
新冠肺炎CXR图像分类新模型COVID-SERA-NeXt
2022-01-27 13:39谢娟英
太原理工大学学报 2022年1期
谢娟英,夏 琴
(陕西师范大学 计算机科学学院,西安 710119)
2019年底至今,新型冠状病毒肺炎(简称新冠肺炎)在全球蔓延[1],严重威胁人类健康。新型冠状病毒是严重急性呼吸系统综合征冠状病毒2型(severe acute respiratory syndrome coronavirus 2,SARS-CoV-2)[2],通过呼吸道传播,导致患者肺部发炎、呼吸困难,以至于死亡[3]。早期症状包括发热、干咳、咽痛、头痛、肌肉酸痛和疲乏等[4-5]。新型冠状病毒感染者或无症状病毒携带者往往表现出与其它急性呼吸道病毒患者非常类似的病症特征[4-6],因此识别新型冠状病毒感染者或无症状病毒携带者是阻止新冠肺炎传播亟待解决的问题。
逆转录聚合酶链反应检测(reverse transcription-polymerase chain reaction,RT-PCR)[7]是最常见的新冠肺炎病例诊断检测方法。该检测通过鼻咽或口咽拭子收集样本,进行病毒基因测序,如果与已知的新型冠状病毒高度同源,则确诊。然而,约翰·霍普金斯医学院的研究表明,多达20%的逆转录聚合酶链反应检测可能产生假阴性[8]。尽管瑞士日内瓦非营利研究中心创新诊断基金会在实验室环境下获得100%的灵敏度和至少96%特异性,但逆转录聚合酶链反应检测的临床灵敏度仅为66%~80%[9].
检查胸部X射线图像(Chest X-ray,CXR)、查看肺部是否有肿胀、炎症或者积液是新冠肺炎诊断的有效途径。便携式X射线扫描仪可在隔离室内成像,降低被检测者交叉感染的风险[10]。JACOBI et al[11]认为,便携X射线扫描仪使人们更加依赖胸部CXR图像进行诊断,并作为传统逆转录聚合酶链反应检测的补充,实现对新冠肺炎感染者的诊断[12]。
深度学习能学习图像的有效特征,已成为医学图像计算的有效手段[13-16],可以帮助医生快速准确地分析X射线图像中的异常,检测新冠肺炎感染者。
本文基于深度学习方法对新冠肺炎进行分类,在ResNeXt模型基础上,集成多种类型的注意力模块,在COVIDx数据集实现高准确度的CXR图像3分类。针对COVIDx数据集3分类任务和ResNeXt模型1 000分类任务类别数差异巨大的问题,提出了维度降解模块来缓解特征突降导致的特征提取不充分问题;针对目前新冠肺炎CXR图像数据稀缺问题,提出借助大规模医学图像预训练策略,提高低资源下的新冠肺炎CXR图像分类准确度。本文主要贡献有:
1) 提出特征维度降解模块,防止特征突降带来的特征提取不充分问题;
2) 将通道注意力和残差注意力模块交叉堆叠,增强提取特征的表达能力和不同类别图像的区分能力;
3) 在ResNeXt模型基础上,添加交叉堆叠的通道注意力和残差注意力模块及维度降解模块,提出COVID-SERA-NeXt模型;
4) 在公开访问数据集COVIDx上测试提出的COVID-SERA-NeXt模型,并与ChestX-ray8医学图像预训练、COVIDx数据集微调参数的COVID-SERA-NeXt模型进行比较。实验表明医学图像预训练进一步提升了模型分类准确度,验证了医学图像预训练对COVIDx数据集分类任务的有效性。
1 相关工作
1.1 新冠肺炎辅助诊断
