
3D多重注意力机制下的行为识别
2022-01-21 07:35吴丽君李斌斌陈志聪林培杰程树英
福州大学学报(自然科学版) 2022年1期
吴丽君,李斌斌,陈志聪,林培杰,程树英
(福州大学物理与信息工程学院, 福建 福州 350108)
0 引言
人的行为识别是视频分析中一个备受关注和具有挑战性的研究课题.相比于图片,视频存在更多的时间信息及多帧之间的关联性,且数据量庞大.因此,用于视频的人的行为识别模型需能提取时间关联信息,且需兼顾处理速度.
近几年,深度卷积网络对图像的处理能力得以飞速提升.大量CNN结构被提出,如GoogLeNet、DenseNet、ResNet、VGG等[1-3]二维卷积神经网络,在单张图像特征的提取上取得良好性能.然而,二维卷积神经网络难以提取视频中的时间信息且难以关注图像中的重点空间信息.针对第一个问题,Tran等[4]提出三维卷积神经网络(3D CNN),利用三维卷积和三维池化操作来兼顾视频中的时间信息的处理,ResNet和GoogLeNet等二维卷积网络在后续也有三维结构的版本[5-8];针对第二个问题,一些注意力机制[9, 10]被提出,这些模块都有一个共同的特性,就是能够帮助二维卷积网络更加关注一张图像当中的重点信息.其中,Woo等[11]提出的一种卷积块注意模块(convolutional block attention module, CBAM),分为通道和空间两个子模块,以分别关注图像中重点信息“是什么”以及“在哪里”.
视频不仅包含着单帧的信息,还有帧与帧之间的关联信息,因此现有的二维的注意力机制难以在三维的数据及相应的三维卷积网络上进行部署.Wang等[9]认为卷积的操作只考虑了局部区域,而丢失了全局的联系,提出一种非局部网络,其非局部操作对空间中所有位置取加权平均值,以表示图像中某个位置的响应.此结构不仅能在同一张图像中建立某一个像素与其他任意像素点的联系,也能针对视频建立不同帧之间像素点的联系,从而为后面的层提供一些更丰富的信息.然而该结构涉及到矩阵点乘的操作导致在三维任务中产生大量参数,计算量庞大.
基于此,本文提出一种多重注意力机制,可用于提升3D卷积网络的性能.由于3D ResNet计算简单、效率高、能解决梯度消失等优点,因此选择3D ResNet[5]作为基础网络.多重注意力机制结构简单紧凑,能够无缝适用于3D卷积网络,使卷积网络能够更加关心时间的重点信息和空间位置的重点信息,在仅增加微量参数的情况下提升一定的精度.本文主要贡献点包括:1)设计一种多重注意力机制,分为通道结合时间注意力机制和空间位置注意力机制两个模块;2) 分别在空间位置注意力机制上进行冗余时间压缩、在通道时间注意力机制上进行信息保留的改进;3) 将多重注意力机制部署到3D ResNet中,使其在参数只有微量增加的情况下,在UCF-101和HMDB-51数据集的性能有一定的提升.
1 相关工作
在视频分析中行为识别一直是重点研究的方向,传统特征提取方法如改机密集轨迹方法(improved dense trajectories,iDT)[12],其在性能上可以达到不错的效果,但是手动设计带来的繁琐及复杂尤为不便;自从深度学习在行为识别被引入以后,不断取得更优的效果.该领域中,深度学习主要分为3种方法: 双流法(two-stream)[13]、长短期记忆网络方法(long short-term memory, LSTM)[14]及3D卷积方法(3D CNN)[5].双流法通过提取视频中的光流信息和单帧图像进行融合训练,最终整合输出结果,目前能够达到的精度最高,然而其光流的提取需要占用大量的训练时间[15];LSTM方法通过选择性忘记和选择性记忆来传输状态,在序列建模问题上具有一定优势,能够解决长序列训练过程中梯度消失和梯度爆炸的问题,然而其在面对超长序列时依旧会失去效果且网络计算量很大、耗时偏多;3D卷积网络通过引入3D卷积和3D池化的操作.解决了2D卷积在时间维度上时间信息丢失的问题,虽然计算量较大于2D卷积网络,但相比于前两种方法处理速度会更快,在2015年就已达到了313 f·s-1[4].
