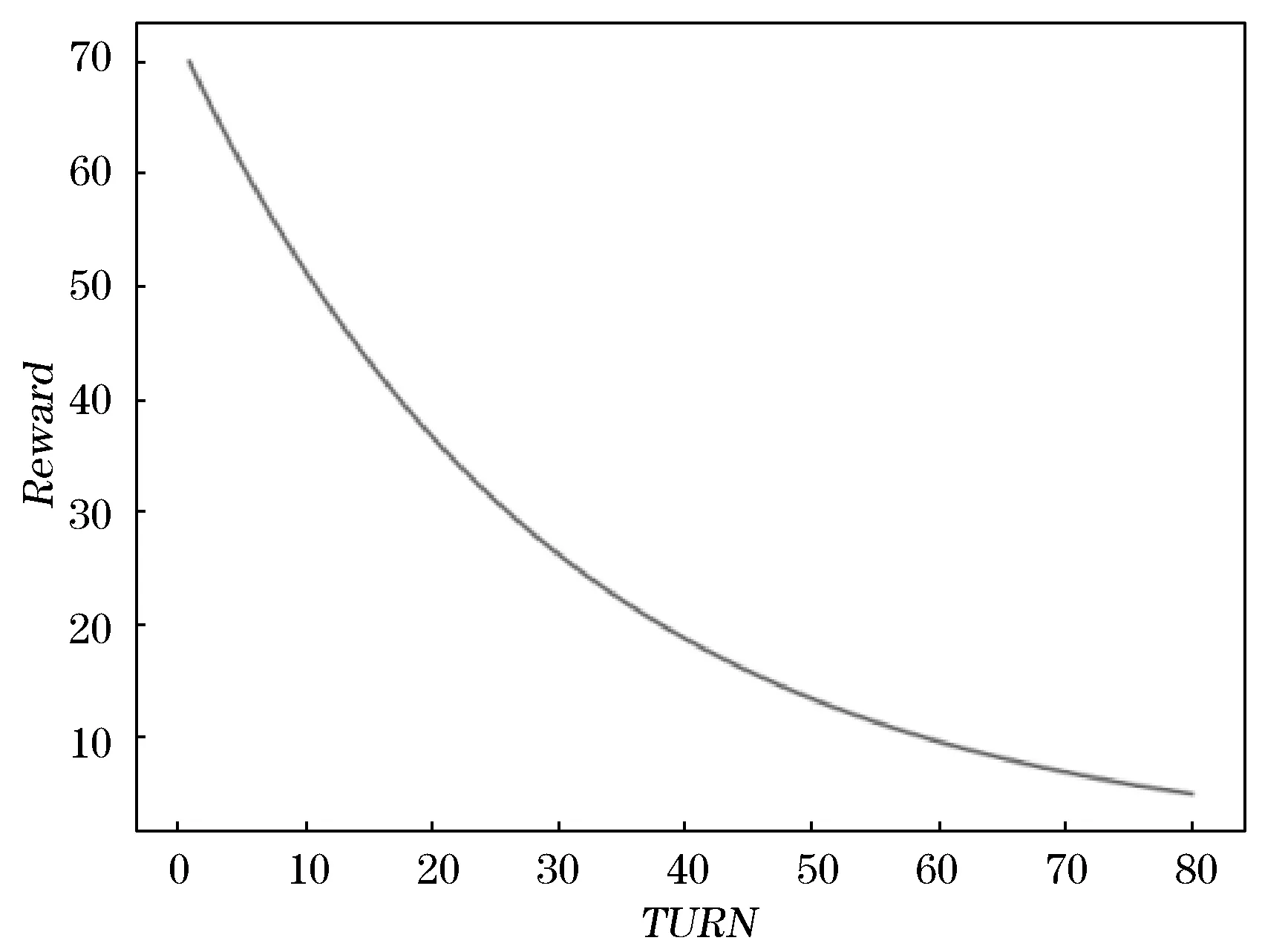
图5 回报函数曲线
3 实验与结果分析
3.1 数据集
实验所使用的恶意软件样本是来自于Virus Total[22]的PE二进制文件,采集自2017年网络上捕获的真实恶意软件样本,每个文件都可以直接运行。为了规范文件命名,本文将每个样本都统一命名为该样本的sha256值。为保证恶意样本标签的正确性,用开源病毒检测工具ClamAV[24]对样本进行扫描,删除标签不明确的样本后,最终数据集由2 918个样本组成,随机抽取其中918个样本作为测试集。RL模型每次从数据集中随机抽取一个PE二进制文件样本,开始一个新的回合(如图2所示)。
3.2 评估指标
本文设计的评估指标如表3所示。
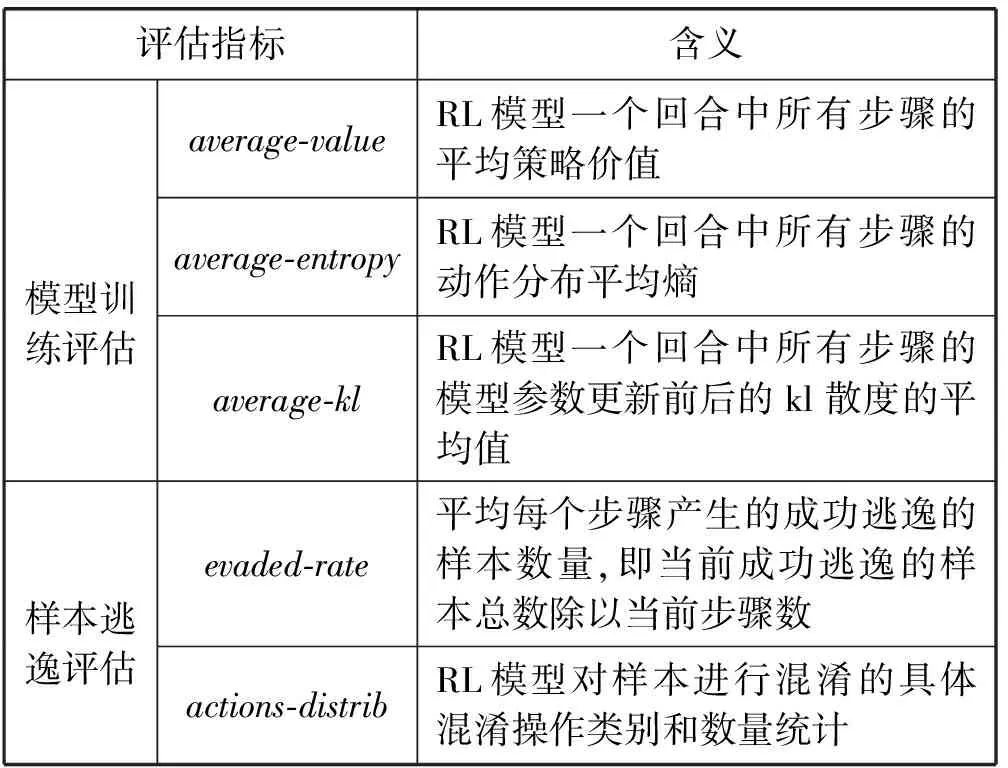
表3 评估指标
对于恶意软件混淆对抗样本生成模型而言,最直观且具有说服力的指标是成功逃逸模型检测的混淆对抗样本数量,因此evaded_rate为评估的主要指标,其余为辅助分析的次要指标。
