
基于Hadoop的DDoS 双属性检测算法研究
2022-02-15 09:35:26程家兴罗文华
佛山科学技术学院学报(自然科学版) 2022年1期
程家兴,罗文华
(中国刑事警察学院 公安信息技术与情报学院,辽宁 沈阳 110035)
分布式拒绝服务(DDoS)攻击能够瞬间发动极大量的攻击使服务器瘫痪,导致其无法正常提供服务[1]。DDoS 攻击者首先通过恶意程序感染多台处于互联网络中的主机,从而对这些主机进行控制,被控制的主机丧失自主权,称为“僵尸机”或者“肉鸡”,攻击者再通过控制这些“僵尸机”对被攻击者发送大量攻击数据包,一般来说,攻击者控制的“僵尸机”数量越多,造成攻击的威力越大。相较其他类型的网络攻击,由于存在多个中转的“僵尸机”,让DDoS 具备了分布式的特点,通过无规律、隐藏的数据源,将传统的单点之间数据攻击变为多点的数据流攻击,且发送的流量本身几乎不包含恶意数据信息,涉及协议与服务的恶意攻击与正常连接请求界限模糊。因此,无论是对DDoS的检测还是防范难度都相当大。
当前存在大量对其进行检测防范的研究,采取的方法大致可分为两种,第一种基于机器学习和神经网络,通过分析流量特征差异来确定攻击流量,另一种则是基于统计模型,通过分析输入流量和正常流量数据量差异来检测。Hameed S 等人提出过一种基于Hadoop的分布式检测框架[2],该算法运用统计计数,能够完成实时自动的DDoS 攻击检测,随着研究深入,发现适应于其中的传统计数算法存在一定的局限之处,本文将统计与流量特征结合,基于MapReduce 框架编写新的检测算法,并与传统计数算法进行对比,根据多方面的检测数据综合分析,研究不同DDoS 攻击环境中最为适合的检测算法。
1 MapReduce 架构与DDoS 检测模型
1.1 MapReduce 架构
MapReduce的框架结构主要由Client、JobTracker、TaskTracker 以及Task 四部分组成[3],各组成部分间的关系如图1 所示。其中,Client 主要为用户与JobTracker 端提供接口,用户能够直观地查看任务的运行。JobTracker 负责监测与调度TaskTracker 与Job,是MapReduce 框架的核心部分,与框架的其他部分均存在联系。TaskTracker 通过“心跳”周期性向JobTracker 发送本节点的运行状态,同时对JobTracker分配过来的命令等进行处理。Task 为MapReduce 任务部分,分为Map Task 与Reduce Task[4]。
