
基于遗传神经网络的油料需求预测研究∗
2022-02-18 09:03屈少辉周庆忠周麟璋
舰船电子工程 2022年11期
王 灿 屈少辉 王 帅 周庆忠 周麟璋
(陆军勤务学院 重庆 401331)
1 引言
充足、及时、可靠的油料保障是作战指挥员在战场上灵活运用兵力的前提条件。战时油料需求的巨量性、紧迫性和制约性突出,今后我军遂行联合作战任务,必须对油料保障进行提前筹划,对油料需求进行精准预测,破除需求预测难题,拨开需求障眼迷雾,从而为优化油料储备方案、筹措油料保障力量、制定油料调运计划、组织补给加注活动提供基本依据,促进保障能力生成和作战效能发挥。
战时油料需求预测面临诸多挑战,最为棘手的困难可以从两个方面概括。一方面,若基于潜在任务和消耗标准计算、汇总油料需求,原理易懂、过程简单,但现实中油料保障部门往往无法准确掌握潜在作战任务,缺乏进行详算的依据;不同层级的油料需求分别详算后,欠缺统一的汇总标准,在逐级传递过程中容易出现需求放大效应,向上传递的效率也有待提高;若由战区相关部门统一详算油料需求,计算结果对战役层面后勤谋划具有一定意义,但不能直接指导任务部队油料保障实践。另一方面,若基于历史数据和先进算法进行预测,对油料消耗历史数据的完整性、规模性和可靠性要求很高,然而我军油料数据体系建设尚不完善,主要是实战背景下生成的数据难以获得,只能通过实战化演训生成与今后实战近似的数据;同时对数据重视程度不够,缺少刚性的油料数据采集机制,导致演训相关数据未能有效收集、传递和存储,缺乏必要的历史数据已成为油料需求预测工作的掣肘。
军内外学者对于油料需求预测问题进行了尝试和探索。杨晓峰[1]提出推动大数据在军用油料供应保障中的应用,对利用大数据预测油料需求进行了初步思考;王冰[2]对主流的科学预测方法进行归纳总结,从适用条件、优势劣势等方面分别考量,提出油料需求预测策略;李忠国[3]总结基于潜在任务和消耗标准的需求计算方法,与当前经验做法相契合;吴书金[4~5]对模糊推理方法进行改进,用于预测多种油品需求;樊荣[6]、陆思锡[7]等提出用支持向量机对军种油料需求进行预测;周庆忠[8]、陆思锡[9]、夏秀峰[10]、杨祺煊[11]等提出不同方法改进神经网络,一定程度上提高了神经网络预测油料需求的精度;此外,还有学者提出运用灰色理论[12]、小波分析[13]、随机时间序列[14]、改进粒子群算法[15]等预测油料需求的思路。