3.3 性能评估
本文模型是基于Anserson等[17-18]在2017年首次提出的基于RL的恶意样本逃逸攻击方法进行改进的,文献中的模型分别使用了两个全连接网络分别作为ACER模型的价值函数和策略函数。由于文献未公布详细参数,因此本文以历史帧数量设置为1的HF模型(表2所示的HF_1)作为文献[17-18]模型的实现,并将其作为实验的baseline。
如表2所示,本文设计并实现了包含baseline模型在内的一共七种模型,其神经网络结构及超参数设置如表4、表5和表6所示。

表4 网络层级结构的参数说明

表5 网络层级结构的参数
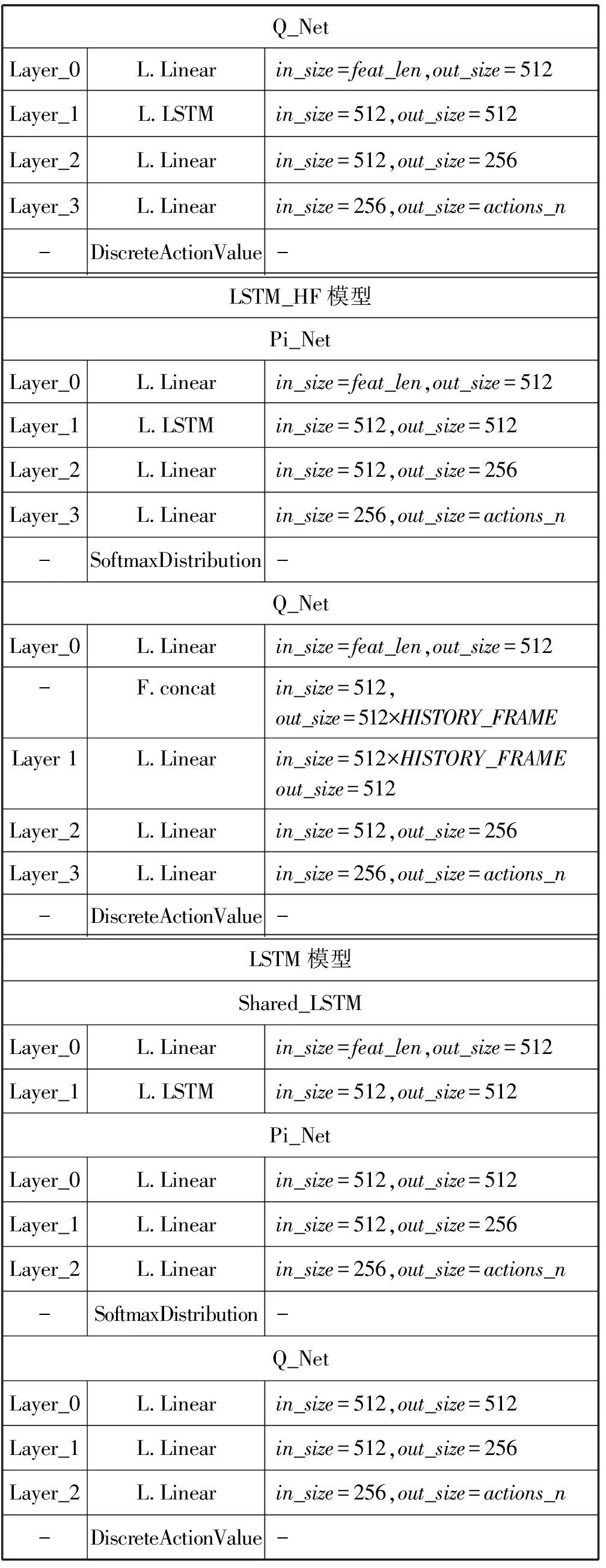
续表5
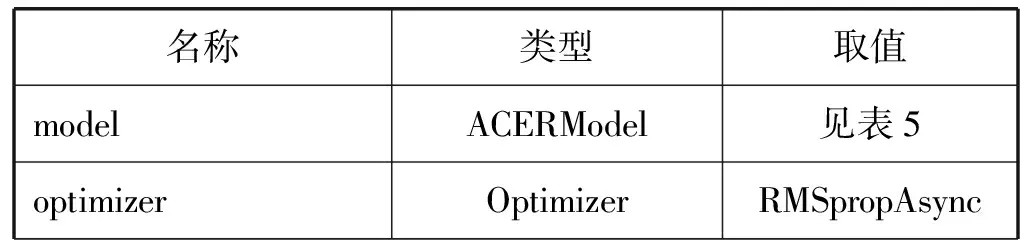
表6 RL模型的参数
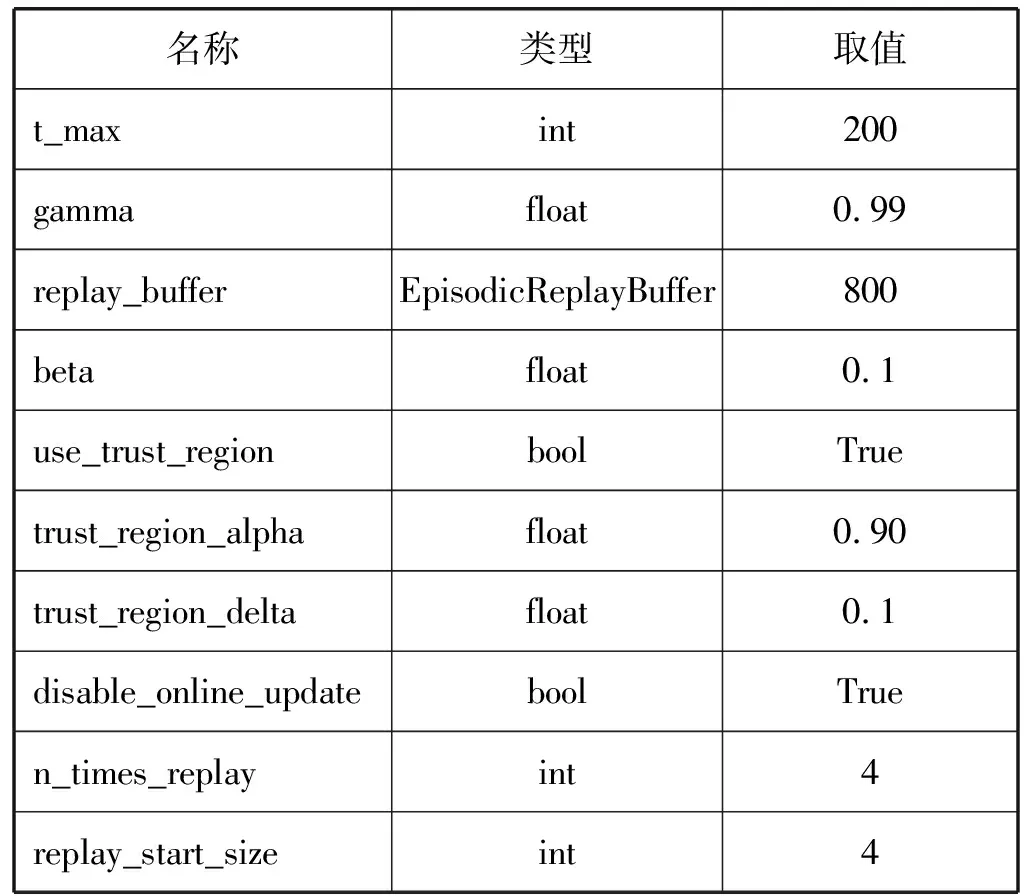
