
基于机器学习的5G无线传播模型的构建
2022-02-19 11:16谭海军朱世宇单欲立陈善雄
计算机应用与软件 2022年2期
谭海军 朱世宇 单欲立 陈善雄
1(长江师范学院信息化办公室 重庆 408100) 2(重庆工程学院计算机与物联网学院 重庆 400056) 3(西南大学计算机与信息科学院 重庆 400715)
0 引 言
相比于传统4G网络,5G的显著特点是波长下降到了毫米波的区间,因此收发天线及设备尺寸大大减小。此外,毫米波的绕射和穿墙能力差,在传播中的衰减大,趋近于直线传播。基于以上两个原因,5G发射基站的体积和发射功率都有所下降,这就要求覆盖区域内的5G基站密度增加。因此,在5G网络基础设施建设的过程中,发射基站的设备成本占总成本的比例相比于4G网络大大提高[1]。合理地规划5G网络部署需要高效的网络估算模型,该模型可以去预测通信覆盖区域内的无线电传播特性,进而使得估算小区覆盖范围、小区间网络干扰以及通信速率等指标成为可能。对于5G网络目前学术界和工业界尚未有通用、成熟的部署算法。通常的思路是参考以往4G网络中的无线传播模型,并根据5G的新特点对原有模型进行修正和优化。然而,在4G及4G以前的无线网络的实际应用中,由于无线电波传播环境复杂,传播路径上会受到诸如平原、山体、建筑物、湖泊等各种因素的影响,使得电磁波的传播方式和路径不再单一,产生复杂的透射、绕射、散射、反射和折射等现象。而在5G网络中,毫米波作为信号的载波,基本是以直线传播,此外,链路衰减差异和Massive MIMO技术也使5G无线传播模型与4G及以前的模型有明显的差异[2]。因此,本文需要借鉴4G及以前无线通信环境建模的思想,并结合5G通信中的新特性,使之既具有传统经验模型或理论模型的可解释性,又能根据特定地理位置上实际部署的5G无线网络产生的数据进行网络模型修正,从而建立一个准确有效的模型。
传统通信模型通过参数的拟合来进行修正,但庞大的数据和实时更新的要求,让传统模型的预测能力捉襟见肘。因此需要建立合适的无线传播模型,对目标通信覆盖区域内的无线电波传播特性进行预测,使得对小区覆盖范围、小区间网络干扰以及通信速率等指标的估算更加准确。近年来,大数据驱动下的人工智能,机器学习技术获得了长足的进步,在无线通信、模型预测等领域取得了非常成功的运用。机器学习算法可以合理地规划特定地理位置的基站,使其对覆盖小区通信中产生的大量数据进行自动学习,建立该小区的无线传播模型,以预测该小区的通信指标,辅助该小区5G基站部署方案的设计。
本文采用机器学习的相关方法来构建5G无线智能传播模型。首先,参照模型Cost231-Hata[3],从已知的参数中选取出传播路径损耗最小的特征;接着通过Pearson系数来分析这些特征与参考信号接收功率RSRP(Reference Signal Receiving Power)的相关性,从中选取出相关性最高的前十个特征;最终将这些特征分别送入到决策树、随机森林、BP神经网络,这三个模型中进行训练。实验中,本文以4 000个小区的5G网络传播参数作为样本,对三种模型进行参数上和结构上的微调来提高模型的预测性能,结合Root mean squared error(RMSE)对预测结果进行评估,最终在RMSE的结果中选取出了最佳的训练参数和结构。实验结果表明,采用随机森林模型的预测结果的准确率高于其他模型,有利于减少网络的建设成本,提高了基站的建设效率。
