
单区型物流配送中心订单分批与路径优化研究
2022-01-23 04:31莉ZHANGJuanLILi
物流科技 2022年1期
张 娟,李 莉ZHANG Juan, LI Li
(新疆农业大学交通与物流工程学院,新疆 乌鲁木齐 830000)
0 引 言
随着社会经济的快速发展,人们网购的数量直线增长,同时人们消费需求也向小批量、多品种转变,伴随着人们观念的转变,对物流业发展的要求也愈发的严格。尤其是对货物的分拣工作,这是最耗时同时也是物流成本占据较大的环节,因此如何选择快速、高效、准确的拣货方式已经成为物流配送中心急需解决的重大问题并且也是当前研究的重点之一。
在对订单分批的研究中,陈晓艳等把仓库拣选问题转换成TSP 问题,将蚁群算法、遗传算法、禁忌搜索算法、模拟退火算法进行对比研究,然后经过仿真对比,当订单量多时,蚁群算法的优化结果更好。徐宣国等采用系统聚类的方法研究了大批量情况下的订单分批过程,通过建立系数矩阵,对客户的订单进行聚类。胡小建等将Canopy 编程环境与聚类算法相结合,提出了基于两者结合的Canopy-k-means 算法,发现改进后的算法大大减少了拣选的批次,在很大程度上加快了拣选货物的效率。Zhang 等建立了有类别约束和无类别约束的JOBPRP 优化模型,并对种子算法进行了改进、采用新的种子添加规则和改进的近优路由方法对模型进行求解。李诗珍等建立了订单分批模型,基于相似系数对订单进行分批,通过启发式算法求解订单分批结果,根据模型得到了最短的拣选货物的路径。秦馨等研究的是“货到人”模式下的订单分批问题,比较了基于欧式距离的聚类算法、基于余弦相似性的聚类算法,先到先分批算法以及不分批算法四种算法下的拣选搬运次数,最后得到基于余弦相似性的聚类算法更加能够提高拣选效率。
本文主要研究的是单区型物流配送中心“人到货”工作场景中的静态订单,通过对订单之间的品项相似系数以及货位相似系数的计算,来作为对订单分批的依据,并且通过禁忌搜索算法来对研究的订单进行拣选路径的计算,进而比较两种算法在订单拣选过程中的优势和劣势,希望能为订单拣选工作提供新的方法。
1 模型构建
1.1 问题描述
本文主要研究的是某医药物流公司在一定的时间节点内到达的货物拣选订单,由于医药物品种类繁多且在疫情期间需求量大、时间紧急,因此对物品的拣选工作要更加以节省时间为主。若对到达的订单进行逐个拣选,则需要增加更多的劳动力,并且会浪费更多的时间,可能在货物拣选过程中造成拥堵的情况,在很大程度上增加了时间成本以及人力成本。因此在对订单进行拣选时需要对订单进行分批,并且尽可能多的减少拣选的路径,在一定程度上提高效率。
1.2 相似系数
在判断两个订单的相似程度时,可以通过对订单中品项的相似系数以及巷道相似系数进行计算,通常采用的是Jaccard 相似系数计算原理,即把每个订单都看作是一个集合,定义为用集合的交集比上集合的并集,公式如下:

