
基于局部敏感哈希的隐私保护实时服务推荐*
2022-02-16 08:32和凤珍
计算机与数字工程 2022年1期
和凤珍
(1.丽江文化旅游学院信息学院 丽江 674199)(2.丽江师范高等专科学校数学与信息技术学院 丽江 674199)
1 引言
信息技术和互联网的快速发展改变了人们的生活消费方式,同时也产生了信息过载问题。如何快速从过载的信息中提取有价值的、能够满足用户需求的信息仍具有挑战性。服务推荐(如文献推荐[1~2]、健康推荐[3]、新闻推荐[4~5]、电影音乐推荐[6~8]等)是解决信息过载问题的有效方式之一。
研究人员已经提出一些推荐算法和模型,其中协同过滤推荐方法是最有效的,也是应用最为广泛的推荐算法[6,9]。协同过滤算法分析用户的历史行为数据并为其自动推荐一些与用户兴趣爱好相匹配的top-k物品,其侧重于改善推荐结果的准确度,却忽略了推荐效率。
例如,k 近似最近邻(Approximate Nearest Neighbor,ANN)协同过滤算法通常需要穷举搜索数据集中所有用户或物品才能发现k个最近邻居。其计算代价非常高,尤其是在大体量数据中。现有n个用户和m个项目,利用余弦距离进行相似度计算时,基于用户的协同过滤推荐算法时间复杂度为n2m;基于项目的协同过滤推荐算法时间复杂度为m2n,而且用户、物品的数量及用户行为数据更新频繁。基于矩阵分解的协同过滤算法[10]在Netflix 大赛中表现突出,其需要经过模型训练和推荐两个步骤。尽管模型训练可以离线完成,但是,用户、物品的数量及用户行为数据更新频繁,模型也需要频繁调整更新。这些都将降低协同过滤推荐算法的效率,影响服务推荐的体验效果。
此外,用户的历史评级数据可能包含用户的隐私信息,可能被非法使用,甚至转售。然而,大多数现有的协同过滤推荐方法很少考虑隐私保护。这可能导致用户隐私泄露的风险升高。
考虑到传统协同过滤算法存在的上述问题,我们对传统协同过滤算法进行扩展:结合高效率的局部敏感哈希技术挖掘相似项,在此基础上提出基于局部敏感哈希(Locality Sensitive Hashing,LSH)的协同过滤(Collaborative Filtering,CF)算法(简写为LSHCF)。LSHCF算法利用了局部敏感哈希函数的性质和其在效率上的优势以及协同过滤算法较高的准确度,从而使得我们的服务推荐算法在准确率和效率上取得较好折衷,同时还保护了用户隐私。
文章主要的贡献如下:
1)利用局部敏感哈希技术过滤了绝大多数不相似的项目,降低了相似度的计算时间;同时,利用哈希技术将用户行为数据哈希为二进制哈希编码,保护了用户隐私。
2)提出一种新的基于局部敏感哈希技术的协同过滤算法LSHCF,算法还在评分预测时考虑了相似项的相似度。
3)在不同规模的数据集上实验,实验展示了我们算法在效率和准确率上具有较好的折衷。
2 相关工作
Resnick[11]等提出了推荐系统的概念,随着信息技术和互联网的快速发展,推荐系统吸引了学术界和工业界越来越多的关注,成为一个非常重要的研究领域。
文献[12]最先使用协同过滤推荐算法开发Tapestry 推荐框架,解决电子邮件信息的过载问题。Herlocker[13]等提出基于用户的协同过滤算法,主要思想是从评分信息中发现与当前用户偏好相似的最近邻居,通过整合这些邻居的偏好进行评分预测,最后生成推荐结果列表回显给当前用户,其模拟的是一种“人以群分”的思想。但是,评分矩阵中,用户的评分信息会经常频繁更新,这将导致每次推荐后都需要重新进行相似度和最近邻居的计算。尤其是在大数据中,用户规模较大,基于用户的协同过滤系统效率较低。
为解决文献[13]中的效率问题,Sarwar[14]提出基于项目的协同过滤推荐算法,其模拟的是一种“物以类聚”的思想,与基于用户的协同过率算法不同之处在于文献[14]的相似度是在物品与物品之间进行计算的,使用该方法计算项目之间的相似度较稳定。相似度和最近邻居的计算过程可以离线进行,在系统用户数量远小于物品数量的情况下,基于项目的协同过滤算法可提高系统效率[8],显然,基于项目的协同过滤算法在大数据系统推荐时效率也较低。
上述基于邻居的协同过滤算法是比较经典的推荐技术,能够获得较高的准确度。但是,基于邻居的协同过滤算法是基于内存进行计算的,需将评分矩阵数据全部装载到内存后进行计算,当用户或物品的规模非常大时,无论是基于物品的协同过滤还是基于物品的协同过滤在相似度的计算过程中都会非常耗时,时间开销代价大。评分矩阵中包含的评分数据越多,协同过滤推荐算法将获得较高的推荐精度,而实际上,用户不愿意主动对物品评分,系统引导用户进行评价的激励机制也并不多,导致评分矩阵的稀疏率较高[1~2],影响推荐结果的准确度。为解决基于邻居的协同过滤算法存在的问题,提 出 了Singular Value Decomposition(SVD)[15]、Non-negative Matrix Factorization(NMF)[16]等基于矩阵分解的模型推荐算法和基于聚类[17~18]的模型推荐算法。基于模型的协同过滤推荐算法需进行训练和推荐两个步骤,先利用历史数据离线训练得到一个模型,再利用该模型快速进行评分预测和推荐。然而,用户的行为数据经常被频繁更新,模型也需要不断的训练更新,在大体量数据下不能及时产生推荐结果,无法满足用户实时响应的需求。
综上,在大数据背景下,传统协同过滤算法的效率受到用户和物品的规模巨大,用户行为数据频繁更新等因素的影响;其很少考虑用户隐私,可能存在用户隐私泄露问题。因此,提出新的基于局部敏感哈希的协同过滤推荐算法实现高效率推荐和用户隐私保护。
3 我们的方法
3.1 局部敏感哈希
Gionis[19]提出了LSH概念并证明是一种高效率的近似查询方法。得益于LSH函数的特性,其查询结果的准确度也较高,被广泛应用到视频、图像检索等领域。LSH 的核心思想是原来相似或相近的项目被局部敏感哈希函数哈希到同一个“桶”中的概率很大,而不相似或离的较远的项目被哈希到同一个“桶”中的概率很小。其过滤掉大多数不相似的项目,降低了相似度计算的数量,提高了计算效率。
文献[19]将LSH函数定义如下。