胸部CXR图像是诊断各种肺部疾病广泛使用的影像,医生通过筛查病人胸部CXR图像进行早期肺炎诊断[17]。基于深度学习的计算机辅助诊断引起诸多学者关注[15],成为基于胸部CXR图像检测新冠肺炎的有效手段[18-24]。WANG et al[18]搜集整理用于新冠肺炎CXR图像分类的5个公开数据集,取名为COVIDx数据集,并针对该数据集提出COVID-Net模型。此后,基于COVIDx数据集的各种深度学习模型被相继提出。HAO et al[19]结合无监督的ResNet-50与高斯分类器,提出CNN-GP混合模型。JIA et al[20]结合MobileNet模型不同层特征,提出Modified MobileNet模型。KARIM et al[21]基于Grad-CAM++和逐层相关性传播技术提出DeepCOVIDExplainer模型。此外,针对新冠肺炎数据集3分类任务的深度学习模型还有COVIDx-CT[22]、COVID-ResNet[23]、DarkCovidNet[24]等。上述深度学习模型的优势是能学习到CXR图像的像素级信息,但新冠肺炎CXR数据集样本量不足对深度学习效果的影响无法克服。
1.2 注意力机制
注意力机制是对人类认知功能的模拟,能从大量信息中快速筛选出高价值信息,在计算机视觉、自然语言处理、语音识别等领域得到广泛应用。注意力机制对输入信号的不同部分赋予不同权重,将可用资源偏向输入信号的信息丰富部分,抽取出关键和重要的信息,提升模型准确性和可解释性。计算机视觉中的注意力机制包括空间域、通道域、混合域3种。
JADERBERG et al[25]提出空间转换器模块,自动对图片中的空间域信息进行变换,提取关键特征。WANG et al[26]提出了非局部模块,通过计算特征图中空间点间的相关性矩阵生成有效注意力图,直接融合全局空间信息,而不需通过堆叠多个卷积层获取全局信息。
SE(Squeeze and Excitation)模块由HU et al[27]提出,通过构建通道间的相互依赖关系,重新校准通道间的特征响应,提高网络表达能力。WANG et al[28]在SENet基础上,提出一种不降维的局部跨信道交互策略和自适应选择一维卷积核大小方法,用于图像分类、目标检测和实例分割,提升了效率。
空间域忽略了通道域的信息,将每个通道的图片特征同等处理,使得空间域变换局限在原始图片特征提取阶段,应用在神经网络其他层的可解释性不强。通道域注意力对一个通道内的信息直接全局平均池化,忽略了通道内的局部信息。因此,WOO et al[29]将通道注意力和空间注意力结合,提出CBAM(convolutional block attention module)模块,提高CNN网络表达能力,强调和细化中间特征的内容和位置。LI et al[30]融合通道注意力和空间注意力,提出了SGE(spatial group-wise enhance)模块,将通道划分为组,组内通过空间注意力自主学习增强表征并抑制噪声。
1.3 深度图像分类
图像分类任务是计算机视觉领域的基础任务,深度学习促进图像分类研究的空前发展。SZEGEDY et al[31]提出GoogLeNet模型,即Inception v1模型,由Inception结构作为基本模块,用卷积对输入通道进行降维,减少参数量,用全局平均池化取代最后一层全连接。随后Inception v2[32]、Inception v3[33]、Inception v4[34]等模型相继被提出。HE et al[35]在VGG19基础上,提出ResNet模型,通过短路机制加入残差单元,解决深度学习的梯度消失等退化问题。