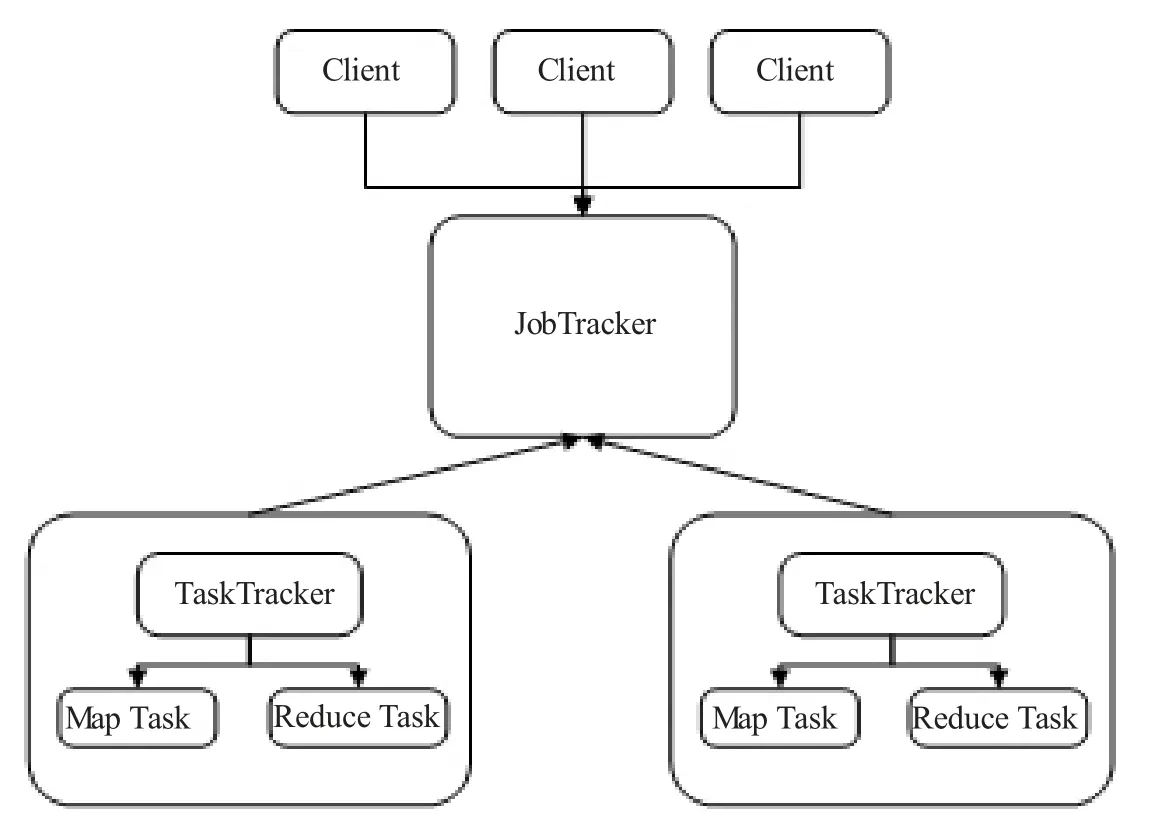
图1 MapReduce 组成框架
1.2 DDoS 检测模型
检测模型基于Hadoop 架构搭建,包含一个主节点和若干个从节点,其中主节点同时充当检测核心,数据的输入以及检测形成结果到最后的输出均在此检测核心中进行。
该模型主要包含两个部分,第一部分为数据的输入部分,第二部分为检测部分,模型能够完成输入日志的检测并生成结果。
(1)数据输入。输入的数据均为通过Tshark 收集的DDoS 攻击流量日志,部分日志文件如图2 所示,其中一条描述结果如下:11 3.775 426 138 192.168.253.179→192.168.253.175 TCP 74 41 910→80[SYN] Seq=0 Win=29 200 Len=0 MSS=1 460 SACK_PERM=1 TSval=287 474 TSecr=0 WS=128,其中,11代表此条数据序号,3.775 426 138 为Tshark 计算的时间戳,192.168.253.179 为源IP,192.168.253.175为目的IP,TCP 代表此条数据的使用的协议类型,74 为此条数据的数据帧长度,41 910 为源端口,80 为目的端口,之后为具体的TCP 协议信息。模型的检测核心为Hadoop的主节点,实验中在此主节点设计一个简易的Java 程序,通过该程序对输入日志进行调控,完成日志接收之后随即将该日志文件上传HDFS 之中[5]。

图2 部分输入日志
(2)执行检测。集群通过中央管理器将HDFS 中的输入日志划分成各种日志碎片,这些片段有序化处理之后进入MapReduce 阶段,通过检测算法的Map 和Reduce 两个函数对输入的日志碎片进行检测,形成输出文件。MapReduce 阶段之后,输出的文件会再次返回HDFS 之中,集群的中央管理器能够对HDFS 中的文件进行解析,生成最终的检测结果,可通过调控检测核心中的Java 程序将该结果从HDFS 中调出。
检测模型通过以上运行阶段,对输入的日志文件执行检测并生成检测结果,整体运行过程如图3所示。
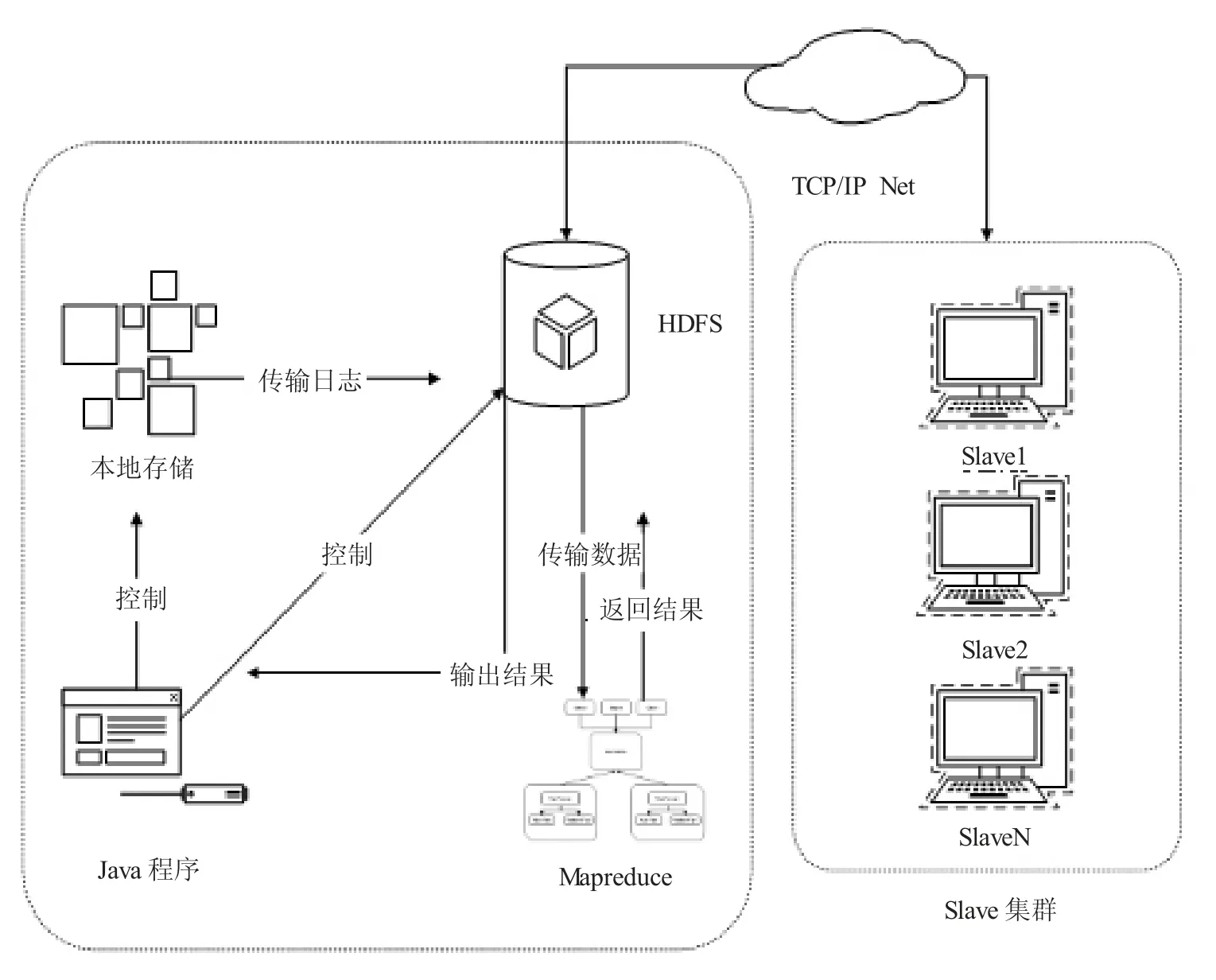
图3 基于Hadoop的DDoS 检测模型
2 双重属性Counter-Based 算法
