
基于改进YOLOv4模型的全景图像苹果识别
2022-02-15 01:22周桂红梁芳芳
农业工程学报 2022年21期
周桂红,马 帅,梁芳芳
基于改进YOLOv4模型的全景图像苹果识别
周桂红,马 帅,梁芳芳
(1. 河北农业大学信息科学与技术学院,保定 071001;2. 河北省农业大数据重点实验室,保定 071001)
苹果果园由于密植栽培模式,果树之间相互遮挡,导致苹果果实识别效果差,并且普通的图像采集方式存在图像中果实重复采集的问题,使得果实计数不准确。针对此类问题,该研究采用全景拍摄的方式采集苹果果树图像,并提出了一种基于改进YOLOv4和基于阈值的边界框匹配合并算法的全景图像苹果识别方法。首先在YOLOv4主干特征提取网络的Resblock模块中加入scSE注意力机制,将PANet模块中的部分卷积替换为深度可分离卷积,且增加深度可分离卷积的输出通道数,以增强特征提取能力,降低模型参数量与计算量。将全景图像分割为子图像,采用改进的YOLOv4模型进行识别,通过对比Faster R-CNN、CenterNet、YOLOv4系列算法和YOLOv5系列算法等不同网络模型对全景图像的苹果识别效果,改进后的YOLOv4网络模型精确率达到96.19%,召回率达到了95.47%,平均精度达到97.27%,比原YOLOv4模型分别提高了1.07、2.59、2.02个百分点。采用基于阈值的边界框匹配合并算法,将识别后子图像的边界框进行匹配与合并,实现全景图像的识别,合并后的结果其精确率达到96.17%,召回率达到95.63%,F1分数达到0.96,平均精度达到95.06%,高于直接对全景图像苹果进行识别的各评价指标。该方法对自然条件下全景图像的苹果识别具有较好的识别效果。
图像识别;YOLOv4;苹果;scSE;深度可分离卷积;边界框匹配合并
0 引 言
苹果作为中国主要的消费级水果,有着悠久的栽培历史。苹果的生产需要大量的人工作业,而随着城市化的发展,人工成本提高、作业效率低等问题为苹果产业的发展带来一定程度的影响[1]。随着智慧农业的提出,果园普遍采用现代化标准种植模式,以信息化、自动化的技术对果园产业进行升级的趋势日益明显[2-3]。对果树果实的识别及计数成为实现智慧果园的关键性技术之一,精准的识别可为自动采摘提供技术基础,准确的计数可为产量预测、果园管理决策、仓库分配以及营销策略提供资助。
目前,国内外研究人员针对果树果实的识别进行了大量的研究,主要包括传统图像处理方法和基于卷积神经网络的方法等。传统图像处理方法主要通过果实的颜色、纹理和轮廓等特征信息对果实进行形态学处理从而达到对果实识别的效果[4-5],但对于复杂环境图像的识别准确率较低。廖崴等[6]使用Otsu阈值分割法对苹果图像RGB颜色空间的像素值进行分割,得到仅包含果实和叶片的图像,通过随机森林算法建立苹果叶片模型,并利用霍夫变换检测苹果果实的轮廓,达到对苹果识别的效果,其平均识别准确率只有88%。卷积神经网络由于其较高的识别准确率被广泛地使用,以R-CNN算法衍生出的Mask R-CNN和Faster R-CNN等网络模型,其识别过程分为定位和分类两个阶段,故称为两阶段目标检测算法[7-8]。其中,将Faster R-CNN网络应用于果树果实识别场景中的研究较多,对果实的检测和识别效果较好[9-10]。闫建伟等[11]通过对Faster R-CNN网络模型进行改进,将其中ROI Pooling模块替换为ROI Align模块,对自然环境下不同形态的刺梨果实进行识别,F1分数最高达94.99%。Gao等[12]采用Faster R-CNN网络模型对比不同主干特征提取网络对苹果果实识别的影响,使用VGG-16作为主干特征提取网络的效果最好,mAP达到87.9%。而以YOLO系列算法为代表的单阶段目标检测算法,以其较快的检测速度和简单的算法流程也得到了越来越多的应用,其主要以YOLOv3[13]、YOLOv4[14]等算法在果实识别领域表现优异,在果实识别的场景中的也取得了较好的识别效果[15-19]。赵辉等[20]采用改进YOLOv3网络模型对不同场景下和不同成熟度的苹果果实图像进行识别,其F1分数为91.8%。Ji等[21]采用EfficientNet-B0作为YOLOv4的主干特征提取网络,对夜间环境下的苹果果实进行识别,其F1分数达到90.35%,达到较好的识别效果。
