
基于预训练语言模型的藏文文本分类
2022-02-03 13:12龙从军
中文信息学报 2022年12期
安 波,龙从军
(中国社会科学院 民族学与人类学研究所,北京 100081)
0 引言
文本分类是自然语言处理领域的基础任务,在信息检索、情感分析、垃圾邮件分类、舆情监控等领域具有应用价值[1]。随着互联网及自媒体在我国藏族地区的发展和普及,以藏文作为语言载体的文本信息呈指数级增长,如何高效地分类处理这些数据成为当前的迫切需求[1],在这种背景下,藏文文本分类的重要性也更加凸显。同时,我国保有数量众多的藏文古籍、历史文献,这些数据对于藏族历史、汉藏同源等研究具有重要价值。藏文文本分类技术也可以辅助藏文古籍研究[2-3]。
基于统计的文本分类方法和基于深度学习的文本分类方法是当前文本分类的主流方法[4-6]。基于统计的文本分类方法包括: 基于最优超平面(SVM)[5]的文本分类、基于朴素贝叶斯的文本分类[7]等。随着深度学习在图像和自然语言处理中的广泛应用,基于深度学习的文本分类方法取得了更好的性能[5-6],例如基于卷积神经网络(Convolutional Neural Networks, CNN)[8]的文本分类、基于循环神经网络(Recurrent Neural Network, RNN)[9]的文本分类、基于长短时记忆网络(Long Short-Term Memory,LSTM)[10]的文本分类等。
近期,大规模预训练语言模型(Elmo[11]、BERT[12])在自然语言处理领域的多个任务中取得了显著性能的提升[12-13]。在预训练语言模型的基础上对下游任务进行微调也成为当前自然语言处理研究的主流范式[12]。基于预训练语言模型的文本分类也取得了当前最好的效果[11-13]。
大规模预训练语言模型,需要大规模的单语数据进行无监督训练,如BERT在大规模文本数据上,利用MLM[14]任务预测mask掉的词。然而,在藏文环境下缺少大规模公开的文本数据,目前也没有开源的藏文预训练语言模型,因此也藏文环境下也没有使用预训练语言模型进行文本分类的工作。
