
基于深度图正则化矩阵分解的多视图聚类算法
2022-02-18 08:12刘相男丁世飞王丽娟
智能系统学报 2022年1期
刘相男,丁世飞,王丽娟,2
(1.中国矿业大学 计算机科学与技术学院,江苏 徐州 221116; 2.徐州工业职业技术学院 信息与电气工程学院,江苏 徐州 221400)
随着多元化数据的产生与积累,传统聚类算法只针对于单一视角进行数据的相似性聚类对于现实中的很多数据不再适用。现实社会中,数据集往往从多个数据源收集,或存在不同的表示形式和特征信息构成多视图数据[1-3]。例如,同一事件通过不同的内容形式播报出来;同一文档可以翻译成多种语言;网页数据可以通过文本或网页链接获取。相较于单一视角的数据,多视图数据从多个视角呈现对象,使之特征信息更加完整。那么,如何利用多个视图的完整信息发现不同视图间存在的一致的潜在信息成为多视图聚类算法的目标[4-5]。
近年来,多视图聚类算法获得了越来越多的关注和发展。根据多视图聚类算法的根本机制和原则,多视图聚类算法主要包括基于K-means的算法、基于矩阵分解的算法、基于图的算法以及基于子空间的算法[6]。例如,伍国鑫等[7]结合co-training的思想提出了一个改进的多视图K-means聚类算法。Xu等[8]提出了一种基于K-means处理高维数据的算法,将多视图聚类和特征选择集成到一个联合框架中,选择合适的视图和重要的特征聚类。最近提出的FRMVK算法提出使用较小权重消除不相关特征,实现简化有效特征信息的目的[9]。Nie等[10]开发了一种基于图的聚类算法,能够同时学习多视图聚类和局部结构。之后,Nie等[11]又提出了一种基于图的多视图聚类算法,其基础思想是从一系列低质量的特定视图中生成一个具备鲁棒性的共有图。Gao等[12]在早期考虑尝试扩展传统的基于子空间的多视图聚类算法,称为多视图子空间聚类算法(multi-view subspace clustering, MVSC) 。Zhang等[6]提出可以在隐藏公共空间中进行子空间聚类。针对多个视图在聚类性能上贡献度的差异问题,黄静对每个视图进行了加权[13];范瑞东等[14]则采用了更具鲁棒性的自加权方式。Zheng等[15]提出使用l2,1范式解决融合的多视图数据中特定样本与特定簇之间的关联性问题,从而获得多视图数据的共有信息。
在众多研究中,非负矩阵分解算法及其扩展算法因其良好的聚类可解释性而受到越来越多的关注[16],如何通过非负矩阵分解获取多视图数据潜在的数据信息成为热点研究方向之一[17]。半非负矩阵分解算法(semi-nonnegative matrix factorization, Semi-NMF)是为扩展非负矩阵分解算法(nonnegative matrix factorization, NMF)的应用范围而提出的算法[18]。考虑到特征表示矩阵与原始数据矩阵之间的映射矩阵存在隐藏的层次结构信息,Trigeorgis等[19]提出一种深度半非负矩阵分解模型,通过逐层分解自动学习数据点的层次属性。从数据的几何结构出发,数据点往往是从嵌入在高维环境空间中的低维流形空间中采样而得[20],数据的固有几何结构在矩阵分解中并没有得到充分的运用。而现有的很多算法证明了图正则化从样本的相似性上保护了数据的几何结构[21],例如,Zhao等[20]将深度矩阵分解模型应用于多视图,并在最后一层分解中加入图正则化,有效提高模型性能。算法MMNMF将共识系数矩阵与多流形正则化相结合,在对数据进行矩阵分解的同时保护数据的局部几何结构[22]。Zhang等[23]通过图嵌入增强了有用的信息,并在每个视图中使用正交约束进行聚类,从而删除多余信息。