1 研究现状
一个优秀的无线传播模型要能够适应不同的特征地貌轮廓,如平原、丘陵、山谷等,或者是不同的人造环境,例如开阔地、郊区、市区等。这些环境因素涉及了传播模型中的很多变量,它们对无线信号的传播有着重要影响。因此,一个性能良好的移动无线传播模型需要不断修正和改进才能形成。为了完善模型,需要利用统计方法,在测量出大量的数据基础上,对模型进行校正。一个好的模型应该简单易用、结构清晰,不应该让用户进行主观判断和解释,因为主观判断和解释往往在同一区域会得出不同的预期值。同时,模型应具有好的公认度和可接受性。目前主要的无线传播模型分为经验模型、物理理论模型、改进模型,当然,这种通用传播模型的分类思想也适用于当前5G传播模型。
就经验模型而言,Okumura-Hata和Cost-23-Hata是两个比较典型的模型,文献[4]对比了Okumura-Hata与Cost-231-Hata之间的差异。Cost231-Hata适用于1.5 G到2 G的信号,小区半径大于1 km的蜂窝系统,有效天线高度在30到200 m之间,接收天线在1到10 m之间,它可以作为5G通信模型的参考,但是因为传输波段远低于5G模型,所需模型中的经验参数不适用于新的5G网络群。Okumura-Hata[5]模型适用频率范围150~1 920 MHz,距离1到100 km,天线高度30到1 000 m。此模型信号频率的更低,但是模型构建思想值得借鉴。
物理理论模型根据电磁波传播理论,考虑了电磁波在空间中的反射、折射等计算损耗,如Volcano模型[9]。但是这种物理模型只适用于干扰因素少、范围比较小的理想环境,不太适用于现实中复杂多变的无线通信环境。
针对改进模型,文献[6]提出了一种适用于28 GHz和38 GHz毫米波频段蜂窝规划的新的路径损耗模型,该模型来源于对无线覆盖商业规划工具中使用的现有路径损耗模型的修正。文献[7]提出了针对特定城市的5G移动通信的路径损耗模型,为其他地区模型及通用模型的建立提供了参考。另外Standard Propagation Model[8]也是一种应用广泛的模型,它从Hata公式演化而来的,适合频率在150~3 500 MHz,传输距离在1~20 km场景。同时,该模型在拟合公式中引入更多的参数,从而可以适应更细的分类场景。
2 特征设计
对于移动通信系统中的信号传输,很难建立一个完全与实际情况吻合的理论模型。由于环境的繁杂多样,导致信号传播呈现出多样化的形式。目前已知的电磁理论,很难直接应用于较大计算量的无线网络传播模型的体系之中,往往只能预测微蜂窝以及微微蜂窝模型。通常情况下需要专家结合各个地区的实测数据,通过分析和计算然后对传播模型的参数进行校正,进而提高预测模型的准确率。而由于传播模型的结构和参数的复杂性,使得直接进行优化变得比较困难,通常采用了提取传播模型特征的方式,利用机器学习算法实现最优设定。
