
基于转换生成网络的素描人脸识别
2022-02-15 07:14:20霍西宝郭亚男杜康宁
计算机工程与设计 2022年1期
霍西宝,曹 林+,郭亚男,杜康宁
(1.北京信息科技大学 光电测试技术及仪器教育部重点实验室,北京 100101; 2.北京信息科技大学 信息与通信工程学院,北京 100101)
0 引 言
近年来,人脸识别作为快速身份验证的重要形式已广泛应用于视频监控[1]、智能门禁[2]、金融支付[3]等民生领域。素描人脸识别[4]作为人脸识别的重要分支主要应用于刑侦追捕、安全保卫等领域,画师根据目击证人的口头描述,勾勒出嫌疑人的素描人脸图像。
目前针对素描人脸识别的方法主要分为两类:模态内算法和模态间算法。模态间算法旨在提取出人脸图像中能够保留对象身份信息的关键特征,最大限度区分不同对象身份。但由于素描图像和可见光图像数据来源不同导致二者存在较大模态差异,该方法并没有考虑图像间模态差异问题,因此直接使用模态间算法进行素描人脸识别并不能取得理想的结果。模态内算法将不同模态域的图像转换到同一模态,在同一模态域中完成人脸的特征提取、识别工作。这一方法有效减少了不同模态域图像间的差异,通过将数据集中的图像统一到同一模态域进行识别,使得不同域的图像具有可比性。但由于现有的模态内算法生成器和分类器分开进行训练,生成网络合成的图像并不能保证是对提升识别精度最有利的,因此辅助提升识别性能的帮助有限。
针对上述问题,本文提出了一种基于转换生成网络的素描人脸识别方法,该网络同时实现跨模态图像生成和人脸识别的任务。利用该网络生成素描图像对应的可见光域图像,转换到同一模态并加入到训练集样本图像,充分补充模态信息,丰富同一对象的特征信息,有效提升素描人脸识别性能。
1 相关工作
素描人脸识别因其在案件侦破、公共安全领域的重要地位,正受到越来越多的国内外研究工作者的关注。素描人脸识别的研究方法主要分为两类:模态内算法和模态间算法。
模态间算法旨在提取出区分不同对象身份的关键人脸特征,例如:人脸中眼部区域对人脸识别贡献最大,提取特征时,应重点保留眼睛所包含的判别性特征。Lu等[5]提出了一种无监督的用于异质人脸识别的特征学习和编码(SLBFLE)方法。不同于LBP,SLBFLE仅使用一阶段特征学习和编码过程,便可以从不同人脸图像中获取判别信息。Wan等[6]提出了一种基于转移学习的素描人脸识别方法。该方法设计了一种三通道卷积神经网络体系结构,以提取判别性的人脸特征,来自同一对象的数字照片和素描图像面部特征更加接近,如果数字照片和素描图像来自不同的身份,则相反。
模态内算法将数据集中的图像转换到同一模式图像,减少模态差异,在同一模态域完成人脸识别任务。Wang等[7]提出了一种用于人脸素描合成的贝叶斯框架,考虑了相邻图像块之间的空间相邻约束,而现有方法则忽略了相邻选择模型或权重中的约束,大量实验结果表明,所提出的贝叶斯方法可以取得更好的性能。Zhang等[8]提出的合成方法结合了不同图像块之间的相似性和先验知识,将给定测试照片分成重叠的小块,通过学习词典获得其稀疏系数,使用最近邻算法匹配不同的模块,最终将具有高频信息的马尔可夫网络应用于人脸素描图像的合成。
近年来,对抗学习理论得到快速发展,基于生成对抗网络(generative adversarial networks,GANs)[9]的深度学习模型广泛应用于图像合成领域。Yi等[10]提出了APDra-wingGAN,采用全局网络(用于整体图像)和局部网络(用于个人面部区域)相结合的方法,使得合成的人脸图像更清晰、细节更完整。
2 本文方法
由于素描图像和可见光图像之间存在模态差异,因此素描人脸识别仍是一项极具挑战的任务。针对上述问题,本文提出了基于转换生成网络的素描人脸识别方法。转换生成网络采用端到端的训练方式优化模型参数,同时实现生成跨模态图像和识别。在模型训练过程中,生成网络和识别网络相辅相成,彼此促进,通过使用识别损失约束项指导生成更好的跨模态图像,通过生成的跨模态图像减少模态差异带来的识别精度损失。本节主要从网络模型框架和损失函数介绍所提出的方法。
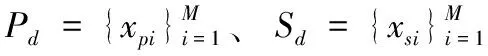

