
一种基于最大最小策略和非均匀变异的萤火虫算法
2022-02-18 08:12赵嘉陈丹丹肖人彬樊棠怀
智能系统学报 2022年1期
赵嘉,陈丹丹,肖人彬,樊棠怀
(1.南昌工程学院 信息工程学院, 江西 南昌 330099; 2.华中科技大学 人工智能与自动化学院, 湖北 武汉430074)
现实生活中许多优化问题涉及多个相互制约且相互冲突的目标,这类问题称为多目标优化问题(multi-objective optimization problem, MOP)[1]。解决MOP的难点在于改进其中一个目标必然会导致另一个或多个剩余目标的退化,因此针对MOP求解并不能同单目标优化问题一样找到一个唯一的最优解使得各个目标同时取得最优值,而是通过各个目标函数的相互协调,得到一组权衡最优解,即Pareto最优解集[2]。为尽可能的趋近于真实的Pareto最优解集,通常采用多目标进化算法(multi-objective evolutionary algorithms,MOEA)[3]求解 MOP。
近30年来,MOEA研究成果丰富,种类繁多,主要包括基于Pareto支配关系的MOEA、基于精英保留机制的MOEA、基于分解的MOEA、基于指标的MOEA、混合机制的MOEA以及新型进化机制的MOEA,不同种类的MOEA表现出不同的优劣势与差异性。基于Pareto支配关系的MOEA原理简单,参数少,易于理解,代表算法有非支配排序遗传算法(nondominated sorting genetic algorithm, NSGA)[4]及其改进版本NSGA-II[5]、NSGAIII[6]和多目标遗传算法(multi-objective genetic algorithm, MOGA)[7]等。基于精英保留机制的MOEA通过建立外部档案(external archive, EA)[8]来存储精英解以增加解群的多样性从而获得优良的Pareto前沿,代表算法有强度Pareto进化算法(strength pareto evolutionary algorithm, SPEA)[9]及其改进版本SPEA2[10]、Pareto存档进化策略算法(pareto archived evolution strategy, PAES)[8]及其改进版本PESA和PESA-II[11]等。基于分解的MOEA将MOP转化为一组单目标优化问题,在此基础上进行子问题邻域信息协同求解,代表算法有基于分解的多目标进化算法(multi-objective evolutionary algorithm based on decomposition, MOEA/D)[12]以及在此基础上改进的基于多层交互偏好的多目标分解进化算法(multi-layer interaction preference based multi-objective evolutionary algorithm through decomposition, MLIP-MOEA/D)[13]等。基于指标的MOEA运用性能评价指标来引导搜索及对解进行选择,使算法能够找到针对评价指标好的解,代表算法有多目标搜索中基于指标的选择算法(indicator-based selection in multi-objective search,IBEA)[14]和基于超体积的多目标快速优化算法(algorithm for fast hypervolume-based many-objective optimization, HypE)[15]等。混合机制的MOEA通过结合每个MOEA和元启发式算法的优点以克服单个MOEA或元启发式算法的固有局限性,从而进一步提高解空间搜索的有效性,代表算法有超多目标进化算法(hyper multi-objective evolutionary algorithm, HMOEA)[16]和自适应多种群混合进化算法(hybrid evolutionary algorithm with adaptive multi-population strategy, HMOEAAMP)[17]等。