
贵州省级大数据政策量化评价研究
2022-02-18 13:37沈俊鑫何承洪王晓萍
重庆理工大学学报(社会科学) 2022年1期
沈俊鑫,何承洪,王晓萍
(昆明理工大学 a.管理与经济学院; b.创新发展研究院, 云南 昆明 650093)
一、引言
大数据产业已成为贵州经济新的增长点,许多国家纷纷将大数据产业发展上升为国家战略。产业的发展离不开政策环境的支撑,我国非常重视大数据产业的发展。从2014年政府工作报告出现“大数据”起,各界都积极关注。2015年,国务院发布我国发展大数据的首部战略性指导文件;2017年,党的十九大报告再次为大数据产业未来发展指明了新的方向,推动实体经济和大数据产业融合发展。作为首个国家大数据综合试验区的贵州省,率先发布了省大数据产业发展应用规划纲要等系列措施,积极促进大数据产业发展。2016年,贵州省政府明确提出强力推进大数据战略行动,为加快推进全省大数据发展提供了新动能,2019年,全省大数据产业发展指数位居全国第三。
二、文献研究综述
(一)政策评价研究
政策评价是运用科学准则和方法,建立评价标准,对政策体系和过程进行全方位考察,并对其进行衡量和总结的复杂系统工程[1],目的是为下一步政策制定和完善提供决策依据,其评价的形式和结果会受到评价过程等因素影响。可见,选择合理的评价方法是确保评价结果具有可参考价值的重要因素[2]。目前,国内学者对政策评价的研究更注重研究方法的使用,国外学者则关注政策评估模型的建立[3]。如Poland创新性提出的三E评价架构[4]和Suchman提出的5类评估模型[5]都是较为经典的政策评价方法;Nola为评价政策的执行效果设计了一个政策评价逻辑模型[6];Xie等通过BP神经网络构建出基于深度学习的政策评价模型[7];常飞等通过脉冲响应研究发现货币政策的调控能够影响房地产价格一定时期的预期走势[8];施巍巍等研究发现政策在演进过程中,国家的角色是从扩大到收缩再到强化的发展过程[9];现在国内外很多政策评价方法都存在精确度不高、客观性不强等不足,如模糊综合评价法的变量设置主观性较强[10-11]。
(二)大数据政策评价研究
随着大数据产业的蓬勃发展,针对大数据的相关研究已成为广泛关注的热点,各类大数据政策相继发布,大数据政策体系日渐复杂化,而大数据政策的制定水平和实施效果仍存在突出问题,因此如何对已有政策进行客观科学的评价,从而为新一轮政策的制定提供具体可操作的决策依据,如何实现制定的大数据政策协调引领产业发展是政策制定者的关注焦点[12]。当前,相关文献对大数据政策研究的方法基本可以归为以下三类,涉及文本挖掘和PMC指数模型等。
1.定性研究
