
改进的ResNeXt50神经网络面部表情识别方法*
2022-02-03 02:58:58钱智哲
西安工业大学学报 2022年6期
张 洁,穆 静,钱智哲
(西安工业大学 计算机科学与工程学院,西安 710021)
人类对于情绪的感知,往往来自于面部表情。个人对他人的初印象,仅有7%取决于谈话内容,绝大部分来自于面部表情[1]。从表情中可判断情绪状况的好坏,继而可以更好的进行交流,表情的这种直观性使其具有很高的应用价值。将表情识别与机器进行结合,提高识别效率,有助于表情识别在医学、自动驾驶等领域的应用。面部表情识别过程包括图像获取、图像预处理、特征提取、表情分类四个部分。特征提取是整个表情识别过程中最为关键的步骤,对表情分类的结果产生直接影响[2]。
面部表情识别方法一般分为传统方法和深度学习方法。传统方法中,文献[3]对图像序列进行了面部表情的自动识别分析,文献[4]将光流法引入面部表情识别,提取光流值构成面部表情的特征向量,再对面部表情特征进行识别,文献[5]提出局部二进制模型(Local Binary Pattern,LBP),在不同的数据集上,手工设计出不同的分类器进行表情识别。上述的传统面部表情识别方法采用手工设计的特征提取器,在提取特征时容易将对分类有较大影响的特征忽略掉,从而导致分类结果不准确。随着软硬件设施的进步,特征提取方法也在不断的发展。2006年,文献[6]提出深度信念网络,深度学习重新开始进入研究人员视野,此后,研究人员提出了许多经典的分类网络模型,如AlexNet[7],GoogelNet[8]等等。深度学习的迅猛发展使得表情识别也取得巨大突破,文献[9]将卷积神经网络与支持向量机相结合,通过监督学习来增强卷积网络对表情的分类能力,但这种方法特征提取方面的能力仍旧不强。在早期的深度学习中,获取更多表情特征的主要方式是增加网络深度,也就是堆叠卷积运算符,这样容易出现梯度消失或者梯度爆炸现象[10-11],文献[12]提出ResNet网络,以“短接”的方式直接将信息绕道传到输出,不但在一定程度上保持了信息的完整性,还有效解决了梯度消失或爆炸问题。