
数据库模式的主动在线匹配方法
2022-01-25 06:49陈又咏黄双双
现代电子技术 2022年1期
庄 莉,陈又咏,黄双双,丁 阳,张 照
(1.福建亿榕信息技术有限公司,福建 福州 350003;2.西安交通大学 电子与信息学部,陕西 西安 710049;3.北京国网信通埃森哲信息技术有限公司,北京 102211;4.北京中电普华信息技术有限公司,北京 102211)
0 引 言
长期以来,我国数据库管理系统的市场主要被国外数据库厂商占据。这种状况既不利于我国信息产业的安全,更威胁我国基础信息设施的可控权。为实现关键信息技术自主可控,研发并推广应用国产数据库管理系统,已成为我国信创产业发展的战略性任务之一。
为紧跟国家战略、推动信创生态体系建设,当前国产数据库迎来蓬勃发展时期,一大批优秀的国产数据库产品迅猛发展。虽然我国各机构在信息化办公过程中逐步采用国产数据库进行信息管理,但由于信息系统规模大、业务复杂性高,数据呈现出分布、海量、异构等特点,且大量历史数据通常同时使用国外数据库平台存储。在这种条件下,为了实现数据从国外数据库到国产数据库的转移,有数据转移需求的数据库使用者需要完成数据跨库迁移工作。因此,当前的重要任务是实现数据从国外数据库到国产数据库的迁移。
模式匹配是实现数据迁移任务的一项关键技术。图1是一个模式匹配的示例,若要将源数据库中的数据转移到目标数据库中,需要对数据库的子模式和字段分别建立匹配关系。图1中源模式的项目信息子模式和目标模式的交易信息模式建立匹配关系,源模式的单位信息子模式需要与目标模式的单位信息子模式建立映射关系,建立映射的子模式的各个字段也需要建立映射关系。要将源数据库中的数据转换到目标数据库中,需要建立源数据库子模式到目标数据库子模式的联系,以及源数据库模式字段和目标数据库模式字段之间的联系。

图1 模式匹配示例
现有研究一般使用批量学习实现数据库的自动模式匹配,但在实际应用场景下,模式匹配任务具有时间顺序性和经验积累增量性,批量学习进行模式匹配缺乏经验累积学习的能力。本文提出将集成学习与增量式贝叶斯思想用于模式匹配,利用在模式匹配过程中已得到的匹配模式对优化模式的匹配算法,通过扩大训练集规模提高分类准确率。
1 相关工作
目前有关自动数据库模式匹配的研究基于匹配知识的不同主要分为两类:数据库结构层级的匹配和实例层级的匹配。
结构层级的数据库模式匹配利用模式字段名称、字段类型、字段描述等模式级信息结构相似程度进行模式匹配。如文献[3]利用模式映射的元映射以及模式名称特征重用现有的模式映射,将元映射存储在可搜索的存储库中,并建立索引以进行快速检索。文献[4]使用图匹配的思想提出一种简单的结构算法用于模式匹配。
实例层级的模式匹配通过判别数据的分布、统计特性、数据相关性等数据库实例级信息的相似程度进行模式匹配。文献[5]提出的统计数据模式中属性列的概率分布,依据概率分布评估属性列之间的相似性。文献[6]提出了基于互信息的非透明列值数据模式匹配方法,能够在不透明的列名和数据值的情况下实现数据库的模式匹配。
本文针对现有模式匹配方法存在的主要问题,通过对现存模式匹配信息的学习,能够减少人工标定样本的工作量,在后续的增量模式匹配中提供完备的匹配信息。本文提出将集成学习与增量式贝叶斯思想用于模式匹配,利用在模式匹配过程中已经得到的模式匹配关联关系对模式匹配算法进行优化。
2 动态模式匹配方法
2.1 方法概述
本文提出的动态数据库模式匹配算法如图2所示(其中,为当前子模式分类后验概率,为主动选择的置信度阈值),分为初始模型训练、模式分类、分类结果主动选择、增量学习四个部分。初始模型训练利用已有少量模式训练集训练一个初始模式匹配分类模型,用于后期增量学习过程中的模式分类;模式分类使用初始模式匹配分类器对增量集中没有模式标签的未知模式分类;分类结果主动选择部分对增量集中的子模式样本进行筛选,选择最有利于提高分类器性能的实例加入训练集;增量学习将满足主动选择筛选条件的实例以及主动在线模式匹配算法赋予该实例的模式标签加入反馈集中,使用增量学习的思想再次训练分类模型。