2 GA-BPNN预测模型构建
2.1 BPNN结构和原理
误差反向传播神经网络(简称BP神经网络,BPNN)属于多层前馈神经网络,具有柔性的网络结构,通常由输入层、隐含层、输出层构成,隐含层可以是单层或多层,且单层最为常见,隐含层数量、各层神经元数量可按照需求设定,不同结构的BPNN,其性能有所差异,以三层的BPNN为例,基本结构如图1所示。
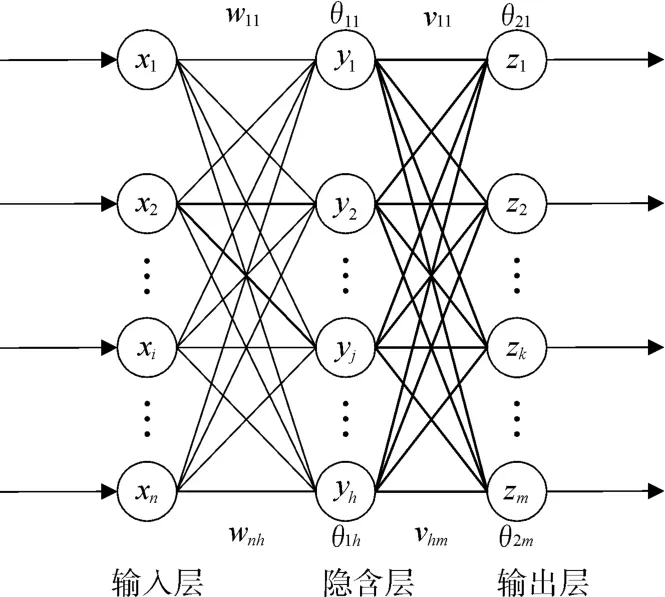
图1 BPNNN基本结构
隐含层的输入、输出分别为
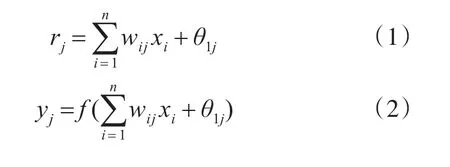
输出层的输入、输出分别为
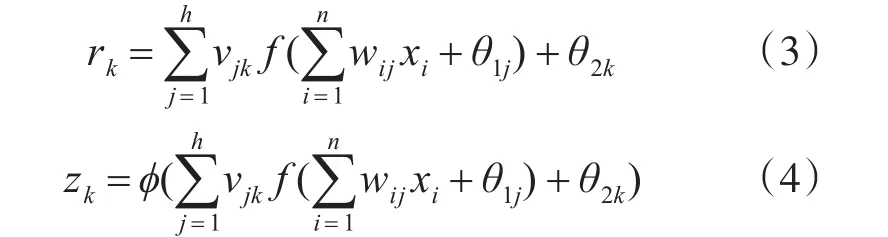
输入层、隐含层和输出层分别对应n、h、m个神经元,wij是输入层第i个神经元对应隐含层第 j个神经元的权值,vjk是隐含层第 j个神经元对应输出层第k个神经元的权值,θ1j和θ2k分别是隐含层第 j个神经元和输出层第k个神经元的阈值,f(x)为隐含层的激活函数,ϕ(x)为输出层激活函数。
BPNN通过信号前向传播和误差反向传播,不断修正权值和阈值,使输出结果误差最小。信号前向传播阶段,输入信号经过隐含层作用于输出层,输入信号经非线性变换产生输出信号,若网络输出和期望输出不一致,进入误差反向传播阶段。误差反向传播阶段,输出误差经过隐含层向输入层传递,同时把误差分摊至各层所含节点,将各层误差信号当作各神经元权值调整依据。通过学习训练,调整输入节点与隐层节点之间联接强度wij、隐层节点与输出节点之间联接强度vjk以及阈值(θ1j、θ2k),促使误差沿梯度方向下降,以期使网络输出和期望输出差别最小。
2.2 GA原理和步骤
遗传算法(GA)是一种模拟生物进化过程的最优解搜索技术,该算法包括编码、选择、交叉、变异、解码等关键步骤,以适应度函数为目标进行优化,通过种群个体迭代,不断趋近优化目标,具有运行高效、能够并行、全局搜索等特点,是一种求解复杂系统优化问题的通用框架,广泛用于目标函数优化和组合优化等,GA实现步骤如图2所示。