3.2 基于局部敏感哈希的隐私保护推荐方法


3.2.1 初始化
在初始化阶段,输入评分矩阵M中用户数量n,LSH tables 数量h以及每个LSH table 包含LSH functions的数量r,根据算法1完成初始化工作。

3.2.2 离线生成索引
在离线生成索引阶段,需对评分矩阵M中每个用户或者项目进行哈希,每个哈希函数哈希后都会得到一个0 或1 的布尔值,经过LSH table 中的哈希函数哈希后生成一串由0和1组成的二进制哈希编码,该二进制哈希编码可当作索引,遍历完所有LSH tables 后生成一个局部敏感哈希索引表,具体如算法2。


3.2.3 查找最近邻居

3.2.4 评分预测
算法4 对未评分项目集合unrated_set 中每一个项目i利用式(5)进行评分预测,sim()i,m是i与m的相似度,使用Pearson Correation Coefficient距离计算相似度。


3.2.5 Top-k推荐
选择邻居集合中评分大于阈值threshold 的项目作为候选集,按照评分降序排列后取前k项作为推荐结果集,具体如算法5。

4 实例
为更加简洁明了地理解我们提出的方法,本节通过一个实例进一步详述所提算法。如表1 所示,现有6 个用户对5 个物品的评分数据,其中0 表示用户尚未对物品进行评分。矩阵中每一行代表一个用户向量。