目前,果树果实识别通常以局部场景和简单场景的图像识别为主,而对于国内大部分果园,局部场景识别和简单场景的识别不能满足精准园艺的需求。本文旨在通过全景拍摄的方式,对自然环境下果园中连续多棵果树的两侧全貌进行图像采集,并基于“分割—合并”的思想,以YOLOv4网络模型算法对分割图像进行识别,并以一种基于阈值的边界框匹配合并算法将识别后的结果进行合并,提高对分辨率较大的图像的识别精确率及召回率,达到对果实识别及计数的效果。
1 图像采集与数据集构建
1.1 苹果果树图像采集
试验采用的苹果果实图像采集于河北省保定市顺平县,品种为富士,处于盛果期,果实颜色以红色为主。果园以株距1.5 m、行距4 m的栽培模式。这种栽培模式对采集单棵果树的图像带来了很大的困难,因此,本文以全景拍摄的方式对种植在一行的连续多棵果树进行拍摄,通过相机内置的全景拍摄方式采集连续多棵果树的单侧全貌,全景拍摄方式如图1所示。拍摄时天气晴朗,以人工手持拍摄设备的方式进行拍摄,相机距地面1.7 m,并在采集时使用稳定设备(DJI OM 4 SE)保证全景图像的拍摄质量,以顺光方向距果树间隔约2 m进行平行拍摄,使图像能包含每棵树的单侧全貌。
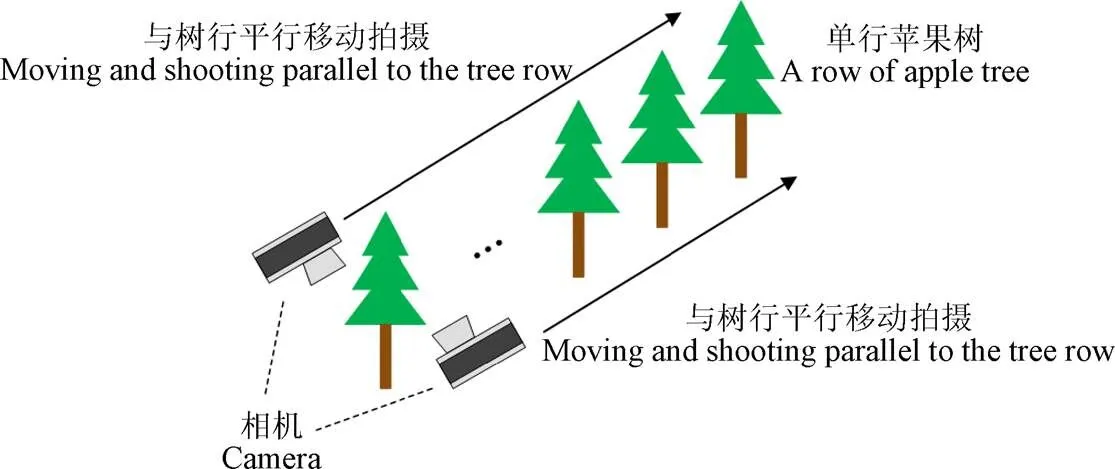
图1 苹果果树全景图像采集示意图
试验采集了包含71棵苹果果树的图像,若采用对单棵果树的东西两侧分别采集图像的方法,则需采集142幅图像,且图像中重复信息过多。采用对苹果果树两侧分别拍摄全景图像,能够减少图像中重复的信息,最终得到苹果全景图像共29幅。全景苹果图像的原始格式为JPG,图像分辨率不固定。采集的果树图像样本示例如图2所示。

图2 苹果果树全景图像示例
1.2 图像预处理
本文对采集到的29幅苹果全景图像通过OpenCV库函数进行预处理操作。首先采取水平镜像的方式进行数据增强,得到增强前后的图像共58幅。由于每排果树的数量不定,故采集的全景图像分辨率并不固定,主要体现在图像宽度的不同,而图像识别网络需要固定分辨率的输入图像,对不符合输入分辨率的图像需要进行缩放操作,但缩放操作会导致图像失真,对图像中较难识别的目标产生影响,从而降低识别效果。因此需保证图像不失真的前提下,将图像处理为相同的分辨率。YOLOv4神经网络模型以608×608像素的分辨率作为图像的输入,因此将58幅图像进行逐行逐列分割,将一副不定分辨率的全景图像(全景图像的分辨率均大于608×608像素),按次序分割为若干幅608×608像素的子图像。若全景图像的宽或高不是608的整倍数,会导致图像分割后仍有部分图像不能分割为608×608像素的图像,故在全景图像的右侧和下侧添充纯色像素条,使全景图像的宽和高均为608的整倍数。本文添加的像素条颜色为RGB(0,0,0),即黑色的填充。
分割后的图像按先行后列的方式进行排序,并将序号标注在子图像的文件名中,用以标识为同一幅图像的子图像,例如全景图像“pic1.jpg”有30幅子图像,则子图像的名称为“pic1_1.jpg”~“pic1_30.jpg”
1.3 数据集构建
本试验将预处理后的图像进行整理,最终得到608×608像素的图像共4 698幅。使用labelImg对苹果果树全景图像及其分割后的子图像制作标签,并且保证子图像中标出的目标与原全景图像中所标出的目标相同,仅由于分割而在多张子图像中将同一目标重复标记。全景图像子图像与其所属的全景图像有关联,因此,在试验过程中按照子图像所属全景图像以9∶1的比例随机划分为训练验证集和测试集,最终得到训练验证集图像4 080幅,测试集图像618幅。将训练验证集的4 080幅图像,以9∶1的比例随机划分为训练集和验证集。
2 苹果全景图像识别方法
2.1 苹果全景图像识别问题分析
本文所采集的苹果全景图像分辨率较大,而通过神经网络直接对分辨率较大的图像进行训练,通常会对分辨率进行压缩,这将导致图像的失真和图像中目标信息的丢失,进而导致目标检测召回率较低、识别效果较差的问题。因此,本文设计了“分割—合并”的方法,即将苹果全景图像分割为子图像,采用神经网络模型先对子图像进行识别,然后将识别结果进行合并,实现对全景图像苹果的识别。
神经网络模型能够对全景图像分割后的子图像进行有效的识别,但由于全景图像中的某一个目标,在图像分割时可能被分在多幅子图像中,导致该目标被重复识别,如图3所示。图3a展示的是最严重的一种情况,单个目标被分到4幅子图像中,目标分散在每幅子图像中的部分均被识别,导致单个目标被识别了4次,无法正确表达全景图像的识别结果,需要设计一种方法,将该目标识别为一个完整的目标,如图3b所示。因此本文提出了一种基于阈值的边界框匹配合并算法,对子图像识别结果合并时产生的错误结果进行修正。