数据及对应的特征表达是机器学习的目标,而模型和算法正是为了达到这一目标,所以特征选择是首要步骤。在移动通信系统的传播模型中,原始数据集特征包括小区发射机相对地面的高度、小区发射机水平方向角、小区发射机中心频率、栅格点位置到基站的水平距离等二十余项特征指标。本文需要从原始特征集合中抽取对预测结果最有效的特征集合,简化算法模型,加快计算的速度,实现网络优化和维护的灵活性。
2.1 数据编码
在移动通信系统的通信过程中会产生大量的传输数据,对海量数据的分析增加了计算和存储的复杂度,数据压缩是进行数据分析前的一个重要的预处理步骤,能有效去除特征变量集的信息冗余。通常特征包含连续型特征和离散特征。
(1) 连续型特征。对于连续型特征,用z-score标准化的方法,消除每个特征向量的均值冗余,使方差范围在[0,1],使得各个参数的取值在一个相对稳定的范围。通过标准化,可以在不损失该特征的波动特性的前提下消除冗余,减少算法学习过程中的计算量,同时提高收敛速度,从而增强机器学习模型训练的效率。
(2) 离散型特征。本文中的数据是无序的离散变量,将其直接送入到模型中是不可取的。而One-hot编码[9]可以将类别特征转化为二进制向量来表示,首先将类别映射到整数值,每个整数值被表示为二进制向量,除了整数索引被标记为1外,其他都为0。
2.2 特征冗余约减
特征约减是将特征参数集合中相互之间存在冗余的特征参数重新组合,构造新的特征参数。在特征设计之前,通常需要先理解所提供的数据变量,再对数据进行预处理和适当的变换,从中挖掘出所需要的信息。这里,Cost 231-Hata模型对变量的定义如下:
PL=46.3+33.9log10f-13.82log10hb-α+
(44.9-6.55log10hb)log10d+Cm
(1)
其中:
式中:PL定义为传播路径损耗(单位:dB);f为载波频率(单位:MHz);hb为基站天线有效高度(单位:m);hue为用户天线有效高度(单位:m)、α为用户天线高度纠正项(单位:dB);d为链路距离(单位:km);Cm为场景纠正常数(单位:dB)。
以Cost 231-Hata模型为例,从特征工程的角度分析,数据集的特征参数包括三种类型:
(1) 与Cost 231-Hata传播模型参数定义一致的,如f、hb。
(2) Cost 231-Hata传播模型中含有的特征参数,但是,不是直接在数据集中定义的特征参数,而是需要通过对多个数据集中原始的特征参数进行计算而得。比如:
(2)
式中:d在Cost 231-Hata是指链路距离,理论上是一个三维空间直线距离。但是因为实际工程应用中,数据集是5G基站在开阔的室外无穿墙的情况下采集的,所以小区覆盖半径在1.5 km左右,而发射点和接收点的高度差基本不会影响最终的链路距离,所以直接用二维距离代替三维距离。把垂直特征作为一个单独的特征,并在下面的相关性分析中发现它与预测结果RSRP相关性较大。
(3) Cost 231-Hata模型中没有,但是数据集中含有的类型信息,如地形类型信息。
第一类特征参数可以直接利用;第二类特征参数可数据预处理提取出有效参数;第三类特征参数需根据这些特征是否发散以及特征与目标的相关性进行合理筛选。
2.3 特征参数选择
完成降维之后,我们需要从特征参数中筛选出对预测结果影响大的特征参数,作为下一步训练机器学习模型的精简有效的输入参数。通常来说,可以从以下两个筛选指标来判断这个特征参数是否合适。
