
面向电力巡检语音指令识别后的文本纠错算法*
2022-02-16 08:32曹雪虹焦良葆张四维
计算机与数字工程 2022年1期
陈 楠 曹雪虹 焦良葆 孟 琳 徐 逸 张四维
(1.南京工程学院人工智能产业技术研究院 南京 211167)(2.国网南京供电公司 南京 210009)
1 引言
随着智能电网[1]和人工智能技术[2]的不断发展,语音人机交互技术[3]在电力领域的需求也在不断增加。为了保障变电站安全、稳定的运行,电力工作人员需要定时定点进行电气设备巡检,而巡检工作具有巡检项目繁琐、巡检质量要求高等特点,传统的集控中心指令控制模式对于电力巡检人员来说存在现场设备状态信息查询效率低的弊端,为了充分发挥现场电力巡检人员的作用,采用人机交互技术将巡检指令输入无线麦克风,实现相关巡检信息的查询,进而为其他巡检操作提供参考。
然而在电力巡检领域有特定的专业信息词汇,利用面向公共领域下的语音识别技术(Automatic Speech Recognition,ASR)进行语音识别时,电力巡检语音指令中的专业词汇很难被正确识别,使电力行业语音识别的正确率不高。例如,在采用科大讯飞[4]进行语音识别时,会出现把“查询林山222线的设备健康状况”误识别成“查询灵山222 线的设备健康状况”,把“井蒋”识别成“请讲”,把“代维”识别成“戴维”等,由于存在同音字或人本身造成的口音偏差使电力巡检词汇被误识别成日常通用词,大量的指令词无法准确识别最终造成了电力巡检操作可靠性差的问题。因此,针对面向公共领域的语音识别方式在识别电力词汇时错误率高的问题,进行语音识别后文本纠错算法的研究是十分必要的。
目前,针对电力巡检的语音指令识别方面的研究较少,语音识别后文本的校对和纠错方法有以下几种:Park G[5]提出了一种基于序列对序列神经网络的修正ASR 误差的后处理模型。该模型只使用音节作为输入特征,且依赖ASR引擎返回的多个候选句子;张俊祺[6]提出了组合N-gram 模型,融合双向长短期记忆神经网络Bi-LSTM 语言模型和多策略产生候选集的方法,分别进行查错和纠错;张佳宁[7]提出了一种基于word2 vec的语音纠错方法,利用word2 vec 生成具有上下文核心词的关键词,通过深度语言模型对文本进行错误检测通过将拼音混淆集与语义和上下文信息相结合来纠正可能出现的错误。
以上的校对和纠错算法,在处理语音识别下规范的中文文本语法、语义有良好的处理效果,然而面向电力巡检领域下的语音识别后文本纠错能力较差。因此,本文提出一种基于模式匹配的算法进行语音识别后文本纠错,首先构建指令词特有的语法模型,将独立的指令词相互之间构成联系,然后利用AC 自动机(Aho-Corasick Automaton,ACA)高效匹配的优势构建汉字和拼音AC 自动机,分别进行精确匹配下的查错和纠错,最后针对精确匹配下纠错失败的问题,进一步实现模糊纠错,大大提高了纠错能力。
2 电力巡检指令语音识别后文本纠错算法
2.1 纠错算法整体架构
本文对于电力巡检语音指令词识别后的文本纠错算法整体架构如图1 所示。首先经过语音识别系统获得识别后的文本,然后将识别后的文本进行模式匹配算法的纠错。
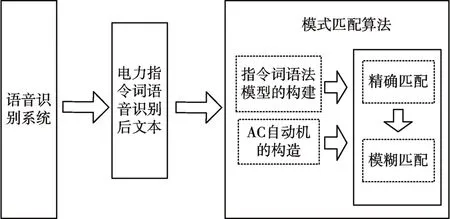
图1 语音识别后文本纠错结构框图
本文基于模式匹配的纠错算法主要包括语法模型的构建、AC自动机的构造、模式匹配过程三部分内容。
1)语法模型构建
通用的纠错算法对于数据库不进行特别的处理,而数据库本身的构建与纠错算法的设计息息相关。电力巡检词条数据库中包含庞大的词汇文本,通过对电力环境语言的语法分析,设计了一种面向电力巡检指令的语法模型。
2)AC自动机的构造
AC 算法本质上是自动机存储结构,该算法使用Trie 树结构来存储所有模式串。利用该算法的快速检索、统计、排序和保存大量字符串的特点,高效地实现巡检指令识别串与匹配串之间的匹配过程。
3)模式匹配
在电力巡检领域的语音交互中,将模式串与识别串进行匹配,即为模式匹配过程。为了对同音字误识别进行纠错,结合语法模型和AC自动机,提出了精确匹配过程;为了进一步对同音字误识别外的别字错误进行纠正,提出了基于编辑距离的模糊匹配纠错算法。
2.2 电力巡检指令的语法模型
首先对电力巡检指令词数据集和语音识别文本进行研究,构建识别串的“动作、属性、对象”语法模型,如“查询代维一班班组到位率”,其中“查询”为动作,“代维一班”为属性,“班组到位率”为对象。该语法模型如图2 所示。由于所有模型都是以对象为主干,将动作和属性彼此联系,因此根据模型结构对数据库进行预处理分类:对象类关键词、属性类关键词和动作类关键词,将所有关键词以对象类关键词为主干彼此联系,构建语法分支模型。每一类语法分支模型包含对象1、对象2、…、对象n 及其所关联的动作和属性词条,如图3(a)、3(b)、3(c)所示,每类对象分别有其对应的属性和动作。