表1 用户-项目评分矩阵

步骤1:初始化。我们从[-1,1]中随机生成6个向量v,如等式(6),v中每一行为一个向量。为方便演示,我们仅使用1个LSH table。
步骤2:离线生成索引。将每个用户向量与向量v中的每个向量按照式(3)、(4)的局部敏感哈希函数建立索引,将每次哈希后得到的0 或1 的二进制哈希编码合并后便可以得到每个用户的二进制哈希编码索引。经过计算后,得到用户u0,u1,u2,u2,u3,u4,u5,u6的二进制哈希编码分别为001011,001011,000111,010011,000101,010111,001011。
步骤3:查找最近邻居。设用户u6为目标用户,查找与用户u6在同一个LSH table 中并且具有相同二进制哈希编码的邻居有u0,u1。
步骤4:评分预测。通过PPC 相似度计算得到用户u6与用户u0,u1的相似度分别为0.302325,0.413665。利用式(5)计算用户u6尚未评分的物品i1,i3。

步骤5:top-1 推荐。按照评分降序排列,选择评分大于阈值0.5的top-1物品i1推送给用户u6。
5 实验
实验环境为Win 10 专业版64bit,Intel Core i7-3367U CPU,RAM 8GB,程序设计语言为Python3.8,实验使用Anaconda3(64-bit)开发工具,采用k折交叉验证法,实验结果为重复执行实验50次后的平均值。实验在MovieLens(http://grouplens.org/datasets/movielens/)ml-latest-small(简 写为ml-small),ml-1m 两个不同规模的数据集上对比所提方法的效率,同时与主流了协同过滤算法对比所提方法的准确度。两个数据集的详细信息如表2所示。

表2 数据集
5.1 评价指标
效率上使用时间开销进行度量;准确率上,文献[13]对协同过滤推荐系统提出了度量方法,本文也是一种基于协同过滤的top-k推荐,实验结果的准确度采用文献[13]中的F1 作为度量标准,F1 定义如下:

其中,R(u)为用户u的推荐结果集,T(u)为测试集中用户u喜欢的物品集合。
5.2 对比算法
我们从准确率和效率两个方面与下面主流的协同过滤算法进行对比,这些主流算法能够获得较高的准确率、效率。
UBCF:文献[13]提出的基于用户的协同过滤推荐算法,能够获得较高的准确率,同时,当用户数量远小于项目数量时,UBCF还能获得较高的效率。
IBCF:文献[14]提出的基于项目的协同过滤推荐算法,能够获得较高的准确率。
LSHCF:我们提出的基于局部敏感哈希技术的协同过滤推荐算法。
5.3 实验结果
5.3.1 选择参数tables和functions
实验设置LSH tables、LSH fuctions 的数量均为[2,4,6,8,10],当LSH tables 取2 的时候,观察F1值在LSH fuctions 在[2,4,6,8,10]上的变化情况,改变LSH tables 的数量,进行25 组实验,每组实验重复进行50次。F1的变化情况如图1所示,从图1可以观察到,随着LSH tables 数量的持续增加,准确率先上升,再保持稳定,后下降。也就是说,LSH tables 的数量应适量。随着LSH fuctions 数量的增加,准确率整体呈上升趋势,LSH fuctions 数量增加,计算量也将增大。综合图1 中(a)、(b)两图可以观察到:LSHCF在LSH tables取6,LSH fuctions取10时能够获得较高的准确率。