针对上述现状,为了进一步提升藏文文本分类的性能,本文首先利用网络爬虫抓取大规模藏文文本,并在这些文本的基础上训练得到藏文预训练语言模型(BERT-base-Tibetan)。其次,我们实现多种常用的基于神经网络的文本分类模型。最后,对比词向量的随机初始化、预训练的词向量和预训练语言模型在藏文文本分类上的效果,实验结果表明,预训练语言模型能够显著地提升藏文文本分类的性能。但是由于藏文文本分类的数据较少,并且用于藏文预训练语言模型的语料规模较小,藏文文本分类的性能远低于中文和英文的文本分类性能。本文的主要贡献包括:
(1) 采集了一个较大规模的藏文文本数据集,并在该数据集的基础上训练了一个藏文预训练语言模型;
(2) 在多种神经文本分类方法上的结果表明,藏文预训练语言模型能够显著地提升藏文文本分类的性能,为后续的藏文自然语言处理提供了参考。
1 相关工作
本文的主要工作包括两部分,藏文预训练语言模型和藏文文本分类,本节将分别介绍这两部分工作。
1.1 大规模预训练语言模型
近几年,大量工作表明预训练语言模型(Pre-trained Language Model, PTM)能够学习到有价值的文本表示,并对下游自然语言处理(Natural language processing, NLP)任务具有显著提升[11-13]。按照时间发展,PTM大致可以分为两个阶段。
第一阶段是以SkipGram[15]、CBOW[16]和Glove[17]为代表的词向量模型,这些模型通过预测词汇共现信息能够学习到有意义的分布式词向量(Word Embeddings)。在这种方式下,针对每个词会产生一个或多个向量表示,产生词级别的表示。对于短语、句子、篇章等粒度的表示,更多地是借助于循环神经网络(RNN)[9]、长短时记忆网络(LSTM)[10]等模型对词向量进行组合得到长文表示。
第二阶段是以Elmo[11]、BERT[12]、GPT[18]为代表的大规模预训练语言模型。这些模型能够同时建模整个句子的信息,针对每个词汇在不同的上下文中产生不同的表示向量。因为能够更好地建模句子的上下文信息,在问答系统、信息检索、语义解析等方面取得了显著效果[11-13]。
目前,基于预训练语言模型在任务数据上进行微调(Fine-tuning)已经成为自然语言处理研究的常用方法。但是第二阶段的PTM(如BERT)需要大规模的训练数据,同时也需要强大的计算能力来实现语言模型的建模。因此,主要的开源预训练语言模型集中在汉语、英文等较为主流的语言中,在藏语等少数民族语言中很少有开源的预训练语言模型[19]。
