
基于复杂网络模块分析的区域物流协同效应研究
2022-01-28 12:38谢欣雨
工业技术经济 2022年2期
谢欣雨 王 健
(福州大学经济与管理学院,福州 350100)
引 言
中共中央在2018年11月印发 《关于建立更加有效的区域协调发展新机制的意见》,对加快形成统筹有力、竞争有序、绿色协调、共享共赢的区域协调发展新机制,进行了全面的部署。实施区域协调战略是新时代国家重大战略之一。而区域物流协同发展是区域协调发展的基础和前提[1]。区域物流的协同发展促使区域物流高效运作,城市间物流的带动效应加强,从而提升区域物流的发展水平,助力区域经济更好地发展[2]。
目前学术界对于区域物流的评价更多的是聚焦于区域物流评价与区域经济发展的均衡与否。李宝库和李销[3]利用DEA-BCC模型探索了长三角区域物流和区域经济之间的互动关系,发现两者长期影响,但是在前期存在负效应态势;郭湖滨和齐源[4]结合复合理论和耦合度模型分析了长三角地区区域物流与区域经济之间协同发展的水平以及空间协同的特征;刘卜榕[5]采用因子分析法和熵权-灰色关联组合分析模型探究发现江苏省的区域物流和区域经济之间处于中度协同发展水平;刘妤和顾正刚[6]采用格兰杰因果检验方法验证出西藏的区域物流和区域经济之间存在双向互动关系;张旭等[7]利用云PDR的方法对区域物流进行评价,结果表明各地区之间的物流能力差异明显;唐建荣等[8]利用DEA-Malmquist模型对区域物流的效率进行测算,发现区域物流效率有着显著的差异。先前的研究分析可以清晰地反映出各区域物流发展的均衡性,但是忽略了各区域物流之间发展的相关性。
本文利用2005~2019年间区域物流的相关指标,构建了区域物流的评价模型,采用结构熵权法计算出各地区的物流发展水平。然后通过复杂网络刻画出中国各省、自治区和直辖市之间物流发展的相关性,且结合滑动时间窗口得到了15年间区域物流发展水平复杂网络的动态信息,最后根据各地区物流发展水平的相关性的强弱进行模块划分,以此来揭示中国区域物流发展的关联性。
1 研究方法
1.1 结构熵权法