XIE et al[36]通过融合ResNet模型的层次堆叠、残差连接设计策略,以及Inception模型的split transform merge网络体系结构,提出一种同质多分支结构模型ResNeXt,在ImageNet分类数据集的性能胜过ResNet-101/152、ResNet200、Inception-v3和Inception-ResNet-v2,101层的ResNeXt模型比ResNet200模型精度高,但复杂度仅为后者的50%.此外,ResNeXt模型与所有Inception系列模型相比,设计更简单。鉴于ResNeXt模型的简洁高效及其模块化设计策略和优异的分类性能,本文以ResNeXt模型作为基础模型。
2 实验数据集
本文使用WANG et al[18]于2020年搜集整理的COVIDx数据集,该数据集是目前可获取的新型冠状病毒肺炎病例数量最大的开放性基准数据集,包含来自13 870名患者的共15 475张具有临床代表性的胸部CXR图像,其中266例新型冠状病毒肺炎患者、5 538例非新型冠状病毒肺炎患者、8 066例未感染肺炎者(正常人),由5个公开可用数据集整合而成。包括:1) COVID-19 Image Data Collection[18]数据集的非新型冠状病毒肺炎病例和新型冠状病毒肺炎病例;2) COVID-19 Chest X-ray Dataset Initiative[37]数据集的新型冠状病毒肺炎病例;3) ActualMed COVID-19 Chest X-ray Dataset Initiative[38]数据集的新型冠状病毒肺炎病例;4) RSNA Pneumonia Detection Challenge dataset[39]数据集的无肺炎(即正常)和非新型冠状病毒肺炎病例;5) COVID-19 radiography database[40]数据集的新型冠状病毒肺炎病例。COVIDx数据集部分图像示例如图1所示,(a)-(e)列分别是上述5个数据集的3张CXR图像。COVIDx数据集不同感染类型的图像、患者数量分布如图2所示。
图1可见,COVIDx数据集来自5个不同数据集的图像亮度、角度和尺度等存在差异,样本存在多样性和广泛性。图2显示,COVID-19图像数量和患者数量与其他两类差别很大,存在严重的类别不平衡问题,给图像分类任务带来巨大挑战。

图2 COVIDx数据集中不同感染类型数据分布Fig.2 Data distribution of different infection types in the COVIDx dataset
3 模型与方法
3.1 注意力模块
注意力机制允许网络重新校准提取的特征,从而自适应地学习目标特征。获得ILSVRC 2017比赛冠军的SENet模型[27]的SE(squeeze and excitation)模块是一种典型的通道域注意力机制,通过Squeeze操作整合特征图不同通道的全局信息,然后利用Excitation模块为对应通道的特征加权,强化对任务有效的特征,弱化无效特征,实现特征通道的自适应校准。SENet和ResNeXt结合成为SE-ResNeXt模型[27]。本文采用SE-ResNeXt模型实现通道注意力。