2017年,受到Inception[13]思想的启发,文献[14]将ResNet与Inception结合,提出ResNeXt网络,与ResNet相比,在同等网络层数条件下,ResNeXt用到的参数数量更少,且计算速度和精确度有明显提升。深度学习网络在特征提取方面有了很大的进步,但仍不可避免一些重要信息在卷积和池化过程中丢失。文献[15]提出一种基于混合注意力机制的网络,强化网络通道在提取特征时对于一些表情细节的关注,如眼睛、嘴角等,文献[16]提出融合了全局特征与局部特征的算法,文献[17]提出融合局部特征与两阶段注意力权重学习的面部表情识别方法,这些方法都旨在提取更多表情特征以提升分类效果。金字塔卷积(Pyramidal Convolution,PyConv)[18]利用大小不同的卷积核,既可以关注到全局特征,也可以很好的照顾到局部特征,进而细化特征提取。文献[19]提出基于全局注意力及金字塔卷积的表情识别,文献[20]提出深度多尺度融合注意力残差面部表情识别网络,都从细化特征提取方面入手以获得更好的结果。ACNet (Asymmetric Convolution Network,ACNet)[21-22]中使用非对称卷积模块从不同的维度提取特征,提升网络模型的鲁棒性。
基于此,文中拟从强化特征提取方向入手,以ResNeXt网络为基础架构,采用多尺度特征融合方式细化纹理方面的特征提取,选用SoftPool池化[23-24],以减少特征信息的损失,再结合非对称卷积良好的性能,增强残差网络的鲁棒性。
1 算法原理
SoftPool是一种变种的池化层,它可以在保持池化层功能的同时尽可能地减少特征图信息的损失。SoftPool是可微的,是基于Softmax加权方法来保留输入的基本属性。局部领域内,激活的自然指数与领域内所有激活的指数之和之比即为权重,对领域内所有权重进行加权激活累加,得到池化操作的输出[25]。权重计算公式及加权激活公式为
(1)
(2)
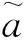
图1为SoftPool下采样的过程。输入一张特征图,图中彩色部分表示正在进行采样的3×3大小的区域。利用权重计算公式,计算出选区中每个元素的权重,将每个权重与相应的激活值进行相乘并累加,得到最后结果,在此过程中,权重与相应的激活值一起做非线性变换。