王能强提出大数据政策要加强标准体系等制定[13];张宁等认为政策要不断完善内容,并提出了改进建议[14];孙志煜等认为,各级政府对于大数据的政策内容,要不断细化和归纳[15]。
2.定量研究
刘亚亚等对我国94项大数据相关政策文本进行研究,其结论指出我国大数据政策体系协同性不强,大数据系统不够完善,各级政府需要加强对我国大数据政策制定的完善[16]。在大数据政策的完善方面,周京艳等研究指出,增加对政策工具的使用,可以有效地填补当前大数据政策的不足[17]。
3.定量定性结合研究
季飞等利用Nvivo11软件对贵阳市发展大数据产业的42份文件研究发现,政策中政策工具对产业的发展发挥了很好的促进作用[18]。胡峰等基于Herring模型从情报过程视角对我国11项国家级大数据政策量化评价,指出每项政策的优劣并提出参考性政策改进路径[19]。周海炜等通过构建PMC指数模型对我国国家级、省市级和地方级8项大数据政策量化评价,并提出了合理优化路径[12]。
综合以上政策评价研究的文献可以得知:一是大部分政策评价方法存在不可避免的主观性和较低的精确度;二是大数据政策评价中大部分学者是对政策效果进行评价,对某一项具体的大数据政策优劣评价较为缺乏;三是部分学者对大数据政策本身评价时,样本范围较为宽泛,对基础条件不一样的区域大数据政策完善不具有针对性的参考价值;四是在研究方法上定量研究的成果较少;五是政策评价指标的设置上多元性不足,难以从宏观和微观上同时把控政策具体水平。
因此,本文拟以贵州大数据政策为研究对象,对大数据政策本身进一步分析探讨,以了解当前这些大数据政策在哪些方面发挥了作用,存在哪些不足,从而为后续制定和完善适合贵州发展的大数据政策提供可参考依据。
三、构建大数据政策PMC指数模
(一)评价方法设计
为避免上述问题,本文采用文本挖掘和PMC指数模型相结合的方法,即定性与定量结合研究方法。文本挖掘是借助计算机技术从文本中选取有价值内容的过程[20]。PMC指数模型是Ruiz Estrada在Omnia Mobilis假说的基础上提出的,PMC指数可以方便地测量任何“政策模型”政策文本的一致性,模型在选取变量时详尽地挖掘一切可能变量,其中二级变量的数目不设置限制且变量权重相同[21]。采用该组合方法原因有6项:一是弥补了采用定性方法进行研究容易缺乏对政策某一领域的针对性,以及单纯定量研究信效度不强的问题[3]。二是文本挖掘可以快速分析到评价政策的关注热点和发展主题,也可以获取足够的待测样本数据,提高衡量指标精确度,让政策的评价更加客观全面,而通过人工方式去查找和处理有用的信息则非常困难[20]。三是PMC指数模型是目前对某一具体政策进行评价较为先进的方法[22]。