
基于事件演化图与图卷积神经网络的事件预测
2022-02-03 13:12张作为
中文信息学报 2022年12期
唐 彦,陈 逸,张作为
(河海大学 计算机与信息学院,江苏 南京 211100)
0 引言
事件预测是事件研究的下游任务,现有研究大多都是在已经抽取出的事件基础上挖掘事件之间在时间维度、因果维度上的联系,从外部语料中获取先验知识和事件演变规律来支撑推理和预测。事件预测作为事件推理的主流方向,最早由Chambers和Jurafsky等人[1]提出,任务被定义为根据一个由事件链构成的事件语境,从候选后续事件列表中预测出正确的后续事件,经过多年的发展目前已经取得很好的应用结果。通过将语料库中总结出的事件发展演变规律和模式作为先验知识指导预测最终的后续事件,事件预测在医疗领域预测病人最终恢复情况、在金融领域预测商品和股票的走势、在政府管理领域预测宏观调控政策最终影响等方面,均有极大的应用价值[2-4]。
事件预测的形式化描述如下: 给定一个由初始文本表示的事件语境C和k个候选后续事件{c1,c2,…,ck},事件预测模型先从事件语境中抽取出一个事件链(事件序列)c={e1,e2,…,en}对其进行抽象表示,其中ei为采用预先定义好的事件结构,表示语境中的第i个事件。然后从每个候选后续cj中提取出一个事件ecj对其抽象表示。事件预测就是提取事件特征来构建事件的表示向量,计算候选后续事件ecj与事件链c之间的关联性,选取关联性最强的后续事件为预测结果。
举例来说,图1中事件预测模型先抽取语境中所有的事件并用统一的结构(事件主语,谓语,宾语,间接宾语)进行表示,然后计算每一个候选后续事件与语境中事件相似度的加权和作为该候选事件为预测结果的置信度,最后选择置信度最大的(客户,离开,餐厅,-)事件为该语境的预测后续事件。

图1 事件预测示意图
事件预测方法大致可以分为三类[5-7]: 基于事件对的方法;基于事件链的方法;基于事件图的方法。随着神经网络模型不断发展并被用来建模事件序列,基于事件对的统计性方法逐渐被取代,基于事件链的方法采用LSTM等结构可以对长距离事件链进行编码而不丢失历史信息[8]。然而,基于事件链的方法并没有完全挖掘出事件之间的关系。近年来,基于事件图的GCN模型被提出,进一步提升了事件预测的性能[9]。如何从语料中抽取事件、提炼事件演变规则和模式并构建事件演化图来预测事件已成为事件预测领域的一个重要研究方向。
经过多年发展,事件预测研究已取得显著进步,但还存在以下三个问题:
(1) 事件之间的联系未充分挖掘。传统的基于事件对的统计学事件预测模型常常受制于数据稀疏问题。基于事件链的事件预测方法通过向量化完成事件到低维度特征的映射,并且利用神经网络的强序列学习能力提高事件预测的准确率[8]。但该类方法缺乏外部先验知识的指导,在复杂语境下的预测结果不佳。本研究通过构建事件演化图并利用图神经网络的表示能力充分挖掘事件之间的关系。
(2) 事件演化图的信息丢失问题。构建事件演化图,首先需要从初始语料中抽取出结构化的事件信息,传统的事件抽取方法往往采用基于模式匹配的方法,该类抽取方法的缺点是精度不高。此外,在设定事件演化图中边的权重时,现有方法往往是以共现在一个事件链上的事件频率作为权重[10],忽略了节点之间的互信息,即若两个事件经常成对出现在同一个事件链,那它们之间的权重应该更大一点。本研究引入事件互信息改进了事件演化图的构造,并应用前期的事件抽取研究成果[11],改善了事件抽取精度低和信息丢失等问题。
