
一种用于可信计算的RISC-V 处理器设计
2022-02-17 12:11:28裴焕斗唐道光
电子设计工程 2022年3期
宫 健,裴焕斗,唐道光
(1.中北大学仪器与电子学院,山西太原 030051;2.山西百信信息技术有限公司,山西太原 030006)
可信计算是保障设备运算按照预期执行的技术,而安全可信的计算环境由硬件平台和操作系统共同组成[1],可信计算的核心思想是在执行安全防护的同时进行运算[2]。我国进入可信计算3.0时代后,提出了主动防御思想,意在对系统实施主动监控,确保应用程序按照预期结果执行,使系统免于病毒、黑客威胁[3]。
可信计算的运算控制功能由处理器核实现,对于处理器性能而言,绝对的硬件水平不是第一位的,指令集架构同样起到重要作用[4]。而在ARM和x86处于统治地位的同时,RISC-V 横空出世,在世界各地及各种重要应用领域快速崛起。RISC-V 指令集易于移植,设计简单方便,拥有完备的软件开发工具链,方便进行嵌入式开发,并且完全开源,无任何知识产权问题,任何公司或个人均可以根据其架构进行处理器设计。这一特点很大程度上降低了处理器设计的准入门槛[5]。RISC-V 具有很好的稳定性,因为其基准指令确定后不再发生改变[6]。
基于以上背景,文中在平衡性能、功耗的情况下,设计了一种适用于可信计算领域的32 位RISC-V 架构处理器,通过了指令仿真测试,借助FPGA(Field-Programmable Gate Array)在国产操作系统深度下成功运行SM3 算法,并根据杂凑值计算比对结果,输出对外部设备的主动控制信号。
1 整体架构设计
文中采用无知识产权问题的开源指令集RISC-V设计适用可信计算的软核处理器,其主要承担设计的控制和运算功能,采用经典5 级流水线设计可以显著提高运算速度,提升数据吞吐率[7]。通过设备总线外接密码模块的方式,令处理器支持符合可信标准的国产密码算法SM3,处理器通过SPI(Serial Peripheral Interface)接口对密码模块进行调用,计算杂凑值,并与预存杂凑值比对,根据比对结果正确的与否,可信主动控制逻辑将生成不同的I/O(Input/Output)控制信号,对外部可信设备发出控制命令[8]。图1 为系统整体设计框图。
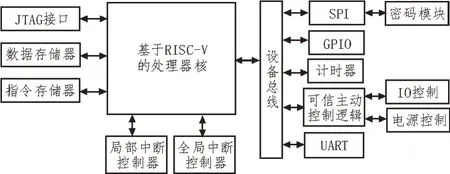
图1 整体设计框图
1.1 处理器核设计
1.1.1 流水线设计
指令执行效率直接关系到CPU的运算性能,将一条指令的处理过程拆分为5 个阶段,每个阶段设计专门的硬件单元完成,在经过一段时间的“建立时间”后,每个时钟周期每个单元保持满负荷运行,从而大大提高指令执行效率[9]。流水线时空图如图2所示。

图2 流水线时空图
由图2 可知,5 级流水线处理3 条指令花费7 个时间单位,相比串行执行花费15 个时间单位,效率显著提高。相比2 级或3 级流水线执行阶段时间过长的问题,采用5 级流水线硬件单元分布更均衡,吞吐率更高。处理器核总体设计如图3 所示。

图3 处理器核结构
取指阶段包含简单译码模块,译出所取指令是否为跳转指令,这样可以简化电路单元设计,由于没有配备硬件分支预测器,同时考虑到功耗影响,因此采用静态分支预测方法,设定向后跳转预测为需要跳转,反之则不跳转[10]。
译码阶段依据RISC-V 指令结构完成对指令的解析,包括确定当前指令源操作数地址、写回地址等,根据地址信息从通用寄存器组中取出所需操作数,并借助相关性检查模块确定指令是否存在数据相关。
执行阶段主要负责普通运算指令的计算,如加减法、移位运算。多周期乘除法由专门运算单元完成。一般来说,32 位数据的除法需要花费32 个时钟周期来完成。为了加快运算效率,采用两位试商法计算,只需16 个时钟周期即可完成,大大提高多周期指令的执行效率。这一阶段对于访存指令不作任何处理,直接送到访存阶段处理[11]。
访存阶段只进行访存指令的地址计算及数据存取,对其余指令不作处理,直接送到下一阶段即可。由于每个时钟周期都需要取出一条指令,采用分离的指令存储器和数据存储器设计可以避免一个周期内产生两个访问请求,产生存储器结构冲突。
写回阶段将指令计算结果按序送回通用寄存器,完成指令的最后处理。
1.1.2 数据相关处理
提高流水线级数在提升处理器性能的同时,也不可避免地引发了数据相关问题。由于该设计使用的是顺序处理器,所以存在写后读相关,即假设指令x比指令y先进入指令队列,而指令y需要指令x的计算结果,但指令x需要经过写回阶段写入通用寄存器,指令y才能读到正确的数值,如此在邻近指令中便产生了数据相关。
为此,该设计采用定向前推技术来解决流水线中的数据相关问题,即不等待数据被写回通用寄存器,在相关数据产生时就将数据定向前推至所需单元[12]。译码-执行相关解决方法如图4 所示。