图3 单一目标重复识别与正确识别示意图
2.2 改进YOLOv4模型的子图像中苹果识别方法
本文采用YOLOv4模型作为子图像中苹果识别的基础模型。YOLOv4由主干特征提取网络CSPDarknet-53[22]、空间池化金字塔模块(Spatial Pyramid Pooling, SPP)[23]和路径聚合网络(Path Aggregation Network, PANet)三大部分构成。首先通过CSPDarknet-53对输入图像提取特征,之后将其最后一层的输出进入SPP模块,最后将其输出与CSPDarknet-53的第5层和第6层的输出进入PANet模块进行特征的反复提取和融合。
YOLOv4网络模型的网络结构较为复杂,参数量较大,且对小目标的识别效果较差,而本文数据集中小目标的数量占比较大。因此,为了进一步提高模型的检测能力,减少模型的参数量,本文引入scSE(Spatial and Channel ‘Squeeze & Excitation’)注意力机制[24]和深度可分离卷积[25]对YOLOv4模型进行改进,改进后的YOLOv4模型如图4所示,其中“scSE Resblock×”为嵌入scSE注意力机制的Resblock模块,代表“Res”残差模块的重复次数,“Three Conv”、“Five Conv”、和“YOLO Head”模块中分别嵌入了深度可分离卷积模块。
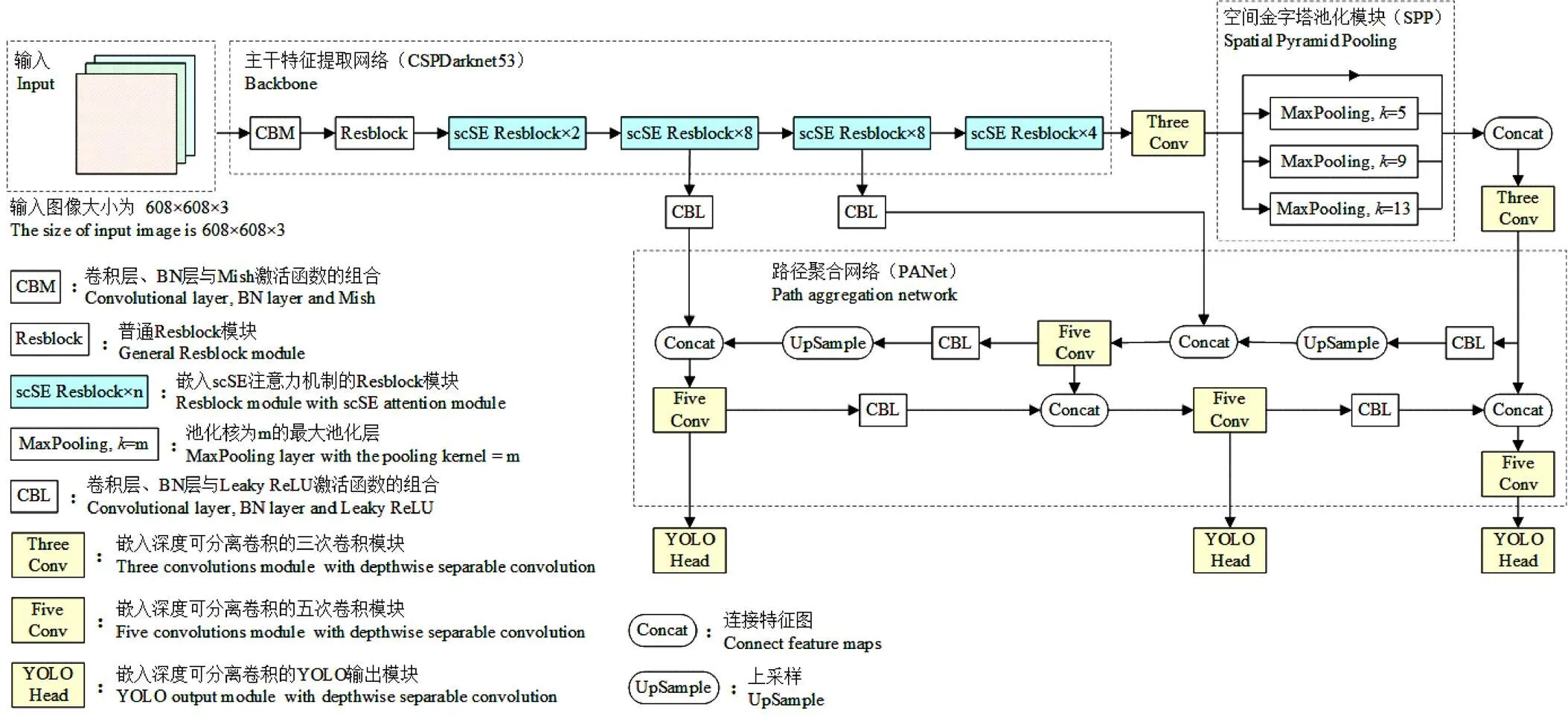
注:k为池化核尺寸,n为“Res”残差模块的重复次数。
2.2.1 嵌入scSE注意力机制的Resblock模块
scSE注意力机制是对压缩和激发网络(Squeeze and Excitation Networks, SENet)的一种改进,常用于语义分割模型,通过scSE注意力机制能够对小目标进行更加准确的识别。其主要分为并联的两部分,对输入特征图进行sSE模块和cSE模块,即对输入特征图分别进行空间注意力的施加和通道注意力的施加。
为了使注意力机制能够有效地对特征层中重要特征进行关注,提高特征层的表征能力,本文对主干特征提取网络CSPDarknet-53中第2、3、4、5个Resblock模块引入注意力机制,将其中每个残差结构之后和特征图连接操作之后分别施加scSE注意力机制,引入scSE注意力机制的Resblock模块结构如图5所示。

图5 嵌入scSE模块的Resblock模块结构
2.2.2 深度可分离卷积模块
深度可分离卷积将普通卷积操作分解为2个阶段,首先对输入特征图进行逐通道卷积,即采用一个通道数与输入通道数相同的卷积核进行卷积操作;之后进行逐点卷积操作。深度可分离卷积能够减少卷积操作的计算量和参数量,通过增加深度可分离卷积的输出通道数能够提高特征提取的效果。
为了减少YOLOv4模型的参数量,本文将YOLOv4模型中3次卷积模块、5次卷积模块以及YOLO输出模块中的部分卷积模块替换为深度可分离卷积模块,并且为了提高深度可分离卷积对特征提取的能力,将深度可分离卷积的输出通道数改为原普通卷积输出通道数的2倍。嵌入深度可分离卷积的3次卷积模块、5次卷积模块以及YOLO输出模块结构如图6所示。

图6 部分嵌入深度可分离卷积的模块结构
如表1所示,引入scSE注意力机制和深度可分离卷积的YOLOv4模型,其参数量由原来的63 937 686降低为44 797 126,模型大小由243.90 MB降低为170.89 MB,比原YOLOv4模型降低了30%,有效减小了模型尺寸。

表1 网络模型参数量对比
2.3 边界框匹配合并算法
本研究采用边界框匹配合并算法,将子图像的苹果识别结果进行合并,对由于被分割在多幅子图像中的苹果目标进行合并,以得到更加准确的全景苹果图像识别结果。
边界框匹配合并算法首先将所有子图识别结果的边界框重新计算,以子图所对应全景图像的左上角为原点,以横向为轴、纵向为轴,重新计算它的4个参数来描述其坐标,即min、min、max和min共4个值,表示边界框的最小值、最小值、最大值以及最大值。以图像左上角为原点,横向为轴,纵向为轴,则纵向分割线为于点1,2, …,x做垂直于轴的垂线,横向分割线为于点1,2, …, y做垂直于轴的垂线,其中1,2, …,x与1,2, …, y为每个子图的分辨率(本试验中为608)的整倍数。