图2 语法模型

图3
为了能够在模型匹配下构造汉字和拼音AC自动机,需要完善模型的词条信息,即语法模型中的所有“动作、对象、属性”都必须包含“词条ID 地址”、“词条名称”、“汉字”、“拼音首字母”、“全拼”的词条信息,其中“词条名称”为最终返回给用户的值;“汉字”为具体的词条,用于构造汉字AC 自动机;“拼音首字母”,用于构造拼音首字母下的AC自动机;“全拼”是对拼音首字母的扩充,为模糊匹配下编辑距离的计算提供了更大的维度。例如:“查看、查询、输电一班、代维一班、班组到位率”这五个关键词的各自五种信息构成如表1。

表1 词条信息构成
2.3 模式匹配算法
从给定的字符序列中找出给定的字符串并获得具体的位置,即为模式匹配问题。其中模式串为给定的字符串;待匹配的文本串为文本序列。
常用的模式匹配算法包括BF 算法[8]、KMP 算法[9]、Shift-And 算法[10]和AC 算法[11]。为了高效地实现识别串的模式匹配,采用基于AC 自动机的多模匹配算法,来提取识别串的关键词条。
2.3.1 AC多模匹配算法
AC 算法关键分为三个步骤:构成Trie 树,构造失败指针,Output函数。
1)构造拼音AC自动机
根据词条文本数据库中预处理好的词条的文本数据,依托于Trie树,分别构造拼音AC自动机和汉字AC自动机。于是根据语法模型构造中文识别串中三类词条的拼音和汉字的AC 自动机,分别是对象的拼音和汉字AC 自动机、属性的拼音和汉字的AC自动机、动作的拼音和汉字AC自动机。设中文模式串集合M={查询,查看,代维一班,输电一班,班组到位率,八百三六二线,零零一号杆,设备台账,沿布图,设备健康状况},拼音首字母模式串集 合M={CX,CK,DWYB,SDYB,BZDWL,BBSLEX,LLYHG,SBTZ,YBT,SBJKZK},其中模式串xi为预处理好的词条中的“拼音”,对M中的每个模式串xi从根节点(root)出发,逐个取出xi中的每一个字符。汉字AC 自动机的Trie 树如图4 所示,拼音AC 自动机的Trie 树如图5 所示。其中图4(a)是汉字动作字典树图,图4(b)是汉字属性字典树图,图4(c)汉字对象字典树图。图5(a)是拼音动作字典树图,图5(b)是拼音属性字典树图,图5(c)是拼音对象字典树图。