续表6
每个模型分别在训练集上进行50 000次迭代(一次迭代代表智能体对PE文件进行一次混淆)。在相同的50 000迭代次数内,不同模型进行的回合数量是不一样的,因为在一个回合中,如果智能体对PE文件进行混淆后使其成功逃逸检测,则该回合的迭代次数少于逃逸失败的回合迭代次数。为了方便评估样本逃逸量指标,本文以50 000次迭代内各模型中最少的回合数量为样本总数,总数为897个。也就是说,虽然训练集中一共2 000个样本,但在50 000迭代次数内模型只能进行897次样本随机抽取。
3.3.1模型训练评估
模型训练过程中大小为100个回合的滑动窗口内evaded_rate指标随模型迭代次数增加的变化情况如图6所示。
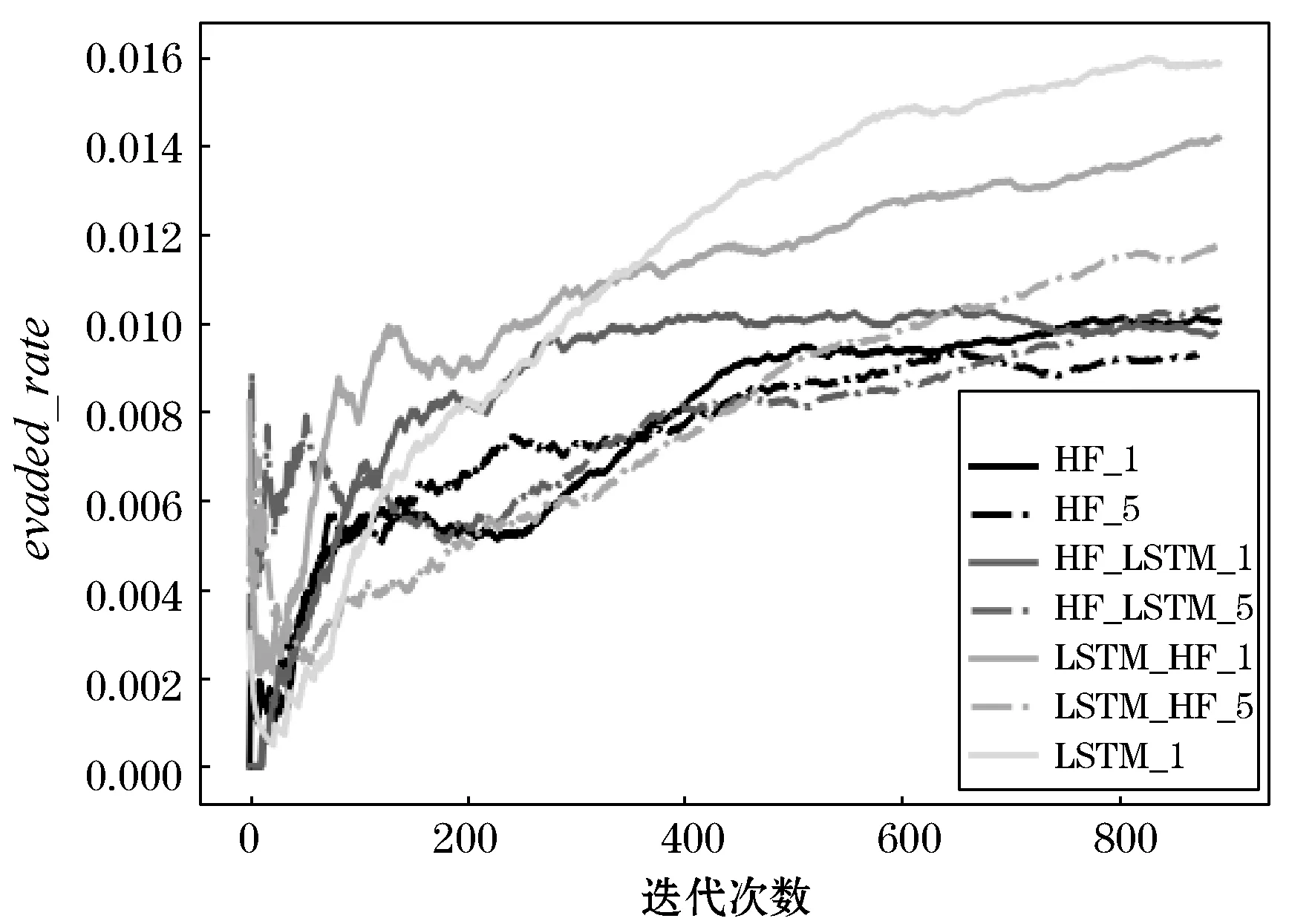
图6 七种模型的evaded_rate指标对比
从上述evaded_rate指标的结果来看,LSTM_1模型在训练集上的效果是最突出的。