本文提出的检测算法,本质为基于异常的计数算法[6],该类型的检测算法从网络流量包的特征属性出发,通过统计计数的方法确定攻击来源。对DDoS 攻击数据进行区分,需要根据计数的数量设定一定的界限,计数数量超过此界限的数据就被认定为攻击数据,这个界限可被称作阈值,根据MapReduce的运行模式以及实际环境中DDoS 攻击强度,实验统一采用每秒800 数据包的阈值[7]。
2.1 算法思路
通过对输入的DDoS 攻击流量日志进行研究,发现流量存在的几项特征属性能够被统计分析,包括源IP、数据类型、数据帧大小,根据不同的特征组合能形成不同类型的检测算法,随着组合数量的增加,算法的复杂度也会提升,这些都会对检测产生影响。
单一属性Counter-Based 算法[8]采取源IP 这种单一的特征作为检测标准,该算法的检测原理为:一定时间内访问服务器的单一IP的流量超过实验所设定的阈值,此IP 就被认定为攻击IP,来源于此IP的流量就被认定为攻击流量[9]。通过近期的研究发现,该算法在实际的DDoS 检测环境中存在一定局限性,由于算法过于简单,只存在源IP 这一种检测参数,对DDoS 攻击的检测率不高,当前发动的较为广泛的多IP 攻击行为,攻击者通过控制大量“僵尸机”,而每台“僵尸机”又伪造多种不同的IP 对服务器进行攻击,此种情况下,单一IP的攻击流量往往难以达到阈值标准,因此存在较多的漏报,此时仅采取源IP 这种单一的检测方式难以准确感知DDoS 攻击。对于这种伪造多IP的攻击方式,需要寻找更多流量的特征项进行识别。通过研究发现,攻击者伪造大量IP 发送的攻击数据包往往具有相同的长度,此时采取数据帧长度作为计数的特征参数更为合适。因此将最具有识别价值的源IP 与数据帧大小提取进行组合,形成双重属性Counter-Based 算法。
2.2 算法伪代码
该算法的检测类型包括TCP-Flood、UDP-Flood、ICMP-Flood、HTTP-Flood,以下为算法执行TCPFlood 检测过程的伪代码,执行Mapredcue 之前,输入的日志文件会被划分成新的日志碎片,这些日志碎片经过Map 和Reduce 两个函数阶段最终形成输出文件。

Map 阶段,该函数作用是从输入的日志碎片中提取相应的网络数据特征值,包括源IP、数据帧长度、数据类型,首先过滤包含TCP的碎片,然后将源IP 和数据帧长度分别与TCP 组合形成<源IP,TCP,1>、<数据帧长度,TCP,1>两种类型的输出数据,其中1 代表形成单一键值对。