(1) 特征参数自身发散性。如果一个特征参数不发散,例如方差接近于0,也就是说样本在这个特征参数上基本上没有差异,这个特征参数对于样本的区分作用较小。特征参数自身的微小波动是具有正态分布特征的随机性引起的,因此对于预测目标而言是一种噪声,与预测目标无关。由于各个小区是分散地分布在实际地理环境中的,因此接收点的位置具有发散性。表1展示了单个基站覆盖区域中,接收站点位置特征。可以看出接收点的水平坐标(X,Y)具有发散性,而海拔和接收物高度的发散性则明显低于水平坐标的发散性。
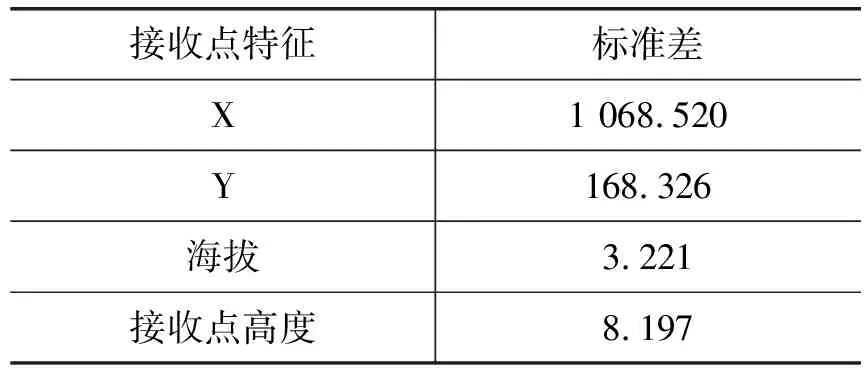
表1 接收站点特征的发散性分析
(2) 特征与目标的相关性。通常,与目标相关性高的特征,应当优先选择。本文通过评估单个特征与预测结果之间的相关程度,排序后留下排在前10位的特征子集作为优选特征。虽然这个方法只评估了单个特征对结果的影响,没有考虑特征之间的相互关联,但由于预处理阶段已经消除特征集合之间的相关性,所以可以完全规避单一特征相关系数筛选方法的弊端。采用这种方式的原因在于,数据的特征本身已经相互独立,而且没有时间上的因果关联,具备良好的独立条件。
3 传播模型的构建
本文针对5G无线网络传播模型的构建,通过特征参数分析和选择,构造出新的特征参数,再将这些特征参数送入到基于决策树、随机森林以及BP神经网络交替优化模型中来建立无线传播模型,并且能够预测出新环境下无线信号覆盖的强度。
3.1 决策树
解决分类与回归问题经典的模型便是决策树模型,此模型有很多经典的算法,例如ID3算法、C4.5算法、CART算法和CART剪枝算法[10-11],本实验中采用的是CART算法,此算法既可以用于分类,也可以用于回归。CART算法由决策树生成和决策树剪枝两个步骤组成。在决策树生成步骤中,使用训练数据生成尽可能大的决策树;在决策树剪枝步骤中,使用验证数据对已生成的决策树剪枝并选择最优的子树。具体的决策树生成算法如下:
输入:训练数据集D,特征集合A,模型停止条件E;
输出:决策树T。
使用训练数据集,从根节点开始,递归地对每个节点进行如下操作,构建二叉决策树:
(1) 使用训练数据集D,对每一个特征Ai和该特征的每一个取值aij,将训练数据集划分为D1和D2两部分,计算特征Ai在aij处的基尼指数。
(2) 针对所有可能的特征Ai和该特征所有可能的切分点aij,选择基尼指数最小的特征及其对应的切分点作为最优特征和最优切分点。从该最优切分点生成两个子节点,将划分数据集D1和D2分别分配到两个子节点。
(3) 对两个子节点递归地调用步骤(1)和(2),直到满足停止条件,停止条件是节点中样本个数小于预定阈值,或样本集基尼指数小于预定阈值,或者无可用特征。
(4) 生成CART决策树。
3.2 随机森林
在特征选择的过程中,随机森林是通过特征对模型的贡献率进行特征的重要性评分[12],对于评分高的特征,其贡献率就大,将这些因素纳入最后的机器学习模型中,进一步进行回归预测,其具体算法流程如下:
(1) 原始训练集为N,应用bootstrap方法,有放回地随机抽取k个新的样本集,并由此构建k棵分类树,每次未被抽到的样本组成了k个候选数据。
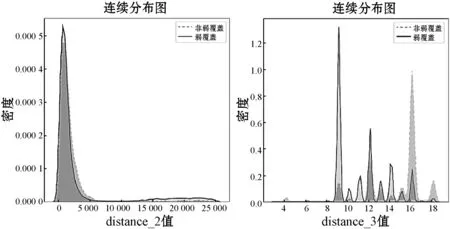
