
基于自注意力机制的视频行为分析*
2022-02-16 08:32祝伟吴陈
计算机与数字工程 2022年1期
祝 伟 吴 陈
(江苏科技大学计算机学院 镇江 212003)
1 引言
视频行为检测在视频监控,医疗领域,智能人机交互、视频检索中有着广泛的应用,具有重要的研究价值[21]。视频是由连续的图片形式的帧组成的,相较于图片多了时间上的维度,即帧之间的运动信息。从语义上理解视频需要结合单个视频帧包含的场景信息即空间特征和帧之间变化上的时间特征[17]。在过去的数十年间,传统基于RGB 帧序列人体行为识别研究取得了很大进展[10]。人工特征提取常用的方法有时空兴趣点(Space Time Interest Point,STIP),视觉词袋(Bag of Visual Words,BOVW),尺度不变特征转换(Scale-Invariant Feature Transform,SIFT),方向梯度直方图(Histograms of Oriented Gradient,HOG)和运动历史图像(Motion History Image,MHI)等,通过聚类等方法将上述初步提取的人工特征构造出更易区分的子特征,然后使用如支持向量机等分类器对子特征进行分类。传统方法一般通过特征提取与表征、识别分类等步骤。由于视频数是通过普通相机获取的,本质上就是一系列RGB 图片组成的序列。RGB 图片对各种环境变化比较敏感,如不同的运动场景、相机拍摄的角度、背景运动或相机运动、人为习惯造成运动上的差异等。因此,准确把运动前景与背景完全分割,从图像中提取运动的有效信息很困难。传统方法从表示方式上可以分为整体表示法和局部表示法。整体表示法把一个行为的所有运动特征表示为一个整体,从整体分析行为。Blank 等提出了MEI 模板的体积扩展,主要思想是提取人体帧上的剪影按时间序列拼接成三维形状用来表示运动[4]。Weinland D 等提出通过运动历史体(MHV)表示不同人在不同角度执行不同动作,并表明使用绕垂直轴的圆柱坐标中的傅立叶变换,可以高效地执行对齐和比较[5]。由于整体法不够灵活,对运动细节不敏感,不能有效处理遮挡等问题。对于通过提取叠加运动主体轮廓获取运动特征的方式无法处理轮廓内部的细节特征。
在深度学习被广泛使用之前,主流的方法是IDT,之后发展出来的算法很多都是在IDT 方法上进行改进。IDT 的思路是利用光流场来获得视频序列中的一些轨迹,再沿着轨迹提取HOF、HOG、MBH 等特征[11]。最后利用FV(Fisher Vector)方法对特征进行编码,再基于编码训练结果训练SVM分类器。视频比静态图像多了时间域,包含的特征更多,语义信息更复杂。为了提取时间域特征,视频行为识别需要处理大量视频帧并得到其中隐含的联系[6]。深度学习出来后,陆续出来多种方式来尝试解决这个问题。由于深度学习是学习样本数据的内在规律和特征表示,不用人工干预的特征提取可以保留更多也许在人类看来无意义但有价值的信息[22]。