四是PMC指数模型避免了其他政策评价方法在专家评分过程中的主观性,能以较高的精确度挖掘出每一项政策文本的优势及薄弱环节。五是PMC指数模型采用二进制平衡各影响因素的作用,可有效平衡所有变量,以此对各指标进行线性数据融,很大程度避免主观误判并提升精确度[23]。六是PMC指数得出的PMC曲面可以直观地展现政策评价全貌[20],使人们能多角度直观剖析政策合理性与可行性并提出相应的优化路径,为下一步大数据发展政策的制定与创新提供借鉴[12]。因此,本文通过构建PMC指数模型对大数据政策进行量化评价,可以使人们直观地了解每一项大数据政策的优劣势和政策间的差异情况,也可以针对性了解到各自政策未来改进的参考性路径。
(二)研究数据来源
本文选取贵州省政府及贵州省其他省级部门2014年至2019年发布的26项大数据政策文本为研究样本。首先对下载的26大数据项政策文本进行预处理,将政策文本数据库导入ROSTCM6软件中进行分词和词频统计,按照词频频率由高到低顺序输出;其次结合研究对象和区域,剔除如“单位、贵州、加快、以上、应当”等对政策评价无明显作用词汇,整理汇总得到大数据政策高频词汇,本文提取了前60个高频词作为政策样本关键词(见表1);最后对政策样本关键词汇作进一步处理,绘制了大数据政策高频词词云图(见图1)。图1直观体现了大数据政策文本的关注热点和核心内容,为选取PMC指数模型评价指标提供了重要依据。
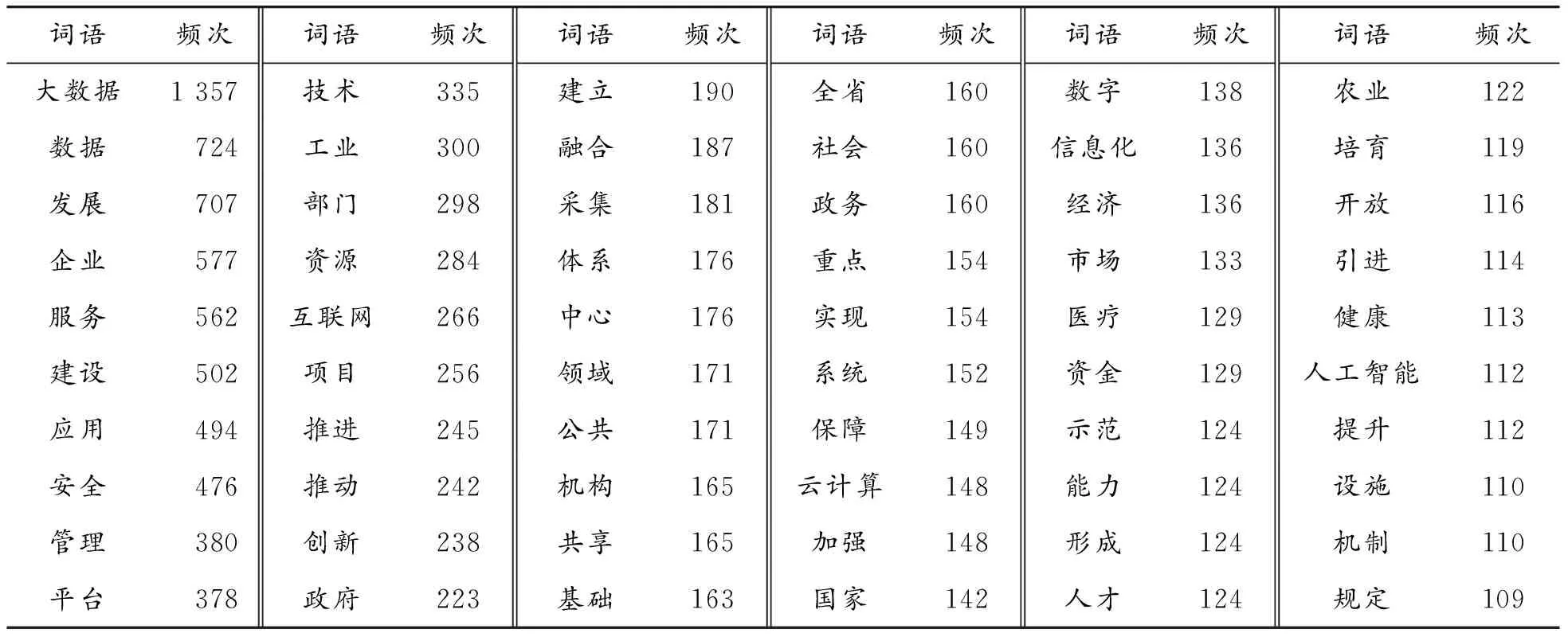
表1 大数据高频词汇表

图1 大数据政策高频词词云图
(三)建立PMC指数模型
学者Mario Arturo Ruiz Estrada指出构建PMC指数模型有4个基本步骤[24],即(1)使用多输入输出表;(2)变量和参数的分类;(3)PMC指数的度量;(4)PMC表面图绘制。本文结合PMC指数模型构建思路,将PMC指数模型建立步骤优化为:(1)变量和参数的分类;(2)使用多输入输出表;(3)PMC指数测量;(4)PMC曲面图绘制。
1.变量确定分类和参数设定
变量确定以Mario Arturo Ruiz Estrada提出的变量设置方法为指导[24],参照学者周海炜[12]、胡峰[19]对大数据产业政策评价和杜丹丽等[3]对科技创新政策评价的既有指标,设定了政策性质、政策效力、政策工具、政策视角、政策领域、激励措施、政策内容、政策受众和政策干预共9个具有通用性的一级政策评价指标[25](用X1~X9表示)。二级变量的设定除了参照上述学者的既有指标外,政策领域、政策内容和政策受众包含的二级变量还结合文本挖掘方法进行设定,共46个二级变量(用X1:1~X1:n表示),一级变量、二级变量具体情况见表2。

