
基于改进的加权补集朴素贝叶斯物流新闻分类
2022-02-15 07:13:48许英姿任俊玲
计算机工程与设计 2022年1期
许英姿,任俊玲
(北京信息科技大学 信息管理学院,北京 100192)
0 引 言
常用文本分类算法主要有朴素贝叶斯[1](Naive Bayes,NB)、支持向量机[2](support vector machine,SVM)和K近邻[3](k nearest neighbor,KNN)等。NB算法以其计算效率高、精确度高且稳定性强的特点,成为常用的文本分类算法之一。纵观国内外学者使用NB算法对专业领域的文本进行分类的研究,赵燕等[4]建立了适用于农业文本分类的NB模型;孙宇[5]构建NB模型,挖掘稻米产品物流因素与顾客满意度间的关系。在物流领域,现有工作大多集中于对物流数据的挖掘与分析[6,7]或对评论文本的情感分析[8,9],物流新闻文本相关研究较少。
根据各大官方物流新闻网站调研结果,不同类别物流新闻总数差距较大,物流新闻具有类间分布不均衡的特点,较大程度影响了分类器的实际分类效果。针对分类数据集不均衡的特点,王占伟[10]对样本空间进行改进,提出基于重采样技术的非平衡分类算法;Naderalvojou等[11]对分类加权算法进行改进,提出一种正负项和类别相关度的概率特征加权算法。以上方法均未考虑改进算法对分类时间的影响。本文针对物流新闻文本专业性强且类别分布不均衡的特点,构建物流新闻语料库,使用在中文数据集中表现最好的卡方检验[12,13](chi-square test,CHI)进行特征选择,考虑局部、全局和类内、类间的特征加权算法进行特征加权,实现基于加权补集朴素贝叶斯(weighted complement Naive Bayes,WCNB)的物流文本分类模型,通过不均衡的物流新闻文本分类实验验证模型的有效性与性能。
1 基于补集的朴素贝叶斯模型
1.1 朴素贝叶斯原理
朴素贝叶斯[14]是一种基于贝叶斯定理和特征条件独立假设的概率统计方法。根据贝叶斯定理,假设有v个类别集合C={c1,c2,…,cv};T={t1,t2,…,tm} 表示m篇文本,每个文本由n维特征词向量X={x1,x2,…,xn} 表示,其中xi∈T(1≤i≤n)。 则对任何满足P(tk)>0的tk都有公式
(1)
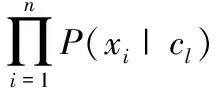
由于在给定的输入中P(cl)是一个常量,且取最大后验概率作为样本所属类别
(2)
式中:c(tk) 为该文本所属类别对应的数值。
1.2 补集朴素贝叶斯模型
传统分类算法都假设类的样本数量大致相同,面对不均衡样本时,由于少数类信息表达不充分,而多数类信息提取更充分,分类模型易将少数类样本分到多数类,导致分类性能大大降低。补集朴素贝叶斯[15](complement Naive Bayes,CNB)模型的基本思想是在估计文本属于某一类别的概率时,通过估计文本不属于该类别的概率,即利用补集的特征来表示当前类别的特征,进而预测待分类文本的类别,以解决分类模型容易倾向大类别而忽略小类别的问题。
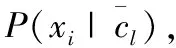
(3)
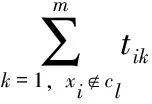
用CNB模型对文本tk进行分类,得该文本的类别最大值cCNB(tk)