早期的深度学习方法是直接将视频截帧,然后基于单帧进行卷积提取特征。由于单帧图片相对于整个视频只是很少的一部分,对视频的表述不够充分。之后出现的双流网络分别以静态图像和光流图作为输入,使用两个并行卷积网络分别处理这两种不同的输入,最后两个网络的输出取均值,得到最终的输出结果[16]。由于视频拍摄的环境是在时刻变化的,前后帧的差异不仅仅在运动主体的运动上,还有镜头晃动、视角变化和环境光线突变等,甚至不同的摄像头模组,不同的视频编码方式也会带来噪声[18]。
由于自然行为运动是连续的过程[19],不同的行为可能包含很多相似的运动细节,因此理解辨别一个行为需要综合前后的运动特征从整体上判断[20]。结合以上因素,为了在视频行为分析中提取有效的运动特征,减小环境变化带来的无关信息,并对空间特征在时间轴上进行融合编码提取语义信息,本文提出了一种基于空间注意力机制以静态图像帧及其相邻帧的灰度图的视频帧块分别作为网络输入,分别用于计算空间特征与微运动特征,时间注意力机制将视频的各个微运动特征融合提取运动的更高层语义特征的方法。在UCF101与HMDB51数据集上实现了94.78%和71.47%的准确率。
2 基于三维卷积注意力机制的深度神经网络模型
运动是连续的过程。视频中的运动信息是表现在时间维度上的,也就是相邻两帧之间的像素变化,是离散的。邻帧的像素变化组成运动的最小单元,可以称为微动作。这些微动作前后关联,构成一个具体的行为。
在静态图片的分类、目标检测、分割的任务中卷积神经网络已经取得很大的成功。但对于静态图片很有效的二维卷积网络架构很难提取视频中的运动特征。一种常用的方法是人工提取运动特征,其中典型的方法是Simonyan等提出的双流卷积神经网络[2],但这种方法需要预先耗费大量时间计算光流图,并且光流图中会包含很多无效的运动特征。对于深度学习所期望的是能实现端到端的学习,所以使用三维卷积网络的架构把对运动特征的提取也包含网络的学习任务中是一个很好的选择[23]。其中典型的是Tran 等提出的C3D(Convolutional 3D)网络[15],对于视频数据增加了时间维度上的卷积,可同时提取空间特征与运动特征。但C3D 采用的是11层VGG Network的架构,网络层数虽然不深,但模型参数量十分庞大,需要大量的计算资源。
本文基于三维卷积网络,对输入的视频数据在时间维度上进行分块,一个视频抽取固定数量的块,每一块包含固定数量的帧。对抽取的每一块进行预处理,包括从每一块内随机抽取一帧原始RGB图,获取块内每一帧的原始灰度图。将RGB 图与灰度图分别作为模型的两个输入。为了有效提取块内的微动作特征,将用于二维卷积的空间注意力机制拓展到三维。为了抽象出微动作前后的语义特征,使用时间注意力机制对块间的微动作特征进行融合编码。
2.1 深层网络模型结构