考虑到深度半非负矩阵分解模型和图正则化各自对于数据的层次属性和固有几何结构的作用,同时从保护数据的局部结构和全局结构两个方面出发,在深度分解模型中,对每一层的特征表示矩阵加入两个图正则化限制,从而充分挖掘出数据的层次属性信息的同时保护数据的固有几何结构。换言之相较于现有的基于矩阵分解的多视图聚类算法,本文提出的算法不仅使用了局部结构的相似性而且加入了全局结构的不相似性共同构成图正则化器,从而更全面的保护和使用数据的几何结构关系。与此同时,图正则化器不只作为共识表示矩阵的调节器,同时将其加入每一层分解中,使得多视角的几何结构关系扩展至每个视角的每一层的表示矩阵中,保持几何关系的稳定性,最大化视角间关系。除此之外,考虑到多视图数据的差异性,对每个视图加入一个权重值,调节每个视图在共识表示矩阵中所占比重。本文针对所提出的模型采用相应的迭代优化算法,从理论上证明算法的收敛性。在多个数据集上的实验结果与分析证实了算法的性能优越性。
1 相关工作
1.1 半非负矩阵分解算法
非负矩阵分解(nonnegative matrix factorization, NMF)算法对基础矩阵Z和特征矩阵H的非负限制使得算法本身更具备聚类易解释性, 但与此同时数据矩阵X的适用性也受到了限制。为了扩展矩阵分解的应用范围,Ding等[18]提出了一种半非负矩阵分解算法(semi-nonnegative matrix factorization, Semi-NMF),改变了对数据矩阵X和基础矩阵Z的限制条件,其优化问题为

式中: ‖ ·‖代表Frobenius范数;X∈ Rd×n是输入的数据矩阵,包括n个样本;Z∈ Rd×k是分解后的基础矩阵;H∈ Rk×n是分解后的特征表示矩阵,它是非负的;k是数据矩阵经过矩阵分解之后的维度。使用迭代的优化算法,文献[18]给出式(1)中基础矩阵Z和特征表示矩阵H的更新策略为
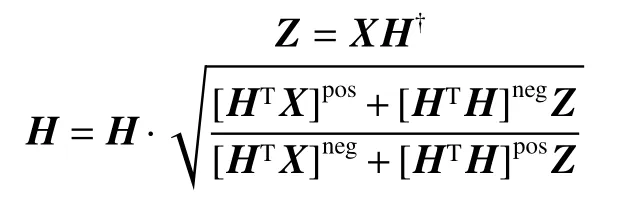
式中:H†是指矩阵H的Moore-Penrose伪逆矩阵;矩阵M的 [M]pos表示矩阵的负数均用0代替,相似的 [M]neg表示矩阵中的正数均用0代替,两者的计算公式如下:
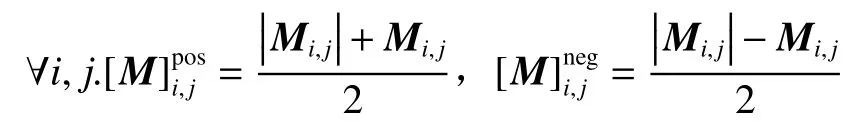
1.2 深度矩阵分解算法
Semi-NMF是NMF算法的扩展算法,从聚类的角度出发,分解之后产生的基础矩阵Z可以看作是聚类质心矩阵,特征矩阵H可以看作数据点聚类之后的成员关系矩阵[18,24]。那么,半非负矩阵分解产生的低维表示矩阵H与原始特征矩阵X之间的映射矩阵Z中很有可能包含更为复杂的层次结构信息。因此,Trigeorgis等[19]提出一种深度矩阵分解模型(deep Semi-nonnegative matrix factorization, Deep Semi-NMF)。其算法结构如图1所示。
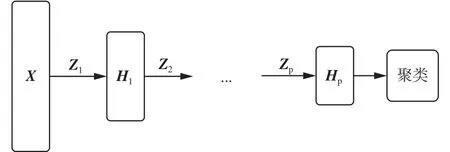
图1 深度半非负矩阵分解Fig.1 Deep semi-nonnegative matrix factorization