图4 汉字AC自动机的Trie树


图5 拼音AC自动机的Trie树
2)构造失败指针
构造失败指针,即使用失效函数failure 函数来计算某个字符失配时应转移的状态:若某状态的父状态为0,则该状态的失效函数值为0;对于其他状态n,设其父状态为r,当前字符为a,则该状态的失效函数值failure(n)=goto(failure(r),a)。
3)Output函数
Output 函数记录了自动机跳转状态过程中发生匹配的模式子集,它的作用是输出已经发生匹配的模式。Output表的生成贯穿于goto表和failure表的过程中。
2.3.2 模式匹配下的精确匹配
模式匹配下的精确匹配包括查错和纠错两部分。模式匹配的对象是语音识别下的中文巡检指令词识别串,对该串进行汉字AC 机的精确匹配过程,即为识别串的查错过程;该识别串下的拼音首字母匹配过程,即为精确匹配中纠错过程。
1)对象词条匹配
在模式匹配中对象词条是整个识别串的核心,因此首先对识别串进行查错,若对象词条能与对象汉字AC机完全匹配,则对象词条匹配成功,否则进行纠错过程,进行对象拼音AC自动机匹配,直到匹配成功,则完成纠错,否则对象词条匹配失败。具体匹配流程如图6所示。

图6 对象词条的匹配
2)属性和动作词条匹配
成功匹配到识别串的对象关键词条后,根据该对象词条所在的语法分支模型如图2,对该分支模型下所对应的属性和动作词条同时进行汉字和拼音的精确匹配,即同时进行查错和纠错,提高纠错过程的效率。具体匹配过程如图7所示。

图7 属性和动作词条的匹配
识别串的匹配过程遵循对象词条的匹配,若汉字或拼音首字母匹配成功,则完成匹配,否则匹配失败。
完成所有词条的匹配,则完成模型匹配下的精确匹配过程。
2.3.3 模糊匹配算法
由于模式匹配下的精确匹配依然会存在纠错失败的情况,如别字错误的误识别情况,因此为了提高纠错正确率有必要进一步进行模糊检索。
汉字是非字母组成的语言,把任意两个汉字之间的差别都算成同一个值不够准确,且汉字不像拼音具有声母、韵母、音节等,可以通过多个维度进行编辑距离[12]的测算,所以提出了基于拼音的模糊匹配算法设计。
1)基于拼音的编辑距离
通过国网南京供电公司提供的电力词汇数据库进行实验,发现精确匹配错误的文本串多为音近词错误,因此考虑采用模糊匹配中的最小编辑距离纠错算法,该算法能补充似然匹配算法的弱点,在使用过程中能够降低查询词的错误率。最小编辑算法的具体描述如下:由精确匹配匹配失败的识别串为“Q1Q2…Qn”和匹配串“M1M2…Mn”,通过删除、增加、替换的操作后,将识别串编辑成匹配串所使用的最小操作数,称为识别串到匹配串的最小距离,记为Med(Query,Mathch),由于精确匹配下的识别串多为音近词,则只进行替换操作。例如,要找到所有与识别串的编辑距离为1 的匹配串,则变化可能是拼音其中的一个字母改变了1 个距离单位。而当两匹配串都相同的时候,则编辑距离为0;当两者编辑距离越小,则两匹配串之间的相似性越大。

(2)设定发音相近(更容易发生替换错误)的声母之间的编辑距离小于1,即如/l/和/n/,在进行替换操作时,编辑距离小于1(设为0.8),因此在实际的编辑距离的计算中,替换错误的串更容易被匹配提取。
2)模式匹配下的模糊匹配
模式匹配下的精确匹配分别采用汉字和拼音AC 自动机实现识别串的查错和纠错,但是该方法在纠错别字错误时没有显著的效果,因此进一步提出以下模糊匹配纠错算法进行纠错。
(1)替换词操作


