
基于ERNIE-Gram和TinyBERT混合模型的复句关系体系转换
2022-02-03 13:12杨进才陈雪松蔡旭勋
中文信息学报 2022年12期
杨进才,陈雪松,2,胡 泉,蔡旭勋
(1. 华中师范大学 计算机学院,湖北 武汉 430079; 2. 武汉中学,湖北 武汉 43006;3. 华中师范大学 人工智能教育学部,湖北 武汉 430079)
0 引言
复句是由两个或两个以上意义上紧密相关、结构上互不包含的分句构成的句子[1]。复句作为联结篇章的桥梁,其研究属于篇章关系研究范畴。在中文信息处理领域,对篇章关系的研究还处于初级阶段,处理方法和评价标准大多借鉴于西方语言学[2]。复句理论不仅适用于句子,经过改进后也能用于句子以上的篇章单元[3]。
常见的复句关系分类体系有复句三分系统、宾州篇章树库(Penn Discourse Treebank,PDTB)2.0分类体系。复句三分系统是汉语复句关系研究的重要分类体系,PDTB 2.0是英语篇章分析领域重要的分类体系,以PDTB 2.0为指导构建的语料库是篇章分析领域规模最大的语言学资源[4]。建立复句三分系统与PDTB 2.0的关系对应模式与转换算法能促进语言学研究对篇章关系的进一步补充与完善,深化中英文篇章关系的衔接,推动中文篇章关系研究的国际化。同时指导机器翻译、语言教学、自动问答等任务。复句三分系统与PDTB 2.0面向的语言分别为汉语、英语,难以根据语料直接建立两者关系对应模式。哈工大HIT-CDTB[5]分类体系以PDTB 2.0为基础,同时使用了汉语复句分类系统中的部分关系定义,对汉语复句进行分类。以HIT-CDTB中语料为基础,标注每条语料在三种分类体系下的关系类别,能够建立三者的对应关系。如例1在复句三分系统、HIT-CDTB、PDTB 2.0三种分类体系中对应的关系类别分别为: 转折类-让步、比较-让步-让步在先、COMPARISON-Concession-expectation。
例1 尽管英文很生硬,他仍然谈笑风生。(HIT-CDTB语料库)
以HIT-CDTB为媒介,三者的关系对应模式如图1所示。图1中,复句三分系统与HIT-CDTB关系对应模式有两种,分别为“一对一”与“一对多”。HIT-CDTB中的关系类别大多源于PDTB 2.0,而PDTB 2.0关系类别则多为一一对应模式。因此,只要能够建立复句三分系统与HIT-CDTB的关系对应转换算法,就能够实现三种分类体系之间关系类别的自动转换。

图1 三种分类系统的对应关系