表2 大数据政策变量确定及分类
二级变量参数的设定,为对各项政策评价指标进行量化打分,通过二进制对所有二级变量设置为同等权重。如果该政策文本包含评价指标对应内容,则记分1,否则记为0,大数据政策量化指标体系及二级变量评价标准见表3。

表3 大数据政策量化指标体系及二级变量评价标准

续表(表3)
2.建立多投入产出表
多投入产出表的建立是为PMC指数模型的测算提供数据分析框架。且一级变量没有固定的排列顺序且相互独立,只存在二级变量的基本分类,二级变量构成一级变量,各二级变量权重相等[12]。本文结合大数据政策各变量的具体情况,建立多投入产出表如表4所示。

表4 多投入产出表
3.PMC指数计算
对于PMC指数的计算,本文主要分为4个步骤完成,第一步在多投入产出表中分配好一级变量与二级变量;第二步根据政策文本填入多投入产出表,由表达式(1)和表达式(2)对变量进行赋值;第三步根据表达式(3)计算每个一级变量的具体数值;第四步通过表达式(4)计算每项待评价政策的PMC指数。相较于以往有关PMC指数计算步骤,本文进一步指明了在第二步是如何使用指标去评价政策文中的内容,即是借助ROSTCM6软件通过文本挖掘对各项政策文本内容进行关键词识别,而后根据结果进行赋值评价。这样,一是延展了如何使用指标去评价政策文中内容;二是有效弥补了以往通过专家打分等方式导致评价精准度不高的不足。
X~N[0,1]
(1)
X={XR:[0~1]}
(2)
(3)
其中,t=1,2,3,4,5,…;t为一级变量;j为二级变量。
(4)
本文设置了9个一级指标,根据Mario Arturo Ruiz Estrada的评价标准,大数据政策PMC指数结果的评价等级标准见表5。

表5 大数据政策PMC指数值评价等级标准
4.PMC曲面图绘制
PMC曲面是基于PMC指数的数据值,以图像化的形式直观展示某项政策优点和存在不足。而绘制PMC曲面首先要设置PMC矩阵[26],本文结合表4大数据政策量化指标体系,将9个一级评价指标建立3×3矩阵进行计算绘制PMC曲面,PMC曲面图的矩阵计算方法如表达式(5)所示。
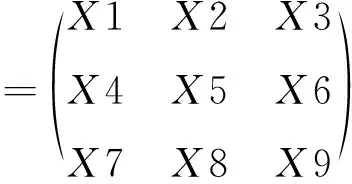
(5)
四、PMC指数模型实证分析
(一)评价政策选取
政策文献计量基于所有政策样本,通过政策关键词分析政策文本的共性,政策文献的个性特点容易被忽略[1],而以案例研究为特征的质性研究则能弥补这方面的不足[27]。PMC指数模型对评价政策没有特定规定,可对任何政策进行评价研究[28]。PMC指数模型在实证研究选取政策样本时不必遵循特定的规律,在选取政策时不必按照发布机构等维度进行样本选择,如果主观地选取样本无疑会带来评估模型的主观偏差[29]。