1.2 藏文文本分类
文本分类是自然语言处理中最基础的任务之一,是问答系统、情感分析、意图识别等任务的基础。当前,主流的文本分类方法以基于神经网络文本分类方法为主。FastText[20]是Facebook研发的一种通过学习词向量对文本分类的算法,能够实现快速的文本分类。TextCNN[21]利用卷积神经网络对句子进行表示和分类。为了解决CNN在建模文本时上下文范围有限的问题,Johnson等人[22]提出了DPCNN,是较早的深层CNN模型在文本分类中的应用。为了更好地建模文本的序列信息,基于循环神经网络的TextRNN[9]被用于文本分类。为了解决循环神经网络梯度爆炸和梯度消失的问题,研究者引入长短时记忆网络(LSTM)来优化文本分类的结果。为了能够在文本分类时更好地关注核心的分类词,注意力机制(Attention Mechanism)[22]被引入到文本分类模型中。基于自注意力机制的Transformer模型在文本分类中也得到了广泛的应用[12]。近期,随着大规模预训练语言模型的快速发展,基于Emlo和BERT的文本分类方法也得到了广泛的应用[11-12]。
由于文本分类任务的基础性和重要性,藏文文本分类任务也吸引了大量的研究者。藏文文本分类方法按照时间顺序大概可以分为三个阶段: 基于词典和规则的文本分类方法、基于统计学习的文本分类方法和基于神经网络的文本分类方法。贾会强等人[24]提出了基于规则和词典的藏文文本分类方法。袁斌[25]设计不同的情感特征并利用SVM实现藏文的文本分类。王勇[26]利用朴素贝叶斯分类器实现了藏文文本分类。李艾琳[27]也基于朴素贝叶斯分类器实现了用于Web舆情的藏文分类。为了更好地利用上下文信息,基于N-gram的藏文词和音节的文本分类方法也被广泛使用,基于逻辑回归、AdaBoost等常用的分类模型也被应用到藏文文本分类任务中[28-31]。胥桂仙等人[32]基于栏目信息,设计了一种藏文网页分类系统。