Map 函数的输出值作为Reduce 函数输入值进行计算,Reduce 函数将输入的形如<源IP,TCP,1>、<数据帧长度,TCP,1>的相同键值对进行统计计数,相同源IP的计数结果为Counts1,相同数据帧长度的计数结果为Counts2,并将两项计数结果与指定的阈值进行比较,如果小于阈值,则被认定为合法数据,如果大于等于阈值,则被认定为攻击数据,并将计数后键值对进行输出,形成
3 检测算法的实验测试
3.1 实验环境配置
检测模型包含的多个节点均运行于Ubuntu 虚拟机之中,并采用桥接的模式连接到互联网之中,保证集群的各节点之间能够通过TCP/IP 协议进行交互,虚拟机的配置如表1 所示。

表1 检测模型虚拟机配置
3.2 实验参数
依据将要进行实验测试的性能指标,需要配置不同的实验环境,与集群运行相关的参数包括输入DDoS 攻击日志的大小、Hadoop 集群规模、DDoS 攻击比例、HDFS 分块大小。根据测试需要,实验参数可以进行调整,以保证实验的准确性,以下对实验涉及的具体实验参数进行分析。
(1)日志大小。基于实验机器的性能考虑,实验选择10 M,20 M,40 M,80 M 大小的输入日志。
(2)集群规模。检测模型采用典型的完全分布式的Hadoop 架构,设置一个主节点和若干从节点,实验中部署1~4 个从节点来进行测试。
(3)DDoS 攻击比例。DDoS 攻击比例为监听日志中DDoS 攻击流量和合法访问流量的比例,该比例的改变会影响检测模型执行检测的时间,为了保证日志文件大小这一单一变量的原则,检测时间与检测结果对比实验中,统一采用70%DDoS 攻击比例(DDoS 攻击流量占比70%,合法访问流量占比30%)的输入日志,检测率实验中,增加90%DDoS 攻击比例的输入日志进行对比。
(4)HDFS 分块大小。HDFS 分块为集群存储计算的基本单位,实验采取16 M,32 M,64 M,96 M 作为测试的HDFS 分块大小。
3.3 两种检测算法的对比研究
不同的检测算法会影响输入日志检测的时间,执行不同算法对DDoS 攻击的检测率与生成的检测结果也有所不同,本节通过检测时间与检测率以及输出结果三方面对两种检测算法进行对比。
3.3.1 检测时间对比
(1)改变HDFS 分块大小。本节实验设定HDFS 分块大小分别为16 M,32 M,64 M,96 M,从节点数量为2 个,输入日志大小为80 MB,执行两种检测算法的时间如图4 所示。
通过图4 可以看出,当HDFS 分块大小为16 M 时,执行单一属性Counter-Based 算法、双重属性Counter-Based 算法时间分别为22.8 s、33.1 s,随着算法复杂度的提升,执行检测的时间增加较为明显,且随着HDFS 分块的改变,不同检测算法执行时间的差值基本保持不变。
