
基于强化学习提升双GNSS测向精度方法研究∗
2022-02-18 09:03刘佳铭段静玄张学良
舰船电子工程 2022年11期
刘佳铭 段静玄 张学良 林 静
(1.海装上海局驻上海地区第五代表室 上海 200135)(2.中国舰船研究设计中心 武汉 430064)
1 引言
近年来,利用全球卫星导航系统(Global Navi⁃gation Satellite System,GNSS)的雷达标校技术逐渐成为主要方式,通过在远距离释放携带GNSS接收机的无人机,以及舰上安装的GNSS接收机,将两个接收机的经纬度、海拔数据转化为方位距离仰角,再经过位置间隔修正到雷达所在位置,比较雷达读数和修正后的方位距离仰角,分析其误差。由于GNSS的定位精度可以达到厘米级,因此标校精度可以达到0.01°,成为了现在标校的主要技术。
然而在动态测量中我们发现,由于船舶的摇摆及无人机的位置变化,以及GNSS信号的波动,在测量过程中可能会出现部分数据精度不足的问题,严重影响了标校结果。因此,本文提出一种基于GNSS数据优化改进方位距离仰角测向定位的方法,具体来说,我们开发了一个强化学习模型来实现修正双GNSS相对位置计算的最优策略。为了加速训练过程并获得更好的性能,实现了一种最先进的并行训练架构,即异步优势参与者-批评(A3C)协议,用于学习最优校正策略。由于缺乏对模型参数的严格假设,所提出的框架具有通用性,适用于非静止环境下的不同GNSS设备和位置。
在提出的强化学习模型中,我们提出了一种独特的奖励机制,不同于其他深度学习或强化学习[1]框架中通常使用的奖励结构。我们没有使用直接分数,就像在为玩游戏而开发的模型中所做的那样,我们使用一种抽象方法来提供低方差奖励值,并通过在奖励函数中加入预测置信度来提供额外的好处。所提出的方法通过使奖励独立于地理位置来建立一个通用框架。模型性能通过合成数据以及真实世界的实验进行评估,并与扩展卡尔曼滤波器算法进行了比较,该算法是定位问题中常用的基准算法。
2 国内外研究现状
提升双GNSS测向精度的主要方法之一是提升单点定位精度的精度,目前主要的研究可以分为基于硬件的和基于软件的两类。
基于硬件的方法尝试使用额外的硬件设备来提高GNSS精度。在整个网络中部署参考站是提高GNSS精度性能的一种方法[2]。然而,建造参考站可能既昂贵又耗时。也有大量研究使用辅助硬件来增强传统GNSS设备,例如惯性测量单元(IMU),是提高 GNSS定位性能的另一种方法[3]。基于辅助设备和增强的基础设施,设计了具有不同定位精度的不同类型GNSSGPS。惯性导航系统已广泛用于航位推算系统。差分GPS(D-GPS)使用高质量GPS接收器和高质量参考位置来构建可以提高定位精度的系统[4],而实时动态(RTK)GPS使用RTK网络来提高GPS性能[5]。缺点很明显:辅助硬件的故障会降低GNSS系统的性能。大规模部署基于硬件的设备也很昂贵。
