
基于旅客-航班异构网络的旅客同行子图抽取
2022-02-19 11:16:46王彦威
计算机应用与软件 2022年2期
卢 敏 王彦威
1(中国民航大学计算机科学与技术学院 天津 300300) 2(民航旅客服务智能化应用技术重点实验室 天津 300300) 3(中国民航大学信息技术科研基地 天津 300300)
0 引 言
民航旅客同行子图抽取旨在从旅客-航班异构网络中抽取具有潜在同行关系的旅客子图,其本质是根据部分旅客出行具有相似性的特点对旅客进行划分,使得子图内部连接紧凑,子图外部连接稀疏。旅客-航班异构网络是由描述旅客选择航班关系的旅客-航班二部图,以及描述航班相似性的航班同构网络构成。民航旅客同行子图具有广泛的应用,例如:发现潜在同行旅客,为具有潜在同行的旅客预留座位;发现旅客潜在出行意图,为具有相同出行意图的旅客进行航班推荐;通过对危险旅客及其同行旅客的监控,为民航业提供安全保障等。
民航旅客同行子图抽取目标是抽取关系最紧密的旅客节点。由于旅客出行的高代价和低频性,使得旅客出行记录稀疏,现有子图抽取[1-3]方法难以应用在稀疏图;并且仅从单一维度进行旅客同行子图抽取不能准确地发现旅客间的潜在同行可能。
针对上述问题,本文设计了基于“旅客-航班”异构网络的子图抽取算法,旨在通过旅客乘坐的历史航班记录和航班与航班的相似关系找到潜在的旅客同行信息。在此基础之上,对生成的旅客同行信息进行分析,发现旅客可能存在多个潜在同行信息。因此,在进行子图抽取过程中,应保证旅客可以属于多个子图。因此,本文提出标签传播的方法进行子图抽取并使用后处理阈值来记录每个旅客所在的子图。在旅客订票记录真实数据集上的实验表明:相比于基准算法,本文算法在子图模块度和精准度指标上具有良好效果。
本文主要贡献如下:(1) 针对旅客同行记录高度稀疏,提出了基于旅客-航班异构网络的旅客同行子图抽取方法,能够将稀疏的旅客出行记录转换成稠密的旅客潜在同行记录;(2) 提出了通过随机游走进行旅客间相似度计算方法;(3) 将本文算法应用在国内某旅客订票记录中,相比于LPA、COPRA、CPM等基准算法,本文在子图抽取模块度和准确率上具有更好效果。
1 相关工作
1.1 旅客同行研究现状
旅客同行研究旨在通过对旅客的出行记录发现具有潜在同行关系的旅客。叶绍贵等[4]通过对旅客同行网络进行层次划分,然后根据共同邻居的信息来构造出节点的一系列层次属性,使得网络的特征更加丰富,并使用分类算法发现潜在同行链接。张奥爽等[5]根据航空公司旅客信息系统中旅客历史出行记录提取旅客之间的社会关系并构建旅客同行网络,对潜在同行旅客进行分类。
上述方法研究在旅客同行同质网络上的旅客关系链接预测,但并未考虑旅客与航班以及航班与航班的关系。在现实生活中,这种关系表现为乘坐相似航班的旅客有可能同行。
1.2 子图抽取研究现状