(2)改变集群规模。本节实验设定HDFS 分块大小为64 MB,从节点数量为1~4 个,输入日志大小为80 MB,执行两种检测算法的结果如图5 所示。
图5 显示的实验结果与图4 较为类似,随着从节点数量的增加,模型执行两种算法的时间均存在一定的下降,但两种时间的差值较为稳定。

图4 HDFS 分块大小对不同检测算法检测时间的影响
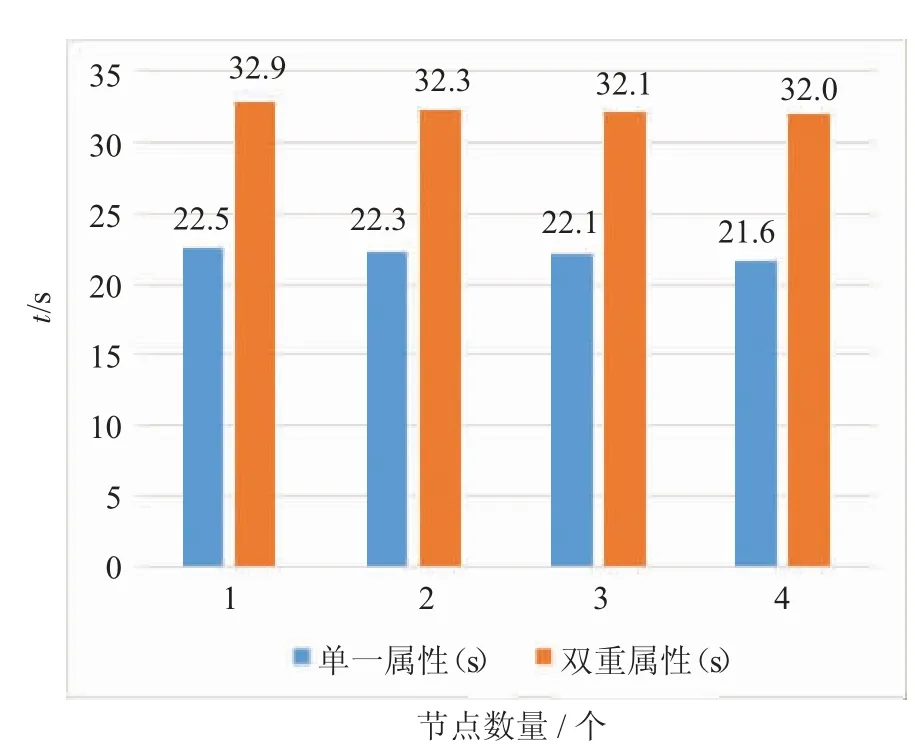
图5 集群规模对不同检测算法检测时间的影响
(3)改变输入日志大小。本节实验设定HDFS 分块大小为64 MB,从节点数量为2 个,输入日志大小分别为10 M,20 M,40 M,80 M。执行不同检测算法检测相同输入日志所用时间如图6 所示。
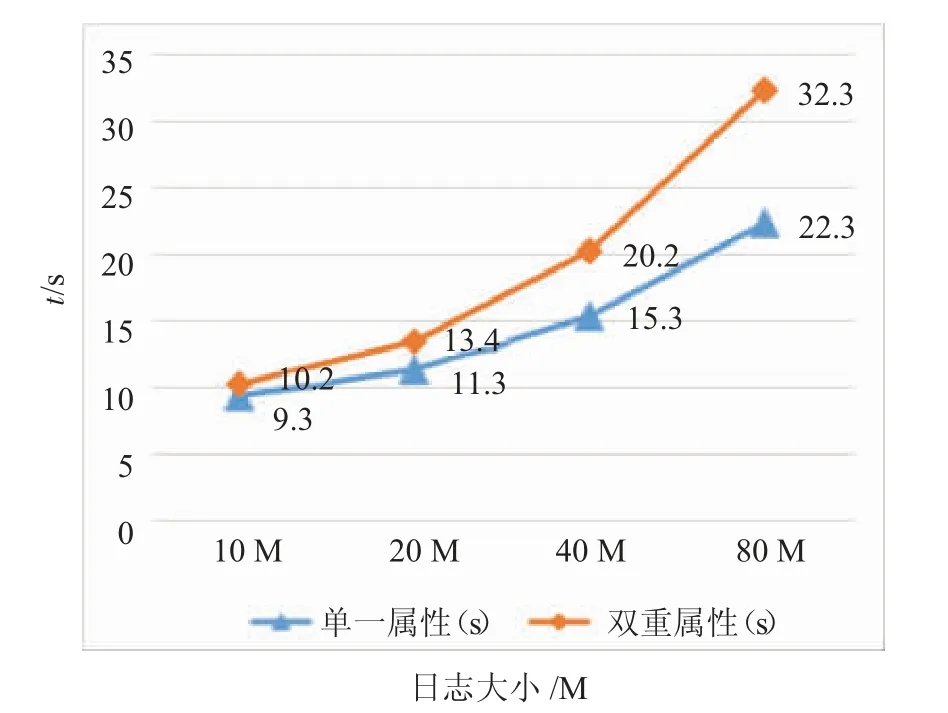
图6 输入日志大小对不同检测算法检测时间的影响
通过图6 可以发现,随着输入日志大小的变化,检测时间的差距逐渐在变化,当输入监听日志为10 M 时,单一属性Counter-Based 算法、双重属性Counter-Based 算法检测时间分别为9.3 s、10.2 s,当监听日志为80 M 时,两种算法的执行时间变成22.3 s、32.3 s,其中的差值正在逐渐增大,从折线图中很容易看到这一趋势,在处理大文件时,这种时间上的差值更应该被考虑到。
单纯从检测时间的角度来看,随着算法复杂度的提升,对相同输入日志检测的时间变化明显,且随着输入日志容量的增加,这种时间差正在加剧。
3.3.2 输出结果对比
根据检测算法的编写原理,对比单一属性Counter-Based 算法,执行双重属性Counter-Based 算法能够获得DDoS 攻击数据包的数据帧长度,通过增加数据帧长度的验证,能够获得更为准确的检测结果。两种检测算法对同一输入日志的检测结果如图7、8 所示。
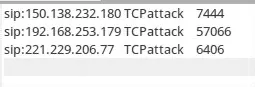
图7 单一属性Counter-Based 算法检测结果
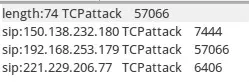
图8 双重属性Counter-Based 算法检测结果
3.3.3 检测率对比