模型训练过程中average_value、average_entropy和average_kl指标随模型迭代次数增加的变化情况如图7、图8和图9所示。
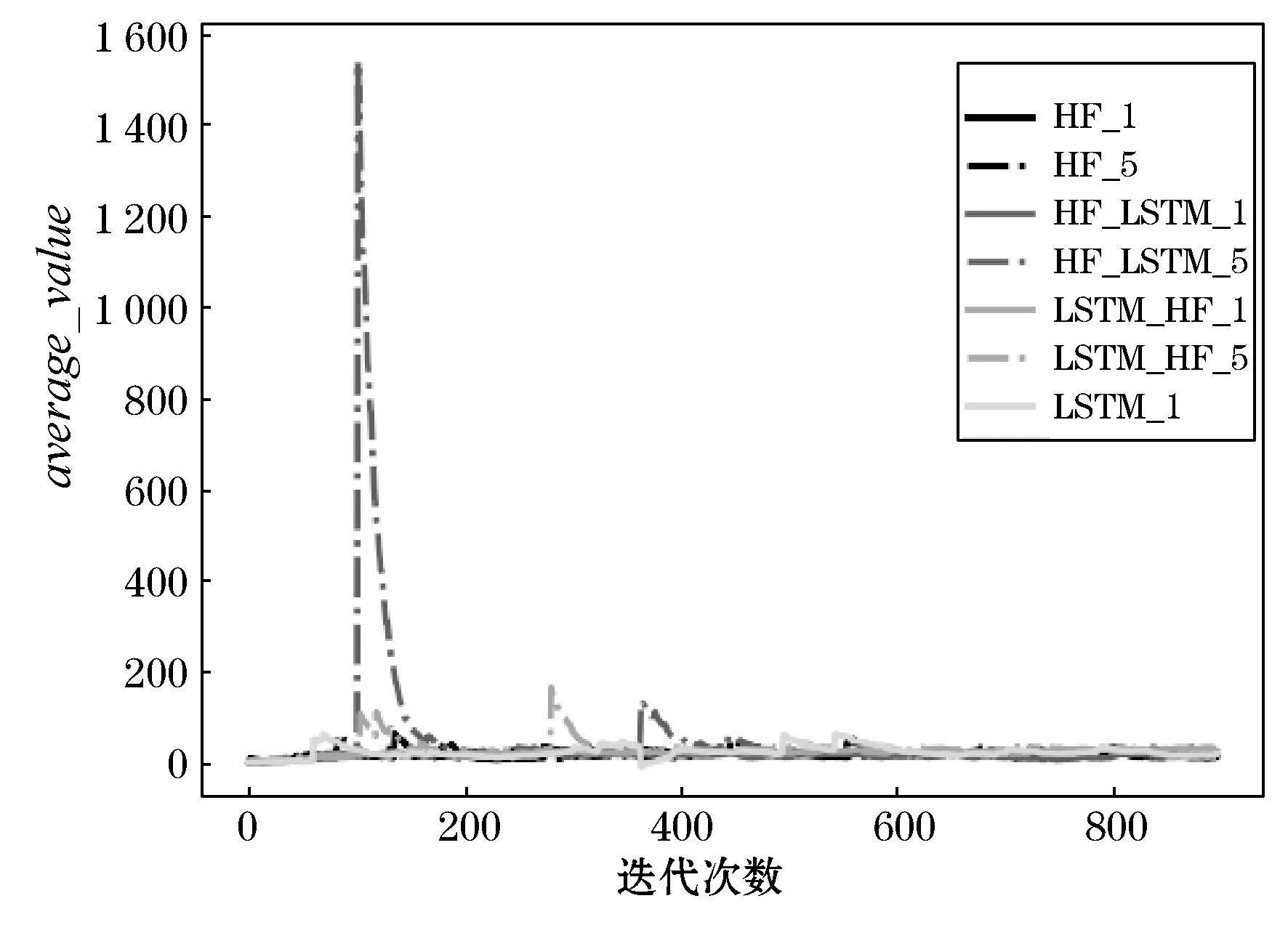
图7 七种模型的average_value指标对比
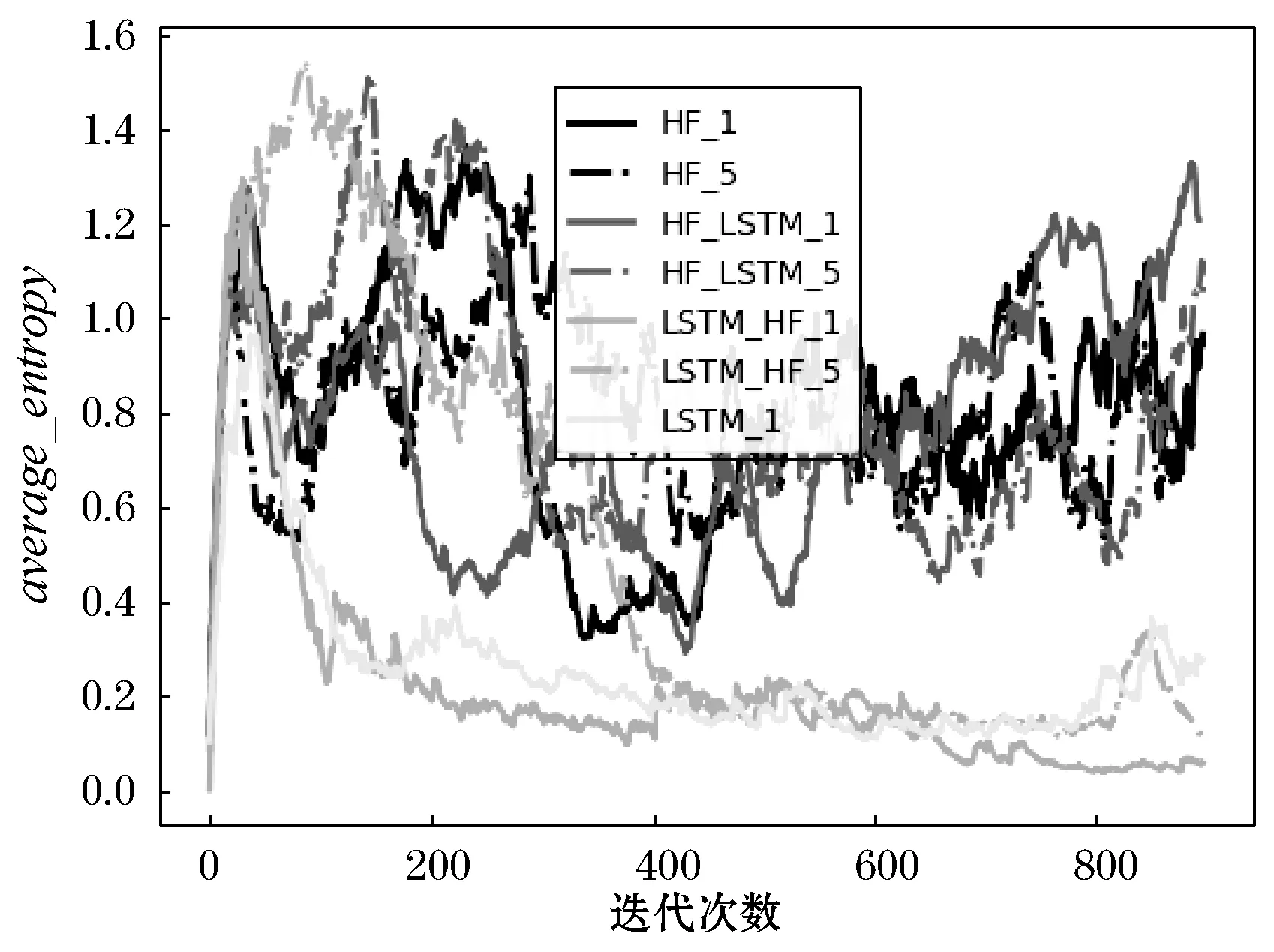
图8 七种模型的average_entropy指标对比
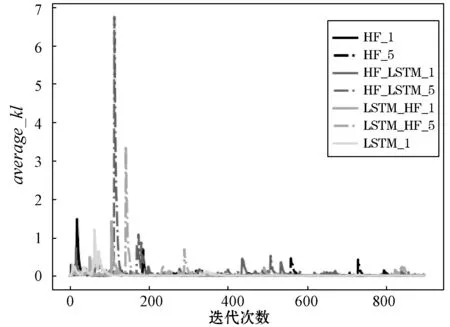
图9 七种模型的average_kl指标对比
从上述结果可以看出,average_value指标和ave-rage_kl指标往往出现同步的突然上升情况,据此推测原因可能是模型从训练集中抽取到了比较容易被混淆且成功逃逸的样本,模型从中得到了较大的正向反馈,因此有较大程度的模型参数更新。