有两种方法可用来实现不同分类体系之间的关系转换: 基于规则的专家系统与基于统计模型的方法。前者由专家手工制定规则并构建推理程序、产生推理结果,其优点是规则详细、考虑全面,缺点是规则建立过程复杂、难以拓展,且容易出现规则冲突。后者主张通过建立特定的数学模型来学习语言结构,利用统计学、机器学习等方法来训练模型的参数,使用模型产生结果[6],其优点是简单高效、易于扩展,缺点是准确率低于前者、模型过程不透明、对硬件要求高。
如果能够结合两种方法的优点,同时保持较高的准确率与较广的适用范围,将大幅提高转换算法的应用水平。
目前,我们已经建立两种分类体系部分关系之间的转换规则,并通过构建专家系统实现部分关系的自动转换(另有论文详述,本文仅简单介绍规则转换框架)。
基于统计的学习方法是当前学界的主流处理方法。其中,使用微调后的预训练模型对文本进行处理成为共识[7]。预训练方法基于大规模文本,通过预训练得出通用的语言表示,再通过微调的手段将学习到的知识用于下游任务,可扩展性强。
本文在已经建立复句三分系统与HIT-CDTB部分关系类别转换规则的基础之上,使用预训练模型与规则相结合的方法,同时使用数据增强技术实现从复句三分系统到HIT-CDTB、从HIT-CDTB到复句三分系统关系类别的自动转换。
1 相关工作
国内关于复句关系分类的理论有很多,邢福义[1]与张牧宇[5]的理论较典型。邢福义根据“从关系出发,用标志控制”的原则构建汉语复句关系因果、并列、转折三分系统,下辖12小类。张牧宇吸收西方PDTB篇章关系分类体系,将包括复句在内的篇章关系分为4大类,构建HIT-CDTB语料库。
基于复句三分系统,华中师范大学开发了汉语复句语料库(the Corpus of Chinese Compound Sentences,CCCS)(1)http://linguist.ccnu.edu.cn/jiansuo/TestFuju.jsp,这是一个面向汉语复句研究的专用语料库。该语料库仅涉及有标复句,每条语料均标注了关系标记。
张牧宇等[5]基于PDTB 2.0(2)https://catalog.ldc.upenn.edu/LDC2008T05,并对其进行了适当的修改,构建了哈工大中文篇章关系语料库(HIT-CDTB)(3)http://ir.hit.edu.chit-cdtb/index.html。HIT-CDTB增加了二级关系类别“目的”“递进”“并列”,删除了有关时态的关系类别并对其进行重构。该体系从句群、复句、分句三个层次对语料进行标注。
应用研究主要关注两个方面: 一是复句关系标记的识别,二是复句关系类别的识别。
1.1 复句关系标记识别
文献[8-9]在复句关系标记识别规则的建立与维护上做了大量工作,包括建立汉语复句关系词库,提出复句关系标记识别的规则表示方法,构建规则库及其维护与冲突处理方法等。复句关系标记的研究为复句关系的识别打好了基础。