子图抽取算法[6]最早在2004年被提出,旨在发现关系紧密的节点。近年来,为了发现子图中的内部规律,例如万维网中的子图是讨论相关主题的若干网站;电子电路网络中的子图可能是具有某一类特定功能的单元等,一些学者展开了深入研究,形成了大量的研究成果,其中代表性的方法可以分为基于模块性优化的子图抽取方法[7];基于标签传播的子图抽取方法[8-9];基于划分的子图抽取方法[10]等。例如Clauset等[11]提出局部模块度的概念,并使用边界节点和子图内节点连接的边数与该节点的度的比值来进行子图抽取,其提出从起始节点出发,通过广度优先遍历节点,找到使得模块度增大的节点并放入子图中,直到遍历完所有节点。LPA算法[12]是一种基于标签传播的算法,该方法将每个节点标签化,节点选择邻居节点中出现次数最多的标签作为自己的标签。
上述方法仅考虑节点属于唯一子图,而在现实生活中,一个节点可能隶属于多个子图,例如在旅客同行网络中,处于子图边缘的乘客有可能与多个乘客存在同行关系;在学术合作网络中,一个学者可能同时参与多个学术团体;在蛋白质互相作用网络中,根据蛋白质功能的不同,应划分为多个子图。针对上述问题,子图抽取引入隶属度的概念,用来发现可能重叠的子图。例如BMLPA算法[13]在初始化阶段设置平衡归属因子用来约束节点标签的更新,以便形成不重叠的子图。陈杰等[14]提出一种从图中抽取有意义的密集子图方法,该方法利用矩阵分块的思想,抽取节点度大于阈值的节点。上述子图抽取算法需要保证图中节点类型一致,由于其抽取不同类型的子图并无实际意义,因此不适用于旅客-航班异构网络子图抽取中。
2 算法设计
本文首先对旅客-航班异构网络进行随机游走以便发现旅客潜在同行信息。旅客-航班异构网络是由描述旅客选择航班关系的旅客-航班二部图,以及描述航班相似性的航班同构网络构成。在此基础之上,使用标签传播的方法根据旅客潜在同行信息进行旅客同行子图抽取,首先得到图中较大度的完全子图,并为每个节点打上一个唯一的标签,然后根据标签传播规则对节点标签进行更新,最后处理可能具有多个标签的节点。
2.1 基于“旅客-航班”异构网络的旅客同行网络构建
“旅客-航班”异构网络是指在旅客订票记录(PNR)中构建旅客-航班矩阵,此矩阵分为4个模块,如式(1)所示:
(1)
式中:Wxx表示“旅客-旅客”模块;Wxy表示“旅客-航班”模块;Wyx表示“航班-旅客”模块;Wyy表示“航班-航班”模块。“旅客-航班”模块定义将旅客乘坐过相同的航班号填入到“旅客-航班”矩阵的对应位置,“旅客-航班”模块与“航班-旅客”模块一致。与此同时,本文构建“航班-航班”矩阵,该矩阵描述航班与航班间的相似性。航班的相似度根据航班起始地和目的地的经纬度,使用余弦相似度计算。其计算方法如下:
(2)
式中:F1以向量的形式表示航班1的经纬度;F2以向量的形式表示航班2的经纬度;构建旅客同行网络的目的是为了得到旅客潜在同行关系。
2.2 随机游走重构网络