则订单品项相似系数=相同的货物品项数/总货物品项数,巷道相似系数=共同巷道数/总巷道数。
1.3 订单分批问题的聚类模型
根据上面的分析,将订单分批和拣选路径结合起来,建立两阶段的订单分批模型,第一阶段为以订单相似系数最大为依据,先对订单进行分批,第二阶段为分批订单之间的拣选路径最短,对货物进行拣选。
为了构建模型的方便,所用到的符号及定义如表1 所示。
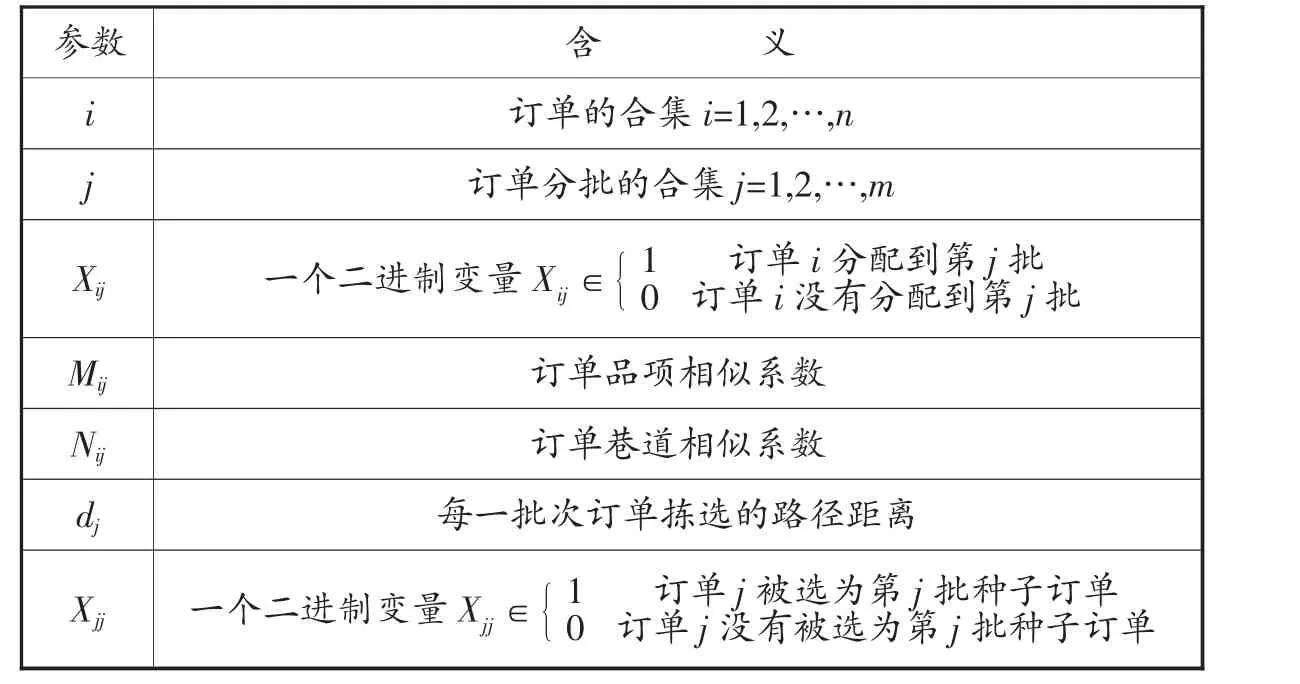
表1 参数定义

目标函数式(1) 表示形成分批的订单中,同一批次中的订单的品项相似系数和巷道相似系数之和为最大,并且分批订单的拣选路径为最短。约束条件式(2) 表示一个订单只能对应一个批次,不能重复分批。约束条件式(3) 表示只有当拣选路径存在即第j 批订单时,订单i 才分配到第j 批。本模型暂不考虑拣货车的容积和重量问题,因此不设对于此的约束条件。
2 聚类算法
2.1 聚类分析概念
聚类分析是对事物按照一定的规则进行分类的算法,它又称群算法。它是对事先已经获得的数据,按照一定的规则,将数据分类到不同的类或者簇这样的一个过程,类和簇就相当于是一个相似数据的集合。采用聚类的思想对订单进行分批是为了最小化拣取所有订单的行走距离,从而加快货物的拣选速度,减少人力劳动成本。
2.2 聚类结果分析
本文随机选取了某医药物流公司某天的12 张订单,对这12 张订单的品项相似系数和巷道相似系数进行计算,得到品项相似系数和巷道相似系数之和,结果如表2 所示。通过对品项相似系数和巷道相似系数之和进行计算,采用聚类算法,对订单进行分批,结果如图1 所示。

图1 订单分批结果

表2 相似系数结果表
本文选用8 巷道的单区型仓库作为研究对象,仓库为长方形,仓库的出入口位于仓库的左上角和左下角,仓库布局图如下,假设货架宽1 个单位,每个货格长1 个单位,巷道宽2 个单位,图2 中黑格表示货物存放的位置,拣选路径都采用“S型”和“中点返回”拣选策略,对订单进行分批后,以第一批订单为例,其拣选路径如图2 所示,总拣选路径为L=82 米,三批订单总的拣选路径L=230 米。