(3) 事件语境的序列信息被忽略。将事件的表示向量输入到神经网络中经过多跳更新每个事件的表示向量,依据相似度预测后续事件是基于图的事件预测模型的传统做法[9]。但该类模型仅仅利用子图来挖掘事件之间的关系,忽略了语境的序列信息。本研究利用BiLSTM和记忆网络共同挖掘事件语境的序列信息,充分利用语境信息提高事件预测的准确率。
为解决上述三个问题,该文提出了基于事件演化图与图卷积神经网络的事件预测模型。首先,从语料库中抽取结构化事件构建事件演化图,作为事件的演变模式引入到事件预测模型中,充分挖掘事件之间的关系。然后,利用事件抽取模型完成语料库的事件抽取并在定义事件演化图中边的权重时结合了事件之间的互信息,改善了事件抽取精度低和信息丢失问题。最后,在现有方法的基础上利用BiLSTM结构先获取语境的序列关系,更新语境中事件节点的初始表示向量,再利用记忆网络更新候选后续事件的初始表示向量,弥补语境的序列信息丢失问题。
在基准数据集Gigaword上进行的事件预测对比实验结果表明,本文模型在准确率(Accuracy)评价指标上优于六种典型的事件预测方法。对比基线方法SGNN[10],精度提高了5.55%。有效提高了事件预测的准确率。本文的主要贡献如下:
(1) 提出了一种基于事件演化图和图卷积神经网络的事件预测模型,该模型使用改进的事件演化图来指导图卷积神经网络节点间的信息传递,获得上下文和邻域感知的完整事件表示向量,提升了事件预测性能。
(2) 对传统的事件演化图的构建方法做出改进,结合事件频率和互信息作为图中边的权重,进一步捕捉事件之间的关系。
(3) 引入了BiLSTM和记忆网络更新事件的表示向量,获取上下文感知的事件语境表示,实现更准确的事件预测。
1 相关工作
脚本事件预测任务被定义为,给定一个事件上下文语境和候选后续事件列表,从候选事件列表中选取最合理的后续事件。事件预测方法主要分为: 基于事件对、基于事件链和基于事件图三种类别。早期的研究主要是基于事件对挖掘事件关系指导事件预测,通过从语料中计算事件之间的互信息作为它们之间的关联强度并据此做出事件的预测[6,12]。Chambers等人在对事件预测任务做出定义后,利用指代消解技术有效解决了文本中实体指代不明的问题,完成了大规模语料中脚本事件链的抽取,并使用槽填充的方式来评估事件预测模型。基于事件对的方法主要是通过统计学的方法计算事件对共现率来刻画事件对之间的关系,割裂事件为个体,忽略了上下文之间的联系。
随着神经网络模型不断发展并被用来建模事件序列,基于事件对的统计性方法逐渐被取代,基于事件链的方法可以对长序列事件链进行编码而不失去上下文信息[6,13]。该类方法通常是引用循环神经网络(RNN),以整体语境为单位实现信息从事件链的头部事件传递到尾部事件,每个事件的表示向量都包含了上下文信息,可以进一步利用事件之间的关系更为准确地计算事件相似度完成事件预测。Wang等人[14]提出MemNet模型,该模型拼接事件四个组成部分的词嵌入作为事件的初始表示向量。该模型使用事件链完成事件预测工作,但会遗漏事件之间丰富的关联信息,可以利用基于大量语料构建出的图进一步挖掘事件之间的关系。