注意力机制被引入卷积神经网络后对网络的提升效果相当显著,它能够让网络更加关注重点信息并且抑制无关信息.注意力机制按作用域来区分有空间域、通道域、层域、混合域的注意力机制.Xiao等[16]提出的空间变换器网络,其通过一个空间变换来提取空间域的信息;Hu等[17]提出的挤压激励网络 (squeeze-and-excitation networks, SENET)通过挤压、激励、注意3个步骤来完成通道域的注意力机制;Wang等[18]提出的残差注意力网络借鉴了残差网络的想法,将当前层的信息加上掩码作为下一层的输入来完成混合域的注意力机制,这使得网络得到的特征更为丰富.
在行为识别中,也有注意力机制的引入.Girdhar等[19]结合变换器设计一种注意力机制,能够自发学习跟踪并且从人的行为中获取上下文的语义信息.Kim等[20]通过引入一种自我监督来学习视频帧的空间外观和时间关系,以此进行行为识别的任务.可以发现,目前注意力机制更多的是在二维卷积上使用,而三维卷积则很少使用注意力机制.
基于以上问题的思考,本文提出一种适用于3D卷积网络的多重注意力机制.此注意力机制分为两个子模块,一个是通道结合时间的注意力机制模块,关心视频中的重要时间信息;另一个是空间位置注意力机制模块,关心的是单帧视频中空间位置的重点信息.此外,分别在通道结合时间的注意力机制上加强信息提取、在空间位置注意力机制上进行冗余时间压缩,改进完的注意力机制性能均有提升.
2 原理实现
2.1 整体方案
研究一种多重注意力机制的结构,使卷积网络能够更加关注视频中重点的时间信息和空间信息.文中将多重注意力机制部署至3D ResNet的每个卷积块中: 在卷积层之后先提取特征图中通道和时间上的重点信息,然后提取输出特征图中的重点空间位置信息, 如图1所示.
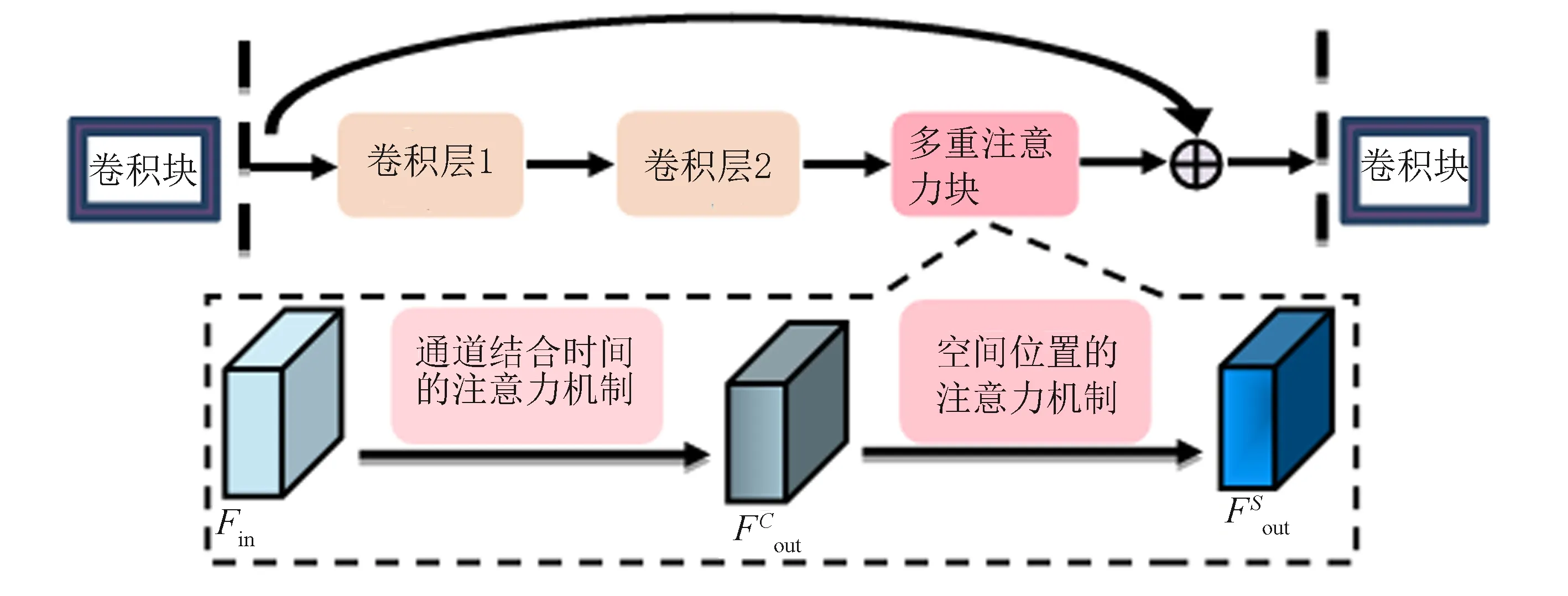