残差注意力网络[41]由多个注意力模块堆叠而成,能够捕获不同类型和不同层次的注意力信息,不同模块的注意力感知特征随层数加深而自适应变化。本文的残差注意力模块使用文献[41]的注意力模块。需要注意的是,残差注意力网络涉及的通道注意力和SENet的通道注意力不同,SENet由全局平均池化获取通道间关系,与空间位置无关;残差注意力网络的注意力模块中每个位置点的权重既与本通道其他位置点相关,也与其他通道位置点相关,与空间相关。因此,受CBAM[29]顺序堆叠通道和空间注意力工作启发,本文融合多种类型注意力模块,以期提高对COVIDx数据集图像的分类效果。
3.2 维度降解模块
ResNeXt模型针对ImageNet图像分类任务,COVIDx数据集由多个开源数据集组合而成,各数据集,甚至同一数据集,图像大小不一,最大为4 757×5 623像素,最小为156×157像素。另外ImageNet图像分类的类别数为1 000,而COVIDx图像类别数为3.针对图像大小不一问题,本文统一将COVIDx图像调整为256×256,与ImageNet数据集的图像大小一致。针对图像类别差异悬殊,本文对原始ResNeXt模型进行了改进。
图3展示了原始ResNeXt模型,以及本文对ResNeXt模型的改进,图3(a)是原始ResNeXt模型,图3(b)是在原始ResNeXt模型上增加输入1 000维输出3维的全连接层,并将得到的模型训练COVIDx数据集,图3(c)是将维度降解模块插入ResNeXt模型后,训练COVIDx数据集的网络结构图。
图3(a)可见,输入图像为256×256×3,经过卷积层1,输出尺寸为112×112×64的特征图。图中卷积层2~5由多个图3(a)左侧虚线框中所示的残差块堆叠而成,残差块每层卷积的通道数不同,C1、C2、C3表示通道数。卷积层5输出的特征图经过全局平均池化(GAP),将特征图高度和宽度缩减为1,得到一个2 048维的向量。针对1 000类的ImageNet图像分类任务,全连接层将2 048维的向量转换为1 000维的向量。
图3(b)在图3(a)的全连接层后增加一个全连接层,将图3(a)输出的1 000维向量变换为3维,用于训练和分类COVIDx数据集样本。由于ImageNet和COVIDx两个数据集的类别数分别为1 000类和3类,图3(b)第二个全连接层的特征突降,可能导致特征提取不充分和信息丢失问题。
为此,提出了图4所示的维度降解模块,由3个子模块ConvBn2d组成,以充分提取图像特征。然后,丢弃图3(a)ResNeXt模型的全局平均池化和全连接层,添加图4的维度降解模块,接着是新的全局平均池化和全连接层,得到图3(c)网络模型,以训练和分类COVIDx图像。
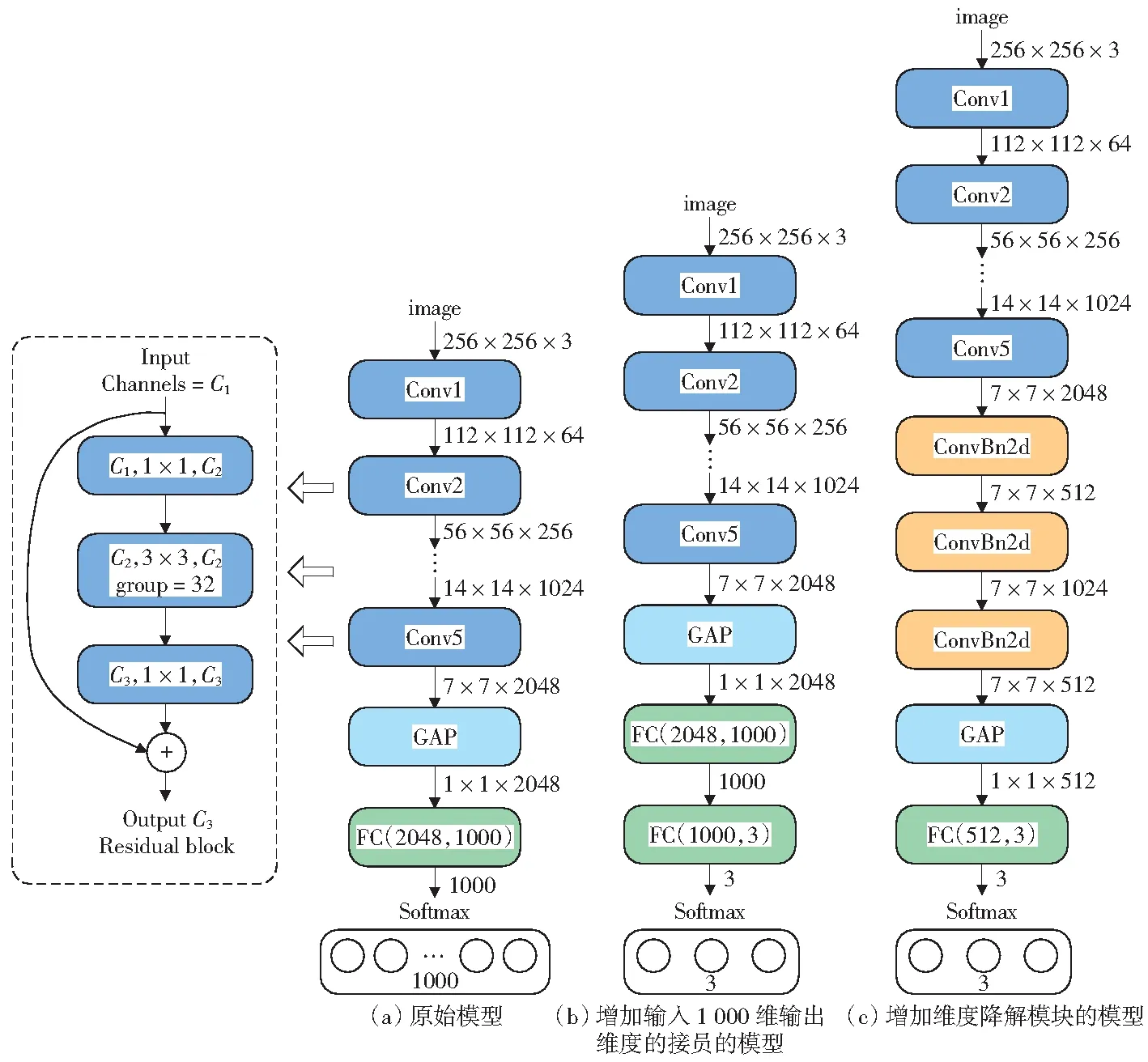
图3 ResNeXt网络结构及其改进Fig.3 Architecture of ResNeXt and our improvements
图4的ConvBn2d子模块包括不同参数设置的二维卷积层Conv、批归一化处理层BN和非线性激活操作Leaky ReLU,二维卷积层Conv调整特征图的通道数,并保持特征图分辨率不变,批归一化处理BN缓解网络中梯度消失问题,使模型训练更稳定,非线性激活函数采用渗漏型整流线性单元函数Leaky ReLU,参数值为0.1.图4维度降解模块的3个ConvBn2d子模块用于降低特征维度,具体过程为:输入7×7×2 048的特征图,经过卷积核大小为3×3的第一个ConvBn2d子模块后,输出7×7×512的特征图;然后经过卷积核大小为1×1的第二个ConvBn2d,输出特征图变为7×7×1 024;最后经过卷积核大小为3×3的第三个子模块ConvBn2d,输出特征图变为7×7×512.