近年来,基于新型进化机制的MOEA在多目标优化领域崭露头角,如多目标粒子群算法(multi-objective particle swarm optimization,MOPSO)[18],多目标灰狼算法(multi-objective grey wolf optimizer, MOGWO)[19]等,这类算法通过引入元启发式算法和新型进化机制来求解多目标优化问题,提供了研究MOP的新思路,在多目标优化领域广受关注。
Yang[20]通过对萤火虫种群行为的模拟和简化,提出了萤火虫算法(firefly algorithm, FA)。FA与其他进化算法相比,前者在概念、过程、涉及的参数和适用性方面具有优势[21-22],鉴于FA的种群搜索特性以及良好的优化性能,Yang[23]将其应用于求解多目标优化问题,提出了多目标萤火虫算法(multi-objective firefly algorithm, MOFA)。MOFA改进了FA中的移动公式,使公式的随机项随迭代次数呈非线性递减,并采用权重比策略确定当前最好解,但萤火虫的移动仅受制于支配解或者当前最好解,算法的搜索范围具有局限性,勘探能力有待增强,导致MOFA易早熟且收敛性能差。
为了提升MOFA的勘探能力,增强算法的优化性能,Tsai等[24]提出了一种基于非支配排序的多目标萤火虫算法(non-dominated sorting firefly algorithm for multi-objective optimization, MONSFA),MONSFA中提供了两种随机搜索策略供萤火虫选择移动,通过随机改变萤火虫的搜索方向来提高算法的勘探能力,同时运用NSGA-II的非支配排序和拥挤距离策略实现种群再生和档案维护以提高算法的全局搜索能力。谢承旺等[25]提出了一种多策略协同的多目标萤火虫算法(multi-objective firefly algorithm based on multiply cooperative strategies, MOFA-MCS),该算法改进了MOFA的学习公式,通过随机选取档案精英解作为引导者指引粒子学习来间接阻止种群向局部区域靠拢,拓宽种群的搜索范围以达到提升算法勘探能力的目的。LYU等[26]提出了一种基于补偿因子与精英学习的多目标萤火虫算法(multi-objective firefly algorithm based on compensation factor and elite learning, CFMOFA),CFMOFA中通过精英学习来扩大萤火虫的探测范围,以此来提高Pareto最优解集的多样性和准确性。
上述提到的各改进算法在一定程度上均提升了算法的勘探能力,但大都是对算法的局部进行改进,算法的整体性能并未取得大的突破,且学习策略单一,具有一定的局限性,一方面,萤火虫移动的方向过于片面,种群的勘探能力有待进一步提高,解集覆盖域不够广泛;另一方面,算法的寻优性能差,难以收敛到真实的Pareto最优解。基于此,为提升算法的勘探能力,增强算法的全局搜索能力,本文提出了一种基于最大最小策略和非均匀变异的萤火虫算法(heterogeneous variation firefly algorithm with maximin strategy, HVFAM)。HVFA-M具有如下特点:1)引入Maximin策略[27],一方面用于维护档案群体的多样性,以获得分布性较好的解集,另一方面用于从外部档案中随机挑选精英解,参与种群进化;2)精英解[19]配合当前最好解引导萤火虫移动,以扩大种群的搜索范围,增大Pareto最优解所在区域被探测到的可能性,使得解集覆盖域更广,有利于提高解集分布的广泛性;3)萤火虫位置更新后进行非均匀变异[28],促使算法进行局部搜索,在提高算法全局探索能力的同时兼顾算法的局部开采能力,有利于收敛到真实的Pareto最优解。以上3种策略分工明确,协同实施,作用于HVFA-M的不同阶段,显著增强了算法的勘探能力和寻优能力,提高了多目标萤火虫算法的收敛性及多样性。