模型的整体结构如图1 所示。模型有两个输入端,Gray Block 的维度(N×M)×112×112×1,是由N 个视频块帧的灰度图(112×112×1)堆叠而成的,112分别为帧宽与帧高,RGB Block大小为(N×112×112×3)是与之对应的,从每个视频块中随机抽取的一个RGB 帧(112×112×3)堆叠而成。其中M 为N个视频块中每个视频块的帧数。输入灰度帧的分支主要用于提取运动特征,视频数据在浅层的运动特征主要表现在相邻两帧像素点的偏移,抽象的语义较少。模型浅层网络主要目的是通过压缩空间与邻帧提取像素的偏移特征,其运算如式(1)所示。
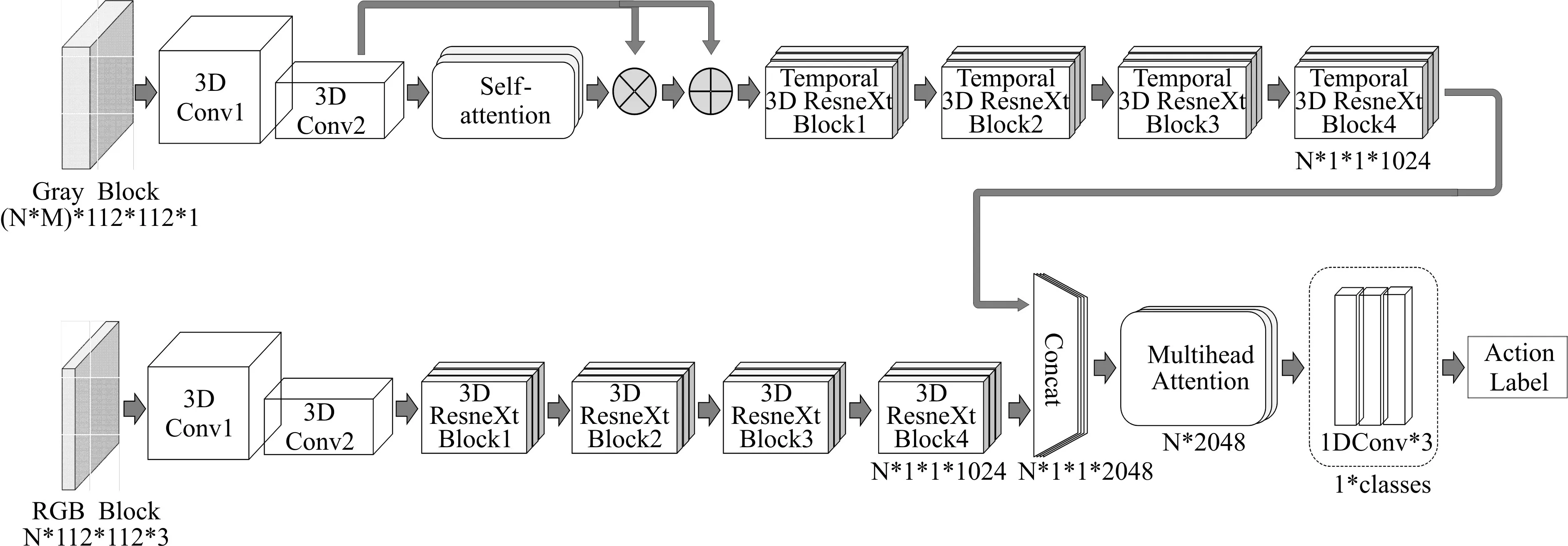
图1 深层网络模型整体结构
其中m 为batch size,x 为网络中某一层的特征块,y为批归一化层的输出,γ,β分别为缩放、平移系数,是归一化层需要学习的参数。计算方法如式(3)所示。
式中ε为非零常数,E(xi),Var(xi)分别为一个batch中特征块对应channel 的均值于方差,如式(4)和式(5)所示。
在网络模型整体结构示意图中,灰度视频块先经过两层标准三维卷积,再与Self-attention 机制残差连接,连接方式如式(6)所示。
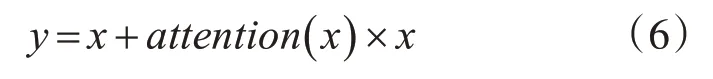
式中x 表示自注意力机制上层的网络输出,y 表示自注意力机制与前层网络残差连接后的输出,其输出结果输入Temporal 3D ResNeXt Block。同样,对于RGB 视频块先经过两层三维卷积,由于RGB 分支的主要目的是提取场景特征,需要综合考虑整个图像的信息,结构中没有加入注意力机制,经过三维卷积后的特征图直接输入3D ResNeXt Block中。灰度与RGB分支的特征图在channel的维度进行拼接,输入Multihead Attention,最后经过三层一维卷积与softmax 层后得到类别标签。模型的损失函数采用的是softmax 交叉熵损失函数,如式(7)所示。
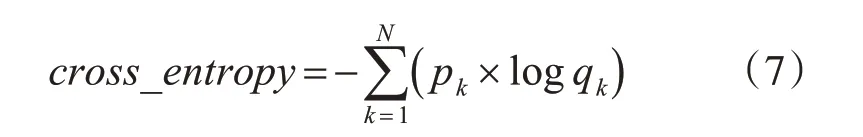
其中p为实际的标签,q为模型的预测,N为p与q的维度。
2.2 3D ResNeXt Block的改进
由于人或物体三维运动的灵活性,同个运动会因为视角或运动主体的差异,在时间轴上跨度有很大的差别。与静态图片中物体的外形特征相比,很难有效地在时间维度上的提取运动特征。通常的三维卷积在时间维度上采用相同单一的卷积核尺寸,很难有效融合不同时间轴跨度上的运动信息。针对这个问题,在ResNeXt Block 的基础上进行改进,提出了Temporal 3D ResNeXt Block 结构如图2(b)所示。图2(a)为原始的ResNeXt Block 结构。Temporal 3D ResNeXt Block 的数学表达如式(8)所示。