图4 维度降解模块Fig.4 Dimension reduction module
图4的维度降解模块旨在改变ResNeXt模型,使其更好地适用于COVIDx数据集CXR图像的3分类任务,为此,需要尽可能降低最后输入全连接的特征图维度,同时保持特征的分辨能力,因此,设计了纺锤形的维度降解模块,维度降解模块结构的设计借鉴了MobileNetV2模型[42]中inverted residuals模块的纺锤形结构,通过扩展层(Expansion Layer)扩展维度,抵抗由于特征突降和非线性函数导致的信息丢失,保证模型提取到足够多的有用信息。第二个子模块ConvBnd的作用是通过更多的卷积核,弥补第一个子模块ConvBnd可能引起的信息丢失。
3.3 COVID-SERA-NeXt模型
通道注意力SE模块加入ResNeXt模型得到的SE-ResNeXt模型[27]是由一系列相同拓扑结构带有通道注意力的模块堆叠而成,用全局上下文对不同通道进行权值标定,调整通道依赖,然而,仅使用通道信息不能充分利用全局上下文抽取图像语义信息。
残差注意力模型[41]是由一系列残差注意力模块堆叠而成,不同模块的注意感知特征随着层数的加深而自适应变化,浅层注意力模块主要集中于图像背景,深层注意力模块则聚焦于待分类图像,深浅层多注意力模块增强了特征表达能力。得益于残差注意力模型的优异性能,本文在ResNeXt模型基础上,先加入交叉堆叠的通道注意力和残差注意力模块,再加入维度降解模块,提出COVID-SERA-NeXt模型,旨在通过融合更多类型的注意力模块,增强模型的特征表达能力和对不同类图像的区分能力,注意力交叉堆叠的优势补充,防止有效特征丢失,且每个类型的特征不会随着网络深度增加出现远程遗忘。值得说明的是,本文尝试了3种不同的模块组合方式:1) 先堆叠通道注意力模块,后堆叠残差注意力模块;2) 先堆叠残差注意力模块,后堆叠通道注意力模块;3) 通道注意力和残差注意力模块交叉堆叠。基于COVIDx数据集的实验表明,第三种方式能够实现对COVIDx图像的最好分类结果。
COVID-SERA-NeXt模型如图5所示,4个通道注意力和3个残差注意力交叉堆叠,随后是维度降解模块,通道注意力模块是黄色框的SE-ResNeXt模块,灰色虚线框表示残差注意力模块,3个浅蓝色ConBn2d构成维度降解模块。表1是模型结构细节与具体参数。

图5 本文提出的COVID-SERA-NeXt模型架构Fig.5 Architecture of our proposed COVID-SERA-NeXt model

表1 提出的COVID-SERA-NeXt模型结构细节Table 1 Details of the proposed COVID-SERA-NeXt model for COVIDx dataset
3.4 模型预训练
预训练能提供更好的模型初始化,增强模型泛化能力,加速任务模型收敛速度和提升模型性能。深度学习模型通常采用预训练-微调模式,预训练通常在具有大量标签的大规模基准数据集下(如ImageNet)进行;然后对预训练网络针对目标任务进行微调训练,预训练数据集通常比目标任务数据集样本量大很多。预训练可帮助模型学习通用特征,用于目标任务。ImageNet是深度学习预训练模型最常用的数据集,鉴于ImageNet自然场景图像和COVID-19 CXR医学图像的巨大差异,本文选择与COVID-19 CXR图像数据相似度更高的ChestX-ray8数据集预训练提出的COVID-SERA-NeXt模型。
ChestX-ray8是一个胸部X射线图像CXR数据集,用于多标签分类与检测,包含来自32 717个患者的108 948张正面CXR图像,每张图像代表一种或者多种疾病或者正常。数据集包含8种常见胸腔疾病:肺不张(Atelectasis)、心脏肥大(Cardiomegaly)、积液(Effusion)、肿块(Infiltration)、结节(Mass)、肺炎(Pneumonia)和气胸(Pneumathorax).