为了更好地判断两边界框是否能够合并,本文采用3个阈值D1、D2和D3对两边界框之间的距离进行判定,并按照如下步骤进行边界框匹配与合并。
1)将边界框加入匹配集合。首先以纵向分割线为基准进行匹配,查找与第一条纵向分割线=1相邻的第一个边界框,即判断该边界框的min和max是否与1的距离小于阈值D1,若小于D1则加入待匹配集合(Match set)。
2)判断两边界框是否可匹配。每有一个新的边界框bbox_new加入Match set中时,判断该边界框与Match set中的边界框bbox_ms是否有匹配,即分别判断bbox_new的min与bbox_ms的max的距离是否小于阈值D2,或者判断bbox_new的max与bbox_ms的min的距离是否小于阈值D2,若满足该条件,则进行步骤3),若匹配失败或不满进入步骤3)的条件,则重复步骤2),直至Match set中的边界框均不能匹配,则将其加入Match set。重复步骤1直至无可加入的边界框。
3)匹配两边界框合并为新的边界框。将步骤2)中的2个可能匹配的边界框再次进行判断,即分别判断两边界框的min的距离和max的距离是否均小于阈值D3,若均小于D3则匹配成功,将两边界框移出Match set,并取两边界框的min最小值、min最小值、max最大值、max最大值形成新的min、min、max、max;若不小于阈值D3,则匹配失败,将bbox_ms放回Match set并将bbox_new重复步骤2)中的匹配。
4)重复步骤1)~3),直至所有纵向分割线相关的边界框均匹配完成。之后使用相同算法和阈值D1、D2、D3,判断横向分割线,直至横向分割线相关的边界框均匹配合并完成。
将关于纵向分割线匹配后的结果作为对横向分割线匹配的输入bbox,则关于横向分割线进行匹配的算法的步骤与上述步骤相同,只需将其中“min”和“min”相互替换、“max”和“max”相互替换,得到关于横向分割线匹配合并的结果,完成边界框匹配合并算法。
通过上述算法,能够对表示同一个目标的边界框进行合并,从而得到正确的识别结果,阈值D1、D2和D3的取值对最终的边界框合并效果有着较大的影响,因此本文将通过试验来确定阈值D1、D2和D3的值,通过不同阈值D1、D2和D3的取值,判断其对边界框合并结果的影响,确定最优的阈值D1、D2和D3,并采用基于最优阈值D1、D2和D3的边界框匹配合并算法对全景苹果子图像的识别结果进行合并,得到全景图像苹果的识别结果,并与直接对全景图像苹果识别的结果进行对比,验证基于该算法对全景图像分割子图像识别结果合并的效果。
2.4 模型训练与性能评价
2.4.1 试验平台
本文试验的硬件为 Ubuntu 18.04操作系统,硬件采用 Intel(R) Xeon(R) Gold 5220 @ 2.20 GHz处理器,GPU为 NVIDIA Quadro RTX 5000 16 GB。本文所使用的软件环境为 Python 3.8,采用 Pytorch 1.7.1 框架,CUDA 版本为10.0。
2.4.2 训练参数
本文模型训练初始学习率设置为0.001,采用迁移学习的方法,使用COCO数据集预训练权重作为模型训练的初始权重。模型训练迭代次数共500次,其中前80次采用冻结主干特征提取网络权重测策略进行训练,对之后的训练采用全部权重进行训练。
对于模型训练需要的9组先验框,本文采用K-means++聚类算法对数据集中的边界框的宽和高进行聚类,得到9个聚类中心,将聚类中心作为9组不同先验框的尺寸。
本文通过计算预测框与真实框的CIoU损失、置信度损失和预测框的类别损失,对网络模型的训练效果进行对比分析。其中置信度损失为计算预测结果置信度与1的对比,预测框类别损失为预测结果类别与真实类别的差距。
2.4.3 评价指标
对于神经网络模型,通常采用以下4个指标进行评估:精确率(Precision,)、召回率(Recall,)、1分数(1score,1)以及平均精度(Average Precision,AP)。对于模型的检测结果,有4种不同的情况,即正确预测正样本(True Positive, TP)、正确预测负样本(True Negative, TN)、错误预测负样本(False Positive, FP)以及错误预测正样本(False Negative, FN),通过4种情况的数量用来计算精确率、召回率,从而得到其他的平价指标。精确率、召回率、1分数和AP值的计算式如式(1)到式(4)所示。




本文以置信度0.5作为评估阈值,选取精确率、召回率、1分数以及平均精度等4个评价指标对模型进行评估。