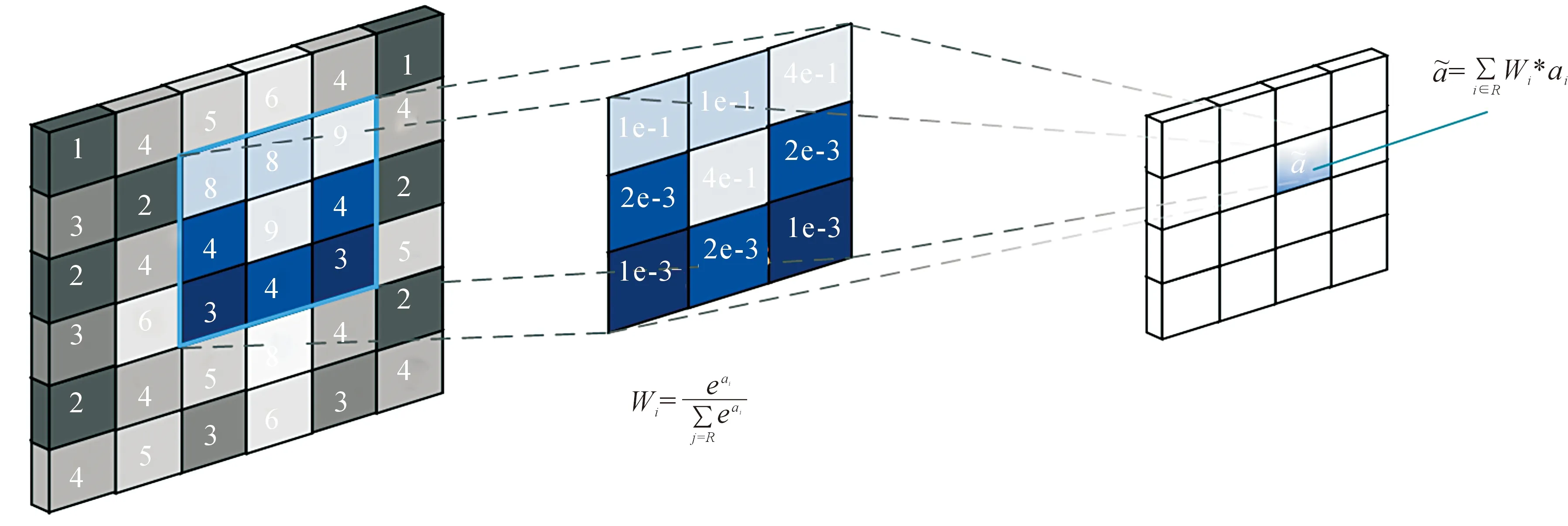
图1 SoftPool下采样过程Fig.1 SoftPool downsampling process
ACNet的核心在于非对称卷积模块(Asymmetric Convolution Block,ACBlock),其原理是利用大小方向不同的卷积核,强化特征提取,实现效果提升[26]。目前3×3卷积是大多数网络所使用的基础组件,因此,非对称卷积模块针对3×3的卷积核进行,将原本一个3×3的卷积核拆分成1×3,3×1以及3×3的三个卷积核,对特征图分别进行卷积,最后进行融合。非对称卷积模块如图2所示。
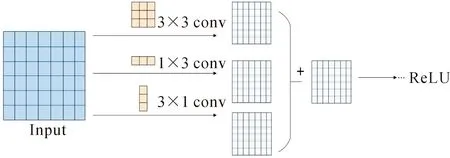
图2 非对称卷积模块Fig.2 Asymmetric convolution module
2 ResNeXt50神经网络改进
文中以ResNeXt50网络为基础,结合多尺度特征融合、SoftPool和非对称卷积,设计出基于多尺度特征融合的AC-SP-ResNeXt50网络。多尺度特征融合层(Multi-Scale Feature Fusion Convolution,MFFC)为网络的第一层卷积结构,使网络以多个感受野采集特征信息,再将非对称卷积模块融入残差结构中,构成非对称残差模块,受到文献20的启发,将SoftPool作为本网络的池化层,尽可能地减少输入特征信息的损失。
2.1 AC-SP-ResNeXt50网络构建
图像输入网络后经过MFFC层进行特征提取,经过SoftPool池化后进入到添加了ACBlock的残差网络中,具体网络结构如图3所示。
图3 AC-SP-ResNeXt50网络结构图Fig.3 AC-SP-ResNeXt50 network structure
残差结构中,将原本的普通卷积模块替换成非对称卷积模块,目的是让残差分支能够提取到更丰富的特征。与原ResNeXt网络结构的分组相同,残差结构共有32条平行路径,每条分支路径的拓扑结构相同,但参数相互独立,可以有更好的性能提取特征。进入残差结构后,由1×1的卷积核将输入数据的特征映射到新的特征空间中,经过拆分后的1×3,3×1,3×3三路并行卷积,从不同的空间上提取多尺度的特征信息再进行线性相加融合,实现强化特征提取的目的,再由1×1卷积灵活控制特征图输出到网络的下一层的深度,最终将整个分组卷积融合,与短接的分支相加,经过ReLU函数激活输出到下一层,该非对称卷积计算过程为