目前,基于事件链的方法并没有完全利用事件之间的关系,基于事件演化图的图卷积网络模型被提出来指导正确的后续事件预测[7,15]。Duvenaud[2]为解决CNN在非结构数据上的限制,介绍了一种可直接对图进行运算的网络模型,可以用任意大小和形状的数据作为输入完成事件预测任务的端到端学习。Kipf和Welling[3]提出了一种基于卷积神经网络的可伸缩半监督学习方法。Li等人[4]将门循环单元的现代优化技术引入GCN,进一步提高了事件预测的效果。但该类方法通常采用单个结构的网络模型,忽略了事件语境的序列信息,并且没有充分挖掘出语料中事件之间的关系,限制了事件预测的性能。
2 事件预测模型
2.1 模型总览
事件预测的总体流程如图2所示,本文的工作围绕事件演化图的构建和事件预测两个部分展开。主要技术环节和处理步骤与图2中的标注序号一致,具体描述如下。

图2 事件预测总体流程图
(1) 事件抽取: 利用事件抽取模型从初始语料库中抽取事件,并依据事件主语构成事件链。
(2) 事件演化图的构建: 抽象事件演化图中的节点结构,依据频率和互信息计算节点之间边的权重。
(3) 获取事件语境表示并更新后续事件节点的表示: 拼接事件的四个组成元素的词向量作为事件的表示向量,从事件语境中提取事件序列,输入到BiLSTM中获取上下文感知的事件语境表示,更新事件语境中每个事件节点的表示向量,并利用记忆网络更新候选事件节点的表示向量。
(4) 利用GCN网络获取高阶事件表示: 从事件演化图中选取包含事件语境中事件节点和候选节点的子图,将事件演化图中边的权重作为邻接矩阵,将事件节点的表示向量和候选后续事件节点的表示向量作为初始向量,输入到GCN中,经过多跳的信息传递,获得事件节点的高阶表示向量。
(5) 基于相似度的后续事件预测: 对于每一个候选后续事件节点的表示向量,计算其与事件语境中事件节点的加权相似度,选择相似度最大的候选后续事件作为该事件语境的后续事件。
2.2构建事件演化图2.2.1 抽取事件链
传统的事件演化图通常是将从初始文本中抽取的事件抽象化为一个由四个元素组成的结构:{P(a0,a1,a2)},其中,P为事件的谓语,a0为事件的主语,a1为事件的宾语,a2为事件的间接宾语。
为了便于与之前的研究进行对比实验,本文采用相同的新闻语料作为初始文本,并且定义了相同的事件组成结构。与传统研究中构建事件演化图不同的是,本文采用我们前期提出的事件抽取模型[11]从初始新闻语料文本中完成事件的抽取。事件结构中的谓语P对应的是事件触发词,在检测出文本中所有的触发词后,再分别完成与每一个事件触发词对应的主语、宾语、间接宾语三种事件元素角色的抽取,与对应的事件触发词组成一个结构完整的事件。
在抽取出所有的事件后,遵循先前研究,将事件主语相同的事件划分到一个事件链,得到事件链集合S={s1,s2,s3,…,sn},其中,si={T,e1,e2,e3,…,em}为一个事件链,ei为事件链中的事件,T为这些事件共有的主语。例如,一个完整的事件链si= {T= 客户, 步行(T, 餐厅, -), 坐下(T, -, -), 阅读(T, 菜单, -), 点餐(T, 食物, -), 用餐(T, 食物, 叉子), 付款(T, 服务员, 手机)},主语T为客户,为该事件链所有事件的共享主语。
2.2.2 构建事件演化图
完成事件的抽取得到事件链后,需要进一步构建事件演化图,抽取出的事件集合即该图的顶点集,但是继续采用四部分组成的事件结构作为顶点会带来事件演化图的稀疏性问题。事件演化图更多地是挖掘语料库中事件谓语的发展模式,进而指导事件预测。因此本文遵循先前的研究[10],将事件节点抽象为一个二元组结构ei=(vi,ri)表示图中的事件节点ei,其中,vi为事件谓语,ri为该谓语与事件主语之间的语法依赖关系。在统计出所有的(vi,ri)二元组后,将其作为事件演化图的顶点集,下一步需要确认事件演化图中事件节点之间有向边的权重。