1 基础知识
1.1 多目标优化问题
以最小化问题为例,MOP的数学模型通常可以描述为以下形式:

式中:x表示决策向量;n为决策向量的维数;X是n维决策空间;y表示目标向量;m为目标函数的个数;Y是m维目标空间。对于任意两个决策向量xi,xj∈X,当且仅当成立时,称xiPareto支配xj,记为xi≺xj。若 ¬ ∃x∈X,使得x≺x∗成立,则称x∗为非支配解个体,种群中所有非支配解个体组成的集合称为Pareto最优解集(pareto-optimal set, PS),其在目标空间的投影称为Pareto最优前沿(pareto-optimal front, PF)。
1.2 多目标萤火虫算法
萤火虫算法中,亮度和吸引力是两个关键要素。亮度表征了萤火虫所处位置的优劣,吸引力决定了萤火虫移动的方向,所有萤火虫根据位置更新公式移动到新的位置后,更新自身亮度,并根据吸引规则进行下一次移动。通常将萤火虫xi的绝对亮度I(xi)表示为I(xi)⇔f(xi),即用萤火虫xi所在位置解的目标函数值表征xi的绝对亮度。吸引力 β是一个相对参数,取决于每一只萤火虫所处的相对位置,根据萤火虫之间的吸引力与它们的亮度成正比,而与它们的距离成反比的特性[22],萤火虫j对萤火虫i的吸引力可定义为

式中: β0为最大吸引力,即在光源处rij=0萤火虫的吸引力(通常取值为1);γ为光吸收系数,用来体现光强随距离增加和传播媒质的吸收而逐渐减弱的特性,从而描述出吸引力的变化,一般取γ ∈[0.01,100];rij为萤火虫i到萤火虫j之间的空间距离,一般采用欧氏距离计算,但不仅仅局限于欧氏距离。
对于任意给定的两只萤火虫,萤火虫i被萤火虫j吸引并朝着j所在的方向移动,其位置更新公式为

式中:第2部分是学习部分,取决于吸引力的大小;第3部分是随机部分,是带有特定系数的随机项。其中t为算法的迭代次数,xi(t)和xj(t)分别为算法在第t次迭代时,萤火虫i和萤火虫j的空间位置;α为步长因子,取值为 [0 ,1]内均匀分布的随机数,εi为服从均匀分布、高斯分布或者其他分布得到的随机数向量。
多目标萤火虫算法中,根据Pareto 支配的定义确定任意两只萤火虫之间是否存在吸引关系,以萤火虫i作为研究对象,若萤火虫j≺i,i被j吸引,并按照式(3)朝着萤火虫j所在的位置和方向移动。若萤火虫i不被其他任何萤火虫支配,则根据式(4)进行位置更新[21]:

其中,g∗表示当前最好解,α和 εi的含义同式(3),其取值可参考文献[23]。g∗是由式(5)将多目标函数以随机加权和的方式转换成一个组合的单目标函数而取得的最优值,若求取的是最小化问题,则g∗是令单目标函数最小化得到的针对给定的多目标优化问题的当前最小解。

式中:K表示目标函数的个数;wk∈(0,1),权重wk应该在每次迭代中随机选择,以便非支配解沿着帕累托前沿进行不同的采样。
1.3 Maximin 策略
Maximin策略起源于游戏理论,由Balling[29]首次将其应用于求解多目标优化问题,并得出其在不使用其他多样性维护机制的条件下可以实现非劣解前沿均匀分布的目标。Maximin策略中,运用Maximin适应值函数计算出每只萤火虫的Maximin适应值,借助Maximin适应值的大小区分每只萤火虫的优劣,萤火虫 的Maximin适应值函数定义为