图1 镶嵌多重注意力机制的3D ResNet结构Fig.1 3D ResNet structure embedded with multiple attention mechanisms
2.2 通道结合时间注意力机制
在3D卷积中输入和输出的特征图一共有5个维度,分别是(N、C、D、H、W),其中N代表批尺寸大小,C代表通道数,D代表时间长度,H和W代表高度和宽度. 由于通道信息维度C和时间维度D的信息具有关联性,因此将通道信息与时间信息进行结合以更好地关注视频中的重点时域信息. 具体实现方式如图2所示,设计了三种不同的结构.

图2 两种通道结合时间的注意力机制结构Fig.2 Two attention mechanism structures of channel combined with time
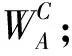
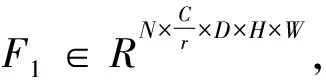
2.3 空间位置注意力机制
如图3所示,借鉴经典的CBAM算法中空间注意力机制子模块的思想,并将其推广到3D卷积网络中得到空间位置模块A(spatial position A,SPA)模块.
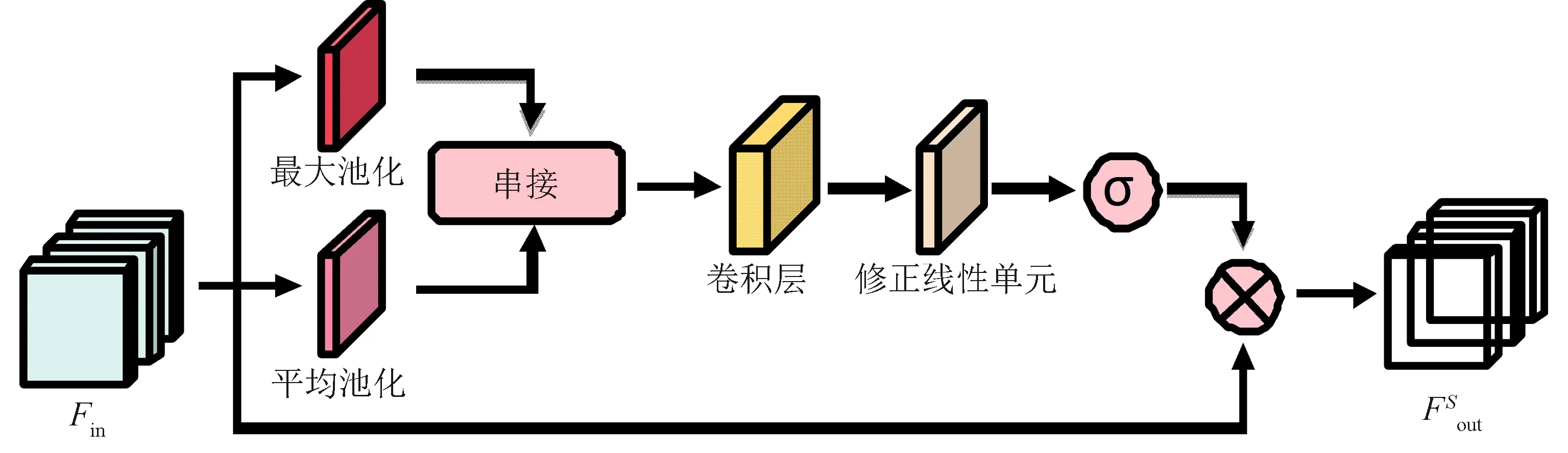
(a) SPA模块
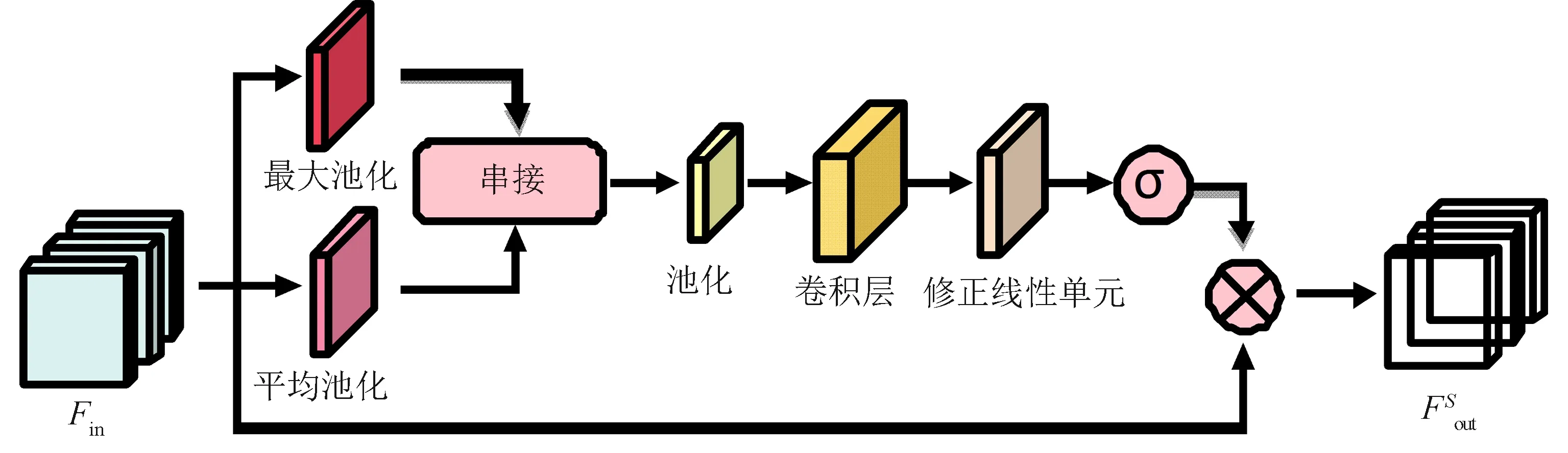
(b) SPB模块 图3 两种空间位置的注意力机制结构Fig.3 Two attention mechanism structures of spatial position
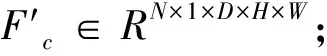

2.4 网络架构

3 实验验证
3.1 数据集