图2 GA实现步骤
2.3 GA-BPNN模型构建
BPNN的优势在于较强的非线性映射能力,劣势在于容易陷入局部最优解,影响需求预测能力。为此,本文将使用GA优化BPNN权值和阈值,提升模型对油料需求的预测精度,实现步骤如图3所示。

图3 GA-BPNN实现步骤
初始种群产生。随机产生一定规模的初始种群,进行实数(浮点数)编码,个体的每个基因值用一定范围内的某个浮点数来表示,个体的编码长度N 根据式(5)计算[16]:

其中,权值个数为n×h+h×m,阈值个数为h+m。
种群适应度函数。适应度函数是遗传进化过程的驱动力,本文将适应度函数设置为BPNN预测输出值和实际值之间的均方误差(Mean Square Er⁃ror,MSE)。
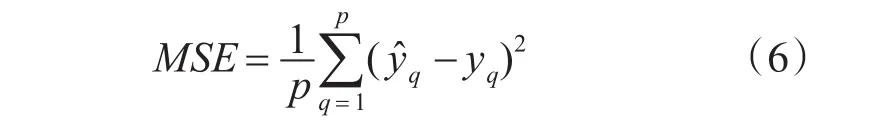
选择操作。通过选择操作实现群体中个体优胜劣汰。轮盘赌选择,个体进入下一代的概率等于其适应度值与整个种群所有个体的适应度值之和的比例,该比例与被选中概率呈现反向关系。最佳保留选择,在完成轮盘赌选择后,将当前群体里适应度最小的个体保留至下一代。
交叉操作。两个染色体之间依据交叉概率按某种方式互相交换部分基因,形成两个新的个体。本文采用两点交叉方式,在个体编码串中随机设置了两个交叉点,然后再进行部分基因交换[17]。
变异操作。依据变异概率将个体编码串中的某些基因值用其它基因值来替换,从而形成一个新的个体。变异运算决定了GA的局部搜索能力,与交叉运算共同完成对搜索空间的局部搜索和全局搜索。本文实行高斯近似变异,使用符合正态分布的一个随机数来替换原有的基因值。
3 GA-BPNN预测案例实践
3.1 数据来源和预先处理
油料需求数据来源解释。为验证遗传神经网络(GA-BPNN)预测效果,更好地与其它模型进行对比,本文选取公开文献[18]所列数据进行研究。该数据集包含25组数据,每组数据由4个自变量(装备数量、任务时长、环境状况量、任务强度量)和1个因变量(油料需求)构成,其中环境状况量化为9个等级,无量纲,任务强度量化为3个等级,无量纲,如表1所示。
训练集和测试集划分。表1所列数据为随机排序,将前20组数据划分为训练样本,用于GA-BPNN训练,最后5组数据用于检验预测效果,验证模型泛化能力。

表1 任务情况和油料需求历史数据
数据归一化处理。鉴于影响油料需求的各个变量具有不同的量纲和数量级,使用神经网络进行预测,必须将样本数据进行归一化处理,把原始数据映射到[0,1]区间,转化为无量纲的纯数值,避免造成预测误差,本文采取最大最小归一化方法(min-max normalization)[19]:

xmin、xmax分别为原始样本数据的最小值和最大值,xi为原始数据,xi'为处理后的数据。
3.2 参数设置和模型训练
网络结构和隐含层节点数。具有三层结构的BPNN能够逼近绝大多数复杂的非线性映射,因而使用三层BPNN进行油料需求预测。由于BPNN的预测性能对隐含层节点数较为敏感,本文首先根据经验公式确定隐含层节点数取值范围[19]:

其中,a为[1,10]内的整数。
尔后,计算不同隐含层节点数对应的训练集MSE,MSE的值越小,模型性能越好。
计算结果如表2所示,最佳的隐含层节点数为4,对应的训练集MSE为4.7578×10-3。

表2 隐含层节点数与训练集均方误差
BPNN和GA关键参数设置。经过数据预先处理,分析数据特点,逐一设置相关参数,如表3所示。
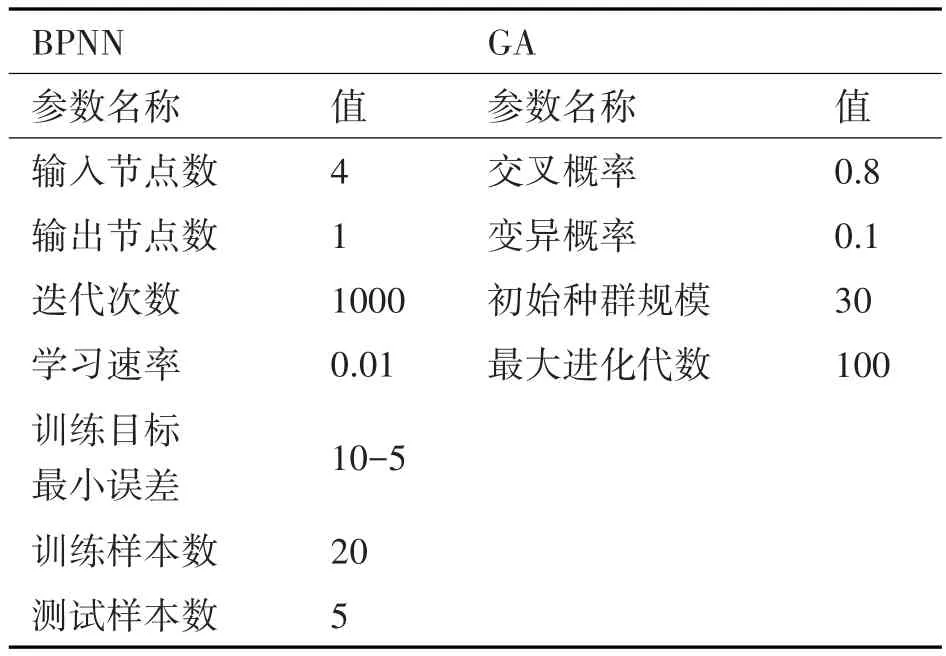
表3 GA-BPNN参数设置
激活函数和训练算法。隐含层激活函数选择双曲正切S型传输函数(tansig),输出层的激活函数采用线性传输函数(puerlin)[20]。我们采用增加动量的梯度下降法(Levenberg-Marquardt,L-M)进行训练,L-M具有收敛速度快、避免陷入局部极值的优点。
3.3 优化前后预测结果比较
油料需求预测结果输出。使用测试集数据对训练好的GA-BPNN进行测试,将预测油料需求与实际油料需求进行对比,如表4所示。