图1 网络整体结构
2.1 生成器
对输入的素描图像,使用生成器合成其对应的可见光域跨模态人脸图像,加入到训练集样本,补充模态信息,辅助提升识别精度。
生成器网络主要由下采样层、残差模块、上采样层构成。输入图像首先经由下采样层网络提取特征,减少网络要学习的参数数量,保留需要的特征参数。下采样网络结构如图2(a)所示,原始人脸图像首先由卷积层提取特征,卷积结束后对特征图进行实例归一化(instance normalization,instance norm)[11]处理,减小特征图中不同通道的均值和方差对图像风格的影响,保持每个图像实例之间的独立。使用线性整流函数(rectified linear unit,ReLU)作为激活函数,缓解模型出现过拟合问题。为了防止随着网络越来越深,出现性能退化问题,在下采样结束后,在模型中引入残差模块,如图2(b)所示。最后,由上采样层对提取的人脸特征放大、还原,生成跨模态的人脸图像。
2.2 判别器
使用判别器网络对输入的图像进行真伪判别,通过与生成器形成对抗学习的方式,使得生成图像具备两种模态信息,提升人脸识别精度。将原始域和生成域的目标图像作为判别器的输入,经过判别器网络的处理,提取判别性的人脸特征,鉴别图像的真伪。通过在判别器网络中引入批量归一化操作(batch normalization, batch norm)[12],把每层神经元的输入值拉回到标准正态分布,防止随着网络深度的增加,其分布发生偏移,降低网络的训练速度和泛化能力。使用LeakyRELU作为网络的激活函数,判别器网络结构如图3所示。