从图1中可以看出,深度矩阵分解算法使用多层分解的方式,将i层的分解矩阵Zi作为下一层分解的输入矩阵,最后一层的特征表示矩阵将用于聚类获得数据的类别信息。多层次分解的具体过程和优化问题如下列公式所示:
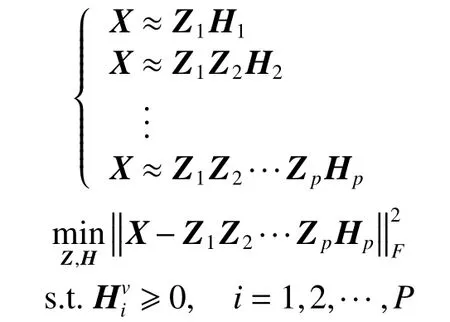
式中:Zi是第i层的映射矩阵;Hi是第i层的特征表示矩阵。
2 多视图深度图正则化矩阵分解聚类算法
深度半非负矩阵分解算法通过逐层分解的方式证实了原始数据与特征表示矩阵之间隐藏着低维特征属性的层次属性,但是在应用于多视图聚类时忽略了数据的固有几何结构。本文提出多视图深度图正则化矩阵分解聚类算法,通过对深度矩阵分解的各层加入两个图正则化的限制,保护数据的几何结构信息。
2.1 图正则化
假如两个数据点Xi和Xj在数据分布中有相近的内部几何关系,那么在新的基础空间中对应的表示矩阵Zi和Zj应该拥有类似的关系,这就是流形假设[25-26]。这种几何结构信息可以通过构建数据点的最近邻图进行有效的建模[27]。Mikhail通过最近邻图对数据局部几何结构的保护提出降维算法−拉普拉斯特征映射(laplacian eigenmaps, LE)[28]。在此基础上,SNE(stochastic neighbor embedding)算法加入数据几何结构的全局关系,认为高维空间数据点之间的不相似性关系在低维空间中保持不变[29]。EE(elastic embedding)算法[30]沿用SNE的思想,改变全局结构的计算方式,使得算法更简单,更易实现。EE算法的目标函数为
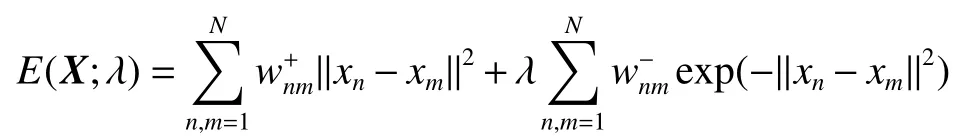
2.2 多视图深度图正则化矩阵分解聚类算法的目标函数
受到EE算法[30]对数据几何结构的保护以及数据隐藏的层次属性的启发,在深度矩阵分解的各层中加入局部几何结构和全局几何结构信息,将两个图正则化嵌入深度分解的各层,使得数据的几何结构对数据新的表示矩阵进行微调。算法的目标就是为了最小化下列问题:

其中优化问题(式(2))中对数据的局部几何结构的计算可进一步简化:
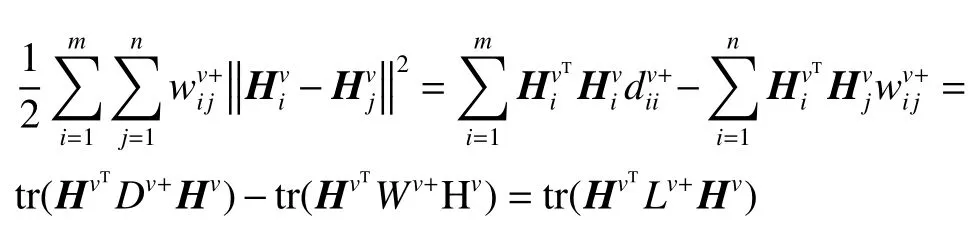
那么优化问题(2)可以改写为:
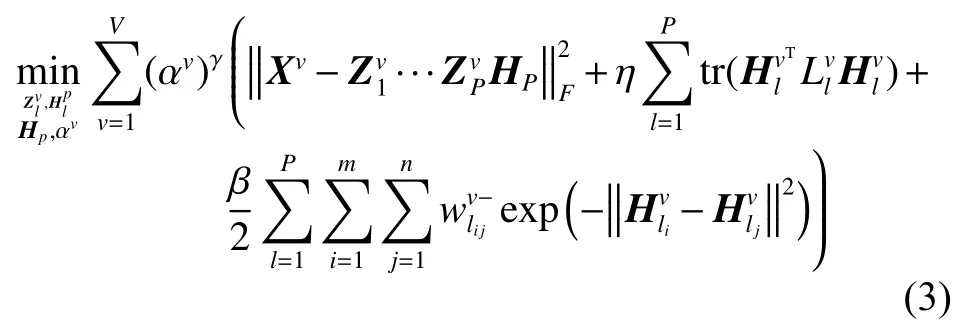
根据对数据全局几何结构的计算方式,优化问题(3)可进一步简化为
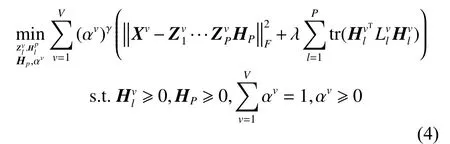
3 算法优化
为优化模型的性能,在对数据进行深度图正则化矩阵分解之前,需要对每个视角各层的基础矩阵和特征表示矩阵进行初始化。这里使用加入了图正则化的半非负矩阵分解算法进行各层的初始化。之后,使用迭代更新的方式优化函数变量。算法的成本函数为
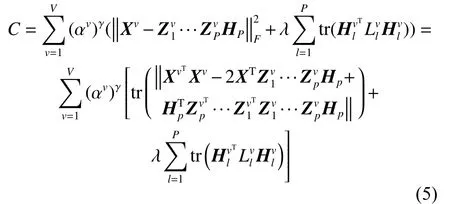
根据拉格朗日乘子法,对每个变量进行求导更新计算。
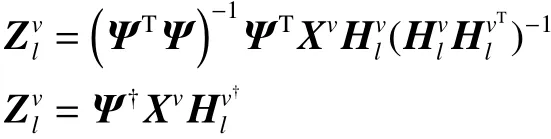
2) 固定变量、 αv,优化更新,HP。
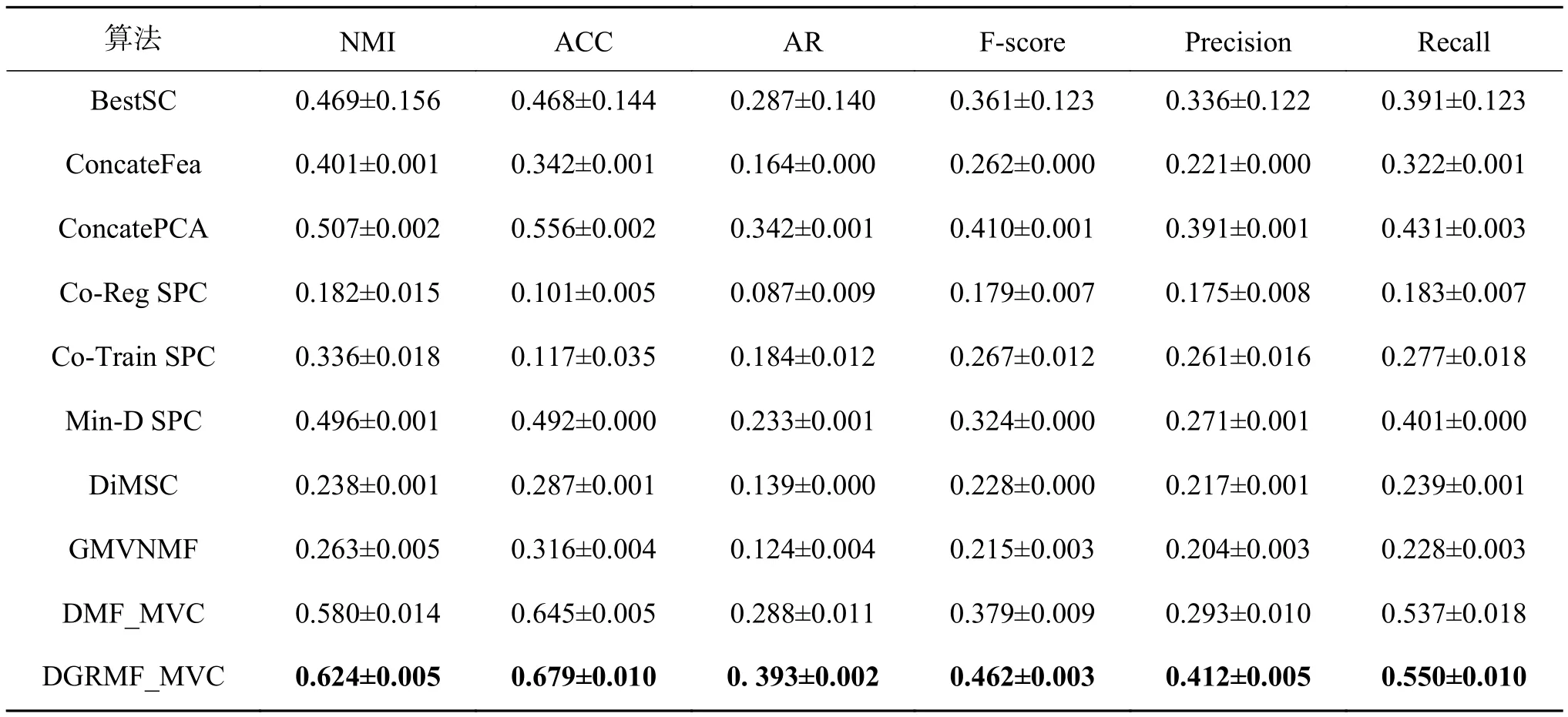
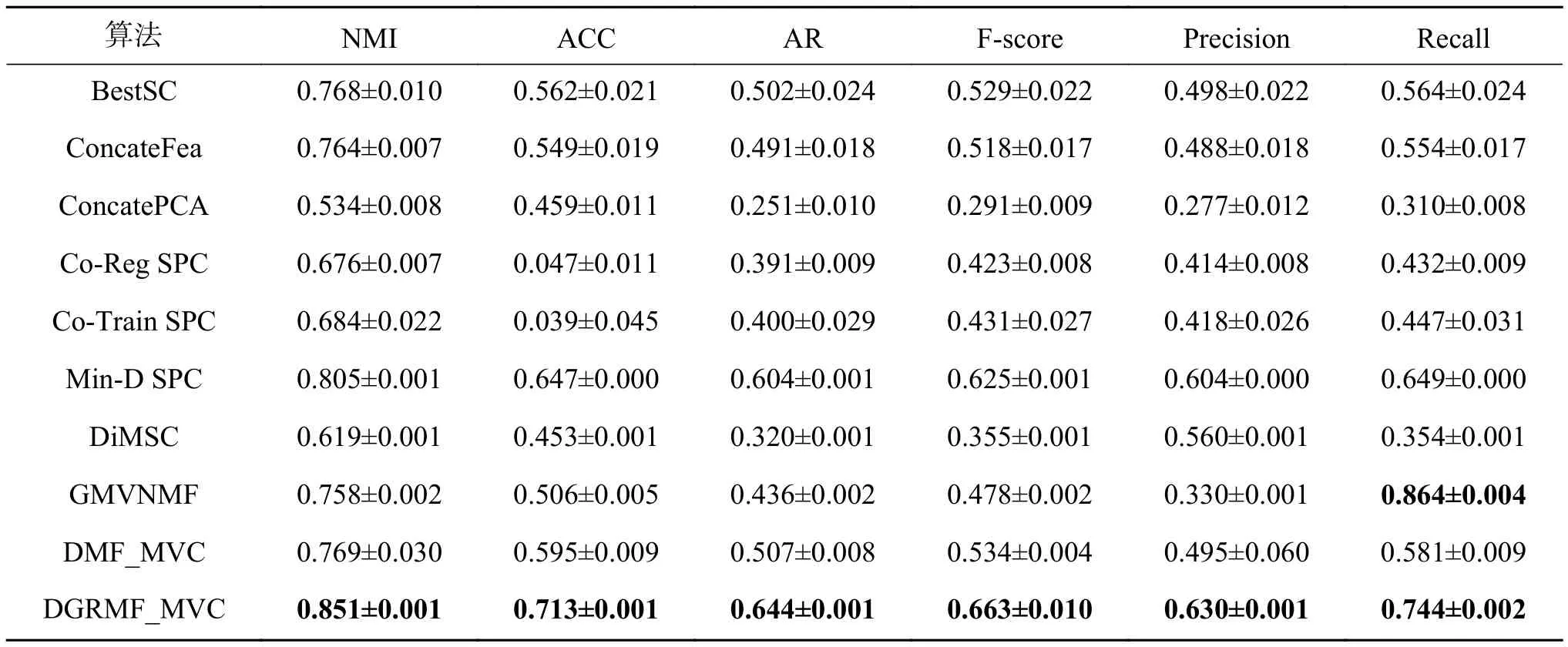
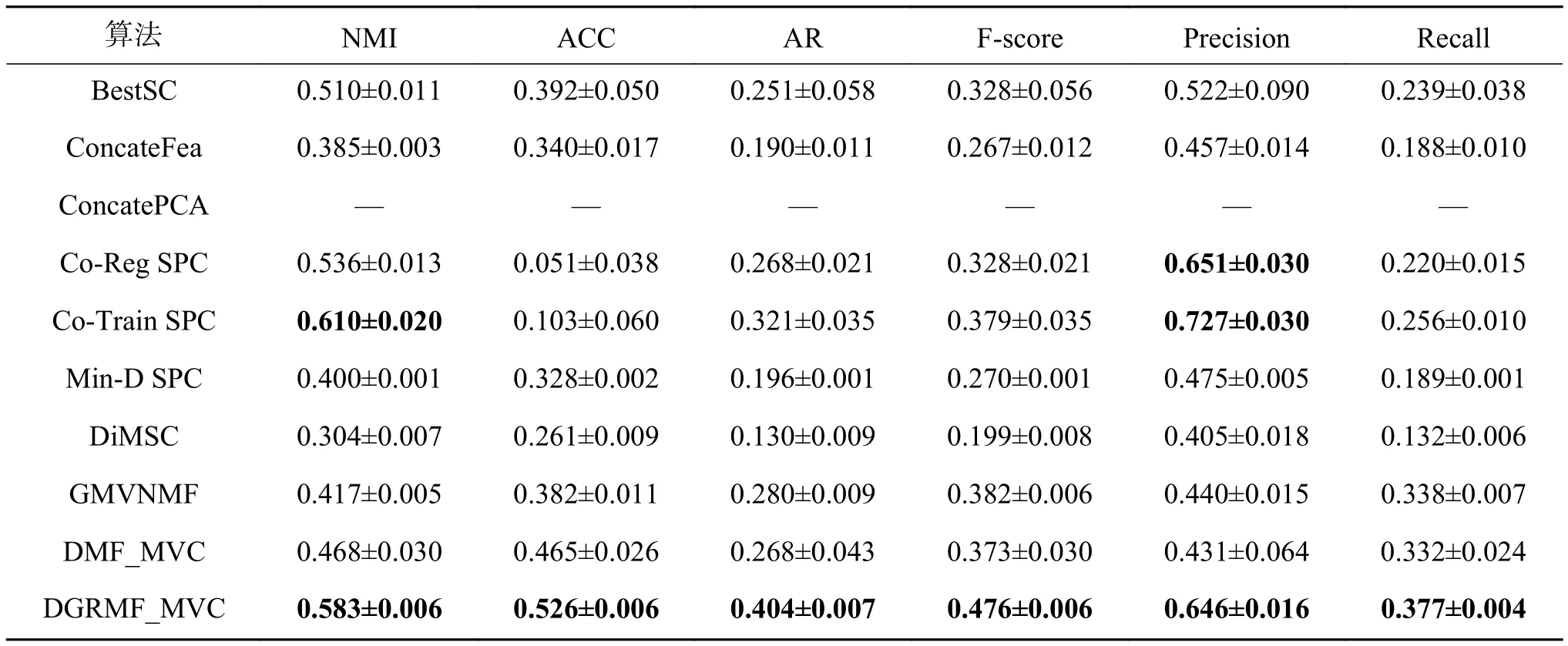
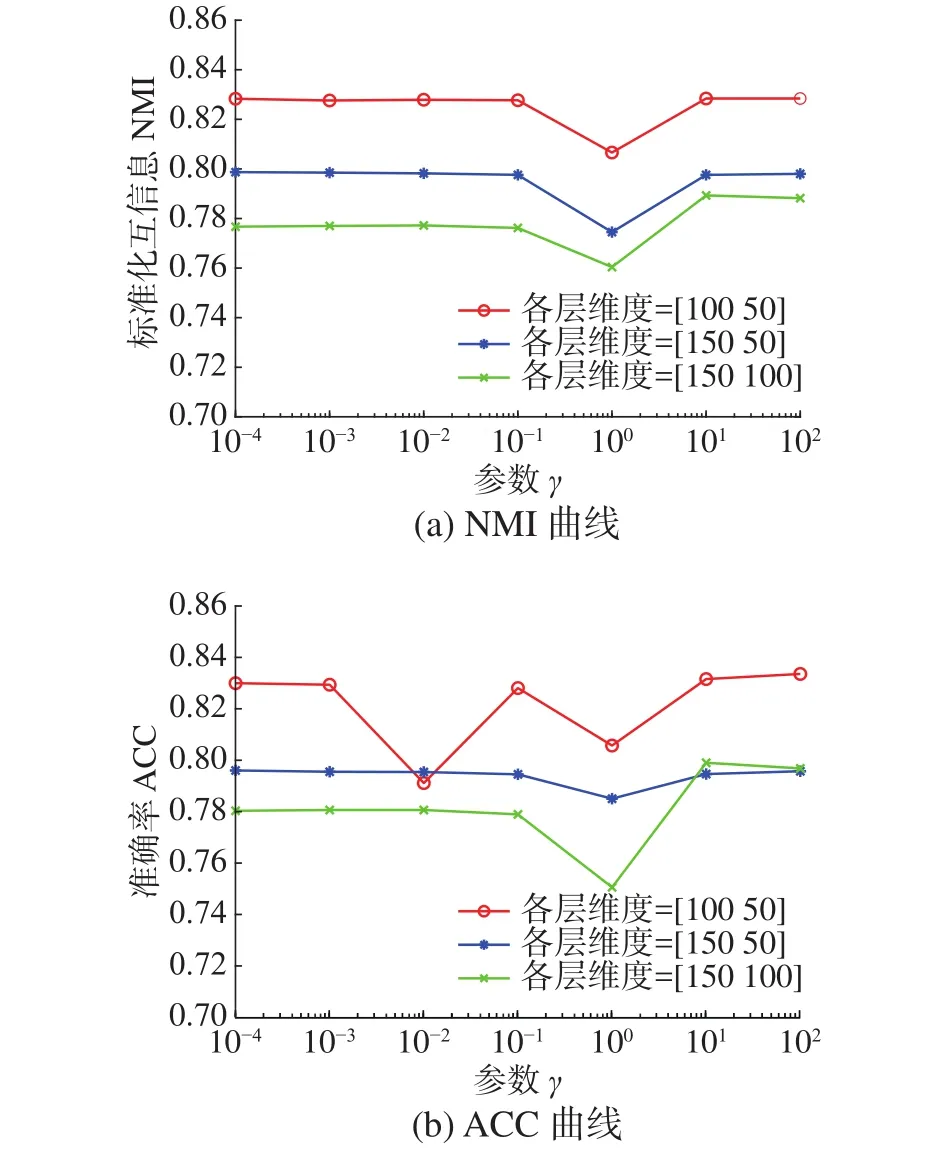