1.2 复句关系识别
复句关系的识别有基于规则的方法与基于统计的方法。基于规则的方法借助已经建立的关系标记规则库,构建复句关系识别的规则。文献[10-11]使用SVM、语义相关度算法等对复句进行识别。基于统计的方法借助大规模语料库,利用概率论等知识建立复句关系识别的数学模型,文献[12-13]基于CNN等神经网络模型识别汉语复句关系。上述方法都是基于特定任务而设计的,过程复杂,在处理不同任务时需要从头开始训练,时间花费大。本文利用已经在大规模基准数据集上训练过的模型,通过微调,将其应用到复句关系转换任务上。
2 关系识别与转换的混合模型
2.1 预训练模型(PTM)
在复句关系识别任务中,传统的方法多基于机器学习与不可迁移的神经网络。预训练属于迁移学习的范畴,它能够将学习到的知识存储在模型里,从而提高下游任务的准确率。预训练模型因简便高效而逐渐被广泛应用于自然语言处理领域。
2013年,Word2Vec[14]首次将预训练模型用于自然语言处理。随后Transformer[15]模型将预训练语言模型的效果提升到了新的高度。BERT[16]、GPT-3[17]等模型分别使用自编码(Autoencoder)语言建模和自回归(Autoregressive)语言建模作为预训练目标。后续的 PTM 都是这两个模型的变体,如本文中使用的ERNIE-Gram、TinyBERT。
预训练模型分为预训练和微调两个阶段。在预训练阶段,借助大规模语料,使用Masked掩码语言模型等方法生成深度双向语言表示向量;在微调阶段,根据不同任务使用不同网络模型。本文在ERNIE-Gram、TinyBERT模型中嵌入主成分分析PCA(Principal Component Analysis)方法提高句向量的区分度 (图2)。
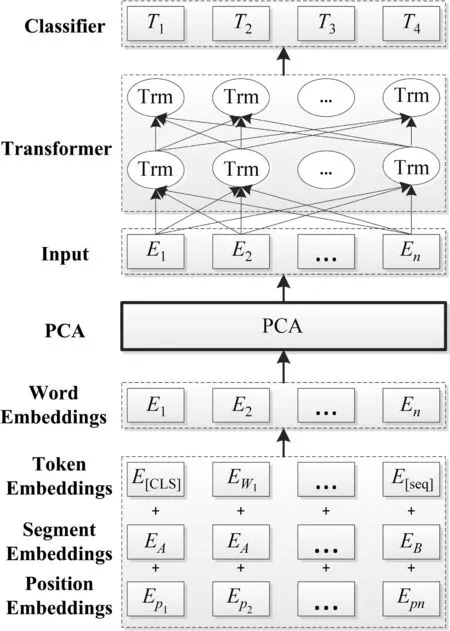
图2 嵌入PCA方法的BERT/ERNIE-Gram/TinyBERT模型架构
2.1.1 ERNIE-Gram
命名实体与短语等粗粒度的语言信息有助于在预训练时进行充分的表征学习,从而更好地处理中文文本。之前的预训练模型主要集中在扩展BERT的掩码语言建模(MLM)目标,忽略了对粗粒度语言信息的内在依赖和相互关系的建模。ERNIE-Gram[18]提出一种显式的N-gram掩蔽方法,以将增强粗粒度信息集成到预训练模型,同时提升预训练模型的收敛速度(图3)。图3(a)中,传统的MLM方法(Contiguous MLM)将“谈笑风生”等类似的短语、命名实体中的每个字符单独掩码并预测,这种方法忽视了该短语内部各字符之间的关系。