实验使用的数据集为UCF-101[21]和HMDB-51[22]两个中型数据集.UCF-101包含101类动作,共13 000多个视频,在动作的采集上具有多样性.HMDB-51包含51类动作,共6 000多个视频,包含一般的身体动作和交互动作等.
在所有实验中,网络的参数设置如下: 视频一次输入16帧,并以红绿蓝颜色的形式被调整成大小为128 px×171 px的尺寸;而后在每个输入中加入一个16 px×112 px×112 px 的随机抖动和50%概率的水平翻转;优化器选择带有动量的随机最速下降法,设置动量为0.9;批尺寸设为16,初始学习率设为10-3,并且每30个回合下降为原来的十分之一,共训练100个回合.
3.2 消融实验
本研究分别进行了5组实验,即3D ResNet-18、CTA模块与SPA模块的组合、CTA模块与SPB模块的组合、CTB模块与SPA模块的组合、CTB模块与SPB模块的组合.从头开始训练最终得到几组实验的Top-1精度,如表1所示.

表1 几种组合在UCF-101和HMDB-51下的Top-1精度
3.3 实验分析
根据表1可看到,在4种组合的多重注意力机制上,CTB模块与SPB模块的组合性能最好,且它们在单独和模块A组合时性能也优于CTA和SPA模块的组合.最终,CTB模块与SPB模块的组合在UCF-101数据集精度上可达到91.70%,相比于原始3D ResNet-18的90.2%的精度提升了1.5%;且在HMDB-51数据集上相比于3D-ResNet提升了1.24%.
为进一步验证多重注意力机制的通用性,文中将CTB + SPB模块的组合嵌入现有的3D网络,并在UCF-101下训练得到精度对比, 如表2所示.在加入多重注意力机制后,各3D卷积网络的性能相较于原始结构的性能均有提升,由此证明多重注意力机制的通用性强,可嵌入各3D卷积网络.