(2)编辑距离的计算
设定编辑距离为k,首先为了避免把拼音串看成英文字母串进行字母替换后,造成拼音串本身的不合法,通过拼音AC 自动机的匹配对替换后拼音串的合法性进行判别。针对第一种情况,对替换中的对象词进行拼音AC 自动机的匹配,匹配过程与精确匹配过程一致,匹配失败则进行下一次匹配,获取匹配成功的匹配串的词条信息,然后将匹配成功的词条信息中的全拼与识别串的全拼比对,计算出编辑距离k,当编辑距离k<TH(其中TH为预先设定的阈值)时保留匹配串的匹配结果,将标定过的拼音首字母对编辑距离进行替换,最终比较阈值内编辑距离的替换串的匹配结果。
综上,根据语法模型实现对识别串的模糊替换,该匹配过程虽然需要遍历近邻空间的操作,但是结合语法模型和拼音首字母下的AC自动机能大大减少检索的时间复杂度,模糊匹配过程实际上也就是分成多个精确匹配,模糊匹配结果即最后基于编辑距离下阈值范围内的有效结果。
3 测试与验证
3.1 数据的准备
实验中使用的电力巡检指令词汇数据来源于南京国网公司,该公司提供的电力词条约5500 个,本实验召集20 位录音者进行语音的读录,每人录入约1000句音频,音频时长共计约25小时,通过调用科大讯飞的API对录制好的音频进行语音识别,识别串的错误类型如表2所示。

表2 识别串结果
由表可知,语音识别结果中错误类型主要为同音字错误和别字错误,本实验对该10875 个错误结果进行语音识别后文本的纠错算法的验证分析。该识别结果中的错误串可以被认为是在实际的电力语言环境中电力巡检人员语音识别下的误识别结果,纠正结果的正确率是需要考虑的重要指标。
3.2 评价指标
本实验主要对查错和纠错算法性能展开评价,其中查错算法性能主要采用时间复杂度、准确率[12](Precision,又为查准率)、召回率[6](Recall,又为查全率)作为评价标准;纠错算法的评价指标主要采用词错误率[13](Word Error Rate,WER)和句错误[14](Sentence Error Rate,SER)率来判断模型的算法的有效性。计算公式见式(1)、式(2)、式(3)、式(4)。
1)时间复杂度
为评判不同算法的时间复杂度,本文考虑采用时间频度来反映,即计算同一问题规模下算法完成匹配所耗时间。响应时间越长,说明其时间复杂度越高,匹配算法越复杂;若响应时间越短,则说明其时间复杂度越低,定位算法性能越好。
2)查准率

3)召回率

4)词错误率

其中,Insertions表示插入错误的词数,Deletions表示删除错误的词数,Substitutions表示替换错误的词数,Numbers表示句子中的总词数。
5)句错误率

3.3 数据分析与验证
数据分析与验证的目的分为四点。第一,验证AC 匹配算法相较于其他模式匹配算法更高效;第二,判断查错和纠错算法的时间复杂度是否有良好的表现;第三,测试基于模式匹配的纠错算法对实际数据的纠错能力;第四,检验模糊匹配的纠错算法较精确匹配算法的纠错能力改进程度。
本实验的文本集合的规模为20000,每个识别串包含的结果数在3~25 个不等,其中正确的识别串占比45.6%,错误的识别串占比54.3%,错误的识别串不同类别数量如图8。

图8 错误识别串类别图
数据分析与验证的评价过程包括时间复杂度评估和纠错结果对比分析,且设计以下几组方案展开对比验证。方案1,传统的N-gram 模型纠错算法,通过建立统计词与字的N元语法模型进行查错和纠错;方案2,基于序列对序列神经网络的修正ASR误差的后处理模型;方案3,只采用精确匹配下的语音识别后文本纠错算法;方案4,采用精确匹配和模糊匹配结合的语音识别后文本纠错算法。
1)时间复杂度验证
(1)AC匹配算法的时间复杂度验证
为了验证AC匹配算法是否高效,设计了AC算法与BF 算法、KMP 算法、Shift-And 算法的匹配时间对比实验,来具体分析AC 算法在时间复杂度上的性能。实验中识别串文本规模的集合为{1000,2000,3000,4000,5000,6000}。算法对比结果如图9所示。