3 结果与分析
3.1 全景苹果图像分割子图像识别结果
3.1.1 训练损失值与训练过程
采用本文所提出的改进YOLOv4模型,对训练集进行训练,并将训练得出的模型对验证集进行检测,各训练世代的训练集和验证集的Loss曲线与验证集训练过程如图7所示。
由图7中的训练过程中可以看出,当迭代次数达到300时,验证集loss曲线趋于平缓,对验证集的各项评价指标也逐渐稳定。最终,验证集损失率在0.04附近波动,验证集AP值达到了93%以上,模型收敛。

图7 改进后的YOLOv4模型的训练过程
3.1.2 不同模型的性能评价
试验采用相同划分策略的训练集对目前使用较为广泛的目标检测网络模型CenterNet[26]、Faster R-CNN、YOLOv4、YOLOv4-Lite[27]、YOLOv5-l和YOLOv5-x等以及本文所提出的改进YOLOv4模型进行训练,并分别对相同的测试集数据进行测试,所得到的结果如表2所示。
由表2可以看出,Faster R-CNN模型占用空间较大,且精确率只有57.94%,识别效果较差。CenterNet模型的精确率和召回率较低,分别为93.55%和82.73%,低于YOLOv4与YOLOv5系列算法。YOLOv4-Lite模型所占空间较小,且检测速度较快,但召回率只有88.73%。YOLOv5-l和YOLOv5-x模型的精确率较高,分别达到了95.48%和95.81%,但召回率低于YOLOv4接近4个百分点。而本文所提出的改进YOLOv4模型,其检测速度与YOLOv4模型相当,精确率为96.19%,召回率达到95.47%,AP值也达到了97.27%,相较于改进前的YOLOv4模型分别提高了1.07、2.59、2.02个百分点,1分数达到0.96。改进前后YOLOv4模型的识别效果如图8所示。
由图8a可以看出,采用改进前的YOLOv4模型训练得到的模型对苹果果实的识别存在漏识别的现象,主要体现于对于阴天、晴天等条件拍摄到的苹果图像中,遮挡较严重或者因为过曝导致的果实颜色出现偏差的果实目标,漏识别现象较为严重。通过本文改进后的YOLOv4模型对相同图像进行检测,能够对上述漏识别的果实进行有效的检测。

表2 不同模型对子图像识别结果对比

注:图中矩形框为识别结果边界框。下同。
3.2 合并子图像识别结果算法的评价
3.2.1 边界框匹配算法中阈值的选定
采用本文所提出的基于阈值的边界框匹配合并算法,对本文改进YOLOv4模型的全景子图像的识别结果合并为原全景图像的识别结果,并与人工标注的全景图像数据集进行对比。通过对边界框匹配合并算法中阈值D1、D2和D3的值进行采样,以计算对全景图像识别的精确率、召回率、AP值和F1分数。边界框匹配合并算法中阈值D1、D2和D3的取值,对合并全景子图像的识别结果得到的全景图像识别结果的影响如图9所示,为了使结果图更有可视性,本文对结果影响相同的阈值D1、D2和D3的值只保留了一种情况进行绘制。

图9 边界框匹配合并算法中阈值D1、D2和D3对合并结果的影响分布
如图9所示,边界框匹配合并算法中阈值D1、D2和D3取值对F1分数、召回率和精确率都有影响。由图9a可以看出,阈值D1和D2越大,对图像识别的召回率越小,阈值D3越大,对图像识别的精确率越大,而图9b和图9c所示阈值D1、D2和D3对召回率及AP值的影响相似。通过基于不同阈值D1、D2和D3的边界框匹配合并算法,对子图像识别结果合并后的全景图像识别结果评价指标的分析,取精确率、召回率与AP值最高的一组阈值D1、D2和D3作为最优的取值,分析得到最优的阈值D1、D2和D3分别为3、1和45,故将其作为最终D1、D2和D3的值。
3.2.2 合并前后的对比
为了验证“分割—合并”的方法对全景图像苹果识别结果的效果,本文首先采用不同模型对苹果全景图像直接进行训练和识别,结果如表3所示。

表3 各模型对苹果全景图像直接检测的结果对比
由表3可知,直接对分辨率较大的苹果全景图像进行识别,其中CenterNet模型的精确率达到87%以上,但召回率只有1.39%,表明未能识别出大部分的果实目标;YOLOv4-Lite模型的精确率只有35.33%,召回率不足30%,其识别效果较差。Faster R-CNN模型的识别精确率达到51%以上,而召回率只有16.48%,AP值也只有10.81%。YOLOv5-l及YOLOv5-x的模型精确率均达到50%以上,召回率均达到30%以上;YOLOv4模型的精确率达到64.21%,召回率达到43.51%,本文所提出的改进YOLOv4模型精确率达到64.94%,召回率达到52.00%,但仍不能满足对苹果的有效识别。