对“旅客-航班”模块,“航班-旅客”模块和“旅客-航班”模块初始化后,通过随机游走的方式对上述模块进行更新。在本节中,根据上节构建的“航班-旅客”和“旅客-航班”关系网络,进行旅客和旅客的相似度计算。
旅客间的相似度物理含义是有可能同行的旅客,本文对“旅客-旅客”矩阵进行处理,将其初始化为对角矩阵。“旅客-旅客”矩阵的相似度通过“旅客-航班”矩阵,“航班-旅客”矩阵和“航班-航班”矩阵来表示,其计算方法如下:
(3)
式中:Wij表示旅客i和旅客j之间的相似度;aik表示“旅客-航班”矩阵中旅客i与航班k归一化后的权值;bkl表示“航班-航班”矩阵中航班k与航班l归一化后的权值;clj表示“航班-旅客”中航班l与旅客j归一化后的权值。“旅客-旅客”矩阵中的值表示的含义是旅客间潜在的同行概率,本文通过随机游走来更新旅客间的潜在同行概率。
随机游走可以理解为节点通过对邻居节点的访问,以达到对网络进行随机遍历的行为。节点访问其邻居节点的概率被称作转移概率,节点转移概率pij计算方法如下:
(4)
式中:Z表示节点归一化因子;Wij表示旅客节点i选择旅客节点j的概率。得到节点转移概率后,“旅客-旅客”模块更新方式如下:
(5)
式中:θ为随机游走次数。
2.3 标签传播算法
标签传播算法首先为图中任意旅客节点初始化标签;然后在标签传播的过程中,每个节点在接收其邻居节点标签的同时,也向邻居节点发出标签;在每个节点的存储空间中,可以保存之前迭代所接到的标签,为避免出现每个节点所对应子图标签过多的情况,标签传播算法使用相同标签所占比例大于给定参数的方式来确定哪些标签将保存下来,最终完成子图抽取。
2.3.1标签传播算法初始化
由上述“旅客-航班”“航班-旅客”和“航班-航班”矩阵得到“旅客-旅客”矩阵后,本节对“旅客-旅客”矩阵进行子图抽取。由于在初始阶段,每个节点随机接收邻居节点的标签,造成节点标签收敛慢。因此,在初始化阶段,本文首先发现图中完全子图,然后使得完全子图持有相同的标签,提高算法收敛速度的同时减少算法的随机性。
定义1完全子图。若图G1是图G的子图且G1中每个节点对之间都有一条边相连,则G1是G的完全子图。
以完全子图进行标签传播,往往能取得较好的效果[15]。其原因是完全子图内部连接紧密,因此其标签一致,在标签传播过程中可以看作一个节点,进而加快标签传播过程。其算法描述如算法1所示。
算法1以较高节点度为中心的完全子图
输入:“旅客-旅客”矩阵N。
输出:完全子图集合G。
BEGIN
(1) 初始化节点标签:为“旅客-旅客”矩阵N中的每个节点按照从1到n的顺序编号;
(2) 从编号1的节点开始搜索;
(3) If节点i未被搜索;
(4)i标记为已被搜索;
(5) 搜索节点i的邻居节点中度大于等于i的节点集合,从中选择度最大的节点p,若度最大节点不唯一时,则随机选取一个节点,并将其标记为已被搜索;