图9 四种算法的匹配时间
由图9 可知,较其他算法AC 算法的匹配时间最短,时间复杂度最低,在巡检指令词的查错中能够更高效地进行识别串的匹配,很大程度上节省了时间开销,提升了性能。
(2)纠错算法时间复杂度验证
为了进一步进行时间复杂度的检验,分别对以上四种方案的纠错过程展开验证,图10 显示了四种纠错方案的纠错时间对比结果。

图10 四种方案纠错时间对比结果
图10 中可以看出,基于模式匹配的纠错过程时间复杂度最低,能够快速地实现纠错任务,虽然随着文本规模的增大与精确匹配相比会增加一部分时间的消耗,但是仍能保证较低的时间复杂度,纠错时间有很大的优势。
2)纠错结果对比分析
纠错算法的对比分析过程,首先分别进行查准率和召回率的分析,来验证方案的查错能力,然后通过比较词错误率和句错误率,来验证方案的纠错能力,纠错对比结果如表3 所示,纠错后错误类型对比情况如图11所示。

图11 纠错后的错误类型

表3 纠错结果对比分析
从表3 可以看出,通过分析方案的查准率和召回率,本方案基于模式匹配的算法,通过结合AC自动机和语法模型,在巡检指令词的查错中达到了85%以上的准确率,远高于通用的查错方式。
另外,通过分析词错误率和句错误率,基于模式匹配的纠错算法词错误率至少降低了12.37%,句错误率至少降低了17.28%,相较于传统的纠错算法,方案3 和方案4 在电力巡检指令词的纠错上有明显的改进。
其次,结合图11 分析可知,与模式匹配下的精确匹配纠错相比,模糊匹配提升了对于别字错误的纠错能力,保证查错能力稳定的同时进一步提升了纠错效果,在纠错性能上能有更好的实际表现。
综上所述,可以验证基于模式匹配的纠错算法对实际数据的纠错能力有进一步改善,且模糊匹配算法对模式匹配下的精确匹配算法纠错失败的识别串能进行准确修正,有巨大的实际应用价值。
4 结语
本文从现有的语音识别技术出发,对面向电力巡检语音指令识别后的文本纠错算法展开研究,得出结论如下。
1)提出了构建电力词汇库的语法模型,在查错和纠错过程中提供语法原则,提升了纠错效率;
2)利用AC 自动机高效匹配的优势,将其应用于语音识别后文本的纠错中,通过建立汉字和拼音AC自动机实现了电力巡检指令词的语音识别后文本的查错与纠错,保证了在较低的时间复杂度下对同音字词的纠错正确率;
3)针对精确匹配依然会存在纠错失败的情况,提出了模糊匹配纠错算法,该算法进一步解决了别字错误类型的纠错,在性能上满足了实际的需求,能够较好地完成电力语音后文本的纠错;
4)在实际的电力词汇语音识别后文本中,虽然同音字错误、别字错误类型占有最大的比例,但是还有其他类型的错误,例如缺字或多字错误等,本方案在此类型的语音识别后文本错误类型上不能有很好的性能表现,需要进一步的研究。
未来,计划将本文提出的纠错算法应用于实际的电力环境中,考察长期实际应用下的精确匹配和模糊匹配的算法性能,并进行有效地改进。
猜你喜欢
华文教学与研究(2022年1期)2022-04-27
社会科学战线(2022年2期)2022-03-16
电脑知识与技术·经验技巧(2020年3期)2020-05-07
华东师范大学学报(自然科学版)(2020年1期)2020-03-16
华东师范大学学报(自然科学版)(2019年2期)2019-06-11
小天使·一年级语数英综合(2015年8期)2015-07-06
小天使·一年级语数英综合(2015年2期)2015-01-14