ERNIE-Gram在预训练阶段将“谈笑风生”作为一个整体进行掩码并预测(ExplicitN-gram MLM)[图3(b)]。在实际预训练模型中,ERNIE-Gram同时采用上述两种方法预测掩码代表的字符与短语[图3(c)],既考虑单个字符含义,也考虑短语内部字符关系,能够获取中文句子内容不同层次单元的语义信息。因此,对于包含大量粗粒度语言信息的中文文本来说,ERNIE-Gram具有较好的性能。本文中的混合模型正是基于ERNIE-Gram生成的词向量进行复句关系的识别与转换。

图3 三种MLM方法
2.1.2 TinyBERT
TinyBERT[19]是华为公司提出的一种蒸馏 BERT 的方法(图4),模型大小接近BERT的1/7,而速度能提高9倍。图4左侧为Teacher模型BERT,右侧为蒸馏后的Student模型TinyBERT。Student模型在Embedding Layer、Transformer Layer、Prediction Layer都小于Teacher模型。原始的BERT功能强大,但体量过大,计算耗时,使用TinyBERT可以取长补短。总体而言,TinyBERT具有简便、高效的特点。本文的组合模型体量庞大,使用TinyBERT能够在保证性能的前提下尽量降低模型复杂度,同时降低对硬件的要求。

图4 TinyBERT蒸馏过程
2.2 主成分分析(PCA)
主成分分析[20]通过将许多存在关联的指标按照一定的变换方法再次组合,以此取代原来指标的方法。在一条复句中,每个词所代表的词向量都存在不同程度的相似性,通过PCA提取所有词向量中相似度高的部分,即主成分,用原来的词向量减去主成分,生成新的词向量。新生成的词向量最大程度地剔除了相似部分,保留了相异部分,也就间接构造出相关度低的句向量,最大程度地保留了每条复句的特异性,能提高复句关系类别转换准确率。对于本文用到的每个预训练模型,在Embedding层对词向量进行去除第一主成分操作。
2.3 转换规则与专家系统
复句三分系统与HIT-CDTB分类系统存在对应关系,依据两种分类体系的标准,对八种关系建立了关系对应模式(表1)。以关系标记“因为”为例,部分转换规则见表2。“分句数量”“关系标记所在序号”“关联分句的序号”三项特征由特征分析器识别,分句的序号按从左到右的顺序标示,当分句位于复句末尾时也可用“-1”标示。表2中的转换规则用于两种分类体系的关系对应双向转换。

表1 八种关系对应模式
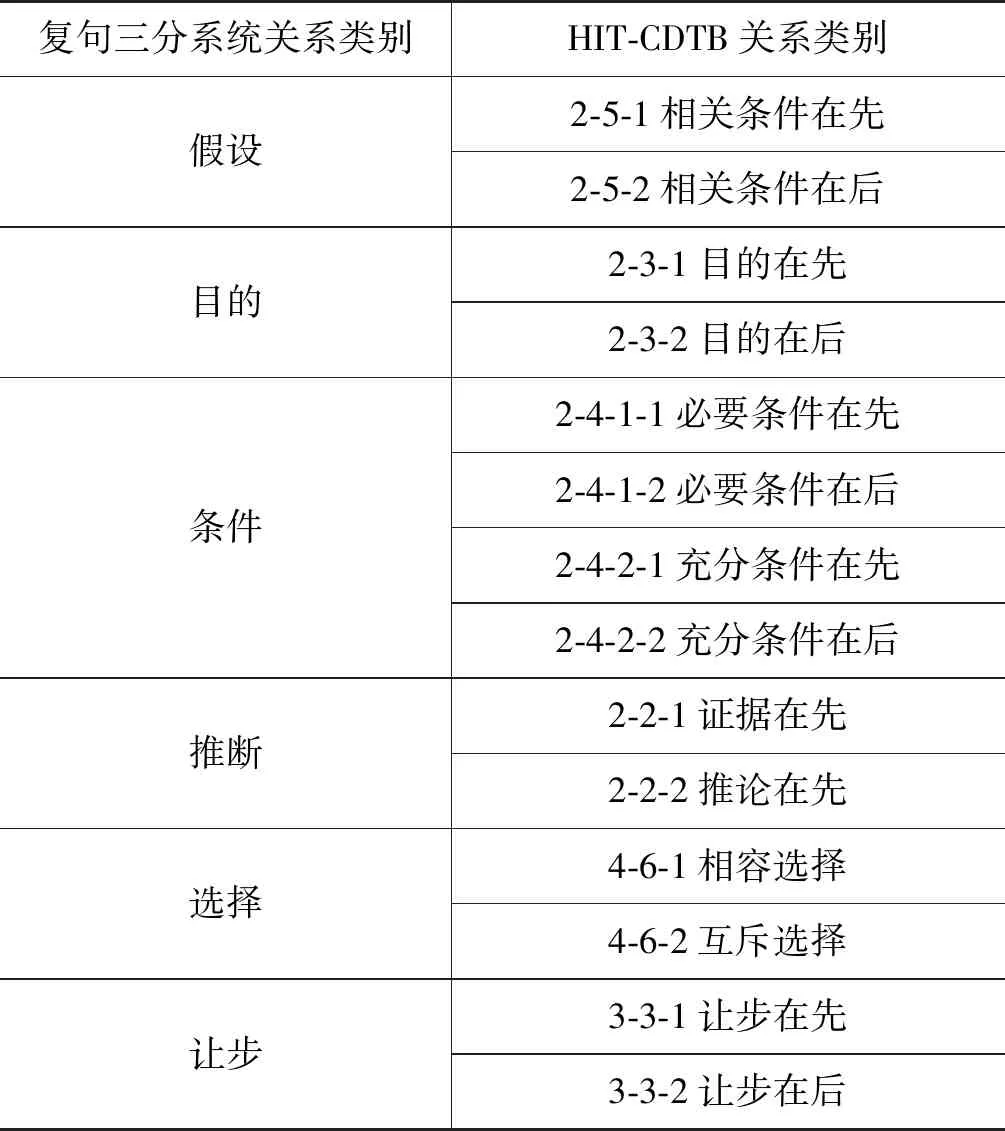
续表