图2 动态数据库模式匹配算法
本节提出利用朴素贝叶斯和随机森林模型实现对模式进行增量分类的算法,并详细地介绍了子模式特征表示方法和主动在线模式匹配算法设计。
2.2 子模式特征表示方法
朴素贝叶斯分类方法一般使用多维特征向量表示数据样本。数据库子模式信息包括名称、类型、属性描述等内容,这些描述信息不易组织成维向量。因此,在提取子模式特征时将参考文献[8]提出的模式特征表示方法,将多种描述信息组合成短文本,并对其进行修改以适用于本文中的模式匹配场景。将子模式用文本表示后可使用TF⁃IDF生成子模式的特征向量,在本文中,子模式的单个信息出现频率SF可以表示为:
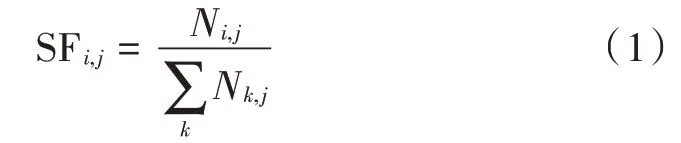
式中:SF 表示子模式的信息在子模式S 中的信息频率;N 表示子模式的信息在子模式S 中的出现次数;分母表示子模式S 所有信息总数。子模式单个信息的逆向模式频率ISF 表示为:

式中:||表示子模式的总数;|{:N ∈S }|表示含有信息的子模式个数。由于本文将子模式各个字段的信息组织成文本,故可以采用此方法提取每个子模式的特征,经TF⁃IDF处理后可以得到一个能够表示子模式特征的稀疏矩阵,作为主动在线模式匹配算法的输入。
2.3 主动在线模式匹配算法设计
本文选用朴素贝叶斯模型和随机森林模型实现子模式的增量匹配。数据库模式的贝叶斯分类是根据训练数据库子模式的类先验概率和类条件概率,预测子模式是否属于某一数据库模式类别。在当前模式匹配场景下,仅使用初始少量标定子模式训练集显然是片面且不合理的,需要使模式匹配的模式训练集随着模型训练逐渐更完备,从而优化数据库模式匹配分类器。在数据库模式匹配过程中使用增量学习可以解决此矛盾。挑选测试过程中的模式匹配实例,重新作为模式匹配的训练集,顺应数据增长变化趋势,从而优化匹配效果。
本文模式匹配增量方法假设为随机变量,是先验信息。如果有新增模式匹配样本加入,计算(|,)的公式如下:

由上式可见,随着样本的加入,先验信息由(|)变为(|,),先验信息是贝叶斯增量学习模型的基础。在增量模式匹配过程中,当新的子模式到来,之前的子模式匹配信息可以作为模型训练的新样本,这种迭代训练方法利用测试子模式实例信息,是一个逐渐改进先前模式匹配模型的增量过程。
子模式增量学习模型构建的伪代码如算法1所示。假定子模式类别为={,,…,C },子模式特征向量为F ={, ,…, },是特征数量,子模式类别的先验概率(C )抽象为参数θ,特征的类条件概率(q | C )抽象为参数θ 。参数θ和θ 的值为:

式中:| |表示训练集中类别C 的训练子模式数量;||表示子模式类别总数;||为子模式总数;| ,C |表示子模式类别C 的特征q 的频率;||表示子模式中特征q 出现的频率。
根据θ和θ 可以得到子模式朴素贝叶斯分类器的初始分类模型NBM:

子模式增量修正模型是对子模式增量集中的实例选择,根据新增子模式调整模型参数的动态过程,θ和θ 增量调整为:

具体算法流程如算法1所示。
算法1:主动在线模式匹配算法
输入:模式匹配初始训练集,模式匹配增量集,模式匹配反馈集,模式匹配置信度阈值
输出:模式匹配分类模型
1:function OBSMMODEL(,,,)
2:←length()
3:NBM←InitialBayesTrain()
4:RFM←InitialRFTrain()
5:while<=do
6: if RFM([])==NBM([])then
7: if P_voting(RFM([]))>then
8:←+[]
9: end if
10: end if
11:end while
12:NBM←IncreBayesTrain(NBM,)
13:return NBM
14:end function
基于增量学习进行子模式匹配算法,其要点是从大量子模式样本中选择最适合模式匹配模型的模式实例,加入模式匹配训练集,从而达到优化子模式分类器分类性能的目的。通常有两种实例选择方法:被动选择方法和主动选择方法。
数据库模式匹配模型增量训练过程中,被动选择策略对测试子模式实例的选择具有随机性,该策略下,模式匹配模型会被动地接收新信息。但是在模式匹配过程中使用被动选择策略不适用于本文的模式匹配场景,在动态修正模式匹配的过程中,被动选择策略就表现出明显的不足,因为按照某一种单一没有依据的筛选规则会使学习的分类器具有顺序相关性,使得模式匹配模型对数据较为敏感。此外,如模式匹配过程中遇到噪音数据,这种噪音持续下去会严重影响模式匹配结果。
相较而言,在本文的场景下采用主动选择策略对子模式实例的选择具有可控性,该策略会选择最有利于子模式分类器性能提高的测试子模式实例,更智能也更适用于本文中的模式匹配场景。
本文主动选择使用集成学习的思想主动选择样本。具体地,本文使用随机森林算法对增量集中的样本进行分类,能够得到当前随机森林中每一棵决策树的分类结果,多个学习器的集成结果和投票分类结果更具有说服力,能够和朴素贝叶斯的分类结果相互验证。
其中,子模式增量集中的单个子模式样本的主动选择过程如图3所示,本文将子模式增量集中的样本实例输入具有多棵决策树的随机森林中,每一棵决策树的分类结果用T ()(1≤≤)表示,经过决策树投票,可以得出每种子模式类别C (1≤≤)的投票计数为(C ),则每个类别C 的投票占比可以表示为:

图3 主动在线模式匹配算法主动选择策略

计算每个类别的投票占比后选择投票占比最高的类别满足以下条件:

作为多棵决策树的子模式分类类别,把投票占比()作为该类别的置信度,如果与初始贝叶斯模式分类模型的分类结果Bayes()的结果一致且置信度满足阈值要求,即:

将子模式样本实例以及对应分类标签(,)加入子模式增量集中,完成单个样本的主动选择。
3 实验结果
3.1 实验数据和方法
本文实验需使用中文异构数据库的迁移数据测试本文中的增量贝叶斯模式匹配模型,但由于目前没有适用于本文的公开中文异构数据库迁移数据集,本文选用公开中文文本分类sms数据集,对该数据集进行改造,经改造的数据集与本文所需的国产数据库迁移数据逻辑等价。实验数据信息如表1所示,在实验过程中,将数据集划分成模式匹配初始训练集、模式匹配增量集、模式匹配测试集。

表1 实验数据集
本文中模式匹配的目标是寻找源数据库子模式和目标数据库子模式的匹配关系,为验证动态模式匹配方案的有效性,分别使用批量学习和主动在线模式匹配算法使用相同初始训练集训练模型。此外,本文将模式匹配增量集划分为10等份用于观察本文所提方法随模式匹配增量学习的表现,使用同一测试集评估模式匹配模型的匹配效能。最后,为观察本文所提方法对于置信度阈值的敏感性,通过设置多种阈值,记录本文方法在不同置信度阈值时的模式匹配效能。
3.2 评估指标
为了评估匹配质量,采用以下三个通用指标:
1)准确率:子模式测试实例中正确分类的数量占测试子模式实例总数的比例。计算公式为:

2)召回率:被正确分类的子模式正例个数占实际正例个数的比例。计算公式为:

3)全面性:
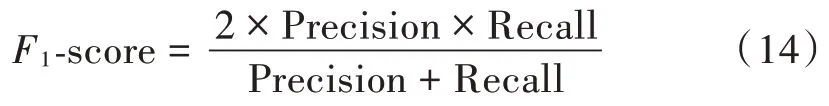
3.3 实验结果与分析
图4为使用批量模式匹配算法和主动在线模式匹配算法在相同数据集上的模式匹配对比。