(4)
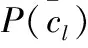
2 特征选择与权重计算
2.1 基于卡方检验的特征选择
基于特征独立性的NB算法假设所有特征词对文本分类的贡献相同,但实际上,向量化后文本的特征维数高达上万维,每个特征词的重要性也不相同的。若一个特征词在某一类别中多次出现,而在其它类别中很少出现,则认为该特征词具有较高的类别区分度[16]。
常用的特征选择方法有基于词频、方差、信息增益、互信息、卡方检验等[17]。常规的特征选择方法对小类别的特征提取不足,卡方检验度量了特征词与类别的关联程度[18],能通过计算关联度来进行特征选择。特征词xi相对于类别cl的卡方值χ2(xi,cl) 计算公式如下
(5)
式中:fa表示类别cl中出现特征词xi的文本数;fb表示除类别cl的其它类别中出现特征词xi的文本数;fc表示类别cl中未出现特征词xi的文本数;fd表示除类别cl的其它类别中未出现特征词xi的文本数。
利用最大值思想计算特征词xi对于训练集文本的卡方值,公式为
(6)
对特征全集的卡方值进行降序排列,并选取前z个特征词以构成特征子集。
2.2 基于TF-IDF特征加权算法的改进
2.2.1 TF-IDF加权算法分析
词频-逆文档频率[19](term frequency-inverse document frequency,TF-IDF)为应用最广泛的特征词权重计算方法之一。TF是局部加权因子,反映特征词xi相对于文本tk的重要度,默认出现次数越多越重要;IDF是全局加权因子,反映特征词xi相对于整个训练集的重要度,即包含特征词的文本越少,特征词越重要。
第i个特征词权重计算公式如下
(7)
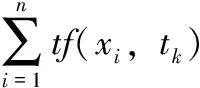
(8)
TFIDF(xi,tk)=TF(xi,tk)·IDF(xi)
(9)
式中:N表示训练集的文本总数;df(xi) 表示包含特征词xi的训练集文本数;TFIDF(xi,tk) 为特征词xi的TF-IDF 值。
在特定的分类任务中,N是一个常数。因此,IDF(xi) 随着df(xi) 的增大而减小,即特征词xi的IDF(xi) 值与出现该词的文本数成反比。故IDF能使TF的敏感性降低。
IDF主要有两个缺陷,第一,仅有极少数文本出现某一特征词时,其IDF值趋近无穷大;第二,若某一特征词出现在很多文本中,则IDF约等于零[20]。此外,IDF忽略了特征词在类内和类间的分布,当特征词在某一类内频繁出现,而在其它类中出现较少,则认为该词具有良好的类别区分能力,但由于包含该词的文本数较多,其权重可能并不高。
2.2.2 TF-IECF与TF-RIECF
为减小具有高TF、增强具有低DF与高类别区分度的特征词对权值的影响,本文用具有以下属性的新全局加权因子替换IDF因子:
(1)当DF值增加时,全局加权因子具有较大的衰减率;
(2)为避免被零除,df(xi) 不能当作分母;
(3)函数是有界函数。

(10)
(11)
观察式(10)和式(11),IEF与RIEF因子仍未解决特征词在类内和类间的分布问题,本文引入类内及类间加权因子。类内加权因子I(xi)反映所有类别中包含特征词xi文本数最多的那一类的分布情况,值越大代表该词在某类中分布越广;类间加权因子B(xi)反映特征词xi在各类间的分散程度,值越大代表该词出现的类别越集中。类内加权因子I(xi)和类间加权因子B(xi)的公式如下