而average_entropy指标反映了混淆操作的多样性,LSTM_HF_ 1、LSTM_HF_5和LSTM_ 1模型随着迭代的进行,最终趋向较小的average_entropy值,这意味着这几个模型可能出现了过拟合情况。
3.3.2 模型测试评估
本文统计了在模型训练的897个回合(即897个样本)中成功逃逸的样本数量以及测试集上共918个样本中成功逃逸的样本数量,结果如表7所示,其中RANDOM模型表示采用随机策略,每次从动作空间中随机抽取混淆算法,统计样本在MAXTURN混淆次数内成功逃逸的数量,与其他模型进行对比。
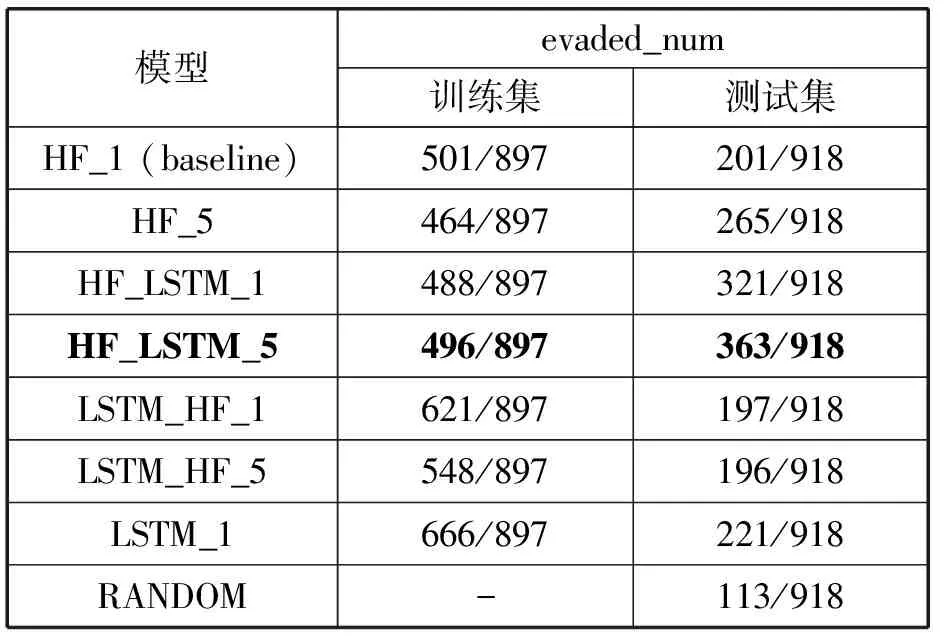
表7 不同模型在测试集上的样本逃逸数量
从表7所示的统计结果得知,在训练集上逃逸率最高的模型是LSTM _1和LSTM_HF _1,但它们在测试集上的逃逸率远比不上在训练集上的逃逸率,出现了较严重的过拟合情况。