表2 各3D网络加入CTB + SPB与原始结构精度对比
3.4 对比实验
从表1中可得到在镶嵌了多重注意力机制的3D ResNet-18上的Top-1精度为91.7%.如表3所示,和现有的其他3D网络相比,它在UCF-101数据集上精度仅次于双流I3D方法.然而,双流法高精度因光流信息的提取步骤占据整个训练过程90%的时间,较为费时.文中的结构无需提取光流信息,在训练速度上优于双流I3D方法.为进一步探索模型的速度和衡量模型的复杂度,文中还进行了各网络之间浮点运算次数(FLOPs)的对比,如表4所示.可见双流I3D的光流输入及红绿蓝颜色输入需要经过两次网络,浮点运算为原I3D的两倍;而文中提出的 3D ResNet-18 + CTB + SPB结构浮点运算优于双流I3D.
在3D ResNet-18网络结构添加了多重注意力机制之后,参数量从33.24 MB增加到33.32 MB,只增加0.24%,可见加入多重注意力机制的残差网络参数量仅会微量增加.此外,本文的模型是未经过预训练的,在容易产生过拟合的中型数据集上依旧能够取得较佳的性能.

表3 现有3D网络在UCF-101上精度和参数量的对比
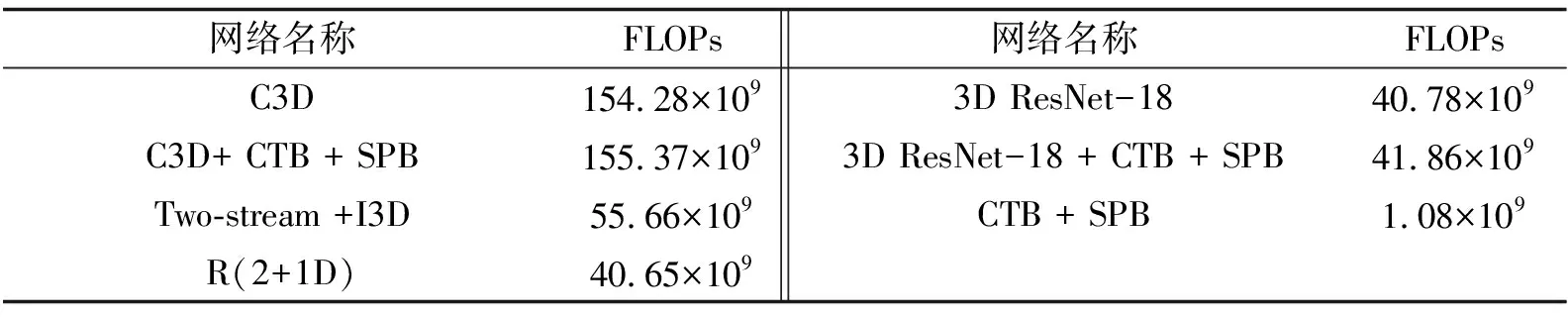
表4 现有3D网络浮点运算次数(FLOPs)的对比
4 结语
本文提出一种多重注意力机制用于提升3D卷积网络的表达能力,此多重注意力机制分为通道结合时间注意力机制和空间位置注意力机制.在探索结构中提出两种优化方法: 首先,去除通道结合时间注意力机制中的多层感知器并先进行卷积,减少信息损失并提高精度;其次,压缩空间位置的注意力机制中的时间维度,减少冗余时间信息.文中将多重注意力机制部署到3D ResNet-18中,相比于原始3D ResNet-18,在保持参数量仅增加0.24%情况下,在从头训练的UCF-101数据集上提升了1.5%,在HMDB-51数据集上提升了1.24%.此外,多重注意力机制模块通用性强,可以无缝镶嵌到各种3D卷积网络中.
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
一重技术(2021年5期)2022-01-18
北京航空航天大学学报(2021年9期)2021-11-02
甘肃教育(2020年22期)2020-04-13
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
电子制作(2018年11期)2018-08-04
北京航空航天大学学报(2018年1期)2018-04-20
第二课堂(课外活动版)(2016年2期)2016-10-21
华人时刊(2016年16期)2016-04-05