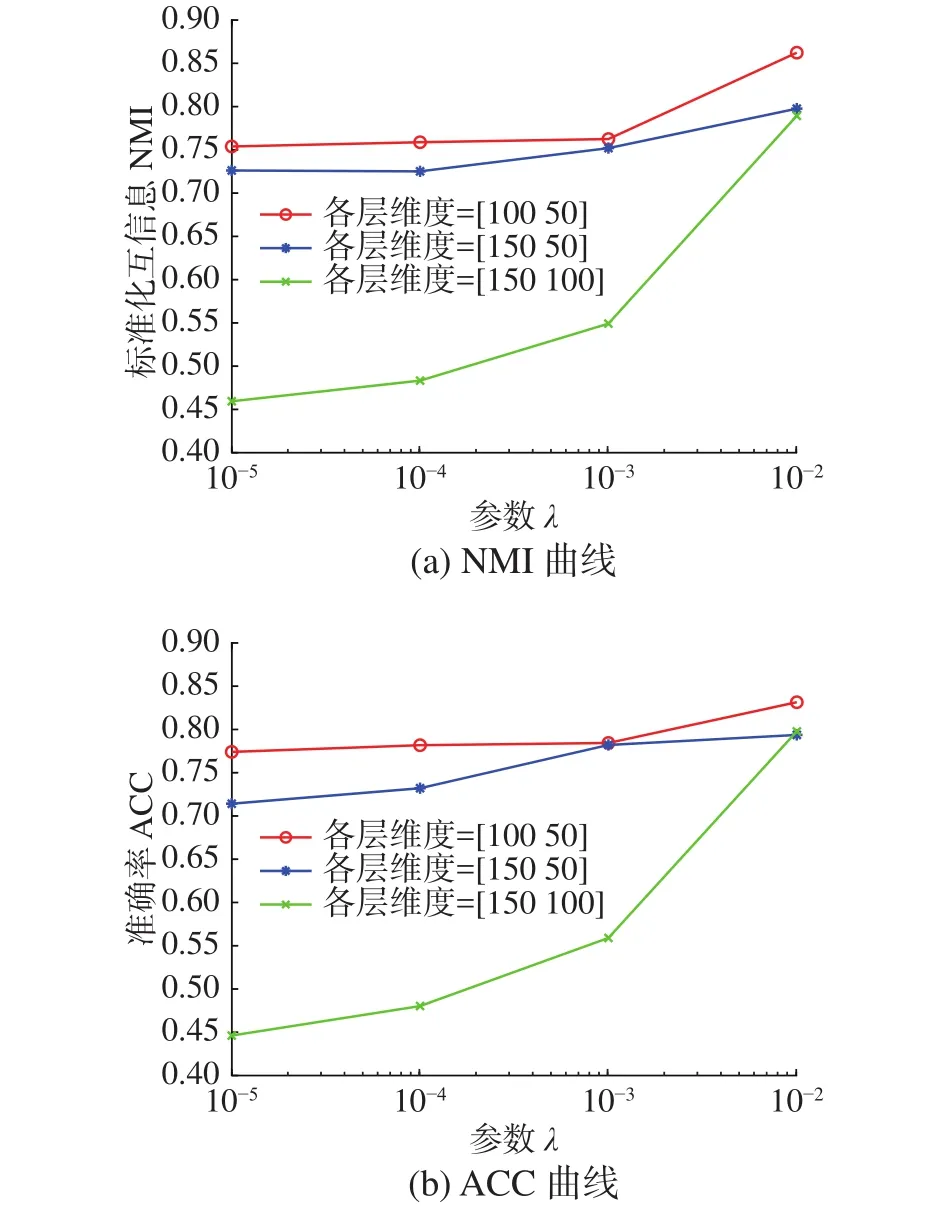
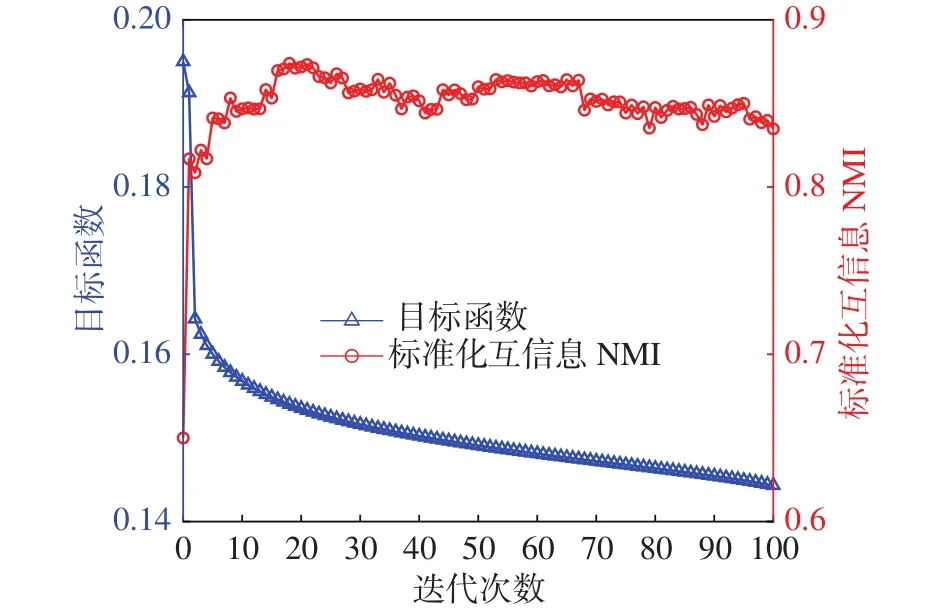
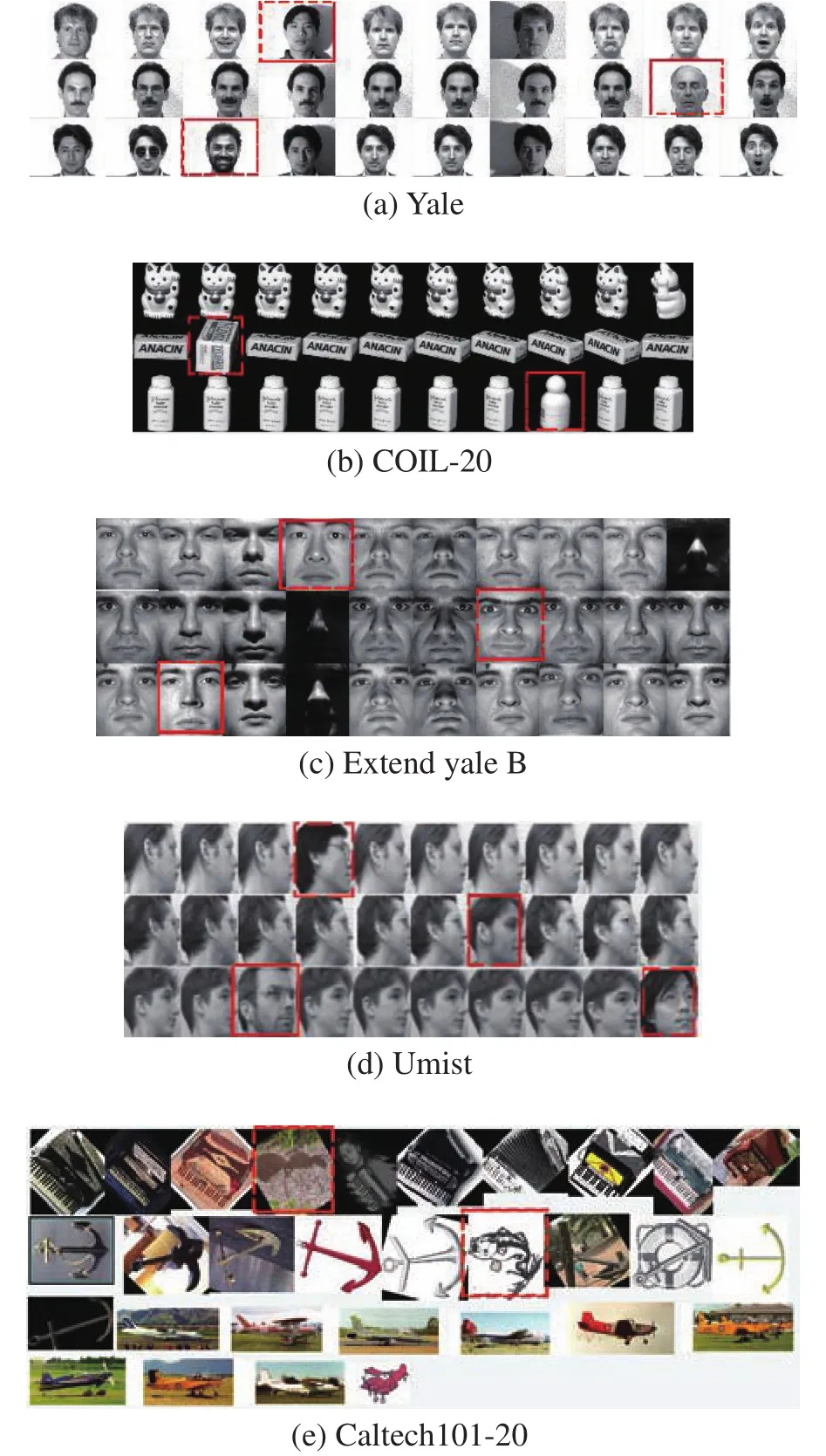
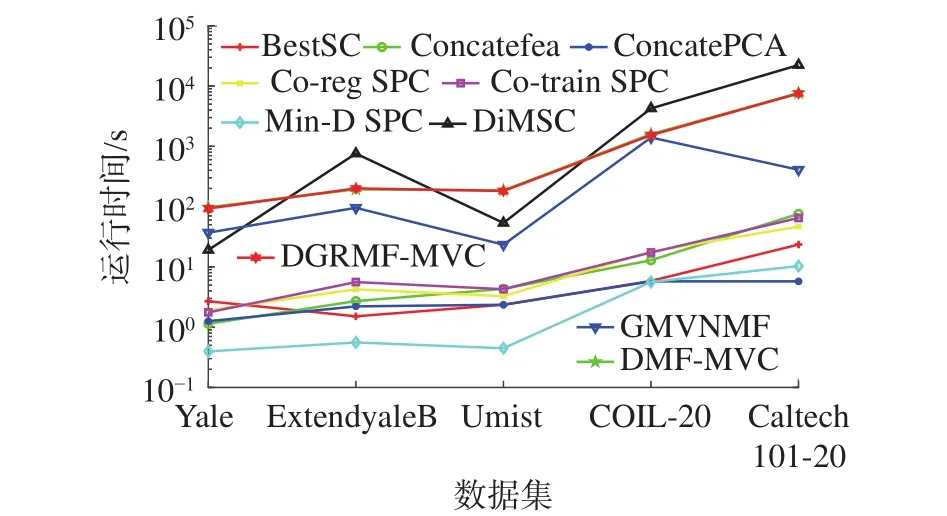
当l 定理1更新公式(6)的有限解满足KKT条件。 证明有关的优化问题是含有不等式约束条件的拉格朗日函数: 其中参数 ξ是为了满足不等式约束条件≥0而产生的乘子。对式(7)进行求导并使之为0,即根据对偶性定理,可以得到: 根据M=[M]pos−[M]neg,式(8)可以简化为 根据等式的收敛性,式(7)与式(8)等价。当其中一个等式满足时另一个等式也是满足的,且具有可逆性。 当l=P时,更新变量HP。HP是通过逐层分解获得的视角间共有的特征表示矩阵,优化问题同样满足KKT条件,同时考虑到视角的互补性和差异性,在更新每个视角的最后一层时在式(5)的基础上加入视角权重获得共识表示矩阵。 多视图深度图正则化矩阵分解聚类算法的整体优化过程如下:{} 输入多视图数据X=X1,X2,···,Xv,参数λ,γ,各层维度 = [l1,l2,···,lP],最近邻居数k; 输出各层基础矩阵和特征矩阵以及视角间的共识表示矩阵HP。 1) 使用加入图正则化的Semi-NMF算法初始化每个视角各层的基础矩阵和特征矩阵;视角权重 αv=1/V;构建每个视角的全局图和局部图。 2)当v= 1:V时 3) 当l=P−1:1时,根据逐层分解的方式更新各层特征矩阵: 4)当l=1:P时 5) 当l 6) 当l=P时,使用式(9)更新HP。 7) 使用式(10)更新视角权重 αv。 8) 重复2)~7)直至收敛。 本实验中选择了5个数据集,包括3个面部基准数据集和2个图像数据集,面部数据集和图像数据集均具备良好的结构信息,能更显著的表现逐层分解中加入图正则化的效果。 Yale面部数据集由15个人在面部表情和配置信息不同的情况下产生的共165张GIF格式的灰度图像。每个人有11张图片,面部表情和配置信息包括表情、光照方向、情绪(快乐/悲伤)、有无眼镜等[3]。 Extend Yale B面部数据集由38个人在将近64个不同光照条件下所得的面部图像组成。在实验中,选择了640张,10个子集的面部图像进行测试。 UMIST面部数据集包括20个人的564张图像(混合种族、性别、外观)。每个人都以一系列的姿势显示,从侧面到正面,均已PGM的格式存在,大约220像素×220像素,256灰度,像素值用作特征表示[31]。 COIL-20(columbia university image library)图像数据集包含了20个对象物体,每个物体在水平上旋转360°,每隔5°拍摄一张照片,因此每个对象共72幅图,图片大小为64像素×64像素,总共1 440张图像。 Caltech101数据集是图像数据集,共包括了101种分类,每个分类包含了40张到800张不等的图片,大多数类别有50张图片。每一张图片的大小为300像素 × 200像素。我们选择了20个类别,共2 386张图像。 本实验中选择了9对比算法。 BestSC:在多视图数据的每个视角数据采用标准的谱聚类算法[32],记录最好的实验结果。 ConcateFea:将所有视角的特征结合起来,使用谱聚类算法获得实验结果。 