程启月[9]提出的结构熵权法首先将专家调查法和模糊评价法结合,形成 “典型排序”,再利用信息论里的熵值法进行计算,以此进行盲度分析,减少典型排序的不确定性。肖枝洪和王一超[10]发现该方法在盲度分析时将隶属函数χ(I)转化成U(I)时存在问题,所以本文采用了肖枝洪提出的改进的结构熵权法来计算权重。
权重计算方法:
第一步,采集专家意见,形成主观上的 “典型排序”,再对 “典型排序”进行盲度分析。对典型排序确定排序转换的隶属函数为:
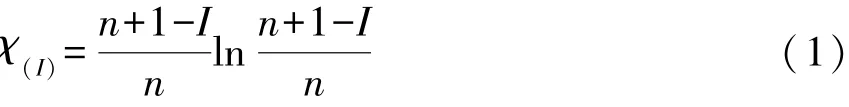
其中I表示专家对各个指标的初始排序,n为指标个数。
在式 (1) 中令I=aij,就可以得到bij=χ(aij)。bij即为排序数I所对应的隶属函数值,也就是不确定性。 数组{1-b1j,…,1-bkj}视作K个专家对指标Uj的话语权, 对数组{b1j,…,bkj}取算数平均值,记作bj,称1-bj为K个专家对指标Uj的一致看法,也叫做平均认知度。
第二步,根据信息论中的对于熵的定义,记K个专家对指标Uj认知的不确定性为Qj,也称作认识盲度,其定义为:
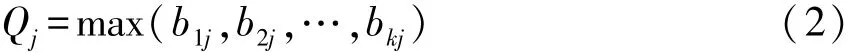
记K个专家对指标Uj认知的整体认识度为:

第三步,进行归一化处理,指标U={u1,u2,…,un}中第j个指标的权重:
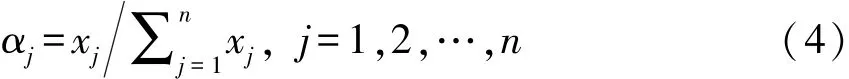
1.2 复杂网络的模块化算法
复杂网络中模块化分析的计算方法主要有图划分方法[11]和层次聚类方法[12]。 但本文采用了更高效和准确的基于模块矩阵和特征向量的模块分析方法[13]。采用复杂网络建模方法可以刻画物流发展水平的整体性[14],模块化分析具有良好的扩展性[15],可以在不事先设定社团数量的情况下最大程度地挖掘复杂网络中社团结构的模块属性[16]。本文将中国31个省、自治区和直辖市作为复杂网络的节点,把各时间段内区域物流的得分的相关性作为连边,构建了反映区域物流间发展协同性的复杂网络。以5年作为一个时间窗口,计算区域物流发展水平之间的相关性,得到了不同时期复杂网络的动态演化,并根据相关性水平进行模块划分,以此来解释中国区域物流之间发展相关性的动态演化规律。相关性系数的计算方法如下:
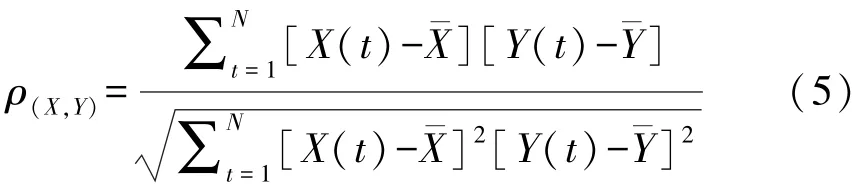
其中的X(t)和Y(t)代表了两个时间序列,N是数据点的个数,和表示两个时间序列的平均值。ρ∈(-1,1),数值越高代表区域之间的物流发展的协同性越高。
2 实证分析
2.1 评价指标体系的构建及权重计算
在阅读大量文献的基础上,基于数据的可得性,本文借鉴了郭湖斌和齐源[4]的研究成果,结合对物流专业高级人才的调研,选取基础设施、产出规模以及发展潜力3个方面来评价区域物流发展水平,确定了如表1的区域物流评价指标。所选取变量的原始数据均来自 《中国统计年鉴》(2005~2020),且所有数据通过极差法进行无量纲化处理。
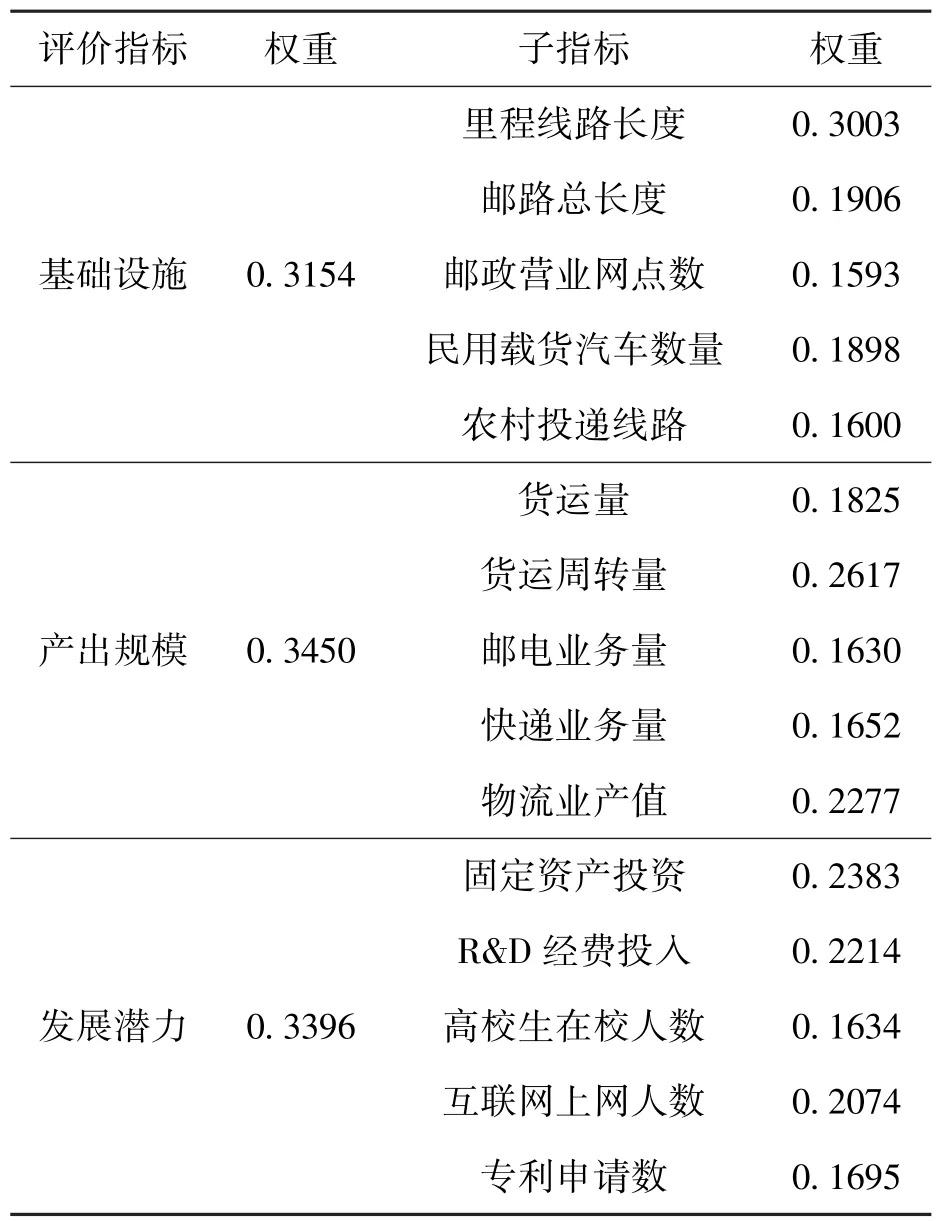
表1 区域物流评价指标体系及各指标权重值
本文采用全国各省、自治区和直辖市2005~2019年的面板数据,结合结构熵权法算出的权重值分别得出了各区域物流子系统的综合发展水平值。利用肖洪枝提[10]出的改进的结构熵权法计算出各指标的权重系数如表1所示。从表中可以看出在区域物流系统中里程线路长度指标的权重最大(0.3003),邮政营业网点数指标的权重最小(0.1593)。结合各指标权重计算出如表2的区域物流综合发展水平。从表2可以看出各省(区、市)之间物流的综合发展水平差异较大,东部沿海城市物流的综合发展水平较高,广东物流水平最高,其次就是位于长三角经济带上的省域等。地处西北的宁夏和青海物流综合发展水平最低。影响区域物流发展的最主要的因素是劳动力要素和资本要素的投入,区域物流发展水平与区域人口结构以及人口数量有着极大的关系。结合第七次的人口普查结果来看,区域物流发展水平较高的省(区、市)都属于人口净流入较多的省域,而且人口结构呈现高度的年轻化。尤其是广东省,人口数量居全国第一且60岁以上的人口仅占全部人口的12.35%(全国为18.7%)。物流作为生产性服务业,主要依附于制造业、工业以及其他行业发展,而这些行业又是区域经济的重要组成部分,因此现代物流业的发展水平也取决于区域经济的发展水平。可以从表中看出区域物流发展水平较高的地区经济发展水平同样处于全国前列。