图2 生成器网络主要模块网络结构

图3 判别器网络结构
为了合成与原始域尽可能逼真的图像,补充模态信息,辅助提升识别精度,本文引入了对抗损失函数。生成器根据判别器的反馈,不断调整模型训练参数,提升合成图像的质量
(1)
2.3 特征转换网络
xsm,xsn∈Sd,G(xsm) 是xsm对应可见光域Pd中的表示,在不引入额外约束条件下,素描域Sd的任一图像可映射为可见光域Pd的任意成员来满足其目标,可能造成生成的图像都映射到目标域的同一对象。为了避免这一现象的发生,使用特征转换网络(S网络)将图像映射到某个空间,在该空间中,原始图像之间的关系与其在目标域中生成图像之间的关系相同,完成生成图像的单一映射。
S网络作为特征提取模型[13],主要用于学习输入图像的高级语义特征,辅助生成图像和人脸识别。生成器和判别器采用对抗学习的方式训练,生成器根据判别器的反馈,不断调整模型训练参数,生成更逼真的图像,直到生成的图像达到以假乱真。而S网络和生成器采样合作的方式训练,促使原始图像之间的关系与生成的版本之间保持一致,生成更真实的人脸图像。S网络结构使用预训练的resnet18网络[14],主要由4层基本残差模块构成。基本的残差模块结构如图4所示,图中虚线框为下采样过程,将提取的特征进一步压缩、降维,降低计算复杂度。其中第一层残差模块不包含下采样过程。
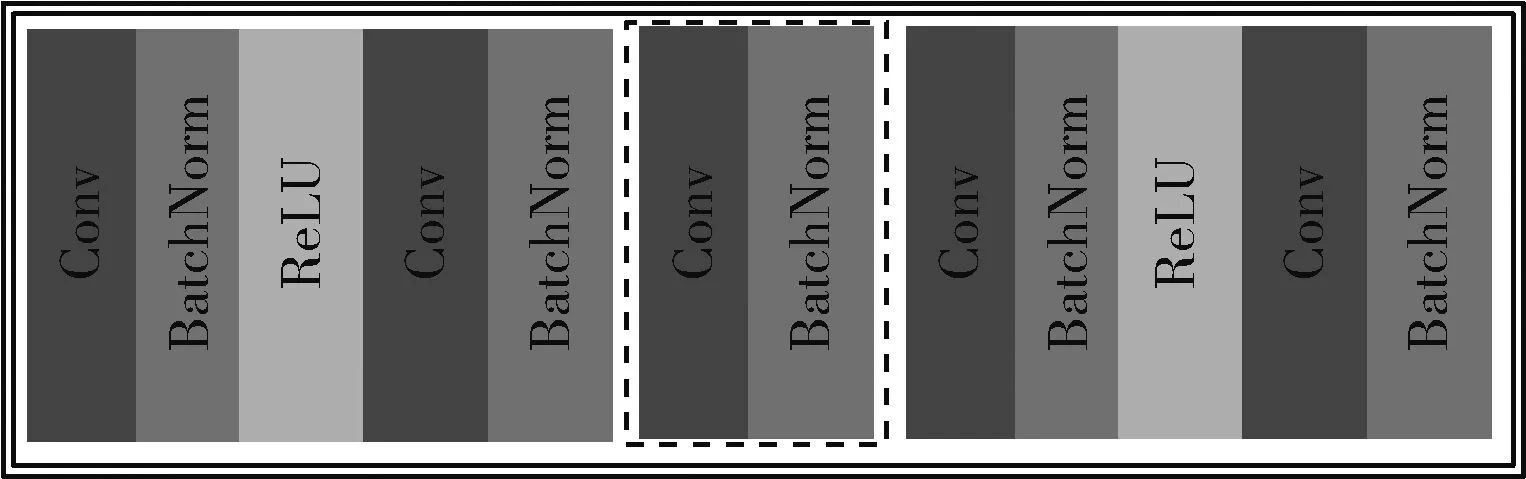
图4 残差模块结构
为了生成和原始图像具有相同语义信息的跨模态图像,生成器必须学习一个映射,使得S(xsm)-S(xsn)=S(G(xsm))-S(G(xsn))。 如式(2)~式(4)所示
vmn=S(xsm)-S(xsn)
(2)
(3)
(4)
其中,Dist是距离度量标准,例如余弦相似度。
在训练过程中,为了避免经过S网络处理后,输出始终为零,增加约束条件,使每个点与空间中的其它点至少相距δ(默认为10),如式(5)所示
(5)
2.4 分类器
为了判别不同对象所属的类别,本文将S网络所提取的特征信息输入到分类器,预测其所对应的标签,实现素描人脸识别。分类器由两个全连接层构成,在第一个全连接层后加入批量归一化操作,使得每一层神经网络的输入保持相同分布。为了防止模型出现过拟合现象,在第一个全连接层中使用Dropout衰减函数。第二个全连接层的输出为训练样本集的图像类别数。分类损失使用交叉熵损失,如式(6)所示

(6)
其中,xi为输入素描、可见光和生成人脸图像,p(yi|C(S(xi))) 表示某一输入样本图像xi通过模型预测出其属于样本标签为yi的概率。
总生成损失如式(7)所示
Ltotal=λadvLadv+λtravelLtravel+λmarginLmargin+λclsLcls
(7)
其中,λadv,λtravel,λmargin,λcls分别为生成对抗损失(Ladv)、转换损失(Ltravel)、边沿损失(Lmargin)、识别损失(Lcls)等控制相关损失项重要性的权重参数。
3 实验与分析
3.1 数据集
为了验证本文方法的识别性能,在S1(UoM-SGFSv2 SetA)、S2(UoM-SGFSv2 SetB)[11]、S3(e-PRIP)[15]等3个数据集上进行识别率的评估。UoM-SGFSv2包括UoM-SGFSv2 SetA和UoM-SGFSv2 SetB,它是最大的软件生成的素描数据集,也是唯一一个以全彩色表示所有素描图像的数据集。UoM-SGFSv2 SetA包含600对可见光-素描人脸图像,其素描图像由EFIT-V创建。图5展示了部分UoM-SGFSv2 SetA数据集原始样本对图像,包括人的上半身图像和背景信息。