(12)
(13)

综上,本文将改进的特征加权算法命名为词频-类别逆(根)指数频率(term frequency-(radial) inverse exponential class frequency,TF-(R)IECF),其公式如下
(14)
(15)
3 TF(R)IECF-WCNB模型
TF(R)IECF-WCNB模型分别使用TF-(R)IECF特征加权算法计算文本中经过CHI特征选择后的特征词权重。假设特征词xi在文本tk中归一化后的权重为wik,并用wik修改式(3)
(16)
特征词xi对类别cl的权重Wil计算公式如下
(17)
将式(17)标准化
(18)
根据式(18)修改式(4),得出待分类文本D的最大后验概率cWCNB(D) 为
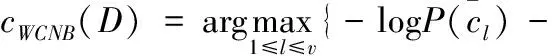
(19)
文本D的所属类别即为cWCNB(D)所对应的类别。
4 物流新闻分类方法
4.1 物流新闻语料库构建
文本分类已经涉及多个领域,但迄今为止,尚没有公开的物流新闻分类语料库。因此,本文爬取中国物流信息中心网、中国贸易金融网等多家官方物流信息网站共4856条物流新闻,新闻文本具有真实性与一定的权威性。从物流领域的角度出发,结合当下物流热点,在各网站物流新闻划分的基础上,将物流新闻语料库划分为6个类别[21]:采购、仓储、运输、冷链、电子商务和快递配送。物流新闻语料库类别分布情况如图1所示。

图1 物流新闻文本分布
根据图1所示,实验使用的新闻文本类间数量有一定差距,仓储类与运输类占总数据集的51%,其余4类共占49%,体现物流新闻的不均衡性。
4.2 物流新闻分类流程
物流新闻分类流程分为三大模块:构建物流新闻语料库、TF(R)IECF-WCNB分类器分类和输出分类结果。本文通过获取已发布的物流新闻来构建物流新闻语料库,将原始语料库划分为训练集和测试集,对分类器进行训练和测试,最终输出分类结果。全流程用Python语言实现。物流新闻分类流程如图2所示。

图2 物流新闻分类流程
TF(R)IECF-WCNB分类器分类分为两大过程:训练过程和测试过程。训练过程利用划分的训练集训练分类模型。主要步骤为:
步骤1 文本预处理。实现所有文本的分词、剔除停用词和去标点符号等操作。根据物流领域专业文本词汇特征,在原有jieba分词词库的基础上,人工构建并添加物流专业词库,防止物流专业词汇在分词阶段被误切,如:“冷链”被误切为“冷”和“链”。依据物流新闻文本特点,修改中文停用词表,作为本文的停用词表。使用正则表达式匹配并删除无关的英文及标点符号;
步骤2 文本向量化。将分词后的文本转化为向量空间模型(vector space model,VSM)中的向量,生成文本-词语矩阵,矩阵元素a[i][j] 表示第j个词语在第i个文本下的词频;
步骤3 CHI特征选择。原始文本-词语矩阵特征维度过大,进行特征选择不仅可以筛选出正确分类有贡献的特征词,还能大大缩短分类时间。计算每个向量的CHI值,将计算结果按照降序进行排序,选择前z个特征词,构成特征子集;
步骤4 特征加权。对特征子集中的特征词用TF-IECF或TF-RIECF特征加权算法计算每个特征词的权重,并以权重更新文本-词语矩阵;