(6)Gp=Gp∪p;
//Gp是以p为中心的完全子图集合;
(7) 搜索节点p的邻居节点,从中选择度最大的节点,若度最大节点不唯一,则随机选择一个节点q;
(8) 如果q的邻居节点k与Gp中的节点均有边时,将其加入到Gp,并将节点标记为已被搜索;
(9) 更新Gp节点中的标签为相同标签。
算法首先为每个节点进行标签化,接着在未搜索的区域找到节点度较大的节点,并将其作为完全子图的中心节点。完全子图的搜索过程是指选择与中心节点相连的度最大的节点,将其加入完全子图集合;接着选择与完全子图集合中所有元素都相连的最大度的节点将其加入完全子图集合,并将同一个完全子图集合中的元素统一贴上相同标签。反复执行以上操作,图中会得到多个完全子图。完全子图的元素作为标签传播的初始点。
2.3.2标签传播过程
初始化阶段,每个节点的标签已被标记,首先对完全子图中的元素进行传播,然后对完全子图外的节点按照节点编号更新。该传播策略减轻网络中较重要节点在更新标签的过程中受到图中边缘节点标签的影响。
在选定当前需要更新标签的节点后,与其直接相连的节点标签作为当前节点更改标签的因素。其更改标签需要遵循如下原则:节点按邻居节点出现频次最高的标签进行修改,若存在多个相同频次的标签,则根据“旅客-旅客”矩阵中旅客的相似度,选择相似度高的节点的标签,将其修改为自身标签。节点标签传播规则使用同步更新方法,其表示如下:
Ci(m)=f(Ci1(m-1),Ci2(m-1),…,Cit(m-1))
(6)
式中:Ci(m)表示节点i的第m次的标签;Ci1(m-1)和Cit(m-1)表示节点i第1个至t个邻居节点在m-1次出现的标签。相比于异步更新,同步更新在更新节点标签时,仅依赖前一次更新的标签集,减少了因为节点更新顺序不同而产生的随机性。因此本文使用同步更新策略来更新节点的标签传播。
2.3.3重叠子图发现
标签传播算法记录了每个节点的每个标签,在迭代结束后,计算每个节点互异标签出现的概率,以便发现可能属于多个子图的节点。每个不同标签的概率表示如下:
(7)
式中:T为迭代的次数;count(labeli)表示在迭代过程中;labeli出现的次数。若节点中出现两个最高的相同概率的标签,则保留这两个标签,节点拥有多个标签表明节点可能属于多个子图。在节点标签达到迭代次数或趋于稳定后,对每个节点的标签矩阵进行分析,其目的是保留大于阈值的标签,并将其作为节点的最终标签,删除剩余标签。标签传播算法如算法2所示。
算法2以标签传播方法进行子图抽取
输入:初始化后的旅客同行网络M,迭代次数T,后处理阈值r。
输出:节点标签列表listi。
BEGIN
(1) 采用同步更新方式,根据邻居节点标签信息对目标节点进行更新;
(2) 如果目标节点的邻居节点出现最多的标签唯一,修改目标节点的标签;否则根据旅客同行网络中旅客-旅客的权值,选择权值最高的旅客节点的标签作为目标节点的标签;