使用ChestX-ray8数据集对本文提出的COVID-SERA-NeXt模型进行预训练,保存最优模型,使用COVIDx数据集微调模型参数。带有预训练和微调的COVID-SERA-NeXt模型如图6所示。

图6 采用ChestX-ray8预训练和COVIDx微调的COVID-SERA-NeXt模型Fig.6 COVID-SERA-NeXt model with pre-training by ChestX-ray8 and fine-tuning by COVIDx
4 实验结果与分析
本文实验操作系统为Ubuntu 16.04,在单个型号为NVIDIA GeForce RTX 2080 GPU上训练模型。基于PyTorch 1.4.0深度学习框架构建分类网络,CUDA版本为9.0.使用Adam优化器更新网络模型权重,初始学习率为0.0001,学习率衰减值为0.001,β1参数为0.9,β2参数为0.99.使用交叉熵损失函数,batch size为32,最大训练次数为30,保留最优结果模型。按照COVID-Net提供的数据划分脚本划分训练集和测试集,训练集包含13 918张图像,测试集包含1 579张图像。实验每训练一轮,在测试集上测试结果,保留最优测试结果。
COVIDx数据集的3个类别Normal、Pneumonia、COVID-19存在类别不平衡。处理类别不平衡问题的欠采样、过采样或数据增强会改变数据类别分布,且过采样会导致过拟合问题,本文采用阈值调整方法缓解类别不平衡问题,在损失函数中给样本不足类别赋以较大权重,以弥补类别不平衡问题,Normal、Pneumonia、COVID-19等3个类别的损失函数权重分别为0.05,0.05,1.00.
使用准确率(Accuracy)、宏召回率(Macro-Recall)、宏精确率(Macro-Precision)、宏F1值(Macro-F1)4种评价指标评估模型有效性。各指标定义为式(1)-(4).
(1)
(2)
(3)
(4)
式中:Nrec表示正确预测的样本数,Nall表示样本总数;式(2)-(4)分别表示Macro-Recall、Macro-Precision、Macro-F1,其中n表示类别数,Ri、Pi为一对其余策略下,第i类的召回率和精确率。
可视化是解释实验结果的重要手段。将其引入新冠肺炎CXR图像分类,不仅可以更深入地了解与新冠肺炎阳性病例相关的关键因素,帮助临床医生进行更好筛查诊断,还可验证模型是根据图像哪些信息做出的决策。CAM、Grad-CAM、Grad-CAM++是计算机视觉领域实验结果可视化的重要技术,由于Grad-CAM不需要重新训练模型且准确度高,本文使用Grad-CAM对实验结果进行可视化解释,以类激活图方式展示模型通过哪些像素判定图像类别。
4.1 数据增强测试
数据增强用于增加训练数据,常用的数据增强技术包括裁剪、填充、翻转等,从不同视角刻画同一图像,提高训练模型的准确性和学习能力。本文仅对训练集图像进行增强,测试集图像是没有增强的原始图像,增强方式为线上增强,将数据送入学习模型时,进行小批量扰动处理并保留关键语义内容,从而使得对每一轮训练数据,模型将“看到”完全不同的数据集,避免网络记忆训练数据,提高模型泛化能力。这种方式增强了数据多样性,但未显式增加数据集图像数量。
实验采用的数据增强策略包括:水平翻转、垂直翻转、随机仿射变换、色彩抖动。分别以0.5概率进行以上图像变换。以Accuracy、Macro-Recall指标验证数据增强对提出的COVID-SERA-NeXt模型性能的影响,实验结果如图7所示。