ConcatePCA:将所有视角的特征结合起来,使用PCA将特征矩阵映射到低维子空间,使用谱聚类算法获得聚类结果。 Co-Reg SPC:通过共正则化聚类假设的方式使得数据点在不同视角中拥有相同的聚类成员关系[33]。 Co-Train SPC:基于潜在聚类为同一类别分配一个数据点,无关视角的假设,通过协同训练的方式获得视角之间一致的聚类[34]。 Min-Disagreement SPC:该算法以最小化不一致性为标准构建二分图,使用谱聚类算法进行聚类[35]。 DiMSC:在子空间聚类的背景下,使用希尔伯特施密特独立标准(HSIC)探索多视图数据的完整性信息[36]。 GMVNMF:将PVC算法[37]从双视图扩展到多视图聚类,同时加入视角图拉普拉斯规则化探索每个视角中数据分布的内部几何结构[38]。 DMF_MVC:将 deep semi-nmf model[19]应用于多视图数据,同时对最终获得的特征表示矩阵加入视角的图拉普拉斯矩阵进行微调[20]。 为更加全面的比较算法性能,本文中选择了6种不同的度量指标,包括标准化互信息(normalized mutual information, NMI),准确率 (accuracy,ACC),调整兰德指数 (adjusted rand index, AR),综合评价指标(f-score),精确率(precision),召回率(recall)。这些指标都是数值越大,性能越好。在实验中,每个算法都采用其原算法中最佳的参数设置并运行10次以上,最终结果以均值和标准差的方式呈现。 表1是本文算法与其他对比算法在Yale面部数据集上的实验结果。从实验结果可以看出,本文提出的算法相较于其他对比算法性能均良好,其中NMI和ACC两个指标提高了10%以上,其余指标均在15%以上。表2是算法在Extend Yale B面部数据集上的实验结果。在该数据集上,本文提出的算法在各项指标上均有所提高。将其与各项指标的最佳数值对比,在NMI上提高了4.4%,在ACC上提高了3.4%,在AR上提高了4.9%,在F-Measure上提高了5.2%,在精确率和召回率上各提高了2.1%和1.3%,均值保持在3.5%。表3是算法在面部数据集UMIST上的实验结果。从实验结果上看,本文提出的算法比其他算法拥有5个指标的提高,且均在2%~5%以上。在召回率上,本文算法性能并没有达到最好,但是总体来看,本文的算法性能更加稳定。表4是算法在图像数据集COIL-20上的实验结果。从表中可以看出,本文提出的算法较之其他算法表现良好。同时,各项指标的提高均值来看,本文算法与基于谱聚类的算法性能相近,尤其是BestSC算法,这就说明本文算法能够捕捉最佳视角信息并使用图规则化改善聚类性能。表5是各算法在Caltech101-20图像数据集上的性能表现。从数据中可以看出,Co-Train SPC算法因其协同训练的方式能够最大化视角间的标准化互信息。虽然在某些指标上,本文提出的算法并未达到最优,但是在其他指标上表现良好,且比协同训练的两种算法提高了10%以上。 