近期,基于神经网络的方法成为藏文文本分类的主要研究方向。Qun等人[33]最早使用神经网络的方法来解决藏文文本分类,并开源了一个藏文文本分类的数据集。Li等人[34]结合藏文的N-gram特征实现了sepCNN和Bi-LSTM分类器。Ma等人[35]利用FastText实现了一种藏文文本分类器。王等人[31]实现了一种基于多分类器的藏文文本分类方法。
由于藏文目前缺少开源的大规模预训练语言模型,藏文预训练语言模型的相关研究还较少[37-38],并且在投稿时没有使用BERT模型在开源文本分类数据上开展藏文文本分类工作,无法与之进行直接的对比。
2 基于预训练语言模型的藏文文本分类
本文首先基于网络爬虫抓取了一个较大规模的藏文文本语料,并在此基础上训练了一个藏文预训练语言模型(BERT-base-Tibetan)。然后,在主流的基于神经网络的藏文文本分类方法上进行测试。本节将分别介绍这两部分工作内容。
2.1 藏文预训练语言模型
由于缺少开源的藏文文本数据,本文基于Scrapy(1)https://scrapy.org/实现了一个藏文网站的网络爬虫,从主流的藏文新闻网站(中国西藏新闻网、中国藏语等)上抓取了约100万页面。
汉语预训练语言模型通常以字为单位进行表示学习。藏文通常以音节作为基本的语义单位,因此本文首先使用SegT[36]对藏文文本进行切分,形成藏文字,最终得到了包含964 208 205藏文音节的语料,以音节为单位进行藏文预训练语言模型的训练。
在上述语料的基础上,我们在Pytorch(2)https://pytorch.org/实现了基于Transformer[12]的预训练语言模型。我们参考BERT-base的参数设置,具体的参数设置为: max_seq_length为512,learning_rate为0.0001,train_batch_size为128,vocab_size设置为10 000,block_size设置为509,hidden size设置为768。
2.2 基于神经网络的藏文文本分类
为了更好地验证预训练语言模型对于藏文文本分类任务的价值,本文基于神经网络模型实现藏文文本分类。本文模型的文本分类框架如图1所示。通过图1可知,藏文文本模型主要包括以下几个层次: 藏文分词层、词向量化层、文本表示学习层和文本分类层。在本文中,我们使用SegT[36]进行藏文分词。

图1 藏文文本分类框架