图5 原始UoM-SGFSv2 SetA数据集样本对图像
使用图像编辑程序对UoM-SGFSv2 SetA中的素描进行稍微改动,以使素描更真实(模拟执法机构在现实生活中执行的过程),构成了UoM-SGFSv2 SetB。e-PRIP包含AR数据库中的123个人的可见光图像和对应的合成素描。本文实验数据集设置见表1。

表1 实验数据集设置
其中,S1、S2、S3数据集均由两种模态的人脸图像构成:可见光图像、素描图像,每个数据集划分为训练集和测试集,训练集图像主要用来拟合模型,确定模型参数,测试集用来评估训练模型的性能和分类能力。
为了评估本文方法与现有算法的识别性能,保证实验的公平性,对于UoM-SGFSv2数据集,前两个实验设置(S1设置和S2设置)与DEEPS[16]保持一致。具体划分如下:随机从UoM-SGFSv2 SetA抽取450对可见光-素描人脸图像作为S1训练集图像。S1测试集由Probe和Gallery组成,Probe为UoM-SGFSv2 SetA中剩余150对人脸数据集中的素描图像,Gallery由UoM-SGFSv2 SetA中剩余150对人脸图像中的可见光图像和扩充的1521张可见光照片构成。扩充的1521可见光照片包括来自MEDS-Ⅱ数据库的509张照片、来自FEI数据库的199张照片以及来自LFW数据库中的813张照片。S2数据集具体设置同S1一致,只是将随机抽取的数据集更换为UoM-SGFSv2 SetB,其它保持不变。对于e-PRIP数据集,实验设置(S3设置)与Deep Network[17]保持一致。随机从e-PRIP数据集抽取的48对配对的人脸图像作为S3训练集图像。S3测试集Probe和Gallery分别包含e-PRIP剩余75个人的素描图像、可见光图像。
3.2 实验设置
本文的训练模型采用Pytorch框架搭建而成。训练过程中,采用随机加载的方式训练模型,每次随机载入的样本对数设置为16。使用Adam优化器迭代更新模型的训练参数,将Adam优化器的学习率设置为0.0002。总损失函数中各部分权重分别设置为:λadv=0.01,λtravel=0.1,λmargin=0.1,λcls=10。
在模型开始训练前,首先使用MTCNN[18]对现有的数据集进行人脸检测,获得仅包括面部的人脸输出图像。使用MTCNN对UoM-SGFSv2数据集和e-PRIP数据集中的人脸图像进行检测、对齐,保留有利于识别的人脸关键点信息,获得同一尺度的人脸输出图像。经过MTCNN处理后的UoM-SGFSv2数据集部分人脸图像如图6所示,其中第一列为可见光图像,第二列为UoM-SGFSv2 SetA数据集中的素描人脸图像,第三列为处理后的UoM-SGFSv2 SetB数据集中的素描人脸图像。

图6 UoM-SGFSv2数据集样本对图像
部分裁剪后的e-PRIP数据集中的人脸图像如图7所示。

图7 e-PRIP数据集样本对图像
在对数据集人脸样本处理完毕后,使用自定义的数据加载器将样本图像载入模型进行训练。数据加载过程中对本文使用的数据集进行以下预处理:包括人脸图像的裁剪(将输入的人脸图像裁剪到同一尺度进行处理)、图像填充(图像上下左右填充10个像素点)、图像随机裁剪(裁剪尺寸为256*256)、图像水平翻转操作(默认概率值大小为0.5)、归一化处理(经过归一化处理后,可加快模型的收敛速度)。
为了减少因实验波动带来的识别精度误差,本文训练采用五重随机交叉验证的方式。将每个数据集随机抽取5次,分别统计在这5个数据集上的识别率,最终识别率取5个值的均值。
3.3 实验结果与分析
3.3.1 合成结果定性分析
如图8展示了本文方法生成的部分人脸图像。生成的跨模态图像五官细节更加锐利、突出,可以有效补充模态信息,与原始数据集人脸图像一起输入到识别网络,不断更新、优化模型参数,极大丰富了同一对象的特征信息,有效提升素描人脸识别性能。