传统研究仅统计节点与邻居节点共同出现在一个事件链上的频率作为边的权重,本文在此基础上加入节点之间的互信息作为边权重的另一个指标,互信息主要衡量的是两个事件节点分布集合之间的相关性。互信息计算由式(1)定义,并在此基础上更新节点之间的有向边的权重计算如式为(2)所示。
其中,I(ei;ej)为事件节点之间的互信息,Num(ei,ej)为同时包含事件ei和事件ej的事件链的数目,n为事件链的总个数,Num(ei)为仅包含事件ei的事件链个数。freq(ei,ej)为事件节点vi和vj出现在语料库中的频率,ek为事件节点ei的邻居节点。
经过对事件演化图中点和边的定义及计算后,可以以大型语料库为基础构建出一个完善的事件演化图。事件演化图从大量文本中抽取丰富的事件联系信息,可以作为特定领域内事件的通常发展模式和规则信息,引入到事件预测模型中,充分挖掘并利用事件之间的联系来指导事件的预测任务。本研究构建出的大型事件演化图部分子图如图3所示。
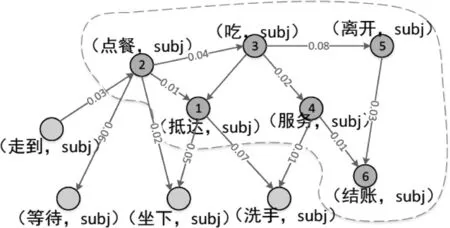
图3 事件演化图部分子图的示意图
2.3 基于事件演化图和GCN的事件预测模型
事件预测任务被定义为: 给定待预测的事件语境,从候选后续事件列表中预测出最为可能的后续事件。构建的事件演化图可以看作事件发展的规则,图中边的权重用于获取事件之间的关联信息以指导事件预测。本节提出的基于GCN及事件演化图的事件预测模型详细结构如图4所示,由以下几个部分组成。
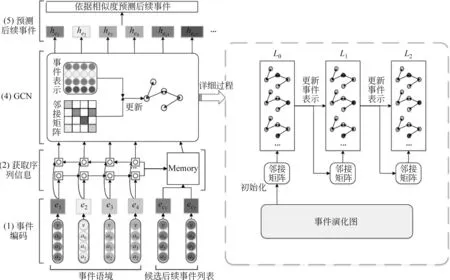
图4 事件预测模型图
(1) 事件编码: 对于事件语境中的事件序列和候选后续事件列表中的事件,需要对其进行编码表示,作为模型的初始输入向量。事件结构包含四个元素,本节将四个元素的词向量拼接起来作为事件的表示向量。
(2) 获取序列信息: 将事件语境中的事件集作为一个事件序列,输入到BiLSTM网络来获取事件序列的表示,更新语境中每个事件节点的表示向量,使其包含语境上下文信息。
(3) 记忆网络更新候选事件节点向量: 初始的候选事件节点向量仅仅是自身的特征表示,与事件语境彼此分割,引入记忆网络更新候选节点的事件向量,使其包含更深层次的语义信息。
(4) 利用GCN网络获取高阶事件表示: 从事件演化图中选取包含事件语境中事件节点和候选节点的子图,子图中点之间的边权重作为GCN的邻接矩阵,将经过步骤(2)、步骤(3)更新后的事件节点表示作为GCN输入,经过多跳的信息传递后获取每个事件节点的高阶表示向量。
(5) 预测后续事件: 计算每个候选后续事件与事件语境之间的向量相似度,选取相似度最大的候选后续事件作为该语境的事件预测结果。
2.3.1 事件编码
依据前文所述,事件结构被定义为四个元素组成: {P(a0,a1,a2)},其中,P为事件的谓语,a0为事件的主语,a1为事件的宾语,a2为事件的间接宾语。四个组成部分包含的信息对描述整个事件都是必不可少的,因此本节采取拼接事件谓语和三个事件元素的词向量的方式来对整个事件进行编码表示。