基于以上考虑,本文在26项政策样本中选取了8项具体政策文本组成案例样本进行评价研究,主要原因如下:(1)PMC指数模在做实证分析时候不需要特别按照什么样的规律来选取政策样本,可以评价中央到地方各个层面公开的政策;(2)案例样本选择均衡,发文机构涉及多部门,发文时间涵盖2014年、2016年、2017年、2018年、2019年,政策内容覆盖大数据发展中云计算、人工智能、健康医疗等热点问题,具有较强对比性;(3)案例样本主题内容范围相对宽泛,研究主题清晰明了,研究结果更具参考性;(4)周海炜等[12]选取包含国家级、省市级和地方级的8项大数据政策进行评价,胡峰等[19]以11项国家级大数据政策进行评价,本文选择省级政策基于已有评价结果为依据具有一定的科学性;(5)案例样本中各政策文本可获得性高。8项具体政策文本信息如表6所示。

表6 八项大数据政策研究样本
(二)PMC指数计算
基于前文确立的大数据政策评价指标体系和指标参数设定,建立8项大数据政策的多投入产出表,如表7所示。根据上文表达式(4)分别计算8项大数据政策的PMC指数,并按照其大小对照上文政策评级标准对以上8项大数据进行等级划分,具体结果如表8所示。
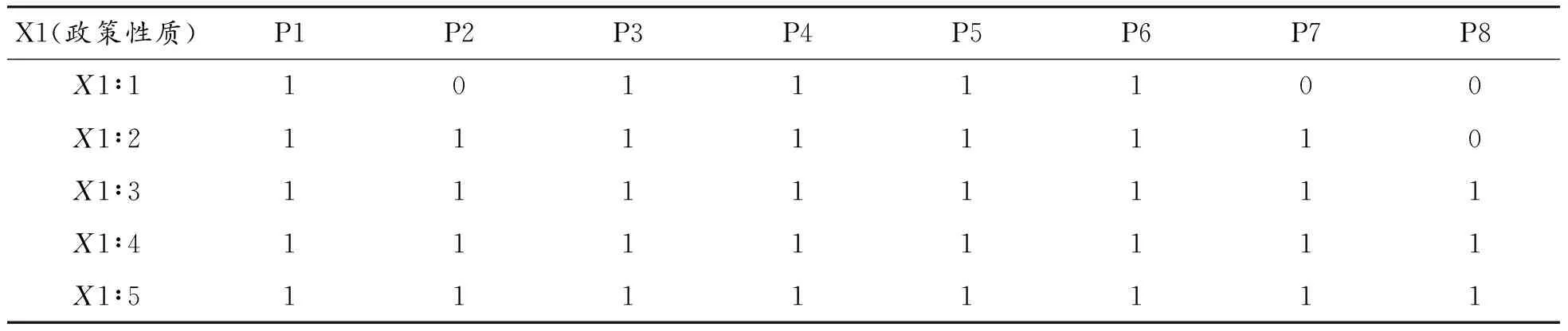
表7 大数据政策评价的多投入产出表(以X1变量为例)
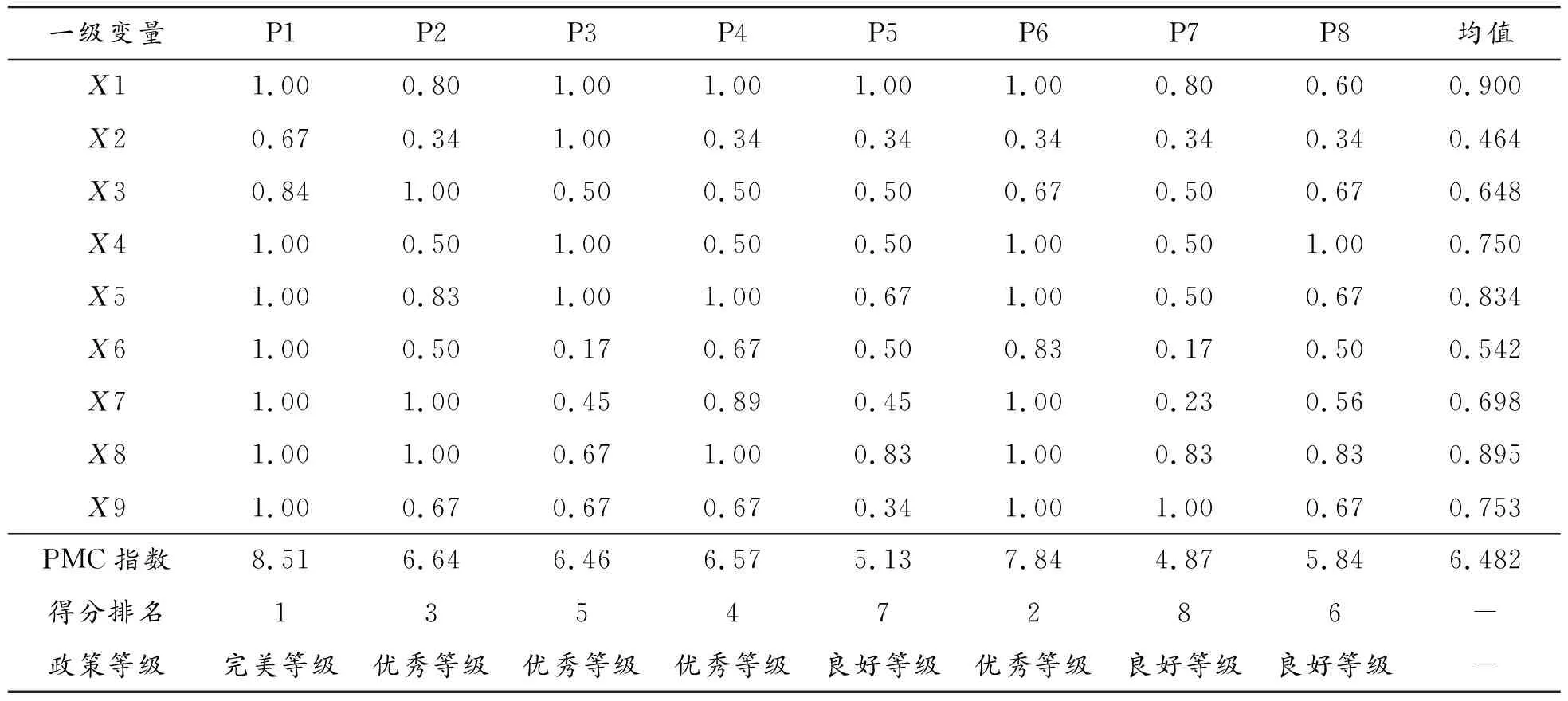
表8 八项大数据政策PMC指数及政策评价等级
(三)PMC曲面图绘制
根据表达式(5)建立8项大数据政策的PMC矩阵,如表9所示。
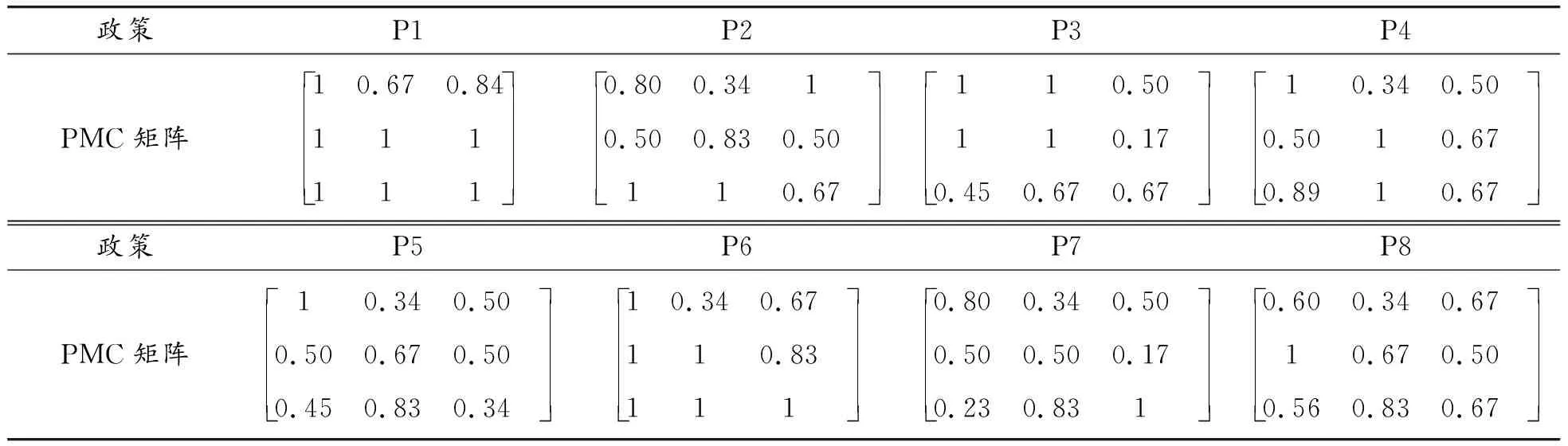
表9 八项大数据政策的PMC矩阵
根据表6的PMC矩阵,进一步得到8项大数据政策的PMC曲面,如图2所示。
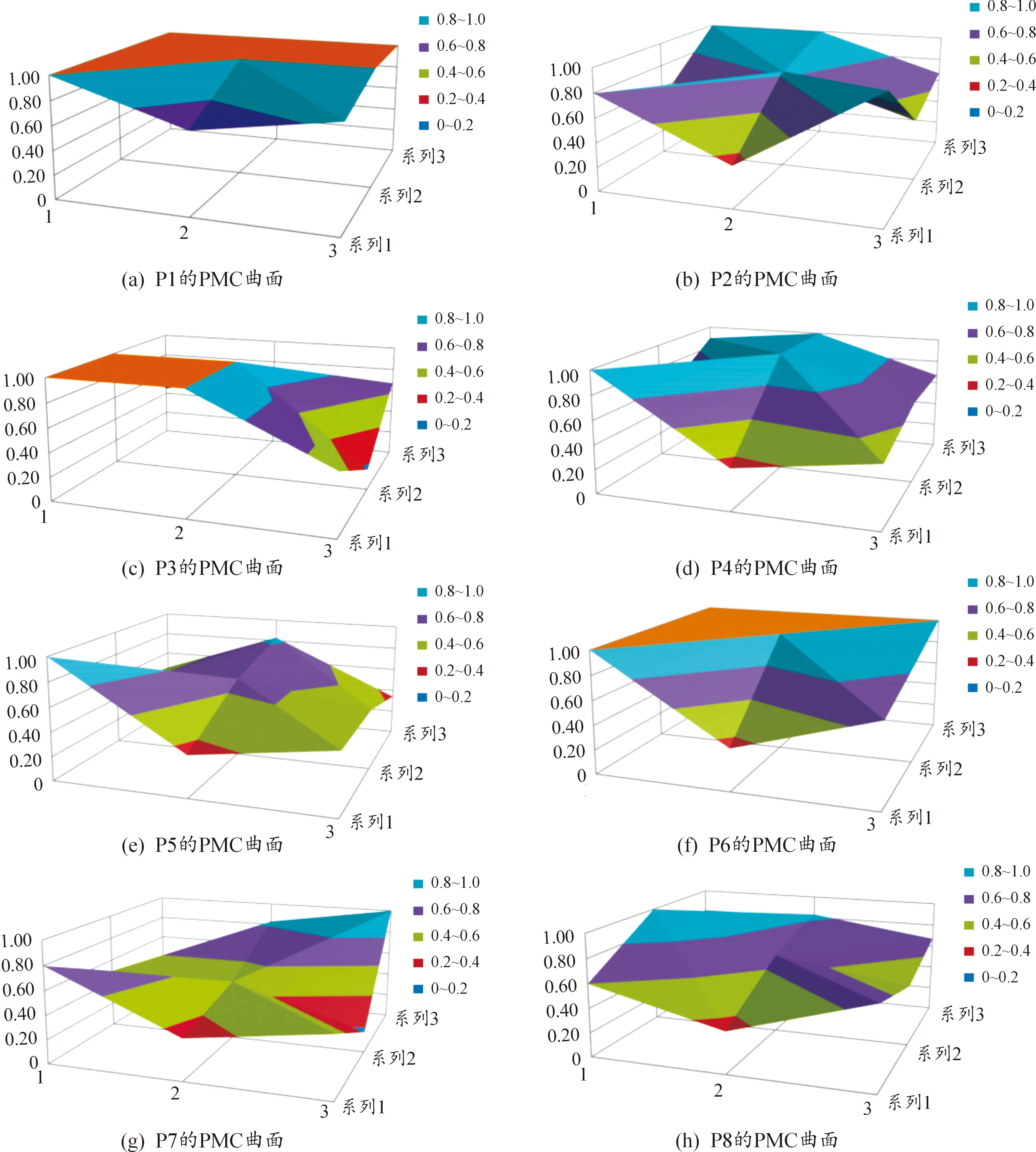
图2 八项大数据政策PMC曲面图
(四)评价结果分析
1.整体结果分析
本文以时间为序,绘制了8项大数据政策的PMC指数值折线图(如图3所示),从所有的PMC指数结果来看,8项大数据政策研究样本PMC指数得分虽有起伏,但总体等级为优秀。其中有1项政策为完美级别,有4项政策为优秀级别,3项政策为良好级别,按PMC指数由高到低排名是:P1,P6,P2,P4,P3,P8,P5,P7,这充分说明了贵州省级政府很重视大数据产业的发展,能依据贵州大数据产业发展需求结合自身实际情况,积极制定相关助力大数据产业发展的政策,内容覆盖面广、具有全局性的指导作用。从整体水平上看,待评价政策政策性质X1、政策视角X4、政策领域X5、政策受众X8、政策干预X9的PMC指数值具有明显优势,而在政策效力X2、政策工具X3、激励措施X6、政策内容X7方面较为薄弱,各项政策可结合一级变量的数值结合薄弱环节进行针对性完善。