在测试集上逃逸率最高的是HF_LSTM _5模型,逃逸率为39.54%,比作为baseline的HF_1高出17.65百分点,比随机混淆算法RANDOM高出27.23百分点。因此得出结论:HF_LSTM_5是上述对照实验中效果最佳的模型。
3.3.3测试集逃逸样本分析
接下来对HF_LSTM_5模型在测试集上逃逸成功的363个样本进行混淆次数分布情况分析。
由于预混淆阶段的混淆次数为2,RL模型对样本进行混淆的最大次数设置为80,因此总混淆次数在 [2,82]区间内。在363个逃逸样本中,在预混淆阶段成功逃逸的样本共124个,在RL模型的混淆策略下逃逸的样本共239个。逃逸样本中各类别恶意软件的数量占测试集总样本的比例如表8所示,不同类别逃逸样本的混淆次数分布情况如图10所示。分析得知,在逃逸样本中占测试集对应类别样本数量比例最大的是dropper恶意软件,并且都是在预混淆阶段逃逸成功的。
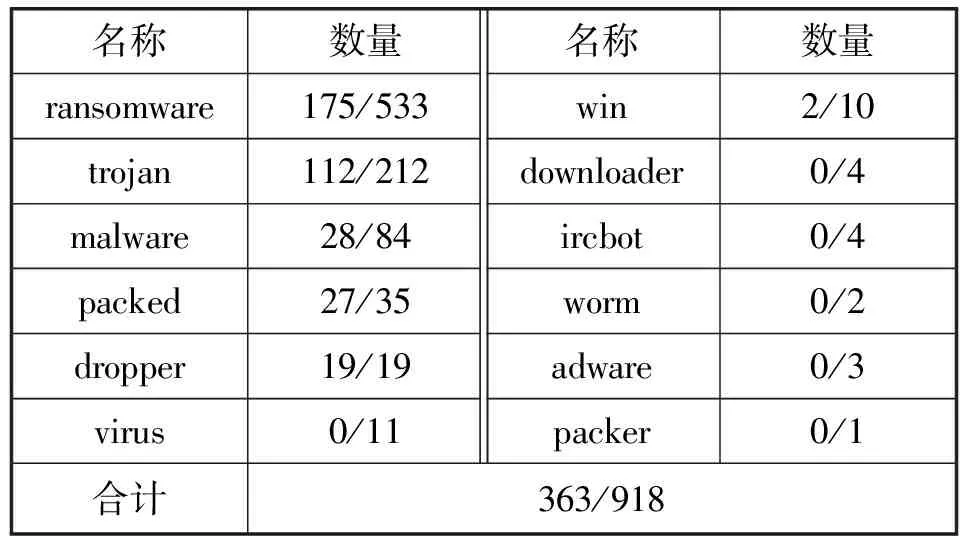
表8 测试集逃逸样本的恶意软件类别比例