图4 定向前推过程
指令x在执行阶段结束就计算出了写回结果,按流水线进行,需等待写回阶段结束才能得到计算结果,可以在执行阶段结束将结果直接送入译码阶段,这样就避免了译码-执行相关。同理,译码-访存相关、译码-写回相关也可以通过这样的方式来解决。判断是否存在译码-执行相关的代码如下:

对于加载指令,从数据存储器中读出结果才可以送回译码阶段,所以当译码模块检测到当前是访存指令后,流水线需要暂停一个时钟周期,至访存阶段取出数据,送回译码阶段,否则会出现错误。
1.2 外设接口设计
该设计外设部分通过SPI 接口外接密码模块,支持可信标准SM3 算法,具有可移植性强的优点。密码模块完成SM3算法的执行及计算结果的比对功能,最终通过可信主动控制逻辑实现对电源接口和IO接口的控制,完成对外部可信设备的控制与度量。UART(Universal Asynchronous Receiver/Transmitter)接口用来发送接收数据,在深度系统终端上打印计算比对结果。GPIO(General-Purpose Input/Output)扩展接口作为处理器的JTAG(Joint Test Action Group)接口,完成对处理器的调试下载功能[13]。总线地址分配如图5 所示。

图5 总线地址分配
1.3 SM3算法原理
SM3 算法是我国自主设计的密码算法,安全性高,全称为SM3 密码杂凑算法,其本质上是一种哈希算法[14]。对于长度小于264bit的数据,SM3 算法能将其转化为256 bit的哈希值。其主要流程如下:
1)填充
首先在长度为X的数据后添加1 个“1”和Y个“0”,使其满足1+X+Y=448mod512,其中Y取最小非负整数[15]。最后,将表示X长度的64 位2 进制比特串添加至数据末尾,构成n组512 比特的数据格式。数据“ab”的填充结果如图6 所示。

图6 数据填充结果
2)迭代压缩
将填充后的消息划分为n组,每组长度为512 bit,例如消息“ab”只有1组,n取(X+Y+65)/512。

将填充后的消息进行迭代:

其中,CF是压缩函数,V(0)为256 bit 初始值IV:7380166f_4914b2b9_172442d7_da8a0600_a96f30bc_163138aa_e38dee4d_b0fb0e4e。
3)消息扩展
将消息分组B(i)(256 bit)进行扩展生成132 个字(132×32=4 224 bit)。
W0至W15:消息分组平均划分为W0至W15,共16个字;
W16至W67:

其中,P1为置换函数,⊕为异或运算,<<<为循环左移操作。置换函数算法步骤如下所示。
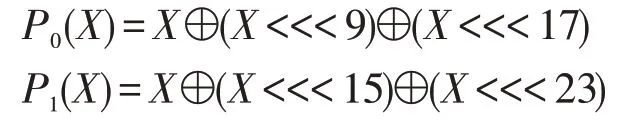
4)压缩函数
A~H为8个32位宽数据,FFj、GGj为布尔函数,其余为中间变量,计算步骤如下所示:


2 仿真验证
设计完成后,对处理器进行指令验证。通过Vivado 2020.1 加载.coe 文件至指令存储器完成初始化,并修改仿真环境调用第三方工具Modelsim 进行仿真,完成处理器整数指令验证。当pc为0时,取指阶段取出的指令码为002081b3,可以得知此为ADD 指令,译码阶段取出的两个操作数分别为1和2,这条指令在访存阶段不作操作。经过5 级流水后在写回阶段输出结果为3,结果正确;经过一个时钟周期后,pc加4,取出下一条指令为SLT,比较操作数1和操作数2的大小,由于操作数1大于操作数2,输出结果为0,结果正确。对不同类型的指令进行仿真验证后,结果均与预期一致,处理器功能正常[16]。部分仿真波形如图7所示。
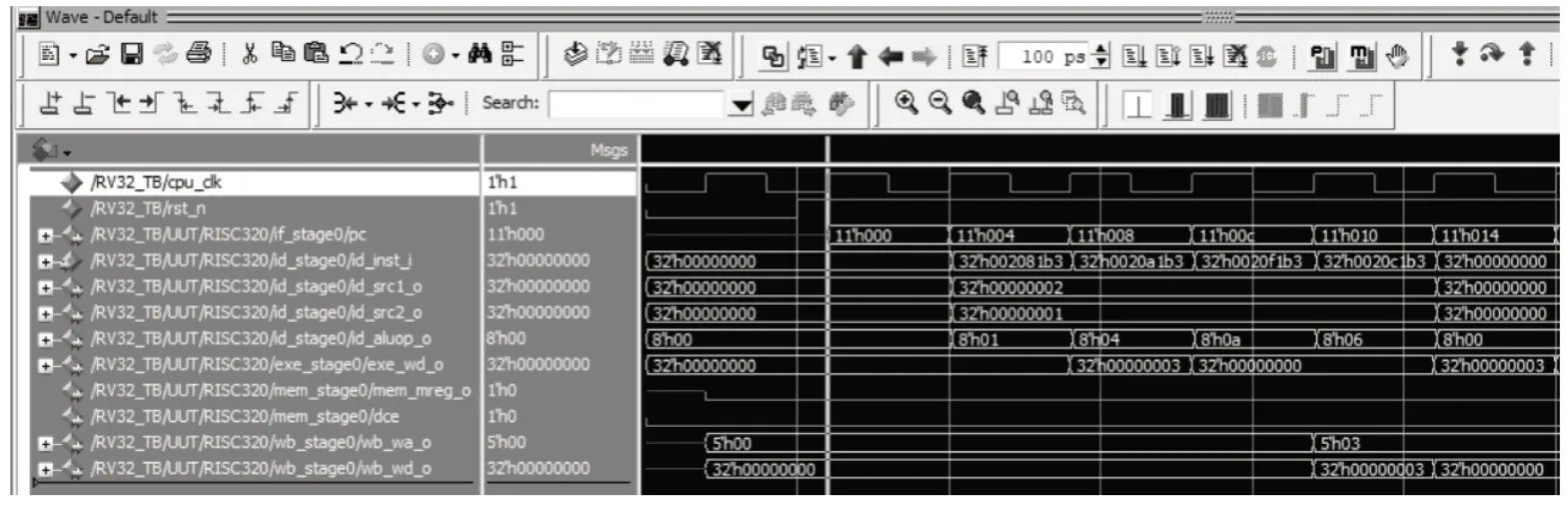
图7 仿真结果
3 FPGA原型验证
该设计借助Vivado 2020.1 软件将比特流文件烧写至FPGA 开发板,型号选择XI-LINX Artix-7 系列的XC7A100T-2FGG484。在国产操作系统深度下,安装GNU 工具链,配置下载器及flash 链接脚本,将SM3 算法程序烧录至外接flash 中,输入明文计算出256 bit 杂凑值,与程序内预存的杂凑值进行比对,最后通过可信主动控制逻辑实现对LED 灯的亮灭控制,并在终端上打印比对计算结果。终端打印结果如图8 所示。

图8 终端打印结果
该设计输入abc 值模拟从外部可信设备中获取的明文,通过计算比对,在结果正确的情况下控制FPGA 开发板的LED 灯,完成对IO 接口的控制。经验证,处理器控制功能正常。
4 结论
文中提出一种用于可信计算的RISC-V 处理器方案,对内核、外设以及算法原理进行了介绍。在国产操作系统深度下搭建交叉编译环境,最终通过FPGA 实现软件与硬件的交互。经过验证,处理器能流畅执行SM3 密码算法并完成杂凑值比对,输出相关控制信号,达到预期目标,对可信计算领域有较高的应用价值。
未来将通过外接可信设备进行进一步验证,并支持更多可信标准密码算法,实现完备的可信计算体系。
猜你喜欢
汉语世界(The World of Chinese)(2023年2期)2023-06-22 14:50:17
科普童话·神秘大侦探(2023年1期)2023-05-30 12:48:10
现代计算机(2021年36期)2021-03-14 00:50:38
小学科学(学生版)(2020年2期)2020-03-03 13:40:16
测控技术(2018年5期)2018-12-09 09:04:26
电子测试(2018年18期)2018-11-14 02:30:34
新闻传播(2016年3期)2016-07-12 12:55:27
中国资源综合利用(2016年9期)2016-01-22 08:35:22
遥测遥控(2015年2期)2015-04-23 08:15:19
自动化博览(2014年6期)2014-02-28 22:32:05