图2 订单拣选路径
3 禁忌搜索算法
3.1 禁忌搜索算法步骤
禁忌(Tabu Search) 算法是一种随机搜索算法,它可以避免产生局部最优的情况,在运用禁忌搜索算法求解路径优化问题时,通常将问题转化为求解TSP 问题,具体计算步骤如下:
Step1:将订单中的各个品项所在的巷道数和层数在直角坐标系中用XY 轴表示出来,这样就将订单拣选问题转换成TSP 旅行商问题,在本文中,所有订单总共有90 个品项,因此对应90 个二维坐标,这样就把问题转换成遍历90 个地方所需的最短路径问题;
Step2:产生任意两个城市的间隔矩阵,并初始化禁忌表并确定禁忌表长度。产生一个90*90 的零矩阵,作为初始禁忌表,确定禁忌表的长度,公式为(N* (N- 1 )/2 )^0.5;
Step3:设置候选集的个数为200,存放于一个新的集合中,初始化拣选货位,随机生成初始解,设置迭代次数G 为1 000次;
Step4:进行禁忌搜索循环计算,判断是否满足收敛准则,即如果参数p>G,则停止运算,输出结果,反之转Step5;
Step5:在初始解的邻域内进行搜索产生新的候选解,求交换的货位矩阵,生成邻域解,选择最好邻域解并判断是否满足藐视准则,若满足,则转Step6,若不满足,则判断候选解的属性,转Step7;
Step6:将该邻域解作为当前解,并将此解移动列入禁忌表中,禁忌表向前移动,将最初进入禁忌表的邻域解移出禁忌表,不断地更新禁忌表,转Step4 继续进行计算;
Step7:将非禁忌对象对应的最优解作为当前解,并列入禁忌表中,禁忌表向前移动,将最初进入禁忌表的候选解移出禁忌表,转Step4 继续进行计算;
Step8:求解结束,输出当前的最短路径以及适应函数曲线。
3.2 结果分析
参数设置完毕后,经MATLAB R2015b 仿真研究,获得最短路径和适应度进化曲线。其中路径距离中的点代表货点的位置,适应度进化曲线的横坐标代表算法的迭代次数,在计算过程中,设置迭代次数为1 000 次,纵坐标代表目标函数值,可以看出目标函数值由最初的350 米经过不断的迭代最后变为82 米。根据MATLAB 仿真得到数据结果如图3、图4 所示。
将两种算法进行对比,如表3 所示。
从表3 可以看出,订单相似系数的聚类算法下,总的拣选路径为230 米,禁忌搜索算法下的拣选路径为82 米,可以看出禁忌搜索算法是将所有的订单当作一批进行拣选,而在订单不分批情况下,拣选路径长度为763 米,可以看出大大提高了拣选的路径,前后优化了64%左右,但在进行计算时,禁忌搜索算法的工作量大,迭代次数较多,在实际工作之中,订单相似系数的聚类算法速度更快,计算方法也更加简便。
4 结束语
本文在当前社会面临的大背景下,通过对医药物流的研究,基于“人到货”模式下,以单区型物流配送中心为研究对象,根据仓储系统拣货操作实际情况,以优化拣货路径为目的建立了基于订单相似系数的两阶段聚类算法模型,通过对订单进行分批,计算订单拣选路径,又通过禁忌搜索算法来计算订单拣选路径,经MATLAB 仿真研究,得到禁忌搜索算法的优化最短距离和适应度曲线。通过对比得到禁忌搜索算法的优化路径远远大于订单相似系数的聚类算法的优化路径。

图3 禁忌搜索算法最短路径图

图4 适应度进化曲线
猜你喜欢
今日农业(2022年4期)2022-11-16
中国石油石化(2021年9期)2021-03-30
烟台大学学报(自然科学与工程版)(2021年1期)2021-03-19
矿产勘查(2020年9期)2020-12-25
当代陕西(2018年9期)2018-08-29
江西煤炭科技(2015年1期)2015-11-07
电测与仪表(2015年15期)2015-04-12
河北科技大学学报(2015年5期)2015-03-11
山西焦煤科技(2015年7期)2015-02-28
创业家(2015年6期)2015-02-27