词向量化层: 词向量化层将离散的词序列转换为分布式表示。本文我们使用三种方式得到词向量: ①基于随机初始化的词向量表示,这种方式下词向量是基于训练数据学习得到的; ②基于FastText预训练得到的词向量(3)https://fasttext.cc/docs/en/crawl-vectors.html,该词向量是由Facebook基于藏文文本数据训练得到的; ③基于BERT预训练得到的上下文相关的向量表示。
文本表示学习层: 文本表示是进行藏文文本分类的基础。本文实现了多种主流的基于神经网络的文本分类模型,包括TextCNN、TextRNN(LSTM cell)、TextRNN_Att、TextRCNN、DPCNN、Transformer共6种常用的模型。
文本分类层: 本文使用全连接层和Softmax作为最后的分类层。
为了更好地验证藏文预训练语言模型的作用,我们使用多种模型设置开展实验。
词向量随机初始化: 在该设置中,所有实验包含藏文分词层、词向量化层,文本表示学习层、文本分类层。其中词向量化层为随机初始化,通过分类数据进行训练得到。
基于预训练FastText的词向量: 在该设置中,所有实验包含藏文分词、词向量化层,文本表示学习层、文本分类层。我们使用FastText提供的藏文词向量作为词向量层的初始化,并在训练中对词向量进行优化。
基于藏文BERT的文本分类: 在该设置中,所有实验包含词向量化层、文本表示学习层、文本分类层。因为BERT是以字为单位进行表示学习的,因此在这种设置下不需要进行藏文分词。此外,词向量层是使用藏文BERT对每个藏文字符学习得到的向量表示,作为词向量的输入。
3 实验
3.1 实验数据
为了更好地与已有的实验结果进行比较,本文使用Qun等人[33]开源的藏文文本分类数据(4)https://github.com/FudanNLP/Tibetan-Classification,并且以藏文新闻标题作为主要的分类对象,包括旅游、经济、教育、艺术、医疗等12种类型的藏文新闻文本标题。通过主流的文本分类模型,可以更加直观地观察藏文预训练语言模型的效果。由于该数据集没有提供训练数据、测试数据的切分,因此我们按照其论文中的比例,即8∶1∶1的方式将数据集划分为训练集、开发集和验证集。后续实验的所有模型均先在训练集上训练,利用开发集找到最优模型,结果为在验证集上得到的结果。具体的数据统计信息如表1所示。