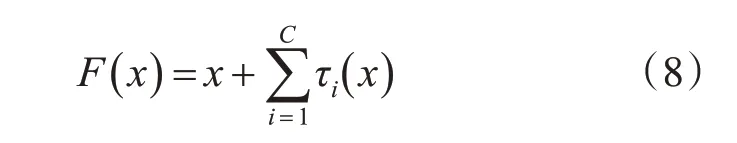
式中C 表示block 内channel 的分组数,每一组的τi的结构相同。改进后的block结构在第一层上与原结构相同,通过1×1×1的三维卷积核拆分并压缩特征块的通道。第二层采用1×3×3 的核仅在空间维度上卷积。第三层仅对时间维度卷积,对第二层的输出分别采用1×1×1,3×1×1,5×1×1 三种不同尺寸的卷积核,并分别对对应特征块时间维度上进行0、1、2尺寸的padding,使三种卷积核的输出特征块在时间维度上尺寸相同,然后在channel 的维度上拼接,最后通过卷积核尺寸为1×1×1的卷积层将特征块通道恢复到输入大小并与输入残差连接。
2.3 Self-attention机制结构
由于存在相机位移、背景变化等与运动主体行为无关的运动,在提取特征时会包含无效的信息。采用self-attention 机制,网络结构如图3 所示。灰度视频块经过两层三维卷积后得到的特征块{C1,C2,…Ck},其中Ck为第k 个通道的特征块,w,h,d 分别为视频帧特征块的宽,高和帧数。{C1,C2,…Ck}分别经过三个卷积分支,其中3D Conv1、3D Conv2 将通道压缩至原来的1/a,将特征块尺寸reshape 成(h×w,k/a,d)与(k/a,h×w,d)并在特征块的宽和高的方向相乘得到尺寸为(h×w,h×w,d)的特征块,再与经过3D Conv3 卷积并将尺寸reshape 成(k,h×w,d)的特征块在宽和高的方向相乘,得到的特征块尺寸为(k,h×w,d)。最后经过reshape 成与特征块{C1,C2,…Ck}尺寸相同注意力矩阵。

图3 Self-attention机制结构
2.4 模型结构分析
为了获取不同时间跨度的特征信息,我们在3D ResNeXt Block 中,将对视频块在时序通道上的卷积采用了三种尺度的卷积核,使提取到的特征中融合了更多不同时间跨度的运动特征。同时将空间通道的卷积与时间通道分离,减小了模型参数量。视频的本质是序列,模型前半部分的三维卷积对视频数据的空间通道及短距离相邻的时间通道压缩编码。即对应的是相当于将一个完整行为分割成多个微运动,再对每个微动作编码。模型后半部分采用的Multihead Attention 采用的是自然语言处理中Transformer的编码器部分,将各个微动作的编码综合,进一步抽象融合成一个具体的行为特征。
3 实验
本实验数据采用的是UCF101 与HMDB51 公开数据集。其中UCF101 数据集中包含101 种行为类别,是在日常现实环境中拍摄的13320 个视频片段。HMDB51 数据集中包含51 种行为类别,6849个视频片段,主要来源于影视作品,小部分来自现实环境。
3.1 数据预处理
数据集中的视频片段随机抽取80%作为训练集,20%测试集。每个视频均匀分割成16 个部分,每个部分中随机抽取连续的四帧,总帧数少于64的视频,不足的帧用空白画面补全。每一帧的大小按宽高比缩放并用零像素补全将尺寸调整至112×112。