(3) 重复上述步骤(1)-步骤(2),直到达到迭代次数T或标签趋于稳定;
(4) 记录每次目标节点的标签,在迭代结束后,计算互异标签出现的概率;
(5) 根据节点互异标签的概率和后处理阈值r,选择最终作为目标节点的标签,并删除其余标签。
3 算法复杂性分析
假设旅客节点数为m,航班节点数为n,随机游走的迭代次数为l,旅客节点的平均度为k,完全子图的数量为f,标签传播过程迭代次数为t,在迭代完成后具有多个标签的节点数量为n。本节主要从时间复杂度方面对子图抽取方法进行分析。
随机游走阶段,计算航班相似度的时间复杂度为O(n2),计算“旅客-航班”转移概率矩阵的时间复杂度为O(ml),生成“旅客-旅客”矩阵的时间复杂度为O(m2·n)。因此,随机游走阶段所需要的时间复杂度为O(n2+2ml+m2·n)。
标签传播方法分为初始化阶段和标签传播阶段。在初始化阶段中,需要给每个节点编码,其时间复杂度为O(m),在算法1中,搜索完全子图的时间复杂度不超过O(mkf)。在标签传播阶段,更新标签所需要的时间复杂度为O(mkt),发现重叠子图所需要的时间复杂度为O(tm),因此标签传播方法的时间复杂度为O(m+mkf+mkt+tm)。
4 实 验
将上述算法应用到国内某航空公司旅客订票记录(PNR)真实数据集中,并检验其准确度、模块度和算法收敛速度。
4.1 实验设置
实验数据集来自201X—201Y年国内某大型航空公司旅客订票记录。实验数据集是由中国民航信息网络股份有限公司订座系统提供,每一条记录为旅客真实订票记录,具体字段包括旅客身份证号、出生年月、旅客乘坐航班记录、旅客乘坐航班的起飞机场和降落机场(使用机场三字码表示)及旅客订单号等。机场的经纬度来源于谷歌地图上机场真实位置的经纬度。本文已对旅客信息进行加密处理。实验数据集反映了旅客真实订票习惯与旅客潜在同行关系,为此可开展旅客同行子图抽取的实验。旅客订票记录使用见表1,航班信息示例见表2。
表1 旅客订票记录示例
表2 航班信息示例
4.1.1数据预处理
本实验原始数据集为201X—201Y年旅客真实订票记录,大小为48.6 GB。对原始数据进行分析,发现其中部分旅客在201X年和201Y年中并无同行记录且出行次数较少,这类数据不在本文考虑范围内。因此本文首先对原始数据进行处理,抽取在201X—201Y年都活跃的旅客,即抽取两年内都有乘机记录,且乘机次数大于等于5次的旅客,旅客数据共有113 MB。旅客订票记录共有204 825条。本文根据201X年的旅客订票记录,生成旅客潜在同行网络。为了验证子图抽取的准确性,将由本文生成的旅客同行子图与测试集上的旅客同行子图进行对比。在对比之前,需额外增加一维标签信息。本文通过抽取201Y年相同的订单号的旅客,以及订单号不同但同时乘坐相同航班3次以上的旅客,将他们标注相同标签。标注后的旅客订票信息如表3所示。