表1 不同算法在Yale面部数据集上的实验结果(均值±标准差)Table 1 Experimental results of different algorithms on the Yale face dataset (mean ± standard deviation) 表2 不同算法在Extend Yale B面部数据集上的实验结果(均值±标准差)Table 2 Experimental results of different algorithms on the Extend Yale B face dataset (mean ± standard deviation) 表3 不同算法在UMIST面部数据集上的实验结果(均值±标准差)Table 3 Experimental results of different algorithms on the UMIST face dataset (mean ± standard deviation) 表4 不同算法在COIL-20数据集上的实验结果(均值±标准差)Table 4 Experimental results of different algorithms on the COIL-20 dataset (mean ± standard deviation) 表5 不同算法在Caltech101-20数据集上的实验结果(均值±标准差)Table 5 Experimental results of different algorithms on the Caltech101-20 dataset (mean ± standard deviation) 值得注意的是,本文的算法是基于矩阵分解的。在对比算法中,算法GMVNMF和DMF_MVC也是建立在矩阵分解之上的,且均加入了图正则化。从实验结果中可以看出,本文提出的算法在4个数据集上的表现比两种算法都好。其中,在Yale面部数据集上,本文算法相较于两种算法在各项指标上平均提高了43.1%和18.7%;在Extend Yale B面部数据集上分别平均提高了27.8%和6.6%;在UMIST面部数据集上,本文提出的算法在与算法GMVNMF进行比较时虽然在召回率上表现略低,但是在NMI上提高了9.3%,在ACC上提高了20.7%,在AR上提高了20.8%,在F-Measure上提高了18.5%,在精确率上提高了30%,均值仍能保持在14.5%,并且本文提出的算法在各项指标上表现更加稳定;在与算法DMF_MVC进行比较时,本文的算法在各项指标上分别提高了8.2%、11.8%、13.7%、12.9%、13.5%和16.3%,均值达在12.7%。在COIL-20图像数据集上则平均提高了30.6%和7.3%;在Caltech101-20图像数据集上平均提高了12.9%和11.2%。由此可见,本文算法使用的图正则化计算方式和逐层加入视角图正则化对于聚类有显著的改善效果。 4.3.1 参数分析 算法中包括了视角权重和图正则化使用的平衡参数γ、λ,深度矩阵分解的各层维度以及计算局部图和全局图使用的最近邻值k,两者结合计算图矩阵的平衡参数η,其中λ与η有计算关联性。考虑到数据中局部关系和全局关系的等价值性,实验中固定设置 η =1。参数,参数最近邻值k的选择在KNN算法中是一个开放性的问题,这里选择 {5 ,10,15}3个值进行测试。 图2和图3是在参数γ、λ和各层维度{[100 50],[150 50],[150 100]}影响下,算法生成的NMI和ACC的变化曲线。首先,从图2中可以看出,当γ变化时,NMI和ACC的各3条曲线变化幅度并不大,均控制在0.03以下,这就说明γ的变化对算法的性能影响不大。其次,从图3中NMI和ACC的变化曲线中可以看出,只有在分解维度为[150 100]时,参数λ的变化对于性能的影响才是最大的,同时,当λ=0.01时两项指标均达到最大且变化明显。