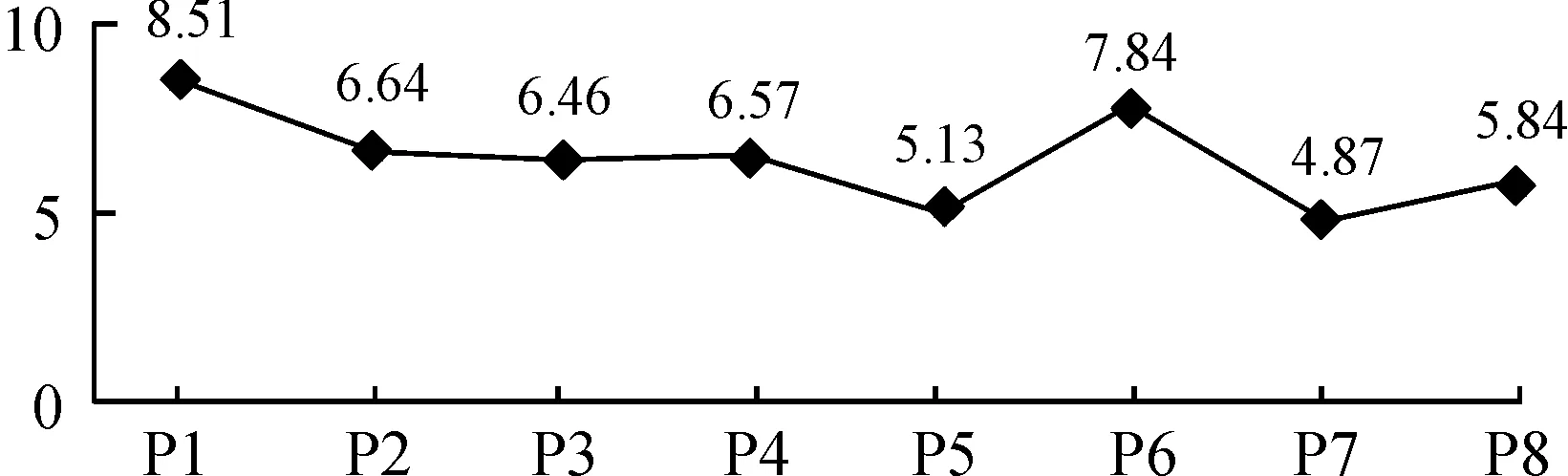
图3 八项大数据政策PMC指数的变化
2.单项政策结果分析
P1的PMC指数值为8.51,排名第1。除政策效力X2和政策工具X3变量,其他变量均为满分,表明这一政策的设计相对合理、科学,对各政策制定的各个维度指标考虑比较充分。P1作为贵州大数据产业发展的引导性文件,在长期发展目标上须加以明确,而该政策在长期变量项没有得分,未来可以考虑在长期规划上进行改进。
P2的PMC指数为6.64,排名第3。P2政策评价中政策性质X1、政策效力X2、政策视角X4、政策领域X5、激励措施X6和政策干预X9分值都低于均值,主要是政策文本中缺乏宏观层面、中长期规划内容,经济激励型政策干预手段政策较为缺乏,未来需要在X1、X2、X4、X5、X6和X9方面进行优化,参考性改进路径为X4—X2—X1—X9—X6—X5。
P3的PMC指数为6.46,排名第5。P3政策的主要作用是运用大数据监管市场主体,而目前政策主要关注监督管理,忽视了税收优惠、数据安全和受众对象内容。未来,在政策完善中,要提高激励措施、着眼于政策内容的全面性(如加强大数据知识产权方面的立法与执法力度,为大数据产业的发展应用提供坚实保障),也要做好政策工具使用和政策受众对象的均衡搭配,参考性优化路径为X6—X7—X8—X3—X9。
P4的PMC指数为6.57,排名第4。P4是一项促进和规范健康医疗大数据应用发展的省级专项政策,该政策在作用对象方面涵盖从政府到个人等广泛的受众,政策领域覆盖了经济、社会服务、政治和环境等领域。但在政策工具、政策视角、政策效力和政策干预方面数值低于均值,其中规划方面还不够详实,缺乏对宏观内容的兼具,未来可以考虑以X4—X3—X2—X9路径进行优化改进。
P5的PMC指数为5.13,排名第7。P5政策是针对精准脱贫颁布的专项政策,评价结果中仅有政策性质X1高于均值,其余8项评价指标得分值全部低于均值。而借助大数据平台助力脱贫攻坚,是有效实现精准扶贫、精准脱贫的有力举措。该政策本身相对其他政策文本而言,内容上还存在着许多不足,政策文本内容优化空间较大,未来可以考虑以X9—X4—X7—X5—X3—X2—X8—X6路径优化改进。