给定一个事件ei={P(a0,a1,a2)}以及该事件四个组成元素的词向量,拼接四个词向量作为整个事件的表示向量,完成事件到表示向量的映射,并将事件的表示向量作为模型的初始输入,如式(3)所示。
Ei=Embp⊕Emba0⊕Emba1⊕Emba2
(3)
通过拼接操作,将输入事件语境{e1,e2,…,en}和候选后续事件列表{ec1,ec2,…eck}中的每个事件ei转换成实数值向量Ei,该向量包含事件结构的四个组成部分信息,能完整表示事件。
2.3.2 获取事件语境中事件的序列信息
事件语境中的事件初始表示向量仅对事件本身信息进行了编码,忽略了整个语境的上下文信息,本节通过引入BiLSTM结构捕获每个事件的前序事件的信息和后续事件的信息。
将事件语境中的事件表示向量Ei输入到一个隐藏层状态大小为h的BiLSTM中,将得到的前向隐藏状态和反向隐藏状态拼接起来作为事件新的更抽象的表示向量hi∈(h*2),使其包含整个语境的信息。通过本节完成事件语境中{e1,e2,…,en}的事件表示向量的更新,具体如式(4)所示。
(4)
2.3.3 记忆网络更新候选事件节点向量
候选后续事件作为整个事件语境的后续预测,应该与语境之间存在信息流通而不是独立存在。本节首先获取整个事件语境的表示,然后引入记忆网络,利用该向量完成候选后续事件列表中事件节点向量的更新。
语境中不同事件对整个语境特征表示的贡献不同,引入注意力机制计算事件表示向量的加权和作为整个事件语境的表示向量C,如式(5)~式(7)所示。
其中,hi为事件语境中的第i个事件ei的表示向量,Ec为候选后续事件的初始表示向量,Wei、Wc和bu为模型参数,通过计算更新后的事件表示向量hi的加权和得到整个事件语境的表示C。
得到语境表示向量C后,利用它对候选后续事件的初始表示向量Ec做进一步的运算处理,通过记忆网络选择性保留候选后续事件的初始信息并添加语境信息,得到候选事件的最终表示向量hc。具体步骤如式(8)~式(11)所示。
η=σ(WηC+UηEc)
(8)
λ=σ(WλC+UλEc)
(9)

(10)
(11)
2.3.4 基于GCN网络的事件高阶表示
经过上述处理,将事件语境{e1,e2,…,en}和候选后续事件列表{ec1,ec2,…eck}进行向量表示和进一步的更新,分别得到语境事件节点和候选后续事件节点的表示向量{h1,h2,…,hn}和{hc1,hc2,…,hck},但是该向量仅仅是从事件链的角度对事件进行了抽象表示,事件之间的联系并没有被完全利用。2.2节构建的事件演化图在大量外部知识的基础上以边权重的方式刻画了事件节点之间的联系性,可以看作是抽象化的事件发展模式和准则,本节利用事件演化图和图卷积网络充分挖掘事件之间的联系,进一步抽象事件语境和候选后续事件列表中事件节点的表示向量,便于提高后续的事件预测准确率。
选择事件语境和候选后续事件列表中的事件节点作为GCN的顶点集,事件向量矩阵h(0)、邻接矩阵A作为GCN的输入,其中h(0)={h1,h2,…,hn,hc1,hc2,…,hck}(n为事件语境中事件个数,k为候选后续事件列表中事件个数),A∈(n+k)*(n+k)被定义如式(12)所示。

(12)
得到输入向量矩阵h(0)和邻接矩阵A后,利用GCN的多跳传输实现图中节点的信息流通,每个事件节点都获取了其邻居节点的信息,得到最终的事件表示向量,具体如式(13)~式(17)所示。