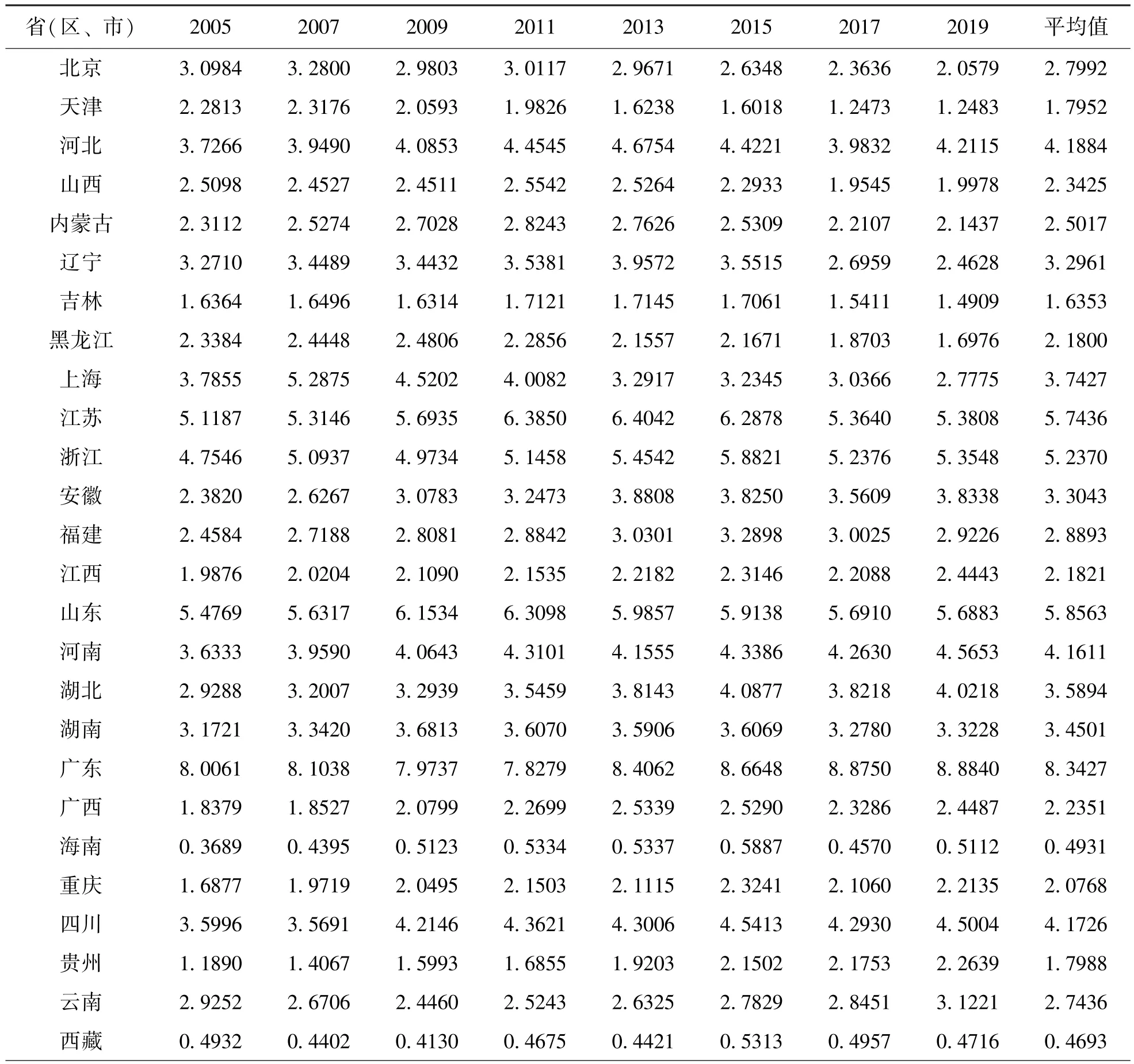
表2 区域物流综合发展水平
2.2 相关性分析
本文以5年作为时间窗的宽度,依次将时间窗后移,以各省(区、市)作为节点构建复杂网络。根据各省、市及自治区的物流综合发展水平进行相关性分析,得到了2005~2009,2006~2010,……,2015~2019 11个连续变化的动态复杂网络。11个复杂网络连边相关系数的分布如图1所示,可以看出不同时期的网络连边都均匀地分布在0~1之间,在p>0.5的区间内的概率分布大于p<0.5区间内的概率分布。从图2可知这15年间区域物流的平均相关系数变化幅度不大,控制在正负0.1之间。由图可知2006~2010年之间的相关系数明显下降,这是因为2008年全球金融危机对中国经济造成巨大影响,从而对物流业也造成巨大冲击,但是随着时间的推移,市场逐渐复苏,由金融危机带来的影响逐渐减小。另外受国务院颁布的 《物流业发展中长期规划2014~2020》等政策的影响,区域物流也逐渐开始发展,平均相关系数开始逐渐增大。2009年开始,受电子商务发展的影响,对中国物流提出了新的要求,部分地区率先开始发展,这就导致区域间的差异扩大,后伴随着全国电子商务的普及发展,区域间物流发展速度也逐渐恢复。整体的相关系数再次开始呈现上升趋势,说明中国区域物流之间能够较为协调的发展。

续 表
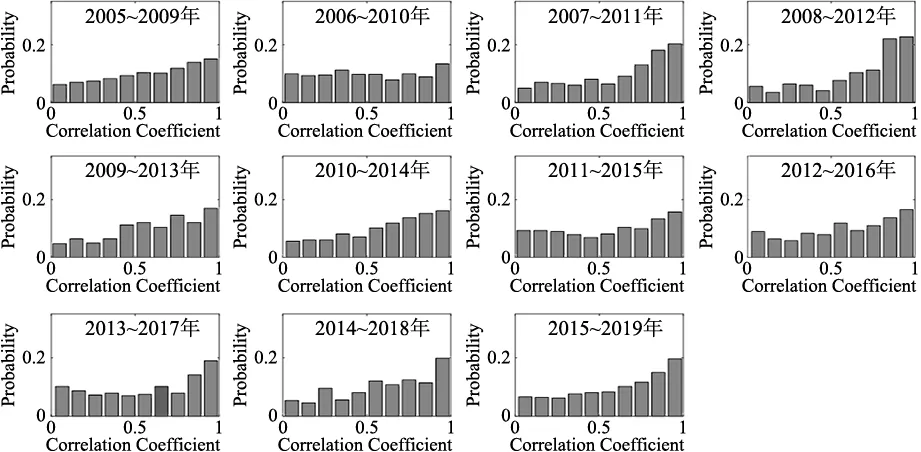
图1 各个时期区域物流复杂网络中相关性系数分布

图2 区域物流平均相关系数
2.3 模块化分析