表1 藏文文本分类数据
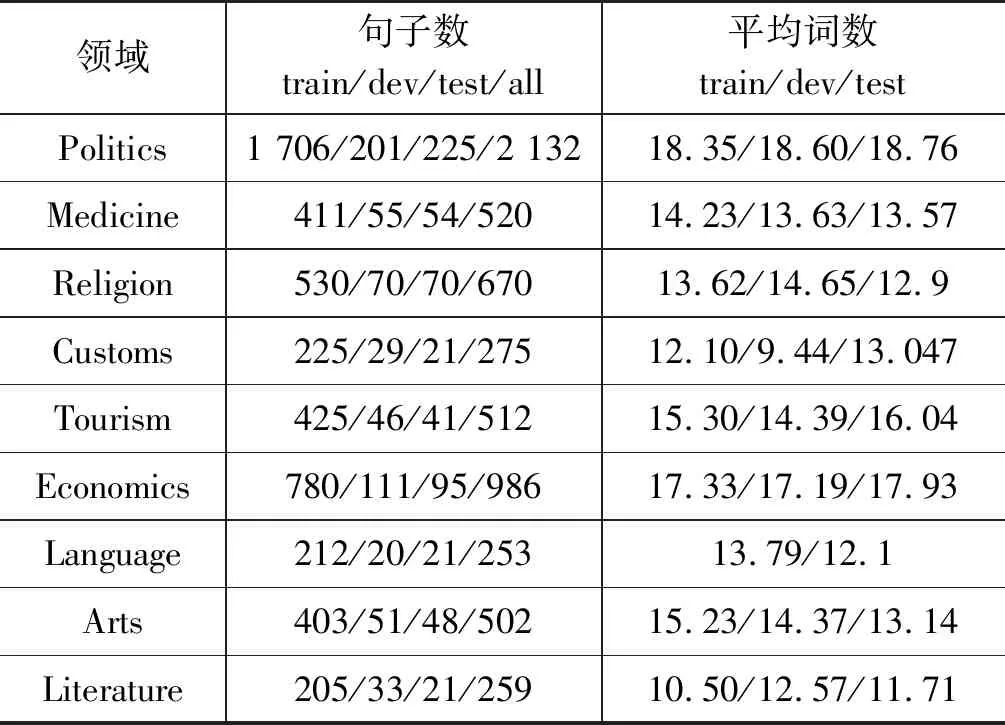
续表
3.2 实验设置
本文采用词向量随机初始化、预训练词向量初始化和预训练语言模型初始化三种设置来开展实验。本节实验所涉及的模型的超参数如表2所示。使用预训练词向量的设置与随机初始化的模型设置完全相同,词向量也会跟着训练进行微调,模型的超参数如表3所示。
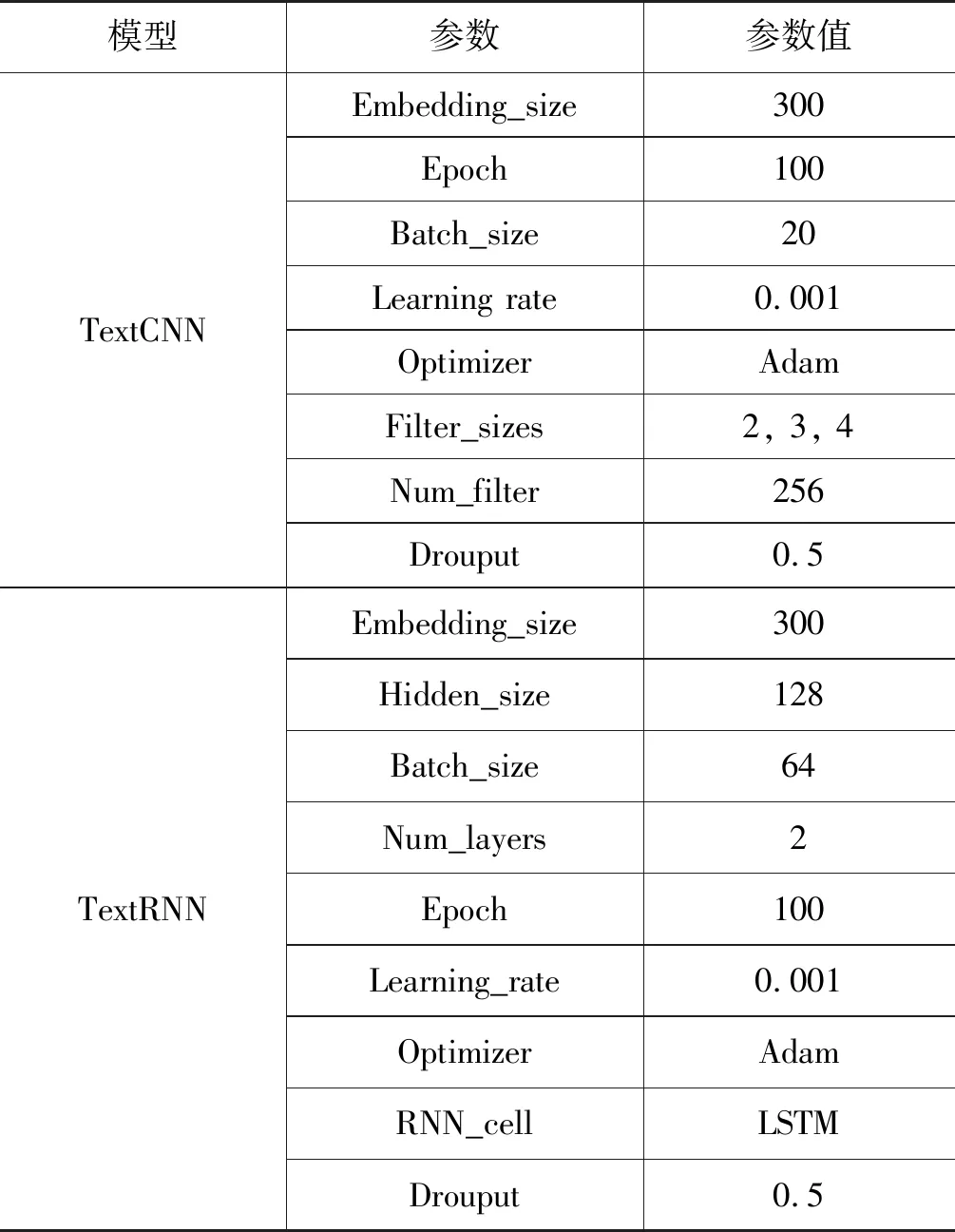
表2 模型超参数
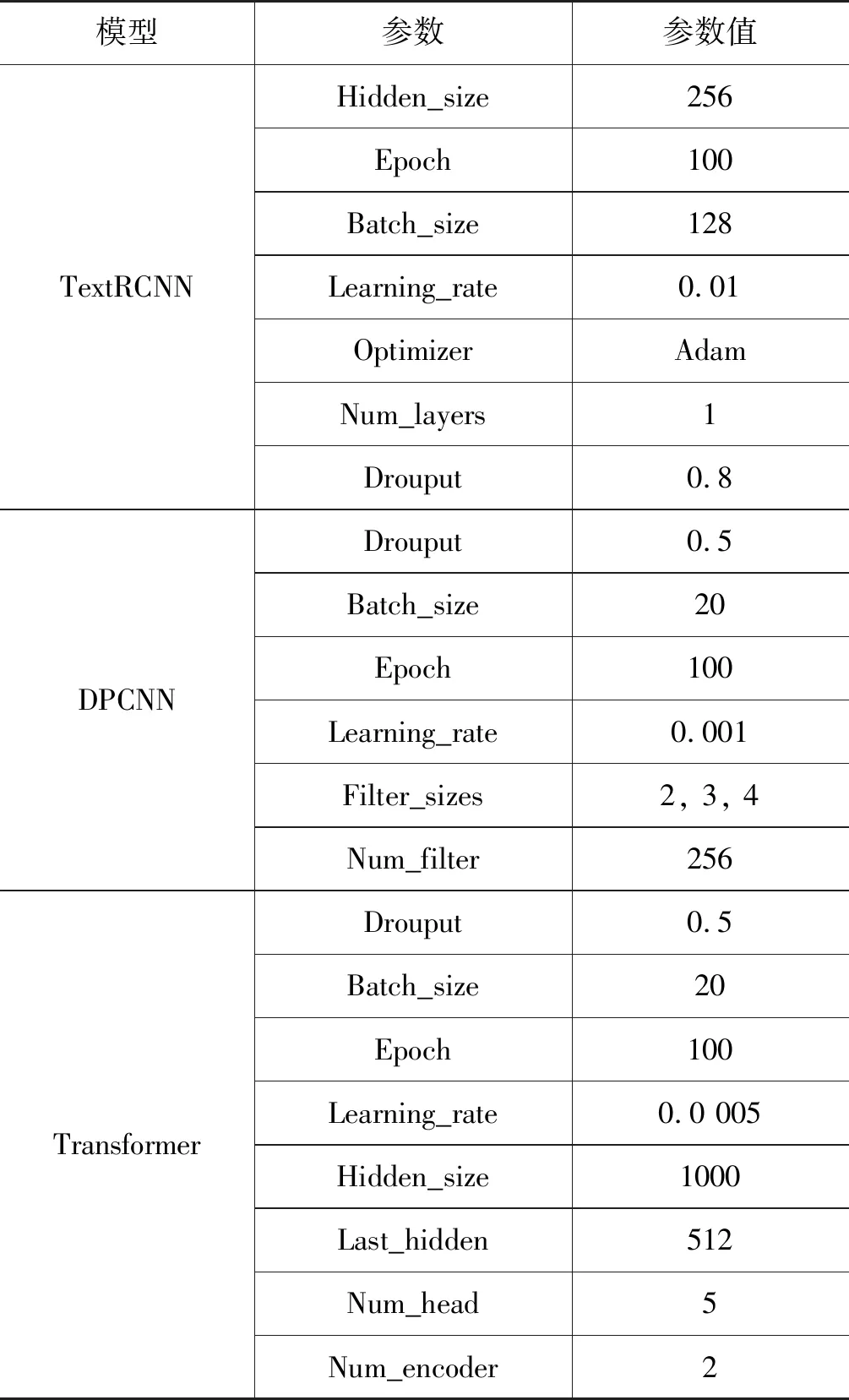
续表

表3 基于预训练语言模型的模型超参数

续表
本文使用精确率(Precision,P)、召回率(Recall,R)和F1值(F1)作为文本分类的评测标准,同时为了更好地反映计算结果,宏观本文也会给出三个指标的宏观平均值(macro avg)及加权平均值(weighted avg)其权重为该领域的测试数据数量占总体的测试数据比例,其计算方法如式(1)~式(7)所示,其中,TP为正确预测为正例的数量,FP是错误预测为正例的数量,FN是错误预测为负例的数量。
3.3 实验结果
总体的实验结果如表4所示,其中P代表精确率、R代表召回率、F代表F1值,Macro avg代表一行结果的平均是,Weighted avg代表一行结果的加权平均值。从实验结果可知: ①基于藏文预训练模型的训练方法能够显著提升藏文文本分类的性能,在所有的方法中,我们的方法在精确率(相比于随机初始化平均提升6.2%,相比于预训练词向量平均提升16.1%)、召回率(相比于随机初始化平均提升10.6%,相比于预训练词向量平均提升17.3%)和F1值(相比于随机初始化平均提升9.3%,相比于预训练词向量平均提升18.1%)上均有提升; ②基于预训练词向量的方法不能显著地增强藏文文本分类的性能(精确率平均下降7.9%,召回率平均下降5.5%,F1值平均下降7.0%),这可能是因为预训练词向量采用的分词系统不同,导致词向量未能很好地被利用; ③几乎所有的方法在Customs类别上的性能不高,这可能是因为该类别缺少显著的区分性; ④与中文文本分类相比,藏文文本分类的总体性能还较低,这一方面是因为藏文文本分类数据集的规模较小,容易导致模型过拟合;另一方面是由于目前藏文分词准确率不足、无监督数据规模较小等因素导致了性能的下降。