(3)
Y=Bn(X1×3+X3×1+X3×3),
(4)
X=ReLU(Y),
(5)
式中:X为输入矩阵;Convn×n(·)为卷积核尺寸为n×n的卷积;Y为三个不同大小卷积核卷积后进行融合的结果;Bn(·)为批量统一化。AC-SP-ResNeXt网络结构详细信息见表1。
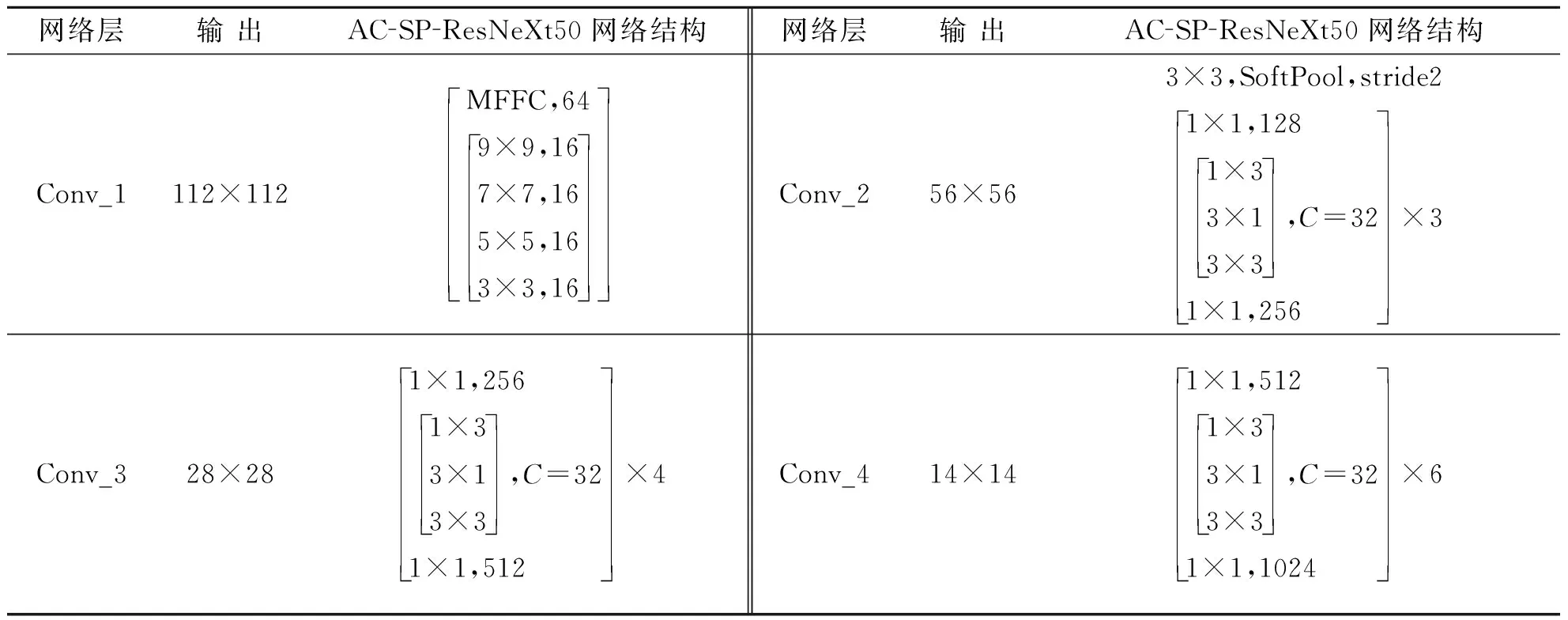
表1 AC-SP-ResNeXt50网络结构详细信息表Tab.1 Detailed information of the AC-SP-ResNeXt50 network structure

续表
2.2 多尺度特征融合
在进行特征提取时,不同尺寸卷积核具有不同的感受野[27],尺寸较大的卷积核进行特征提取时能很好的提取到图像的整体特征,但容易忽略掉比较重要的细节,而尺寸较小的卷积核虽然能很好的照顾到图像的细节特征,却不容易提取到图像的整体特性,且对于图像分类来说,高层特征图包含的特征信息会更加丰富清晰,基于此,文中提出采用3×3,5×5,7×7,9×9四个不同尺度的卷积核对原始图像以多个尺度进行特征提取。
如图4,选取ResNeXt50和AC-SP-ResNeXt50网络第一层输出中最具有代表性的12张特征图,(a)、(b)分别为图像经过ResNeXt50网络的第一个7×7卷积后输出的特征图以及文中提出的AC-SP-ResNeXt50网络MFFC层后输出的特征图,从图像上可以看到,文中提出的方法在进行特征提取时对于纹理特征的关注明显多于ResNeXt50,且对于图像全局特征的关注也优于ResNeXt50,因此在以后进行更深层次的特征提取操作时所拥有的语义细节特征更多,识别效果也会更加出色。

图4 网络第一层特征图Fig.4 The feature map of the first layer of the network
3 实验结果及分析