式中:l=1,2,···,m,m为目标函数的个数;npop为种群大小。首先计算出萤火虫i与其他萤火虫对应不同目标函数上的差值,从中选取最小值 m in(xi),再从i与其他所有萤火虫计算所得的所有min(xi)中选取最大值 m ax(min(xi))作为i的Maximin适应值。显然,非劣解的Maximin适应值均小于零,即在解群中根据Maximin适应值的正负便可辨别非劣解,同时,Maximin策略可用于“奖励”分散的非劣解和“惩罚”聚集的非劣解[27],即分散解的Maximin适应值更小,聚集解的Maximin适应值较大。Maximin策略凭借这两个独特的性质成为求解MOP的一个有效工具,一方面,区分了非劣解的优劣;另一方面,根据这一区分可以保留种群中Maximin适应值小且分散的解,保证了解集之间分布的均匀性。
标准的Maximin策略计算不在同一数量级的目标值时,得到的Maximin适应值具有偏向性,其次,支配解的存在会影响非支配解的Maximin适应值。针对Maximin策略存在的缺陷,徐鸣等[30]提出应先对所有目标值进行规范化处理,Gong等[31]提出应仅计算非劣解的Maximin适应值,此外,贾树晋等[27]提出为了获得广泛的Pareto最优端,应令边界解的Maximin适应值最小以避免其丢失。因此在本文算法中运用改进的Maximin策略[27],定义为
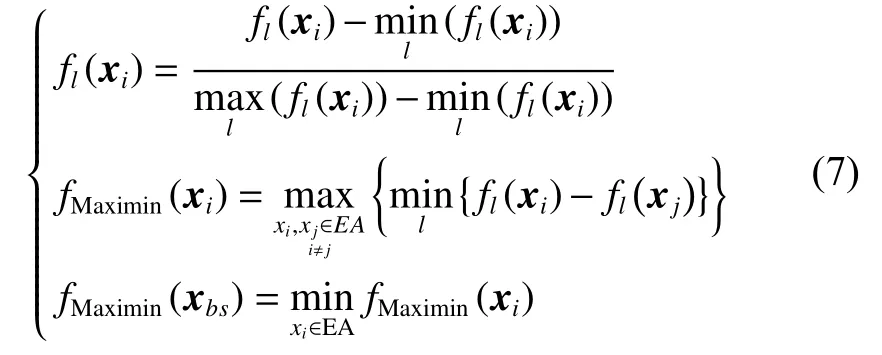
式中:l=1,2,···,m;fl(xi)指萤火虫i进行规范化后第l维目标值;xbs表示非支配解集的边界解。
2 HVFA-M算法
2.1 Maximin策略维护种群多样性和选取精英解
MOEA 通常采用设置一定大小的外部档案来储存算法在迭代过程中产生的非劣解,为避免资源赘余,引入 Maximin 策略[27]。Maximin 策略作为一种多样性维护策略,常用于多目标优化算法中维护种群的多样性,本文算法中,Maximin策略不仅作为外部档案更新策略,还作为精英选择策略,一方面用以维持解群的多样性,另一方面用以区分精英解之间的优劣信息,便于选择较优的精英解参与种群进化。当外部档案EA 中非劣解的数量超过算法限制的最大容量时,运用Maximin策略删除多余的非劣解。具体步骤为:
1) 根据式(7) 计算EA 中每个非劣解的Maximin 适应值;
2) 将EA 中所有的非劣解按照Maximin 适应值进行升序排序;
3) 删除Maximin 适应值最大的解,重复此步骤,直到档案中的容量达到其限定值。
2.2 学习策略的改进
从式(3)、(4) 可以看出,标准MOFA中被支配的萤火虫仅仅受到支配它的萤火虫和随机项的影响,不受任何支配的萤火虫仅仅受到当前最好解和随机项的影响,而存储在外部档案中的非劣解,也就是精英解,也没有得到充分的利用,这导致种群进化缓慢,使得算法的勘探能力弱,不利于解集逼近并广泛完整的表达真实的Pareto前沿。基于外部档案中的精英解携带了优良的种群信息,可以指导种群进化,本文对学习公式进行了改进,引入精英解结合当前最好解共同引导萤火虫移动,合理的继承了解群中的优良基因,扩大了算法的搜索范围,有利于算法获得位置更为优异,分布更为均匀,覆盖范围更为广泛的Pareto最优解集。改进如下:
1) 当萤火虫i被j支配时,萤火虫i的位置更新公式为

2) 当萤火虫i不被其他任何萤火虫支配时,萤火虫i的位置更新公式为

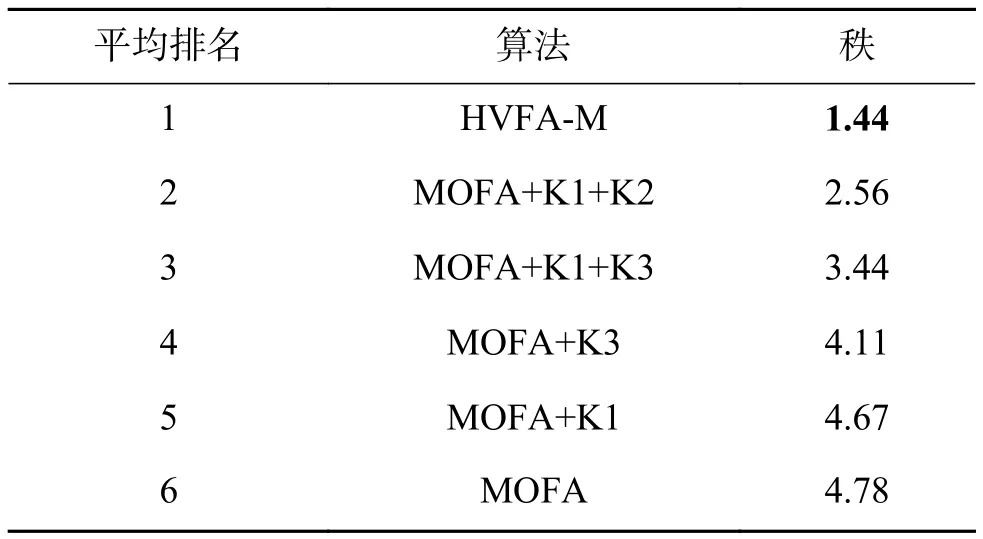
以存在支配关系的萤火虫的位置更新公式为例,求解二目标最小化问题,给出MOFA和HVFA-M两种算法搜索范围的简化模型,如图1所示。图1中,黑色曲线为Pareto最优前沿,红色五角星代表外部档案中的精英解,红色圆点代表当前最好解g∗,黑色圆点表示萤火虫,橙色圆圈为萤火虫的搜索范围。MOFA中,若萤火虫j 图1 MOFA与HVFA-M搜索范围的差异性Fig.1 Differences in search scope between MOFA and HVFA-M 萤火虫算法收敛速度较快,导致多目标萤火虫算法后期在寻优过程中易陷入早熟收敛,很难收敛于真实的Pareto 前沿,通常通过引入变异算子解决这一问题。非均匀变异算子[28]作为一种动态变异算子,在初始阶段能够均匀的搜索空间,具备一定的全局搜索能力;在后期则具备一定的局部搜索能力,有利于寻找到更好的非支配解,进一步提高解的质量。