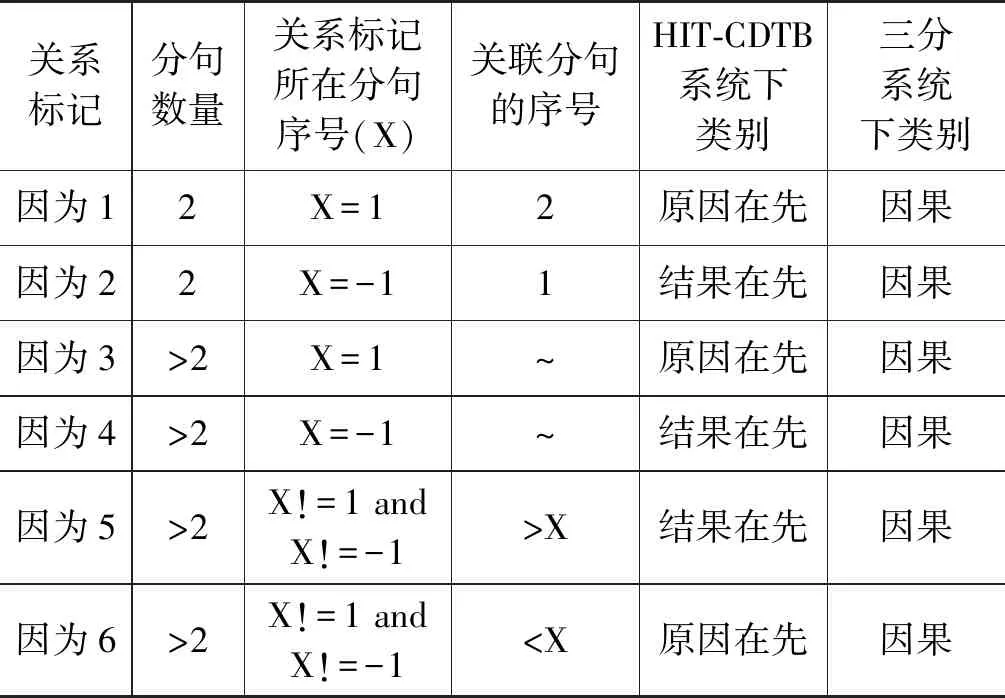
表2 关系转换规则
进行关系转换的专家系统如图5所示。输入一条复句,复句特征分析器提取词性、依存关系、关系标记等特征;规则引擎分析提取的特征,利用关系类别对应表识别复句关系类别;利用关系转换规则库将关系类别转换为另一分类体系下的关系类别,实现两种分类体系下复句关系类别的自动转换。

图5 基于规则的关系对应自动转换专家系统
2.4 数据增强
HIT-CDTB语料库数据量小且分布不均衡,通过数据增强的手段可以增加数据量,提高模型性能。文本数据增强有加噪、回译两种方法。加噪指在原数据的基础上通过替换、删除等操作改变原数据部分字词,从而产生类似的新文本。回译通过将原有数据翻译为其他语言再翻译回原语言,产生与原始文本类似的数据。EDA[21]对比分析同义替换、随机插入、随机交换等几种加噪方法,指出同义替换方法对文本原义影响最小。因此,本文采用同义替换的数据增强方法,根据词向量的相似度大小,从哈工大《同义词词林》扩展版(4)https://www.ltp-cloud.com/download中抽取同义词对原数据进行扩充,过程见图6(b)。但是,扩充的语料不是越多越好,过多容易过拟合。参照文献[18]的建议,结合实验数据,每1条原始句子生成新句子的数量为7,每条原始句子替换1~3个同义词后组成一条新句子。
图6(b)中,提取原句子中的“很”“生硬”“仍然”三个词,在《同义词词林》中分别找到上述三个词的同义词组,同时利用腾讯AI实验室(5)https://ai.tencent.com/ailab/zh/index训练好的对应词向量计算它们与原词词向量的相似度,取相似度最高的词“非常”“别扭”“依然”。经过组合,原句子生成了7条新的复句。最终训练集扩展为53 741条,验证集仍为683条。

图6 转换过程示意图
2.5 基于ERNIE-Gram和TinyBERT混合模型的关系转换
语料库中的复句不是所有的都满足“一一对应”模式,规则只针对复句三分系统中的8类、HIT-CDTB中的17类,不能覆盖所有关系对应模式。因此,设计基于ERNIE-Gram和TinyBERT的关系转换混合模型。
转换过程见图6(a)。ERNIE-Gram的主要功能是利用HIT-CDTB语料库生成具有复句特征的词向量,分别供两个TinyBERT模型使用。左边的TinyBERT1输入ERNIE-Gram生成的词向量,转换为三分系统分类体系下的关系类别。右边的TinyBERT2输入ERNIE-Gram传递过来的词向量,转换为HIT-CDTB系统分类体系下的复句关系类别。在每个预训练模型中,增加了主成分分析模块,对每组词向量,都去除其第一主成分。最后,利用规则库(表2),再次对两种分类体系中的部分关系对应进行转换。