步骤5 构建并训练模型。构建加权补集朴素贝叶斯模型,以特征加权后的文本-词语矩阵作为输入,训练模型。
测试过程中的测试集经过相同的预处理、向量化和特征选择后,利用已训练的加权补集朴素贝叶斯模型对物流新闻测试集进行分类,最终输出分类结果。
5 实验与分析
5.1 评价指标
文本分类的评价指标分为局部指标和全局指标。局部指标主要有准确率P和召回率R。准确率描述当前类别分类正确的文本占分类至当前类别文本总数的比例;召回率描述当前类别分类正确的文本占当前类别文本总数的比例。全局指标有精确度和Kappa系数[22]。相较于精确度,Kappa 系数更适合应用于多分类模型评价。本文使用两种局部指标与全局指标Kappa系数来评价模型。
两种局部指标公式如下
(20)
(21)
式中:TP表示正确分类至当前类别的文本数;FP表示其它类别文本错分类至当前类别的文本数;FN表示当前类别文本错分类至其它类别的文本数
(22)
(23)
Kappa系数公式中,ai表示第i类文本的实际样本数量;bi为预测出的第i类文本样本数量;M表示样本总数;Kappa取值范围[0,1],数值越大代表模型分类效果越好。
除局部、总体指标外,本文定义模型分类时间,特指文本向量化至输出最终分类结果的时间间隔,也用于评价模型性能。
5.2 结果与分析
本文分别使用基于NB模型、MNB模型、CNB模型、TFIDF-WCNB模型、TFIECF-WCNB模型和TFRIECF-WCNB模型的6种分类器,进行两组实验。
实验1:为了达到最优模型性能,对原始特征词用CHI进行特征选择时,实验对特征词维度z的取值从0开始以间隔400为单位逐渐递增。z=0代表不进行特征选择。特征词维度z的取值对CNB模型的全局指标Kappa系数的影响如图3所示。
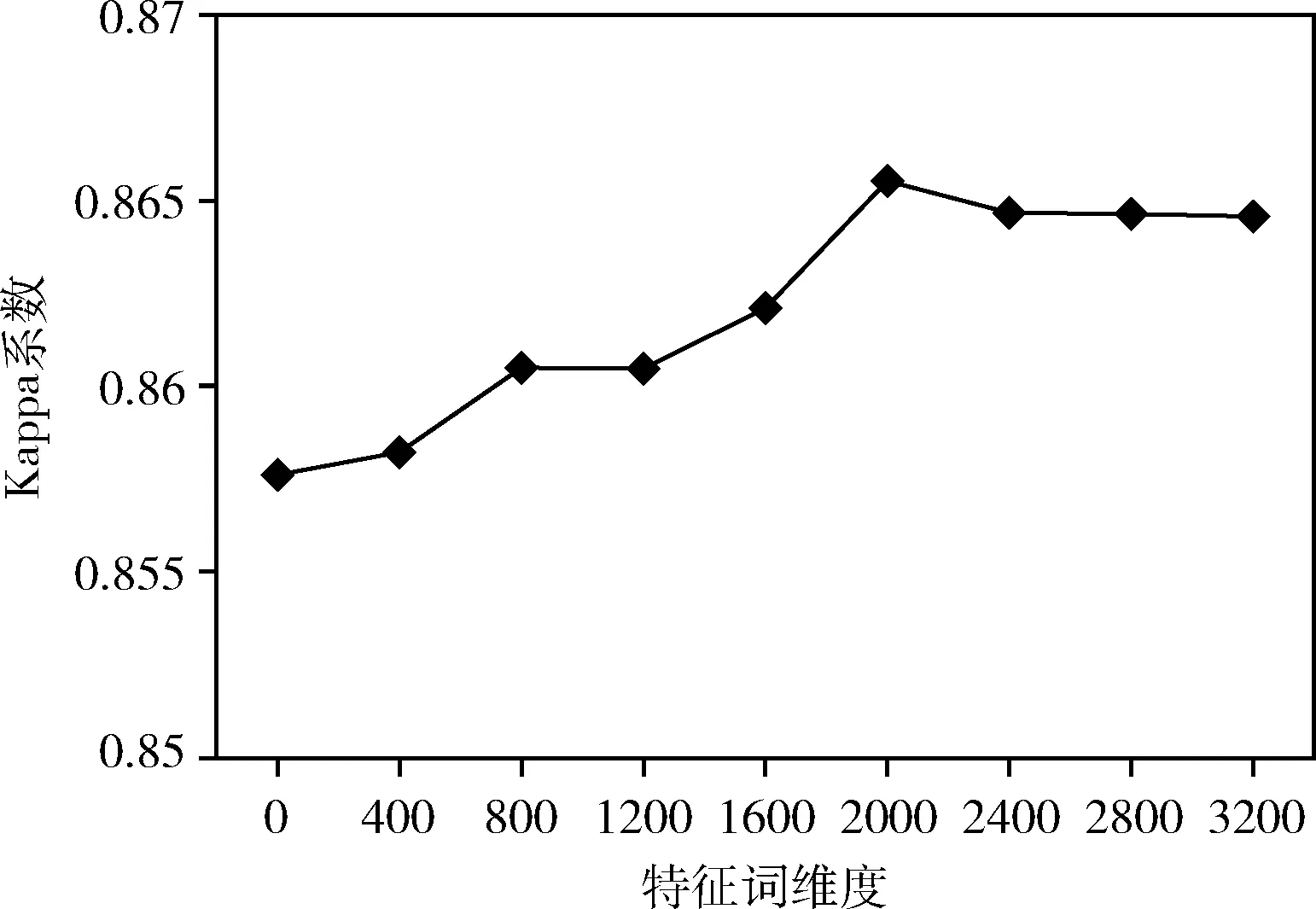
图3 特征词维度取值对Kappa系数的影响
从图3的折线图可以看出,特征词维度z从0以400为单位递增到2000的过程中,随着特征子集增大,所选特征词对各类别特性表述的完整性提高,描述的类别信息增多,CNB模型分类的Kappa系数也不断增加;当z取值大于2000时,特征子集所表述的类别信息临近饱和,特征词维度的增加并不能增多其对各类别信息表述,反而导致模型出现轻微过拟合现象,故Kappa系数随着z值的增加而缓慢减小,直至平稳。当z=2000时,模型分类性能最优。
实验2:在特征词维度z=2000的条件下,比较各模型在物流新闻语料库的6个不同类别内的分类性能。实验采用Laplace平滑方法,即先验平滑因子α=1。各模型不同类别下的准确率P和召回率R对比如图4所示。

图4 z=2000时各模型局部指标对比
由图4可以看出,各模型不同类别的分类效果不同,运输类、冷链类和电子商务类分类效果较好;快递配送类分类效果最差。传统NB模型在6种模型中,其准确率和召回率皆为最低,分类性能最差。在NB模型的基础上,形成的服从多项分布的MNB模型其局部指标较NB模型有较大提升。适用于不均衡数据集的CNB模型与适用于均衡数据集的MNB模型相比,无论大类别还是小类别,其两种局部指标大都有所提高,且小类别表现更好,验证了CNB模型能有效利用补集的思想弥补传统模型小类别信息提取不充分的缺陷。运用传统特征加权思想的TFIDF-WCNB模型,由于其IDF因子原有的缺陷且忽略了特征词在类内、类间的分布,分类准确率较CNB模型并无较明显提升,相反,在运输类、冷链类、电子商务类中其准确率不升反降,表明对不均衡数据集的特征词用传统算法进行加权,不一定能取得理想的效果。