另一方面,基于软件的算法已显示出提高GNSS精度的潜力。基于卡尔曼滤波器的算法是提高GPS定位精度的最广泛使用的算法之一[6~7]。然而,这些方法通常被开发用于线性运动和传感器模型,使其不直接适用于非线性的运动模型。虽然卡尔曼滤波器可以升级为无迹卡尔曼滤波器(UKF)或扩展卡尔曼滤波器(EKF)来解决非线性转换,但很难为此类模型找到合适的高斯噪声参数[8]。当状态空间变大时,识别正确的运动模型和计算雅可比矩阵在计算上也可能很昂贵[9]。此外,运动模型可能因测量环境和目标移动而异,因此很难开发出能够在一组适用于无人机标校的卡尔曼滤波器。
强化学习(Reinforcement Learning,RL)的目的是生成将系统状态映射到动作集的策略分布,从而最大化奖励回报[10]。基于强化学习的方法在众多应用领域取得了令人瞩目的进展,由于它们在不同领域的广泛使用和高性能,近年来大量研究致力于改进 RL 算法[11]。
与文献中发现的物理系统中典型的强化学习实现不同,所提出的模型不需要物理代理来控制GNSS设备。相反,它通过“校正”动作提高了廉价GNSS单元收集的GNSS经度和纬度数据的准确性。与基于硬件或软件的方法不同,所提出的模型不需要任何辅助设备,也没有对GNSS单元的噪声参数或其运动模型做出严格的假设。所提出的模型利用GNSS读数的历史,在以前未见过的环境中训练自己。与引用研究使用的方法相比,所提出的模型不使用与地理位置直接相关或受环境影响的奖励函数。相反,它引入了动作置信度以形成抽象的奖励机制,因为奖励的计算与地理位置无关,这使得模型具有泛化性。
3 基于强化学习的模型
3.1 问题描述
本文的主要目的是提高GNSS设备的定位精度,以及双GNSS进行测向计算时得到的方位、距离、仰角数据更加准确,以达到标校的标准。目标是在观测到的GNSS经纬度坐标上找到最佳校正策略,以产生更准确的位置。一般过程类似于过滤——强化学习模型将GNSS设备收集的实时经纬度坐标作为输入,并利用该模型来改进定位。模型的输出是关于如何纠正观察结果以产生更准确定位的行动策略。
所提出的框架的行为类似于过滤器——它将GNSS设备的典型经纬度输出作为输入,并对估计的经纬度执行“校正操作”以提供更准确的输出。当接收到新的数据点时,强化学习模型会训练代理来确定需要调整观察到的经度和纬度以返回更准确定位的“单位”数量。Kollar[12]指出,从决策理论的角度来看,这种顺序决策问题可以建模为部分可观察的马尔可夫决策过程(Partially Observable Markov Decision Process,POMDP)。该模型的目标是学习一个策略π(a|z,θ),其中a表示动作向量,z是观察向量,而θ是模型参数的向量。该策略的目标是参数化在给定特定观察z时执行动作的条件概率,以最大化一个人的奖励。
3.2 模型设置
在本节中,我们将介绍所提出的强化学习模型的细节,包括动作空间、隐藏状态、观察、信念状态、奖励机制、模型结构和训练协议。
1)动作空间
我们将动作定义为经纬度更新操作。为了降低所提出算法的计算复杂度,我们将连续的经度和纬度值离散为小步。通常不建议对动作空间的每个单独维度进行离散化,因为它可以成倍地增加策略表的大小。然而,离散化动作空间对于降低算法在低维动作空间中的计算复杂度可能很有用,就像这个问题中的情况一样。因此,建议的工作根据以下过程离散化动作空间:
(1)定义纬度和经度的单位运算,分别用ux和uy表示,以及一个缩放矩阵S。不失一般性,我们为 S 定义以下范围:S=[-10,-9,-8,…,0,1,2,…,10]。
(2)纬度和经度上的操作域,分别用Lx和Ly表示,是 Lx=Sux和 Ly=Suy。
(3)通过结合经纬度操作将动作离散化为动作集A。离散动作 a∈ A可以定义为 a=(x,y)∈ Lx×Ly
(4)对经纬度的连续运算由动作集A表示,其中A包含所有可能的动作。基于上述对应的缩放矩阵S,有限动作集A的长度为212=441。
在观察到的GNSS数据点上在动作空间A中执行动作可以产生441个可能的输出。例如,如果观察到的GNSS数据点是(x,y),则可能的输出是(x±mux,y±nuy),m,n∈ S 。当前的 GNSS设备很少报告与地面事实有太大偏差的点。因此,我们假设通过选择合理的ux和uy,GNSS设备的准确位置包含在所有可能的输出中。ux和uy的合理值受相应GNSS设备精度的影响。因此,可以通过为ux和uy选择不同的值来修改操作范围。
2)测量和模型输入
GNSS设备以特定频率报告其位置。在所提出的模型中,观察不限于最后报告的GNSS位置,而是包含最后报告的位置以及最近的点预测历史的堆叠向量。也就是说,我们不使用报告的GNSS轨迹,而是使用模型预测来形成观察历史向量。需要注意的是,预测频率可以设置为高于GNSS数据收集频率的值。这种形成观察向量的方法允许模型利用GNSS设备的历史轨迹信息以及模型性能,使模型能够学习高质量的策略来校正报告的GNSS点。
用qt表示GNSS报告的时间戳t点,用gt表示它的真实位置数据。由于真实位置未知,因此可以将问题表述为POMDP。在这个POMDP中,我们使用pt来表示GPS报告点qt的置信状态,在强化学习模型中为pt。本文通过完全可观察的信念状态马尔可夫决策过程(Markov Decision Process,MDP)来确定最优的行动方案,其中信念形成状态,策略π将行动映射到信念状态;也就是说,部分观察到的状态被它们的估计、信念状态所取代,从而形成一个MDP。我们使用具有恒定大小N的观察缓冲区Zt来存储最近N-1个GNSS报告点的历史模型估计值和当前 qt;即 Zt={pt-N-1,…,pt-1,qt}。让我们分别用St和bt来表示Zt的隐藏状态和置信状态。给定一个大小为N的观察缓冲区,在时间t,向量St包含这些点的相应地面实况缓冲区;即St={gt-N,…,gt}。向量bt包含最近N个点的估计;即bt={pt-N,…,pt}。需要注意的是,Zt和bt仅在最后一个元素上有所不同,即Zt的最后一个元素是qt,而向量bt的最后一个元素是pt。该模型基于Zt估计bt。用R表示奖励,POMDP图如图1所示。
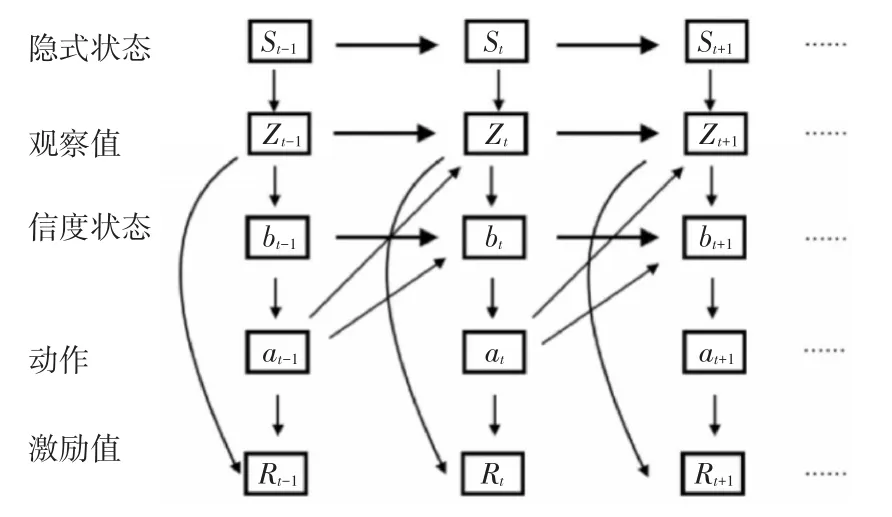
图1 部分可观察的马尔可夫决策过程模型示意图
相应的信度状态控制器如图2所示。状态估计器将观察、动作和信度状态作为输入,并提供信度状态作为输出。学习到的策略将信度状态映射到动作,输出动作会影响下一个时间戳中的观察和信度状态。