2.5.1 数据增强
对于任意一条从HIT-CDTB提取的复句向量,表示为矩阵Uij={u1,…,un},利用同义词词林进行数据增强后,生成7条新句子,如式(1)所示。
Uij→{Ui1,Ui2,Ui3,Ui4,Ui5,Ui6,Ui7,Ui8}
(1)
2.5.2 利用预训练模型进行自动转换
将每条复句在复句三分系统、HIT-CDTB中的关系类别分别标记为向量y1、y2。其中,y1∈三分系统12小类,y2∈HIT-CCDTB系统29小类。带关系标记的复句表示为U′ij={y1,u1,…,un,y2}。经ERNIE-Gram模型中Embedding层编码,输入的复句表示为如式(2)所示的矩阵。
(2)
其中,We为字符的Embedding矩阵,Ws为分段矩阵,Wp为位置编码矩阵。
利用PCA主成分分析方法计算h0的第一主成分,表示为p1,去除p1过程如式(3)所示。
(3)
随后将去除第一主成分后的矩阵h0输入具有n层结构的Transformer模块中,这一过程如式(4)所示。
hl=Transformerblock(hl -1)∀l∈[1,n]
(4)

Wy为线性层权重。TinyBERT1预测三分系统共12小类,TinyBERT2预测HIT-CDTB系统共29小类。
2.5.3 利用预训练模型+规则进行转换
在第二阶段已经对所有6 691条语料得出转换结果的基础上,对符合转换规则的部分关系(共3 029条语料,约占语料总数的45.3%),重新利用规则进行转换,所得结果覆盖第二阶段基于预训练模型进行转换的结果;对不符合转换规则的语料(共3 662条),保留第二阶段的转换结果。最后合并两种方法的转换结果,统一计算各项指标。具体而言,对于每条复句,提取其关系标记,如果关系转换规则库(表2)中包括该关系标记,则使用专家系统重新对该条复句进行分类,覆盖基于预训练模型的转换结果;如果未包含该关系,则保留基于预训练模型的转换结果。
(7)
其中,Rules如表2所示。
3 实验
3.1 数据集
选取HIT-CDTB语料库中的有标复句。HIT-CDTB语料库共包含语料24 706条,包括句群、句间、句内等篇章单元,提取其中的复句语料共6 691条。同时根据复句三分系统对这6 691条复句进行分类(表3)。每条复句在两种分类体系下都有对应的关系。