3.2 实验结果与分析
深度网络模型由pytorch 框架搭建。在UCF101 与HMDB51 数据集下,对单独使用灰度帧的输入分支、RGB帧输入分支和融合两种输入的方式分别进行了测试,未经预训练的结果如表1所示。
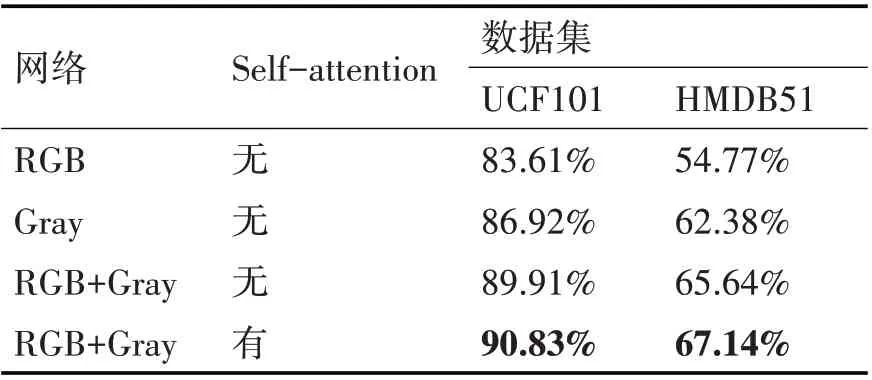
表1 改进的模型准确率
从表1 中可以看出,融合了灰度帧分支和RGB帧分支的模型在准确率上相对独立分支有了很大提升。在加入Self-attention 机制后模型的准确率进一步增高,表明了Self-attention机制的有效性。
表2 展示了本文方法与已有算法模型经过预训练后,在UCF101 与HMDB51 数据集上准确率的比较。其中的Pre-training 为模型预训练使用的数据集。本文改进的模型经过kinetics数据集预训练后,与原始的ResNeXt101 算法相比,在HMDB51 数据集上的提升更明显。通过表1、表2,表明了本文在模型结构设计,ResNeXt Block 的改进上对视频行为识别准确率的提升方面具有一定的作用。
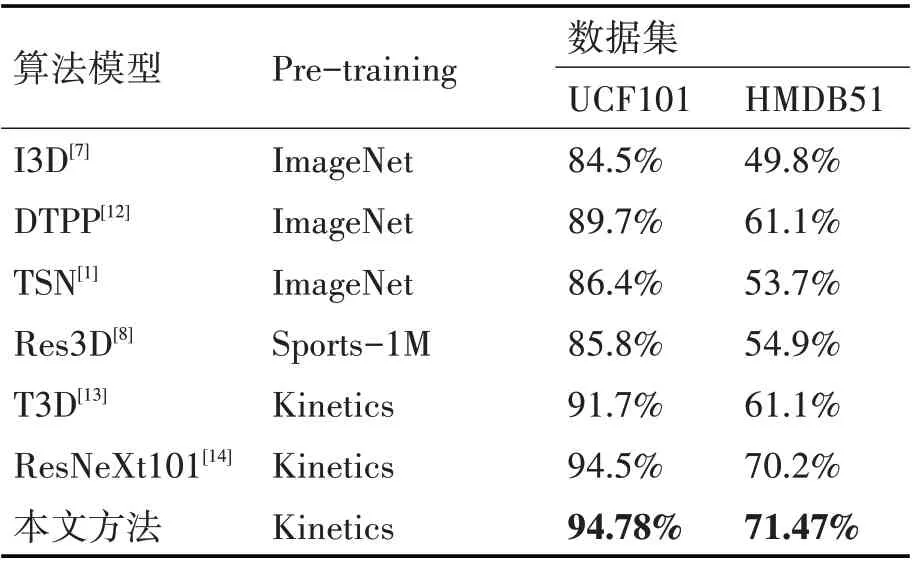
表2 不同模型准确率比较
4 结语
近些年来,深度学习方法已经在计算机视觉的图像领域取得了巨大的成功。由于其端到端训练的设计思想简单,在海量数据的支持下,相较于人工设计的图像分析算法可以应付更复杂的环境,识别效果好,因而得到了越来越多的研究者的关注。相对于图像分类,视频中行为特征更丰富,语义更抽象,还有其在时间上的连续性都给识别任务增加了难度。虽然自行为识别研究以来已经取得了不少成果,但是任然有很多困难需要面对。例如复杂的行为,多个运动主体的互动及场景的多变等;在视频的时序关系上,同个行为持续的时间有长有短,开始与结束的分界很模糊,本文在ResNeXt Block 的改进中采用的多时间尺度卷积核、对视频进行序列编码后采用自然语言处理的方式针对这个问题虽然有所改善,但无法有效解决对需要长时序关系推理、时效性要求高的行为识别任务中,未来还有很多问题有待研究。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
包装工程(2022年9期)2022-05-13
当代陕西(2022年4期)2022-04-19
计算技术与自动化(2022年1期)2022-04-15
集装箱化(2021年1期)2021-04-12
当代陕西(2020年22期)2021-01-18
中国信息技术教育(2020年2期)2020-02-02
上海师范大学学报·自然科学版(2019年5期)2019-12-13
中华诗词(2019年7期)2019-11-25
中国新通信(2017年9期)2017-05-27