图1 LSHCF在不同tables和functions的F1
5.3.2 LSHCF推荐结果准确率
在LSH tables=6,LSH fuctions=10 时,观察topk与precision,recall 和F1 的变化情况。由图2 可以看出,随top-k 不断增大,四种推荐算法的precision 呈下降趋势,LSHCF 推荐算法表现最好。由图3 可以看出,随top-k不断增大,四种推荐算法的recall 呈上升趋势。由图4 可以看出:在两个不同规模尺寸的数据集上,UBCF 和IBCF 协同过滤推荐算法的F1相当;我们提出的LSHCF在top-k=5时能够取得与UBCF 和IBCF 相当的准确度,随着top-k的不断增大,LSHCF 的F1 值在提高。与主流算法对比显示,LSHCF能够取得较好的准确率。

图2 top-k下precision的变化
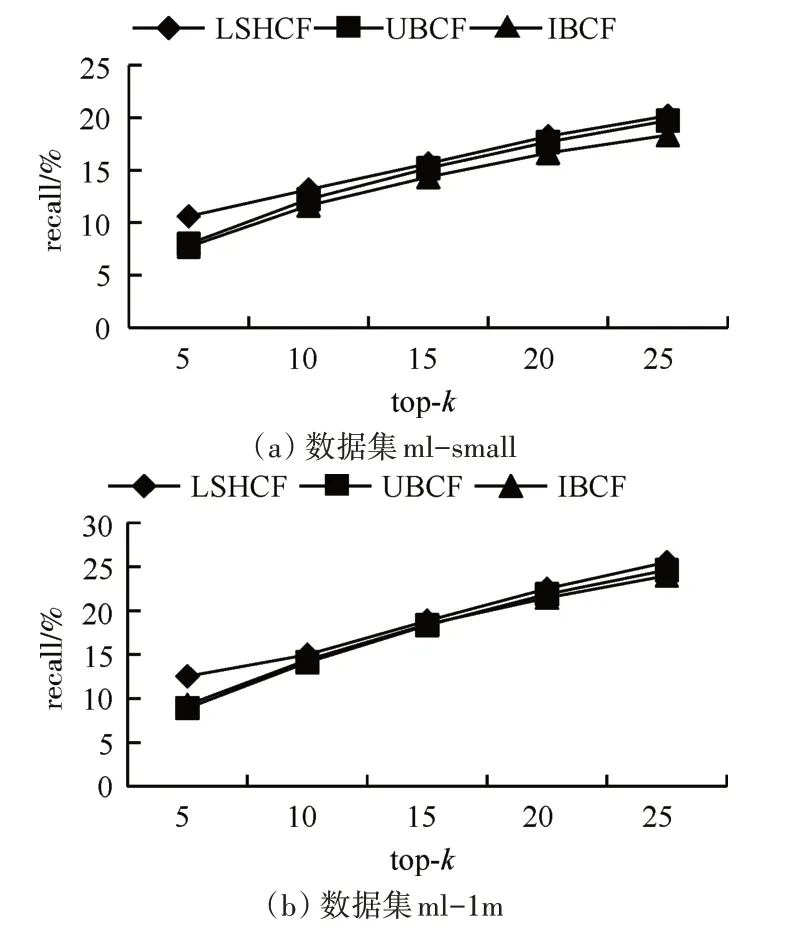
图3 top-k下recall的变化

图4 top-k下F1的变化
5.3.3 效率
在同样的实验设置下,我们进一步观察LSHCF的效率。从图5 中可以看到,LSHCF 随数据规模的增加,LCHCF算法推荐效率仍较高。

图5 top-k下F1的变化
6 结语
我们提出的基于局部敏感哈希的隐私保护实时服务推荐方法LSHCF,能够获得较好的准确率和效率上的折衷,同时保护了用户隐私。所提算法仅使用了用户评分矩阵,后续将考虑利用更多的项目信息(如类别、时间等)进一步扩展算法,改善推荐质量。
猜你喜欢
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
电脑爱好者(2021年8期)2021-04-21
电脑爱好者(2021年1期)2021-01-13
健康体检与管理(2021年10期)2021-01-03
电脑爱好者(2020年20期)2020-10-22
读与写·教育教学版(2017年10期)2017-11-10
南都周刊(2015年4期)2015-09-10
南都周刊(2015年3期)2015-09-10