由于HIT-CDTB语料库中复句较少、数据分布极不均衡,不能体现PCA模块对原始预训练模型性能的影响。为了验证ERNIE-Gram、Tiny-BERT模型添加PCA模块后的性能,也为了使ERNIE-Gram能够生成更好的带有复句特征的词向量,从CCCS语料库中提取有标复句12 000条(如表4所示),以此试验添加PCA后ERNIE-Gram与Tiny-BERT的性能变化。

表3 三分系统与HIT-CDTB关系对应语料库

续表

表4 CCCS语料
3.2 参数与指标
语料来自前文所述的HIT-CDTB与CCCS,硬件使用百度AI studio服务器(6)https://aistudio.baidu.com/aistudio/index,具体参数见表5。

表5 实验相关参数
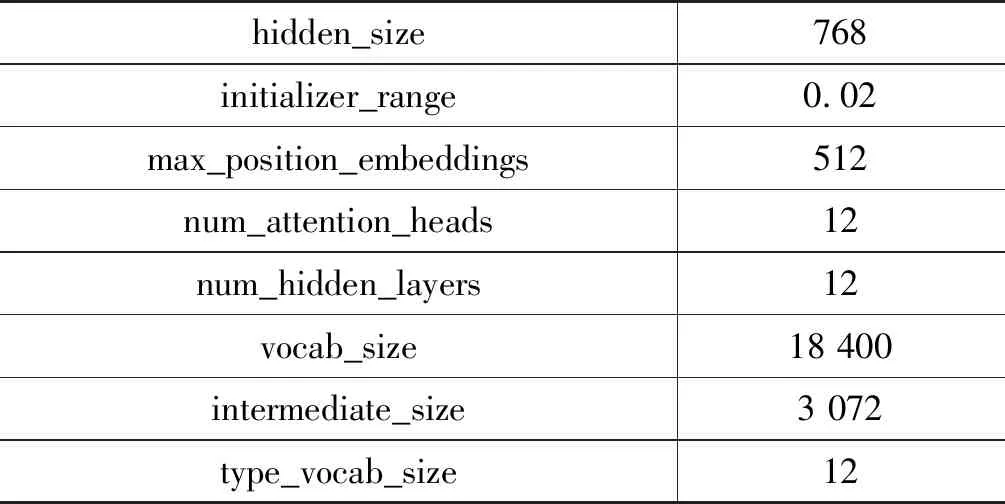
续表
指标包括精确率(Precision,P)、召回率(Recall,R)、F1值(F1-score)、准确率(Accuracy,Acc)。针对具有K种篇章关系类别的分类系统,可定义如式(8)所示分类结果的矩阵。
(8)
其中,nij表示将i关系类别的篇章关系实例推断为j关系类别的实例个数。上述评价指标的计算如式(9)~式(12)所示。

3.3 结果与分析
3.3.1 ERNIE-Gram、TinyBERT在添加PCA模块前后的性能对比
在混合模型中,只需要ERNIE-Gram生成的词向量,ERNIE-Gram不直接参与关系转换过程,但是为了判断词向量的质量,验证模型的可行性,我们利用从CCCS中抽取的语料验证ERNIE-Gram和TinyBERT预训练模型的性能,结果如表6所示。
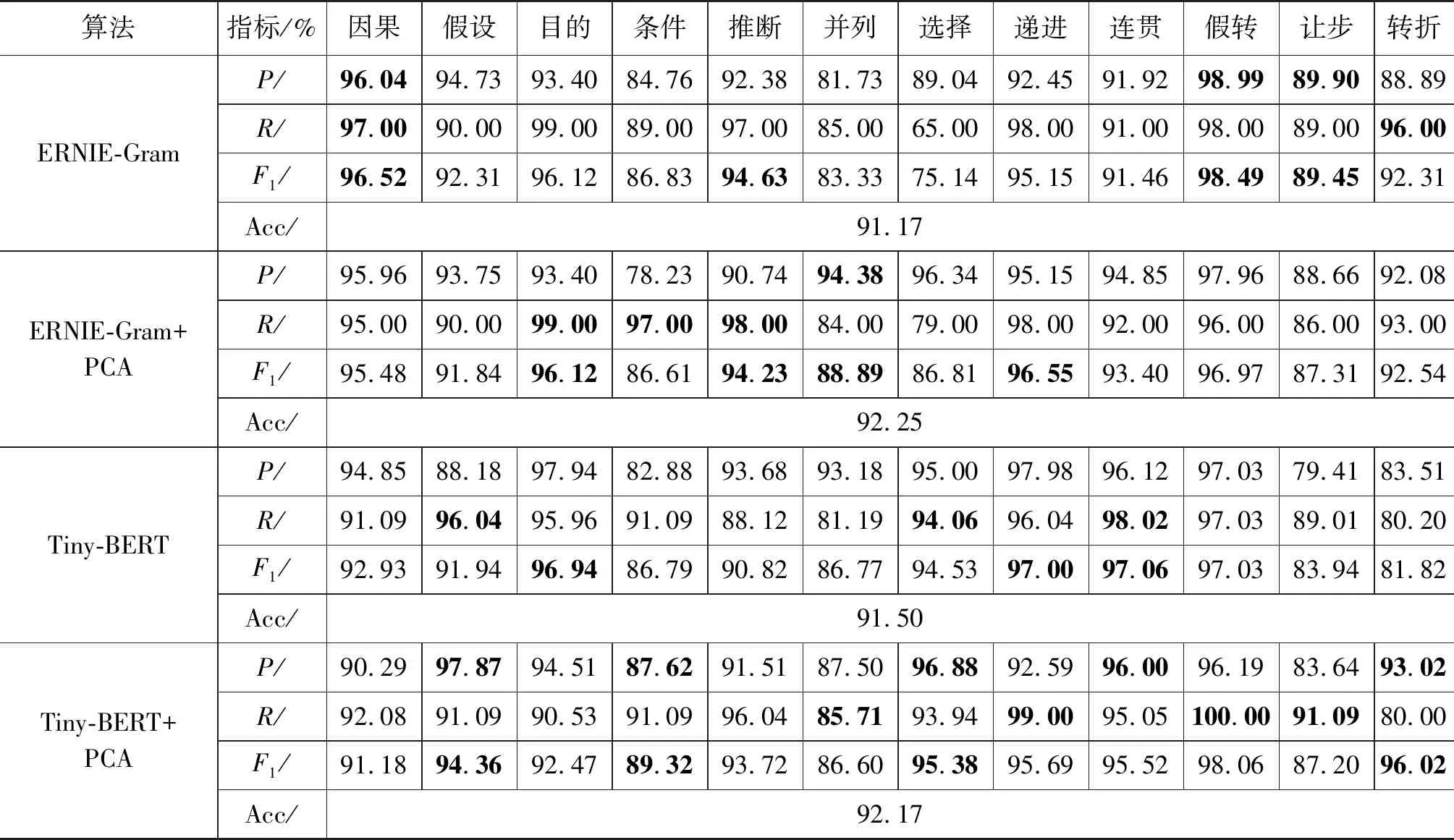
表6 CCCS语料库的实验结果
从表6中可看出,ERNIE-Gram与TinyBERT整体上性能接近,准确率都超过了90%,在每个预训练模型中,添加PCA模块去除第一主成分的模型性能优于未添加PCA的原始模型。
实现复句三分系统12小类与HIT-CDTB系统29小类的相互转换在图6中第二、第三阶段均可完成,第二阶段使用预训练模型进行转换;第三阶段使用预训练模型+规则进行转换。
3.3.2 HIT-CDTB→复句三分系统实验结果
表7展示从HIT-CDTB到复句三分系统这一方向的转换结果,分为“基于预训练模型”与“预训练模型+规则”两种方式。表7整体准确率较表8更高,主要原因为三分系统只有12类,而HIT-CDTB有29类。此外,“预训练模型+规则”转换准确率远高于仅依赖预训练模型转换,原因则是HIT-CDTB中的类别与三分系统中的类别对应关系以多对一为主,使用规则能减少转换时的不确定性,这也体现了专家系统的优势。

表7 HIT-CDTB→复句三分系统转换结果 (单位: %)