通过上述分析可知,将苹果全景图像直接识别,会因为压缩分辨率导致图像的失真,各模型的识别效果较差,不能应用于实际场景,因此本文采用边界框匹配合并算法将分割后子图像的识别结果进行合并,其中阈值D1、D2和D3的值分别为3、1和45,各模型对子图像的识别结果合并得到的全景图像识别结果如表4所示。
由表4可知,相较于表2中直接对全景苹果图像直接训练并识别的结果,采用边界框匹配合并算法对子图像识别结果合并得到全景苹果图像的识别结果,其精确率、召回率和AP值均有明显提升,表明该方法能够有效地对分辨率较大全景苹果图像的果实进行识别。其中Faster R-CNN由于其对子1图像识别效果较差导致其合并后的结果仍然较差,而CenterNet和YOLOv5-x对子图像识别结果合并后得结果其精确率分别只有84.37%和85.59%,远低于YOLOv4、YOLOv4-Lite和YOLOv5-l模型,而通过本文所提出的改进YOLOv4模型对子图像识别结果进行合并后,其精确率达到96.17%,召回率达到95.63%,AP值达到95.06%,表明采用本文改进后的YOLOv4模型配合边界框匹配合并算法能够有效识别出苹果全景图像中的果实目标。采用边界框匹配合并算法将测试集中分割后图像的识别结果合并为全景图像的识别结果,平均每幅全景图像用时0.28 s。
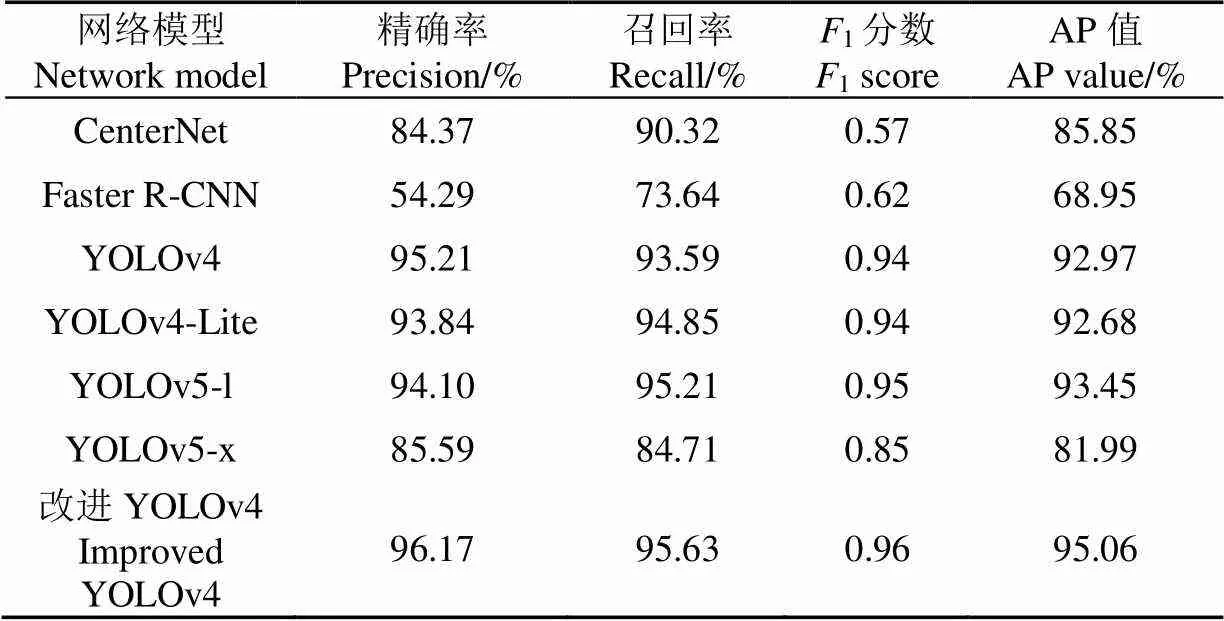
表4 不同模型对子图像识别结果合并后全景图像识别结果对比
合并后的结果相较于模型直接对苹果全景图像识别的效果有较大的提升,原因在于子图像的识别结果中,不会因为压缩分辨率导致图像失真,从而不会导致图像中小目标因分辨率压缩严重而丢失目标,因此,该方法对图像各个目标的识别结果是较为准确的,此时通过边界框匹配合并算法将识别结果进行整理,保留了完整的果实识别结果,从而达到较好的识别效果。采用边界框匹配合并算法前后的合并效果示例如图10所示。

图10 合并前后效果对比
图10a所示的合并前的图像中,每个目标均被分割线分割为2个目标,导致同一个目标在分割线两侧出现了2个边界框,表明该目标被重复识别。图10b所示的图像为经过边界框匹配合并算法处理后,目标被正确地识别为同一个目标,使合并后的目标边界框完整地包含了目标。苹果全景图像的识别效果如图11所示。
由图11a所示的直接对全景苹果图像训练和识别的效果,可以看出大部分的苹果果实目标未被识别出,而图11b所示的采用“分割-合并”的方法对全景图像进行识别,能够识别出图像中的大部分苹果目标,但仍有小部分果实未被准确识别,如小图中方框所示,原因在于部分果实由于叶片遮挡严重或收光线阴影影响较大而较难识别,但大部分苹果目标被准确地识别出来,表明本文方法能够对苹果图像进行有效的识别。

注:图中小图为果实漏识别情况示例。
综合模型对全景图像直接识别的结果,以及对子图像识别结果进行合并的效果,表明采用本文所提出的改进YOLOv4模型对苹果全景子图像识别,并应用基于阈值的边界框匹配合并算法将识别结果合并,对全景苹果图像的识别效果较好。
4 结 论
1)本文引入scSE注意力机制和深度可分离卷积,对YOLOv4网络模型进行改进,对苹果全景子图像进行识别。通过对不同目标检测网络模型及本文所提出的改进YOLOv4模型进行测试,结果表明本文所提出的模型比其他模型效果要好,精确率、召回率和平均精度分别达到了96.19%、95.47%和97.27%,1分数为0.96。
2)本文提出了一种基于阈值的边界框匹配合并算法,将改进YOLOv4模型对全景苹果图像子图像的识别结果进行合并,合并后苹果全景图像识别结果的精确率达到96.17%,召回率达到95.63%,平均精度达到95.06%,相比直接对全景图像识别的效果有明显提升,能够较好地对分辨率较大的全景图像苹果进行识别。
本文利用神经网络模型及基于阈值的边界框匹配合并算法,满足自然环境下的果树果实图像识别的要求。未来可通过开发应用,将相机、手机等设备采集的苹果全景图像上传至服务器端,通过服务器端部署本文的识别模型及算法对上传的苹果全景图像进行识别,将识别结果统计并进行存储与反馈。本研究有利于智慧果园的发展,为苹果产量预测智能化提供了技术基础。
[1] 王丹丹,宋怀波,何东健. 苹果采摘机器人视觉系统研究进展[J]. 农业工程学报,2017,33(10):59-69.