根据上述相关性分析得到的11个连续动态变化的复杂网络进行模块化分析,得到如图3所示的模块化数。由图可知,各省市区按照综合物流发展水平之间的相关性所划分的模块个数在前期是不断波动的,后期逐渐趋于平稳。以每5年为一个时间节点来分析区域物流之间增长的协同性。在同一个模块中的各地区物流发展水平的协同性明显高于其他模块中的地区。图4是3个时期各地区的邻接矩阵,相关系数分布集中的对角线方块即为复杂网络的不同模块(不同模块由黑色方块标出)。根据图4中各地区物流发展水平相关性的排列顺序,将各省市区的模块信息排列在表3中。
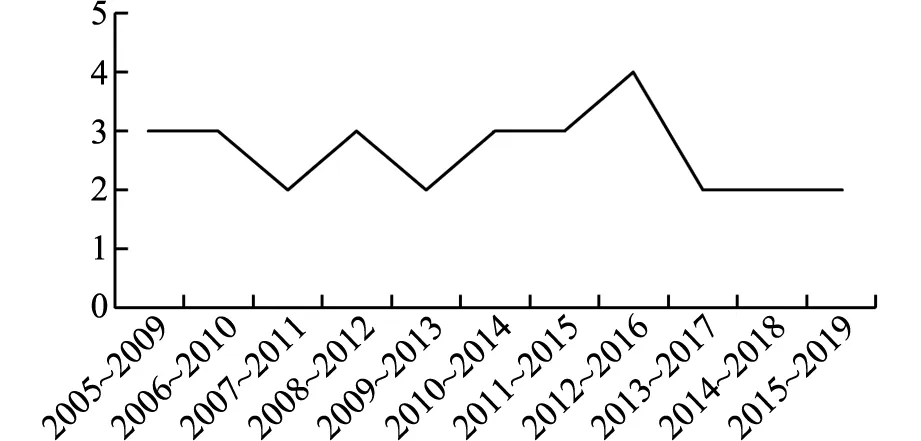
图3 区域物流分属模块数随时间的变化规律
模块化分析能够清晰地看出各省市区之间物流发展的相关性。东三省和西北五省更多地在同一个模块中,从表3中可以看出辽宁省和黑龙江省,以及宁夏回族自治区和青海省在不同时期都处于用一个模块中,这说明区域物流发展存在地缘性。东部发达城市在不同的时期均处于不同的模块中。从地理位置来说,虽然中国西部地区幅员辽阔,但是自然条件恶劣,地势以沙漠戈壁为主,而东部地区地势以平原为主,且自然资源丰富。另外在改革开放以来,中国政策向东部地区倾斜,吸引大量年轻人去东部发展,因此东部经济得到了飞速发展。越是发达的地区在发展过程中有更高的自主性。而西部地区受制于自然条件、经济水平和人口结构,其可以选择的发展方针有限,且因为具有相似的地理、社会和经济环境,所以可选择的发展策略也具有较高的相似性。从图4可知,区域物流发展水平之间整体的相关性逐渐增强而且复杂网络的模块数也逐渐减少,说明了物流发展的整体协同性增强。这是因为随着经济的快速发展,囿于生产要素以及国家政策的号召,为促进地区产业升级,东部发达地区会将一些低端制造业转移至西部地区,产业的转移促进了国内经济大循环,加大了对物流产业的需求,因此带动物流产业协同发展;另外由于迅猛发展的电商其高效和全球性的特点,要求物流必须完善基础设施以及管理技术,促进了区域物流进一步的协同发展。

图4 不同时期的复杂网络邻接矩阵

表3 区域物流相关性复杂网络的模块划分(不含港澳台)
3 结 论