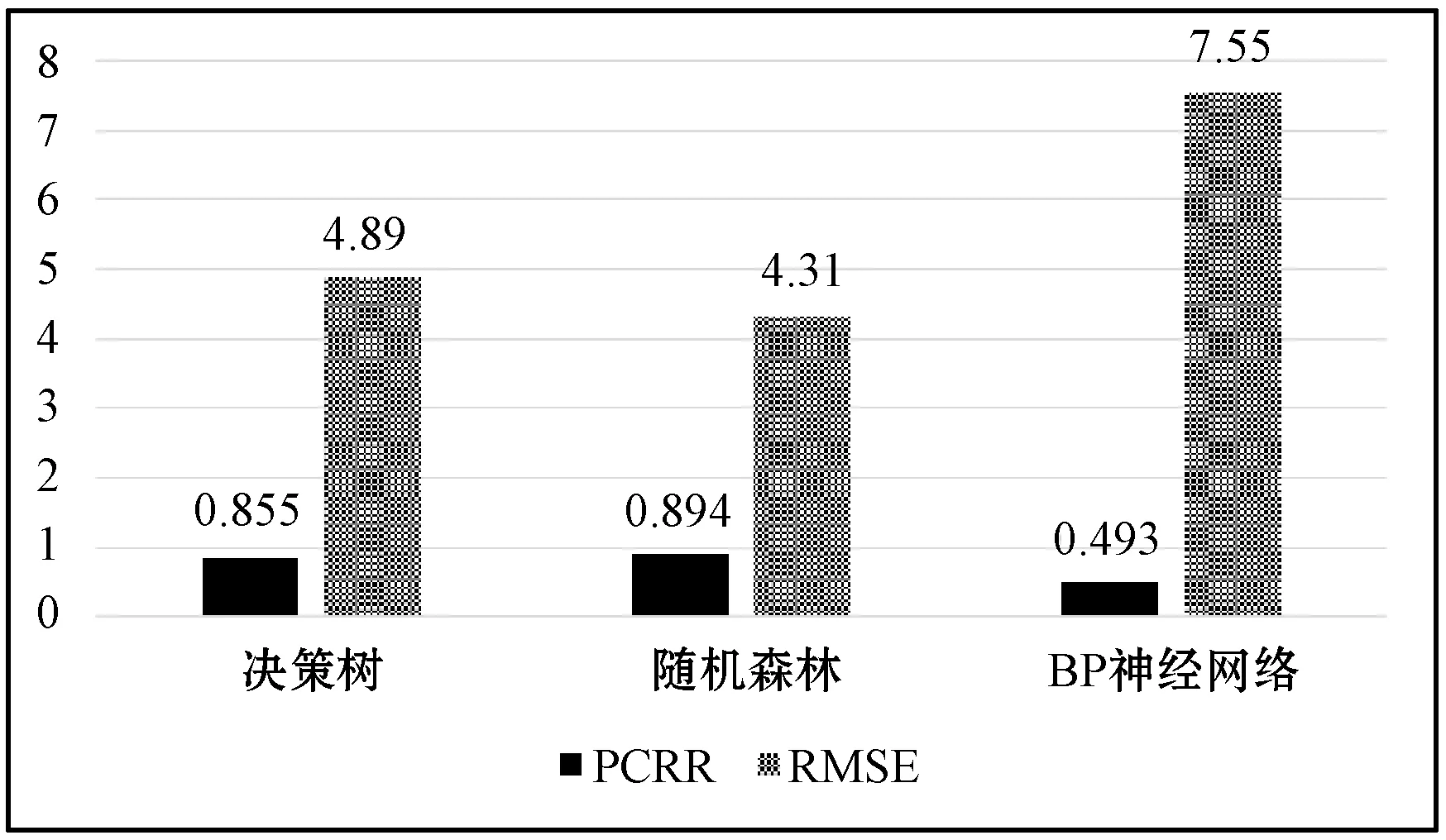
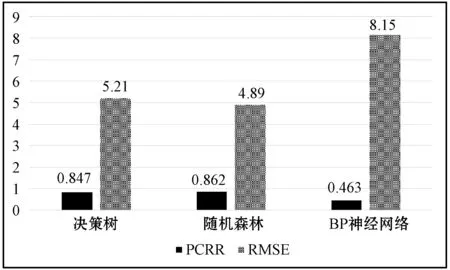
(2) 设有mall个变量,则在每一棵树的每个节点处随机抽取mtry个变量(mtry (3) 每棵树最大限度地生长,不做任何修剪。 (4) 将生成的多棵分类树组成随机森林,用随机森林分类器对新的数据进行判别与分类,分类结果按树分类器的投票多少而定。 BP神经网络学习算法[13]是目前为止最为成功的神经网络学习算法之一,其原理可以概括为“模型+误差修正函数”,每次只需要对训练得到的结果与实际值进行误差分析,进而修改权值和阈值,通过重复迭代来输出和预想结果一致的模型。在本文中将已有的RSRP值作为实际的标签值,并将已选取的特征送入模型中,使用均方根误差作为损失函数,并用Adam优化器来修正网络参数使其达到理想的效果。 实验在分析各区域的数据集选取特征时,将弱覆盖率的准确率也纳入其中,因为弱覆盖率可直接帮助运营商精准规划区域,还能提升用户的体验感。因此,将弱覆盖率、非弱覆盖率的均值以及标准差作为模型训练的评价指标。这里采用Pearson系数作为评价方法来计算各特征的相关系数,其计算公式如下: (3) 经过Pearson系数的检验后,得出的各特征与目标的相关性系数如表2所示。其中,发现栅格点位置到基站的水平距离和栅格点到基站的直线距离对RSRP的影响最大,表明高相关的特征对传播模型的构建起着较大作用。 表2 特征与目标的相关系数 为了研究特征对非弱覆盖和弱覆盖区域的影响,这里选取d(栅格点位置到基站的水平距离)、distance_2(栅格点位置到基站的直线距离)、Height(小区发射机相对地面的高度)、Azimutj(小区发射机水平方向角)、PL(传播路径损耗)五个特征,分析它们在非弱覆盖和弱覆盖区域的分布密度。 图1展示的是Azimutj特征的分布密度。可以看出,弱覆盖区主要集中在值150~350之间,并且分布的密度很大,与之相对应的是非弱覆盖区的分布密度较小,覆盖区间较大,横跨0~350之间。 结合信号发射机相对地面的高度hb、机械下倾角θMD、垂直电下倾角θED以及信号发射机自身所在的栅格位置和目标栅格位置所形成的三角形的斜边长度和发射机的高度,可以得到栅格与发射机的高度以及栅格与信号线的相对高度Δhv,由此可以得到特征distance在非弱覆盖和弱覆盖的分布密度。如图2所示,特征distance_2与distance_3的非弱覆盖和弱覆盖的差异,其中distance_3是在特征distance_2的基础上加入了机械下倾角θMD、垂直电下倾角θED的计算而得到。可以看出特征distance_2的非弱覆盖和弱覆盖的分布密度基本一致,说明该特征对区域模型影响较大,而distance_3的分布则不一致,因此影响较小。 (a) 特征distance_2 (b) 特征distance_3图2 distance特征对非弱覆盖和弱覆盖分布的影响 接着对发射机高度和栅格与发射机的距离在弱覆盖区和覆盖区两类情况下的分布进行分析,结果可如图3所示,发射机高度和栅格与发射机的距离对非弱覆盖和弱覆盖分布的影响。