Wang Dandan, Song Huaibo, He Dongjian. Research advance on vision system of apple picking robot[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2017, 33(10): 59-69. (in Chinese with English abstract)
[2] Tian Y, Yang G, Wang Z, et al. Apple detection during different growth stages in orchards using the improved YOLO-V3 model[J]. Computers and Electronics in Agriculture, 2019, 157: 417-426.
[3] 杨福增,雷小燕,刘志杰,等. 基于CenterNet的密集场景下多苹果目标快速识别方法[J]. 农业机械学报,2022,53(2):265-273.
Yang Fuzeng, Lei Xiaoyan, Liu Zhijie, et al. Fast recognition method for multiple apple targets in dense scenes based on centerNet[J]. Transactions of the Chinese Society for Agricultural Engineering, 2022, 53(2): 265-273. (in Chinese with English abstract)
[4] Liu X, Zhao D, Jia W, et al. A detection method for apple fruits based on color and shape features[J]. IEEE Access, 2019, 7: 67923-67933.
[5] Bargoti S, Underwood J P. Image segmentation for fruit detection and yield estimation in apple orchards[J]. Journal of Field Robotics, 2017, 34(6): 1039-1060.
[6] 廖崴,郑立华,李民赞,等.基于随机森林算法的自然光照条件下绿色苹果识别[J]. 农业机械学报,2017,48(S1):86-91.
Liao Wei, Zheng Lihua, Li Minzan, et al. Green apple recognition in natural illumination based on random forest algorithm[J]. Transactions of the Chinese Society of Agricultural Engineering, 2017, 48(S1): 86-91. (in Chinese with English abstract)
[7] He K, Gkioxari G, Dollár P, et al. Mask r-cnn[C]// Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy: IEEE, 2017: 2980-2988.
[8] Ren S, He K, Girshick R, et al. Faster R-CNN: Towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2017, 39(6): 1137-1149.
[9] Fu L, Majeed Y, Zhang X, et al. Faster R–CNN–based apple detection in dense-foliage fruiting-wall trees using RGB and depth features for robotic harvesting[J]. Biosystems Engineering, 2020, 197: 245-256.
[10] 熊俊涛,刘振,汤林越,等. 自然环境下绿色柑橘视觉检测技术研究[J]. 农业机械学报,2018,49(4):45-52.
Xiong Juntao, Liu Zhen, Tang Linyue, et al. Visual detection technology of green citrus under natural environment[J]. Transactions of the Chinese Society for Agricultural Engineering, 2018, 49(4): 45-52 (in Chinese with English abstract)
[11] 闫建伟,赵源,张乐伟,等. 改进Faster-RCNN自然环境下识别刺梨果实[J]. 农业工程学报,2019,35(18):143-150.
Yan Jianwei, Zhao Yuan, Zhang Lewei, et al. Recognition of Rosa roxbunghii in natural environment based on improved Faster RCNN[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2019, 35(18): 143-150. (in Chinese with English abstract)
[12] Gao F, Fu L, Zhang X, et al. Multi-class fruit-on-plant detection for apple in SNAP system using Faster R-CNN[J]. Computers and Electronics in Agriculture, 2020, 176: 105634_1-105634_10.
[13] Redmon J, Farhadi A. YOLOv3:An incremental improvement[C]//Proceedings of IEEE Conference on Computer Vision and Pattern Recognition. Washington: IEEE Press, 2018: 1804-1823.
[14] Bochkovskiy A, Wang C Y, Liao H Y M. YOLOv4: optimal speed and accuracy of object detection[C]//Proceedings of IEEE Conference on Computer Vision and Pattern Recognition. Washington: IEEE Press, 2020: 102-123.
[15] Tian Y, Yang G, Wang Z, et al. Apple detection during different growth stages in orchards using the improved YOLO-V3 model[J]. Computers and Electronics in Agriculture, 2019, 157: 417-426.
[16] Mazzia V, Khaliq A, Salvetti F, et al. Real-time apple detection system using embedded systems with hardware accelerators: An edge AI application[J]. IEEE Access, 2020, 8: 9102-9114.
[17] 刘天真,滕桂法,苑迎春,等. 基于改进YOLO v3的自然场景下冬枣果实识别方法[J]. 农业机械学报,2021,52(5):17-25.
Liu Tianzhen, Teng Guifa, Yuan Yingchun, et al. Winter jujube fruit recognition method based on improved YOLO v3 under natural scene[J]. Transactions of the Chinese Society for Agricultural Engineering, 2021, 52(5): 17-25. (in Chinese with English abstract)
[18] Li H, Li C, Li G, et al. A real-time table grape detection method based on improved YOLOv4-tiny network in complex background[J]. Biosystems Engineering, 2021, 212: 347-359.
[19] 高芳芳,武振超,索睿,等. 基于深度学习与目标跟踪的苹果检测与视频计数方法[J]. 农业工程学报,2021,37(21):217-224.
Gao Fangfang, Wu Zhenchao, Suo Rui, et al. Apple detection and counting using real-time video based on deep learning and object tracking[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2021, 37(21): 217-224.(in Chinese with English abstract)
[20] 赵辉,乔艳军,王红君,等. 基于改进YOLOv3的果园复杂环境下苹果果实识别[J]. 农业工程学报,2021,37(16):127-135.