本文利用中国31各省、自治区和直辖市(考虑到数据的可获得性,港、澳、台地区未包括在内)与物流相关的数据,采用结构熵权法计算出中国区域物流各子系统的综合发展水平,接着利用动态复杂网络的方法,将各省、自治区和直辖市作为节点,地区之间物流发展水平的相关性作为连边,并结合滑动时间窗口得到各区域物流网络的动态信息,最后根据各区域物流相关性的强弱进行模块化分析。可以发现中国各地区之间的相关性逐渐增大,复杂网络的模块数逐渐减少,说明中国区域物流发展的整体协同性增强。另外从模块化分析中可以看出相关性存在一定的地域性,西北各省(区、市)更多地在同一个模块,如宁夏回族自治区和青海省在不同时期都处于同一个模块中;而东南沿海城市和经济发达的北京市在不同的时期均处于不同的板块,可能是因为这些地区拥有更多发展的自主性。
推动区域物流协调发展,是中国建设现代化物流体系、推动物流高质量发展的重要任务,也是构建 “以国内大循环为主体、国内国际双循环相互促进的新发展格局”的重要基础。因此本文提出以下建议:(1)强化顶层设计,建立机制完善、执行有利的协调机制;(2)加速创新资源集聚共享,打造区域协同创新共同体。跨区域协同发展,重要的是构建区域协同创新体系,有效促进区域内人才、技术、资金等创新要素的共享共用,为高质量发展、提升区域发展能级提供关键支撑;(3)发挥政府引导、市场推动的作用,促进以企业为主体的产业转移。跨区域协同发展,旨在引导企业有序流动,形成新的产业发展格局,重塑地区竞争优势。
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21
中学生数理化(高中版.高考理化)(2022年5期)2022-06-01
新班主任(2022年4期)2022-04-27
科学大众(2020年23期)2021-01-18
物流技术与应用(2019年8期)2019-09-04
汽车观察(2019年2期)2019-03-15
汽车观察(2018年12期)2018-12-26
消费导刊(2018年8期)2018-05-25
中国卫生(2016年5期)2016-11-12
现代企业(2015年2期)2015-02-28