图2 部分可观察的马尔可夫决策过程代理模型
基于上面的POMDP设置,强化学习代理在每个时间戳t的目标是找到纠正qt的最佳纠正动作。该过程基于滑动窗口进行。一旦接收到新的qt,滑动窗口向前移动一步以形成一个具有恒定大小N的新观察向量,其中qt构成最后一个元素,最后N-1个信度构成观察向量Zt的其余部分。模型输入(观察Zt)更新过程(即训练流程)如图3所示。

图3 模型输入数据更新过程
每次GNSS设备报告一个新的位置点qt时,模型都会被训练并移动到下一个观察缓冲区。当GNSS设备获得pt时,将其推送到观察缓冲区以替换qt,同时观察移动到时间t+1。也就是说,在每个训练步骤中,强化学习模型的观察都包含观察到的GNSS点和一系列历史估计。
GNSS报告点q、模型预测点p与相关模型架构之间的关系如图4所示。

图4 模型结构
4 实验
在本节中,通过将其与基准模型(即EKF模型)的性能进行比较来评估所提出的强化学习模型的性能。
1)实验设置
由于GNSS的真实值难以度量,因此我们构建仿真数据进行实验。具体地说,我们使用在现实世界条件下使用GNSS设备收集的轨迹,作为未知的真实值。接下来,我们使用高斯噪声模型生成噪声并将其添加到基本轨迹,模拟GPS传感器观察。这个嘈杂的轨迹如图5所示。在这个轨迹中,每个时间步都包含一个GPS数据点,即一个经度和纬度对。考虑1Hz的GPS频率。

图5 增加噪声后的轨迹
在将强化学习和EKF方法应用于轨迹数据之前,我们将long/lat坐标转换为UTM(即笛卡尔)坐标。为了评估RL和EKF的性能,考虑了每个GPS点的预测误差以及整个轨迹的累积误差。假设每个点 i(GPS设备/车辆未知)的地面实况为(gxi,gyi),其预测结果为(lxi,lyi)。每个预测的误差可以计算为

累积误差可以计算为

其中C是轨迹上的数字操作点,N是观察缓冲区。在这里不需要考虑前N个点,因为至少需要N个点来进行训练。通过比较RL和EKF方法的Ei和Eall值,可以评估所提出的RL模型的性能。
2)结果
我们将强化学习和EKF方法应用于模拟轨迹,并根据方程测量每个预测点的误差。结果如图6所示。对于EKF方法,大约200步后达到收敛。对于RL方法,大约150步后达到收敛。

图6 每个GNSS观测的EKF和RL误差
两种方法在轨迹过程中都有减少的误差趋势。这表明两种方法都能够提高GPS定位精度。此外,与EKF相比,RL方法的误差值更小。在收敛部分,与EKF方法相比,RL方法提供的方差更小。
EKF的较差性能可归因于对噪声参数和模型的严格假设。在使用EKF提高GPS精度时,观测的确切噪声参数和运动模型是未知的,限制了EKF的性能。EKF性能较差的另一个原因是无噪声观测的不可用(即,没有地标或参考站可以为EKF算法提供无噪声观测),提出的RL不是对噪声参数进行严格的假设,而是方法学习一个最佳策略来纠正当前GPS报告的点,并使用模型奖励来衡量其预测的质量。这消除了对噪声分布和参数的严格假设的需要。
5 结语
在本文中,我们提出了一种强化学习模型来提高GNSS测向定位精度。强化学习方法在应用于计算机视觉和机器人技术中的问题时表现非常出色,例如玩ATARI游戏和控制机器人。本文使用强化学习来构建一种类似过滤器的算法,以提高GNSS计算精度。该模型使用历史轨迹的GNSS位置数据作为输入,使其能够根据最近的过去学习轨迹模式,并生成修正后的GNSS位置。我们使用基于置信度度量的奖励机制来评估异步模型的预测性能。
这项工作将提出的强化学习模型与经典的定位方法进行比较,即扩展卡尔曼滤波器(Extended Kalman Filter,EKF)。使用模拟数据的结果表明,EKF和RL都可以提高GNSS定位精度;然而,所提出的RL方法可以提供更高质量的预测,其定位误差是EKF的一半,并且方差更小。
这项工作是基于GNSS读数始终可用的假设,这可能会限制其在实践中的适用性。由于假定GNSS设备的频率是稳定的,因此不考虑包括GNSS信号丢失(例如,由于高楼的阻碍)的情况。放宽这个假设是我们未来研究的方向之一。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
读友·少年文学(清雅版)(2020年4期)2020-08-24
读友·少年文学(清雅版)(2020年3期)2020-07-24
智富时代(2019年4期)2019-06-01
智富时代(2019年4期)2019-06-01
制造技术与机床(2018年10期)2018-10-13
现代装饰(2018年5期)2018-05-26
中国三峡(2017年2期)2017-06-09
雷达学报(2017年1期)2017-05-17