Zhao Hui, Qiao Yanjun, Wang Hongjun, et al. Apple fruit recognition in complex orchard environment based on improved YOLOv3[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2021, 37(16): 127-135. (in Chinese with English abstract)
[21] Ji W, Gao X, Xu B, et al. Apple target recognition method in complex environment based on improved YOLOv4[J]. Journal of Food Process Engineering, 2021, 44(11): e13866_1- e13866_13.
[22] Wang C Y, Liao H Y M, Wu Y H, et al. CSPNet: A new backbone that can enhance learning capability of CNN[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle: IEEE, 2020: 1571-1580.
[23] He K, Zhang X, Ren S, et al. Spatial pyramid pooling in deep convolutional networks for visual recognition[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 37(9): 1904-1916.
[24] Roy A G, Navab N, Wachinger C. Concurrent spatial and channel ‘squeeze & excitation’in fully convolutional networks[C]//International conference on medical image computing and computer-assisted intervention. Springer, Granada, 2018: 421-429.
[25] Howard A G, Zhu M, Chen B , et al. MobileNets: Efficient convolutional neural networks for mobile vision applications[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Hawaii: IEEE, 2017, 17041712.
[26] Zhou X, Wang D, K R Ähenbuhl P. Objects as points[EB/OL]. (2019-04-16) [2022-05-31]. https://arxiv.org/abs/1603.06937.
[27] Howard A, Sandler M, Chen B, et al. Searching for MobileNetV3[C]//2019 IEEE/CVF International Conference on Computer Vision (ICCV), New York: IEEE Press, 2019: 1314-1324.
Recognition of the apple in panoramic images based on improved YOLOv4 model
Zhou Guihong, Ma Shuai, Liang Fangfang
(1.,,071001,; 2.,071001,)
Yield forecasting is one of great significance for decision-making in the apple industry, including labor hiring, harvesting, and storage allocation. Traditional forecasting of apple yield relies mainly on the manual counting of some of the apple trees to estimate the yield of the entire apple orchard. The inaccurate prediction cannot fully meet the large-scale production in recent years. Therefore, it is a high demand for a more accurate and labor-saving way to forecast apple orchard yield. Artificial intelligence in smart orchards can be expected to combine with traditional orchards in the development of the apple industry. The accurate recognition of apples is one of the key technologies to achieve the intelligent yield estimation of apple orchards. However, the shading between apple trees has posed a great challenge to apple fruit identification at present, due to the dense cultivation mode in apple orchards. The repeated capture of apple fruit images can lead to inaccurate fruit counting in the image-collecting mode in each fruit tree. In this study, a panoramic image of apple recognition was proposed using an improved YOLOv4 and threshold-based bounding box matching and merging algorithm. Panoramic photography was used to collect the images of apple fruit trees. Firstly, the Spatial-Channel Sequeeze & Excitation (scSE) attention modules were added to the Resblock module of the backbone of YOLOv4. Some convolutions in the PANet module and YOLO Head module were replaced by the depthwise separable convolutions. The number of output feature channels of depthwise separable convolutions increased to enhance the feature extraction capability, but to reduce the number of model parameters and computation. The panoramic image was segmented intoseveral sub-images. The improved YOLOv4 model was selected to recognize the apples in the sub-images. A comparison was performed on the recognized data of different network models, such as the Faster R-CNN, CenterNet, YOLOv4, YOLOv4-Lite, YOLOv5-l, and YOLOv5-x for the panoramic images of apple trees. The improved YOLOv4 network model achieved a precision rate of 96.19%, a recall rate of 95.47%, and an AP value of 97.27, which were 1.07, 2.59, and 2.02 percentage points higher than the original YOLOv4 model. Secondly, the bounding boxes of the apples in the recognized sub-images were matched and merged by the threshold-based bounding box matching and merging, in order to realize the recognition of panoramic images. The validation experiments determined that the thresholds of 3, 1, and 45 were used for the D1, D2, and D3, respectively. A better performance was achieved in the precision rate of 96.17%, a recall rate of 95.63%, an1score of 0.96, and an AP value of 95.06%, which were higher than each evaluation index for the direct recognition of panoramic images of apples. As such, the panoramic image recognition was obtained to merge the sub-image recognition using the improved YOLOv4 model. The higher evaluation index and better recognition were achieved in the apple recognition of panoramic images under natural conditions. The finding can provide a new strategy to recognize apple fruits for the intelligent measurement of orchard yield.
image recognition; YOLOv4; apple; scSE; depthwise separable convolution; matching and merging of bounding box
10.11975/j.issn.1002-6819.2022.21.019
TP391.4
A
1002-6819(2022)-21-0159-10
周桂红,马帅,梁芳芳. 基于改进YOLOv4模型的全景图像苹果识别[J]. 农业工程学报,2022,38(21):159-168.doi:10.11975/j.issn.1002-6819.2022.21.019 http://www.tcsae.org
Zhou Guihong, Ma Shuai, Liang Fangfang. Recognition of the apple in panoramic images based on improved YOLOv4 model [J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2022, 38(21): 159-168. (in Chinese with English abstract) doi:10.11975/j.issn.1002-6819.2022.21.019 http://www.tcsae.org
2022-05-31
2022-10-24
国家自然科学基金(62106065)
周桂红,博士,教授,研究方向为人工智能、图像处理。Email:hebau_zgh@163.com
猜你喜欢
儿童时代·幸福宝宝(2021年11期)2021-12-21
小学科学(学生版)(2021年4期)2021-07-23
家庭影院技术(2020年11期)2020-12-28
现代装饰(2020年4期)2020-05-20
电子制作(2019年16期)2019-09-27
中国交通信息化(2019年4期)2019-07-13
电子制作(2018年19期)2018-11-14
证券法律评论(2018年0期)2018-08-31
电子制作(2018年14期)2018-08-21
英美文学研究论丛(2018年1期)2018-08-16