表3 带标签的201Y年旅客订票记录
4.1.2基准算法
通过参考大量国内外文献,未曾有人在旅客订票记录数据集中进行子图抽取算法比较。因此,本文基准算法选取在公共数据集中表现较好的子图抽取算法,并将本文算法与之比较。
为了验证算法的有效性,将其与SLPA[16]算法、COPRA[17]算法及CPM[18]算法进行比较。
4.1.3评价指标
性能指标为用来衡量重叠子图质量的模块度及衡量子图抽取准确度的标准化互信息。模块度EQ计算公式如下:
(8)
式中:C表示子图;ni和nj表示节点i和节点j所属的子图数;Aij的取值为0或1,0表示节点i和节点j之间没有边相连,1表示节点i和节点j之间有边相连;di和dj表示节点i和节点j的度;σic和σjc取值为0或1,0表示节点i或节点j不属于子图c,1表示节点i或节点j属于子图。
标准化互信息NMI计算公式如下:
(9)
式中:CA表示真实的子图数目;CB表示本算法划分后的子图数目;N表示矩阵,矩阵的行表示矩阵所属的真实子图,矩阵的列表示该节点由本文算法得到的子图;nij表示真实子图i与本文得到子图j的重合节点个数;ni·表示第i行元素之和;n·j表示第j列元素之和。NMI的取值在0到1之间,其值越大,证明算法识别子图结构准确度越高。
4.1.4算法参数设置
算法中存在三个参数需要预先进行人工设置,分别为随机游走次数θ、迭代次数T和后处理阈值r。通过对旅客潜在同行关系进行分析,发现其中旅客节点数为460 998,在得到的连通子图中,旅客节点的平均路径长度为2.96,节点的平均聚集系数为0.679 6,因此,本文所提出的旅客潜在同行网络具有高聚集系数和低节点平均度的特性,该网络符合小世界网络的特征。根据小世界理论,将随机游走次数θ设置为1~6;迭代次数T设置为20;后处理阈值r设置为0.1~0.3。
4.2 实验结果
算法运行的硬件环境是Intel(R) Core(TM) i7-6800K,3.4 GHz主频,内存为64 GB的计算机。由于本文标签传播算法在标签传播过程具有一定的随机性,为此采用一次运行结果进行性能比较具有较强的不确定性。为了减少随机影响,算法在相同参数下运行多次,取多次性能的平均值。与基准算法对比的实验结果如表4所示。本文在模块度和标准化互信息方面均有提升。
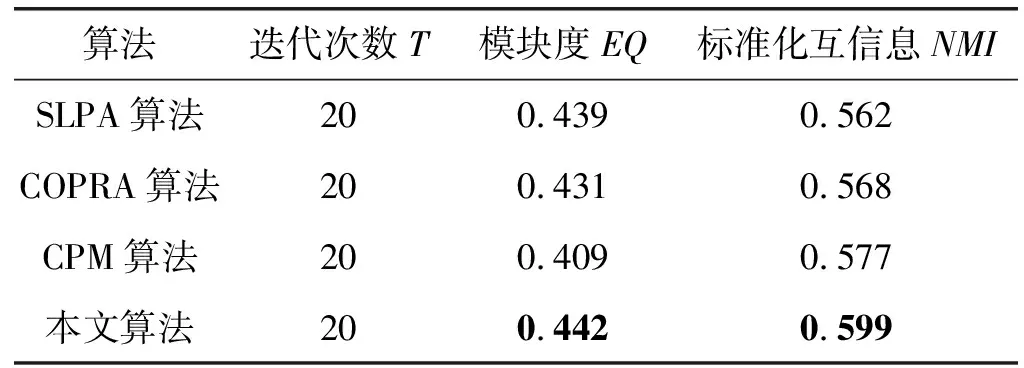
表4 子图抽取性能比较
4.3 实验分析
由表4可以看出,本文算法在模块度和标准化互信息两个指标上具有良好效果。随机游走次数θ控制旅客节点之间的相似度,在θ值增大的情况下,会导致节点间的相似度增大,旅客节点之间具有潜在关联的边也会增多,因此实验需要探究随机游走次数θ的值如何反应节点间的相似度。在随机游走次数θ=1时,由于旅客节点间的联系较为稀疏,因此NMI的值较低,随着随机游走次数的增多,旅客节点间潜在的关系也被挖掘出来,在θ增大时,子图抽取算法的NMI增加。而在θ≥4时,出现了过拟合现象,导致子图抽取算法准确度下降。如图1所示,其中横坐标为随机游走迭代次数,纵坐标为子图抽取的标准化互信息(NMI)。