基于此,引入非均匀变异算子,每一代萤火虫i进行位置更新后,按照一种随迭代次数动态递减的变异概率pm随机对i的向量进行扰动,这里若选中的是第k维分量(1 ≤k≤n,n为向量的维数),变异操作可定义为[26] 式中:uk和lk分别为向量取值范围的最大值与最小值;γ随机的取0或1;t为当前迭代次数;Gmax为最大迭代次数;r为 [0 ,1]内的随机数;b为系统参数,决定了随机数扰动对迭代次数t的依赖程度,取值一般为2到5,本文中取b=3。算法前期,t较小,该算子均匀的搜索空间,充分发挥萤火虫算法的全局搜索能力;算法后期,随着t增大,该算子的搜索变得局部化,使得变异后产生的新解以更大的概率逼近真实的Pareto 最优解,如图2所示。非均匀变异算子的引入平衡了算法全局搜索和局部开采的能力,进一步提高了算法的寻优能力,有效增强了算法的收敛性。 图2 非均匀变异算子下萤火虫的局部搜索Fig.2 Local search of firefly under heterogeneous variation 结合Maximin 策略、学习公式改进及非均匀变异机制3种策略,给出HVFA-M 的算法流程,如算法1所示。 算法1基于最大最小策略和非均匀变异的萤火虫算法 输入决策向量的维数n,决策变量的区间范围 [a,b],种群规模npop,外部档案容量nrep,最大迭代次数Gmax,光吸收系数 γ,最大吸引度 β0,以及初始步长α。 输出Pareto最优解集 1)萤火虫种群初始化。产生规模为npop的初始群体,nrep=0,迭代次数t= 0。 2)计算萤火虫在每一个目标函数上的适应值,并根据Pareto关系进行评价,将非支配解复制到nrep中。 3)根据式(7)计算所有非支配萤火虫的Maximin适应值。 4) 当t 5) 对萤火虫进行遍历,重复6)~8)。 6) 萤火虫i与萤火虫j进行比较,重复7)~8)。 7)萤火虫之间进行相互学习。若萤火虫j 8)非均匀变异。对位置更新后的萤火虫进行变异,若变异后的萤火虫优于变异前的萤火虫,则将该位置替换为变异后的萤火虫,否则不做任何操作。 9)更新所有非支配萤火虫的Maximin适应值。 10)外部档案更新与维护。若外部档案中非支配解的数量超出其最大容量nrep,按照Maximin适应值的大小对档案中的所有非支配解进行排序,通过删去Maximin适应值最大的解来实现外部档案动态调整的目的,直到满足条件为止 11)t=t+1 由于萤火虫算法采用全吸引模型,MOFA算法采用两层循环遍历所有萤火虫,故其时间复杂度为O(N2)。HVFA-M算法在MOFA的基础上,添加了Maximin策略,在求解Maximin适应值时,新增两个循环,第一个循环遍历所有目标m,第二个循环遍历了所有萤火虫,故其时间复杂度为O(N2)+O(mN)。由于求解的目标个数较种群规模少(m 为评估HVFA-M的性能,本文使用9个经典的MOP对HVFA-M进行性能测试[32-34],这9个多目标测试函数由5个2-目标函数和4个3-目标函数组成。其定义及特征如表1、2所示。 表1 2-目标测试函数集Table 1 2-objective test function 表2 3-目标测试函数集Table 2 3-objective test function 为验证HVFA-M的性能,将HVFA-M 与MOPSO[18],NSGA-III[6],MOEA/D[12],PESA-II[11]及MOFA[23]5种经典多目标优化算法进行比较,所有对比算法的参数设置均取自于相应文献,如表3所示。为分别验证HVFA-M 的收敛性和Pareto最优解集的广泛性,采用generation distance(GD)[35]、maximum spread(MS)[36]性能评价指标量化算法获得的Pareto 最优前沿的收敛性和广泛性,其中GD反映了算法所得的近似Pareto 前沿对真实Pareto前沿的逼近程度,GD值越小,表示算法收敛性越好;MS 反映出算法所得的Pareto 最优前沿在目标空间中分布的广泛程度,MS值越大,表示解集的广泛性越好。