最后从图2和图3中可以看出算法在分解维度为[100 50]时效果最好,且最为稳定;在分解维度为[150 100]时效果最差,同时曲线波动也最大。 图2 不同参数γ和各层维度下算法在Yale面部数据集上的性能变化(k=5,λ=0.01)Fig.2 Performance changes of the algorithm on the Yale face dataset under different parameters γ and each layer dimension (k=5,λ=0.01) 图3 不同参数λ和各层维度下算法在Yale面部数据集上的性能变化(k=5,γ=0.1)Fig.3 Performance changes of the algorithm on the Yale face dataset under different parameters λ and each layer dimension (k=5,γ=0.1) 图4是算法在参数γ和最近邻k两者影响下生成的NMI和ACC数值折线图。从图中可以看出,NMI和ACC在k=10时达到最大值,在k=15时值最小,同时k=10与k=5对算法的影响控制在0.03之内;再结合图2可以进一步看出,参数γ在取中的值时,效果能够达到最优。 图4 不同参数γ和最近邻k下算法在Yale面部数据集上的性能变化(λ=0.01,各层维度=[100 50])Fig.4 Performance changes of the algorithm on the Yale face dataset under different parameters γ and the nearest neighbors k (λ=0.01,各层维度=[100 50]) 4.3.2 收敛性分析 关于算法的收敛性问题,从理论上来说,定理1说明了算法模型在每个视角的特征表示矩阵和共识表示矩阵优化问题上均落在一个固定点上。如图5是在实验中,设定参数值γ=10,λ=0.01,k=10,各层维度=[100 50],优化问题 (4)与NMI随着迭代次数不断增加而产生的变化曲线。从图5中可以明确看出,随着迭代次数的增加,目标函数值逐渐降低,NMI增加并逐渐保持稳定。当迭代次数在1~15时,目标函数值下降迅速;当达到20次或保持在50~67次时,NMI一直稳定在最高值,之后逐渐保持稳定,且目标函数值下降缓慢。为保证实验数据的稳定性,实验中迭代次数设定为100次。 图5 迭代更新时算法的目标函数值和性能变化(γ=10,λ=0.01, k=10,各层维度=[100 50])Fig.5 The objective function value and performance change of the algorithm during iterative update(γ=10, λ=0.01, k=10, layer dimension=[100 50]) 4.3.3 聚类可视化分析 为更形象的展示本文算法聚类过程,我们可视化了聚类结果,如图6所示。我们选择了每个数据集中的3个类别,每个类中包含随机的10张图片。从图中可以看出每个类中均包含非本类别中的图片对象。从图6(a)中可以看出,每个类中包含少量的错误对象,证明了算法的高准确率,同样的效果也可以从图6(d)中看到。