针对检测率的对比,实验收集了两种不同DDoS 攻击比例的输入日志进行多次测试。HDFS 分块大小为64 MB,从节点数量为2 个,输入日志大小为80 M,DDoS 攻击比例分别为70%和90%,使用两种检测算法分别进行测试,实验结果如图9 所示。
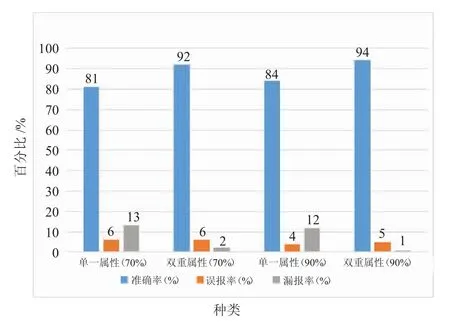
图9 两种检测算法检测率对比
实验结果显示,无论是在70%还是90%的DDoS 攻击比例的实验测试环境中,双重属性Counter-Based 算法对DDoS 攻击都存在极高的检测准确率,误报率较低,而单一属性Counter-Based 算法的误报率与双重属性Counter-Based 算法接近,但却存在较高的漏报,准确率不足。因此,从检测率上来看,单一属性Counter-Based 算法检测效果不如双重属性Counter-Based 算法。
4 结语
本文针对适应于Hadoop 架构的DDoS 检测算法进行分析,根据实际中的运行要求,提出双重属性Counter-Based 算法,并与传统的单一属性Counter-Based 算法从检测时间、检测率、检测结果三方面进行对比,研究两种检测算法在不同DDoS 攻击环境的检测效率。其中,在检测时间方面,处理相同的输入日志,单一属性Counter-Based 算法拥有更快的检测速度,但在检测结果与检测率方面,双重属性Counter-Based 算法拥有更大的优势。在多数情况下,对于DDoS 检测模型来说,检测率应放在首位,此时,双重属性Counter-Based 算法具有更优的检测效率。
面对未来更为复杂的DDoS 攻击形式,需要对网络数据的特征值再次进行发掘,进行更多类型的组合实验,编写适应环境更为广泛的检测算法。
猜你喜欢
华人时刊(2021年13期)2021-11-27 09:19:02
心声歌刊(2020年4期)2020-09-07 06:37:14
中外女性健康研究(2020年10期)2020-08-02 11:03:18
山东农业工程学院学报(2020年12期)2020-03-19 01:58:44
中国医学创新(2019年9期)2019-08-19 01:35:26
小学生(看图说画)(2017年6期)2017-11-06 06:48:08
医学信息(2017年16期)2017-09-05 15:34:20
建筑建材装饰(2016年13期)2017-01-04 22:55:47
湖州师范学院学报(2016年2期)2016-08-21 13:50:52
山西大同大学学报(自然科学版)(2016年6期)2016-01-30 08:29:19