图4 批量模式匹配与主动在线模式匹配对比
其中,批量模式匹配算法包括决策树模式匹配算法、KNN模式匹配算法、批量贝叶斯模式匹配算法。相较于传统的批量模式匹配方法,本文提出的动态模式分类匹配方法将模式匹配全面性提高了5%~33%。表2为本实验中各类子模式的匹配情况。实验结果显示,各类别使用动态模式匹配方法表现明显优于传统方法。
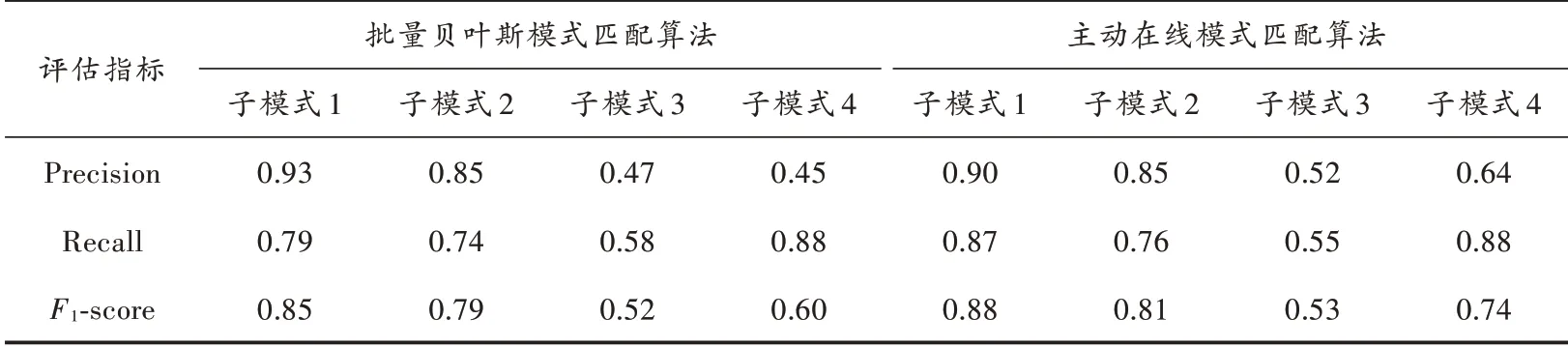
表2 批量贝叶斯模式匹配与主动在线模式匹配算法效果详细对比
此外,为测试本文所提主动在线模式匹配算法在经验累积过程中的模式匹配效能,将子模式增量集划分为10等份,每次增量训练的数据为增量集的1 10,主动在线模式匹配算法增量学习表现如图5所示。

图5 主动在线模式匹配算法增量学习表现
根据图5可知,在模式匹配信息增量的累积过程中,主动在线模式匹配算法增量学习表现总体呈上升趋势。预计随着模式匹配信息不断增加,匹配效能将会不断上升。
在使用模式匹配主动选择策略时,模式匹配置信度的阈值设定是影响模式匹配效果的重要因素。为观察不同模式匹配置信度阈值对主动在线增量学习的影响,本实验设定不同的模式匹配置信度阈值,在同一模式匹配测试集上测试。
本实验测试的主动在线模式匹配算法对置信度阈值的敏感情况如图6所示,不同的模式匹配置信度概率阈值的设定对算法的效果有所影响。

图6 置信度阈值敏感分析
图6中主动在线模式匹配算法在部分模式匹配置信度阈值的表现呈现平台趋势,是因为部分增量集中的样本在一定模式匹配阈值范围内没有满足条件的样本。在针对不同的应用场景时,需要根据增量模型的测试指标反向调整模式匹配置信度阈值。
4 结 论
本文介绍了一种主动在线的模式匹配方法,能够有效减少模式匹配算法的搜索空间,并且相比传统的复杂模式匹配算法,本文方法能够充分利用已有模式匹配信息,为后续模式匹配提供更完备的匹配知识。在未来,本研究将准确定位源模式中子模式和目标子模式的匹配关系,并且把子模式匹配和子模式字段匹配有效结合,从而实现一套完整的模式匹配体系。
猜你喜欢
当代陕西(2022年6期)2022-04-19
核科学与工程(2021年4期)2022-01-12
电子制作(2019年13期)2020-01-14
中学生数理化·中考版(2019年9期)2019-11-25
移动信息(2018年1期)2018-12-28
中央民族大学学报(自然科学版)(2018年3期)2018-11-09
计算机应用(2018年5期)2018-07-25
电信科学(2016年9期)2016-06-15
山东工业技术(2015年21期)2015-07-27
轴承(2015年2期)2015-07-25