图8 本文方法合成人脸结果
图8从第一行至第三行依次为:原始可见光人脸图像、本文方法合成的人脸图像、原始素描人脸图像。
3.3.2 识别性能消融研究
为了验证本文方法的有效性,在本节进行识别性能消融研究。消融实验分别设置为:去掉生成器和判别器,直接对原始数据集进行素描人脸识别(Baseline)、合成和识别阶段分开进行(w/o SPT),查看各项因素对识别性能的影响。其中,Baseline为模态间方法,直接使用识别网络判别素描图像、可见光图像所在的类别,统计在3个数据集上的识别率结果。w/o SPT实验生成和识别阶段分开进行,用于验证端对端训练对识别性能的影响。
Baseline网络模型结构由特征提取器、分类器两部分构成,其中特征提取器采用预训练的resnet18网络。原始成对的素描、可见光人脸图像经过预处理后作为resnet18网络的输入,由该网络完成对人脸图像的特征提取任务,输出的特征作为分类器的输入,完成人脸图像的配对、识别工作。
为了验证本文提出的端对端训练方法是否能带来识别性能的提升,本文进行了w/o SPT消融实验。其中w/o SPT为分开训练合成、识别模型,先生成后识别,加载已训练完毕的生成模型处理原始数据集,生成的辅助图像加入到识别的训练样本中,然后利用识别模型完成对人脸的识别任务。消融研究识别率结果见表2。
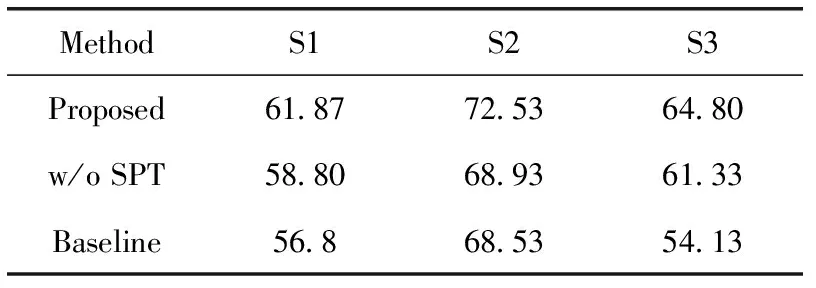
表2 识别性能消融研究结果
表2中,S1/S2数据集上统计Rank1识别率,S3数据集上统计Rank10识别率。
从表2识别率结果可发现,由于可见光人脸图像和素描人脸图像存在模态差异,直接对原始数据域人脸图像识别效果不佳,如表2中Baseline数据行所示。为了验证端对端训练对识别性能是否带来增益,本文将合成和识别模型的训练分开进行,通过实验发现,不采用端对端训练的方法在3个数据集上的识别率明显低于本文方法,如表2 中w/o SPT数据行所示。本文提出了基于转换生成网络的素描人脸识别方法通过引入识别损失约束项指导生成更好的跨模态图像,而且生成的跨模态图像有效减少了模态差异带来的识别精度损失,显著提升了模型的识别率,如表2中Proposed数据行所示。
图9、图10绘制了在S1、S2数据集上的CMC曲线,图中横坐标1~10表示Rank1~Rank10。通过观察曲线,不难发现,本文方法对识别率的提升贡献最大。