在Extend YaleB数据集的3个类别中,算法的准确率并没有达到最优,如图6(c)中所示,算法在第3个类别中存在一定的错误。在图像数据集中,算法在COIL-20数据集上的表现良好(图6(b)),每个类别从上到下的准确率可以达到90%,90%,80%。对于图像构成更为复杂的Caltech101-20数据集,算法的准确度还有一定的进步空间(图6(e))。 图6 算法在各数据集上的聚类可视化Fig.6 Cluster visualization of the algorithm on each dataset 4.3.4 复杂度分析 图7展示了所有算法在5个数据集上的运行时间变化。本文所使用的实验环境是Inter Core i7 8 500 8 GB内存,Matlab R2018a版本。为保证数据的稳定性,大多数算法均运行了10次以上。结合运行时间和实验数据集两个内容可以看出大多数算法的时间复杂度与数据点的量级有直接联系。数据点越多,算法中涉及的计算和处理所消耗的时间越多。在时间复杂度上,基于矩阵分解的算法所需要的时间复杂度为。同时,通过上述对算法收敛性的内容可以看出,基于矩阵分解的算法需要100次以上的迭代才能保持性能稳定,因此,基于矩阵分解的算法比其他大多数算法都需要消耗更长的时间。值得注意的是,相较于相近的DMF_MVC算法,本文提出的算法在时间复杂度上并没有明显的提高。这就说明本文的算法在保证性能提高的同时并没有增加时间消耗。 图7 各算法在数据集上的运行时间Fig.7 Running time of each algorithm on the dataset 本文中提出一种基于深度图正则化矩阵分解的多视图聚类算法,该算法使用深度非负矩阵分解模型并逐层加入图正则化限制,获取数据层次信息的同时保护数据的几何结构。权重的使用和共识表示矩阵的生成确保数据的一致性和差异性。实验数据表明,该算法在含有丰富几何结构的数据集上能够达到较高的准确率和稳定性。今后,需要加强对数据几何结构信息以及多视图数据表示学习的研究,提高多视图聚类的性能。
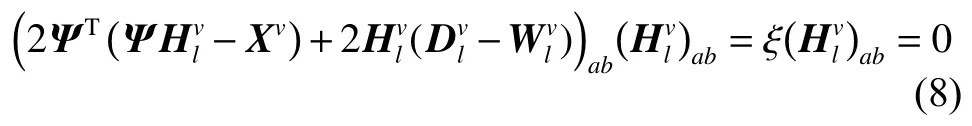

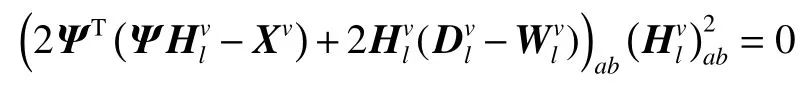
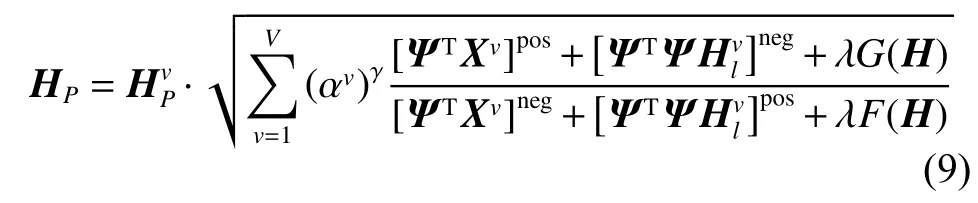
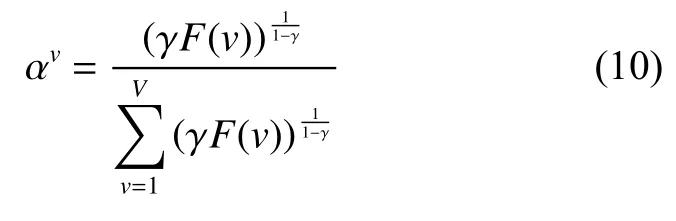
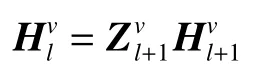
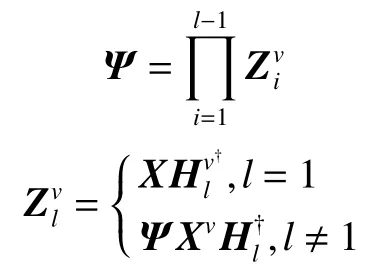
4 实验
4.1 实验设置
4.2 实验结果与分析


4.3 算法分析

5 结束语
猜你喜欢
贵州师范大学学报(自然科学版)(2022年5期)2022-11-18四川大学学报(自然科学版)(2021年6期)2021-12-27兰州理工大学学报(2021年3期)2021-07-05兰州理工大学学报(2021年3期)2021-07-05计算机应用(2020年12期)2020-12-31上海师范大学学报·自然科学版(2018年3期)2018-05-14非公有制企业党建(2017年10期)2017-11-03现代兵器(2017年4期)2017-06-02现代兵器(2017年4期)2017-06-02电脑知识与技术(2016年13期)2016-06-29