文中在CK+数据集和Jaffe数据集上训练模型并验证。CK+数据集是在实验室环境下拍摄的表情数据集,拍摄环境固定,干扰条件较少,包含123名受试人员593个视频序列,这些序列的持续时间从10帧到60帧不等,表现了从中性表情到高峰表情的转变。选取其中带有7个基本表情表达标签(愤怒、蔑视、厌恶、恐惧、快乐、悲伤和惊讶)的327个序列帧共981张图作为文中实验的数据集。Jaffe数据集是由10名日本女生在实验室条件下做出7种表情(愤怒,厌恶,恐惧,高兴,悲伤,惊讶,中性),共包含213张图片,由于Jaffe数据集样本数量较少,为扩充数据,提升网络训练过程中的性能,文中将每个样本数据经过水平方向和垂直方向的翻转后,达到639张样本图片,扩充后的jaffe数据集如图5所示。
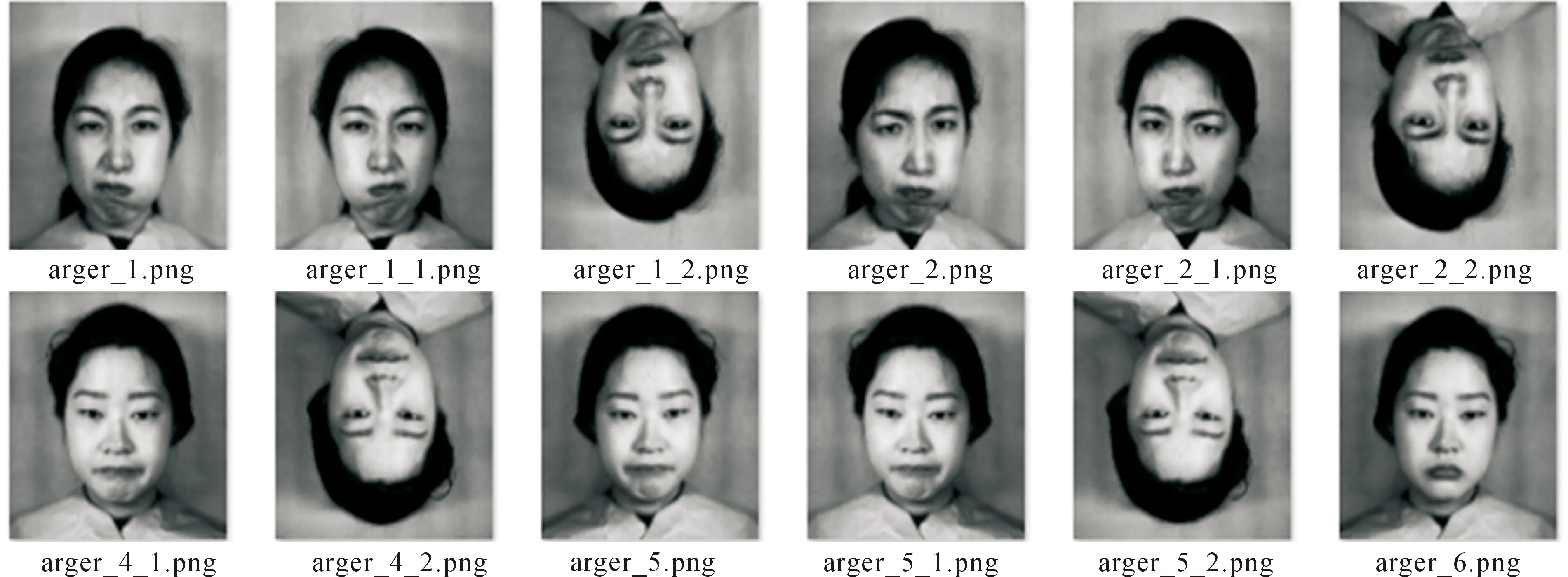
图5 扩充后的jaffe数据集Fig.5 The augmented jaffe dataset
实验使用的操作系统是Windows系统,在python3.8环境下用PyTorch1.7.1搭建网络模型,使显卡内存为12 GB的NVIDIA Tesla K80训练网络.训练过程中,使用Adam优化器更新权重,学习率设置为0.000 1。根据数据集样本数量特点,查阅资料后,先选取100次,150次,200次分别作为迭代参数在CK+数据集上进行实验。经过实验验证,迭代次数为100次时网络性能不够稳定,在迭代150次以后识别率曲线已达到相对稳定状态,因此选取总迭代次数为150次完成文中实验。为了验证和测试文中提出的结构,文中设计了三组实验:
1) 在CK+数据集上,建立消融实验验证文中提出的AC-SP-ResNeXt50神经网络的可行性;
2) 在CK+数据集和Jaffe数据集上,与现有的其他参考文献使用的算法,建立对比实验,测试改进效果;
3) 使用网上随机下载的图片进行表情识别,评估模型的泛化能力。
3.1 消融实验
为验证改进模型的可行性和必要性,文中对改进模型中的MFFC卷积、ACBlock、SoftPool分别与ResNeXt50结合进行实验,并与ResNeXt50和改进的AC-SP-ResNeXt50在CK+数据集上进行对比。