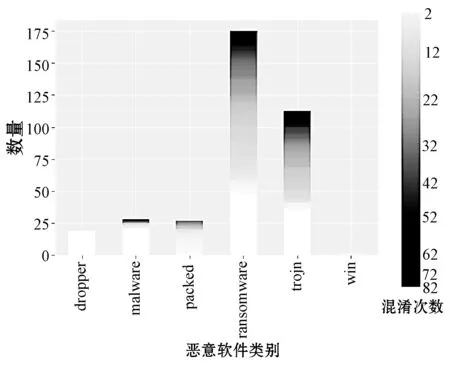
图10 测试集逃逸样本的恶意软件类别分布
4 结 语
在恶意软件检测领域,恶意软件制造者通常使用代码混淆技术来快速开发恶意软件变种以逃避检测。由于机器学习模型容易受到对抗样本的干扰,基于机器学习的恶意软件检测模型也容易受到代码混淆产生的对抗样本的逃逸攻击。虽然对抗样本给机器学习带来了挑战,但若能获取大量高质量的对抗样本,则能用这些对抗样本来修正模型,提高模型的抗干扰能力。为了有效生成恶意软件对抗样本,本文主要研究了基于RL的恶意软件混淆对抗样本生成方法,从PE文件中提取了2 349维特征,使用了RS和RD两种预混淆算法与OA、IA、SR、SA和SP五种混淆算法,结合FCN和LSTM神经网络设计了四种不同的ACER模型结构,通过设置历史帧参数和融合LSTM网络结构使RL智能体具有了“记忆性”。
为了验证本文方法的有效性,本文设计了七种ACER模型作为对照实验,将每个模型分别在大小为2 000的训练集上进行50 000次迭代,对比了在训练集和测试集上各模型的evaded_rate(逃逸率)、average_value(平均价值)、average_entropy(平均动作熵)和average_kl(平均kl散度值)指标。实验结果表明,本文设计的深度强化学习模型在混淆对抗样本生成上的效果优于现有研究。
猜你喜欢
中学生数理化·七年级数学人教版(2020年4期)2020-08-10
电脑报(2020年18期)2020-06-30
数学大王·低年级(2019年10期)2019-11-25
领导决策信息(2018年16期)2018-09-27
数学学习与研究(2017年3期)2017-03-09
文苑(2015年9期)2015-09-10
计算技术与自动化(2014年1期)2014-12-12
新课程学习·中(2013年3期)2013-06-14
西南学林(2011年0期)2011-11-12
中学数学研究(2008年3期)2008-12-09