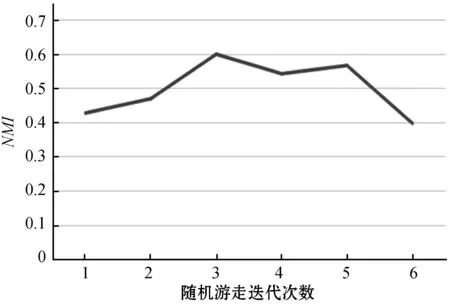
图1 不同θ下的NMI对比
相比于CPM算法,本文算法通过发现高节点度的完全子图进行传播,保障算法找到合适的起点,进而加快节点收敛速度。相比于SLPA和COPRA算法,本文在模块度和标准化互信息方面均有提高。SLPA和COPRA算法在识别子图过程中随机性较强,具有很强的振荡现象。而本文算法在标签传播过程中,考虑到节点的相似性,在选择标签的时候会优先选择相似度大的节点的标签,进而减少因随机选取而产生的不确定性,并且因为本文在标签传播初始化阶段通过完全子图进行传播,将具有紧密关系的节点在开始阶段标记相同标签,相比于SLPA和COPRA算法,减少因随机标注标签而导致的精确度下降问题。算法迭代过程如图2所示,可以看到,在刚开始迭代时随机性较大,随着迭代次数的增多,迭代到16次时算法收敛性趋于平稳。产生该现象的原因是在开始阶段节点选择标签随机性较大,导致在初始阶段节点被分为多个子图。在每次迭代过程中,节点的标签都会被储存下来。多次迭代后节点的标签也趋于固定。
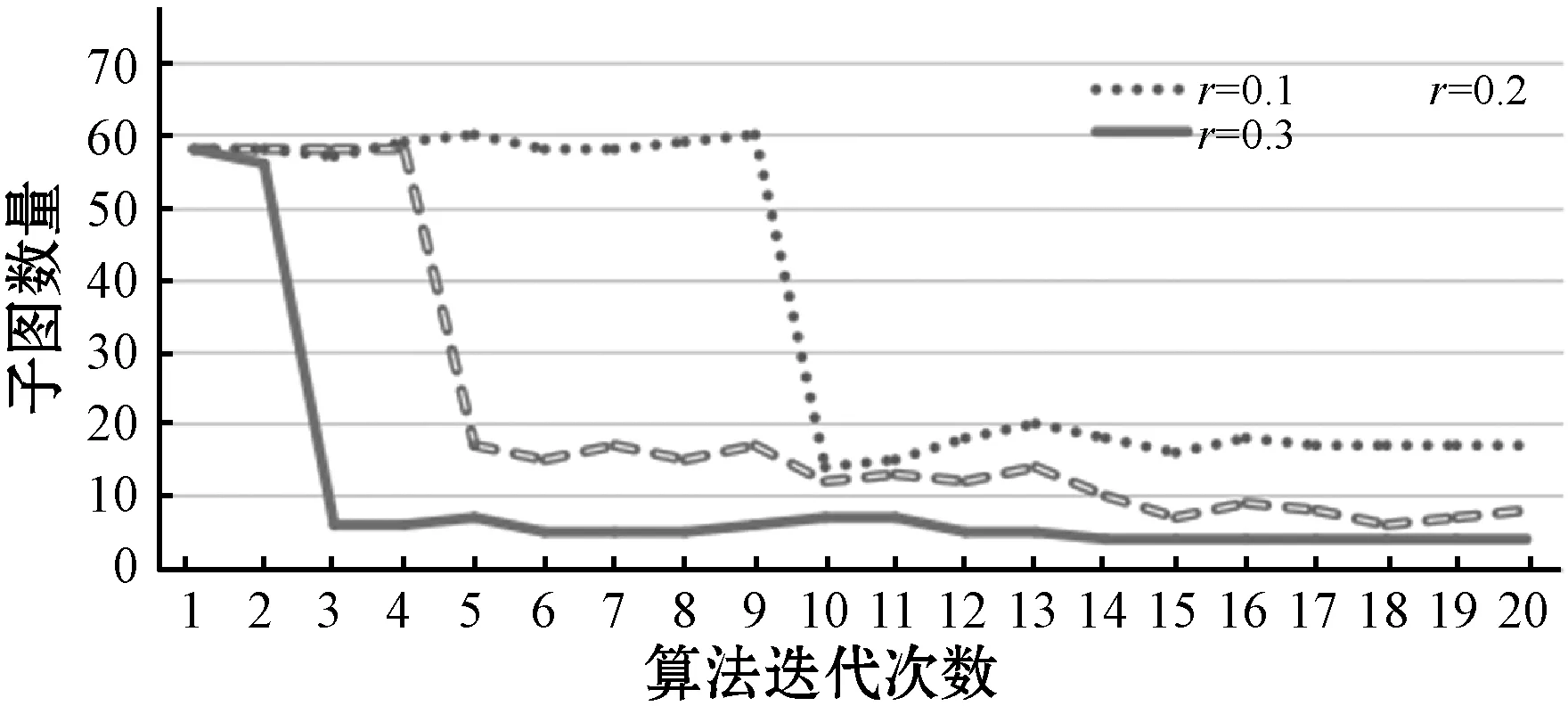
图2 子图抽取算法收敛性分析
5 结 语
针对旅客同行网络稀疏问题,本文提出了基于“旅客-航班”异构网络的旅客同行子图抽取算法。算法首先构建旅客-航班异构网络矩阵,其次对其进行随机游走以计算旅客潜在同行概率。在此基础之上,设计了一种基于标签传播的子图抽取算法,节点根据邻居节点标签以更改自身标签,并且可发现属于多个子图的节点。为了加快迭代速度,进一步设计了基于完全子图的节点标签初始化方法。算法理论分析进一步表明算法求解过程是线性的。并在国内某旅客订票数据集上验证了算法性能的优越性。后期可围绕异构网络和动态子图的抽取进行研究。
猜你喜欢
环球时报(2023-01-12)2023-01-12 15:13:44
金桥(2021年10期)2021-11-05 07:23:10
金桥(2021年8期)2021-08-23 01:06:24
金桥(2021年7期)2021-07-22 01:55:10
小哥白尼(趣味科学)(2021年3期)2021-07-16 07:47:32
同济大学学报(自然科学版)(2019年2期)2019-04-02 05:43:48
故事大王(2018年3期)2018-05-03 09:55:52
电子科技大学学报(2016年2期)2016-08-31 02:50:00
空中之家(2016年1期)2016-05-17 04:47:43
华东师范大学学报(自然科学版)(2014年1期)2014-04-16 02:54:50