图6为训练过程中在验证集上的识别率曲线。
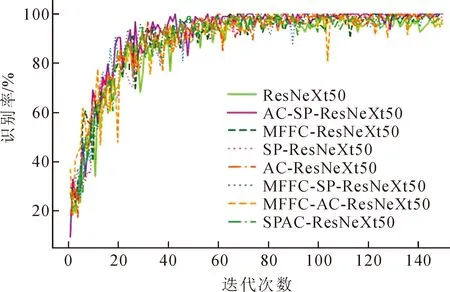
图6 验证集Acc曲线Fig.6 Validation set Acc curves
图6中MFFC-ResNeXt50表示MFFC卷积与ResNeXt50结合,AC-ResNeXt50表示ACBlock与ResNeXt50结合,SP-ResNeXt50表示SoftPool与ResNeXt50结合,MFFC-SP-ResNeXt50表示MFFC卷积、SoftPool与ResNeXt50结合,MFFC-AC-ResNeXt50表示MFFC卷积、ACBlock与Res NeXt50结合,SPAC-ResNeXt50表示SoftPool、ACBlock与ResNeXt50结合。从图像上可以看出,改进后的模型在识别率上优于其他模型,每个因素对于识别率均有一定的提升。
图7为模型的损失曲线,从下降速度来看,迭代30次以后,改进模型AC-SP-ResNeXt50的下降速度最快,表现最好。
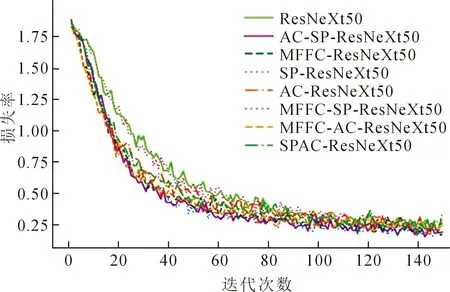
图7 训练损失曲线Fig.7 Training loss curves
表2为消融实验的具体实现过程,将每个模块与ResNeXt50结合,在CK+数据集上进行验证,得出每个模型的识别率。
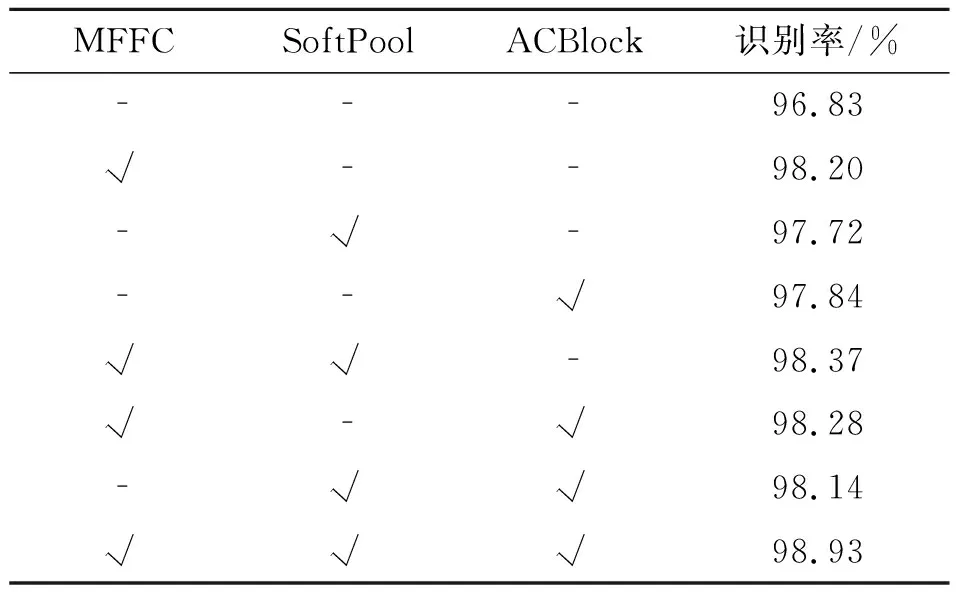
表2 以ResNeXt50为基础模型的消融实验Tab.2 Ablation experiments based onthe ResNeXt50 model
从表2中可知,MFFC,SoftPool,ACBlock均对模型识别能力有一定的提升。其中,文中提出的多尺度特征融合MFFC使模型识别能力有较大的提升。MFFC使模型的识别率上升了1.4%,所以,多尺度特征融合可以提取到更多输入图像的特征信息。
SoftPool使网络的识别率增加了0.9%,实现下采样的同时也保留了更多特征信息,有利于后续残差结构的特征提取。
ACBlock提高了1.0%的识别率,使残差模块具有更好的学习能力,提升网络模型的表情识别能力。