从图可知,弱覆盖区发射机到栅格的距离的密度值较大,而非弱覆盖区的密度相对较小,从发射机高度的连续分布图来说,弱覆盖区的发射机高度在20 m左右的较多,而非弱覆盖区的发射机高度分布相对较均匀。因此可以得出栅格与发射机的距离这一特征对模型构建的影响较大。 (a) 发射机高度 (b) 栅格与发射机的距离图3 发射机高度和栅格与发射机的距离对非弱覆盖和弱覆盖分布的影响 为了研究传播过程特征参数对模型构建的影响,结合经验信道模型Cost 231-Hata,计算传播路径损耗。 从图4可以看出,PL的值在弱覆盖区时,主要集中在100~200之间,与之对应的是非弱覆盖区主要集中分布在80~200之间,可以明显看到这个特征的差异性不大。 图4 信号传播路径损耗对非弱覆盖和弱覆盖分布的影响 通过对以上几个特征的分析表明,经过Pearson系数进行相关性计算后,相关系数值最大的10个特征,能较好地表示5G传播模型特征参数性能,能有效地度量弱覆盖区和非弱覆盖区的;而在选取的最大相关系数的10个特征之外的特征,其差异性较小,不作为5G传播模型的主要度量特征。 实验从4 000个小区中获取移动通信系统中的特征数据,选取排名前10的特征送入到模型中进行训练,采用五折交叉验证对数据多次划分,训练集和测试集的比例为4 ∶1,这样能极大提升模型的泛化能力。随机森林的随机种子设置为2 018,BP网络中使用Kears框架,其网络层数分别设置为256、128、64、12、1,学习率设置为0.001,优化器选择Adam,而batch_size设置为4 000,epoch设置为100其具体参数可见表3。 表3 BP神经网络的结构和参数 为了详细分析决策树、随机森林、BP神经网络在5G无线网络传播模型中,特征参数的定量化影响,这里引入MAE、RMS和PCRR三个指标连进行度量。 (1) 平均绝对值误差(Mean Absolute Deviation,MAE)是预测值和观测值之间绝对误差的平均值。平均绝对值误差可以避免误差相互抵消的问题,因而可以准确反映实际预测误差的大小,公式如下: (4) (2) 均方根误差(Root Mean Squared Error,RMSE)。RMSE是评估预测值和实测值整体偏差的指标,其大小表明了测试的准确性。RMSE的计算公式如下: (5) (3) 弱覆盖识别率(Poor Coverage Recognition Rate,PCRR)。为更好地帮助运营商精准规划和优化网络从而提升客户体验,实验中,弱覆盖判决门限Pth的值设定为-103 dBm。若RSRP预测值或实际值小于Pth则为弱覆盖,标记为1;若大于等于Pth则为非弱覆盖,标记为0。根据比较预测值和实际值得到的弱覆盖以及非弱覆盖的差别,这里采用ROC指标进行分析: True Positive(TP):真实值为弱覆盖,预测值也为弱覆盖; False Positive(FP):真实值为非弱覆盖,预测值为非弱覆盖; False Negative(FN):真实值为弱覆盖,预测值为非弱覆盖; True Negative(TN):真实值为非弱覆盖,预测值也为非弱覆盖。 