P6的PMC指数为7.84,排名第2。除政策效力X2分值低于均值,其余8项指标都高于均值,尤其在激励措施X6方面,贵州省注重人才引进,实施了“百千万人才引进计划”等系列工程。相对而言,该政策设计涉及面广,贵州在大数据产业基础基本完成基础上,开展云计算人工智能创新发展,加强新的人才引进确实是很有必要的。但该政策在政策效力X2中没有涉及5年及以上的内容导致X2分值较低。未来,可考虑首先改进政策效力X2内容,加强大数据政策中长期规划。
P7的PMC指数为4.87,排名第8。该项政策中仅有政策干预X9的得分值高于均值,政策性质X1等8项指标得分全部低于均值,该项政策评分低与政策文本的特殊性有关,是一份推动大数据与工业深度融合发展而制定的实施方案。政策内容X7方面只重点关注了数据采集和基础设施建设,且政策细分度不够,导致该项指标得分仅为0.23,为8项大数据政策在这一变量上的最低值;激励措施X6方面忽视了政府补贴、税收优惠等激励措施,阻碍了大数据与工业深度融合发展的积极性。P7参考性优化路径为X7—X6—X5—X4—X3—X2—X1—X8。
P8的PMC指数为5.84,排名第6。是2019年贵州省大数据发展管理局《关于印发贵州省大数据新领域百企引领行动方案的通知》,在政策工具方面,涵盖了国际合作、金融税收等工具,政策内容也考虑了宏观和微观层面,但在政策性质X1、政策效力X2、政策领域X5等7个方面都存在不足,作为样本中近期发布的大数据政策,政策文本还有待进一步完善,可参照P1和P6政策文本进行改进,参考性优化路径为X1—X5—X7—X2—X9—X8—X6。
五、结语
本文以文本挖掘—PMC指数模型评价分析贵州省省级大数据政策制定优劣情况,通过PMC指数值和PMC曲面直观地了解贵州省发布的单项大数据政策优劣现状,有力地解决了以往政策评价中衡量指标精确度不足的困境,丰富了文本挖掘—PMC指数模型在评价分析省级大数据政策中的应用,弥补了评价过程中对衡量指标数量限制的不足,给出了评价政策改进建议,为政府科学制定大数据政策,引领大数据产业健康稳定发展提供了参考依据。
研究发现:8项大数据政策PMC指数均值为6.482,总体等级为优秀。其中,在制定云计算人工智能相关政策时涉及范围较广,考虑内容较为全面,政策文本的系统完备性强,PMC指数得分高;但P5、P7和P8政策为良好等级,政策文本有较大的优化空间,尤其是在政策效力、政策工具、激励措施、政策内容方面。