通过式(13)得到图中每个节点与邻居节点之间的加权向量和a(t)。利用式(14)和式(15)分别得到更新门z(t)和重置门r(t),其中,σ为logistic函数。以上一跳输出h(t-1)为输入,式(17)被用来计算新的输出h(t)。经过若干次信息更新后得到事件的高阶表示向量h(t)。
2.3.5 依据相似度完成后续事件预测
经过GCN对每一个事件节点进一步抽象化后,得到最终的事件隐藏状态矩阵: {h1(t),h2(t),…,hn(t),hc1(t),hc2(t),…,hck(t)},其中,n为事件语境中事件个数,k为候选后续事件列表中事件个数。对于每一个候选后续事件ecj,计算其与整个事件语境的相似度作为被预测为后续事件的得分Simj,然后选取得分最高的候选后续事件作为该语境的预测结果。相似度计算如式(18)所示。
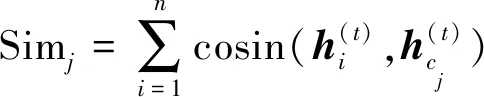
(18)

式(18)只是将所有语境中的事件与候选事件的相似度求和,忽略了语境中不同的事件对评判正确结果的权重不同。因此引入一层注意力机制,分配更多的注意力到对预测后续事件影响权重更大的事件上,新的相似度计算公式被定义如式(19)~式(22)所示。
其中,Wh和Wc为权重参数,bu为偏置项,αij反映了事件语境中事件ei和候选后续事件ecj表示向量的相似度对总体相似度的影响权重。
本文通过交叉熵损失函数进行事件预测模型的训练,具体损失函数如式(23)所示。
(23)
其中,margin为损失函数的参数,y为语境正确的候选事件编号,θ为模型参数集合,λ为L2正则化参数。
3 实验
3.1 数据集和实验设置
仿照Granroth-Wilding和Clark[16]的先前研究,本文以Gigaword语料库[17]的NYT部分作为事件抽取的语料库,并同样使用OpenNLP工具完成分词和共指消解等预处理工作。Gigaword语料库是事件预测领域的标准数据集。将抽取出的5 728 635条事件链用以构建事件演化图,训练集包含50 000条事件链,测试集包含5 000条事件链,发展集包含5 000条事件链。对于每一个事件语境有五个候选后续事件,有且仅有一个是正确结果。详细数据集的统计结果如表1所示。

表1 数据集数据统计表
构建事件演化图的过程如下:
(1)事件抽取: 利用前期研究的事件抽取模型[11]从初始语料库中抽取事件,并依据事件主语构成事件链;
(2)构建事件演化图: 遵循研究[10],将事件节点抽象为一个二元组结构ei=(vi,ri),事件演化图中事件节点之间有向边的权重计算使用式(1)、式(2)完成。本研究构建出的大型事件演化图部分子图如图2所示。
经过多轮实验对比和参数调优实验,并参考文献[10],在本节实验中,词向量维度设为300,BiLSTM的隐藏层维度为128,Adam优化算法学习率设为0.001,损失函数参数margin设为0.015,L2正则化参数λ设为0.0001,参照文献[8]中的设置并结合参数调优实验,GCN的信息传输跳数K设为2。经过多轮实验比较,本实验中Batchsize设为500。同时,为避免与训练集过拟合,模型设置Dropout率为0.20。
对于事件预测任务,本文采用正确率作为评判指标,正确率指的是后续事件预测正确的语境数占所有事件语境数的比例,具体形式如式(24)所示。
(24)
其中,Numt为模型预测正确的语境个数,Numa为所有待预测的语境个数。
3.2 基线方法对比实验