为评价HVFA-M的综合性能,即避免算法收敛性差而导致的更广泛的分布的影响,采用inverted generation distance(IGD)[37]评价指标来判断算法的优劣,IGD指标可同时评价算法的收敛性和多样性,IGD值越小,算法的综合性能越好。为保证所有算法比较的公平性,所有算法的最大迭代次数设置为300,种群大小设置为50,外部档案EA 的[大小设置]为200;为减少随机因素的干扰,所有算法在每个测试函数上均独立运行30次,评价指标数据为算法独立运行30次的平均值。 表3 各算法参数设置Table 3 Parameter setting of each algorithm 表4~6给出了HVFA-M 与其他5种经典算法在9个测试函数上的GD 、MS、IGD 的均值和标准差,表格中加粗数据表示不同算法在同一测试函数上取得的最优值。 表4 HVFA-M与5种经典算法在GD上的实验结果Table 4 Experimental results of HVFA-M and five classical algorithms on GD 续表4 根据表4,单方面考虑算法的收敛性看,HVFA-M在9个测试函数上有5次取得最优,相对于其他5种对比算法获得的最优值的次数最多,尤其对于测试函数ZDT1—ZDT4,在收敛性上的优势更为突出,充分体现出其勘探能力强,收敛性能好的优点。根据表5,从算法求取的Pareto 最优解集的广泛性角度分析,HVFA-M 在9个测试函数上有4次取得最优值,且在剩余的5个测试函数上的取值与最优值相差不大,充分凸显出其搜索范围广、覆盖面积大的特点。根据表6,综合来看,HVFA-M 在9个测试函数上有4次取得最优,且在ZDT6、Viennet1问题上,HVFA-M 与最优值之间具有相同的数量级,表明二者之间差异性小,充分说明HVFA-M 在收敛性和多样性方面具有较强的优势。 表5 HVFA-M与5种经典算法在MS上的实验结果Table 5 Experimental results of HVFA-M and five classical algorithms on MS 表6 HVFA-M与5种经典算法在IGD上的实验结果Table 6 Experimental results of HVFA-M and five classical algorithms on IGD 表7给出了各种算法在3种评价指标上分别取得最优值的数目。表8采用Friedman检验给出6种对比算法在3种性能评价指标上的平均排名。 从表7给出的各算法优势解的总数统计来看,HVFA-M 在3种评价指标上共有13次取得了最优值,排名第一,远胜于其他5种对比算法,PESA-II次之,共取得5次最优,最差的是MOFA,无一次取得最优。综合来看,HVFA-M相对于其他5种对等比较算法表现出显著的性能优势。 从表8可以看出,HVFA-M 在GD、MS、IGD上的名次均是最好的,在GD上随后依次是NSGA-III、PESA-II 、MOFA、和 MOPSO,最差的是MOEA/D;在MS上随后依次是MOPSO、PESA-II 、MOFA和MOEA/D,最差的是NSGA-III;在IGD上随后依次是 PESA-II、MOPSO、NSGA-III和 MOFA,最差的是MOEA/D。Friedman检验结果表明HVFAM较其他5种对比算法求解的精确度更高、覆盖率更广、综合性能显著。 为更加直观的展现HVFA-M 的优势,图3列出了HVFA-M 与5种经典算法在9种测试函数上的Pareto前沿拟合曲线图,其中黑线表示真实的Pareto前沿,红色圆圈表示算法所得的Pareto前沿。