这些也为我们后续的工作提供了借鉴。
为了更清晰地反映预训练语言模型的价值,我们在图2中给出了DPCNN模型在随机初始化、词向量和预训练语言模型的下的对比结果。从图2可以看出,基于预训练语言模型的藏文文本分类结果要显著优于随机初始化和使用词向量的结果。结合表4可以更清楚地看出,基于预训练语言模型的藏文文本分类模型在所有模型中的总体指标均高于基于随机初始化和词向量的模型。

图2 基于DPCNN的藏文文本分类
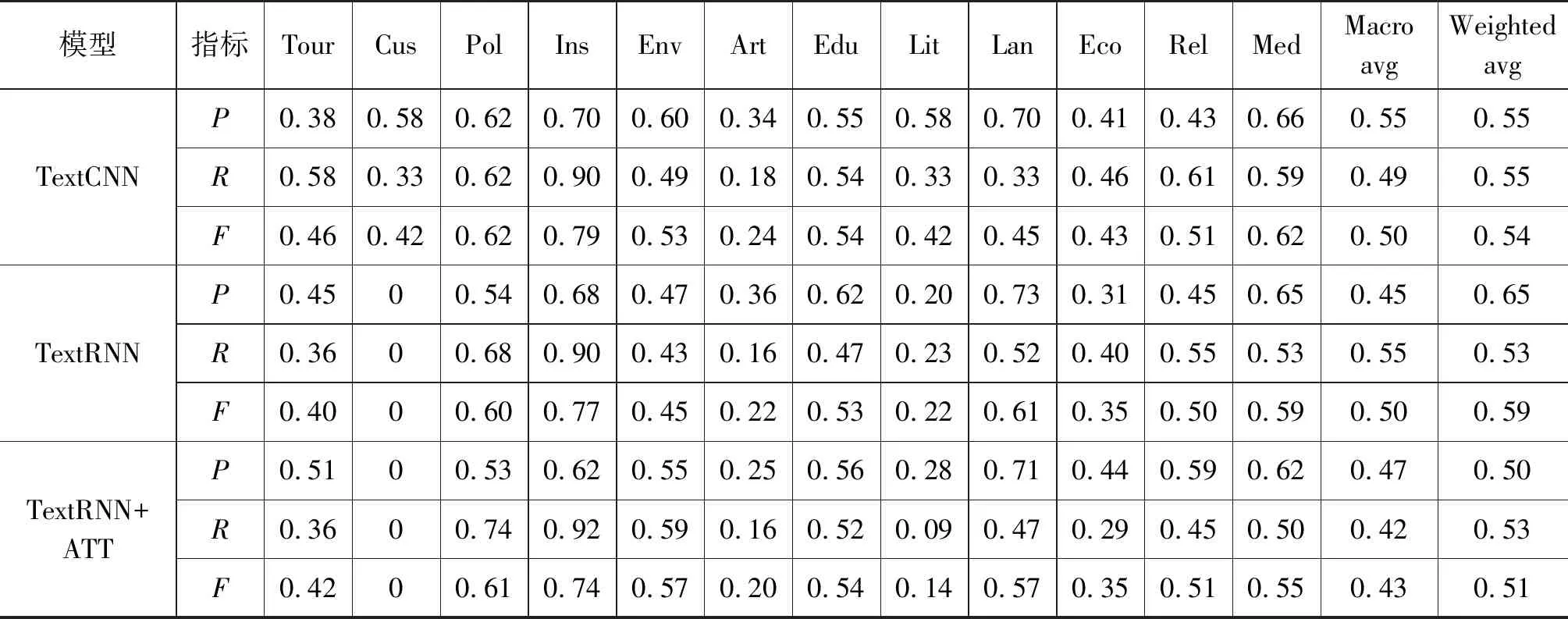
表4 藏文文本分类结果

续表
4 结束语
本文通过爬虫抓取了一个较大规模的藏文文本数据集,并训练了一个藏文预训练语言模型。通过在多种神经网络文本分类模型上的实验表明,基于预训练语言模型的文本分类方法能够显著提升藏文文本分类的性能。同时,我们也发现藏文文本分类的整体性能与中文、英文等主要语言的文本分类的性能有较大差距。
未来我们计划从两个方面来继续优化藏文文本分类: 一方面,收集整理并开源更大规模的藏文文本分类数据;另一方面,抓取更大规模的藏文文本数据,并构建开源大规模藏文预训练语言模型,以更好地推进藏文自然语言处理的发展。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
西藏研究(2021年1期)2021-06-09
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
布达拉(2020年3期)2020-04-13
电子制作(2019年19期)2019-11-23
电子制作(2019年24期)2019-02-23
西夏学(2019年1期)2019-02-10
中央民族大学学报(自然科学版)(2018年1期)2018-06-27
高中生学习·高三版(2016年9期)2016-05-14
重型机械(2016年1期)2016-03-01