图7 数据增强对模型性能的影响Fig.7 Influence on model performance from data augmentation
图7结果显示,同时使用翻转、仿射变换、色彩抖动3种数据增强提高了COVID-SERA-NeXt模型的性能,表明数据增强对COVIDx数据集图像分类很有效。另外,图7实验结果还显示,无论采用3种数据增强方式的哪种方式增加数据,COVID-SERA-NeXt模型的准确率都有不同程度的提高,但模型的宏召回率Macro-Recall都或多或少低于没有使用数据增强时的模型宏召回率,只有3种数据增强方式联合使用时,模型的宏召回率才得到提升,同时准确率得到大幅提升。
4.2 消融实验
为了分析不同模块对模型性能的影响,本文设计了不同的消融实验,验证维度降解模块、通道注意力模块和残差注意力模块的性能。实验结果见表2,所有实验在相同环境下进行,表中加粗数字表示最优结果。

表2 各模块对ResNeXt模型的影响测试Table 2 Experiment results of adding different modules to ResNeXt %
表2消融实验结果可见,维度降解模块、通道注意力模块和残差注意力模块三模块的任何两个组合,都可以使ResNeXt模型的性能在一定程度上得到提升。全部三模块组合能使ResNeXt模型对COVIDx数据集的分类准确率达到96.11%.由此可见,在ResNeXt模型基础上,先加入交叉堆叠的通道注意力和残差注意力模块,再加入提出的维度降解模块,即本文COVID-SERA-NeXt模型对COVIDx数据集分类准确率最好。
4.3 不同模型性能比较
不同基础模型、不同训练策略会影响模型性能,本小节将比较基准模型COVID-Net[18]、CNN-GP[19]、Modified MobileNet[20]和ResNeXt[36],与本文COVID-SERA-NeXt模型和采用ChestX-ray8预训练的COVID-SERA-NeXt模型的性能,实验结果如表3所示,加粗表示最优结果。需要说明的是,表中“-”表示原始模型CNN-GP和Modified MobileNet没有相应评价指标的值。另外, CNN-GP和Modified mobileNet模型的准确率(Accuracy)来自原始文献,COVID-Net和ResNeXt的实验结果是在本文实验环境下运行的结果,因为COVID-Net原文献使用的评价指标是评价模型在单个子类的性能,本文使用的评价指标评价模型对3个子类的平均性能;ResNeXt模型没有在COVIDx数据集测试过。因此,这两个模型被重新运行。

表3 各模型性能的比较Table 3 Performance comparison of different models %
表3实验结果显示,采用ChestX-ray8数据集预训练的COVID-SERA-ResNeXt模型在各项指标均取得最优值,没有预训练的COVID-SERA-ResNeXt模型比基础模型ResNeXt在准确率、宏调和指数F1和宏召回率Macro-Recall均有提升,但在宏精度指标Macro-Precision上略次于ResNeXt模型;然而COVID-SERA-ResNeXt模型在各项指标上均远优于最早用于COVIDx数据集分类的COVID-Net模型;同时,COVID-SERA-ResNeXt模型的准确率Accuracy也优于CNN-GP模型和Modified MobileNet模型。
由此可见,本文提出的用于COVID-19 CXR图像分类的COVID-SERA-ResNeXt模型非常有效,使用ChestX-ray8数据集进行预训练,可以进一步提升模型的性能。