图9 S1数据集消融实验
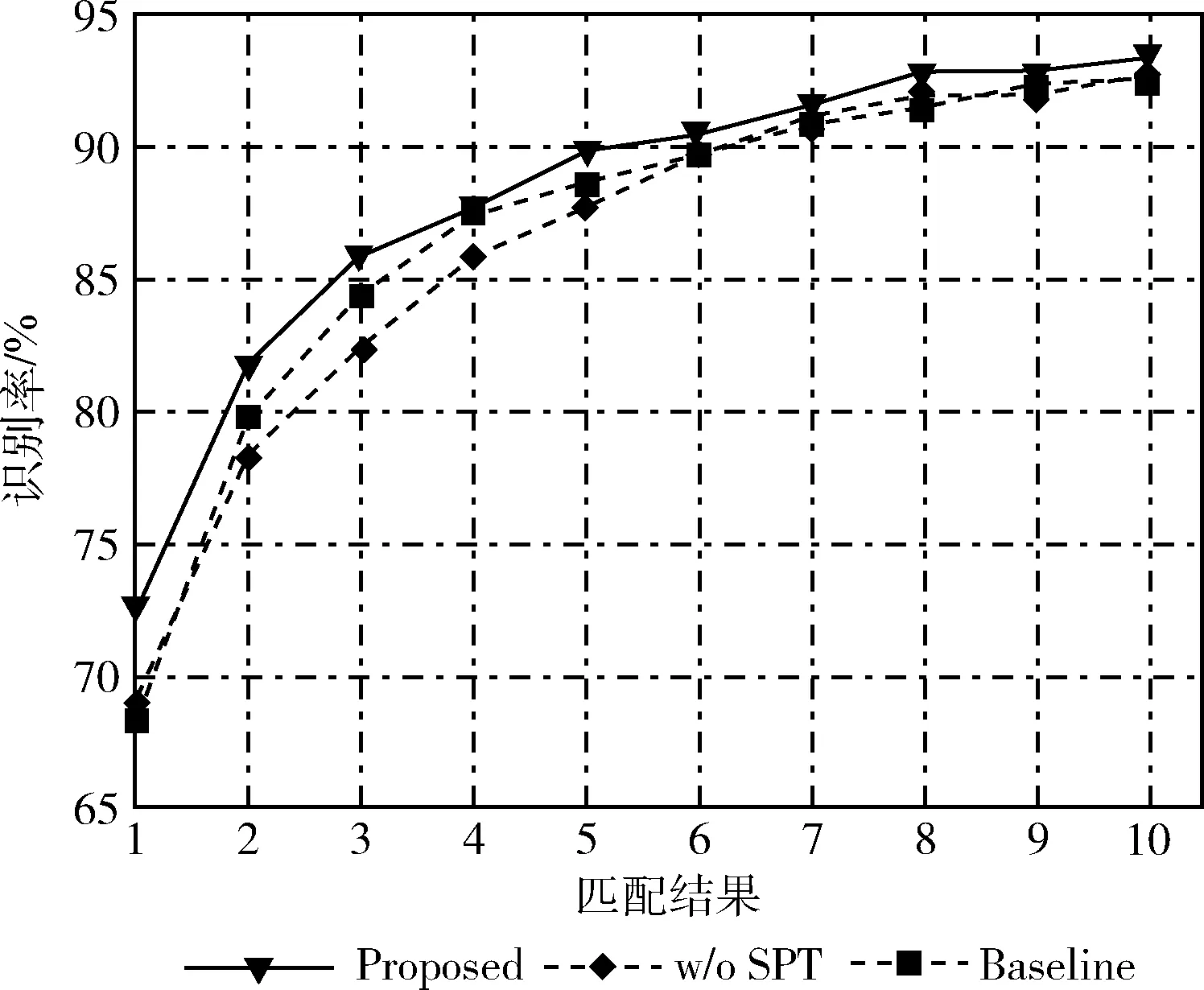
图10 S2数据集消融实验
在S3数据集上的消融实验如图11所示。由于S3数据集仅包括123个人的素描、可见光图像对,数据量少,因此Rank1识别率比较低。

图11 S3消融实验
3.4 对比实验
为了评估本文方法的识别性能,在S1、S2、S3等3个数据集上与现有方法进行比较。其中,S1、S2数据集主要统计Rank-1、Rank-10、Rank-50识别率,S3数据集由于数据量少,主要记录Rank-10识别率。
本文方法与现有方法在S1数据集上识别率结果见表3。其中EP(+PCA)[19]为模态内方法,即将图像转换到同一模态域内进行识别;LGMS[17]、DEEPS[16]、VGG-Face[20]