3.3.3 复句三分系统→HIT-CDTB实验结果
表8展示从复句三分系统到HIT-CDTB这一方向的转换结果。从表8中可看出,预训练准确率为76.13%,模型+规则转换比自动转换高约1.5个百分比,主要原因与表6类似,在关系对应表中,连贯与1-2-1先序、假转与3-2简介对比分别一一对应。

表8 复句三分系统→HIT-CDTB转换结果 (单位: %)
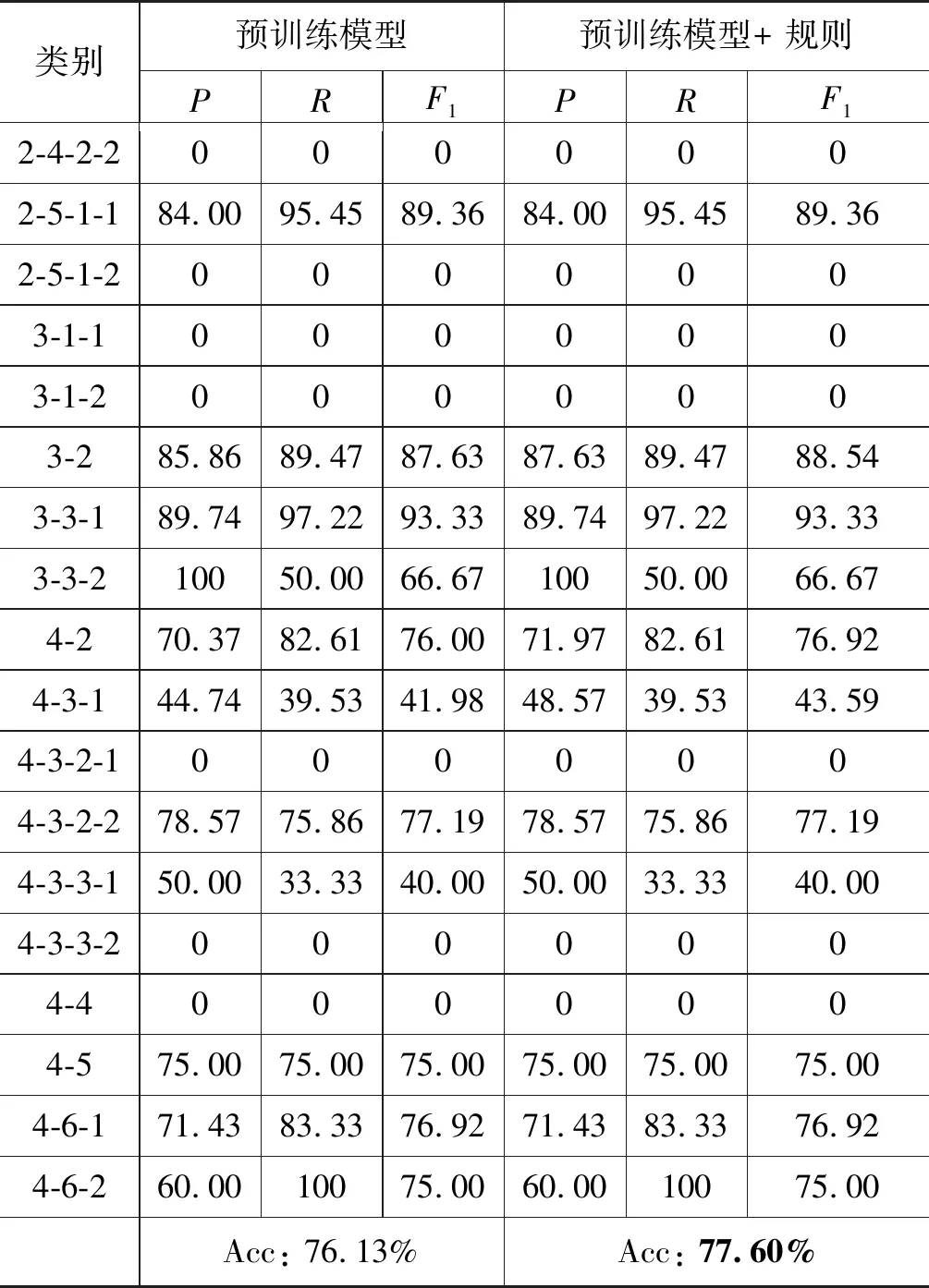
续表
整体来看,从HIT-CDTB→三分系统比从三分系统→HIT-CDTB转换准确率要高,一方面是由于三分系统的12种关系数量少于HIT-CDTB中的29种关系类别;另一方面则与预训练模型、转换规则有关。本文中用到的ERNIE-Gram模型更适合处理中文文本,而HIT-CDTB分类系统以英文篇章分类系统PDTB2.0为基础;自建的转换规则覆盖三分系统12种类别中的8类,而只包括HIT-CDTB系统29类中的17种。第三阶段结合了规则+统计两种方法,既保留了准确率,又提高了转换算法的适用范围,因此效果最好。
4 总结
本文基于ERNIE-Gram和TinyBERT预训练模型,提出了一种复句关系识别与转换混合模型,该模型实现了对两种复句分类体系下复句关系的转换,双向转换准确率达到80.53%、76.13%;将该模型与基于规则的专家系统相结合,双向转换准确率达到89.17%、77.60%。实验结果验证了将规则与统计方法结合起来具有更高的准确率和更广的适用范围。
本文的方法还存在着不足,如混合模型参数较多,对硬件要求过高,因此,如果缩小模型参数使之更适合复句关系识别与转换是需要考虑的问题;同时,转换的准确率还不够理想,一方面需要加大语料库的规模,另一方面,需要研究更高效的模型。
国内外还有句群、RST-DT、CDTB等众多分类体系,本文提出的方法是否适合建立各种篇章关系分类体系之间的关系对应与双向转换,需要进一步的研究检验。
猜你喜欢
成都理工大学学报·社会科学版(2022年1期)2022-05-26
通信技术(2021年12期)2022-01-25
韩国语教学与研究(2021年2期)2021-11-24
华北电力大学学报(社会科学版)(2021年2期)2021-07-21
天津外国语大学学报(2020年1期)2020-03-25
语言与翻译(2015年4期)2015-07-18
民族古籍研究(2014年0期)2014-10-27
西安航空学院学报(2014年4期)2014-07-13
外语教学理论与实践(2014年2期)2014-06-21
中文信息学报(2012年2期)2012-06-29