PCRR的计算公式定义为: (6) 式中:Precision可以理解为预测结果为弱覆盖的栅格,实际也是弱覆盖的概率,定义为: (7) Recall表示真实结果为弱覆盖的栅格有多少被预测成了弱覆盖的概率,其定义为: (8) 最终,通过对决策树、随机森林、BP神经网络的测试、得出结果,对于5G无线网络信号传播中的均方根误差和弱覆盖识别率如图5(a)所示。可以看出随机森林的预测效果优于决策树和BP神经网络,其PCRR值最大(0.894),而RMSE最小(4.31)(PCRR越大表明弱覆盖识别率的精度越高;RMSE越小表示识别误差越低)。在实验中,BP神经网络虽然经过一些列的改进使得训练的结果并未出现过拟合的情况,但是得到的结果较差。为了进一步对表2筛选出的前10个特征,与其他特征在无线信号覆盖的差异,我们从其余特征中每次抽取3个替换掉筛选出的10个特征的任意三个,进行对比测试。根据表2所示,用特征Altitude(序号20)、Clutter_index2(序号21)、P(序号22)L替换掉Clutter_index10(序号8)、Clutter_index7(序号9)、Clutter_index9(序号10),如图5(b)所示。可以看出,三种方法得到PCRR都有不同程度的下降,而RMSE值都有所增加。同样,用序号17、18、19替换序号6、7、8特征(如图5(c)所示),用序号14、15、16替换序号序号3、4、5特征(如图5(d)所示),PCRR都出现下降,RMSE值都有上升。而且排序越靠前的特征,多模型的影响越大,所以图5(d)的模型预测效果最差。因此可以得出采用随机森林方式对5G无线传播模型的信号预测具有更好的效果。 (a) 算法利用筛选出的10个特征的预测效果 (b) 用序号22、21、20特征替换8、9、10特征后的预测效果 (c) 用序号17、18、19特征替换6、7、8特征后的预测效果 (d) 用序号14、15、16特征替换3、4、5特征后的预测效果图5 决策树、随机森林、BP神经网络对5G无线网络信号 传播预测效果 5G网络的部署,需要充分考虑各种因素来选择基站地址,而网络规划的流程中,高效的网络估算可以使得5G网络部署事半功倍。本文中对比传统的Cost 231-Hata模型来选取特征,使用Pearson系数量化特征与目标值之间的相关性,并以此构造出新的特征,再将这些特征送入到机器学习的模型中来建立无线传播模型,并且能够预测新环境下无线信号覆盖的强度,使得网络建设成本大大减少的同时,还提高了建设效率。未来还需要考虑的是:面对实时更新的数据,构造出的模型是否也能取得理想的成绩,以及是否还能在此基础上构造出更多有利的特征来改善模型的精确度。3.3 BP神经网络
4 实验与分析

4.1 特征选择结果分析


4.2 RSRP预测模型的测试结果分析



5 结 语
猜你喜欢
舰船科学技术(2022年10期)2022-06-17
科学与信息化(2019年28期)2019-10-21
移动通信(2019年2期)2019-03-27
大科技·C版(2018年11期)2018-10-21
科学与财富(2016年32期)2017-03-04
电子技术与软件工程(2016年22期)2016-12-26
兵器知识(2016年11期)2016-11-03
科技视界(2016年20期)2016-09-29
决策与信息·下旬刊(2013年1期)2013-03-11