该曲线图清晰的呈现出各个算法在各个测试问题上求取的Pareto 前沿与真实Pareto 前沿的拟合情况,与表4~8给出的实验结果保持一致,均表明HVFA-M 较其他5种算法具有最优的GD、 MS和IGD 性能,即具有较好的收敛性和多样性。 图3 HVFA-M与5种经典算法的Pareto前沿拟合曲线Fig.3 Fitting of Fareto fronts of HVFA-M and five classical algorithms 为进一步验证HVFA-M 的有效性,本部分将HVFA-M 与6种新近的多目标优化算法 SMSEMOA[38]、 TVMOPSO[39]、DMSPSO[40]、 NSLS[41]、MOEA/IGD-NS[42]以及 CFMOFA[26]进行比较,所有对比算法的参数设置均取自于相应文献,如表9所示。这里选取6个基准MOP 测试问题组成的测试集合,包括5个2-目标的ZDT 系列函数ZDT1、ZDT2、ZDT3、ZDT4和 ZDT6,以及 1个 3-目标的DTLZ 系列函数DTLZ4,并利用IGD评价指标来判断算法的优劣。实验中,为了确保公平性,EA最大设为100,除SMSEMOA、TVMOPSO 以及DMSPSO 算法的评估次数维持其实验原始设计外,其他所有算法的2-目标测试问题的最大迭代次数设置为250,3-目标测试问题的最大迭代次数设置为500;为平衡随机性,算法独立运行30次,结果取其平均值,实验结果由表10 给出,其中加粗数据表示不同算法在同一测试函数上获得的最优值。 表9 各算法参数设置Table 9 Parameter setting of each algorithm 根据表10, HVFA-M在6个测试函数上取得了3次最优的IGD均值,TVMOPSO、MOEA/IGDNS、CFMOFA仅仅各取得一次最优,SMSEMOA、DMSPSO、NSLS在6个测试函数上均无一次能获得最优的IGD均值。表11采用Friedman检验给出了HVFA-M与6种新近算法基于IGD指标的平均排名,可以看出,HVFA-M排名第一,MOEA/IGD-NS次之,随后依次是CFMOFA、TVMOPO、SMSE-MOA、NSLS,最差的是DMSPSO,Friedman检验的结果与表10中的IGD均值结果保持一致。综合来看,HVFA-M较其他6种对比算法具有更强IGD性能,即表现出更强的收敛性与多样性。 表10 HVFA-M与6种新近算法的IGD实验结果Table 10 Experimental results of HVFA-M and six recent algorithms on IGD 表11 各算法在IGD上基于Friedman检验的平均排名Table 11 Average ranking of each algorithm based on Friedman test on IGD 经过两次实验比较可知,HVFA-M 是一种可行且有效的多目标优化算法,表现出很强的收敛性及多样性。究其原因:首先,运用Maximin策略一方面有效维护了解群的多样性,另一方面用于选择精英解参与种群进化;其次,档案精英解结合当前最好解指导萤火虫移动,有利于提升算法的勘探能力,扩大种群搜索范围,增强算法的收敛性和广泛性;最后,引入非均匀变异算子平衡算法全局与局部搜索的能力,促进种群全局勘探的同时兼顾种群局部开发,进一步提高种群的寻优能力,促进算法收敛。以上3种策略分工合作,相互结合,共同提高了HVFA-M收敛性、多样性的综合性能。 本文提出的HVFA-M是MOFA与多种策略的融合,它将MOFA与3种策略融合在一起:Maximin多样性维护策略(K1)、改进学习策略(K2)和非均匀变异机制(K3)。为了分析3种改进策略对算法性能产生的影响,将MOFA与每种策略融合进行测试。选取表1、2中的9个典型的多目标测试函数进行数值实验,所涉及的算法描述如下。 MOFA:标准MOFA不添加任何策略。 MOFA+K1:添加Maximin多样性维护策略的MOFA。 