在消融实验的进行过程中不难发现,各个模块对于网络模型的性能均有提升,但这种提升效果不是直接叠加的,而是在一个改进的基础上有小幅度的提升,通过逐步改进ResNeXt50网络,模型的表情识别能力也在逐步提升。
3.2 对比实验
为验证文中方法的有效性和优势,将AC-SP-ResNeXt50结构与存在的一些深度学习方法:文献[9]提出的卷积神经网络与支持向量机相结合的方法(CNN+SVM),文献[15]提出的注意力与空间注意力机制分离方法(CA-ST-DSC),文献[19]提出的金字塔卷积神经网络与注意力机制相结合的方法(PyConv-Attention),文献[2]提出的注意力金字塔卷积残差网络模型结合的方法(APRNET50)在CK+数据集上进行对比分析。文献[16]提出的全局分支和局部分支结合的方法(GL-DCNN),李春虹等人提出的基于深度可分离卷积的识别方法(DSC-FER)[28],文献[17]提出的融合局部特征与全局特征方法(FLF-TAWL),文献[20]提出的多尺度注意力残差网络方法(DMFA-ResNet)与文中所提方法在Jaffe数据集上进行对比。文中提出的AC-SP-ResNeXt50网络首先以多尺度特征融合层提取原始图像上的特征,细化纹理信息,再以SoftPool池化,实现降低计算量防止特征冗余的同时保留更多特征,最后再使用非对称残差结构提取更深层次的特征,达到强化特征提取的目的,从这三个方面最大程度上实现提取到更多特征信息,进而提升识别率。从表3的对比结果来看,文中提出的网络在CK+数据集和Jaffe数据集上的特征提取效果更好,识别结果更优。
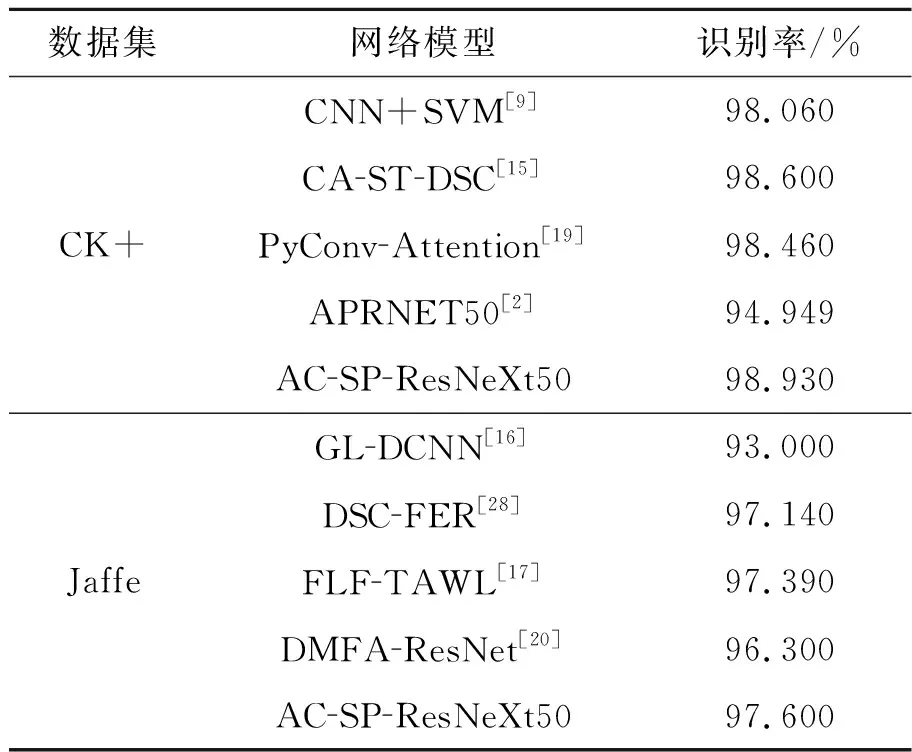
表3 对比结果Tab.3 Comparison results
3.3 模型泛化能力评估
为测试模型在现实场景中的应用能力,将在CK+数据集上训练的模型保存,并在网上随机选取表情图片运用该模型进行面部表情识别,识别结果如图8所示。

图8 表情识别结果Fig.8 Expression recognition results