本文对CNB模型进行改进,提出的TFIECF-WCNB模型和TFRIECF-WCNB模型与TFIDF-WCNB模型相比,局部指标都有一定程度的提高,且小类别较大类别提升更明显。从总体上看,TFRIECF-WCNB模型的在各类别的分类效果最好,TFIECF-WCNB模型次之,实验结果验证了基于TF(R)IECF-WCNB模型的分类器对类别分布不均衡物流新闻分类的有用性。
各模型全局指标Kappa系数与模型分类时间见表1。
根据表1的分类结果,传统NB模型分类效果最差,虽然MNB、CNB模型相对于NB模型在Kappa系数上有很大提升,但也大幅增加了其时间复杂度。对特征词进行加权处理,在小幅提升Kappa系数的同时,能大幅缩短分类时间。本文提出的TFIECF-WCNB模型和TFRIECF-WCNB 模型在Kappa系数和分类时间这两个指标上,都是最佳的。其中,TFRIECF-WCNB模型分类性能最优,其全局指标高达0.8945,且分类时间最短为50.5 s。

表1 z=2000时各模型Kappa系数与分类时间
综合对局部、全局指标和分类时间的分析,本文提出的基于TF(R)IECF-WCNB模型的分类器能快速、准确地对物流新闻进行分类,并验证了TF(R)IECF-WCNB模型在类别分布不均衡的物流新闻文本分类上的优势和可行性。
6 结束语
本文采了一种改进的朴素贝叶斯模型即加权补集朴素贝叶斯模型,用以实现对不均衡物流新闻文本进行分类,并取得了较好的分类效果。NB算法是一个稳定的算法,基于NB算法改进的模型,在保证分类模型的强稳定性同时,还具有较高的计算效率与分类精度。
通过构建物流新闻语料库,并针对语料库中各类别文本数量分布不均衡与专业性强的特点,对文本进行预处理,使用卡方检验进行特征选择,对传统TF-IDF算法进行分析,提出、改进并形成了TF-(R)IECF特征加权算法,解决了传统加权算法对特征词在各类别间分布情况重视不足的问题。实验结果表明,基于TF(R)IECF-WCNB模型的分类器,解决了传统分类器容易倾向大类别而忽略小类别的问题,面对类别分布不均衡的物流新闻数据集,表现出良好的分类性能。
国民经济快速发展的今天,物流业已成为助力经济发展不可或缺的一部分。在物流业快速发展的背景下,快速而准确对物流新闻进行分类,以满足新闻时效性、准确性和真实性三大特性,对相关物流机构及用户来说具有重要的意义。
猜你喜欢
计算机技术与发展(2018年8期)2018-08-21 02:08:14
中国机械工程(2017年22期)2017-12-02 01:52:34
数理化解题研究(2017年4期)2017-05-04 04:07:54
电子制作(2017年23期)2017-02-02 07:17:06
铁道通信信号(2016年6期)2016-06-01 12:10:20
西北工业大学学报(2015年4期)2016-01-19 03:31:47
电子器件(2015年5期)2015-12-29 08:43:15
中文信息学报(2015年4期)2015-04-21 08:29:12
郑州大学学报(理学版)(2014年2期)2014-03-01 04:20:49
振动工程学报(2014年4期)2014-03-01 01:15:41