MOFA+K1+K2: 添加Maximin多样性维护策略和改进学习策略的MOFA。 MOFA+K3:添加非均匀变异机制的MOFA。 MOFA+K1+K3:添加Maximin多样性维护策略和非均匀变异机制的MOFA. HVFA-M: K1、K2、K3的 3种策略融合的MOFA。 需要指出的是,由于策略K2是在添加策略K1的基础上实现,因此无法单独给出MOFA添加策略K2的实验结果。表12给出了添加不同策略的MOFA9个测试问题上获得的IGD均值和方差,算法的参数设置与3.2节相同,其中加粗数据为最好的测试结果。 表12 算法策略分析的IGD实验结果Table 12 Experimental results of algorithm strategy analysis on IGD 续表12 根据表12可以看出,仅添加Maximin多样性维护策略和仅添加非均匀变异机制对改进MOFA的帮助有限,而在Maximin策略的基础上添加改进学习策略或非均匀变异机制均能有效改善算法的性能,特别是MOFA在Maximin多样性维护策略的基础上,添加通过Maximin适应值筛选出精英解来引导学习的改进学习公式策略,对算法的帮助更大。对于DTLZ7测试函数,由于其具有离散、混合和多模态的组合特征,使得3种策略均不适用于求解此类问题。从算法获得的最优值的数目上看,MOFA融合3种策略改进的HVFA-M,能够显著提高Pareto最优解集的质量。表13给出了 HVFA-M与对比算法基于IGD指标的Friedman检验结果,可以看出,HVFA-M排名第一,其次是 MOFA+K1+K2、MOFA+K1+K3、MOFA+K3、MOFA+K1,最差的是MOFA。综合来看,MOFA通过结合3种策略,获得了更好的优化性能。 表13 算法策略分析的IGD平均排名Table 13 Average ranking of algorithm strategy analysis on IGD 多目标萤火虫算法的勘探能力弱,求解精度差,本文针对这一问题,提出了一种新的多目标优化方法−基于最大最小策略和非均匀变异的萤火虫算法(HVFA-M)。首先,Maximin策略用作外部档案的动态调整以保证目标空间中非劣解的良好覆盖从而确保精英解参与种群进化;其次,档案精英解配合当前最好解引导萤火虫移动,使得萤火虫移动的方向更全面,以提高算法的勘探能力从而增大解群寻找最优解的概率;最后非均匀变异算子的引入使得算法融入了一定的局部搜索思想,以提高解的寻优能力从而进一步加快算法收敛。在多目标领域广泛使用的几个基准测试函数上,将HVFA-M 与几种经典及新近算法进行比较研究,数值结果和图形结果清晰地表明,本文所提出的HVFA-M 具有很强的竞争力,是解决多目标优化问题的一种可行且有效的选择。本文的研究重点是小规模多目标优化问题,下一步,将验证HVFA-M 在大规模多目标测试问题上的性能,并运用HVFA-M 求解工程实践中的多目标优化问题。
2.3 非均匀变异机制


2.4 算法流程
2.5 算法时间复杂度分析
3 实验与结果
3.1 测试函数


3.2 与经典多目标优化算法进行比较







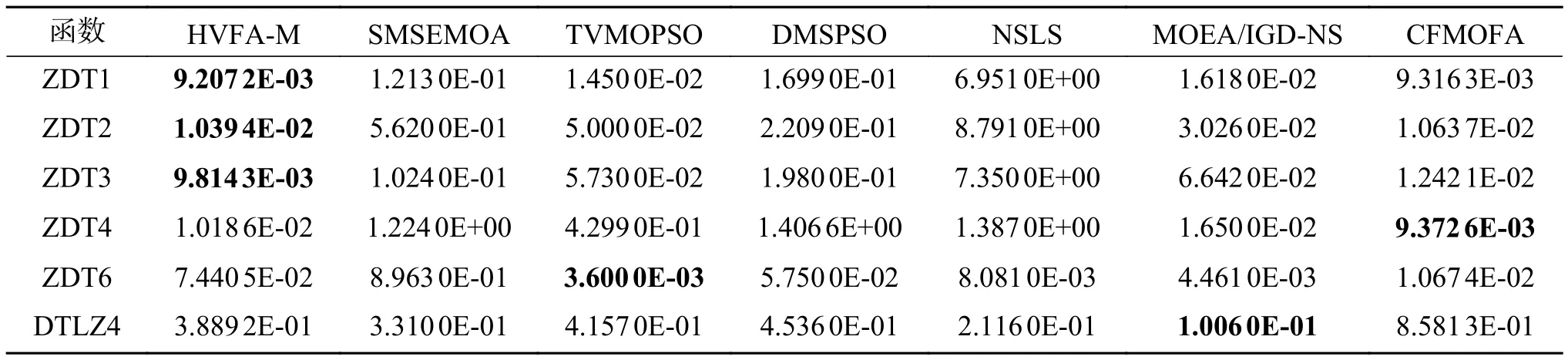
3.3 与新近的多目标优化算法比较


3.4 3种改进策略的有效性分析


4 结论
猜你喜欢
太原科技大学学报(2022年1期)2022-02-24计算机仿真(2021年1期)2021-11-18意林(2021年9期)2021-05-28东北大学学报(自然科学版)(2020年1期)2020-02-15时代风采(2019年3期)2019-03-23时代英语·高一(2019年1期)2019-03-13小天使·一年级语数英综合(2018年7期)2018-09-12小天使·一年级语数英综合(2017年6期)2017-06-07物联网技术(2017年5期)2017-06-03Coco薇(2016年8期)2016-10-09