4.4 结果可视化
使用Grad-CAM对模型COVID-SERA-ResNeXt的实验结果进行可视化,采用类激活图展示模型通过哪些像素判定图像类别。图8展示了部分测试图像的类激活图, (a)列分别为Normal、Pneumonia、COVID-19类别的一个有代表性的原始图像,(b)-(i)列展示了不同模型对(a)列3张CXR图像学习的结果。色调越冷区域对模型分类结果的影响越大。
从图8各模型实验结果的类激活图可见,本文提出的COVID-SERA-ResNeXt模型提取的分类特征主要位于CXR图像的胸部或胸部感染区域,有较强的分类识别能力。带有通道注意力模块的ResNeXt模型(f)提取的特征最差,接着是(d)带有残差注意力模块的ResNeXt模型和(h)带有通道注意力和残差注意力的ResNeXt模型。
图8实验结果还显示带有本文维度降解模块的模型(c)ResNeXt+维度降解模块、(e)ResNeXt+维度降解模块+残差注意力模块、(g)ResNeXt+通道注意力模块+维度降解模块和(i)ResNeXt+通道注意力+残差注意力+维度降解模块(即本文提出的COVID-SERA-ResNeXt模型)的特征提取能力更强,提取的特征均集中在CXR图像的胸部或胸部感染区域。说明提出的特征降解模块对于提取具有强分类意义的特征很重要。
另外,对于拍摄位置不规范、存在残影、前后景区分不明显的CXR图像,如图8第二行的Pneumonia CXR图像,本文提出的COVID-SERA-ResNeXt模型依然能够准确提取胸部感染区域的特征。
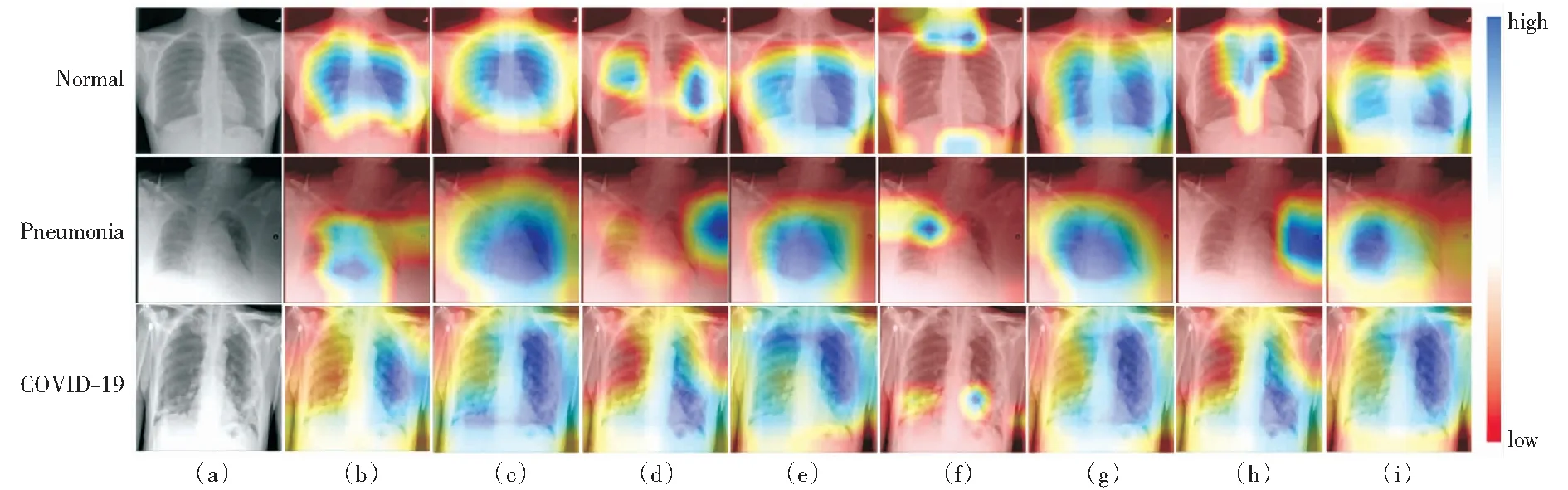
(a)原图; (b) ResNeXt模型; (c) ResNeXt+维度降解模块; (d) ResNeXt+残差注意力模块; (e) ResNeXt+维度降解模块+残差注意力模块; (f) ResNeXt+通道注意力模块; (g) ResNeXt+通道注意力模块+维度降解模块; (h) ResNeXt+通道注意力+残差注意力; (i) ResNeXt+通道注意力+残差注意力+维度降解模块(本文COVID-SERA-ResNeXt模块)图8 各模型的类激活图Fig.8 Class activation graphs of different models
5 结论
提出了针对COVID-19 CXR图像分类的COVID-SERA-NeXt模型。在公开访问数据集COVIDx的实验结果验证了COVID-SERA-NeXt模型在多项指标上优于基础模型ResNeXt,准确率、宏召回率分别达到96.11%、95.46%.ChestX-ray8数据集预训练的COVID-SERA-NeXt模型对COVIDx数据集的分类性能更优,在准确率、宏召回率、宏精确率和宏F1各项指标均达到最优。然而,如何克服残影、前后景区分不明显等图像模糊对模型分类性能的影响仍需要进一步研究。
猜你喜欢
成都信息工程大学学报(2022年2期)2022-06-14
当代陕西(2022年4期)2022-04-19
心理学报(2022年4期)2022-04-12
小雪花·成长指南(2022年1期)2022-04-09
北京大学学报(自然科学版)(2022年1期)2022-02-21
当代陕西(2020年22期)2021-01-18
中华诗词(2019年7期)2019-11-25
第二课堂(课外活动版)(2016年2期)2016-10-21
吐鲁番(2014年2期)2014-02-28
中学英语之友·高一版(2008年10期)2008-12-11