研究结果表明:目前贵州政府在大数据政策支持方面已走在前列,大数据产值明显提升,越来越多的大数据人才成为“贵漂”;大数据督战平台助力精准扶贫,实现省州县扶贫数据共享互通、精准识别、精准脱贫等政策完全可以借鉴使用。待评价政策中也还存在一些有待改进的地方:一是政策效力X2严重缺失长期规划内容,该变量的一级指标政策效力得分均值仅为0.464,为所有一级指标中均值最低,严重影响了政策前瞻性功能发挥;二是待评政策中政策工具X3使用不全面,尤其是服务外包工具使用严重缺位,一级变量政策工具X3的均值仅为0.648;三是待评价政策的激励作用整体不强,一级变量激励措施X6的均值为0.542,低于多项其他指标均值,其中一个因素是激励机制不完善,如税收优惠只有25%待评政策涉及。四是政策内容涉及面狭窄,尤其是专项政策,如推动大数据与工业深度融合发展政策只涉及了数据采集和基础设施建设内容,不能较好把握政策要素的全局性。
研究建议:一是适当增加长期规划,将长期目标分解为阶段性可以实现的短期目标,提高政策落实的可行性,起到长远目标引导短期目标的作用,同时可以兼顾到政策的微观层面和宏观层面;二是提高政策工具类别的搭配使用,尤其是增强需求侧工具的使用,如服务外包工具的使用,促进大数据产业可持续发展;三是完善政策的激励机制,通过税收优惠、政府补贴、股权激励等方式营造大数据产业自由发展环境,增强大数据产业发展生机与活力,持续推动大数据产业健康发展。四是政策内容要拓宽大数据应用场景和融合领域,不仅仅在脱贫攻坚、农业、工业和医疗方面,还要面向金融服务、文化产业和文化保护等领域。
本文采用文本挖掘—PMC指数模型对单项大数据政策量化评价进行了一定的探讨,通过PMC指数模型和PMC曲面了解各项待评价政策的优劣情况,针对性提出参考性改进路径,以期为政府完善具体政策提供参考。后续研究将按照以下思路完善:一是进行关键词指标选取时,为更加全面地反映政策的覆盖面,样本可以根据大数据政策的调控领域适度扩大;二是为更好对比分析,可以结合不同层面政策样本进行对比研究,探讨不同层次政策的异同;三是对于专项政策(如P4医疗、P7工业等),可以对某一细分产业政策文本进行量化评价,了解不同产业间政策共性区别;四是可对每一年颁布的同一类政策文本进行对比评价,找到政策优劣的现实原因和理论依据,为具体政策的优化提供针对性建议。
猜你喜欢
房地产导刊(2022年8期)2022-10-09
导航定位学报(2022年4期)2022-08-15
房地产导刊(2022年6期)2022-06-16
小天使·三年级语数英综合(2022年4期)2022-04-28
非公有制企业党建(2020年2期)2020-03-08
华人时刊(2019年21期)2019-11-17
汽车导报(2017年5期)2017-08-03
中学生数理化·高二版(2016年4期)2016-05-14
新高考·高二数学(2014年7期)2014-09-18
福建中学数学(2011年9期)2011-11-03