表4 BPNN和GA-BPNN预测结果和绝对误差
优化前后预测结果对比。由表4可知,GA-BPNN平均绝对误差(mean absolute error,MAE)为48.1,BPNN平均绝对误差为79.7。与此同时,从图4可以看出,GA-BPNN需求预测曲线对于真实需求曲线拟合更好,与真实需求曲线非常接近。由此说明,通过GA赋予BPNN最优的初始阀值和权值,可以提高BPNN的预测准确度。

图4 BPNN优化前后预测结果与实际需求
4 GA-BPNN模型与其它模型比较
模型预测性能评价指标选取。平均绝对百分比误差(Mean Absolute Percentage Error,MAPE)是预测模型性能评判常用标准之一,将其选作油料需求GA-BPNN预测模型性能评价指标。
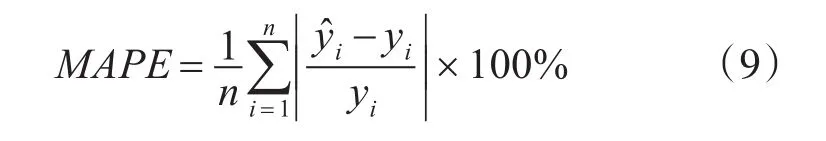
MAPE是一个百分比值,取值越小模型准确度越高,0代表模型完美,大于100%时模型拙劣。
不同模型预测结果对比分析。为进行油料需求预测,文献[18]中提出ELM和SB-ELM模型,文献[21]中提出 SVR和 NRS-SVR模型,现将GA-BPNN与上述模型进行比较,如表5所示。

表5 不同预测模型平均绝对百分比误差
GA-BPNN预测油料需求性能评价。即使本文所用数据仅有25条,可能存在训练不充分的情况,但从表5中可以看出,GA-BPNN的MAPE仅为1.16%,比其它模型的MAPE小,说明GA-BPNN模型具有更好的预测精度,在实践层面这一误差也是可以接受的,符合作战油料需求精准预测要求,具有良好的实战应用价值。
5 结语
由于作战油料需求历史数据稀缺,本文使用文献[18]所列数据进行研究,依据装备数量、持续时长、环境状况、任务强度这四个自变量预测油料需求。个别学者为了提升油料需求预测准确度,考虑了更多的需求影响因素,文献[22]根据9个自变量进行预测。在进行油料需求预测时,考虑更多的影响因素能够在一定程度上提升预测精度,但这些影响因素之间可能存在相关性,可使用因子分析(fac⁃tor analysis,FA)对众多影响因素进行降维,从变量群中提取出隐性的公共因子,计算因子得分用于需求预测,从而降低数据维度,提升预测速率和精度。
伴随着大数据技术的普及推广,相信在不久的将来,军事领域数据建设将取得突破,油料消耗数据体系也将日渐完善,大量可靠的历史数据将会快速积累起来。届时,基于坚实的数据基础,能够训练出更加高效、精确的油料需求预测神经网络模型,有效支撑油料保障活动组织筹划和联合作战后勤指挥决策。
猜你喜欢
现代装饰(2018年5期)2018-05-26
自动化学报(2017年1期)2017-03-11
农家顾问(2016年12期)2017-01-06
中国工程咨询(2016年1期)2016-02-14
中国生化药物杂志(2015年4期)2015-07-07
弹箭与制导学报(2015年1期)2015-03-11
中国民航大学学报(2015年3期)2015-03-01
郑州大学学报(医学版)(2015年2期)2015-02-27
中国储运(2014年4期)2014-04-14
中国储运(2013年6期)2013-01-30