从图8中的识别结果来看,文中模型对与现实生活中的表情图片也能基本准确识别,其中,对于“悲伤”表情识别准确率为95.7%、“惊讶”识别准确率为95.6%、“高兴”识别准确率为90.8%、“厌恶”识别准确率为91.9%,这四种表情识别率都能达到90%以上,“生气”表情识别准确率为86.1%、“恐惧”识别准确率为80.3%、“蔑视”识别准确率为80.1%,这三种表情的识别结果也能在80%以上,从整体来看,文中提出的改进模型泛化能力较好。
4 结 论
1) 文中从特征提取的角度出发,提出一种以ResNeXt50为基础的改进网络模型。在结构中,多尺度特征融合卷积从原始图像上提取了更多的特征信息,SoftPool完成池化功能的同时防止丢失重要特征,非对称卷积使残差网络结构具有更强的特征提取能力。在Jaffe数据集和CK+数据集上设计了消融实验和对比实验,验证了模型的有效性,测试并评估了模型的泛化能力。
2) MFFC、SoftPool、ACBlock这三个模块均对模型的表情识别能力有提升作用,但这种作用的效果不是直接叠加,而是随着模型的改进而逐步提升;相对于现有的一些表情识别方法,文中模型在Jaffe数据集和CK+数据集上的识别结果更好,验证了文中模型的有效性;文中模型在识别网络表情图像的表现较好,泛化能力较好。
3) 下一步计划在数据增强和模型泛化能力评估方面做出进一步的改进,强化数据增强方法,并扩充真实场景下的测试集,全面评估模型的泛化能力。
猜你喜欢
数学年刊A辑(中文版)(2020年2期)2020-07-25 02:04:44
数学物理学报(2019年6期)2020-01-13 06:08:16
数学年刊A辑(中文版)(2018年2期)2019-01-08 01:59:50
电子制作(2018年19期)2018-11-14 02:37:08
数学物理学报(2017年5期)2017-11-23 07:51:31
自动化学报(2017年11期)2017-04-04 02:52:58
数学理论与应用(2016年4期)2016-05-17 04:50:23
电测与仪表(2015年4期)2015-04-12 00:43:04
噪声与振动控制(2015年4期)2015-01-01 07:08:21
新课程学习·中(2013年3期)2013-06-14 05:55:20