表3 S1数据集识别率结果
为模态间方法,通过提取出数据集图像中能够保留对象信息的关键特征来判别其身份。
表3中R-1,R-10,R-50分别表示Rank-1、Rank-10、Rank-50识别率。
通过表3可以发现,在S1数据集上,所有对比算法的性能均较低,因为该数据集模仿了现实世界中的法医绘制的素描人脸图像。本文提出的基于转换生成网络的素描人脸识别方法使用端对端训练来更新模型参数,同时实现生成跨模态图像和识别,识别性能明显优于其它对比算法。
为了直观展示不同算法的识别性能,图12绘制了本文方法与现有方法在S1数据集上的识别率柱状图。
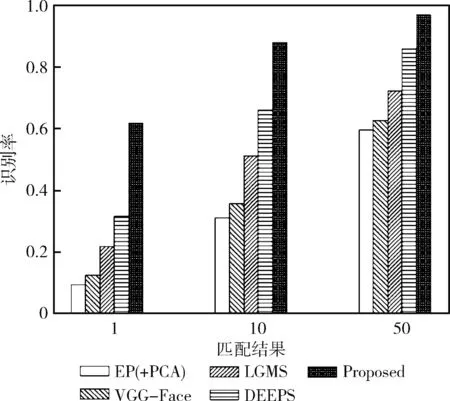
图12 S1数据集对比实验
本文方法与现有方法在S2数据集上识别率结果见表4。
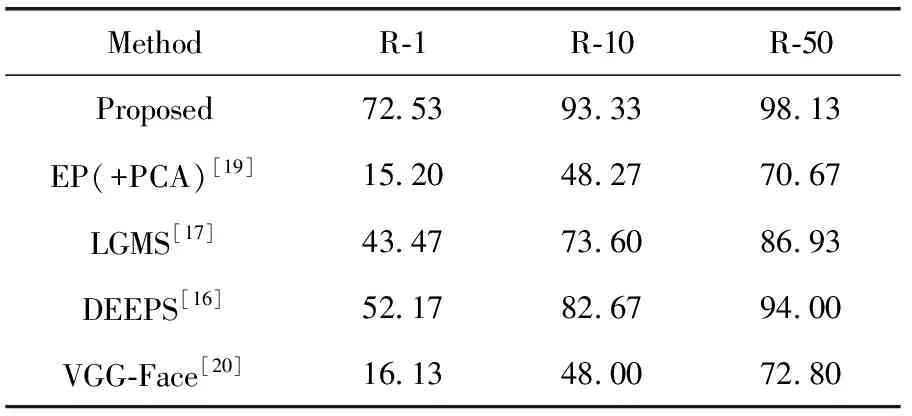
表4 S2数据集识别率结果
相比于S1数据集,S2数据集对素描人脸图像经过稍微改动,所有算法的性能均得到有效提升。
图13绘制了本文方法与现有方法在S2数据集上的识别率柱状图。通过柱状图可以明显发现本文方法的优越性。

图13 S2数据集对比实验
针对S3数据集,表5记录了本文方法与现有方法的识别率统计结果。其中DEEPS扩充了训练集样本数,采用深度神经网络进行素描人脸识别。CNN和Deep Network均采用了迁移学习的方式,将从大型人脸照片数据库学习到的人脸表示应用到素描数据集。

表5 S3数据集识别率结果
4 结束语
素描图像和可见光图像之间存在模态差异,直接进行素描人脸识别效果不佳,本文提出了基于转换生成网络的素描人脸识别方法,该网络由生成模块和识别模块组成,使用端对端训练来更新模型参数,生成和识别部分同时进行,彼此促进。通过生成跨模态图像、补充模态信息来辅助提升识别精度,通过引入识别损失约束项指导生成更好的跨模态图像。为了充分利用数据集的人脸图像,扩充同一对象的特征信息,分别提取原始素描图像、原始可见光图像、合成的可见光图像的人脸特征信息输入到分类器中进行识别,不断更新、优化模型参数,极大丰富了同一对象的特征信息,有效提升素描人脸识别性能。
在UoM-SGFSv2、e-PRIP等数据集上验证本文方法的识别性能,识别率相对现有方法显著提升,尤其在UoM-SGFSv2 Set A数据集上效果最为明显,与现有识别性能最好的DEEPS相比,Rank-1识别率提升了约30%。
猜你喜欢
作文中学版(2022年1期)2022-04-14 08:00:34
江苏安全生产(2021年6期)2021-08-05 07:47:22
歌剧(2020年4期)2020-08-06 15:13:32
学生天地(2020年31期)2020-06-01 02:32:06
雨露风(2020年8期)2020-04-26 19:55:51
计算机工程(2020年3期)2020-03-19 12:24:50
中国听力语言康复科学杂志(2019年3期)2019-06-24 09:51:20
中国交通信息化(2018年3期)2018-06-13 03:27:58
读者(2016年23期)2016-11-16 13:27:55
中国交通信息化(2016年2期)2016-06-06 07:28:02