为了评估本文的模型,本节选取了其他六种代表性的事件预测方法作为基线方法。这些实验基于相同的训练集、测试集,相同的词向量表示和相同的实验设置。对比的基线方法如下:
(1)PMI[1]: 通过计算互信息来预测后续事件的共现模型。
(2)BiGram[5]: 通过计算双字符概率来衡量事件之间联系的计数模型。
(3)EventComp[16]: 由Granroth-Wilding 和Clark提出,他们使用Siamese网络计算事件对之间的分数来学习事件的特征表示。
(4)RNN: 直接将事件表示向量输入到一个RNN网络中来对事件链进行建模,忽略了事件对之间的联系。
(5)PairLSTM[14]: 将事件初始向量输入到双向LSTM中得到隐藏层的状态作为事件的表示,联合语境的序列信息和事件对信息来计算候选后续事件与事件语境之间的相关性得分。
(6)SGNN[10]: 构建事件演化图建模事件之间的关系,然后将事件语境和候选后续事件作为图的节点输入到GNN中参与运算,更充分利用了事件之间的关系,但是忽略了语境中事件的序列信息。
本文模型与基线方法对比实验的详细结果如表2所示。

表2 对比实验结果
将传统的基于数理统计的方法PMI和BiGram与其他神经网络模型对比,可以发现数理统计方法准确率远低于深度学习方法,这主要是由于传统方法缺乏对事件的语义表示能力以及分布的稀疏性。深度学习方法通过一个低维度向量来表示事件,解决了稀疏性问题,有效提高了实验准确率。BiGram方法与PMI方法相比,增加了事件对的信息,但是效果提升却不明显,这也是事件表示的稀疏性造成的。
将基线方法EventComp、PairLSTM以及SGNN方法对比可以发现,EventComp方法的准确率最低,这是因为该方法仅仅从事件对的角度利用事件之间的联系性做事件预测。在加入事件链的序列信息后,PairLSTM取得了更好的实验结果。SGNN方法同样构建了一个事件演化图,尝试从图的角度进一步挖掘事件之间的联系,在三个基线方法中取得了较好的实验结果。
将基线方法与本文模型方法比较,本文模型通过BiLSTM结构获取事件语境的表示,并通过记忆网络更新候选后续事件,再输入到GCN中,这三个步骤能得到信息更丰富的事件表示向量,对比基线方法SGNN,精度提高了5.55%,有效提高了事件预测的准确率。
特别的,我们增加了一个实验结果,Ours_tev,该实验使用传统的事件演化图,并在图中使用事件频率作为边的权重。实验结果表明,在构建事件演化图定义边的权重时,在事件频率的基础上加入了互信息,能更好地捕捉事件之间的联系,改善了事件抽取精度低和信息丢失问题。
本实验的结论是:
(1) 通过BiLSTM和记忆网络,最后结合事件演化图和图卷积神经网络,能获得上下文和邻域感知的完整事件表示向量,有效提高了事件预测的准确率。
(2) 将互信息引入事件演化图的权重,能更好地捕捉事件之间的联系,改善了事件抽取精度低和信息丢失问题。
3.3 参数调优实验
不同的实验参数设置对最终的实验结果也有着很大的影响,本文就GCN信息传输跳数K和训练学习率ρ两个实验参数做了多轮实验,来确认模型可以达到的最优训练结果。对于GCN跳数和学习率两个方面的实验结果和实验分析如下。
3.3.1 GCN信息传递跳数的调优实验
GCN跳数指的是节点信息传递的轮数K,传递第一轮时节点会获取其邻居信息,传递第二轮会获取其邻居节点信息。依次类推,信息每传递一轮,节点就会获取更丰富的邻居节点信息。随着轮数的增加,图中每个节点会不断融合更大领域的信息,能提升事件预测的效果。但是如果K值设置过大的话,会给事件节点表示带来噪声,降低事件之间的差异性,进而导致实验结果变差。本文给出了在不同轮数下的事件预测的准确率,从图5可以看出,随着K值的增加,模型的准确率先逐渐增加,然后显著下降,当K为2时实验结果最佳。

图5 参数K调优实验
3.3.2 学习率的调优实验
优化算法学习率ρ的合理选择对于模型中权值和偏移量参数的优化具有重要意义。如果学习速率过大,实验结果会很容易超过极值点从而左右震荡,使系统不稳定;如果学习速率过小,参数优化更新周期太大,会导致训练时间过长,因此,本节在不同学习率下给出了实验结果,如图6所示。可以看出学习率为0.001时模型的事件预测准确率最高。

图6 学习率参数调优实验
3.4 消融实验
本节同时也做了消融实验来验证本文模型各个组成模块的有效性,各个方法定义如下:
(1)BiLSTM: 模型仅将初始的每个事件表示向量输入到BiLSTM中,并且移除了注意力机制,将每个节点的隐藏层状态作为事件的最终表示向量,然后选择相似度最大的候选事件作为预测结果。
(2)BiLSTM+a: 在上一方法的基础上加入注意力机制,在事件语境中为每个事件分配不同的权重。
(3)BiLSTM+a+d: 在上一方法的基础上引入动态记忆网络来更新候选后续事件节点的表示向量。
(4)BiLSTM+a+d+G: 在上一方法的基础上加入图卷积网络层,在事件演化图的指导下多跳传输邻居节点之间的信息,完成事件表示向量的更新。
实验结果如图7所示。从图中可以发现,随着组成模型的增加,实验结果的准确率也在逐步提升,这说明了本文所提出的模型的各个组成部分的有效性。其中,引入注意力机制后提升效果最为明显。其次是引入记忆网络,通过该网络可以更新候选后续事件的表示向量,将其与事件语境联系起来。最后是引入GCN,在从学习到的事件演化图的指导下,进一步利用事件之间的关系来提升事件预测的准确率。
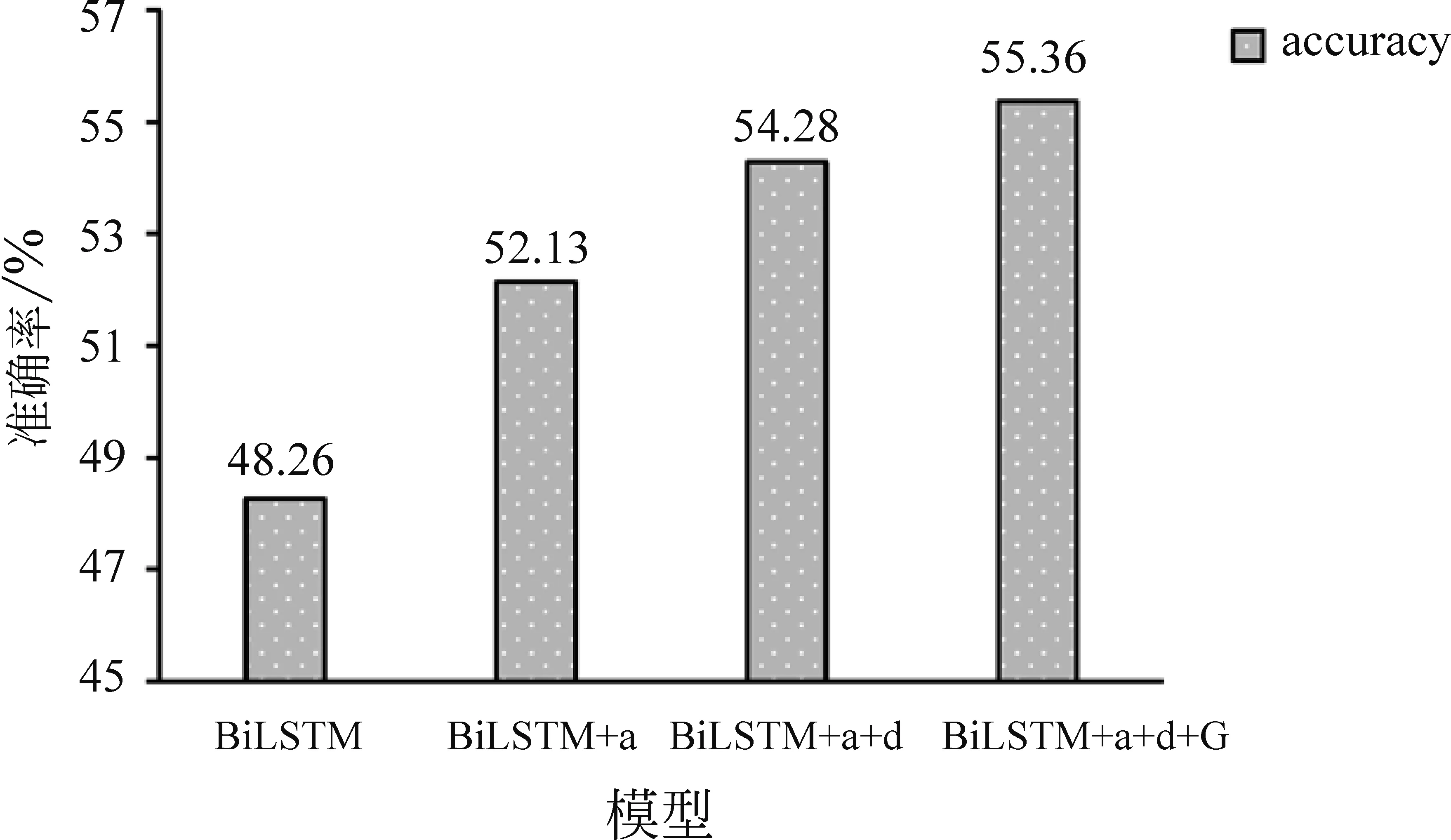
图7 消融实验
4 总结
本文提出了一种新的基于事件演化图和图卷积网络的事件预测模型。该模型结合频率和互信息改进了事件演化图的构造。接着,基于事件演化图,利用图卷积神经网络充分捕捉事件之间的关系,利用BiLSTM和记忆网络学习事件语境的表示,获得每个事件的高阶表示向量。最后,依据候选后续事件与事件语境之间的相似度实现全面而准确的事件预测。在基准数据集上进行的事件预测对比实验结果表明,本文模型在准确率评价指标上优于六种典型的事件预测方法,对比最新的基线方法SGNN,该模型精度提高了5.55%,缓解了事件预测中的精度低和信息丢失问题。
猜你喜欢
艺术生活-福州大学厦门工艺美术学院学报(2022年1期)2022-08-31
机械工业标准化与质量(2022年6期)2022-08-12
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
装备制造技术(2020年2期)2020-12-14
河南科技学院学报(自然科学版)(2020年2期)2020-05-22
疯狂英语·爱英语(2020年9期)2020-01-07
疯狂英语·爱英语(2020年9期)2020-01-07
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
